
SAINE — математически одно из лучших начальных слов WORDLE — вот почему
16 апреля 2022 г.TLDR: я написал бот-решатель Wordle с Javascript и UIlicious. Вы можете повторно запустить или отредактировать этот фрагмент в любой день, чтобы получить ежедневное решение Wordle. Попробуйте и посмотрите, сможете ли вы получить больше очков, чем бот! Не стесняйтесь редактировать его и оптимизировать алгоритм решения!
Полное раскрытие информации: я являюсь соучредителем и техническим директором Uilicious.com (показан в этой статье)
Решатель Wordler состоит из 3 частей, которые охватывают
- Код взаимодействия с пользовательским интерфейсом (ссылка здесь)
- Статистическая модель Wordle и лежащая в ее основе математика (эта статья)
- Модульное тестирование и бенчмаркинг решателя слов (@todo)
*Все статистические примеры можно найти по следующей ссылке: https://uilicio.us/wordle-statistics-sample. Они генерируются с помощью кода, используемого здесь: https://github.com/uilicious/wordle-solver. -и-тестер>

Наша стратегия WORDLE
Отказ от ответственности, я не претендую на то, что это лучшая WORDLE-стратегия (пока), но она довольно хороша =)
Прежде чем перейти к статистике, давайте сначала рассмотрим нашу стратегию WORLDE.
Одна вещь, в которой люди действительно хорошо справляются с классическими компьютерами, — это «интуитивное» понимание вещей. Если я не планирую обучать нейронную сеть, компьютерная программа, которую я разрабатываю, должна будет использовать классический список слов из словаря, чтобы делать свои предположения.
Однако компьютеры хорошо умеют запоминать гигантские списки слов или данных. И выполняя математику на нем. Итак, давайте использовать это в наших интересах, выполнив следующую последовательность.
Учитывая список из 2 слов, один из которых содержит возможные ответы (~ 2,3 тыс. слов), а другой - полный список слов (13 тыс. слов)...
- Отфильтруйте слова в списке возможных ответов по текущему состоянию игры из прошлых догадок.
- Подсчитайте, сколько раз каждый символ появляется в списке слов ответа на соответствующих позициях в словах.
- Из полного списка слов выберите слово, которое с наибольшей вероятностью найдет правильное угадывание символа. Независимо оценивайте его, отдавая предпочтение словам, которые дают больше информации в первых 4 раундах с точным или частичным совпадением.
- Выберите слово с самым высоким рейтингом и попробуйте его.
- Повторите сверху, если необходимо.
Также для уточнения: Мы не запоминаем предыдущие решения Wordle (я чувствовал, что это обман, поскольку система могла в конечном итоге просто запоминать список повседневных дел в последовательности).
В то время как точные детали подсчета очков немного меняются в зависимости от раунда — для оптимизации. Это не меняет общей концепции на высоком уровне.
Так как же это работает на практике? Для нашей текущей итерации стратегии Wordle мы рассмотрим это на практике шаг за шагом (без кода).
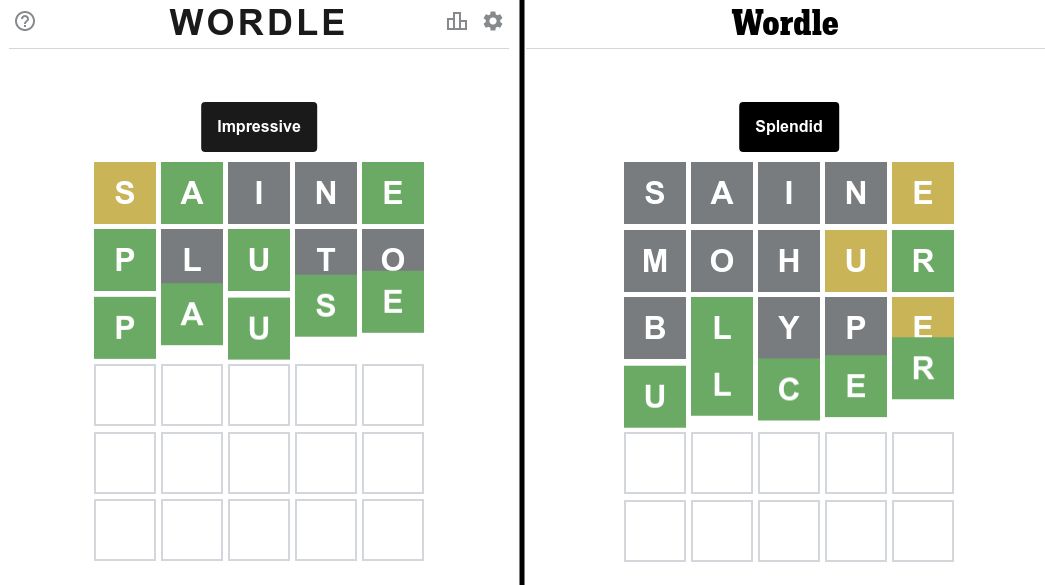
Наше начальное слово: SAINE - и почему вы должны его использовать
- Псевдоним к sain, что означает: перекрестить (себя), чтобы благословить или защитить от зла или греха *
Было много советов по начальным 2 словам. И имеет смысл, что это слово следует с:
- 3 очень распространенных гласных
- Все уникальные персонажи
Но давайте разберемся, почему решатель выбирает именно это слово, взглянув на цифры.
