Тестирование защищает от регрессии. Но самым важным продуктом тестирования является знание предметной области и мощные возможности.
Тестирование — важная, но часто игнорируемая практика машинного обучения. Создание системы машинного обучения без тестирования, скорее всего, приведет к плохим результатам в самый неподходящий момент — когда все флажки будут проверены, когда модель будет запущена в производство и когда затронуты реальные люди.
Это типичная (и правдивая) история тестирования в машинном обучении. Но эта история сплошь кнут, а не пряник. Он идеально подходит для наиболее важного продукта тестирования для команды данных, чтобы добиться прогресса: знания предметной области.
Проекты машинного обучения усложняются по мере продвижения от начальных стадий к зрелости. Каждая итерация в процессе разработки дает новые идеи, инициируя такие действия, как очистка данных, настройка модели или дополнительная маркировка. Эти действия могут быть добавленной стоимостью, но регресс в небольших карманах системы возникает, иногда незаметно. Тестирование защищает от этих регрессий.
Тестирование часто вызывает ощущение рутинной работы, что является хорошей практикой, но не всегда необходимой. Возникают классические вопросы, связанные с тестированием, например, что необходимо тестировать и насколько сложными должны быть эти тесты. Но рассмотрение тестов как процесса накопления и систематизации знаний в предметной области показывает, что тестирование не только храповиком, но и предотвращает откат назад.
Комбинированный взгляд на тестирование с другими видами деятельности по накоплению знаний, такими как анализ ошибок и аннотирование данных, способствует как научному прогрессу, так и хорошему инженерному делу. Аннотации, анализ ошибок и тестирование могут использоваться совместно, что приводит к объединению преимуществ в сторону повышения производительности системы и более глубокого понимания того, что моделируется. Автономные транспортные средства представляют интересную линзу для понимания этого, и методологии автономного вождения Tesla демонстрируют силу этой точки зрения.
