Дни, когда ChatGPT был единственным решением в индустрии искусственного интеллекта, давно прошли. На поле вышли новые игроки, такие как LLaMA и Gemini, разработанные Meta и Google соответственно. Несмотря на разные инструменты и реализации, у них есть общее: они имеют закрытый исходный код (за некоторыми исключениями для LLaMA) и находятся под контролем крупных технологических компаний.
В этой статье рассматривается новый претендент в индустрии искусственного интеллекта, который может похвастаться инструментом с открытым исходным кодом, который превосходит ChatGPT 3.5 и может запускаться локально. Мы также научимся использовать его без цензуры и обучать на наших собственных данных.
Представляем Мистраль 8x7B
Mistral — французский стартап, основанный бывшими исследователями Meta и DeepMind. Используя свои обширные знания и опыт, они успешно привлекли инвестиции на сумму 415 миллионов долларов США, в результате чего оценка Mistral достигла 2 миллиардов долларов США.
Команда Mistral начала набирать обороты, когда они разместили на X торрент-ссылку на свою новую модель Mistral 8x7B. Согласно лицензии Apache 2.0, эта модель не только более мощная, чем LLaMA 2 и ChatGPT 3.5, но и полностью открыта.
Мощь и возможности Mistral
- Обрабатывает контекст из 32 тысяч токенов.
* Работает на английском, немецком, испанском, итальянском и французском языках.
* Демонстрирует отличную производительность при генерации кода.
* Может быть преобразована в модель следования инструкциям.
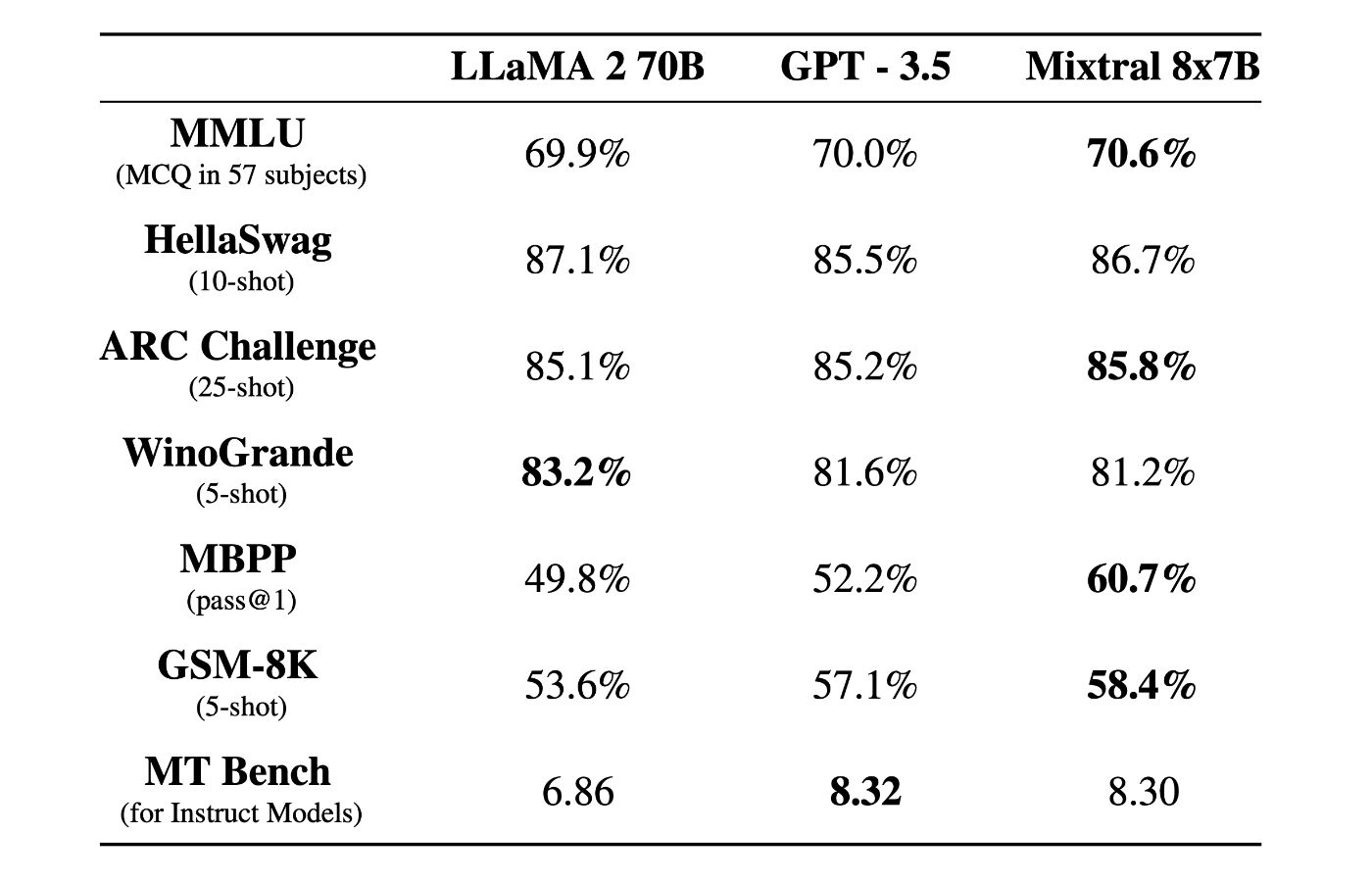
В тестах Mistral продемонстрировал выдающуюся мощность, превзойдя LLaMA 2 70B в большинстве тестов, а также совпав или превзойдя ChatGPT 3.5 в других тестах.
