

Ускорение Presto от Uber с помощью Alluxio — часть 1
2 июня 2022 г.Уменьшите задержку HDFS с помощью управляемого SSD-кэша Alluxio и планирования Soft Affinity на основе согласованного хэширования Presto
Фон

В Uber данные учитывают каждое решение. Presto — один из основных движков, который поддерживает все виды анализа данных в Uber. Например, операционная группа активно использует Presto для таких сервисов, как панель мониторинга; Uber Eats и маркетинговые команды полагаются на результаты этих запросов при принятии решений о ценах. Кроме того, Presto также используется в отделе соответствия Uber, отделе маркетинга роста и специальной аналитике данных.

Масштабы Presto в Uber велики. В настоящее время Presto имеет 7 тысяч активных пользователей в неделю, обрабатывает 500 тысяч запросов в день и обрабатывает более 50 ПБ данных. У Uber есть два центра обработки данных с 5000 узлов и 15 кластеров Presto в 2 регионах с точки зрения инфраструктуры.
Предварительное развертывание Uber
Текущая архитектура
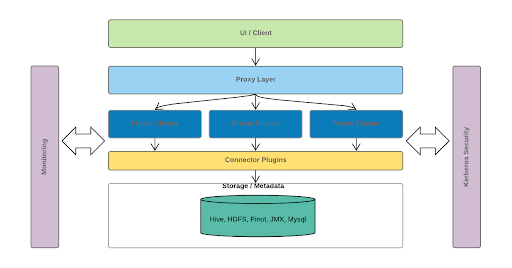
Архитектура Uber Presto показана на диаграмме выше.
- Уровень пользовательского интерфейса/клиента. Сюда входят внутренние информационные панели, Google Data Studio, Tableau и другие инструменты. Кроме того, у нас есть несколько серверных служб, которые используют JDBC или синтаксический анализ запросов для связи с Presto.
- Прокси-уровень. Этот уровень отвечает за получение статистики от каждого координатора Presto, включая количество запросов и задач, использование ЦП и памяти и так далее. На основе этой статистики мы определяем, к какому кластеру должен быть запланирован каждый запрос. Другими словами, он выполняет функции балансировки нагрузки и блокировки запросов.
- Престо-кластеры. Внизу несколько кластеров Presto взаимодействуют с базовыми Hive, HDFS, Pinot и другими. Операции соединения могут выполняться между разными плагинами или разными наборами данных.
Кроме того, для каждого уровня вышеуказанной архитектуры имеем
- Внутренний мониторинг
- Поддержка использования безопасности Kerberos
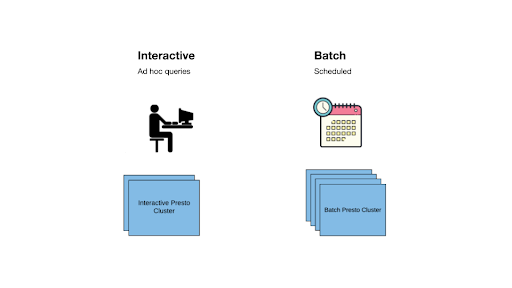
Рабочие нагрузки Presto делятся на две категории.
- Интерактивный: запрос, отправленный специалистами по данным и инженерами.
- Запланировано: в основном пакетный запрос, который является запланированным и повторяющимся, включая запрос панели мониторинга, запрос ETL и т. д.
Путешествие в облако
Последние несколько лет команда Uber думала о том, как и когда перейти в облако и какой должна быть компоновка для взаимодействия с облаком. Мы используем модель «что-почему-как».
Что: у нас есть множество прикладных уровней, таких как приложения бизнес-аналитики. Что касается вычислительного движка, у нас есть Spark, Presto и так далее. В облаке существует множество облачных вариантов. Что касается хранилища, мы можем выбрать GCS, S3, HDFS в облаке и многие другие варианты.
Почему: Одним из наиболее важных мотивов является повышение экономической эффективности и гибкое масштабирование аппаратных ресурсов. Кроме того, мы хотим добиться высокого удобства использования, масштабируемости и надежности.