Для обеспечения накопления знаний посредством тестирования требуется поддержка платформы. Платформенные команды должны стремиться к беспрепятственному взаимодействию при тестировании и других действиях. Разработчики инструментов в ландшафте MLOps должны поддерживать их в этом отношении, отдавая приоритет усилиям по интеграции, а не N-й функции. Недостаточно решить небольшую вертикальную часть рабочего процесса, если мы заботимся о долгосрочной ценности для пользователей платформы.
Тестирование — это накопление знаний
Тест модели — это утверждение, что модель должна вести себя определенным образом в каком-то сценарии. Технически сценарий определяется входными данными модели, будь то один образец или несколько.
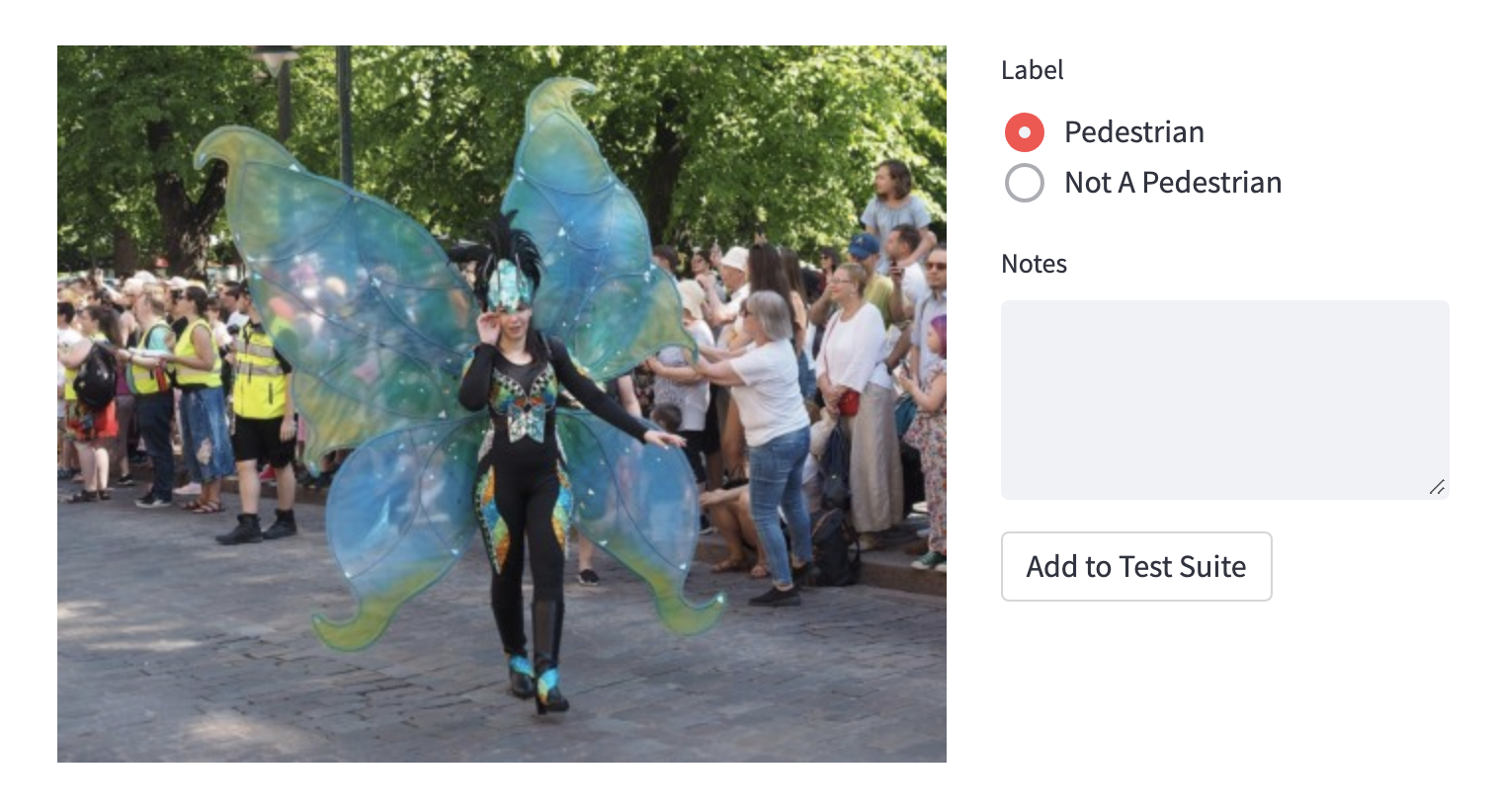
До того, как у вас будет тест, вы можете даже не знать, что сценарий существует. Возьмем модель автономного транспортного средства, которая обнаруживает пешеходов в поле зрения. Вам может не прийти в голову, что у пешеходов могут быть крылья, аномально длинные ноги или сверкающая одежда, пока не пройдете дорожное испытание во время парада с участием множества пешеходов в костюмах.
![Очень запутанный пример пешехода. Источник: Wikimedia Commons] (https://cdn.hackernoon.com/images/-uia3jtp.png)
(Автономные транспортные средства — отличный пример того, насколько важны испытания для безопасности ИИ.)
Узнать об этих странных случаях можно через опыт или неявное знание. Чтобы использовать неявные знания, их необходимо закодировать в системы.
Неявное кодирование знаний наиболее распространено, потому что оно удобно. Странный необъяснимый термин в уравнении или «волшебная» конфигурация, которая стабилизирует обучение модели, являются примерами неявного знания. Их авторы, возможно, знали, что они делают, но никто другой этого не знает. Это приводит к так называемым племенным знаниям.
