

Как ускорить обучение модели с помощью Snapml | Компьютерная культура
29 апреля 2022 г.Как ускорить обучение модели с помощью Snapml | Компьютерная культура
Получить неограниченный доступ
Дом
Уведомления
](/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fme%2Fnotifications&source=---------------------------------------- -notifications_sidenav-----------)[
Списки
](/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fme%2Flists&source=---------------------------------------- -lists_sidenav-----------)[
Рассказы
](/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fme%2Fstories%2Fdrafts&source=-------------------------------------- ---stories_sidenav-----------)
Написать
](/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fnew-story&source=------------------------- -new_post_sidenav-----------)

](https://medium.com/geekculture?source=post_page-----b2e24b546fe5---------------------------- ---)
Опубликовано в
Компьютерная культура
](https://medium.com/geekculture?source=post_page-----b2e24b546fe5---------------------------- ---)

](/@davis-david?source=post_page-----b2e24b546fe5--------------------------------)
Следовать
21 апр
6 минут чтения
Как ускорить обучение модели с помощью Snapml
Обучите модель машинного обучения за меньшее время

Фото Тараса Макаренко с сайта Pexels:
Машинное обучение оказывает огромное влияние на решение бизнес-задач в различных отраслях, включая здравоохранение, финансы и транспорт. Вы можете собирать значительный объем данных, создаваемых каждый день, и обучать модель машинного обучения конкретным задачам, таким как рекомендации по продуктам и анализ настроений.
Рекомендуется обучить и провести несколько экспериментов по машинному обучению на большом наборе данных, чтобы получить эффективную модель машинного обучения. Это имеет свой собственный набор трудностей, таких как длительное обучение модели для достижения желаемых результатов.
В этой статье вы узнаете, как можно ускорить процесс обучения модели машинного обучения за короткий промежуток времени с помощью пакета Python snapml.
Давайте начнем! 🚀
Что такое Snapml?
Это пакет Python, разработанный IBM для обеспечения высокоскоростного обучения моделей машинного обучения в вычислительных средах как с ЦП, так и с ГП. Snampl может помочь вам выполнить следующие задачи в вашем проекте машинного обучения:
- Тренируйтесь и перетренируйтесь на новых данных онлайн.
- Сделать большую настройку параметров.
- Принимать точные решения и прогнозы.
- Тренируйте модель на всех доступных данных с меньшими ресурсами.
- Эффективно обрабатывать большие данные.
Он также поддерживает различные типы моделей машинного обучения, такие как:
- Обобщенные линейные модели (например, линейная регрессия).
- Модели на основе дерева (например, деревья решений и случайный лес).
- Модели повышения градиента (например, Boosting Machine).
При обучении моделей в облачных средах Snapml может помочь вам сократить расходы, ускорив процесс обучения за короткий промежуток времени.

скриншот из https://www.zurich.ibm.com/snapml/
Как установить Snapml
Чтобы установить snapml, выполните следующую команду в своем терминале.
пип установить snapml
Примечание. В настоящее время Snapml поддерживает Python 3.7, 3.8 и 3.9. Для пользователей macOS в настоящее время поддерживается архитектура Intel (x86_64).
Обучить модель машинного обучения без Snapml
В этой части вы сначала обучите модель машинного обучения на большом наборе данных с помощью алгоритма машинного обучения из библиотеки scikit-learn. -learning-library-d6ffea7b88dc) и оцените общее время, затраченное на обучение модели на наборе данных.
Импорт пакетов
Первым шагом является импорт различных важных пакетов Python, которые мы собираемся использовать для загрузки набора данных, подготовки набора данных и обучения модели машинного обучения.
#импорт библиотеки__import numpy as np
import pandas as pd_from_ sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score_import_ время
_import_warningswarnings.filterwarnings("игнорировать")
np.random.seed(123)
Загрузить набор данных
Мы будем использовать набор данных «Статус банковского кредита» для обучения модели, которая может классифицировать будущий статус кредита.