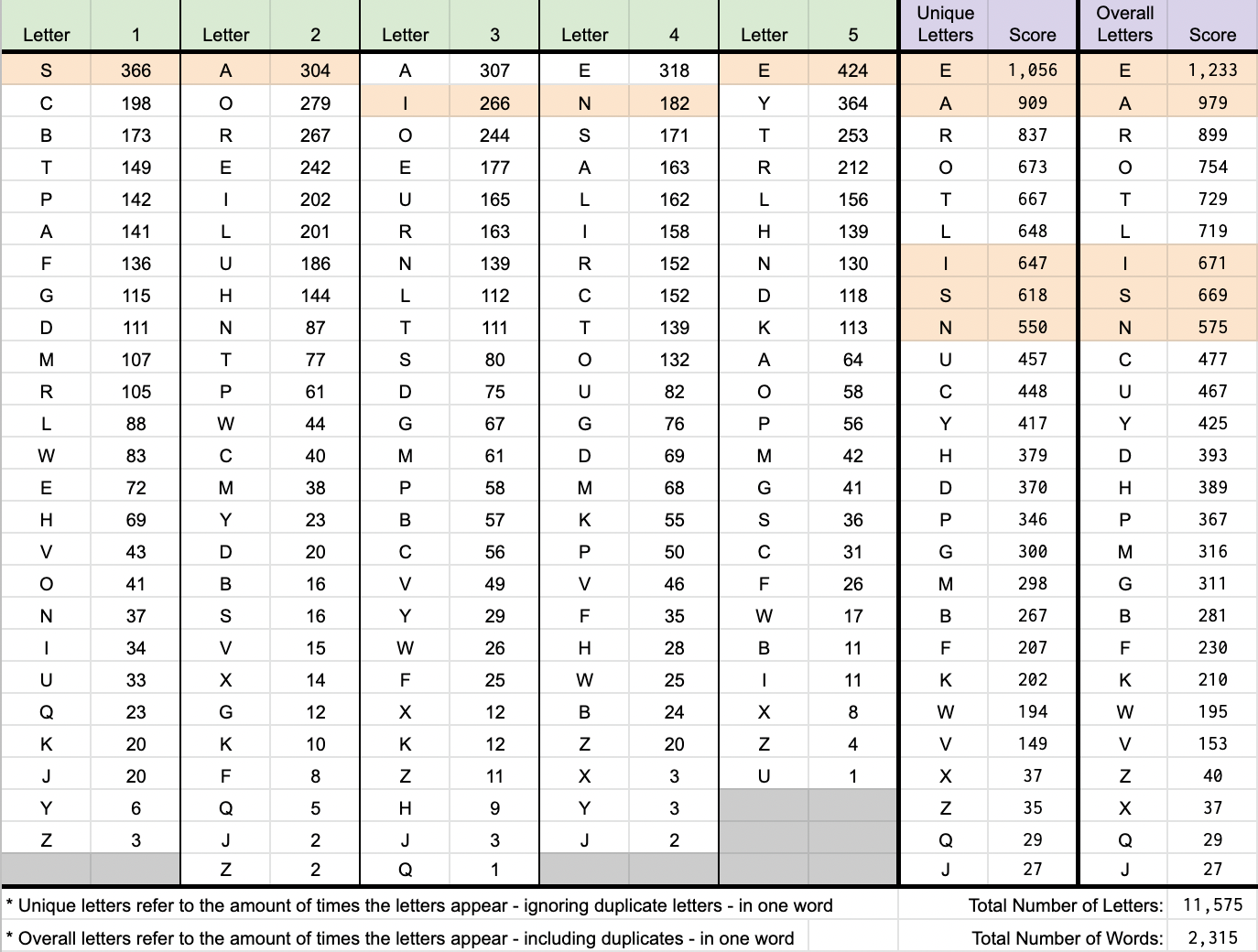
На основе статистики. «SAINE» имеет самый высокий шанс найти точное совпадение зеленого символа в качестве начального слова, имея 3 верхних гласных.
Понятно, что чтение необработанной таблицы распределения может быть трудным для восприятия. Итак, позвольте мне изменить контекст этих цифр здесь. СЕЙН имеет…
- 91,06% вероятность частичного совпадения хотя бы 1 символа (желтый/зеленый);
- 55,94% вероятность частичного совпадения как минимум 2 символов (желтый/зеленый);
- 50,24% шанс точного совпадения хотя бы с 1 символом (зеленый).
Существует очень высокая вероятность получить хотя бы одну или две важные подсказки. И наоборот, поскольку слов без A, I и E мало, несоответствие является «огромной подсказкой».
Неплохо для открытия, да?
А как насчет других популярных вступительных слов, таких как «КРАН» и «АСПЕКТ»?
