Обучение модели классификации изображений в Azure без локального хранения данных с помощью Dagshub Direct Data Access и Azure ML SDK
Введение
Машинное обучение и искусственный интеллект стали повсеместными, и один из ключевых навыков Data Scientist – умение создавать масштабируемые модели, работать с конфиденциальными данными, а также создавать надежные конвейеры данных и моделей , которые воспроизводимы. Хотя облачные технологии позволяют нам создавать масштабируемые конвейеры, нам необходимо хранить все файлы в нашем облаке, прежде чем мы сможем использовать их для обучения моделей, требующих затрат ресурсов графического процессора и времени для извлечения данных.
В этой статье мы собираемся обучить модель в Azure с данными, хранящимися в Dagshub Repo, используя Прямой доступ к данным (DDA) от Dagshub, которая позволяет нам извлекать данные пакетами, когда это необходимо, что сокращает время, необходимое для извлечения и хранения данных на Благодаря Azure также снижается стоимость графического процессора.
Мы будем использовать Azure ML SDK, чтобы создать задание обучения прямо с нашего локального компьютера и отправить его в Azure. Мы также увидим, как мы можем контролировать работу прямо из нашего jupyter-notebook.
Мы будем использовать данные исследования Kaggle, Mayo Clinic — STRIP AI, где основное внимание уделяется дифференциации двух основных подтипов этиологии острого ишемического инсульта (ОИС): сердечный атеросклероз и атеросклероз крупных артерий. Выявление этиологии инсульта может помочь врачам смягчить последствия повторных инсультов.
Код и данные, использованные в этом анализе, можно найти здесь.
О данных
Исходно данные для задания представлены в формате tiff и имеют размер 356 ГБ. Для целей этого анализа мы уменьшаем изображения и сохраняем их в формате png. Код для такого масштабирования данных можно найти здесь. Уменьшенные изображения можно найти здесь. Чтобы сопоставить изображения с классами, к которым они принадлежат, данные о соревнованиях предоставляют нам файл CSV, который содержит информацию о данных. Эти данные можно найти здесь.
Столбец «метка» в наборе обучающих данных состоит из принадлежащих изображений классов. Папка данных поезда состоит из 754 изображений, из которых 547 относятся к классу CE (сердечные) и 207 относятся к классу LAA (атеросклероз крупных артерий). Для нашего анализа мы создали столбец с именем «int_labels», которому присваивается значение 1, если изображение принадлежит к классу «LAA», в противном случае ему присваивается значение 0.
Подход
Чтобы использовать Azure для обучения наших моделей, мы будем использовать Azure ML SDK и запускать наш код в Azure. Это потребует от нас создания рабочей области машинного обучения и вычислений на GPU в Azure. Как правило, мы также загружаем наши данные в хранилище Azure и создаем хранилища данных, чтобы рабочая область машинного обучения могла получить доступ к нашим данным. Мы не собираемся хранить данные в Azure, а вместо этого будем передавать данные из репозитория Dagshub.
Чтобы настроить Azure Workspace и создать вычисление с помощью Azure ML SDK, см. здесь.
Dagshub называют «Github для машинного обучения», поскольку он позволяет нам не только поддерживать наш код, но и обеспечивает контроль версий наших данных.
Контроль версий данных (DVC) позволяет нам отслеживать изменения в больших файлах данных подобно тому, как Git помогает нам отслеживать изменения в нашем коде. Чтобы включить DVC, мы можем использовать любое облачное хранилище, такое как AWS, GCP и Azure, что может быть дорого. Подобно тому, как мы выполняем git pull для получения последней версии кода из Git, мы делаем dvc pull для получения данных, версии которых контролируются с помощью DVC. Подобно командам Git, у нас также есть команды dvc push, pull и commit.
Для этого проекта я создал репозиторий на Dagshub и загрузил все свои файлы данных и код. Все файлы и папки, использующие DVC, отмечены в репозитории как DVC.
n 
После отправки данных в Dagshub мы создадим сценарии, которые будут использовать функцию потоковой передачи из DDA для извлечения данных из репозитория без необходимости выполнять извлечение dvc, что может занять больше времени.< /p>
Потоковая передача данных с использованием прямого доступа к данным Daghub
Традиционно, если мы хотим построить модель или прочитать данные, которые присутствуют в любой системе управления версиями данных — , мы извлекаем все имеющиеся файлы данных. Но во многих случаях нам не нужны все имеющиеся файлы, а извлечение больших файлов может занять много времени, а также затратить время процессора/графического процессора. Чтобы избежать этого, Dagshub представил Streaming API, который является частью функции прямого доступа к данным (DDA) Dagshub.
pip install dagshub # Install the Dagshub package for DDA.