Неявное кодирование не только вредно для совместной работы, но и препятствует накоплению рычагов, присущих технологиям. Явное кодирование позволяет другим учиться и опираться на эти знания. В примере с магическими тренировочными конфигурациями мы можем хранить тренировочные конфигурации в базе данных с примечаниями автора, которые ссылаются на результаты обучения. Позже товарищи по команде могут запрашивать конфигурации для многих экспериментов, чтобы найти те, которые работали лучше всего. Обучение и новое понимание становятся возможными благодаря простой организации и связыванию метаданных.
Написание тестовой функции test_for_winged_pedestrian() в некоторых файлах python упускает важную возможность для накопления полученных знаний. Крылатые пешеходы, если они должным образом организованы в таксономии понятий под пешеходами, оказывают влияние на несколько этапов рабочего процесса, помимо тестирования. Этот рычаг проявляется в построении запросов данных более высокого уровня. Пешеходы в костюмах — это концепция, которую сначала нужно поместить в контекст с другими концепциями:
Дорожный затор
├── Стационарный
│ ├── Дорожный конус
│ └── ...
└── Нестационарная
├── Пешеходный
│ ├── Средний пешеход
│ ├── Пешеход с опорой для ходьбы
│ └── Костюмированные пешеходы
├── Велосипедист
Теперь представьте ситуацию, когда «пешеходы» в качестве целевого ярлыка модели могут страдать от производительности. Пешеходы в костюмах, а также пешеходы с тростями или ходунками, водители скутеров и другие движущиеся препятствия могут быть ценными понятиями для использования в запросе, возможно, для понимания того, почему модель обнаружения пешеходов может дать сбой, или для выявления непомеченных примеров для дальнейшей маркировки. . Первым шагом к реализации этого является признание того, что тестовые примеры, маркировка и анализ ошибок — это разные аспекты одного и того же: накопление знаний в предметной области.
Тестирование в рабочем процессе
В нашем примере техник, едущий на дорожное испытание, может заметить ошибку на экране своего ноутбука, когда это произойдет. Или ученый, проводящий анализ ошибок модели, может заметить это позже. Аннотатор может найти его, когда будут помечены новые данные дорожного испытания. Это может даже произойти из-за сбоя другого теста в конвейере подготовки данных.
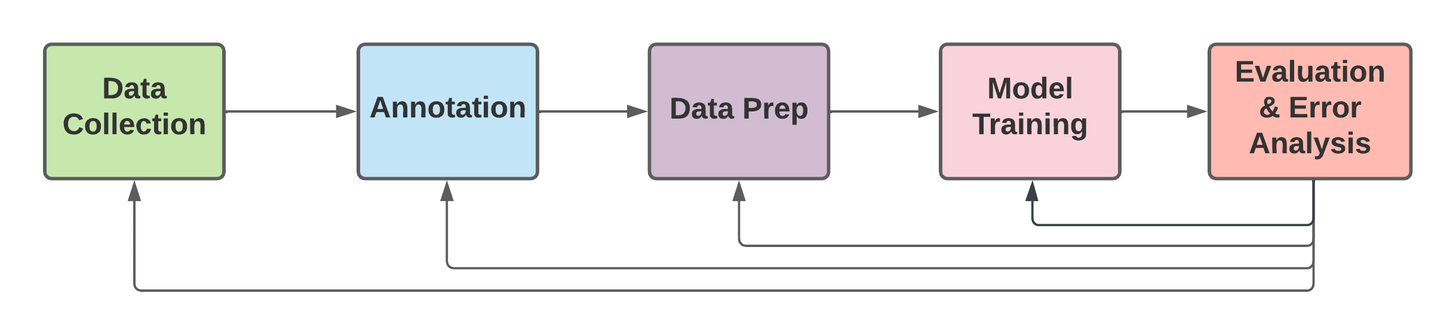
Существует множество инструментов для выполнения каждого шага рабочего процесса, но часто эти инструменты плохо интегрируются. Предполагаемый опыт не учитывал шаги до и после, что приводило к трениям и снижало общую эффективность. Хорошая платформа будет смешивать швы между различными этапами, предоставляя разработчику единый опыт работы.
