
Генерация мультимодального шрифта с использованием моделей на языке зрения и клипа
7 августа 2025 г.Таблица ссылок
Введение
Связанная работа
2.1 Семантический типографский дизайн логотипа
2.2 Генеративная модель для вычислительного дизайна
2.3 Инструмент создания графического дизайна
Формирующее исследование
3.1 Общий рабочий процесс и проблемы
3.2 Беспокойство в вовлечении генеративной модели
3.3 Пространство дизайна семантической типографической работы
Рассмотрение дизайна
Напечатано и 5.1 идея
5.2 Выбор
5.3 поколение
5.4 Оценка
5.5 итерация
Прохождение интерфейса и 6.1 стадия до поколения
6.2 Стадия генерации
6.3 Стадия после поколения
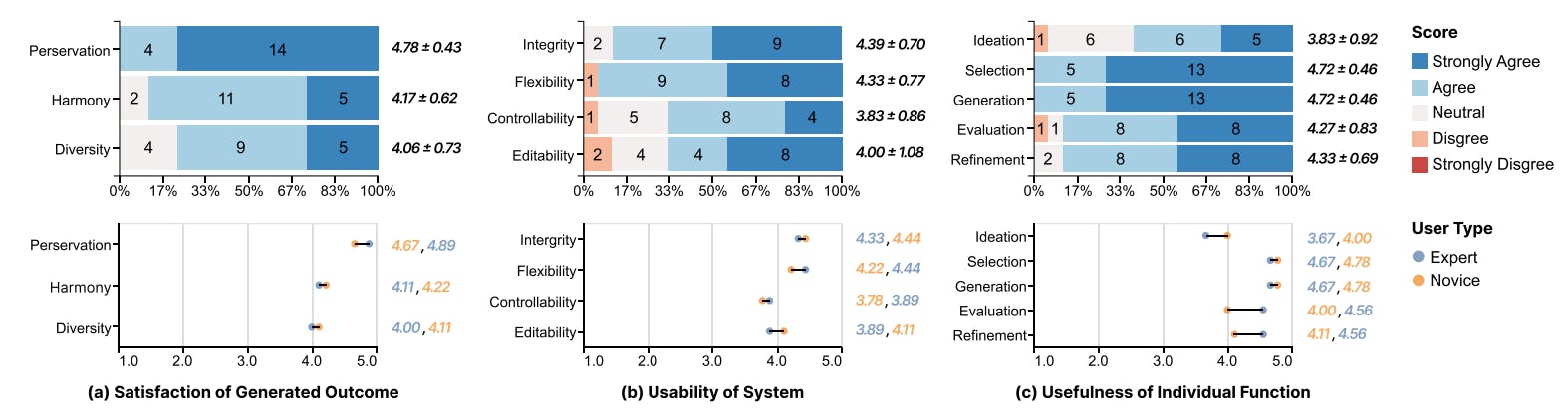
Оценка и 7.1 базовое сравнение
7.2 Изучение пользователя
7.3 Анализ результатов
7.4 Ограничение
Дискуссия
8.1 Персонализированный дизайн: сотрудничество с ИИ
8.2 Включение знаний о дизайне в инструменты поддержки творчества
8.3 Рабочий процесс ориентированного на микс-пользователь, ориентированный на инфекцию,
Заключение и ссылки
5.3 поколение
5.3.1 Generation.В этом разделе описываются три входа, необходимые для процесса генерации. Первым входом является выбранный шрифт 𝐼𝑡, который служит исходным изображением для диффузионной модели. Второй вход - это необязательное приглашение пользователя 𝑇𝑝, которое позволяет им явно выражать свои намерения, такие как конкретный стиль, который они желают. Третий вход состоит из факторов проектирования, извлеченных из выбранного изображения 𝐼𝑖.
СемантикаПолем Текстовая подсказка является доступной и интуитивно понятной средой для создателей для обучения ИИ, который также предлагает способ включить изображения в процесс генерации. Тем не менее, трудолюбиво описать значительный объем информации в рамках ограниченных условий быстрой длины. Typedance решает эту проблему, автоматически извлекая описание выбранных изображений. Описание выбранных изображений включает в себя процесс инверсии текста, охватывающий множественные измерения бетонной семантики. Одной из выдающихся семантики является общее визуальное понимание сцены. Например, на рис. 4 описание сцены«Желтая ваза с розовыми цветами».Мы захватываем эту явную визуальную информацию (объект, макет,и т. д..) Использование Blip [29], модели на языке зрения, которая превосходна в задачах подписания изображения. Более того,стильобразы, особенно когда речь идет о иллюстрациях или картинах, может значительно повлиять на его представление и служить общим источником вдохновения для создателей. Стиль случая на рис. 4«Натюрморт Photo Studio в стиле упрощенного реализма».Такой конкретный стиль получен из получения соответствующих описаний с высоким сходством в огромной базе данных. Таким образом, полная семантика изображений включает в себя сцену и стиль. Чтобы повысить масштабируемость интерфейса, мы извлекаем ключевые слова из подробной семантики. Создатели могут по -прежнему получить доступ к полной версии, парят над ключевыми словами.