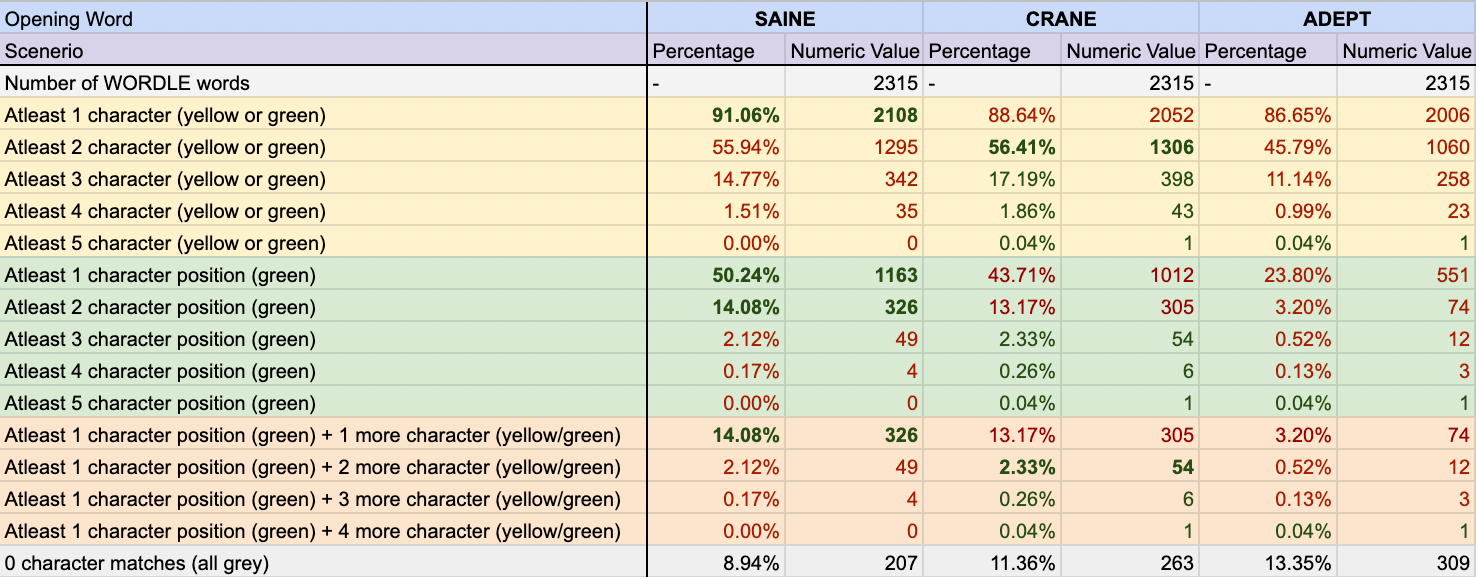
Единственное ключевое преимущество для "CRANE / ADEPT" заключается в том, что они оба имеют шанс 0,04% успешно угадать 1 слово. Я подозреваю, что недостаток предыдущего публичного анализа заключался в том, что они ограничивали вступительное слово известным списком ответов. Однако я считаю, что вместо этого мы должны использовать полный список слов, чтобы максимизировать вероятность подсказок в пользу очень узкого шанса сделать предположение из 1 слова.
Что еще более важно, SAINE имеет значительно более высокий шанс (на \~7%) угадать точное совпадение (зеленый цвет) с первой попытки. Что невероятно полезно в качестве подсказки.
После дебатов о стартовом слове мы увидим, как система реагирует на разные результаты!
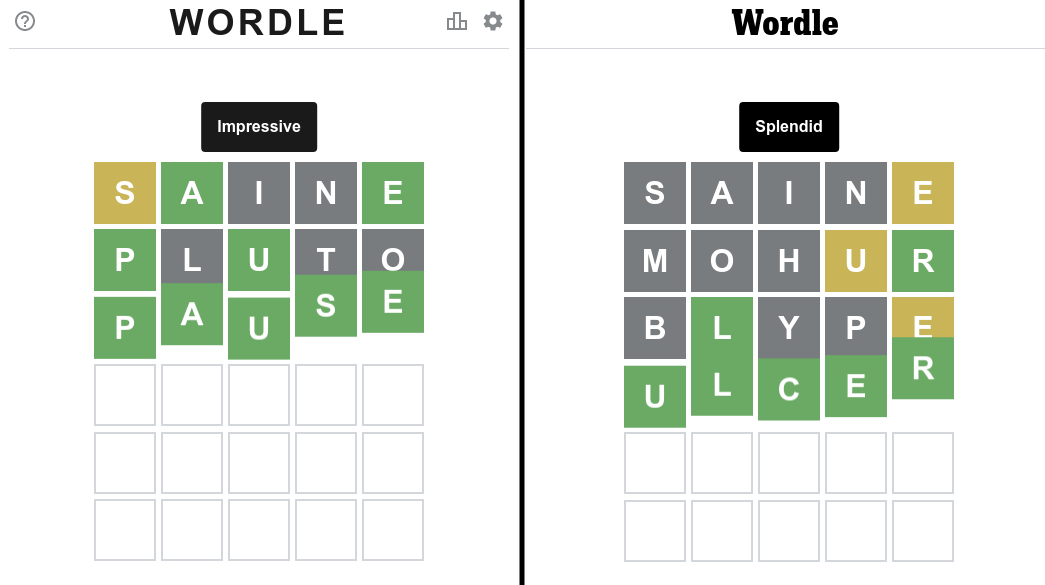
Понимание того, как второе предположение ПЛУТОН приводит к ПАУЗЕ
Итак, давайте посмотрим, как выбирается 2-е слово для ответа «ПАУЗА» (левая часть).
Нам дают следующую информацию:
- Буква I&N в слове отсутствует.
- А — 2-й символ, Е — 5-й символ.
- S — это либо 3-й, либо 4-й символ (это не 1-й символ).
- В списке слов только 12 возможных ответов
Довольно стандартный материал Wordle. Но давайте посмотрим, как это повлияет на статистику оставшихся возможных ответов. И как был выбран «ПЛУТОН».