Как: С одной стороны, поскольку облако предоставляет множество нативных функций, нам необходимо учитывать совместимость функций с компонентами с открытым исходным кодом. С другой стороны, нам нужно выяснить, как работает производительность в разных масштабах. Uber владеет огромным озером данных, поэтому производительность имеет решающее значение для клиентов и для нас. Кроме того, мы изучаем способность облака обеспечивать соблюдение требований безопасности и соответствия. Собственные облачные сервисы также можно использовать для сокращения «технического долга».
Будущее — гибридное облако
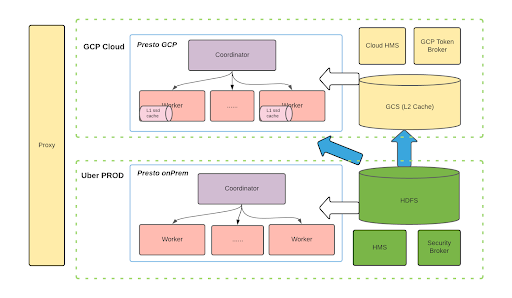
На приведенной выше диаграмме показан долгосрочный план. Решение может быть распространено на различных поставщиков облачных услуг на основе такой архитектуры. Сейчас мы все еще находимся на очень ранних стадиях реализации.
Мы хотим запустить гибридную модель с кластерами PROD (локальными) и облачными кластерами (GCP).
Как показано в правом нижнем углу рисунка, мы ожидаем, что большая часть данных по-прежнему будет храниться в локальной файловой системе HDFS. Синие стрелки обозначают некоторые предварительные тесты, которые мы провели, когда мы проводили некоторые эксперименты без какого-либо кэширования поверх HDFS. Результаты показали высокий сетевой трафик и стоимость, что является огромным накладным расходом.
Поэтому мы изучаем общедоступные облачные сервисы, такие как GCS или S3, в качестве кэша L2. Мы хотим поместить некоторые важные данные или часто используемые наборы данных в «кэш L2 в облаке». Для каждого кластера Presto в облаке мы планируем использовать локальные твердотельные накопители для кэширования некоторых данных для повышения производительности. Это решение можно масштабировать для разных облачных провайдеров, использующих одну и ту же архитектуру, что является нашим видением в долгосрочной перспективе.
Использование Alluxio для локального кэширования
Недавно мы развернули Alluxio в среде нашего продукта в трех кластерах, каждый из которых содержит более 200 узлов. Alluxio подключается как локальная библиотека и использует локальные диски NVMe рабочих Presto. Мы кэшируем не все данные, а выборочное подмножество данных, называемое выборочным кэшированием.
Ниже представлена схема Alluxio в качестве локального кэша. Библиотека Alluxio Cache — это локальный кеш, который работает внутри рабочего процесса Presto. Мы реализовали слой поверх реализации клиента HDFS по умолчанию.
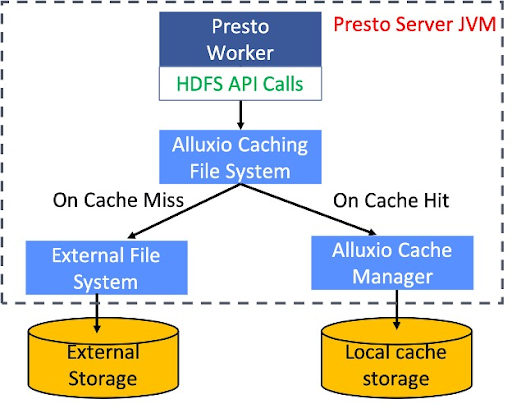
Когда какой-либо внешний API считывает вызов HDFS, система сначала просматривает инвентаризацию кеша, чтобы определить, является ли это попаданием в кеш или нет. Если это попадание в кеш, он будет напрямую считывать данные с локального SSD. В противном случае он будет считывать данные с удаленной HDFS и локально кэшировать данные для следующего чтения. В этом процессе частота попаданий в кэш оказывает значительное влияние на общую производительность.
Мы обсудим детальное проектирование и улучшение локального кэша Alluxio во второй части этой серии блогов.
Ключевые проблемы и решения
Задание 1: Обновление разделов в реальном времени
Первой проблемой, с которой мы столкнулись, были обновления разделов в реальном времени. В Uber многие таблицы/разделы постоянно меняются, потому что мы постоянно добавляем запросы в таблицы Hudi.
