
Скрытые недостатки в вашей стратегии A/B тестирования, о которых никто не говорит
12 августа 2025 г.Таблица ссылок
Введение
Гипотеза тестирование
2.1 Введение
2.2 Байесовская статистика
2.3 тестируйте мартингингинг
2.4 P-значения
2.5 Дополнительная остановка и взгляды
2.6 Сочетание P-значений и дополнительного продолжения
2.7 А/б -тестирование
Безопасные тесты
3.1 Введение
3.2 Классический T-критерий
3.3 Безопасный T-критерий
3.4 χ2 -Test
3,5 безопасного теста на пропорцию
Безопасное моделирование тестирования
4.1 Введение и 4.2 реализация Python
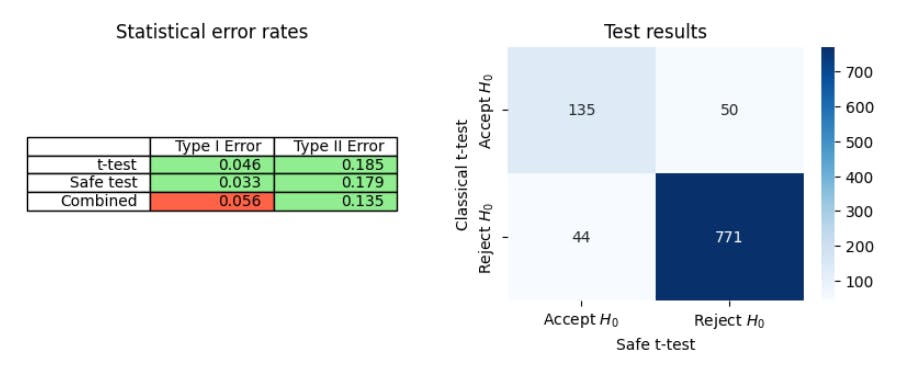
4.3 Сравнение t-теста с безопасным t-тестом
4.4 Сравнение χ2 -теста с тестом на безопасную пропорцию
Смесь последовательного теста вероятности
5.1 Последовательное тестирование
5.2 Смесь SPRT
5.3 MSPRT и безопасный T-критерий
Онлайн -контролируемые эксперименты
6.1 Безопасный t-тест на наборах данных OCE
Vinted A/B-тесты и 7.1 Safe T-критерий для Vinted A/B-тестов
7.2 безопасная пропорция для несоответствия соотношения образца
Заключение и ссылки
2.6 Сочетание P-значений и дополнительного продолжения
Комбинирование P-значений было предметом дебатов с момента их происхождения с Пирсоном и Фишером [HR18]. Эти методы часто применяются для мета-анализа для нескольких экспериментов. Существуют различные методы для разных контекстов, и не всегда ясно, какой метод следует использовать в данной ситуации. Безопасное тестирование обеспечивает простой, интуитивно понятный способ объединить результаты многих экспериментов.
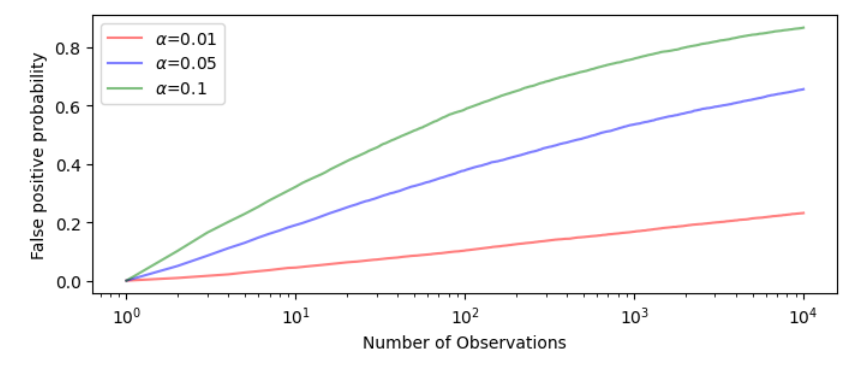
В разделе о мочащем виде было упомянуто, что экспериментаторы могут принять решение о результатах эксперимента на основе промежуточного наблюдаемого величины эффекта. При традиционном статистическом тестировании наблюдаемые результаты не являются статистически достоверными, и, следовательно, правильные выводы не могут быть сделаны. Безопасное тестирование, однако, позволяет экспериментатору принять решение продолжить тест, если требуется больше результатов для наблюдения за значительным эффектом.
2.7 А/б -тестирование
A/B Тестирование сначала появляется как простое применение статистических тестов; Тем не менее, есть нюансы, которые невероятно актуальны для экспериментаторов. Типичный тест A/B будет проходить автоматические измерения десятков или, возможно, сотни метрик. Рассмотрим тест, в котором экспериментатор хочет измерить влияние новой функции на влияние на продажи на их веб -сайте. АЦелевая метрикаДля этого эксперимента может быть общий продажи на одного пользователя. В дополнение к тестированию влияния функции на общие продажи, они, возможно, захотят увидеть больше взаимодействия со стороны пользователей, которые ничего не купили. Это связано с тем, что более высокое взаимодействие с платформой может увеличить свою ценность для пользователей. Поэтому мониторингВторичные метрики, например, количество любимых элементов на одного пользователя, время, потраченного на платформу, и доля поисков, которые приводят к продажам, могут дать дополнительную информацию о производительности функции. Однако могут быть непреднамеренные последствия этой функции. Может быть ошибка, которая заставляет веб -сайт разбиться в определенных браузерах, или эта функция может каннибализировать продажи более дешевых продуктов, показывая более дорогие. Поэтому крайне важно контролировать так называемыеМетрики ограждениячтобы гарантировать, что эта функция работает в соответствии с задумами.
Помимо метрик в эксперименте, есть и другие факторы, которые следует учитывать при оценке результатов. Большинство статистических тестов предполагают, что данные являются независимыми и одинаково распределены. Тем не менее, новая функция может привлечь интерес к любопытным пользователям, что приведет к ненадежным показателям. Это известно какЭффект новизны, и может сметить результаты теста. Другой момент рассмотрения - то время, которое требуется для сходящихся метрик. Некоторые показатели, такие как количество элементов, просмотренных после поиска, дают мгновенные результаты. Такая метрика, как доля пользователей, которые совершают покупку, может занять несколько дней, чтобы сходиться. Это потому, что они могут бытьнезащищенныйна тест во время просмотра продуктов и вернуться через несколько дней, чтобы совершить покупку. На этот раз между экспозицией теста и его реализацией может сделать некоторые показатели ненадежными в краткосрочной перспективе.
Окончательная задача крупномасштабного A/B-тестирования касается случайного назначения пользователей вариантам. Каждый эксперимент имеет связанную вероятность того, что пользователи будут назначены либо контрольной, либо тестовой группе. Результаты сеанса пользователя записаны в базе данных перед агрегированием в ходе метрических расчетов. Проблемы в этом процессе могут привести к неравным образцам в контрольной и тестовой группе. Это известно как несоответствие коэффициента образца (SRM) и может указывать на то, что результаты испытаний являются смещенными и, следовательно, ненадежными. Поэтому для экспериментаторов важно непрерывно отслеживать отношение выборки их A/B -тестов, чтобы остановить ошибочные эксперименты.
Обсуждая A/B -тестирование и негибкость традиционного статистического тестирования, мы теперь вводим безопасное тестирование и то, как его можно применить для решения этих вопросов.
Автор:
(1) Даниэль Бизли
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)