

Алгоритмы оптического распознавания символов могут изменить бизнес-процессы
9 апреля 2022 г.Ввод данных и их перемещение из одного места в другое — это трудоемкая повторяющаяся задача. Один сотрудник может легко потратить до трех часов в день, просто перемещая данные. Ручная обработка данных не только отнимает рабочее время, но и чревата ошибками, что приводит к потерям доходов. Отчет Dun & Bradstreet, исследующий прошлое и будущее данных, показал, что каждый пятый бизнес теряет деньги из-за неполных данных.
Технология оптического распознавания символов (OCR) может помочь предприятиям решить эти проблемы. Алгоритмы OCR могут преобразовывать бумажные документы в редактируемый текст с возможностью поиска. Они также могут извлекать информацию из файлов и вводить ее в соответствующие поля в ИТ-системах компании.
Итак, как же работает OCR? Как эта технология может помочь вам в достижении бизнес-целей? И следует ли вам обратиться к поставщику решений для искусственного интеллекта, чтобы помочь вам создать и настроить программное обеспечение OCR?
Что такое оптическое распознавание символов и как оно работает
определение оптического распознавания символов
Оптическое распознавание символов — это технология, которая преобразует печатный или рукописный текст и печатные изображения, содержащие текст, в машиночитаемый формат цифровых данных. Алгоритмы OCR помогают преобразовывать большие объемы бумажных документов в цифровые файлы, облегчая хранение, обработку и поиск текста.
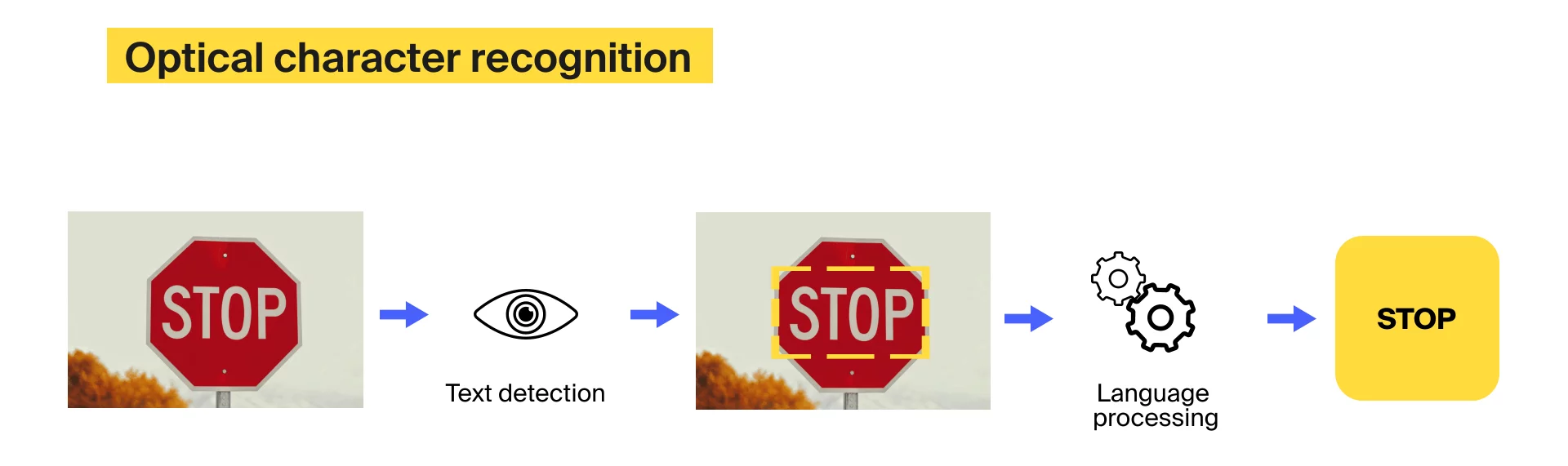
Системы OCR состоят из аппаратного и программного обеспечения. Аппаратной частью может быть оптический сканер или подобное устройство, способное преобразовывать бумажные документы в цифровой формат. Программная часть — это сам алгоритм OCR.
