

Исследователи объединяют GPT-4 и человеческих экспертов, чтобы обучать ИИ по визуальным образном рассуждении
19 июня 2025 г.Авторы:
(1) Arkadiy Saakyan, Колумбийский университет (a.saakyan@cs.columbia.edu);
(2) Шреяс Кулкарни, Колумбийский университет;
(3) Тухин Чакрабарти, Колумбийский университет;
(4) Смаранда Мюресан, Колумбийский университет.
Примечание редактора: это часть 3 из 6 исследований, рассматривая, насколько хорошо крупные модели искусственного интеллекта обрабатывают фигуративный язык. Прочитайте остальное ниже.
Таблица ссылок
- Аннотация и 1. Введение
- 2. Связанная работа
- 3. v-Flute Задача и набор данных
- 3.1 Метафоры и сравнения
- 3.2 идиомы и 3,3 сарказма
- 3.4 Юмор и 3,5 Статистика набора данных
- 4. Эксперименты и 4.1 модели
- 4.2 Автоматические метрики и 4.3 результаты автоматической оценки
- 4.4 Человеческий базовый уровень
- 5. Оценка человека и анализ ошибок
- 5.1 Как модели работают в соответствии с людьми?
- 5.2 Какие ошибки допускают модели? и 5.3 Насколько хорошо оценка объяснения предсказывает человеческое суждение о адекватности?
- 6. Выводы и ссылки
- Статистика набора данных
- B API модели гиперпараметры
- C тонкая настройка гиперпараметров
- D подсказки для LLMS
- E Модель таксономия
- F By-Phenomenon Performance
- G Аннотаторский набор и компенсация
3 V-FLUTE Задача и набор данных

Чтобы построить V-Flute, мы начинаем с существующих мультимодальных фигуративных наборов данных и используем рамки сотрудничества Human-AI с экспертными аннотаторами (Chakrabarty et al., 2022; Wiegreffe et al., 2022; Liu et al., 2022), чтобы превратить их в высокое, объясняемое визуальное эстяжение. Эти наборы данных охватывают конкретные явления, такие как метафоры, сравнения, идиомы, сарказм или юмор. Каждый экземпляр включает в себя изображение и заголовок, а фигуративное явление может быть либо на изображении, или в обоих. Мы трансформируем каждый данные в унифицированный формат для объяснимого визуального въезда. Обзор набора данных и наши вклады можно найти в таблице 1. См. Примеры из каждого набора данных в таблице 2. Ниже мы опишем построение V-Flute для каждого типа обратного языка (метафоры и снимки, идиомы, сарказм и юмор).
3.1 Метафоры и сравнения
Метафоры и сравнения представляют собой мощные риторические устройства, которые могут быть выражены либо в тексте, либо визуально на изображении. Визуальные метафоры используются в качестве убедительных устройств в различных областях, таких как реклама (Forceville, 2002; Scott, 1994). Чтобы создать визуальные экземпляры, содержащие метафоры и сравнения в V-Flute, мы полагаемся на два существующих ресурса: Haivmet (Chakrabarty et al., 2023) и Irfl (Yosef et al., 2023). Примеры, взятые из Хайвмета, содержат метафору/сравнение как часть предпосылки (изображение), в то время как те, которые взяты из IRFL, имеют метафору/сравнение как часть гипотезы (текст).
![Table 2: Sample dataset instances form V-FLUTE corresponding to the source datasets displaying images (premise), claims (hypothesis), labels, and explanations [Row 1-5].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-iv831um.png)
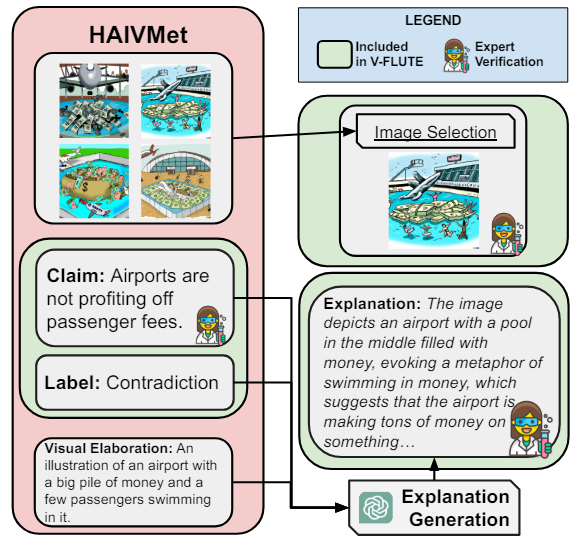
3.1.1 Haivmet в качестве источника данных
Данные Haivmet (Chakrabarty et al., 2023) состоит из 1193 изображений визуальных метафоров, охватывающих более 958 различных лингвистических метафоров. Каждое изображение связано с утверждением, которое может быть противоречивым или влеку от изображения. Кроме того, каждое изображение связывается с визуальной разработкой, которая представляет текстовое описание изображения (см. Рисунок 2). Эта визуальная разработка была использована в оригинальной статье для генерации визуальных метафор (изображений).
