Многие путают мониторинг и наблюдаемость. Хотя эти слова имеют схожие определения, они имеют существенно разные значения в контексте DevOps. Крайне важно понимать эти различия, чтобы выбрать лучшие решения для обеспечения качества и отслеживания ошибок для вашего проекта и, в конечном счете, минимизировать количество ошибок, попадающих в производственную среду.
Давайте посмотрим на сходства и различия между мониторингом и наблюдаемостью, а также на то, как вы можете совместить эти две стратегии, чтобы свести к минимуму количество и серьезность ошибок, попадающих в рабочую среду.
Мониторинг и наблюдаемость могут иметь схожие определения, но это совершенно разные концепции в контексте DevOps.
Определение мониторинга и приложений Наблюдаемость
Системымониторинга отслеживают заранее заданный набор показателей и журналов для обнаружения известных видов сбоев. Например, вы можете посмотреть на показатели времени отклика, чтобы выявить потенциальные проблемы с масштабируемостью. Если время отклика увеличивается, вы можете запустить новые серверы, чтобы снизить нагрузку. Вы также можете просмотреть долгосрочные тенденции, чтобы предсказать будущие проблемы с производительностью.
Системы наблюдаемости помогают понять внутреннее состояние системы на основе ее внешних выходных данных. Несмотря на то, что наблюдаемые системы имеют мониторинг, они делают еще один шаг и отслеживают основную причину проблем в стеке приложений. Другими словами, это помогает выйти за рамки того, что произошло и когда, чтобы понять, почему это произошло и как это исправить.
Наблюдаемость также выявляет неизвестные проблемы. Например, системы мониторинга могут выявить увеличенное время отклика, но наблюдаемость может зафиксировать запрос к базе данных в качестве основной причины. В результате вы сможете реализовать простое изменение запроса, а не платить за новую мощность сервера.
«Три столпа» наблюдаемости
Наблюдаемость состоит из трех компонентов: журналов, метрик и трассировки. Отслеживая метрики, идентифицируя проблемы, журналы и трассировки помогают диагностировать основную причину этих проблем, анализируя как сеть, так и приложение. В результате наблюдаемые системы должны включать все три компонента для эффективной диагностики и устранения ошибок.
Три столпа включают в себя:
- Журналы. Журналы получают метки времени и представляют собой неизменяемые записи отдельных событий, которые дают представление о том, что произошло, когда что-то пошло не так. Вы можете легко анализировать журналы с помощью визуализаций или быстро запрашивать их для поиска информации с помощью структурированных журналов.
- Метрики. Метрики — это подсчеты или измерения, которые вы можете агрегировать с течением времени. Например, метрики могут отслеживать уровни использования памяти или пропускную способность запросов, устанавливая базовые уровни и облегчая обнаружение аномального поведения.
- Трассы. Трассировки предоставляют подробный обзор отдельного запроса, чтобы определить, какие компоненты вызвали ошибки. Отслеживая запросы в стеке приложений, вы можете быстро диагностировать причину проблемы или выявить узкие места в производительности.
Наблюдение + мониторинг
Мониторинг и возможность наблюдения не являются взаимоисключающими понятиями. Скорее, каждая наблюдаемая система по определению имеет встроенные возможности мониторинга. Мониторинг сообщает вам, когда что-то не так, а наблюдаемость помогает понять, почему. Но, к сожалению, построение наблюдаемых систем может быстро стать проблемой для сложных систем.
Вот некоторые рекомендации:
- Определите ключевые показатели. Начните с определения ключевых показателей, применимых к вашему приложению, таких как использование ЦП, емкость хранилища или число транзакций в секунду. Затем настройте системы отслеживания для отслеживания этих показателей и тенденций с течением времени.
- Структурируйте свои журналы. Внедрите структурированные журналы, которые легко анализировать с помощью таких языков, как YAML или JSON. Затем определите такие решения, как OpenTelemetry, которые помогут вам быстро визуализировать и запрашивать журналы для поиска необходимой информации.
- Эффективная трассировка. Ищите решения для трассировки, которые работают со стеком вашего приложения, чтобы быстро отследить основную причину проблем. Лучшие решения могут даже помочь автоматически создавать отчеты об ошибках и сообщать о них остальной команде.
- Автоматизация процессов. Непрерывная интеграция и разработка (CI/CD) упрощают автоматизацию наблюдения. Например, вы можете настроить минимальные пороги ошибок для новых выпусков и ограничить выпуски с низкими показателями стабильности.
Подход с ошибками
Bugsnag — это надежное комплексное решение для наблюдения. В отличие от обычных решений для мониторинга, таких как инструменты APM, платформа обеспечивает полноценную сквозную диагностику, помогающую воспроизвести каждую ошибку. Кроме того, уникальные инструменты Bugsnag помогут вам приоритизировать ошибки, найти баланс между устранением ошибок и разработкой новых функций и оптимизировать взаимодействие команды.