Как работает распознавание символов?
Компьютерам трудно распознавать символы из-за разных шрифтов и вариантов написания одной буквы. Рукописные письма еще больше усложняют дело. Тем не менее алгоритмы оптического распознавания символов справляются с этой задачей. Каждое решение OCR работает в четыре основных этапа:
Получение изображения
Процесс включает в себя использование оптического сканера для получения цифровой копии бумажного документа. Документ должен быть правильно выровнен и иметь размер.
Предварительная обработка
Цель этого этапа — сделать входной файл пригодным для использования алгоритмом OCR. Шум и фон устранены. Предварительная обработка включает в себя следующие этапы:
- Анализ макета: определение заголовков, столбцов и графиков как блоков
- Устранение перекоса: наклон цифрового документа, чтобы сделать линии горизонтальными, если он не был правильно выровнен во время сканирования.

- Улучшение изображения: сглаживание краев, удаление пылинок, увеличение контраста между текстом и фоном.
- Распознавание текста: одни алгоритмы распознают отдельные слова и разбивают их на буквы, а другие работают с текстом напрямую, не разбивая его на символы.

- Бинаризация: преобразование отсканированного документа в черно-белый формат, где темные области представляют символы (буквенные или цифровые), а белые области определяются как фон. Этот шаг помогает распознавать разные шрифты.
https://www.youtube.com/watch?v=cAkklvGE5io
Обнаружение символов
На этом этапе алгоритмы оптического распознавания символов выполняют различные манипуляции для распознавания букв и цифр. Существует два основных подхода:
- Распознавание образов: алгоритмы OCR обучаются на самых разных шрифтах, текстовых форматах и стилях рукописного ввода, чтобы сравнивать отдельные символы из входного файла с тем, что они изучили.

- Распознавание признаков: некоторые алгоритмы используют известные свойства символов, такие как пересекающиеся и изогнутые линии, для идентификации символов во входных файлах. Например, буква «H» определяется как две вертикальные линии и одна пересекающаяся горизонтальная линия. Алгоритмы OCR на основе нейронных сетей (NN) используют другую логику, в которой первые слои NN объединяют пиксели из входного файла для создания низкоуровневой карты признаков изображения.

После обнаружения символов программа преобразует их в американский стандартный код для обмена информацией (ASCII) для облегчения дальнейших манипуляций.
Постобработка
Вывод может быть простым, например, строкой символов или файлом. Более продвинутые решения OCR могут сохранять исходную структуру страницы и создавать файл PDF с текстом, доступным для поиска. Несмотря на то, что пока нет инструментов, гарантирующих 100% точность на разных входных файлах, некоторые алгоритмы оптического распознавания символов могут достигать впечатляющей точности в 99,8% на знакомые тексты.
Использование рукописного ввода значительно ухудшит результаты. Также важно понимать, что при плохой подготовке или незнакомых текстах процент ошибок может достигать до 20% . Следовательно, пользователям необходимо постоянно отслеживать, корректировать и исправлять выходные данные алгоритмов OCR, особенно когда в конвейер поступает новый тип документа.
Этап постобработки также может включать обработку естественного языка (NLP) и другие методы ИИ для проверки данных. ИИ может не только исправлять текст, но и ловить ошибки в расчетах. Предположим, что при обработке счета алгоритм распознавания определил общую сумму в 500 долларов. ИИ может проверить это, сложив все расходы и выяснив, что они не составляют 500 долларов. ИИ может уведомить сотрудника-человека о пересмотре этого конкретного случая. Если вы хотите улучшить качество алгоритма, вы можете поэкспериментировать с библиотеками OCR с открытым исходным кодом, такими как Tesseract, которые используют собственный словарь для сегментации символов.
Другой подход заключается в создании специализированного глоссария терминов, часто встречающихся в вашем домене. Кроме того, рецензенты могут использовать свои отзывы в качестве входных данных для другого сеанса обучения алгоритму оптического распознавания символов.
Как алгоритмы OCR могут помочь вашему бизнесу?
