Впервые представленные как часть стандарта SQ:2003 и доступные в MySQL 8.0, оконные функции в MySQL привлекательны, но их синтаксис также может немного пугать, когда вы впервые начинаете их использовать. Этот пост является первым в серии, в которой мы обсудим оконные функции, включая разбор синтаксиса и использование примеров различных оконных функций.
Определение
Прежде чем мы сможем разобрать различные части оконных функций, давайте определим, что они из себя представляют и что они делают. Оконные функции — это встроенные функции MySQL, которые предлагают агрегатные функции для определенного диапазона строк в запросе. В то время как другие агрегатные функции SUM() группируют результат в одну строку или сгруппированные строки, оконные функции возвращают значение для каждой строки в результате запроса. Оконные функции могут быть агрегатными функциями, такими как, или неагрегатными функциями, такими как RANK(). В этом посте мы покажем примеры некоторых неагрегированных оконных функций.
Настройка наших данных
Прежде чем двигаться дальше, давайте настроим демонстрационные данные. Вот скрипты, которые мы будем использовать для определения и заполнения таблицы для этого поста. Эти данные представляют собой вымышленное соревнование, в котором игроки зарабатывают очки в каждом матче. Используемая нами информация показывает общее количество очков, набранных игроком.
-- Create the schema
CREATE SCHEMA IF NOT EXISTS `window-function-demo`;
-- Switch to use the schema
USE `window-function-demo`;
-- Drop table
DROP TABLE IF EXISTS `player`;
-- Create the table
CREATE TABLE IF NOT EXISTS `player` (
`id` INT NOT NULL AUTO_INCREMENT,
`full_name` VARCHAR(45) NOT NULL,
`points` DECIMAL(5,2) NOT NULL,
`group_name` VARCHAR(10),
PRIMARY KEY (`id`)
);
Как видите, в этой таблице всего четыре столбца: идентификатор, который является первичным ключом, имя игрока, количество очков, набранных игроком, и группа, к которой принадлежит игрок.
-- Insert data
insert into player (full_name, points, group_name) values ('Noe Mann', 155.85, 'Group A');
insert into player (full_name, points, group_name) values ('Precious Cummings', 188.58, 'Group A');
insert into player (full_name, points, group_name) values ('Maryetta Wehner', 81.09, 'Group A');
insert into player (full_name, points, group_name) values ('Todd Sharp', 188.59, 'Group A');
insert into player (full_name, points, group_name) values ('Macie Bartoletti', 142.72, 'Group A');
insert into player (full_name, points, group_name) values ('Emmitt Metz', 155.85, 'Group A');
insert into player (full_name, points, group_name) values ('Ardella Langosh', 188.58, 'Group A');
insert into player (full_name, points, group_name) values ('MARK Reilly', 73.3, 'Group A');
insert into player (full_name, points, group_name) values ('Ardath Greenfelder', 71.4, 'Group A');
insert into player (full_name, points, group_name) values ('Coleman Ferry', 124.2, 'Group A');
insert into player (full_name, points, group_name) values ('Ray Camden', 176.34, 'Group A');
insert into player (full_name, points, group_name) values ('Carolyne Abshire', 176.34, 'Group A');
insert into player (full_name, points, group_name) values ('Jimmie Neighbors', 71.27, 'Group A');
