

Дизайн и внедрение локального кэша Presto в Uber
3 июня 2022 г.В предыдущем блоге мы рассказали о вариантах использования Uber Presto и о том, как мы совместно реализовали локальный кэш Alluxio для преодоления различных проблемы с ускорением запросов Presto. Во второй части обсуждаются улучшения метаданных локального кэша.
Метаданные на уровне файлов для локального кэша
Мотивация
Во-первых, мы хотим предотвратить устаревшее кэширование. Базовые файлы данных могут быть изменены сторонними платформами. Обратите внимание, что такая ситуация может быть редкой в таблицах Hive, но очень распространена в таблицах Hudi.
Во-вторых, ежедневное чтение недублированных данных из HDFS может быть большим, но у нас недостаточно места в кэше для кэширования всех данных. Следовательно, мы можем ввести управление квотами с заданной областью, установив квоту для каждой таблицы.
В-третьих, метаданные должны быть восстанавливаемыми после перезагрузки сервера. Мы сохранили метаданные в локальном кеше в памяти, а не на диске, что делает невозможным восстановление метаданных при выключении и перезапуске сервера.
Высокоуровневый подход
Поэтому мы предлагаем метаданные на уровне файлов, которые содержат и сохраняют время последнего изменения и область действия каждого кэшированного файла данных. Хранилище метаданных на уровне файлов должно быть постоянным на диске, чтобы данные не исчезли после перезапуска.
С введением метаданных на уровне файлов будет несколько версий данных. Новая временная метка создается при обновлении данных, соответствующих новой версии. Новая папка, в которой хранится новая страница, создается в соответствии с этой новой отметкой времени. В то же время мы постараемся удалить старую временную метку.
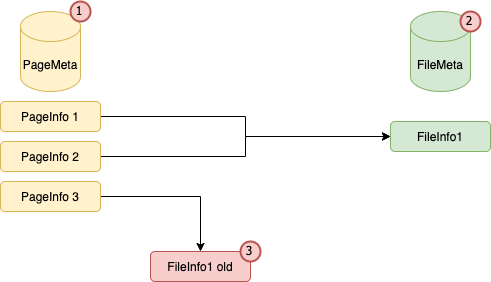
Структура кэшированных данных и метаданных

Как показано выше, у нас есть две папки, соответствующие двум временным меткам: временная метка1 и временная метка2. Обычно, когда система работает, двух временных меток одновременно не будет, потому что мы удалим старую временную метку1 и оставим только временную метку2. Однако в случае загруженного сервера или высокого параллелизма мы не сможем вовремя удалить метку времени, и в этом случае у нас может быть две метки времени одновременно. Кроме того, мы поддерживаем файл метаданных, который содержит информацию о файле в формате protobuf и последнюю отметку времени. Это гарантирует, что локальный кеш Alluxio считывает данные только из самой последней метки времени. Когда сервер перезапускается, информация о временной метке считывается из файла метаданных, чтобы можно было правильно управлять квотой и временем последнего изменения.
Осведомленность о метаданных
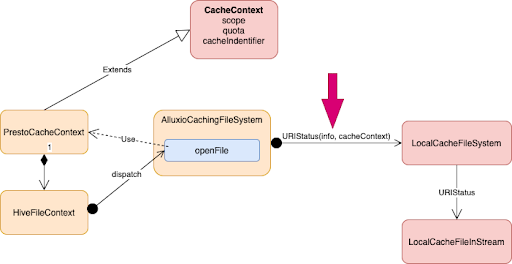
Контекст кэша
Поскольку Alluxio — это универсальное решение для кэширования, для передачи метаданных в Alluxio по-прежнему требуется вычислительный движок, такой как Presto. Поэтому на сайте Presto мы используем HiveFileContext. Для каждого файла данных из таблицы Hive или таблицы Hudi Presto создает HiveFileContext. Alluxio использует эту информацию при открытии файла Presto.
При вызове openFile Alluxio создает новый экземпляр PrestoCacheContext, который содержит HiveFileContext и имеет область действия (четыре уровня: база данных, схема, таблица, раздел), квоту, идентификатор кеша (т. е. значение md5 пути к файлу) и Дополнительная информация. Мы передадим этот контекст кэша в локальную файловую систему. Таким образом, Alluxio может управлять метаданными и собирать метрики.
