

Как превратить текст в высококачественное аниме с высокой детализацией с помощью Anything-v3-Better-VAE
21 апреля 2023 г.Вы энтузиаст аниме и всегда мечтали создавать свои собственные изображения в стиле аниме? Или, может быть, художник, стремящийся вывести свою работу на новый уровень детализации и качества? Что ж, пристегнитесь, у меня есть для вас кое-что по-настоящему умопомрачительное!
В этом посте я познакомлю вас с невероятным миром модели Anything-v3-Better-VAE, которая позволяет создавать потрясающие, высококачественные и детализированные изображения в стиле аниме. легко. Мы подробно рассмотрим модель, на что она способна и как ее эффективно использовать. И в довершение всего, мы изучим возможности Replicate Codex в поиске похожих моделей для расширения вашего креатива. ящик для инструментов. Давайте погрузимся!
n

О модели Anything-v3-Better-VAE
Модель Anything-v3-Better-VAE с более чем 2,1 млн запусков , — одна из самых популярных моделей в Replicate Codex, занимающая 8-е место по популярности.
Он основан на популярной модели стабильной диффузии и использует возможности улучшенного вариационного автоэнкодера (VAE) для создания первоклассных изображений в стиле аниме. VAE – это архитектура нейронной сети, которая кодирует и декодирует изображения в меньшее скрытое пространство и из него, что ускоряет и делает вычисления более эффективными.
В модели стабильной диффузии процесс диффузии работает в пространстве автоэнкодера, а не в пространстве пикселей, что обеспечивает более эффективный в вычислительном отношении и удобный для памяти подход. Эта модель особенно хорошо справляется с распределением изображений, что делает ее мощным инструментом для создания изображений в стиле аниме.
Модель Anything-v3-Better-VAE делает еще один шаг вперед, улучшая возможности декодирования VAE. Результат? Более мелкие детали восстанавливаются лучше, что делает его идеальным для визуализации изображений, где важны сложные детали, такие как глаза и текст.
Однако модель не идеальна. Поскольку набор данных фильтруется, а автоэнкодер агрессивен, он может испытывать трудности с созданием текста по сравнению с такими моделями, как Dall-E. Но для большинства изображений в стиле аниме это не должно представлять серьезной проблемы.
Теперь, когда вы понимаете, что представляет собой модель Anything-v3-Better-VAE, давайте углубимся в понимание ее входных и выходных данных, прежде чем мы перейдем к использованию модели для создания нашего собственного высококачественного, детализированного аниме-стиля. изображения.
Понимание входных и выходных данных модели Anything-v3-Better-VAE
Входные данные
Модель принимает несколько входных параметров, таких как:
приглашение: приглашение ввода для создания изображения.negative_prompt: подсказка или подсказки не управлять созданием изображения (то, что вы не хотите видеть при создании). Игнорируется, если руководство не используется.width: ширина выходного изображения. Максимальный размер – 1024 x 768 или 768 x 1024 из-за нехватки памяти.height: высота выходного изображения. Максимальный размер – 1024 x 768 или 768 x 1024 из-за нехватки памяти.num_outputs: количество изображений для вывода.num_inference_steps: количество шагов шумоподавления.guidance_scale: шкала для навигации без классификатора.планировщик: выберите планировщик (например, DDIM, K_EULER, DPMSolverMultstep, K_EULER_ANCESTRAL, PNDM, KLMS).seed: случайное начальное число. Оставьте поле пустым, чтобы рандомизировать начальное число.
Результаты
Модель выводит массив URI изображений, где каждый URI представляет сгенерированное изображение. Вот пример структуры:
{
"type": "array",
"items": {
"type": "string",
"format": "uri"
},
"title": "Output"
}
Теперь, когда мы понимаем входные и выходные данные модели, давайте углубимся в использование модели для создания фантастических изображений в стиле аниме.
Пошаговое руководство по использованию модели Anything-v3-Better-VAE
Если вы предпочитаете практический подход, вы можете напрямую взаимодействовать с демонстрацией модели на странице Реплицировать. Это отличный способ поиграть с параметрами модели и быстро получить обратную связь и подтверждение.
Для тех, кто более техничен и хочет создать инструмент на основе этой модели, выполните следующие простые шаги для создания образов с использованием модели Anything-v3-Better-VAE в репликации. В этом примере я буду использовать Node.js для взаимодействия с моделью на платформе Replicate.
Примечание. Обязательно создайте учетную запись Replicate и получите ключ API.
Шаг 1. Установите клиент Node.js
Установите клиент Replicate Node.js с помощью следующей команды:
npm install replicate
Шаг 2. Настройте токен API
Скопируйте свой токен API и выполните аутентификацию, установив его в качестве переменной среды:
export REPLICATE_API_TOKEN=[token]
Шаг 3. Запустите модель
Импортируйте библиотеку Replicate и запустите модель Anything-v3-Better-VAE с нужными входными параметрами:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"cjwbw/anything-v3-better-vae:09a5805203f4c12da649ec1923bb7729517ca25fcac790e640eaa9ed66573b65",
{
input: {
prompt: "masterpiece, best quality, illustration, beautiful detailed, finely detailed, dramatic light, intricate details, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
}
}
);
Что вы получаете, запуская модель? Если вы укажете только входные данные по умолчанию, вы получите изображение, подобное приведенному ниже:

Изменение темы на старика вместо этого приводит к следующему изображению:

Вы также можете использовать ИИ для устранения недостатков изображения. Например, ознакомьтесь с этим руководством по использованию codeformer для очистки изображений, созданных искусственным интеллектом!
Дальше — поиск моделей, подобных Anything-v3-Better-VAE, с помощью Replicate Codex
Replicate Codex — это невероятный ресурс для поиска моделей ИИ, отвечающих различным творческим потребностям, включая создание изображений, преобразование изображений в изображения и многое другое. Это полностью доступная для поиска, фильтруемая, помеченная база данных всех моделей на Replicate, позволяющая сравнивать модели и сортировать по цене или исследовать по создателю. Это бесплатно, а также содержит сводку по электронной почте, которая будет уведомлять вас о выходе новых моделей, чтобы вы могли их опробовать.
Если вы хотите найти модели, похожие на Anything-v3-Better-VAE, выполните следующие действия:
Шаг 1. Посетите Replicate Codex
Перейдите на страницу Replicate Codex, чтобы начать поиск похожих моделей.
Шаг 2. Используйте панель поиска
Используйте строку поиска в верхней части страницы для поиска моделей по определенным ключевым словам, таким как "аниме", "генерация изображений" или "высокое качество". Это покажет вам список моделей, связанных с вашим поисковым запросом.
Шаг 3. Отфильтруйте результаты
В левой части страницы результатов поиска вы найдете несколько фильтров, которые помогут вам сузить список моделей. Вы можете фильтровать и сортировать модели по типу (изображение в изображение, текст в изображение и т. д.), стоимости, популярности или даже по конкретным авторам.
Применяя эти фильтры, вы можете найти модели, которые наилучшим образом соответствуют вашим конкретным потребностям и предпочтениям. Например, если вы ищете самую популярную или самую экономичную модель создания изображений, вы можете просто выполнить поиск, а затем отсортировать по соответствующему показателю.
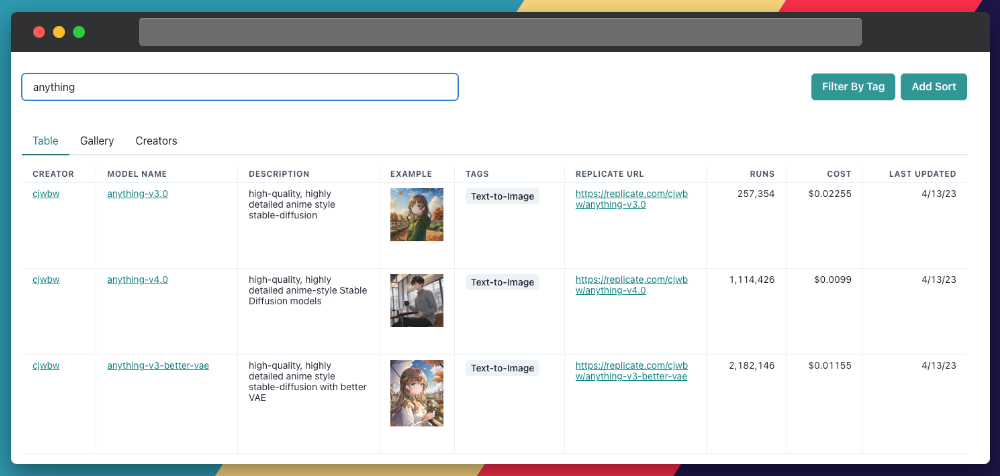
В этом случае я ввел в поле поиска слово «что угодно» и получил пару других моделей от того же автора! Может быть, вы захотите изучить их дальше. Все они связаны с аниме и могут стать альтернативой вашему проекту.
Заключение
В этом руководстве мы рассмотрели модель Anything-v3-Better-VAE, которая отлично подходит для создания высококачественных и детализированных изображений в стиле аниме с использованием улучшенного VAE. Мы прошли пошаговый процесс использования модели с репликацией, а также поняли различные входные и выходные данные.
Мы также обсудили, как использовать функции поиска и фильтрации в Replicate Codex, чтобы найти похожие модели и сравнить их результаты, что позволит нам расширить наши горизонты в мире создания изображений с помощью ИИ.
Я надеюсь, что это руководство вдохновило вас на изучение творческих возможностей ИИ и воплощение вашего воображения в жизнь. Приятного улучшения изображений и изучения мира ИИ с помощью Replicate Codex! п
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27664)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)