Затем мы клонируем DagshubRepo с помощью библиотеки Gitpython.
## Cloning the Repo
git_url="https://"+DAGSHUB_USER_NAME+":"+DAGSHUB_TOKEN+"@dagshub.com/"
+DAGSHUB_USER_NAME+"/"+DAGSHUB_REPO_NAME+".git"
import git
git.Git().clone(git_url)
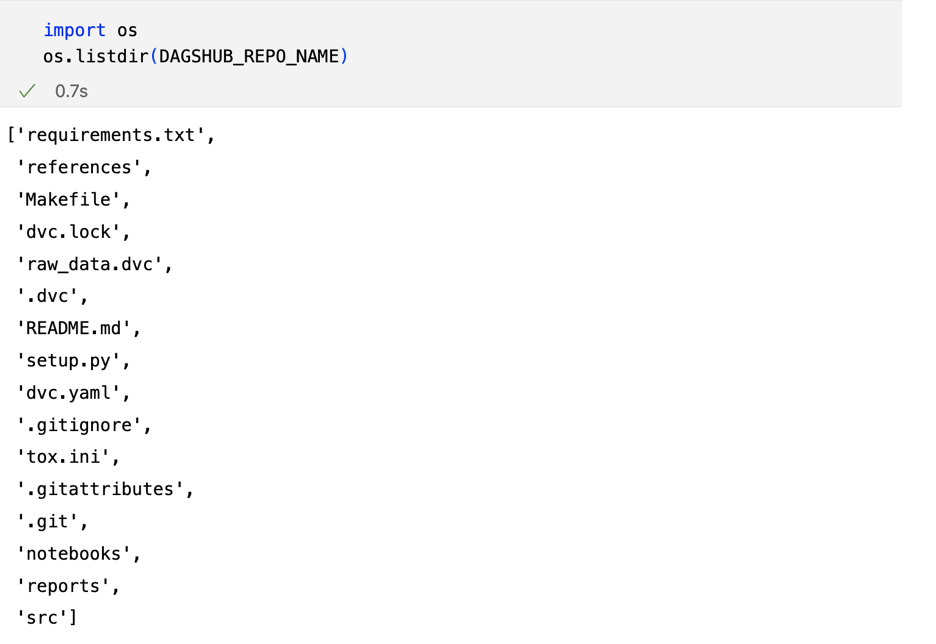
После того как вы клонируете репозиторий, вы сможете увидеть репозиторий в своей локальной системе, но вы не найдете в репозитории папки с версиями, использующими DVC (папка данных и моделей).
Есть два способа использования потокового клиента.
Облегченные хуки только для Python, которые могут автоматически обнаруживать вызовы встроенных файловых операций Python, таких как open(), listdir(), и совместимы с большинством библиотек Python ML. используя install_hooks(), можно просто получить доступ к файлу, как если бы он был сохранен на самом локальном компьютере.
from dagshub.streaming import install_hooks
import pandas as pd
install_hooks(DAGSHUB_REPO_NAME,password=DAGSHUB_TOKEN)
train_data=pd.read_csv(DAGSHUB_REPO_NAME+"/data/raw/train.csv")
train_data.shape
Используя этот метод, когда мы используем os.listdir(), мы можем видеть данные и папку моделей, которые также имеют версию DVC.