Агрегация метрик по запросу на стороне Presto
Помимо передачи данных из Presto в Alluxio, мы также можем перезвонить в Presto. При выполнении операций запроса мы будем знать некоторые внутренние показатели, например, сколько байтов прочитанных данных попало в кеш и сколько байтов данных было прочитано из внешнего хранилища HDFS.
Как показано ниже, мы передаем HiveFileContext, содержащий PrestoCacheContext, в локальную файловую систему кэша (LocalCacheFileSystem), после чего локальная файловая система кэша выполняет обратный вызов (IncremetCounter) в CacheContext. Затем эта цепочка обратных вызовов продолжится в HiveFileContext, а затем в RuntimeStats.
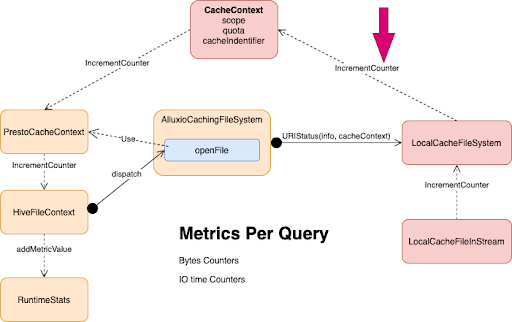
В Presto RuntimeStats используется для сбора информации о метриках при выполнении запросов, чтобы мы могли выполнять операции агрегирования. После этого мы можем увидеть информацию о файловой системе локального кеша в пользовательском интерфейсе Presto или в файле JSON. Мы можем заставить Alluxio и Presto тесно сотрудничать с описанным выше процессом. Что касается Presto, у нас лучшая статистика; на стороне Alluxio у нас есть более четкое представление о метаданных.
Будущая работа
Настройка производительности
Поскольку описанный выше процесс обратного вызова значительно увеличивает жизненный цикл CacheContext, мы столкнулись с некоторыми проблемами, связанными с увеличением задержки сборщика мусора, над решением которых мы работаем.
Принять семантический кэш (SC)
Мы реализуем семантический кэш (SC) на основе предлагаемых нами метаданных файлового уровня. Например, мы можем сохранить структуры данных в файлах Parquet или ORC, таких как нижний колонтитул, индекс и т. д.
Более эффективная десериализация
Чтобы добиться более эффективной десериализации, мы будем использовать flatbuf вместо protobuf. Хотя protobuf используется в фабрике ORC для хранения метаданных, мы обнаружили, что метаданные ORC составляют более 20-30% от общего использования ЦП в сотрудничестве Alluxio с Facebook. Поэтому мы планируем заменить существующий protobuf на flatbuf для хранения кеша и метаданных, что, как ожидается, значительно повысит производительность десериализации.
Подводя итог, вместе с предыдущим блогом в этой серии блогов, состоящей из двух частей, рассказывается, как мы создали новый уровень кэширования горячих данных, необходимых для нашего парка Presto, на основе недавнего сотрудничества с открытым исходным кодом между сообществами Presto и Alluxio в Uber. Этот архитектурно простой и понятный подход может значительно сократить задержку HDFS с помощью управляемого твердотельного накопителя и согласованного планирования мягкого сходства на основе хэширования. Присоединяйтесь к более чем 9000 участникам нашего сообщества slack channel, чтобы узнать больше.
Об авторах
Чэнь Лян — старший инженер-программист в интерактивной аналитической группе Uber, специализирующийся на Presto. До прихода в Uber Чен был штатным инженером-программистом на платформе больших данных LinkedIn. Чен также является коммиттером и членом PMC Apache Hadoop. Чен имеет две степени магистра Университета Дьюка и Университета Брауна.
Др. Бейнан Ван — инженер-программист из Alluxio и коммиттер PrestoDB. До Alluxio он был техническим руководителем команды Presto в Twitter и создавал крупномасштабные распределенные системы SQL для платформы данных Twitter. Он имеет двенадцатилетний опыт работы в области оптимизации производительности, распределенного кэширования и обработки объемных данных. Он получил докторскую степень. в компьютерной инженерии из Сиракузского университета по проверке символьных моделей и проверке распределенных систем во время выполнения.
*Также опубликовано [здесь].
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27648)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)