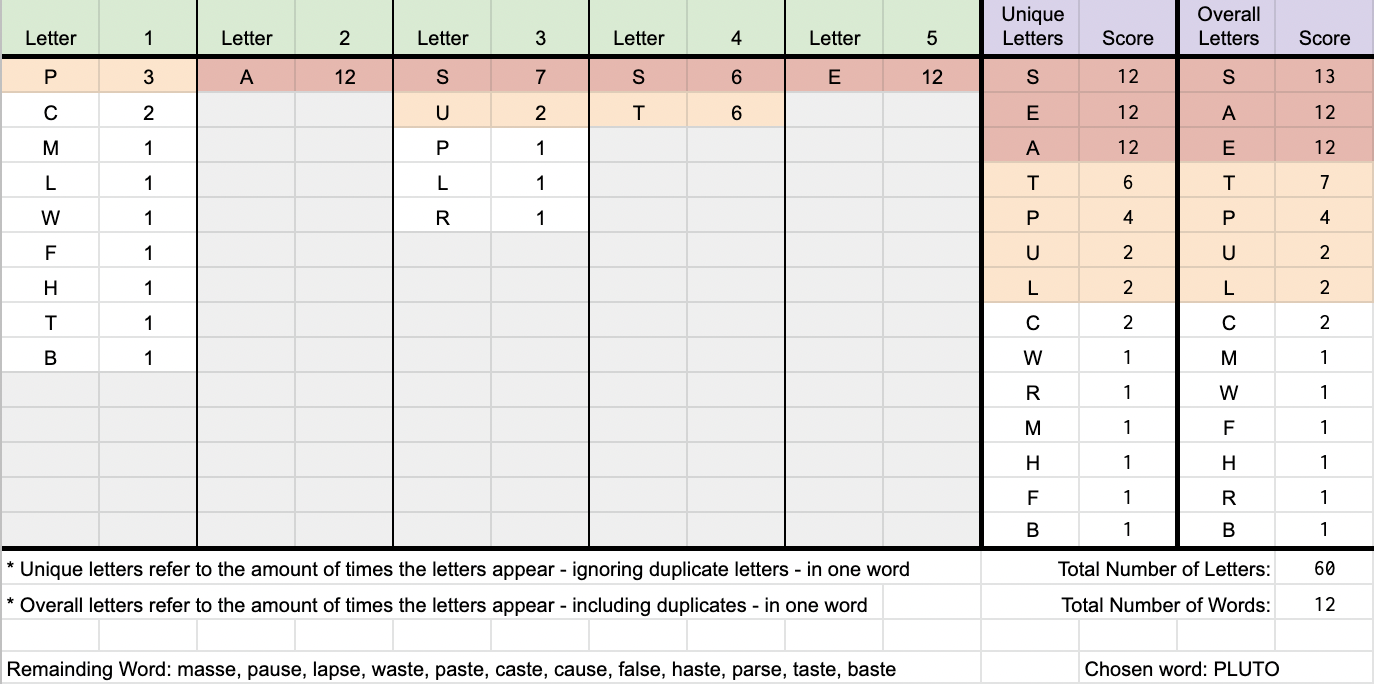
Осталось всего 12 слов, давайте найдем самый эффективный способ исключить наши варианты.
- Поскольку у нас уже есть информация о буквах S, E, A, наша система подсчета очков будет избегать их со штрафом (отмечено красным).
- Следующими по величине вероятностями символов в позициях, о которых мы не знаем, являются P, U и T в позициях 1, 3 и 4 соответственно (отмечены оранжевым цветом).
- Наконец, поскольку у нас есть решенные позиции 2 и 5, мы можем использовать это для получения дополнительной информации. Итак, давайте постараемся использовать символы L и C.
Из следующих ограничений единственным допустимым словом, которое можно было попробовать, было PLUTO. Хотя мы знаем, что буквы O нет в окончательном ответе, для «PLUTC» нет слова. Кроме того, хотя слова PLUTO не было в списке ответов, оно было в полном списке слов, что делало его предположение правильным.
После отправки система знает следующее:
- Л, Т, О в слове нет (О - подтверждение предположения).
- P — 1-й символ, U — 3-й символ.
- S — 4-й символ (это уже не может быть 3-й символ).
Это означает, что мне больше не нужна статистика, потому что есть только одна истина: ПАУЗА.

Но что за сумасшедший шаблон угадывания? С MOHUR, BLYPE и, наконец, ULCER
- Мохур — это золотая монета, которая ранее чеканилась несколькими правительствами, включая Британскую Индию и некоторые княжества, существовавшие рядом с ней.*
Статистика здесь оценивается в реальном времени, и изменения зависят от результата каждого раунда. Таким образом, результат отличался, где:
- Буквы С, А, И, Н в слове нет.
- Буква E может стоять на позициях 1, 2, 3, 4, но не на 5.
Фильтрация списка возможных ответов приводит к следующей статистике:
![Статистика символов второго слова. Когда ответ ULCER.] (https://cdn.hackernoon.com/images/-enh3ko4.png)
Сначала это может не иметь смысла, потому что слово не начинается с C или B. Когда осталось 187 слов, именно здесь начинают иметь значение детали подсчета очков.
- Мы снова игнорируем букву E, которая является уже известной нам информацией (выделена красным цветом).
- Буква R в конце имеет наибольший вес (из 62 слов) с большим отрывом. Выяснение ответа для этого символа либо уменьшает вдвое (не соответствует) список возможностей, либо сокращает его на одну треть (соответствует).
- Отсюда следующим шагом является поиск слова с наибольшим количеством совпадений с другими буквами в соответствующих позициях, например, O в позиции 2 (оценка 37), за которой следуют любые оставшиеся символы. Соответствие либо их позиционному списку, либо списку уникальных букв.
Это может быть не самый оптимальный выбор, учитывая известный список ответов. Однако это сделано намеренно, потому что мы хотим снова сосредоточиться на информации, пока у нас не будет очень высокой уверенности в слове. И в этом процессе мы будем наказывать повторяющиеся буквы, чтобы сосредоточиться на сокращении количества вариантов (возможно, здесь есть место для улучшений).