Вот что могут сделать для вас решения для оптического распознавания символов:
- Сокращение затрат: преобразование файлов в цифровой формат и автоматизация ввода данных сокращают затраты в пересчете на рабочее время.
- Повышение удовлетворенности клиентов: эта технология позволит людям удаленно обновлять свою личную информацию путем сканирования документов, удостоверяющих личность, вместо физического посещения банка или любого другого учреждения.
- Предлагайте более дешевые варианты резервного копирования: нет необходимости хранить бумажные документы вместе с их дубликатами и тройками, что требует дорогостоящих физических единиц хранения
- Облегчение перевода между разными языками: некоторые инструменты OCR позволяют переводить документы с одного языка на другой.
- Автоматизация рабочих процессов: поиск в цифровых файлах с хорошей системой управления выполняется быстрее, чем работа с бумажными документами. Меньше процессов будет приостановлено при поиске потерянного физического файла. Если вас интересует более комплексное решение для автоматизации, вы можете использовать интеллектуальные службы автоматизации процессов, которые включают OCR и другие расширенные возможности.
Решения OCR, доступные на рынке
Если вы думаете о включении функций OCR в свои ИТ-системы, у вас есть несколько вариантов на выбор.
Алгоритмы оптического распознавания символов с открытым исходным кодом
Существует несколько алгоритмов OCR с открытым исходным кодом, которые предприятия могут адаптировать к своим потребностям. Эти решения легче настроить, поскольку их исходный код общедоступен. Однако центральной власти нет. Разработчики решений с открытым исходным кодом не берут на себя ответственность и не предлагают дальнейшую поддержку. Следовательно, качество кода может быть сомнительным. Этот вариант больше подходит для компаний с сильными ИТ-отделами, способными устранить любую неисправность. Кроме того, вы можете обратиться к консультантам по машинному обучению, которые могут настроить и переобучить это программное обеспечение для вас. Вот некоторые часто используемые решения OCR с открытым исходным кодом:
Тессеракт
Tesseract движок с открытым исходным кодом является одним из самых популярных инструментов OCR и считается одним из самых точных бесплатные инструменты. Она была разработана компанией Hewlett-Packard в период с 1985 по 1994 год. Начиная с 2006 года эта платформа управлялась и развивалась компанией Google. Tesseract написан на C++, но предлагает оболочки на Java, Python, Swift, Ruby, R и еще нескольких распространенных языках программирования. Инструмент работает с использованием командной строки и не имеет графического пользовательского интерфейса. Однако есть несколько вариантов графического интерфейса, которые можно развернуть, чтобы сделать это решение удобным для пользователя. Одним из примеров является glmageReader. Этот интерфейс разработан с использованием Python и поддерживает различные форматы изображений, включая PNG, GIF и PNM.
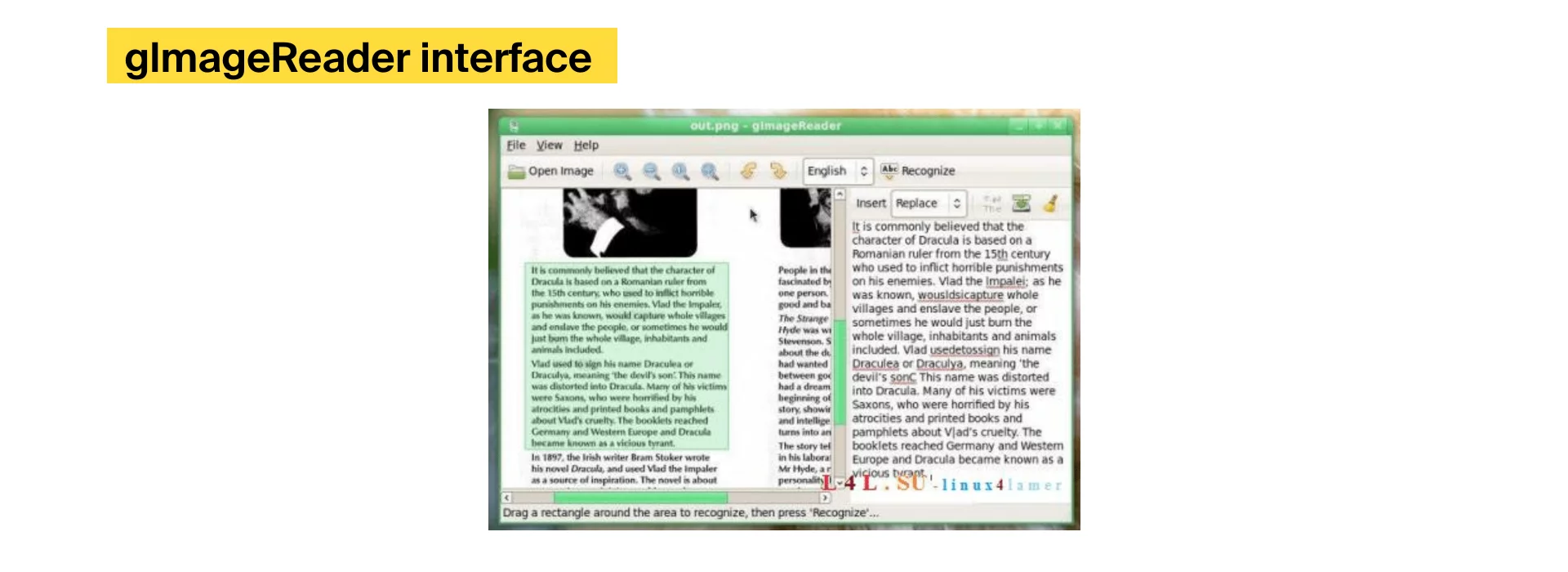
Tesseract не предлагает анализ макета страницы, не форматирует вывод, а его интерфейс командной строки требует, чтобы все изображения были отправлены в формате TIFF. Кроме того, это решение OCR не оптимизировано для графического процессора и не поддерживает пакетную обработку.
OCRopus
OCRopus изначально был написан на Python, а теперь имеет отдельную версию на C++. Он поддерживается Google и использовался в качестве механизма распознавания текста для алгоритма Google ReCaptcha.
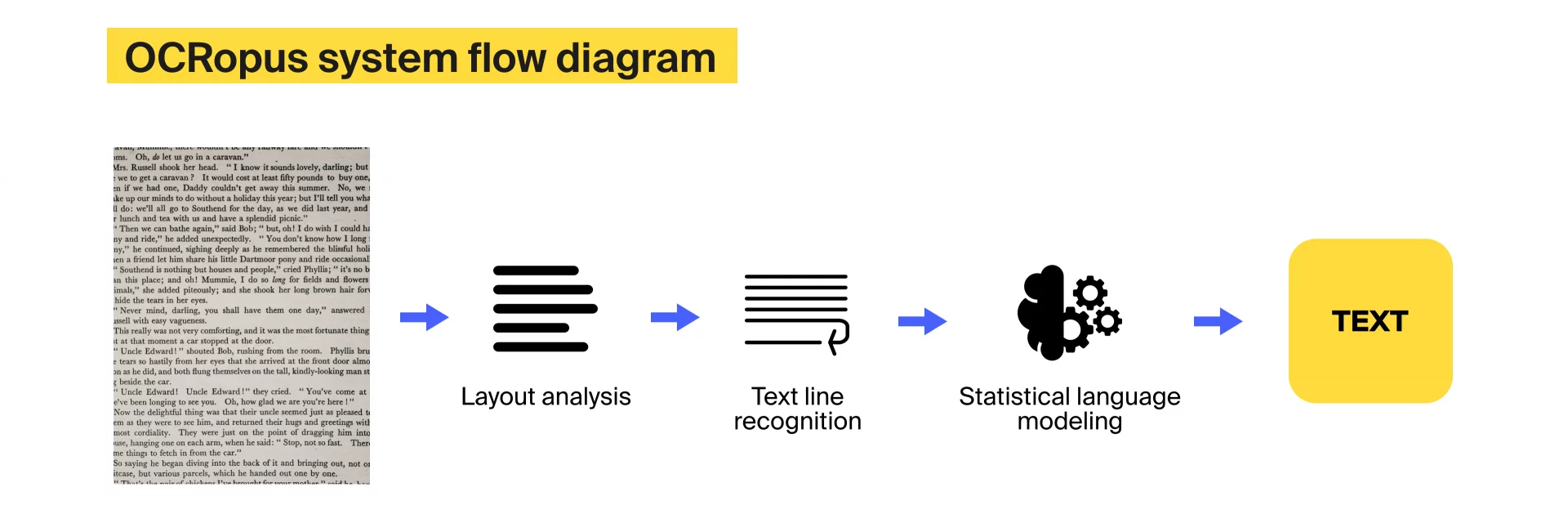
OCRopus имеет три основные функции:
- Анализ физического макета: идентифицирует текстовые блоки, столбцы и строки и определяет порядок чтения. Например, для обнаружения столбцов он использует алгоритм максимального прямоугольника пробелов для обнаружения пробелов между столбцами.