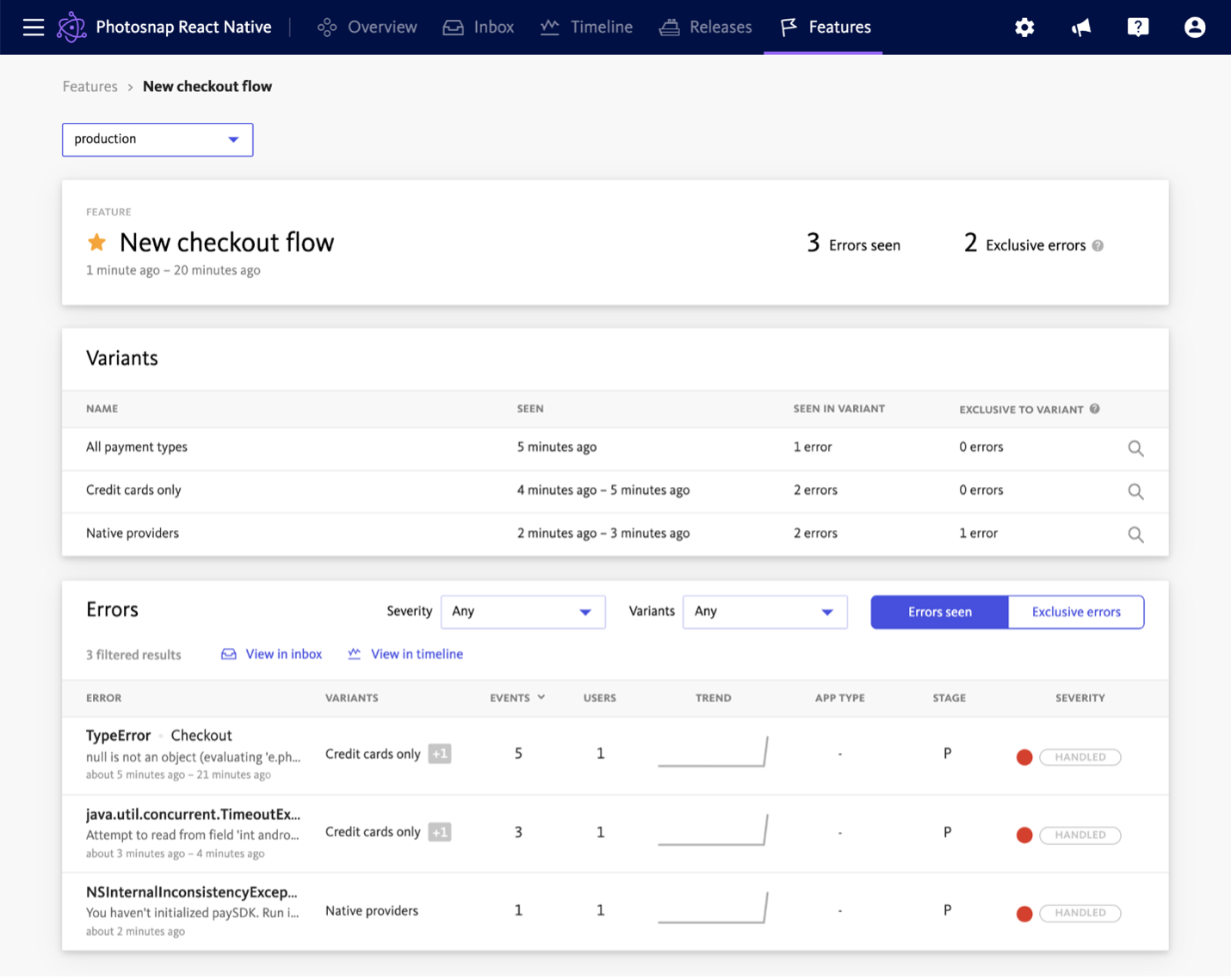
С помощью панели функций от Bugsnag легко выявлять ошибки, возникающие при пометке функции или эксперименте. был активен. Источник: Bugsnag
Процесс состоит из нескольких шагов:
- Стабилизация. Установите целевые показатели стабильности, которые измеряют процент пользовательских сеансов в версии без сбоев. Это позволяет быстро определить, соответствует ли новая версия минимальным требованиям к стабильности или ее нужно отложить для устранения неполадок.
- Приоритизация. Приоритизация ошибок в зависимости от их серьезности с учетом количества затронутых пользователей. Кроме того, вы можете использовать закладки для выявления ошибок, влияющих на VIP-клиентов или SLA. Таким образом, вы сможете сосредоточиться только на самом важном.
- Исправлено. Трассировка стека позволяет легко определить точную строку кода, вызывающую проблемы, и отследить действия пользователя, которые могли привести к ошибке. Кроме того, вы можете автоматически уведомлять соответствующие команды на основе закладок, чтобы избежать усталости от уведомлений.
Итог
Мониторинг и наблюдаемость — важные концепции DevOps, но часто их неправильно понимают. В то время как мониторинг отслеживает любые возникающие ошибки, наблюдаемость помогает определить основную причину ошибки, чтобы помочь в ее устранении. проблемы. Например, они могут использовать трассировки для идентификации кода приложения, ответственного за замедление работы на уровне сети.
Тем не менее, производственные приложения терпят неудачу по самым разным причинам, и всегда будет что-то, что пойдет не так. Ключом к успеху является понимание того, что идет не так, и определение того, что стоит исправить, а не просто надежда, что ничего плохого не произойдет.
Используя универсальные инструменты, такие как Bugsnag, вы оптимизируете отслеживание и исправление ошибок с помощью инструментов мониторинга и наблюдения. Это самый простой способ обнаружить проблемы, устранить ошибки и сосредоточиться на наиболее эффективных действиях, чтобы создать долгосрочную ценность для ваших пользователей. В то же время платформа позволяет легко направлять проблемы нужным разработчикам в нужное время для устранения.
Подпишитесь на бесплатную пробную версию или запросить демо сегодня!