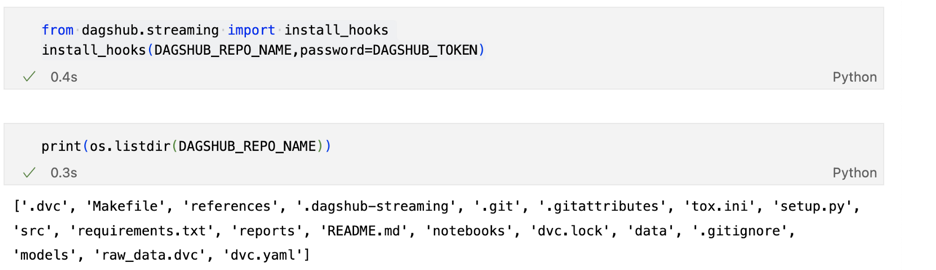
При вызове install_hooks() мы видим, что папки «data» и «models» видны с помощью os.listdir()
Этот метод может не работать с Tensorflow и OpenCV , поскольку у них есть фреймворки ввода/вывода, написанные на низкоуровневом языке, таком как C/C++, которые необходимо обрабатывать по-другому по сравнению с библиотекой, такой как Pytorch. В таких случаях вы можете использовать потоковую передачу файлов, загрузив файловую систему Dagshub.
Потоковая передача файлов с помощью DDA так же проста, как загрузка файловой системы Dagshub.
from dagshub.streaming import DagsHubFilesystem
fs = DagsHubFilesystem(project_root=DAGSHUB_REPO_NAME,username=DAGSHUB_USER_NAME,
password=DAGSHUB_TOKEN)
Затем мы можем заменить любое использование open(), os.stat(), os.listdir() и os.scandir() на fs.open(), fs.stat(), fs.listdir() и fs. .scandir() соответственно. Используя fs.listdir(), теперь мы видим, что папки с данными и моделями присутствуют, даже если их нет на нашем компьютере.
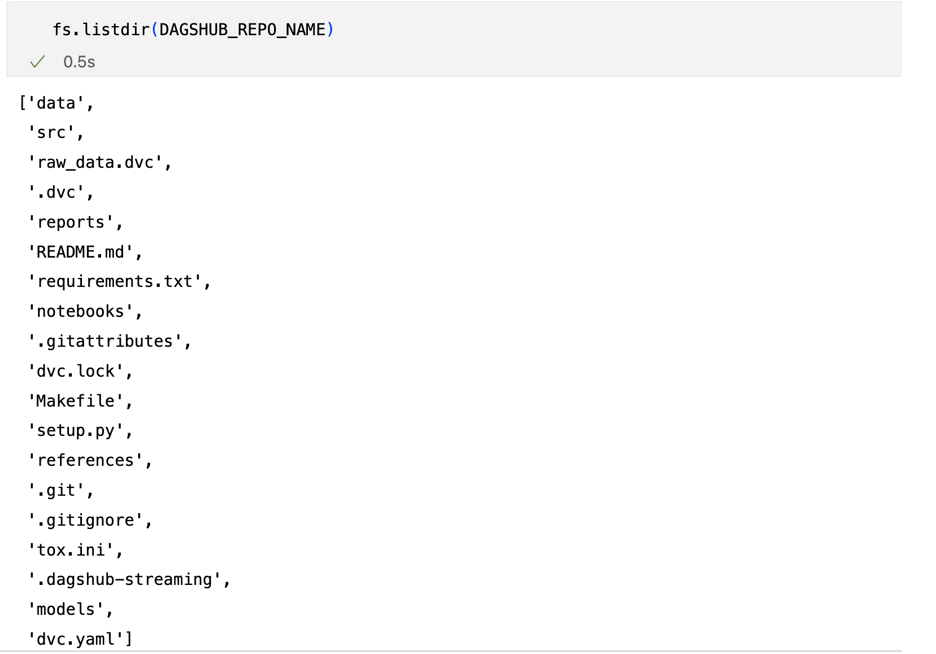
В качестве проверки давайте воспользуемся и fs, и os для вывода списка файлов в каталоге. Как мы видим ниже, мы не можем получить доступ к папкам данных при использовании os , что означает, что мы получаем доступ к файлам, которые находятся в Dagshub Repo, используя функцию потоковой передачи
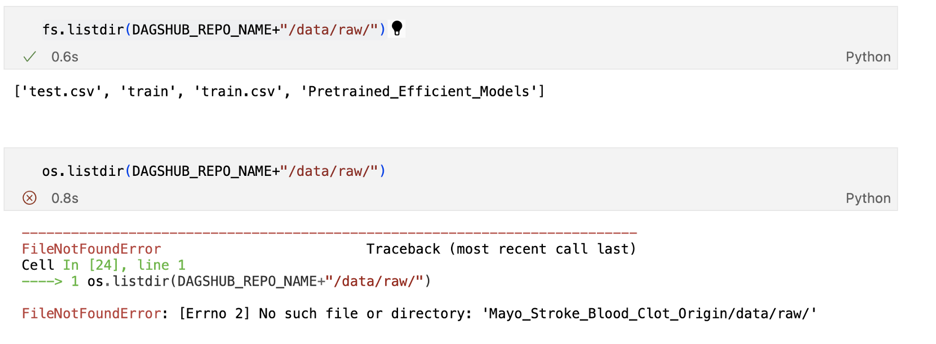
Чтобы прочитать, скажем, файл train.csv, который находится в папке data/raw/, мы можем использовать функцию открытия

Когда вы открываете файл, он сохраняется в кэше на вашем локальном компьютере и, следовательно, будет виден при использовании функции os.listdir().