- Распознавание линий: распознает линии в каждом блоке или столбце, будь то вертикальные линии или строки слева направо.
- Статистическое моделирование языка: использует словари и стохастическую грамматику для решения проблемы пропущенных и неопознанных букв.
EasyOCR
Jaided AI, компания, занимающаяся оптическим распознаванием символов, создала пакет EasyOCR с использованием библиотеки Python и PyTorch с ее моделями глубокого обучения. Он поддерживает более 80 языков, включая кириллицу, китайский и арабский языки, и эта база постоянно расширяется. В рамках дорожной карты реализации планируется добавить настраиваемые параметры для распознавания рукописного текста.

Коммерческие решения OCR
Программное обеспечение как услуга (SaaS) позволяет вам использовать высококачественные алгоритмы и получать полную поддержку поставщиков. В зависимости от выбранной платформы вы можете переобучить алгоритм OCR в своем наборе данных и еще больше адаптировать его к вашим уникальным потребностям.
Текст Амазонки
[Amazon Textract] (https://aws.amazon.com/texttract/) — это сервис на основе машинного обучения, который извлекает печатный и рукописный текст из отсканированных документов. Он может работать с неструктурированными данными и с форматированным текстом, таким как формы и таблицы. Решение использует искусственный интеллект и не требует дополнительных шагов настройки или шаблонов. Этот сервис является безопасным и соответствует правилам защиты данных, таким как HIPAA и GDPR. Amazon Textract предлагает четыре API, которые клиенты могут использовать и соответственно оплачивать:
- API обнаружения текста документа: извлекает неструктурированный печатный текст и почерк из сканов. Стоимость 0,0015 доллара США за страницу за первый миллион страниц; после этого цена снижается.
- API анализа документов: работает со структурированными данными. Извлекает текст из форм и таблиц. Клиенты будут платить 0,015 доллара США за страницу при обработке таблиц и 0,05 доллара США за страницу в случае форм. Цена снижается после первого миллиона страниц.
- API для анализа расходов: работает со счетами. Этот сервис имеет общую таксономию полей, связанных с квитанциями. Например, он может распознавать номер счета. Пользователи будут платить 0,01 доллара США за страницу за первый миллион страниц.
- Analyze ID API: понимает контекст документов, удостоверяющих личность, таких как водительские права и паспорта, и может извлекать текст из определенных полей. Вы можете воспользоваться этой услугой за 0,025 доллара США за первые 100 000 страниц.
Облачное зрение Google
Google предлагает Vision API, который может извлекать печатный и рукописный текст из документов и изображений. Он содержит две функции для оптического распознавания символов:
- Text_detection: извлекает текст из изображений, например фотографий дорожных знаков.
- Document_text_detection: захватывает тексты в документах и изображениях. Она отличается от предыдущей функции тем, что ее отклик оптимизирован для плотных текстов.
Обе функции позволяют пользователям обрабатывать первые 1000 единиц в месяц бесплатно. После этого вы будете платить 1,5 доллара за каждую 1000 единиц. Эта цена будет уменьшаться по мере того, как вы отправляете больше единиц в месяц.