Генерируя текстовые объяснения.Мы дополняем набор данных с помощью текстовых объяснений кандидатов. Мы подсказываем CHATGPT (GPT-3.5-0914) генерировать объяснение для каждого кортежа (см. Рисунок 2; и пригласите в Приложение D.1.1).
Экспертная проверкаПолем Каждое требование в сочетании с 5 изображениями. Однако, поскольку эти изображения были автоматически сгенерированы с помощью DALLE-2 с использованием визуальных разработок, не все полностью верны. Более того, некоторые претензии и ярлыки были непоследовательными. Наконец, автоматически генерируемые кандидаты LLM объяснения не всегда верны и требуют переработки. Чтобы решить эти проблемы, мы используем процесс проверки экспертов с участием трех экспертных аннотаторов со значительным опытом в образном языке и понимании визуальной метафоры. Поскольку каждая претензия может быть в сочетании с более чем одной визуальной метафорой, мы просим аннотаторов выбрать визуальную метафору, наиболее верную лингвистической метафоре и визуальной разработке (см. Выбор изображения на рисунке 2) или не выбрать ни одного в редком случае, когда ни одна из визуальных метафоров не имеет хорошего качества. В рамках того же раунда аннотации мы также просим их проверить и отредактировать объяснение при необходимости, чтобы обеспечить правильность и высокое качество. Опубликуйте строгий контроль качества, у нас есть 857 экземпляров.
3.1.2 IRFL в качестве источника данных
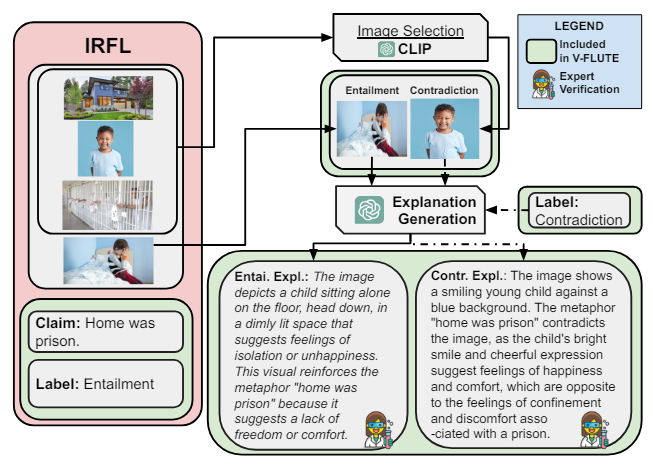
Набор данных IRFL (Yosef et al., 2023) содержит 1440 фигуративных выражений, каждый из которых связан с 4 различными изображениями. Одно из этих изображений представляет собой образное выражение (см. Рисунок 3), а другие 3 действуют как отвлекающие факторы.
Выбор изображения.Мы автоматически выбираем изображения, используя клип (Radford et al., 2021). Мы выбираем одно из изображений отвлекающих факторов, которое имеет самый высокий Clipscore (Clip-vit-базовый Patch16) с соответствующим влеченным изображением для создания сложного, противоречивого экземпляра (см. Где неродственное изображение дома отбрасывается при выборе экземпляра противоречения на рисунке 3).
Генерируя текстовые объяснения.Мы подсказываем GPT-4 (GPT-4-Vision-Preview) с наземной меткой истиной, заявлением и изображением, чтобы объяснить взаимосвязь между изображением и претензией.
Экспертная проверка.Мы набираем те же три экспертные аннотаторы из аннотаций Хайвмета и просим их проверить, что объяснение является адекватным и редактируем его при необходимости. Мы также просим аннотатора отбросить редкие шумные случаи, когда претензия, изображение и этикетка не подходят. Опубликуйте строгий контроль качества, у нас осталось 1149 экземпляров.
3.2 идиомы
Набор данных IRFL содержит идиомы в дополнение к метафорам и сравнению. Идентичная процедура к той, которая описана в разделе 3.1.2, использовалась для генерации экземпляров V-Flute для идиомов (370 примеров).
3.3 сарказм
Чтобы создать визуальные экземпляры, содержащие сарказм, мы полагаемся на данные MUSE (Desai et al., 2022). Подобно IRFL, экземпляры данных Muse содержат сарказм в гипотезе (текст).
3.3.1 Muse в качестве источника данных
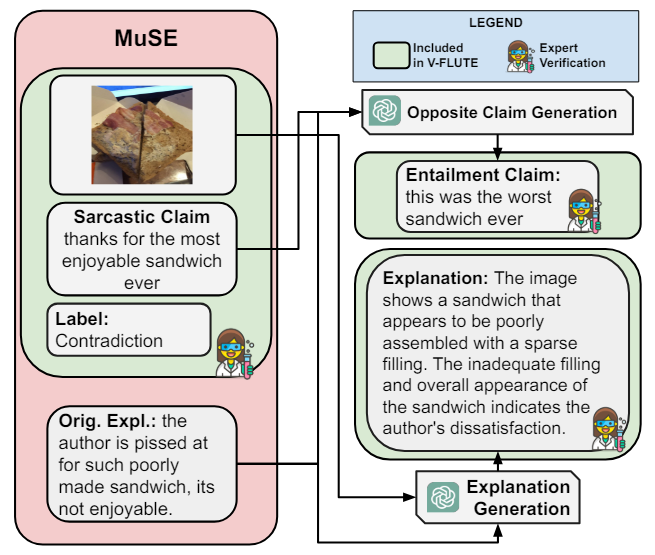
Набор данных MUSE (Desai et al., 2022) состоит из 3510 отдельных изображений, соответствующих саркастических утверждений, которые действуют как случаи противоречия (см. Пример на рисунке 4), а толпы письменных объяснений оправдывают противоречие.