Если обнаружена проблема с точкой данных в аннотации, представьте себе возможность разместить кнопку с надписью «Добавить в набор тестов» непосредственно в инструменте аннотации.
Если проблема возникает во время конвейеров сбора или подготовки данных, у разработчиков должно быть что угодно, от pytest до полноценного инструмента, такого как [Большие ожидания] (https://greateexpectations.io/), для быстрого добавления тестового примера.
```питон
@концепция(
'road_obstruction', 'не_стационарный', 'пешеход', 'одетый_пешеход')
защита test_pedestrians_with_costumes():
image_ids = [232214, 1234832, 89542543]
images_and_neighbors = [
сосед для соседа в get_nearest_neighbors(image_id, k=5)
для image_id в image_ids] + image_ids
правильно = все(
get_pred(image_id) == get_label(image_id)
для image_id в images_and_neighbors)
вернуть правильный
Выше: Пример тестовой функции. Подобный код будет храниться вместе с кодом конвейера в репозитории git. Обратите внимание на декоратор, который связывает тест с концепцией.
Эти интерфейсы упрощают разработчику добавление теста, снижая вероятность регрессии модели и создавая основу для обмена знаниями.
Практический пример: автопилот Tesla
Андрей Карпати описывает рабочие процессы и возможности внутренней платформы, позволяющие разрабатывать автономные транспортные средства, которые в значительной степени зависят от просмотра маркировки, тестирования и анализа ошибок в одном и том же представлении.
![Описание операции «Отпуск» — процесса, с помощью которого команда самоуправляемых автомобилей Tesla собирает и улучшает свои данные посредством маркировки и тестирования. Взято из выступления Андрея Карпати в 2020 году «ИИ для полного самостоятельного вождения в Tesla».] (https://cdn.hackernoon.com/images/-67d3jyu.png)
Для новой задачи обнаружения объектов они создают начальный набор изображений и выбирают некоторые из них в качестве модульных тестов. По мере итерации команды по продукту и маркировке улучшают свои тесты и создают новые. Остальная часть процесса повторяется до тех пор, пока тесты не пройдут.
Как упоминает Карпати, путеводной звездой для его команды является «Операция «Отпуск» — идея о том, что задачи беспилотного вождения должны улучшиться, даже если вся команда компьютерного зрения отправится в отпуск. Реализация этого процесса означает, что платформа поддерживается моделью данных, связывающей метаданные вокруг тестирования, маркировки и прогнозирования модели.
Совокупность результатов накопления знаний
Когда тестовые примеры сформулированы, они также помечаются. Если тестовый сценарий существенно влияет на производительность, аналогичные образцы могут быть добыты для дополнительной маркировки. Если инструмент маркировки упрощает добавление новых тестовых случаев, то у нас есть эффективный процесс для расширения наших знаний о тестовом сценарии.
Эти преимущества усугубляются при рассмотрении этого процесса для большого количества тестовых сценариев. Если бы наша модель когда-то была чувствительна к условиям освещения, у нас могло бы быть понятие «дневной свет» или «время суток». Мы также можем предположить, основываясь на интуиции, что обнаружение велосипедистов — это полезный шаг к обнаружению пешеходов в костюмах. Затем мы можем построить запрос для полезных примеров обнаружения пешеходов:
```питон
из инструментов импортировать soft_intersection
определить запрос (...):
costumed_pedestrians = ...
велосипедисты = ...
время_дня = ...