Компьютерное зрение Microsoft Azure
Microsoft предлагает услуги OCR как часть своего общего API компьютерного зрения, а не как отдельную функцию. Итак, вы платите за весь пакет, который помимо оптического распознавания символов, включает идентификацию знаменитостей, достопримечательностей, брендов и общее обнаружение объектов. Этот API будет стоить вам 1 доллар США за 1000 транзакций для первого миллиона единиц. После этого цена снижается до 0,65 доллара США за 1000 транзакций и будет снижаться по мере того, как вы отправляете больше контента.
Лучшие варианты использования OCR в разных отраслях
Алгоритмы оптического распознавания символов набирают популярность в различных отраслях. Ниже приведены некоторые из наиболее известных приложений OCR.
OCR в банковской сфере
Банковские учреждения используют множество бумажных документов в своих рабочих процессах. К ним относятся чеки, записи о клиентах, кредитные заявки, банковские выписки и т. д. Внедрение алгоритмов распознавания OCR позволяет сотрудникам хранить и получать доступ ко всем этим документам в цифровом виде и предотвращает потерю и повреждение документов. Обработка чеков Одним из примеров OCR в этом секторе является использование банковских приложений для депонирования бумажных чеков в цифровом виде. В этих решениях используются алгоритмы оптического распознавания символов для идентификации соответствующих полей в чеках и выполнения соответствующих операций без необходимости передачи сотрудником всех этих данных вручную. Кроме того, такие приложения могут выполнять проверку подписи по существующей базе данных и немедленно очищать проверку. Включение клиентов Вместо того, чтобы сотрудник проверял личность клиентов вручную, решения на основе OCR могут извлекать и проверять всю необходимую информацию из паспорта человека и других документов, удостоверяющих личность. Это обеспечивает мгновенную проверку и улучшает качество обслуживания клиентов. Обновление информации о клиенте Вместо того, чтобы посещать или звонить в банк, с помощью OCR клиенты могут сканировать свои документы для автоматического обновления информации. Например, Альфа-Банк сотрудничал с Smart Engines, чтобы улучшить свое банковское приложение с помощью оптических возможности распознавания символов. С помощью этой новой функции клиенты могут размещать документы, удостоверяющие личность, перед камерами своего смартфона, подтверждать извлеченные данные и обновлять свою информацию в банковской системе.
OCR в здравоохранении
Как и в банковском секторе, организации здравоохранения накапливают множество бумажных документов, таких как рентгеновские снимки, результаты анализов, планы лечения и так далее. Алгоритмы OCR помогают оцифровывать эти файлы, чтобы предотвратить потерю физических документов и сократить усилия, затрачиваемые на ручную обработку бумажных файлов. Кроме того, некоторые решения OCR, распознающие рукописный текст, могут обрабатывать регистрационные документы и рецепты пациентов.
Система медицинских заявлений
Есть поставщики программного обеспечения, которые специализируются на обработке медицинских заявлений с помощью OCR. Одной из таких компаний является [OCR Solutions] (https://ocrsolutions.com/software/document-capture/medical-claim/). Компания разработала продукт, который может сканировать, проверять и правильно направлять медицинские заявления для дальнейшей обработки. Эта программа обучена и настроена для работы с распространенными форматами, такими как Dental Claim Forms и CMS-1500, среди прочих.
Факс
Многие медицинские учреждения по-прежнему полагаются на факс. Решения для оптического распознавания символов могут преобразовывать входящий материал в доступный цифровой формат.