Проблема заключается в том, что одного идентификатора раздела в качестве ключа кэширования недостаточно. Этот же раздел мог измениться в Hive, а Alluxio все еще кэширует устаревшую версию. В этом случае разделы в кеше устарели, поэтому пользователи получат устаревшие результаты при выполнении запроса, если данные обслуживаются из кэша, что приводит к несогласованности работы.
Решение: добавьте время последней модификации Hive в ключ кэширования
Наше решение заключается в добавлении времени последней модификации к ключу кэширования, как показано ниже:
- Предыдущий ключ кэширования: hdfs://<путь>
- Новый ключ кеширования: hdfs://
Благодаря этому решению новый раздел с последней модификацией кэшируется, гарантируя, что пользователи всегда будут получать согласованное представление своих данных. Обратите внимание, что есть компромисс — устаревшие разделы все еще присутствуют в кеше, тратя место в кеше до тех пор, пока они не будут удалены. В настоящее время мы работаем над улучшением стратегии вытеснения кэширования.
Задание 2: изменение членства в кластере
В Presto планирование Soft Affinity реализовано с помощью простого алгоритма на основе модов. Недостаток этого алгоритма в том, что при добавлении или удалении узла все кольцо запутывается из-за другого ключа кэша. Следовательно, если узел присоединяется к кластеру или покидает его, это может снизить эффективность кэширования всех узлов, что является проблемой.
По этой причине Presto находит тот же набор узлов для данного ключа раздела. В результате мы всегда обращаемся к одному и тому же набору узлов как для кэширования, так и для запросов. Хотя это хорошо, проблема в том, что Presto ранее использовала простую хеш-функцию, которая может сломаться при изменении кластера.
Как показано ниже, в настоящее время поиск узла на основе простого хэш-мода: ключ 4 % 3 узла = рабочий № 1. Теперь узел № 3 отключается, новый поиск: ключ 4 % 2 узла = 0, но рабочий № 0 не имеет байтов. .
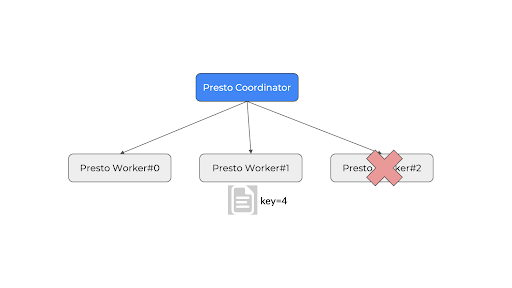
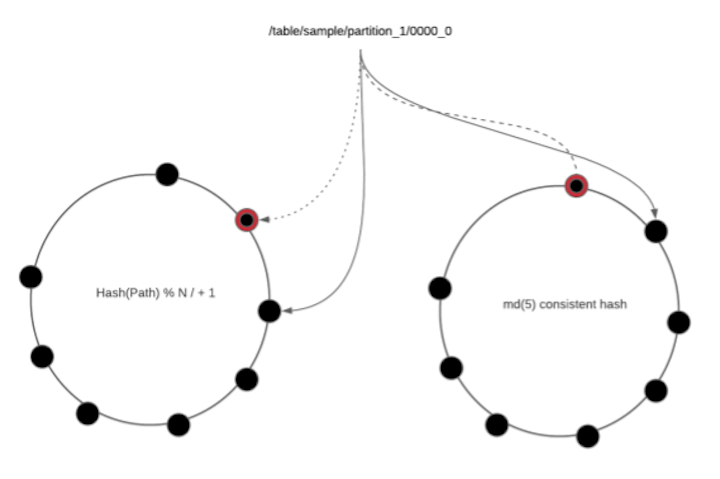
Решение: согласованное хеширование на основе идентификатора узла
Последовательное хеширование является решением. Вместо функции, основанной на модах, все узлы помещаются в виртуальное кольцо. Относительный порядок узлов в кольце не меняется независимо от того, присоединяются они или удаляются. Вместо использования хэша на основе режима мы всегда ищем ключ в кольце. Мы можем гарантировать, что независимо от того, сколько изменений будет сделано, они всегда будут основаны на одном и том же наборе узлов. Кроме того, мы используем репликацию для повышения надежности. Это решение проблемы членства в кластере.