Результаты догадки оказались интересными.
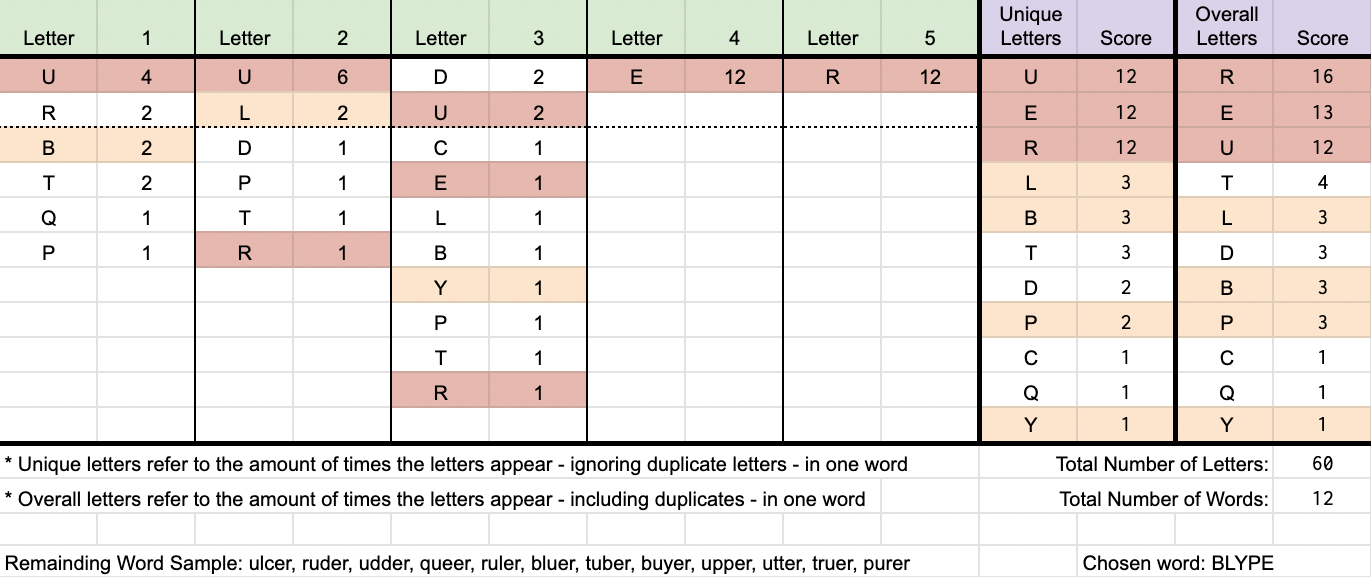
Каким бы странным и запутанным ни было слово MOHUR, в результате количество возможных вариантов сократилось до 12 слов. Еще раз, он пытается расставить приоритеты, пробуя новых персонажей, и дает ему неясное слово BLYPE.
BLYPE: кусок или клочок кожи
Это слово сокращает список возможных вариантов до одного слова - ЯЗВЕННАЯ ГРЯЗЬ, которое является окончательным ответом.
Примечание: * Если вы заметили, он готов попробовать известные ему символы, которых нет в официальном списке ответов. Это сделано намеренно. Примите во внимание клоны Wordle, потому что, если фактический выбранный ответ не входит в исходный список ответов, система автоматически вернется к использованию вместо этого полного списка слов. Делаем это более устойчивым к вариантам Wordle.*

⚠️ Предупреждение о коде: Если вы пришли сюда только из-за математики и статистики, то переходите к концу. Остальной контент в этой статье состоит из кода JS.
Покажите мне код
- Полный курс решения можно найти здесь (https://github.com/uilicious/wordle-solver-and-tester/blob/main/wordle-article-notes/WordleSolvingAlgo.js).*
Эта статья будет посвящена основным функциям, необходимым для работы этого процесса, а не всем частям кода. Если вы не читали Часть 1, прочтите ее здесь.
Код здесь был упрощен, чтобы пропустить "шаблонный" материал.
Решатель должен сделать следующее:
- Учитывая текущее состояние игры, отфильтруйте возможный список слов.
- Учитывая отфильтрованный список слов, вычислить статистику.
- Учитывая статистику и состояние игры, наберите слово, следуя стратегии.
- Предложите слово.
Давайте разберем его по частям.
Normalize Объект состояния игры (сгенерированный в части 1)
Для каждого раунда состояние игры будет генерироваться с помощью:
- .history[] : Массив прошлых догадок слова.
- .pos[]: массив объектов, содержащий следующую информацию.
- .hintSet : набор символов, которые являются допустимыми «подсказками».
- .foundChar: символы, подтвержденные для данной позиции.
Это генерируется с использованием информации на экране в части 1.
Однако для нашего варианта использования нам потребуется нормализовать некоторые общие наборы данных, которые нам понадобятся. Через функцию _normalizeStateObj получаем следующее.
- badCharSet: Известные нам символы, которых нет в слове;
- goodCharSet: Подтвержденные нами символы присутствуют в слове.
Это легко сгенерировать путем повторения .history и данных .pos для создания списка хороших символов в первую очередь. Затем используйте это, чтобы построить список плохих символов обратно против исторического списка слов.
```javascript
- Учитывая состояние объекта, нормализуйте различные значения, используя минимальное «требуемое» значение.