Выставление счетов
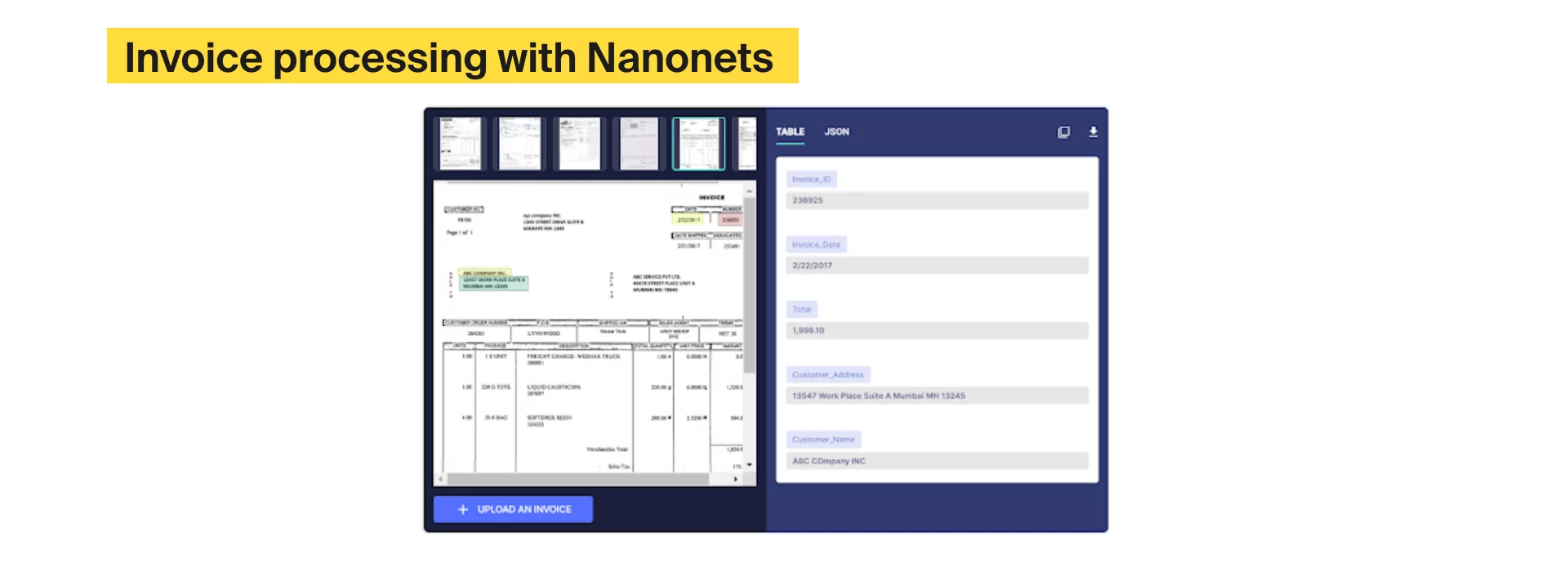
Решения на базе OCR помогают организациям здравоохранения оцифровывать счета и правильно их хранить. Один из примеров распознавания исходит от компании Nanonets из Сан-Франциско (https://nanonets.com/invoice-ocr), которая предлагает решение на базе OCR, специализирующееся на обработке счетов. Компания утверждает, что ее программное обеспечение сократит время ввода данных счета с трех минут до 30 секунд.
OCR в розничной торговле
Алгоритмы оптического распознавания символов позволяют сотрудникам розничной торговли экономить время на обработке заказов на покупку, счетов-фактур, упаковочных листов и других документов. Эти решения также могут извлекать серийные номера из штрих-кодов продуктов и позволяют клиентам сканировать свои ваучеры и извлекать серийные коды.
Сканирование удостоверений личности
Сотрудникам магазина может понадобиться сканировать личную информацию по многим причинам, таким как проверка возраста, заполнение информации для лояльности клиентов и т. д. Поставщики OCR извлекают выгоду из этой возможности. Например, OCR Solutions, базирующаяся во Флориде, разработала idMax, программное обеспечение на основе OCR, которое может сканировать документы, удостоверяющие личность, извлекать соответствующие поля и заполнять базу данных продавца соответствующей информацией. idMax можно установить локально или получить к нему доступ через облако.