Задание 3: Ограничение размера кэша
Озеро данных Uber имеет большие масштабы: в день накапливается 50 ПБ данных. Однако наше локальное дисковое пространство составляет всего 500 ГБ на узел. Объем данных, к которым обращаются запросы Presto, намного больше, чем дисковое пространство, доступное на рабочих узлах. Хотя в кеш можно поместить все, интенсивное вытеснение может снизить общую производительность кеша.
Решение: Фильтр кеша
Идея состоит в том, чтобы кэшировать только выбранное подмножество данных, которое включает определенные таблицы и определенное количество разделов. Решение состоит в том, чтобы разработать фильтр кеша, механизм, который решает, следует ли кэшировать таблицу и сколько разделов. Ниже приведен пример конфигурации:
"базы данных": [{
"имя": "база данных_foo",
"столы": [{
"имя": "таблица_бар",
"maxCachedPartitions": 100}]}]
Наличие фильтра кеша значительно увеличило количество попаданий в кеш с \~65% до >90%. Ниже приведены области, на которые следует обратить внимание, когда дело доходит до кэш-фильтра.
- Ручная, статическая конфигурация
- Должно быть основано на схеме трафика, например:
- Наиболее часто используемые таблицы
- Наиболее распространенное количество разделов, к которым осуществляется доступ
- Таблицы, которые не меняются слишком часто
- В идеале должно основываться на показателях теневого кэширования и показателях на уровне таблицы.
Мы также добились наблюдаемости с помощью мониторинга/панели мониторинга, которые интегрированы с платформой внутренних метрик Uber с использованием метрик Jmx, передаваемых на панель инструментов на основе Grafana.


Текущее состояние и будущая работа
Текущий статус
Мы развернули 3 кластера по 200+ узлов каждый в нашем производственном кластере со всеми узлами на дисках NVMe и объемом кэш-памяти 500 ГБ на каждый узел. Мы использовали фильтр кеша, чтобы кэшировать около 20 наиболее часто используемых таблиц.
Мы все еще находимся на ранней стадии развертывания и мониторинга результатов. Начальное измерение показывает значительное улучшение: около 1/3 времени стены для сканирования ввода (TableScanOperator и ScanFilterProjectOperator) по сравнению с отсутствием кэша. Мы очень воодушевлены этими результатами. Alluxio продемонстрировал отличное ускорение запросов и обеспечивает стабильную производительность в наших сценариях обработки больших данных.
Следующие шаги
Во-первых, мы хотели бы подключить больше столов и улучшить процесс подключения столов с помощью автоматизации, в чем будет полезен Alluxio Shadow Cache (SC). Во-вторых, мы хотим улучшить поддержку изменяющихся разделов/таблиц Hoodie. Наконец, балансировка нагрузки — это еще одна оптимизация, которую мы можем реализовать. Впереди еще долгий путь в нашем путешествии.
Поскольку разделение вычислений и хранилища продолжает оставаться тенденцией наряду с контейнеризацией больших данных, мы считаем, что унифицированный уровень, объединяющий вычисления и хранилище, такой как Alluxio, будет продолжать играть ключевую роль.
Мы поделимся подробным описанием дизайна и улучшения локального кэша Alluxio в следующем блоге.
Об авторах
Chen Liang
Чен Лян — старший инженер-программист интерактивной аналитической группы Uber, специализирующийся на Presto. До прихода в Uber Чен был штатным инженером-программистом на платформе больших данных LinkedIn. Чен также является коммиттером и членом PMC Apache Hadoop. Чен имеет две степени магистра Университета Дьюка и Университета Брауна.
Beinan Wang
Доктор Бейнан Ван — инженер-программист из Alluxio и коммиттер PrestoDB. До Alluxio он был техническим руководителем команды Presto в Twitter и создавал крупномасштабные распределенные системы SQL для платформы данных Twitter. Он имеет двенадцатилетний опыт работы в области оптимизации производительности, распределенного кэширования и обработки объемных данных. Он получил докторскую степень. в компьютерной инженерии из Сиракузского университета по проверке символьных моделей и проверке распределенных систем во время выполнения.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27702)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)