Открытый файл train.csv сохраняется в кеше и становится видимым в репозитории в локальной системе
Основное преимущество использования функции потоковой передачи заключается в том, что вы не загружаете все файлы сразу, а получаете доступ только к тем файлам, которые вам нужны. Это означает, что нам не нужно ждать, пока загрузятся все файлы, прежде чем мы начнем обучение наших моделей, что сэкономит время и ресурсы графического процессора.
n Визуализируйте изображения с помощью DDA
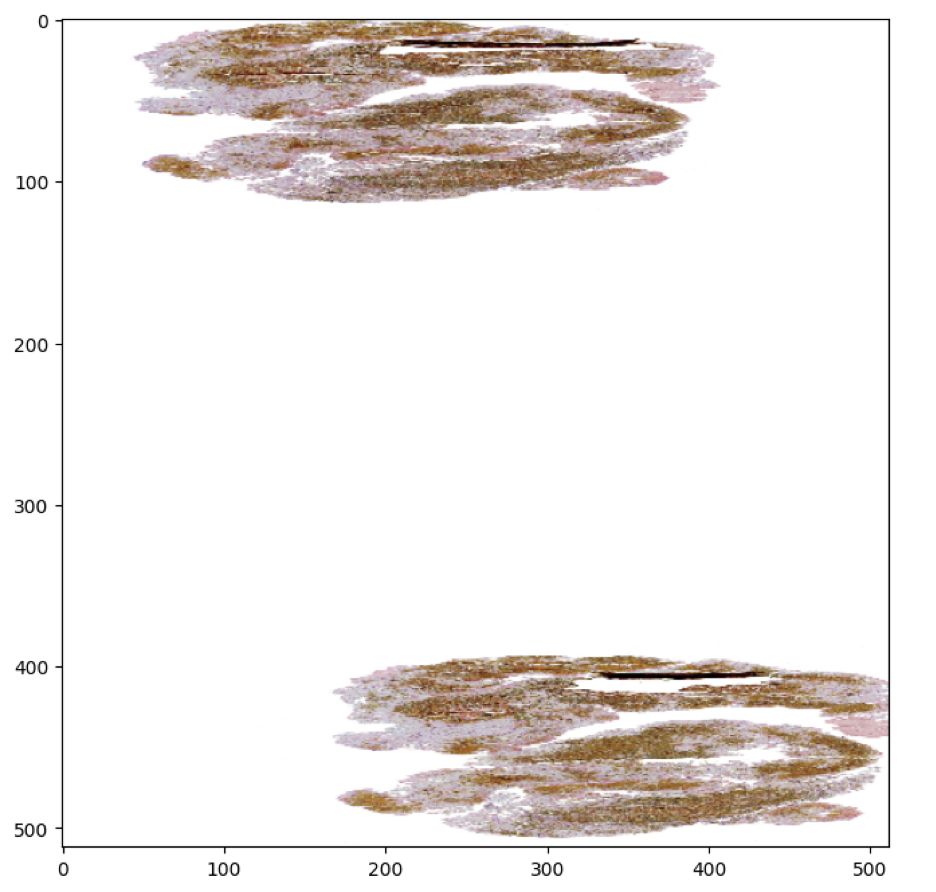
Мы создаем функцию show_image, которая принимает изображение и клиент потоковой передачи в качестве входных данных и считывает изображения — преобразовывает их в (512 512) изображений, а также переворачивает их по горизонтали. Здесь мы используем fs.open() для кэширования файла в нашей локальной системе, а затем используем функцию im.read() для чтения изображения.