insert into player (full_name, points, group_name) values ('Kevin Hardy', 71.27, 'Group A');
insert into player (full_name, points, group_name) values ('Loralee Fahey', 176.34, 'Group A');
insert into player (full_name, points, group_name) values ('Corrinne Raynor', 86.74, 'Group B');
insert into player (full_name, points, group_name) values ('Parthenia Gutmann', 100.01, 'Group B');
insert into player (full_name, points, group_name) values ('Porfirio Medhurst', 161.45, 'Group B');
insert into player (full_name, points, group_name) values ('Alex Cremin', 173.98, 'Group B');
insert into player (full_name, points, group_name) values ('Sibyl Schaefer', 60.82, 'Group B');
insert into player (full_name, points, group_name) values ('Marsha Robel', 191.62, 'Group B');
insert into player (full_name, points, group_name) values ('Shayne Donnelly', 138.91, 'Group B');
insert into player (full_name, points, group_name) values ('Tyler Stroz', 190.66, 'Group B');
insert into player (full_name, points, group_name) values ('Douglass Grimes', 107.61, 'Group B');
insert into player (full_name, points, group_name) values ('Jesse Rosenbaum', 105.52, 'Group B');
insert into player (full_name, points, group_name) values ('Jeri Schmidt', 50.83, 'Group B');
insert into player (full_name, points, group_name) values ('Roy McHaffa', 183.45, 'Group B');
insert into player (full_name, points, group_name) values ('Scott Stroz', 183.45, 'Group B');
insert into player (full_name, points, group_name) values ('Pamala Mann', 159.33, 'Group B');
insert into player (full_name, points, group_name) values ('Bernita Yundt', 187.6, 'Group B');
Синтаксис оконной функции
Использование RANK(), DENSE_RANK() и OVER()
Оконные функции имеют несколько предложений, но все они имеют общие предложения OVER(). Неагрегатные оконные функции требуют предложения OVER(), а агрегатные функции будут работать как оконные функции, когда мы их добавим. Например, если бы мы хотели отобразить рейтинг каждого игрока на основе количества набранных им очков, мы бы использовали оконную функцию RANK(), и запрос выглядел бы так:
SELECT `full_name`,
`points`,
RANK() OVER(
ORDER BY `points` desc
) player_overall_rank,
`group_name`
FROM `player`
ORDER BY player_overall_rank;
Как видите, одна часть предложения OVER() – это предложение ORDER BY. Итак, в этом примере мы говорим RANK(), чтобы вы возвращали значение рейтинга на основе убывающего порядка баллов.
Результаты этого запроса показывают, что ранг каждого игрока будет выглядеть следующим образом:
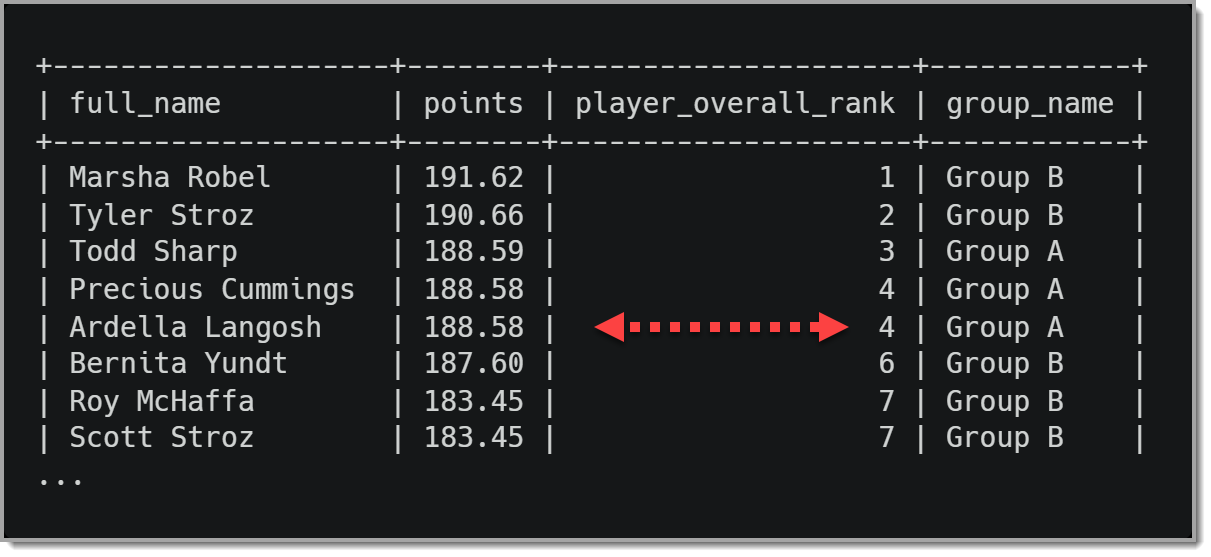
Обратите внимание, что значение ранга является последовательным, пока не дойдет до Ardella Langosh и не повторится четыре раза. Это повторение связано с тем, что Арделла и Прешес Каммингс набрали одинаковое количество очков, каждая из которых занимает 4-е место в общем зачете. Кроме того, следующий игрок, Бернита Юндт, занимает 6-е место. Это действие связано с тем, что мы использовали RANK(), где он будет пропускать числа, если более одного значения совпадают с другим. Эта логика согласуется с тем, как часто работают списки лидеров для соревнований.
