

Поиск веб-поиска г-жи Марко: питание доступа к информации следующего поколения и нейронных индексеров
28 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предыстория и связанная с ним работа
2.1 Поиск информации в Интернете
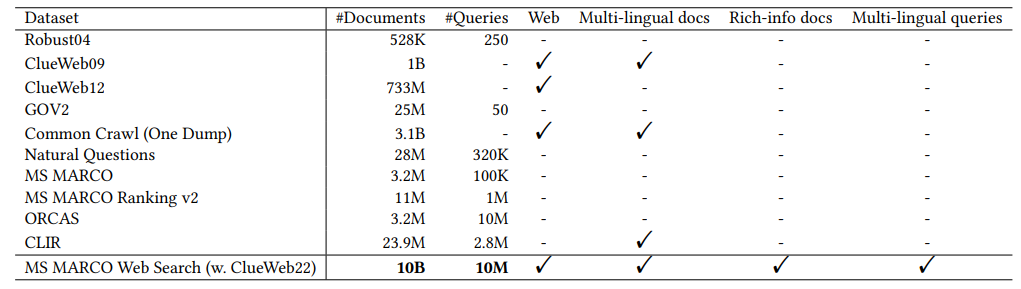
2.2 Существующие наборы данных
3 MS MS MARCO WEBEATET и 3.1 Подготовка документов
3.2 Выбор запроса и маркировка
3.3 Анализ наборов данных
3.4 Новые проблемы, поднятые MS Marco Web Search
4 базовые результаты и настройка среды 4.1
4.2 Базовые методы
4.3 Метрики оценки
4.4 Оценка моделей встраивания и 4.5 Оценка алгоритмов ANN
4.6 Оценка сквозной производительности
5 Потенциальные предубеждения и ограничения
6 Будущая работа и выводы, а также ссылки
АБСТРАКТНЫЙ
Недавние прорывы в крупных моделях подчеркнули критическую значимость шкалы данных, меток и модалов. В этой статье мы представляем веб-поиск MS Marco, первого крупномасштабного веб-данных, богатого информацией, включающим миллионы реальных меток запросов на клик. Этот набор данных тщательно имитирует реальные веб-документы и распределение запросов, предоставляет богатую информацию для различных видов нижестоящих задач и поощряет исследования в различных областях, таких как общие сквозные модели нейронных индексеров, общие модели встраивания и систему информационного доступа следующего поколения с большими языковыми моделями. MS Marco Web Search предлагает эталон поиска с тремя задачами по поиску веб -поиска, которые требуют инноваций как в области машинного обучения, так и в области исследования системы поиска информации. Как первый набор данных, который соответствует крупным, реальным и богатым требованиям к данным, веб -поиск г -жи Марко прокладывает путь для будущих достижений в области ИИ и системы. Набор данных веб-поиска MS Marco доступен по адресу: https://github.com/microsoft/msmarco-web-search.
1 Введение
Недавно крупная языковая модель (LLM), прорыв в области искусственного интеллекта, предоставила людям новый способ получить доступ к информации посредством интерактивного общения. Хотя он стал незаменимым инструментом для таких задач, как создание контента, семантическое понимание и разговорное ИИ, он все еще демонстрирует определенные ограничения. Одним из таких ограничений является тенденция модели производить галлюцинированный или изготовленный контент, поскольку она генерирует ответы, основанные на моделях, наблюдаемых в учебных данных, а не проверке фактической точности. Кроме того, он борется с обновлениями знаний в реальном времени, так как может предоставить информацию только до момента своего последнего обучения. Это делает его менее надежным для получения новейшей динамической информации. Следовательно, интеграция внешней современной базы знаний с большими языковыми моделями имеет первостепенное значение для повышения их производительности и надежности. Эта комбинация не только смягчает ограничения галлюцинации и обновления знаний, но и расширяет применимость модели в различных областях, что делает ее более универсальным и ценным. Следовательно, системы поиска информации, такие как поисковая система Bing [32], продолжают играть жизненно важную роль в новых информационных системах на основе LLM, таких как WebGPT [34] и New Bing [33].
Для современных систем поиска информации ядро представляет собой большую семантическую модель понимания, такую как модель нейронного индексера [51] или модель двойного встраивания [16, 20, 21, 38–40, 45, 46, 54], которая может захватывать намерения пользователей, а также богатые значения документа с лучшей устойчивостью к излишним словам, а также обозначениям и синониме. Обучение высококачественной большой семантической модели понимания требует огромного количества данных для достижения достаточного охвата знаний. Чем больше набор данных, тем лучше будет работать модель, поскольку модель может изучить более сложные и сложные модели и корреляции.
Высококачественные данные, меченные человеком, так же важны, как и шкала данных. Недавние исследования, такие как инструктирование [36] и Llama-2 [50], продемонстрировали решающую роль маркированных данных для обучения крупных моделей фундамента. Эти модели основаны на больших объемах учебных данных для изучения обобщаемых функций, в то время как данные, меченные человеком, позволяют модели изучать конкретные задачи, для которых она предназначена. Это также относится к большим моделям семантического понимания.