пешеходы_like_bicyclists = soft_intersection(
costumed_pedestrians, велосипедисты, порог = 0,9)
возврат (
пешеходы_like_велосипедисты
и (time_of_day == 'вечер'))
Или представьте визуальный компонент запроса, чтобы упростить построение частей приведенного выше запроса:
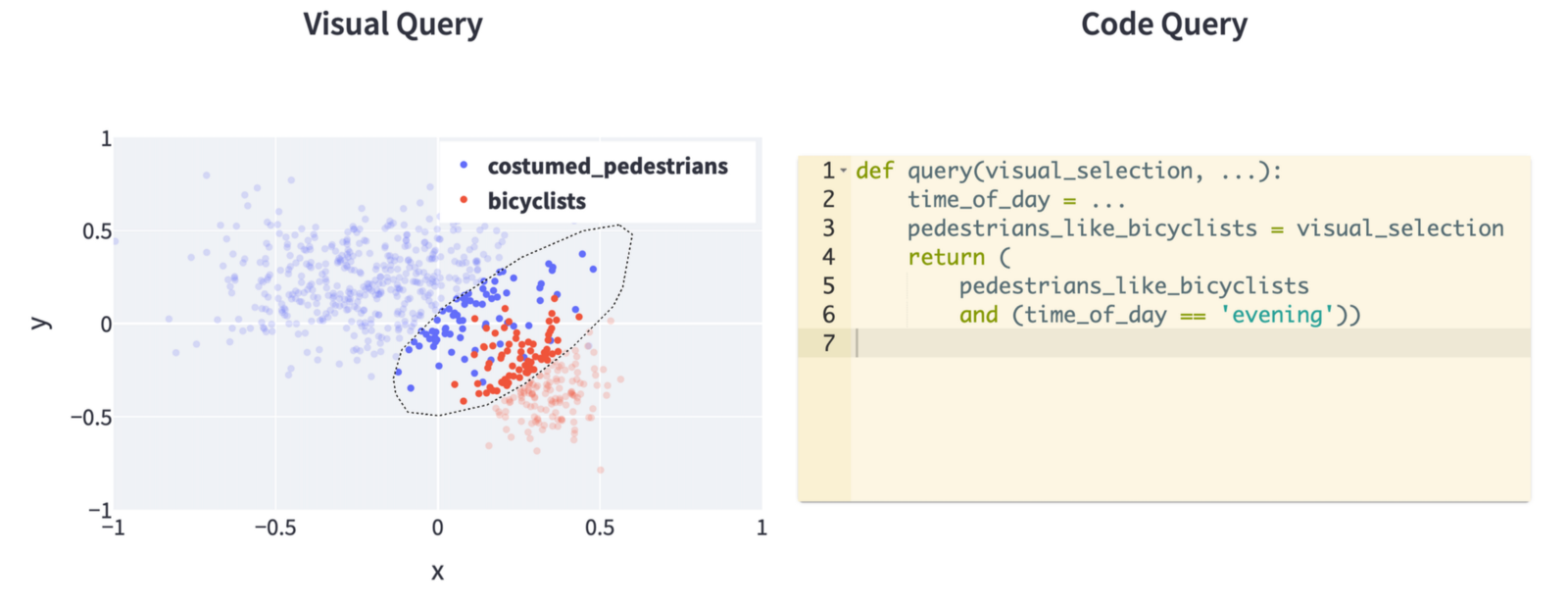
Две вещи дают совокупный выигрыш: удаление швов для удобства использования и трата времени на явную организацию знаний. Команда разработчиков беспилотных автомобилей Tesla демонстрирует эти преимущества с помощью концепции «триггеров» для запроса данных о клиентах для маркировки.
![Примеры триггеров, используемых командой разработчиков беспилотных автомобилей Tesla для получения данных для маркировки. Взято из выступления Андрея Карпатого на CVPR 2021] (https://cdn.hackernoon.com/images/-oif3j69.png)
Разработка этих запросов требует явно закодированных знаний предметной области. Некоторые триггеры требуют понимания концепций разработки автономных транспортных средств, таких как разница между радаром и зрением или определение ограничивающей рамки. Другие триггеры используют концепции реального мира, такие как стоп-сигналы, дороги и то, что представляет собой крыша автомобиля. Многие полагаются на оба типа концепций вместе для реализации триггера. Без определений для этих понятий более низкого уровня построение запросов для этих понятий более высокого уровня (триггеров) было бы довольно сложным.