Пока у нас есть доступ к данным, которые мы используем для разрешения конфликтов, мы можем показать только одного игрока на рейтинг. В нашем случае мы будем использовать имя игрока в качестве тай-брейка, поэтому, если две или более команд равны, игрок, чье имя стоит первым в алфавитном порядке, получит более высокий рейтинг.
Запрос для принудительного применения этого разрешения конфликтов будет таким:
SELECT `full_name`,
`points`,
RANK() OVER(
ORDER BY `points` desc, full_name
) player_overall_rank,
`group_name`
FROM `player`
ORDER BY player_overall_rank;
Обратите внимание, что мы добавили full_name в ORDER BY оконной функции RANK().
Результаты этого запроса будут выглядеть следующим образом:
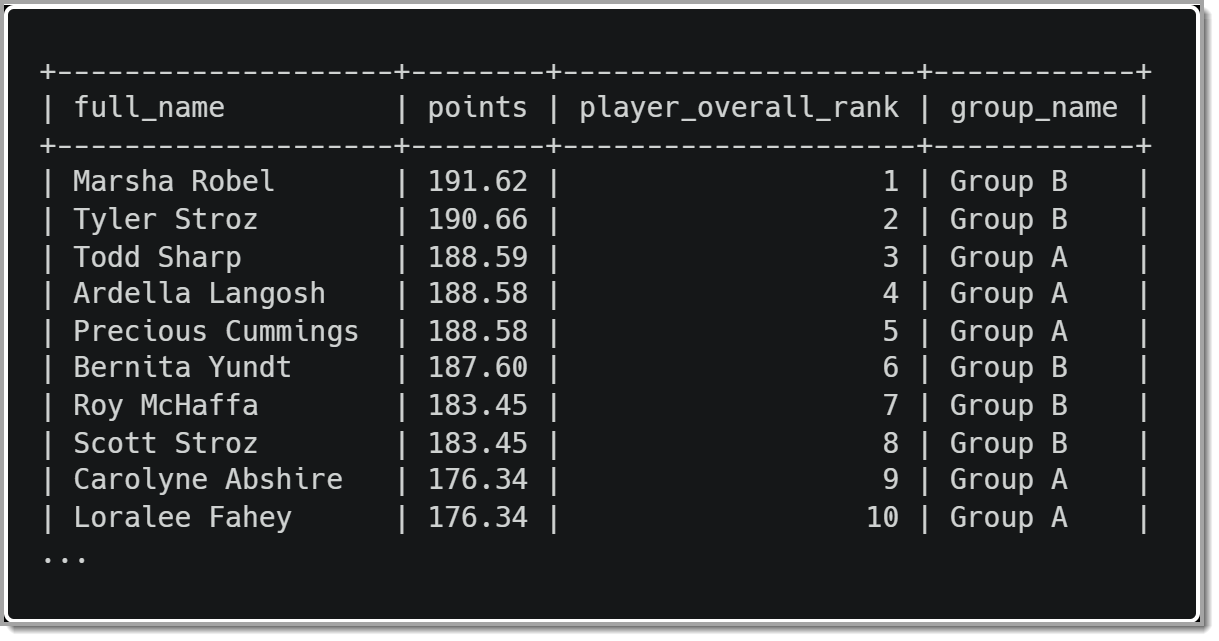
Как мы видим, каждый игрок теперь имеет рейтинг от 1 до 10 вместо того, чтобы дублировать ранги среди игроков с одинаковым количеством очков.
Если бы мы решили не пропускать числа, когда два одинаковых значения, мы бы использовали DENSE_RANK() их, как в запросе ниже.