Загрузите набор данных с [kaggle.com] (https://www.kaggle.com/datasets/zaurbegiev/my-dataset).
Чтобы загрузить набор данных, используйте функцию read_csv из библиотеки pandas.
_#load data_Bank_Dataset = pd.read_csv("../data/credit_train.csv")
Проверьте первые несколько строк набора данных.
_#показать первые пять строк_Bank_Dataset.head()
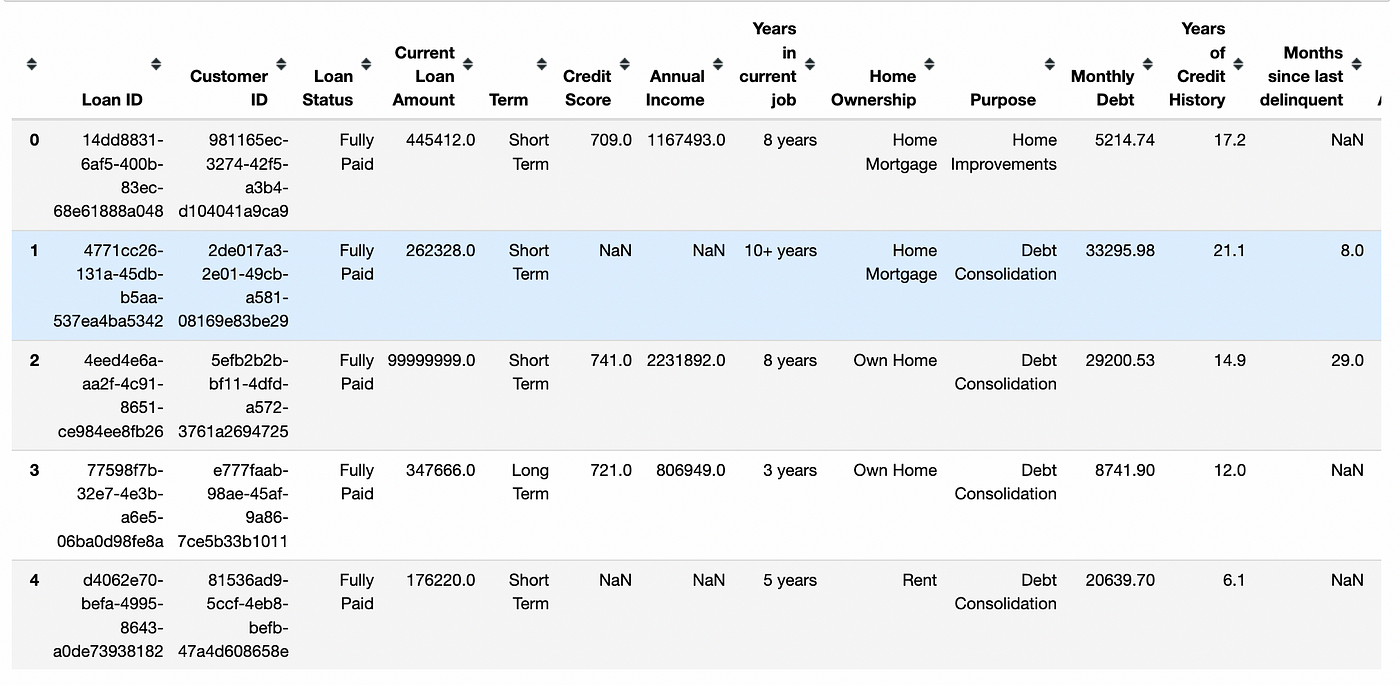
Датафрейм панд
Набор данных имеет множество функций, показывающих подробную информацию о кредите, полученном каждым клиентом.
Давайте проверим форму набора данных, чтобы определить его размер.
# показать форму
Банк_Dataset.shape
(100514,19)
Набор данных «Статус банковского кредита» содержит более 100 000 строк данных и 19 столбцов. Этот набор данных достаточно велик, чтобы оценить разницу во времени при обучении модели с использованием Snapml и без него.