- Это не предоставляет столько данных, сколько
WordleSolvingAlgo, фокусируясь на минимально необходимом
- чтобы текущая система работала
- @param {Объект} состояние
- @return {Object} объект состояния нормализован
функция _normalizeStateObj (состояние) {
// Устанавливаем начальную кодировку
state.badCharSet = новый набор();
state.goodCharSet = новый набор();
// Создадим хорошую кодировку
for(пусть i=0; i<state.wordLength; ++i) {
если (состояние.pos[i].foundChar) {
state.goodCharSet.add(state.pos[i].foundChar);
for(let char of state.pos[i].hintSet) {
state.goodCharSet.add(char);
// Позволяет перебрать историю и построить badCharSet
for(пусть i=0; i<state.history.length; ++i) {
const word = state.history[i];
for(пусть w=0; w<word.length; ++w) {
// проверка отдельного символа
пусть char = слово.charAt(w);
// Если char не в хорошем наборе
если( !state.goodCharSet.has(char)) {
// это плохой набор
состояние.badCharSet.add(char);
// Возвращаем объект состояния нормализации
возвращаемое состояние;
Фильтрация возможного списка слов
Теперь, когда у нас есть текущее состояние игры, давайте рассмотрим фильтрацию списка слов:
```javascript
- Учитывая список слов, отфильтруйте только возможные ответы, используя объект состояния.
- И возвращает отфильтрованный список. Эта функция просто возвращает список слов, если состояние == null
- @param {Array
} список слов
- @param {Объект} состояние
функция filterWordList(словоСписок, состояние) {
// Пропустить, если это не настроено
если (состояние == null || wordList.length <= 0) {
вернуть список слов;
// Получить длину слова
const wordLength = wordList[0].length;
// Фильтровать и возвращать
вернуть wordList.filter (функция (ы) {
// Логика фильтрации
// все проверки проходят, возвращаем true
вернуть истину;
Для логики фильтрации мы сначала удаляем слова из badCharSET.
```javascript
// фильтровать недопустимые слова (жесткий режим)
for(const bad of state.badCharSet) {
// PS: это ничего не делает, если множество пусто
если (s.includes (плохо)) {
вернуть ложь;
Затем следует отфильтровать слова с неправильным расположением подсказок:
```javascript
// отфильтровать слова с неправильным расположением подсказок для каждой позиции символа
for(пусть i=0; i<wordLength; ++i) {
// Получить символ слова
пусть sChar = s.charAt(i);
// Проверяем, не конфликтует ли символ с существующим найденным символом (зеленый)
if(state.pos[i].foundChar && sChar != state.pos[i].foundChar) {
вернуть ложь;
// Проверяем, не является ли символ уже известным несоответствием (желтый, частичное совпадение)
// для каждой позиции
for(const bad of state.pos[i].hintSet) {
если (sChar == плохо) {
вернуть ложь;
Для последующих слов без всех известных найденных (точных и частичных) совпадений:
```javascript
// отфильтровать слова БЕЗ подсказанных символов
// PS: это ничего не делает, если множество пусто
for(const good of state.goodCharSet) {
если(!s.includes(хорошо)) {
вернуть ложь;
Кроме того, у нас есть вариант фильтрации уникальных слов для filterForUniqueWordList. В нем нет повторяющихся символов, и он используется в первых нескольких раундах:
```javascript
пусть wordCharSet = новый набор();
// повторяем символы
for(const char of s) {
// Обновить кодировку слова
словоCharSet.добавить (символ);
// Есть повторяющиеся символы
если (словоCharSet.size! = s.length) {
вернуть ложь;
Создание статистики слов
После фильтрации всех оставшихся возможных ответов статистика генерируется с помощью charsetStatistics( dictArray )
Это делается путем создания объекта для типа статистики. Повторяйте список слов и увеличивайте числа:
```javascript
- Проанализируйте данный массив словаря, чтобы получить статистику символов
- Это вернет требуемую модель статистики, которая будет использоваться при угадывании слова.
- Который представлен в 3 основных частях, используя объект, который использует символ в качестве ключа, за которым следует его частота в виде числа.
-
- в целом : Частота появления каждого персонажа
-
- уникальный: частота появления каждого символа в слове (это означает, что дубликаты в 1 слове игнорируются)
-
- positional : Массив объекта, который обеспечивает частоту появления, уникальную для этой позиции слова.
- Обратите внимание, что, поскольку набор данных может не иметь символов в списке / позиционном расположении,
- вы должны предполагать любой результат без ключа, означает частоту 0
- @param {Array
} dictArray - содержит различные слова одинаковой длины
- @return Объект с соответствующей общей / уникальной / позиционной статистикой
charsetStatistics(dictArray) {
// Проверка безопасности
if( dictArray == null || dictArray.length <= 0 ) {
throw Неожиданный пустой список словарей, невозможно выполнить charsetStatistics/догадки;
// Общая статистика для каждого персонажа
пусть общая статистика = {};
// Общая статистика для каждого уникального персонажа
// (игнорировать дубликаты в слове)
пусть totalUniqueStats = {};
// Статистика для каждого слота персонажа
пусть positionalStats = [];
// Инициализируем positionalStats
пусть wordLen = dictArray[0].length;
for(пусть i=0; i<wordLen; ++i) {
positionalStats[i] = {};
// Позволяет перебрать весь словарь
for(константное слово массива dictArray) {
// Набор символов для слова
const charSet = новый набор();
// Для каждого персонажа заполняем общую статистику
for( пусть i=0; i<wordLen; ++i ) {
// Получить символ
const char = слово.charAt(i);
// Увеличиваем общую статистику
this._incrementObjectProperty (общая статистика, символ);
// Заполняем кодировку общей уникальной статистикой
charSet.add (символ);
// Увеличиваем каждую позиционную статистику
this._incrementObjectProperty(positionalStats[i], char);
// Заполнить уникальную статистику
for(const char of charSet) {
// Увеличиваем общую уникальную статистику
this._incrementObjectProperty(completeUniqueStats, char);
// Вернем статистику obj
возврат {
общий: общая статистика,
уникальный: в целомUniqueStats,
позиционный: positionalStats
Это довольно просто для циклов по каждому слову и каждому приращению символа в соответствующем статистическом подсчете.