SELECT `full_name`,
`points`,
DENSE_RANK() OVER(
ORDER BY `points` desc
) player_overall_rank,
`group_name`
FROM `player`
ORDER BY player_overall_rank;
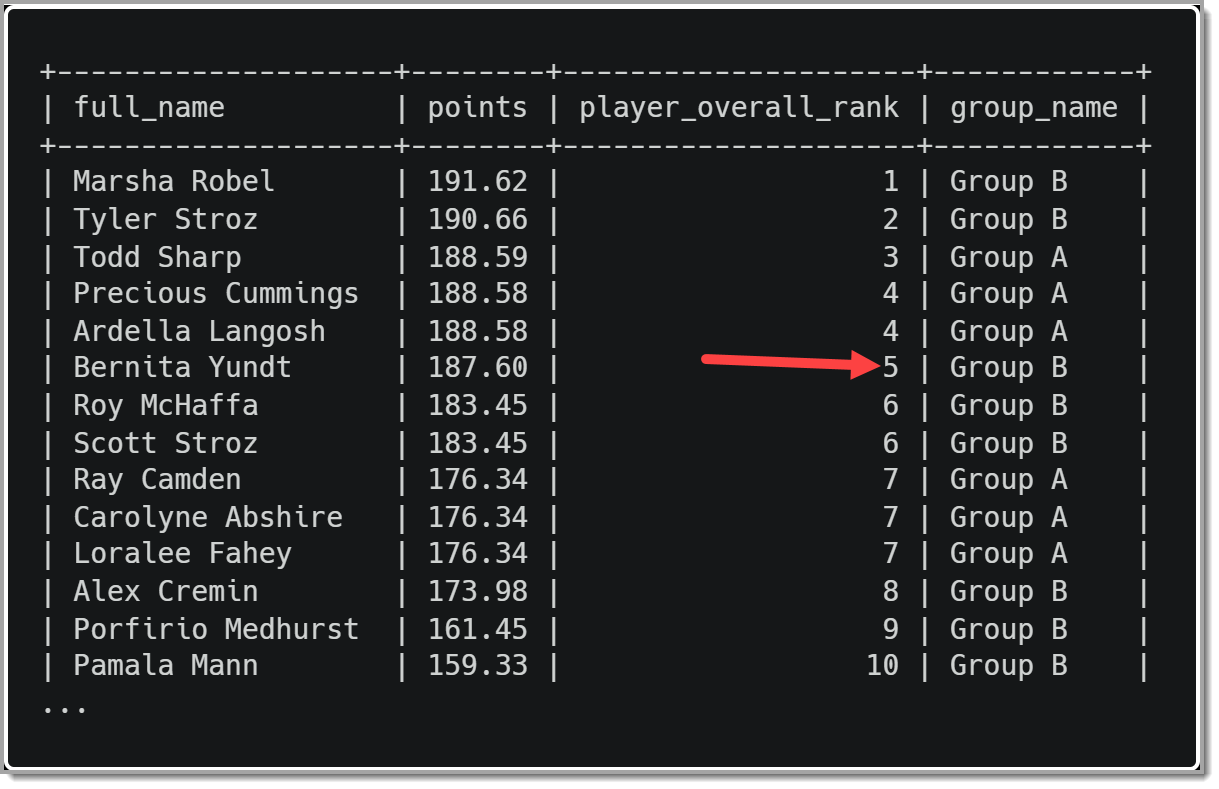
На изображении ниже показаны результаты использования DENSE_RANK(). Обратите внимание, что у Берниты Юндт рейтинг 5, а не 6, как в первом примере.
Использование PARTITION BY
Хотя интересно посмотреть, какое место занимает каждый игрок по сравнению со всеми остальными, это не позволяет легко увидеть, какое место занимают игроки в каждой из двух групп. Если мы хотим показать, какое место занимают игроки в своей группе, нам нужно использовать предложение PARTITION BY нашего предложения OVER(). Раздел сообщает оконной функции, как группировать данные в разные наборы. PARTITION BY работает аналогично предложению GROUP BY.
Вот как мы можем использовать PARTITION BY, чтобы показать ранг каждого игрока в своей группе:
SELECT `full_name`,
`points`,
RANK() OVER(
ORDER BY `points` desc
) player_overall_rank,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` desc
) player_group_rank
FROM `player`
ORDER BY group_name, player_group_rank;
Обратите внимание, что мы добавили еще один столбец, player_group_rank, в результирующий набор, который использует предложение PARTITION BY, и мы используем group_name В качестве раздела, раздел сообщит MySQL для перезапуска ранжирования при смене группы. Если вы не укажете раздел, MySQL будет рассматривать весь набор результатов как один раздел. Это определение раздела — это то, как мы получили рейтинг каждого игрока в обеих группах. Обратите внимание, что в предложении ORDER BY мы сначала сортируем по имени группы, а затем по рейтингу в этой группе.
