

Rock Solid Splunk или как я научился любить проверенные архитектуры Splunk
19 ноября 2022 г.Splunk может быть сложным зверем с его различными компонентами, требованиями и передовыми практиками, помимо выбора ОС и проектирования инфраструктуры… его развертывание может показаться невыполнимой задачей. К счастью для нас, Splunk создал проверенные архитектуры, которые доказали свою эффективность и... просто работают.
Чтобы по-настоящему оценить, что представляют собой проверенные Splunk архитектуры, сначала нужно выполнить несколько шагов. назад и посмотрите, как Splunk был развернут до 2017 года, когда был выпущен официальный документ «Проверенная архитектура». У вас, как у покупателя, оставалось два варианта.
- Либо вы наняли консультанта, чтобы он обучил вас проектированию инфраструктуры Splunk, ЛИБО
- Вы потратили дни и недели, чтобы накопить необходимый уровень знаний, чтобы понять Splunk достаточно хорошо, чтобы развернуть его.
Ставки были высоки! С одной стороны, вы можете потратить десятки или сотни тысяч долларов на консультации и получить архитектуру, которую едва понимаете. С другой стороны, вы можете попытаться создать его самостоятельно и в конечном итоге перестроить его (с гораздо большими затратами) в будущем, когда он не сможет масштабироваться или у вас возникнут проблемы с производительностью.
Перенесемся в 2017 год, когда проверенные архитектуры Splunk (SVA) были обнародованы на конференции Splunk .conf2017 в Вашингтоне, округ Колумбия. Проверенные архитектуры дали каждому с трудом заработанные знания и мудрость для создания архитектуры Splunk мирового класса, которая соответствовала бы их потребностям. SVA обеспечили несколько заметных преимуществ. Во-первых, они позволили клиентам стандартизировать свою архитектуру до той, которая известна и понятна службе поддержки Splunk. Это, в свою очередь, упростило сеансы устранения неполадок и будущие решения по архитектуре. Во-вторых, это снизило совокупную стоимость владения (TCO) для развертываний Splunk. Поскольку архитектуры были настроены только на достаточную мощность, но не на слишком большую, вам больше не нужно было беспокоиться о том, что вы выделили слишком много ресурсов для своего аппаратного стека. В-третьих и, возможно, самое главное, это позволило вам (покупателю Splunk) начать свое путешествие по Splunk, двигаясь по правильному пути. Вы можете сосредоточиться на вводе данных, обучении пользователей и создании контента в Splunk, вместо того чтобы постоянно беспокоиться о своих дизайнерских решениях.
В Splunk SVA представлено семь архитектур, хотя на самом деле наиболее популярны три из них. Эти три будут тем, на чем мы сосредоточимся здесь, остальные четыре великолепны… но большинству людей, читающих это, не понадобится помощь, чтобы разобраться с этими четырьмя… они будут платить консультанту.
«Развертывание одного сервера»
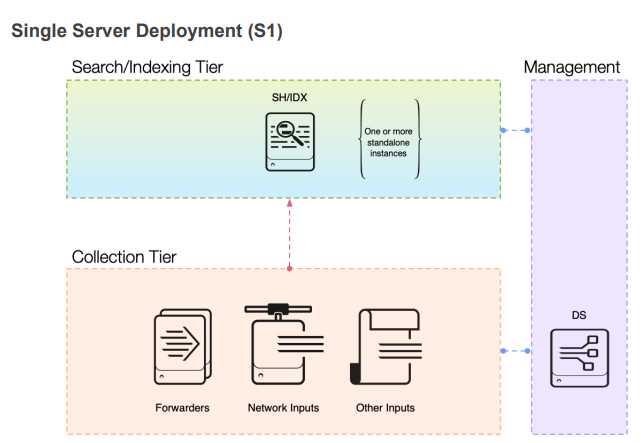
Все компоненты Splunk, от индексации и лицензирования до поиска, устанавливаются на одном сервере. Это отличный способ начать работу с Splunk, если причины, по которым вы используете Splunk, не являются критически важными. Поскольку это архитектура с одним сервером, у вас не будет избыточности. Это означает, что когда придет время исправить Splunk или ОС, Splunk будет отключен в течение этого периода, и никакие журналы не будут собираться. Никто не сможет получить доступ к Splunk для получения контента, и в течение этого периода не будет генерироваться оповещений. Этот SVA с одним сервером также ограничен в своих возможностях по приему данных. Splunk заявляет, что будет обрабатывать около 300 ГБ в день, но это звучит как вымышленное число. Я бы поставил цифру ближе к 150 ГБ в день. Однако это действительно простое развертывание с очень низкими накладными расходами.