ЦветПолем Typedance использует кластеризацию KNN [16] для извлечения пяти основных цветов из выбранных изображений. Эти цветовые характеристики затем применяются в последующем процессе генерации. Чтобы сохранить семантическое соотношение раскраски, извлеченные цвета превращаются в 2D -палитру, которая включает пространственную информацию. Это гарантирует, что сгенерированный вывод поддерживает значимую и когерентную цветовую композицию.
ФормаПолем Форма шрифта может принимать эстетические искажения, чтобы включить богатые образы, как показано в нашем формирующем исследовании. Чтобы достичь этого, мы сначала использовали обнаружение края, чтобы распознать контур выбранных изображений. Затем мы выбираем 20 эквидистантных точек вдоль контура. Эти точки используются для деформирования контура шрифта итеративно, используя обобщенные барицентрические координаты [33]. Деформация происходит в векторном пространстве, что приводит к модифицированной форме, которая изображает грубые образы и облегчает управляемое генерацию.
Эти коэффициенты проектирования применяются независимо от процесса генерации. Создатели имеют гибкость, чтобы объединить эти факторы в соответствии с их конкретными потребностями, что позволяет создавать различные и персонализированные дизайны.
5.3.2 Выходная дискриминация.Чтобы гарантировать, что сгенерированный результат соответствует намерению создателей, Typedance использует стратегию, которая фильтрует хорошие результаты на основе трех баллов. Как показано на рис. 4, мы стремимся к получению сгенерированного результата 𝐼𝑔 для достижения относительно сбалансированной оценки в треугольниках, состоящих из шрифтов, изображений и необязательной подсказки пользователя. Оценка шрифта 𝑠1 определяется путем сравнения карт значимости выбранного шрифта и сгенерированного результата. Карты значимости - это изображения серого, которые выделяют визуально заметные объекты на изображении, пренебрегая другой избыточной информацией. Мы извлекаем карты значимости для шрифта и сгенерированного результата, а затем сравниваем их сходство с точки зрения пикселей. Оценка изображений 𝑠2 получена из сходства косинуса между вставками изображения входного изображения 𝐼𝑖 и сгенерированным результатом 𝐼𝑔. Аналогичным образом, мы получаем оценку подсказки 𝑠3, вычислив сходство косинуса между внедрением изображения сгенерированного результата 𝐼𝑔 и текстом, внедряющим пользовательскую подсказку 𝑇𝑝. Мы используем предварительно обученную модель клипа для получения изображения и текста из-за его выровненного мультимодального пространства. Мы обозначаем 𝑠𝑖 = {𝑠𝑖1, 𝑠𝑖2, 𝑠𝑖3}, где 𝑖 представляет 𝑖-й результат в одном раунде генерации. Чтобы фильтровать результаты, которые в основном соответствуют намерениям создателей, мы используем многоцелевую функцию, которая максимизирует сумму баллов и сводит к минимуму дисперсию между ними. Функция определяется следующим образом:
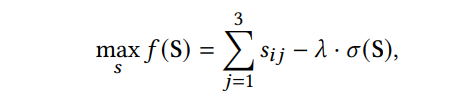
где s - набор баллов из всех сгенерированных результатов, а 𝜎 (s) рассчитывает дисперсию баллов. 𝜆 - это весовой коэффициент, используемый для баланса общего балла и дисперсии, который эмпирически устанавливается как 0,5. Основываясь на этих критериях, Typedance отображает 1 -то верхний результат на интерфейсе каждый раунд и восстанавливается, чтобы получить в общей сложности четыре результата.
Авторы:
(1) Шиши Сяо, Гонконгский университет науки и технологии (Гуанчжоу), Китай;
(2) Лангвей Ван, Гонконгский университет науки и технологии (Гуанчжоу), Китай;
(3) Xiaojuan MA, Гонконгский университет науки и технологии, Китай;
(4) Вэй Зенг, Гонконгский университет науки и технологии (Гуанчжоу), Китай.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)