Подготовьте набор данных
Вам необходимо подготовить набор данных, удалив ненужные функции, обработав пропущенные значения и преобразовав все функции в числовые значения.
(а) Удалить компоненты
На этом шаге вы удалите идентификатор займа и идентификатор клиента.
удалить столбцы ID
Банк_Dataset.drop(["Идентификатор кредита", "Идентификатор клиента"], axis=1, inplace=True)
Теперь у нас осталось 16 функций и целевой столбец («Статус кредита»).
(b) Обработка пропущенных значений
Обычно в наборе данных могут быть отсутствующие значения, которые необходимо обработать перед обучением модели машинного обучения. Вот код для проверки количества пропущенных значений в каждом столбце в вашем наборе данных.
проверить пропущенные значения
Банк_Dataset.isnull().sum()
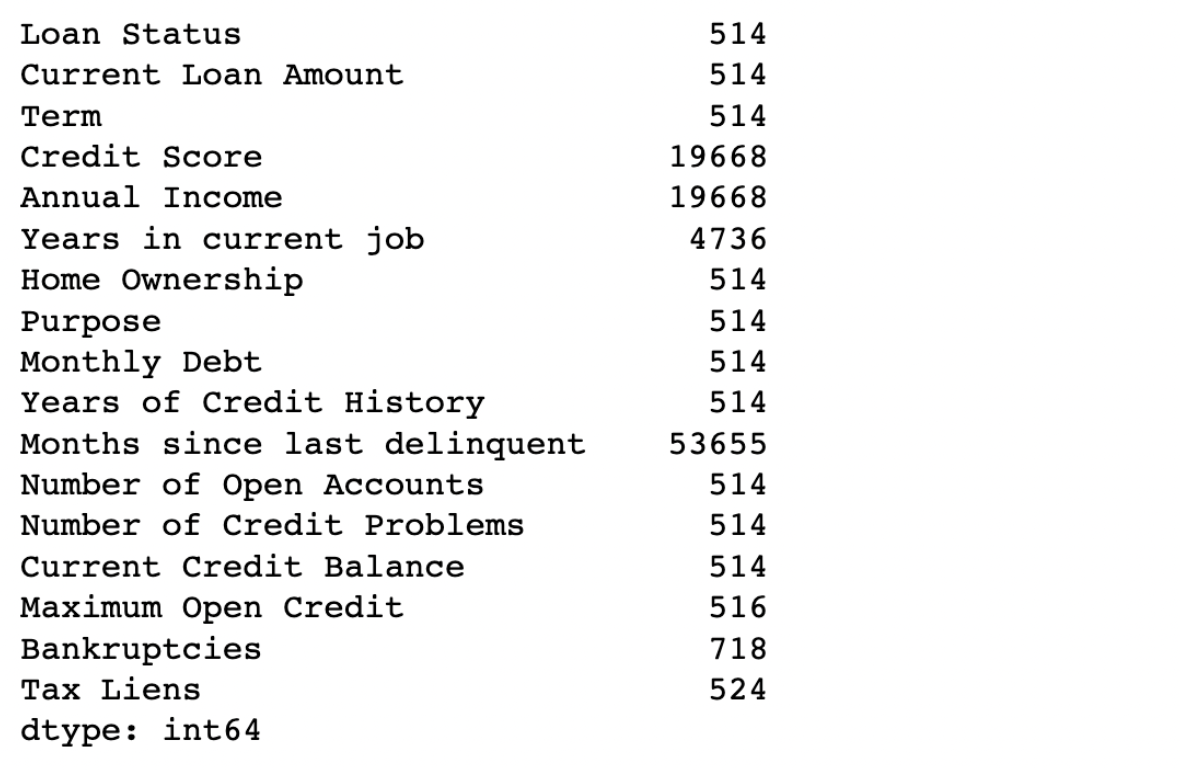
Особенности с общим количеством пропущенных значений
В нашем наборе данных отсутствуют значения во всех функциях, включая целевой столбец («Статус кредита»).