Вот результаты этого запроса:
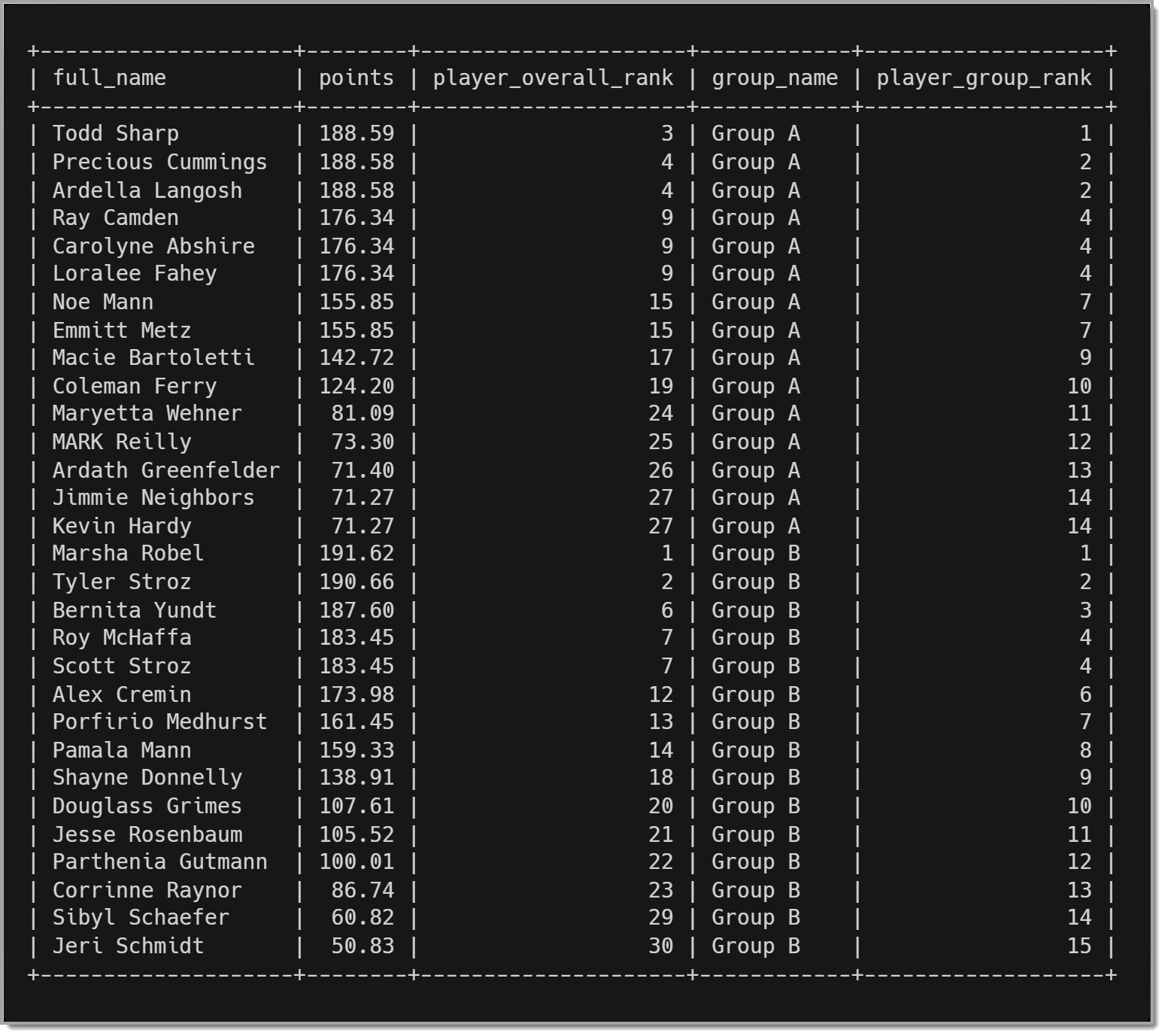
Теперь мы видим, что каждый игрок указан в своей группе, отсортированной по их рейтингу в этой группе. Хотя Тодд Шарп занимает 3-е место в общем рейтинге, он является игроком с самым высоким рейтингом в группе A. Мы также можем видеть, что, хотя Рэй Камден занимает 9-е место в общем зачете, он делит 4-е место в группе A.
FIRST_VALUE() Пример
Теперь у нас есть полезный рейтинг каждого игрока в его группе. Однако что, если мы хотим показать, сколько очков игрок получает от того, чтобы занять 1-е место в своей группе? Этого можно добиться с помощью оконной функции с именем FIRST_VALUE(). Как вы могли догадаться по его имени, FIRST_VALUE() возвращает значение данных из первой строки в разделе. Он немного отличается от того, что мы уже видели, тем, что мы передаем имя столбца для значения, которое хотим вернуть.