## Code to visualise Images - by reading the image from Dagshub
import cv2
import matplotlib.pyplot as plt
def show_img(fs,img_id):
IMAGE_FOLDER=DAGSHUB_REPO_NAME+"/data/raw/train/"
img_path = os.path.join(IMAGE_FOLDER, '{}.png'.format(img_id))
print(img_path)
#slide = Image.open(img_path)
fs.open(img_path) ## This will cache the image
slide = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
img=cv2.resize(slide,(512,512))
print(type(slide))
size = slide.shape
print(size)
#region = slide.read_region((0, 0), 0, size)
flipHorizontal = cv2.flip(img, 1)
plt.figure(figsize=(8, 8))
plt.imshow(flipHorizontal)
plt.show()
show_img(fs,"008e5c_0")
 Создание сценариев для обучения моделей классификации изображений в Azure
Создание сценариев для обучения моделей классификации изображений в Azure
Первым шагом для обучения модели в Azure является создание собственной рабочей области и вычислений. Это можно сделать с помощью Azure ML SDK (см. здесь) или перейдите на portal.azure.com и создайте рабочую область. Чтобы обеспечить воспроизводимость — я создал свою рабочую область и вычислительные кластеры с помощью Azure ML SDK.
Следующим шагом будет создание скриптов на Python, которые будут использоваться для обучения. Все используемые сценарии следует поместить в ту же папку, в которой эта папка будет загружена в Azure.
## Creating Script Folder to store all the scripts that are needed to run job on Azure
import pathlib
script_folder="../src/azure_ml_scripts"
pathlib.Path(script_folder).mkdir(parents=True,exist_ok=True)
print(script_folder)
n В папке сценариев — поскольку мне нужен доступ к Dagshub Repo, я создаю dagshub_config.py, который содержит имя пользователя Dagshub, токен и имя репозитория.Токен должен храниться в секрете и не должны передаваться.
util.py , содержащий код для создания клиента потоковой передачи, клонируйте git, перечислите изображения в обучающей папке с помощью потоковой передачи данных, прочитайте фрейм данных train.csv и разделите данные на обучающие и тестовые наборы и функцию для загрузки модели EfficientNet с помощью потоковой передачи данных.
Теперь последний и окончательный сценарий (train.py) , где все происходит волшебство. Для обучения модели классификации изображений мы используем класс ImageDataGenerator, но для этого необходимо, чтобы файлы присутствовали в системе. Поскольку мы собираемся использовать клиент потоковой передачи для чтения изображений, а также файл train.csv для получения имени файла изображения и класса, а также создадим Custom DataGenerator, который будет считывать изображения партиями. из Dagshub Repo, используя функцию потоковой передачи.
Мы будем использовать модель EfficientNet B5 для прогнозирования тромбов. EfficientNet позволяет систематически масштабировать модели CNN, уравновешивая глубину, ширину и разрешение сети. Мы сохранили эту модель в «data/raw/Pretrained_Efficient_Models» в репозитории, который содержит несколько моделей EfficientNet.
Но поскольку нам нужна только модель B5, мы считываем веса только этой модели. Это возможно благодаря потоковому API , иначе нам придется загрузить всю папку, а затем прочитать этот конкретный файл.
def download_EfficientNet(fs,model_filename):
'''
This function will download the model file into local system and return the path.
'''
fs.open(os.path.join(EFFICIENT_NET_MODEL_PATH,model_filename))
return os.path.join(EFFICIENT_NET_MODEL_PATH,model_filename)
efficientWeight=download_EfficientNet(fs,'efficientnet-b5_tf24_imagenet_1000_notop.h5')
Изменение размера изображения до (512 512) и создание генератора данных проверки и обучения с помощью нашего CustomDataGenerator также определены в нашем скрипт обучения. Мы отслеживаем показатели модели с помощью MLFlow в Azure, чтобы отслеживать показатели с помощью mlflow.autolog().
n Создание среды и запуск сценария в Azure
Теперь, когда у нас есть готовые сценарии, нам нужна среда в Azure, в которой мы можем запустить наш сценарий — это означает установку наших библиотек и других зависимостей. Хотя мы можем создать собственную среду с пакетами conda и pip, мы также можем использовать специализированные среды.
В этом случае я создал свою собственную среду, используя существующий образ докера с установленной CUDA.