Блок кода ниже сначала заполнит пропущенные значения в категориальных столбцах, используя наиболее часто встречающееся значение в каждом категориальном столбце. Затем заполните пропущенные значения в числовых столбцах, используя среднее значение каждого числового столбца.
# заполнить пропущенные значения для категориальных функций
Банк_Dataset["Статус кредита"].fillna("Полностью выплачен", inplace=True)
Банк_Набор данных["Срок"].fillna("Краткосрочный", inplace=True)
Банк_Dataset["Годы на текущей работе"].fillna("10+ лет", inplace=True)
Банк_Dataset["Домашняя собственность"].fillna("Ипотека на дом", inplace=True)
Bank_Dataset["Purpose"].fillna("Консолидация долга", inplace=True)# заполнить пропущенные значения для целочисленных функций
целые числа_columns = список(
Банк_Dataset.select_dtypes(include=['floating']).columns)
для столбца в целых числах_columns:
Банк_Набор данных[столбец].fillna(Банк_Набор данных[столбец].среднее(), inplace=True)
(c)Преобразование набора данных
После обработки отсутствующих значений в наборе данных вам необходимо преобразовать набор данных в числовые значения.
Первым шагом в преобразовании является использование метода LabelEncoder из библиотеки scikit-learn для предварительной обработки двух двоичных категориальных столбцов (Term и Loan Status).
# предварительно обработать двоичные категориальные столбцыle = LabelEncoder()
binary_columns = ["Статус кредита", "Срок"]
для столбца в двоичном файле_columns:
Банк_Набор данных[столбец] = le.fit_transform(Банк_Набор данных[столбец])
Затем вы преобразуете несколько категориальных столбцов с помощью функции get_dummies из библиотеки pandas. Эта функция преобразует следующие столбцы в наборе данных.
- Домовладение
- Цель
- Годы на текущем месте работы
# предварительно обработать несколько категориальных столбцов
Банк_Dataset = pd.get_dummies(
Банк_Набор данных,
columns=[«Владение домом», «Цель», «Годы на текущей работе»])
(d)Разделить функции и цели
Разделите набор данных на столбцы функций и столбец целей.
# разделить данные на цель и функции
target = Bank_Dataset["Статус кредита"].values
функции = Банк_Dataset.drop("Статус кредита", ось = 1)
(e) Масштабирование функций
Преобразованные признаки имеют разные диапазоны значений. Вам необходимо нормализовать все функции с помощью метода MimMaxScaler от scikit-learn до заданного диапазона от 0 до 1.
# масштабирование набора данныхscaler = MinMaxScaler()
функции = масштабирование.fit_transform (функции)
Обучите модель машинного обучения
Чтобы обучить модель без snapml, вам нужно создать экземпляр RandomForestclassifer из библиотеки scikit-learn, используя следующий код.
создать классификатор
sklearn_classifier = RandomForestClassifier()
Наконец, обучите RandomForestClassifier на преобразованном наборе данных. Также найдем разницу во времени до и после обучения модели.
# training classifierstart_time = time.time()scores = cross_val_score(sklearn_classifier, features, target, cv=3)print("Время обучения: {}".format(time.time() - время начала))
print("Очки: {}".format(оценки))
Время обучения: 55.80186605453491
Результаты: [0,82122071 0,8188927 0,82106614]
Таким образом, производительность модели составляет около 82% точности, а время обучения составляет 55,80 секунды (почти 1 минута).
Давайте посмотрим, как мы можем ускорить обучение модели с помощью Snapml.
Обучите модель машинного обучения с помощью Snapml
Первым шагом является импорт контролируемого алгоритма под названием RandomForest Classifier из пакета snapml.