Единственная проблема заключается в том, что мы не можем выполнить приращение ++ к свойству объекта, если оно не инициализировано. Это приведет к следующей ошибке:
```javascript
// Это даст исключение для
// TypeError: Невозможно прочитать свойства undefined (чтение 'a')
пусть объект; объект["а"]++;
Поэтому нам нужно будет использовать простую вспомогательную функцию, чтобы правильно увеличить наш необходимый вариант использования:
```javascript
- Увеличение ключа объекта, используемого на различных этапах процесса подсчета
- @param {Объект} объект
- Ключ @param {String}
_incrementObjectProperty (объект, ключ) {
если (объект [ключ] > 0) {
объект[ключ]++;
} еще {
объект[ключ] = 1;

Оценка каждого слова
В основе решателя лежит логика подсчета очков. Который оценивается по каждому возможному вводу слова с заданной статистикой и состоянием.
*Отказ от ответственности: я не утверждаю, что это самая оптимальная функция подсчета слов для Wordle. Его определенно можно улучшить, но, судя по моим испытаниям, пока он довольно хорош. знак равно
```javascript
- Сердце системы решения wordle.
- @param {Object} charStats, вывод из charsetStats
- @param {String} слово для оценки
- @param {Object} объект состояния (для уточнения оценки)
- @return {Число}, представляющее оценку слова (может иметь десятичные разряды)
функция scoreWord(charStats, word, state = null) {
// Набор символов для слова, используемого для проверки на уникальность
const charSet = новый набор();
// окончательный результат, который нужно вернуть
пусть оценка = 0;
// Примечание по стратегии Wordle:
// - Штрафовать повторяющиеся символы, так как они ограничивают количество получаемой нами информации
// - Отдавайте предпочтение персонажам с высоким позиционным счетом, это помогает увеличить шансы на "точные зеленые совпадения" на раннем этапе
// уменьшение усилий, необходимых для вывода «частичных совпадений желтого цвета»
// - Если есть ничья, в позиционном счете, ничейный разрыв с «уникальным» счетом и общим счетом
// это имеет значение для последних <100 совпадений
// - Раньше мы отдавали предпочтение позиционному счету, а не уникальному счету только в последних нескольких раундах
// но после нескольких проб и ошибок мы пришли к выводу, что лучше всего использовать позиционный счет
// Давайте посчитаем очки
// Возвращаем счет
возвратный балл;
Это проходит через несколько этапов: во-первых, мы добавляем защитную сетку, чтобы система больше не предлагала слово (огромный отрицательный балл).
```javascript
// Пропустить попытки слова - например, ПОЧЕМУ ???
если (состояние && состояние.история) {
если (state.history.indexOf (слово) >= 0) {
возврат -1000*1000;
Затем мы повторяем каждый символ слова и оцениваем их соответственно:
```javascript
// Для каждого персонажа заполняем общую статистику
for( пусть i=0; i<word.length; ++i ) {
// Получить символ
const char = слово.charAt(i);
// Делает подсчет очков для каждого символа
Наказание за слова с повторяющимися или известными символами:
```javascript
// пропустить подсчет известных совпадений символов
// или подсказки о попытке символа
если (состояние) {
// Пропустить известные символы (хорошие/найденные)
if( state.pos && state.pos[i].foundChar == char ) {
оценка += -50;
charSet.add (символ);
Продолжать;
// Пропустить оценку повторяющегося символа
если ( charSet.has ( char )) {
оценка += -25;
Продолжать;
// Пропустить известные символы (хорошие/найденные)
if( state.goodCharSet && state.goodCharSet.has(char)) {
оценка += -10;
charSet.add (символ);
Продолжать;
} еще {
// Пропустить оценку повторяющегося символа
если ( charSet.has ( char )) {
оценка += -25;
Продолжать;
// Заполнить набор символов, мы проверяем это, чтобы отдать предпочтение словам с уникальными символами
charSet.add (символ);
Наконец, мы рассчитываем баллы для каждой позиционной статистики, при этом баллы уникальных персонажей используются в качестве решающих:
```javascript
// Примечание разработчиков:
// В общем - мы всегда должны делать проверку, существует ли "персонаж" в списке.
// Это помогает справиться с некоторыми ситуациями NaN, когда у персонажа нет очков
// это возможно, потому что допустимый список будет включать слова, которые можно ввести
// но не является частью отфильтрованного списка - см. charsetStatistics
если(charStats.positional[i][char]) {
оценка += charStats.positional[i][char]*10000;
если (charStats.unique[char]) {
оценка += charStats.unique[char]
// -- Переходим к следующему символу -- //
Теперь, когда у нас есть функция подсчета очков, мы можем начать собирать вместе все части функции «suggestWord».

Предложение слова (составление)
У нас есть статистика, которую затем можно использовать для подсчета слов. Теперь давайте соберем это вместе, чтобы предложить лучшее слово для подсчета очков.
Начнем с получения состояния игры:
- нормализовать игровое состояние;
- генерировать отфильтрованные, уникальные и полные списки слов.
```javascript
- Учитывая минимальное состояние объекта, предложите следующее слово, чтобы попытаться угадать.