Вот запрос, возвращающий, сколько очков после 1-го места у игрока в данной группе.
SELECT `full_name`,
`points`,
`group_name` group_name,
RANK() OVER(
PARTITION BY `group_name`
ORDER BY `points` desc
) player_group_rank,
points - FIRST_VALUE( points ) OVER (
PARTITION BY `group_name`
ORDER BY points DESC
) points_back_of_first
FROM `player`
ORDER BY group_name, player_group_rank;
Передавая аргумент points в FIRST_VALUE(), мы получаем значение столбца точек из первой строки в разделе. Чтобы подсчитать, на сколько очков отстает игрок от 1-го места, нам нужно сделать что-то отличное от того, что мы делали до сих пор. Нам нужно вычесть очки первой строки раздела из очков игрока в текущей строке. В этом примере мы используем результат нашего вызова FIRST_VALUE() в уравнении. Для меня это одна из замечательных особенностей оконных функций, и мы не ограничены простым добавлением результатов вызова функции в результирующий набор. Мы можем использовать их так же, как и любое другое значение, в том числе использовать значения в предложении WHERE или как часть оператора CASE (мы скоро увидим пример последнего). ).
Результат этого запроса выглядит следующим образом:
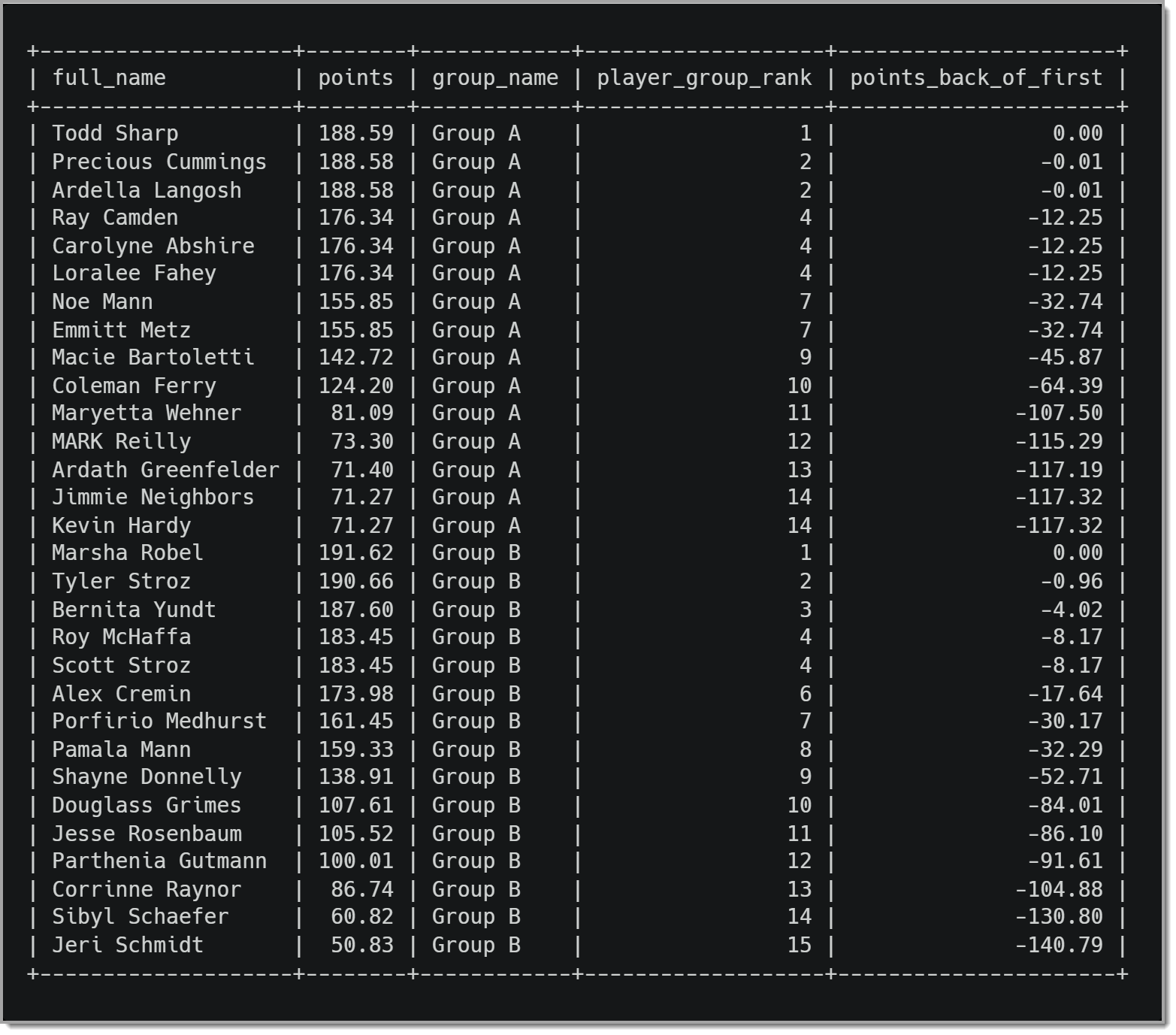
Когда мы просматриваем эти рейтинги, гораздо проще определить, насколько далеко игрок отстает от игрока, занявшего 1-е место. Было бы тривиально обрабатывать это программно на любом языке программирования. Возврат этих данных как части результирующего набора упрощает процесс, возвращая эти данные в результирующий набор.