Генерирование претензий.Поскольку набор данных содержит только саркастические экземпляры, нет никаких претензий с отношением к заруганию. Мы генерируем введенные претензии, побуждая GPT-4 для генерации не саркастической версии претензии при сохранении пользовательского неформального стиля текста (см. Сгенерированное требование Entailment на рисунке 4).
Генерируя текстовые объяснения.В то время как набор данных уже содержит написанные по массовым объемам объяснения, после осмотра их часто считали низким качеством, не имея достаточных деталей и формулы (например, см. Объяснение по массовым работникам на рисунке 4). Чтобы улучшить их качество, мы используем существующие пояснители для набора данных и подсказываем GPT-4, чтобы переписать и генерировать высококачественные текстовые объяснения кандидатов, учитывая претензию и этикетку (см. Переписанное объяснение на рисунке 4). Смотрите подсказку в Приложении D.3.
Экспертная проверкаПолем Каждое изображение в настоящее время в сочетании с GPT-4, которое влечет за собой требование, первоначальное противоречивое требование, а также соответствующие этикетки и объяснения. Те же три экспертные аннотаторы проверили, являются ли сгенерированные объяснения адекватны (то есть, полные, правильные и краткие), и если нет, отредактируйте их. Экспертам также было дано указание отказаться от шумных примеров, например, Когда изображение не противоречит саркастическому утверждению. Через строгий контроль качества мы получаем 1042 экземпляра.
3.4 Юмор
Для мультимодального юмора мы полагаемся на два набора данных: Memecap (Hwang and Shwartz, 2023) и мультфильмы New Yorker (Hessel et al., 2023).
3.4.1 Memecap в качестве источника данных
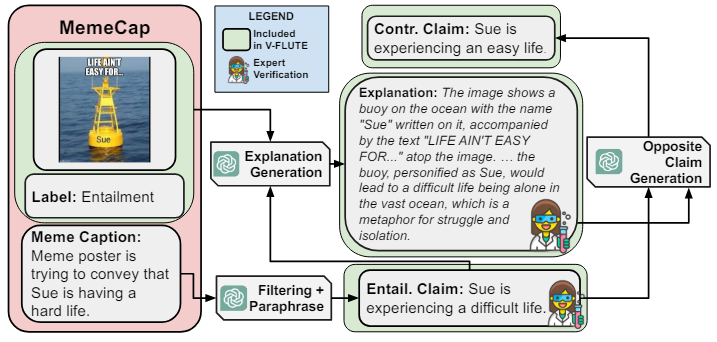
Этот набор данных состоит из мемов, а также их подписи, которые описывают намерение плаката мема (см. Пример на рисунке 5). Мемы часто содержат неявное, нелитеральное значение (Lestari, 2019) и полагаются на визуальные метафоры (Piata, 2016), создавая вызов VLMS.
Поколение претензийПолем Поскольку подписи мемов не подходят для задачи вторжения, мы выполняем быстрый GPT-4 с заголовком для создания претензии (см. Пример на рисунке 5). Мы фильтровали этот набор образцов дальше с GPT-4, спрашивая, влечет ли изображение и выбирая только положительные экземпляры. В дополнение к созданию претензий, которые влечет за собой мем, мы генерируем встречные требования, используя GPT-4.
Генерируя текстовые объяснения.Мы побудили GPT-4 с наземной меткой истиной в подсказке объяснить отношения между изображением и претензией. См. Подсказки в Приложении D.4.
Экспертная проверка.Мы нанимаем тех же трех экспертных аннотаторов, чтобы обеспечить правильность данных. Каждому аннотатору поручено проверить, что 1) сгенерированная претензия соответствует изображению и 2) объяснение является правильным и полным, а если нет, внесите необходимые изменения. Мы также просим отказаться от образцов с неподходящим содержанием. После тщательного контроля качества у нас есть экземпляры 1958 года.
3.4.2 Nycartoons в качестве источника данных
Набор данных Nycartoons (Hessel et al., 2023) содержит 651 высококачественный экземпляры из конкурса мультфильмов из Нью-Йорка. Каждый экземпляр состоит из юмористического изображения в сочетании с заголовком и объяснением естественного языка, оправдывающего неявный юмор между заголовок и изображением. Мы просто используем существующие данные, в которых заголовок рассматривается как утверждение, влечет за собой юмористическое изображение в сочетании с объяснением.
3.5 Статистика набора данных
Мы разделили наши данные на 4578 обучения, 726 валидации и 723 экземпляров тестирования. Подробный счет по явлению и набору данных, а также другие статистики находятся в Приложении A.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)