-
определение объекта "состояние"
- Решатель требует знать существующую информацию о состоянии слова, чтобы она состояла (как минимум)
- .history[] : массив прошлых догадок слов
- .pos[] : массив объектов, содержащий следующую информацию
- .hintSet: набор символов, которые являются допустимыми «подсказками».
- .foundChar : символы, подтвержденные для данной позиции
- Вышеприведенное соответствует формату объекта состояния WordleAlgoTester.
- Дополнительные значения будут добавлены к объекту состояния, используя приведенную выше информацию
- @param {Объект} состояние
- @return {String} угадать слово для выполнения
предложитьWord(состояние) {
// Нормализация объекта состояния
состояние = это._normalizeStateObj (состояние);
// Давайте получим соответствующий список слов
пусть полныйСписокСлов = this.fullСписокСлов;
let filteredWordList = this.filterWordList(this.filteredWordList, state);
let uniqueWordList = this.filterForUniqueWords( this.uniqueWordList, state );
// Как объект
пусть список слов = {
полный: полныйWordList,
уникальный: уникальныйWordList,
отфильтровано: filteredWordList
// Давайте поработаем с различными списками слов и состоянием
// это изменено как suggestWord_fromStateAndWordList
// в кодовой базе
Когда у нас есть различные игровые состояния и списки слов, мы можем выбрать «статистический список слов», который мы используем для создания статистической модели.
```javascript
// Давайте решим, какой список слов использовать для статистики
// который должен быть отфильтрованным списком слов если нет
// нет возможных ответов в этом списке, что возможно, когда
// система используется против варианта WORDLE
// В таком случае давайте вернемся к отфильтрованной версии "полного
// список слов», вместо отфильтрованной версии «списка ответов».
пусть statsList = wordList.filtered;
if( wordList.filtered == null || wordList.filtered.length <= 0) {
console.warn("[ПРЕДУПРЕЖДЕНИЕ]: Неожиданный пустой "отфильтрованный" список слов без возможных ответов: возврат к полному списку слов");
statsList = this.filterWordList( wordList.full, state );
if( wordList.filtered == null || wordList.filtered.length <= 0) {
console.warn("[ПРЕДУПРЕЖДЕНИЕ]: Неожиданный пустой "отфильтрованный" список слов, без возможных ответов: несмотря на обработку из полного списка, используя его необработанный");
statsList = wordList.full;
Как только мы выбираем список слов для статистики, мы получаем статистику:
```javascript
// Получить статистику кодировки
const charStats = this.charsetStatistics(statsList);
Теперь мы определяем список слов, который будем использовать при выборе слова. Мы называем этот список «scoredList».
В первых нескольких раундах мы стремимся использовать как можно больше уникальных слов. Которые не будут включать персонажей, которых мы пробовали ранее. Сюда могут входить слова, которых, как мы знаем, нет в списке возможных ответов.
Это сделано намеренно, так как мы оптимизируем получение информации, но вместо этого из-за небольшого случайного шанса на ранний успех.
Однако, когда он опустеет или игра находится в последних нескольких раундах, мы вернемся к полному списку. Во время последнего раунда мы всегда будем угадывать, используя отфильтрованный список, когда это возможно: (просто дайте ему наш лучший ответ).
```javascript
// сортируем список результатов, используем уникальные слова в первых нескольких раундах
пусть scoredList = wordList.unique;
// Использовать действительный список, начиная с 5-го раунда
// или когда уникальный список исчерпан
if(scoredList.length == 0 || state.round >= 5) {
список результатов = список слов.полный;
// Использовать отфильтрованный список в последних 2-х раундах или когда гарантирована "победа"
if( wordList.filtered.length > 0 && //
(wordList.filtered.length < state.roundLeft || state.roundLeft <= 1) //
scoredList = wordList.filtered;
Как только мы определились со списком подсчета очков, чтобы применить статистику, давайте подсчитаем и отсортируем его:
```javascript
// Ссылка на себя
const self = это;
// Сортировка слов по очкам
scoredList = scoredList.slice(0).sort(function(a,b) {
// Получить счет
пусть bScore = self.scoreWord(charStats, b, state, finalStretch);
пусть aScore = self.scoreWord(charStats, a, state, finalStretch);
// И расположим их соответствующим образом
если (bScore > aScore) {
вернуть 1;
} иначе если( bScore == aScore ) {
// Тай-брейки - редко
// так как в алгоритме уже есть счетчики
если ( б > а ) {
вернуть 1;
} иначе если( а > б ) {
возврат -1;
// Галстук равенства ???
вернуть 0;
} еще {
возврат -1;
И вернуть элемент с наивысшей оценкой:
```javascript
// Возвращаем слово с наибольшим количеством очков
вернуть список результатов[0];

Собираем все вместе
С кодом взаимодействия с пользовательским интерфейсом, выполненным в части 1., нажмите кнопку «Выполнить», чтобы увидеть, как работает наш бот Wordle!
Эй, неплохо, мой бот решил сегодняшний Wordle!

Забрать - для людей?
Потому что боты будут использовать довольно «нечеловеческую» технику расчета вероятностей с гигантскими словарями.
Большинство людей обнаружат, что это граничит с действительно странными и сумасшедшими догадками. Верьте математике, потому что она работает.
Если вы играете за человеческую команду, из этой статьи следует сделать вывод, что вы должны просто начинать со слова «SAINE» или любых других слов, которые вам нравятся.
Это зависит от вас, так как это ваша игра в конце концов! =) Получайте удовольствие.
Счастливый Wordling! 🖖🏼🚀
Впервые опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27409)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)