NTH_VALUE() Пример
В нашем вымышленном соревновании есть плей-офф в конце регулярного сезона. В плей-офф выходят по 4 лучшие команды из каждой группы. Хотя приятно видеть, сколько очков игрок потерял после первого места, для игроков может быть полезнее узнать, сколько очков они набрали после выхода в плей-офф. Для этого мы используем оконную функцию NTH_VALUE().
SELECT `full_name`,
`points`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` desc
) player_group_rank,
points - FIRST_VALUE( points ) OVER (
PARTITION BY `group_name`
ORDER BY points DESC
) points_back_of_first,
CASE
WHEN NTH_VALUE( points, 4 ) OVER(
PARTITION BY `group_name`
ORDER BY points DESC
) IS NULL THEN 0
ELSE points - NTH_VALUE( points, 4 ) OVER(
PARTITION BY `group_name`
ORDER BY points DESC
)
END AS points_from_playoffs
FROM `player`
ORDER BY group_name, player_group_rank;
Вот пример использования оконных функций в заявлении CASE, которое я обещал.
Давайте сначала посмотрим, как мы используем NTH_VALUE(), а затем поговорим о том, как мы используем его в операторе CASE. Как видите, мы используем два аргумента для NTH_VALUE(). Первый — это столбец, который мы хотим использовать, так как в предыдущем примере мы используем значение столбца points. Второй аргумент — это номер строки в результате, который мы хотим просмотреть. В нашем примере мы хотим сравнить каждую строку со значением в 4-й строке, поэтому мы передаем значение 4. Итак, в двух словах, наш вызов NTH_VALUE() указывает MySQL получить значение столбца очков в 4-й строке раздела.
Возможно, вам интересно, почему мы решили использовать оператор CASE для этого значения, и простой ответ — для согласованности. В этой ситуации мы постоянно используем их CASE для возврата числа в результирующем наборе. Как видно из WHEN в операторе CASE, иногда оконные функции возвращают NULL. В этом случае первые три строки вернут NULL, потому что четвертая строка еще не существует для сравнения. Оператор CASE гарантирует, что если возвращаемое значение NTH_VALUE() равно NULL, мы получаем значение 0 ( потому что у игроков с 1 по 3 все еще 0 очков до места в плей-офф). Если значение, возвращаемое функцией NTH_VALUE(), не равно нулю, мы вычитаем это значение из значения баллов для текущей строки и возвращаем результат.