Кроме того, данные, богатые информацией, также имеют решающее значение для эффективного обучения моделей больших семантических понимания. Использование многомодальных наборов данных может помочь моделям понять сложные отношения между различными типами данных и передачи знаний между ними. Например, использование изображений и текста в многомодальном наборе данных может помочь моделям узнать о концепциях изображений и соответствующих описания текста, обеспечивая более целостное представление данных.
Новые крупные, реальные и богатые требования к данным мотивируют нас создать новый набор данных веб-поиска MS Marco, первый набор данных, богатый большим количеством данных, с миллионами реальных меток с реальным кликом. MS Marco Web Search включает в себя самый большой набор данных открытого веб -документа, ClueWeb22 [37], как наш корпус документа. ClueWeb22 включает в себя около 10 миллиардов высококачественных веб-страниц, достаточно больших, чтобы служить репрезентативными данными масштаба в Интернете. Он также содержит богатую информацию со веб-страниц, такую как визуальное представление, отображаемое веб-браузерами, необработанная структура HTML, чистый текст, семантические аннотации, языковые и тематические теги, помеченные в отраслевые системы понимания документов и т. Д. Поиск MS Marco. Дополнительно содержит 10 миллионов уникальных запросов из 93 языков с миллионами соответствующих маркированных запрашиваемых паров, собранных в поисково-подключаемой подбожности в поисково-подключном подбожности в области поискового подключения в поисково-подключном подбожности в области поискового подбора подборочного подбора This large collection of multi-lingual information rich real web documents, queries and labeled query-document pairs enables various kinds of downstream tasks and encourages several new research directions that previous datasets cannot well support, for example, generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models, etc. As the first large, real and rich web dataset, MS MARCO Web Search will serve as a critical data foundation for Будущее исследование ИИ и систем.
MS Marco Web Search предлагает эталон поиска, который реализует несколько современных моделей встраивания, алгоритмы поиска и системы поиска, первоначально разработанные на существующих наборах данных. Мы сравниваем качество их результатов и производительности системы в нашем новом наборе данных веб -поиска MS Marco в качестве базовых базовых показателей для поиска информации в Интернете. Результаты эксперимента показывают, что встраивание моделей, алгоритмы поиска и системы поиска являются важными компонентами в Интернете
поиск информации. И интересно, что простое улучшение только одного компонента может оказать негативное воздействие на сквозное качество результатов и производительность системы. Мы надеемся, что этот эталон поиска может облегчить будущие инновации в методах, ориентированных на данные, модели внедрения, алгоритмы поиска и системы поиска для максимизации сквозной производительности.
Эта статья есть
Авторы:
(1) Ци Чен, Microsoft Пекин, Китай;
(2) Xiubo Geng, Microsoft Пекин, Китай;
(3) Корби Россет, Microsoft, Редмонд, США;
(4) Кэролин Бурактаон, Microsoft, Редмонд, США;
(5) Jingwen Lu, Microsoft, Redmond, США;
(6) Тао Шен, Технологический университет Сидней, Сидней, Австралия, и работа была выполнена в Microsoft;
(7) Кун Чжоу, Microsoft, Пекин, Китай;
(8) Чеменский Сюн, Университет Карнеги -Меллона, Питтсбург, США, и работа была выполнена в Microsoft;
(9) Yeyun Gong, Microsoft, Пекин, Китай;
(10) Пол Беннетт, Spotify, Нью -Йорк, США, и работа была выполнена в Microsoft;
(11) Ник Красвелл, Microsoft, Redmond, США;
(12) Xing Xie, Microsoft, Пекин, Китай;
(13) Fan Yang, Microsoft, Пекин, Китай;
(14) Брайан Тауэр, Microsoft, Редмонд, США;
(15) Нихил Рао, Microsoft, Mountain View, США;
(16) Anlei Dong, Microsoft, Mountain View, США;
(17) Венки Цзян, Эт Цюрих, Цюрих, Швейцария;
(18) Чжэн Лю, Microsoft, Пекин, Китай;
(19) Mingqin Li, Microsoft, Redmond, США;
(20) Chuanjie Liu, Microsoft, Пекин, Китай;
(21) Зенчжонг Ли, Microsoft, Редмонд, США;
(22) Ранган Мадждер, Microsoft, Редмонд, США;
(23) Дженнифер Невилл, Microsoft, Редмонд, США;
(24) Энди Окли, Microsoft, Редмонд, США;
(25) Knut Magne Risvik, Microsoft, Осло, Норвегия;
(26) Харша Вардхан Симхадри, Microsoft, Бангалор, Индия;
(27) Маник Варма, Microsoft, Бенгалор, Индия;
(28) Юджин Ван, Microsoft, Пекин, Китай;
(29) Линджун Ян, Microsoft, Редмонд, США;
(30) Мао Ян, Microsoft, Пекин, Китай;
(31) CE Zhang, Eth Zürich, Zürich, Швейцария, и работа была выполнена в Microsoft.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)