## Creating Environment using CUDA docker image and installing dependencies
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment('blood-clot-env')
conda_dep = CondaDependencies()
conda_dep.add_conda_package("scikit-learn==0.22.2.post1")
for package in ['azureml-dataset-runtime[pandas,fuse]',
'azureml-defaults',
'dagshub',
'GitPython','opencv-python-headless','Pillow','mlflow']:
conda_dep.add_pip_package(package)
other_pip_packages=['azureml-core==1.45.0' ,'azureml-defaults==1.45.0' ,
'azureml-mlflow==1.45.0' ,
'azureml-telemetry==1.45.0' ,
'tensorboard~=2.7.0' ,
'tensorflow-gpu~=2.7.0' ]
for package in other_pip_packages:
conda_dep.add_pip_package(package)
env.python.conda_dependencies=conda_dep
## Loading the Dockr Image with CUDA
env.docker.base_image = (
"mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.2-cudnn8-ubuntu20.04:20220902.v1"
)
# Register environment to re-use later
env.register(workspace = ws)
# Save the environment
env.save_to_directory("Environment/",overwrite=True)
Следующим шагом будет создание эксперимента. Думайте об эксперименте как о папке, в которой организованы ваши задания. Затем мы создаем объект ScriptRunConfig. Вы можете рассматривать ScriptRunConfig как конфигурацию для сохранения всех сведений, необходимых для запуска задания в Azure.
## Creating an Experiment and ScriptRunConfig to save details of the job to run on Azure
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
experiment_name = 'blood-clot-classification-mlflow'
exp = Experiment(workspace=ws, name=experiment_name)
src = ScriptRunConfig(source_directory=script_folder,
script='train.py',
arguments=None,
compute_target=gpu_cluster,
environment=env)
n Чтобы запустить задание в Azure, мы отправляем эксперимент с объектом ScriptRunConfig и отслеживаем ход выполнения прямо из нашей записной книжки с помощью виджета RunDetails.
Мы можем отслеживать метрики из нашего блокнота, используя run.get_metrics()

Мы видим, что модель достигла точности проверки 0,75 и точности обучения 0,76.
Мы также можем скачать сохраненную модель с помощью run.download_files().
## Download the model folder saved after training into our local system
run.download_files(output_directory="outputs/efficientNet_Model")
Ой!! Но что, если я хочу записать метрики в файл и отправить его в свое репозиторий Dagshub — нужно ли мне извлекать все данные, а затем отправлять их??
СЮРПРИЗ!!!
Dagshub представил функцию загрузки как часть функции DDA, которая позволит нам загружать наши файлы в наш репозиторий без необходимости выполнять извлечение.
## Uploading files to Dagshub Repo using upload() functionality of DDA
from dagshub.upload import Repo
repo = Repo(DAGSHUB_USERNAME,DAGSHUB_REPO_NAME,branch="main",
username=DAGSHUB_USERNAME,token=DAGSHUB_TOKEN)
repo.upload(file="../metrics.txt",path="efficientNet_Metrics.txt",
commit_message="Updating Metrics File",versioning="dvc")
ВУАЛЯ!!! Файл загружается в Dagshub Repo с управлением версиями DVC.
n Подведение итогов…
В этой статье мы увидели, как можно развернуть наш код в Azure, а также обучить модель, не тратя много времени на перенос данных в Azure.
Хотя я взял пример классификации изображений, чтобы показать, как мы можем объединить облачные технологии, такие как Azure, с функцией DDA Dagshub, это можно распространить и на другие типы данных , например, на типы данных аудио или видео. Как правило, видеофайлы имеют большой размер и часто занимают много места для хранения, а извлечение их каждый раз может занять много времени.
Интересно, что использование функции потоковой передачи не ограничивается только моделями глубокого обучения, но также может использоваться, когда у вас есть данные из нескольких таблиц, хранящихся в виде файлов, которые часто обновляются, и для вашего анализа требуется всего несколько файлов — при таком использовании данных потоковой передачи можно не скачивать все файлы, а также просто перезапустить скрипт, чтобы получить обновленные результаты.
Используя Azure, мы можем создать собственную среду со своими зависимостями, не имея большого опыта работы с контейнерами Docker. Кроме того, для тех, кто привык к Python Azure ML SDK дает нам возможность запускать наши модели в Azure, даже не выходя из знакомой среды jupyter-notebook.
н