Вот результат запроса выше:
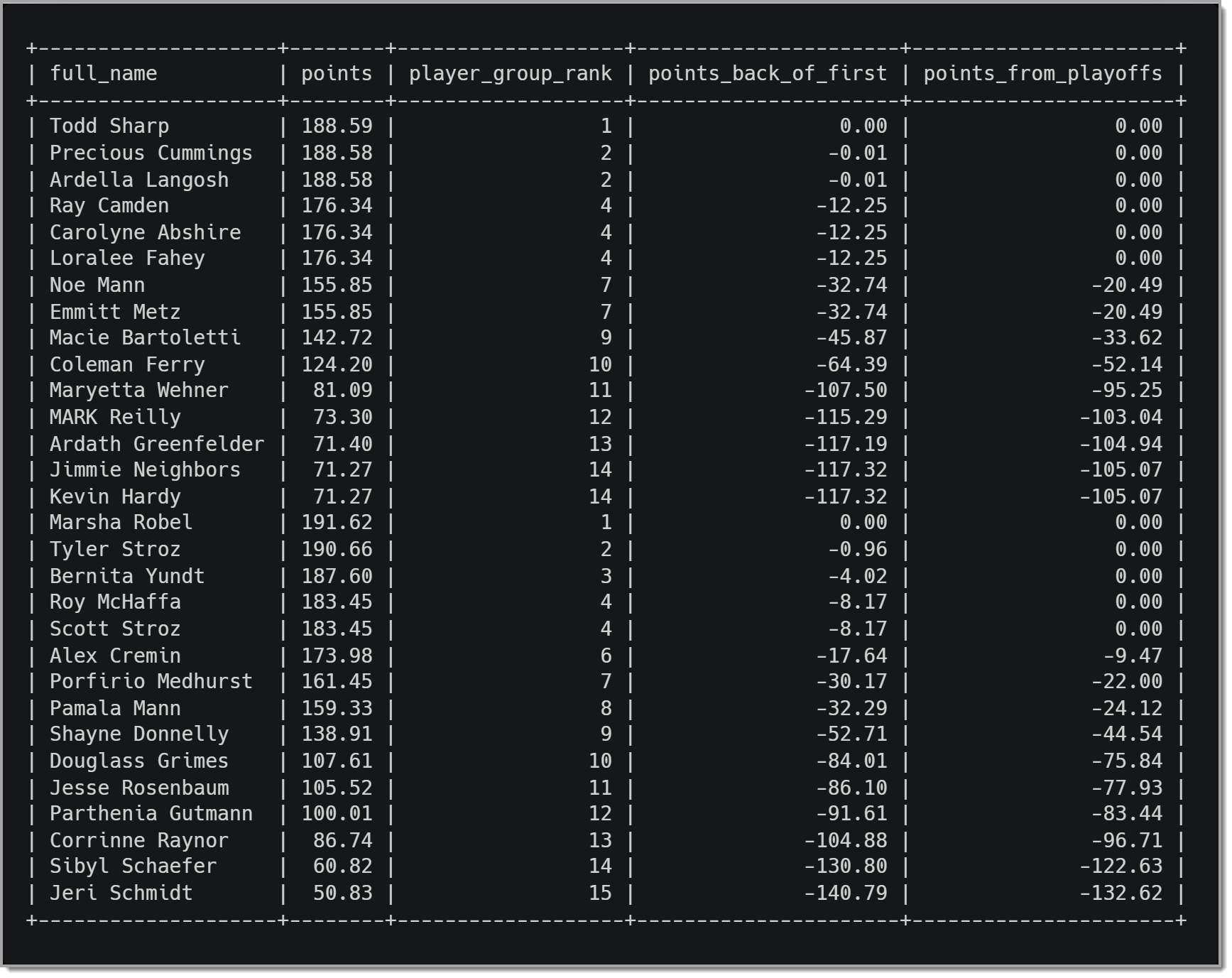
Может показаться странным, что более четырех команд имеют 0 очков от места в плей-офф в каждой группе. Например, в группе А у нас есть две команды, разделившие 2-е место, и три команды, занявшие 4-е место. В группе B две команды делят 4-е место. Если бы у нас была ничья в конце сезона, нам нужно было бы использовать тай-брейк, чтобы определить, кто выйдет в плей-офф. Затем, в зависимости от правил разрешения конфликтов, мы могли бы добавить эту логику в запрос, чтобы обеспечить отображение связанных точек команды на основе информации разрешения конфликтов.
Подведение итогов
Как мы видели, оконные функции предлагают нам множество способов возврата данных, связанных с другими строками в наборе данных. Мы обсудили базовый синтаксис оконных функций и показали примеры использования неагрегированных оконных функций в нашем наборе результатов.
Надеюсь, вы лучше понимаете синтаксис оконных функций MySQL.
В следующем посте мы рассмотрим другие оконные функции и расширим наше понимание различных частей предложения OVER().
Если вы хотите узнать больше об оконных функциях в MySQL, перейдите к документации. .
Первоначально опубликовано здесь.