Проблемы внедрения решения OCR в вашем бизнесе
Если вы решили развернуть алгоритмы распознавания OCR для улучшения своей работы, вам необходимо учитывать несколько аспектов:
- Входной материал: убедитесь, что все входные файлы подходят для алгоритма OCR. Например, файлы не должны иметь повреждений, которые могут помешать алгоритму распознавать их содержимое. Контрастность достаточно высока, страницы правильно выровнены и т. д. Некоторые алгоритмы обладают мощными возможностями предварительной обработки и могут решить некоторые из этих проблем за вас. Но если это не так, возможно, стоит инвестировать в высококачественный сканер и обеспечить правильное выравнивание страниц.
- Обучающий набор данных: если вы решите обучить или переобучить алгоритмы оптического распознавания символов, вам необходимо убедиться, что данные, которые вы планируете использовать, точно представляют исходный материал и содержат достаточно правильных аннотаций. Если ваш обучающий набор данных слишком мал или не содержит адекватных аннотаций, алгоритм не даст желаемых результатов. Также во время обучения нужно обращать особое внимание на похожие символы/символы. Например, числа 2 и 7 могут выглядеть довольно похоже, особенно если ожидается, что алгоритм будет работать с рукописным текстом. Специалисты по данным должны учитывать такие различия в обучающих данных. Другим примером может быть использование алгоритмов OCR для обнаружения и захвата номерных знаков автомобилей. Вы должны убедиться, что ваш алгоритм не использует индивидуальную наклейку с текстом на задней части автомобиля, приняв ее за номерной знак.
- Рукописный текст: с рукописным вводом возникает множество дополнительных проблем с распознаванием текста. У разных людей существует большое разнообразие стилей письма; даже текст отдельных пользователей может быть непоследовательным. Сбор надежного репрезентативного набора обучающих данных является сложной задачей, поскольку вам необходимо учитывать все различные стили. Скорописный почерк особенно сложен для обработки. Кроме того, в то время как печатный текст идет по прямой линии, почерк имеет тенденцию иметь переменное вращение, что еще больше усложняет ситуацию.
- Масштабирование: если вы увеличите количество пользователей или количество запросов на временной интервал, система может рухнуть, особенно если вы используете решение с открытым исходным кодом и полагаетесь на собственные вычислительные мощности. В случае коммерческих продуктов OCR, которые работают в облаке, вы можете договориться о дополнительной емкости и заплатить за нее.
- Мониторинг производительности алгоритма OCR: после развертывания производительность алгоритма может начать снижаться из-за различных факторов. Одним из примеров является изменение распределения между обучающими данными и фактическими производственными данными. Это происходит, когда модель начинает работать с наборами данных, к которым она не была подготовлена, например, с другими шрифтами или символами с необычным наклоном. Эти изменения со временем повлияют на выходные данные модели, и вам необходимо обнаружить эти проблемы и соответствующим образом переобучить модель, чтобы сохранить ее первоначальный уровень точности.
Подводить итоги
Алгоритмы оптического распознавания символов могут ускорить ваши бизнес-процессы. Тем не менее, есть связанные проблемы, которые необходимо учитывать. Выбранный алгоритм, скорее всего, потребует переобучения, а правильно аннотировать большой набор данных — утомительная задача. Вам также необходимо подумать о потенциальном масштабировании по мере расширения вашего бизнеса. Принятие решения с открытым исходным кодом кажется заманчивым с точки зрения цены, но у него есть свои недостатки, такие как отсутствие поддержки и обновлений, которые могут открыть лазейки в безопасности. Коммерческие решения более надежны в этом отношении, но могут быть дорогостоящими и сложными в настройке.
Если вы не знаете, как поступить и какое решение OCR лучше всего подходит для вашего бизнеса, не стесняйтесь обращаться к нам. В ITRex мы будем рады провести тщательную оценку потребностей вашего бизнеса, чтобы определить лучший вариант OCR. Мы также можем помочь вам переобучить выбранное решение и интегрировать его в вашу систему. Мы также можем создать собственный алгоритм OCR, если это необходимо.
Хотите ускорить работу с оптическим распознаванием символов? Напишите нам! Наши специалисты по искусственному интеллекту помогут вам с интеграцией решения OCR и обучением. При необходимости мы также можем разработать для вас индивидуальные алгоритмы.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)