«Распределенное кластерное развертывание — один сайт»
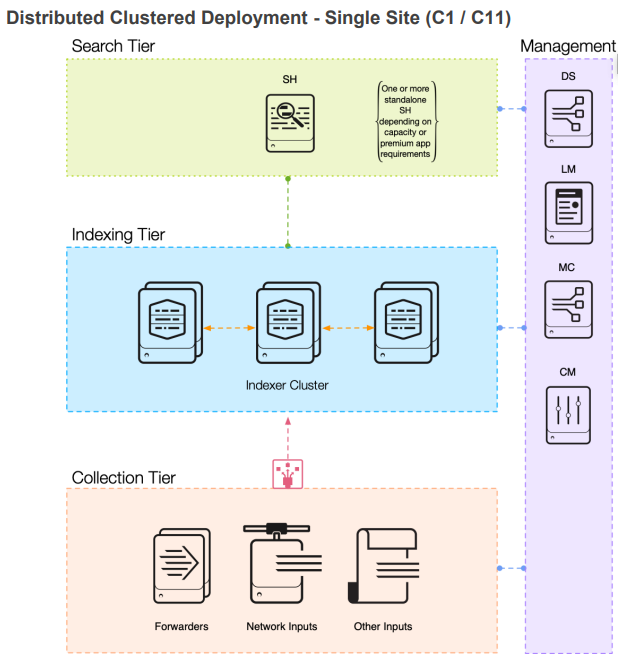
В этой модели основные компоненты Splunk отделены друг от друга. Это устанавливает трехуровневый подход с отдельной плоскостью управления. Первый уровень — это уровень сбора, который включает в себя универсальные серверы пересылки, тяжелые серверы пересылки и все другие источники данных. Следующий уровень предназначен для приема и анализа данных и называется уровнем индексации. На этом уровне есть два или более «индексирующих» сервера, которыми централизованно управляет мастер кластера индексаторов. Мастер кластера индексаторов поддерживает унифицированные конфигурации для всех индексаторов в кластере, предоставляя администраторам простой путь к масштабированию индекса по мере необходимости. Важно помнить, что мастер кластера индексатора — это отдельный компонент Splunk, который устанавливается на отдельный выделенный сервер (возможно, вместе с другими компонентами управления, такими как мастер лицензий, консоль управления и сервер развертывания).
Этот SVA имеет единую головку поиска, что означает, что, несмотря на избыточность приема данных, обеспечиваемую кластером индексатора, нет никакой избыточности для действий головки поиска, таких как создание контента, создание отчетов и т.д. генерация предупреждений или выполнение запросов. Это очень популярная архитектура, которую предпочитают использовать многие организации из-за возможности приема избыточных данных. Хотя в головке поиска нет избыточности, сбои головки поиска случаются очень редко и могут быть легко устранены путем перезагрузки.
Распределенное кластерное развертывание на нескольких площадках с головкой поиска (SHC)
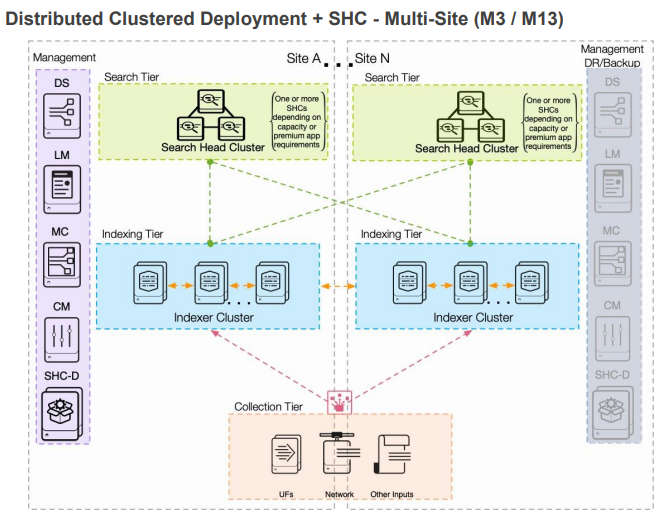
Эта архитектура выводит избыточность на новый уровень за счет эффективного клонирования распределенного развертывания на одном сайте, о котором мы только что говорили. Мало того, что каждый сайт избыточен и может обрабатывать данные независимо от кластеров других сайтов, но также имеется полный набор данных, реплицируемых между сайтами. Это, в сочетании с головным кластером поиска для каждого сайта, обеспечивает меру избыточности, не встречающуюся ни в одном другом SVA. Однако это усложняет развертывание, увеличивает совокупную стоимость владения за счет затрат на инфраструктуру и может затруднить устранение неполадок из-за проблем, часто возникающих при соединении двух удаленных площадок.
Если ваша организация работает в нескольких облачных или локальных центрах обработки данных и вам необходимо предоставлять Splunk, как если бы это было критически важное приложение, эту SVA сложно передать другим.
В этом посте я сосредоточился на обзоре 3 лучших SVA, доступных в официальном документе Splunk, но было бы упущением, если бы я не упомянул, что почти половина официального документа посвящена демонстрации нюансов кластеризованного поискового блока и конфигураций индексатора. Если вам интересны эти темы, обязательно ознакомьтесь с остальной частью официального документа.
Также опубликовано здесь< /p>
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27574)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)