Платформы для развития знаний
Для накопления знаний в рамках различных действий по разработке требуется платформа с единой моделью данных. Унификация является ключом к получению совокупных выгод от знаний в предметной области.
Но создание платформы является сложной задачей по более фундаментальным причинам. Широта требуемой функциональности огромна, а приоритеты функций различаются в зависимости от вариантов использования, команд и компаний. Инструменты с открытым исходным кодом и поставщики для MLOps помогают в определенной степени, но недавние настроения [указывают на ощущение фрагментации] (https://www.mihaileric.com/posts/mlops-is-a-mess/). Платформенным командам необходимо работать с большим количеством инструментов, управлять несколькими поставщиками и строить в течение длительного времени (иногда лет), пока их усилия не будут полностью реализованы.
Команды платформ иногда отдают приоритет крупным инфраструктурным проектам при обучении и развертывании в производственной среде, чтобы минимизировать время выхода на рынок. Хотя это может быть разумной краткосрочной стратегией, она рискует нарастить импульс в неоптимальном направлении.
Команды, работающие над платформами, также могут извлечь выгоду из размышлений о накоплении знаний. Самые большие успехи в системах машинного обучения часто связаны с лучшим пониманием проблемы. Новые знания обнаруживаются в процессе итерации, поэтому главной целью платформы должна быть сквозная эффективность. Низко висящие плоды в рабочем процессе можно наблюдать только при работающем механизме разработки. Платформенные команды должны запускать этот движок любыми средствами, чтобы не попасть в ловушку преждевременной оптимизации. И это может исключить мощную инфраструктуру для запуска.
Думая в первую очередь о фреймворках и моделях данных, можно добавить соответствующую инфраструктуру для максимальной эффективности. Не стоит иметь масштабируемые вычисления на GPU или задержку обслуживания менее миллисекунды, если проблемы с производительностью коренятся в данных или неправильном понимании модели.
Инструменты MLOps также могут сыграть свою роль. Создатели инструментов в индустрии MLOps, как правило, сосредотачиваются на вертикальных срезах вариантов использования разработки или развертывания. В то время как это снижает риск запуска продукта, пользователи страдают в долгосрочной перспективе, оказывая давление на команды разработчиков платформы для интеграции. Накладные расходы огромны — каждый инструмент имеет свой собственный язык, выраженный через его пользовательский интерфейс, API и форматы данных.
Инструменты, которые легко взаимодействуют и стремятся к согласованному опыту, приносят больше пользы своим клиентам (как командам платформы, так и разработчикам, которых они обслуживают) в долгосрочной перспективе. Интеграция — это именно то, что команды рабочих платформ должны делать снова и снова, за исключением специальных функций, которые способствуют конкурентному преимуществу их компании. Если разработчики инструментов заботятся о том, чтобы обеспечить долгосрочную ценность для своих клиентов, они должны отдавать приоритет усилиям по интеграции, а не постепенной разработке функций.
В обозримом будущем платформы будет сложно создавать. Но такие компании, как Tesla, создают ИИ мирового класса, потому что их платформы позволяют разработчикам ИИ узнавать об их предметной области, понимать их модели и кодировать полученные знания в своих системах. Независимо от нашей роли в создании систем ИИ, ясно одно: создание знаний является основой разработки ИИ. На первый взгляд тестирование может показаться неважным, но понимание его как первоклассного средства накопления знаний показывает, что оно имеет решающее значение для успешного развития ИИ.
- Находите эти идеи интересными? Приходите пообщаться с нами в Twitter! @hoddieot @skylar_b_payne или подпишитесь на Data Chasms .*
Также опубликовано [Здесь] (https://datachasms.substack.com/p/model-testing-builds-critical-domain-knowledge?s=w)