Локальный запуск Mistral
Не ограничиваясь цифрами и таблицами, давайте перейдем к практике. Во-первых, нам понадобится инструмент, который поможет нам запустить его локально: Ollama. Пользователи MacOS могут загрузить файл здесь. Для пользователей Linux или WSL вставьте в терминал следующие команды:
curl https://ollama.ai/install.sh | sh
Затем мы можем запускать LLM локально, но мы не просто стремимся к тому, чтобы ИИ отвечал на случайные вопросы — для этого и нужен ChatGPT. Мы стремимся к созданию искусственного интеллекта без цензуры, который можно будет настраивать в соответствии с нашими предпочтениями.
Учитывая это, мы будем использовать dolphin-mistral, специальную версию Mistral, которая снимает все ограничения. Чтобы узнать больше о том, как dolphin-mistral устранил эти ограничения, прочтите эту статью от ее создателя.
Выполните следующую команду в своем терминале, чтобы запустить Ollama на своем компьютере:
ollama serve
Затем в другом терминале запустите:
ollama run dolphin-mistral:latest
Первоначальная загрузка может занять много времени, поскольку для нее требуется загрузка 26 ГБ. После завершения загрузки мистраль будет ждать вашего ввода.

Помните, что запуск dolphin-mistral требует значительных системных ресурсов, особенно оперативной памяти.

Обучение собственной модели
Теперь вас может интересовать возможность обучения мистраля на ваших данных. Ответ – однозначное да.
Начните с создания учетной записи на Hugging Face (если вы еще этого не сделали), а затем создайте новое пространство.
Выберите Docker для Autotrain
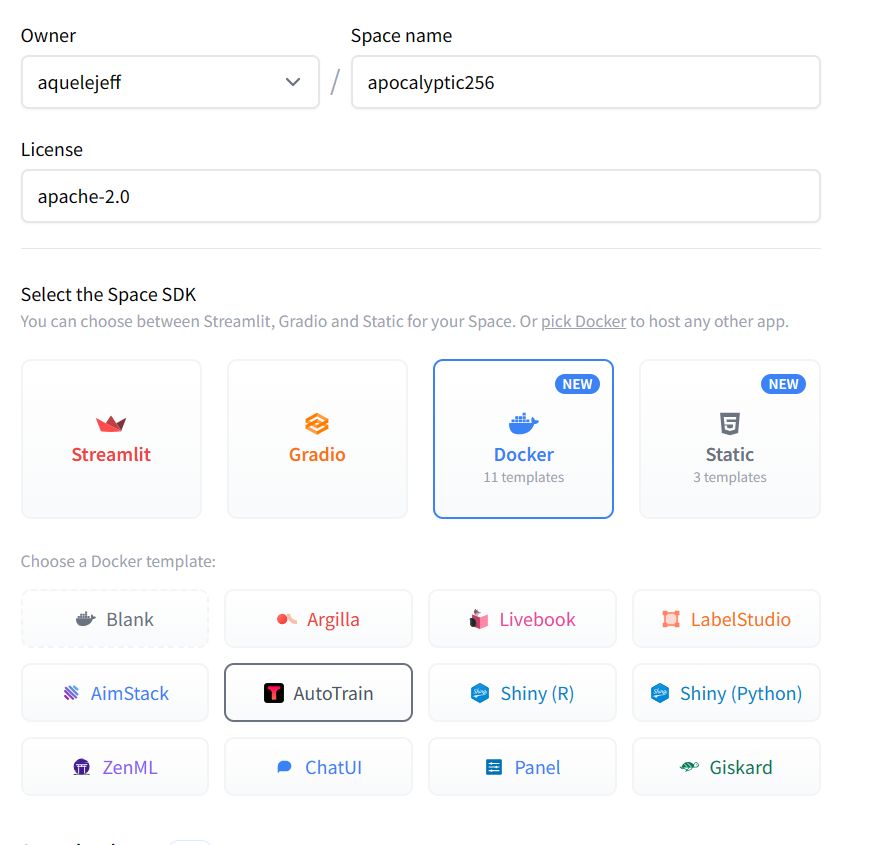
Здесь вы можете выбрать свою модель, загрузить данные и начать обучение. Обучение модели на домашнем компьютере может оказаться сложной задачей из-за требований к оборудованию.
Такие сервисы, как Hugging Face, предлагают вычислительную мощность (за определенную плату), но вы также можете воспользоваться услугами Amazon Bedrock или Google Vertex AI, чтобы ускорить процесс.