# добавить RandomForestClassifier из snapmlfrom snapml import RandomForestClassifier
Затем создайте экземпляр классификатора.
snampl_classifier = RandomForestClassifier()
Наконец, обучите классификатор из snapml и оцените разницу во времени до и после обучения модели.
start_time = time.time()scores = cross_val_score(snampl_classifier, features, target, cv=3)print("Время обучения с snapml: {}".format(time.time() - start _время))
print("Очки: {}".format(оценки))
Время обучения с snapml: 14.459826469421387
Результаты: [0,81065513 0,80946127 0,8109181 ]
Как видите, время обучения при использовании snapml составляет 14,45 секунды, что почти в 4 раза быстрее, чем при обучении модели машинного обучения с помощью библиотеки scikit-learn.
Snapml обладает большим потенциалом и может сэкономить ваше время и деньги при обучении крупномасштабного набора данных в облачной среде.
Snapml поддерживает другие модели классификации, которые вы можете попробовать в своем собственном наборе данных, например:
- Логистическая регрессия
- Деревья решений
- Поддержка машины Vecotr
- Ускоряющая машина
- Пакетные ансамбли деревьев.
Вывод
В этой статье вы узнали о некоторых проблемах обучения модели машинного обучения с большим набором данных и о том, как можно использовать snampl для ускорения процесса обучения модели за короткое время.
Как я уже говорил ранее, snapml сэкономит вам не только время, но и деньги, если вы обучаете свою модель в облачной среде. Библиотека даст вам возможность проводить различные эксперименты по машинному обучению, не беспокоясь о нехватке времени.
Пожалуйста, поделитесь этим постом с другими, если вы узнали что-то новое или вам понравилось его читать. А пока ждите следующего поста!
Вы также можете найти меня в Twitter @Davis_McDavid.
И последнее: читайте другие подобные статьи по следующим ссылкам.
5 лучших стратегий миграции в облако, которые вам нужно знать
Как плавно перенести данные и систему в облако
Medium.com
](/geekculture/top-5-cloud-migration-strategies-you-need-to-know-fb1d92ed3c8a)
Как веб-сканирование используется в науке о данных
Инструменты No-Code для сбора данных для вашего проекта Data Science
python.plainenglish.io
](https://python.plainenglish.io/how-is-web-crawling-used-in-data-science-a116d883419d)
5 основных причин, по которым компании переходят в облако
Почему использование облачных технологий компаниями увеличилось до 90 %
Medium.com
](/geekculture/top-5-причин-почему-компании-переходят-в-облако-c3a609332125)
](/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fgeekculture%2Fb2e24b546fe5&operation=register&redirect=https%3A%2F%2Fmedium.com%2Fgeekculture%2Fhow-to-speed-up-model -обучение-с-snapml-b2e24b546fe5&user=Davis+David&userId=db373139e72d&source=-----b2e24b546fe5---------------------clap_footer------- ----)
](/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fgeekculture%2Fb2e24b546fe5&operation=register&redirect=https%3A%2F%2Fmedium.com%2Fgeekculture%2Fhow-to-speed-up-model -обучение-с-snapml-b2e24b546fe5&user=Davis+David&userId=db373139e72d&source=-----b2e24b546fe5---------------------clap_footer------- ----)
](/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fgeekculture%2Fb2e24b546fe5&operation=register&redirect=https%3A%2F%2Fmedium.com%2Fgeekculture%2Fhow-to-speed-up-model -обучение-с-snapml-b2e24b546fe5&user=Davis+David&userId=db373139e72d&source=-----b2e24b546fe5---------------------clap_footer------- ----)
Новая техническая публикация от Start it up (https://medium.com/swlh).
Подробнее читайте в Geek Culture
Рекомендовано от Medium
](/@zaidamjadghazal?source=post_internal_links----------0---------------)
Зайд Амджад Газаль
](/@zaidamjadghazal?source=post_internal_links----------0---------------)
Прогнозирование смерти в больнице с помощью машинного обучения

](/@samiriff?source=post_internal_links----------1---------------)
Самир Шериф
](/@samiriff?source=post_internal_links----------1---------------)
в
На пути к науке о данных
](https://medium.com/towards-data-science?source=post_internal_links----------1--------------------- -------)
Путешествие от марсианских орбитальных аппаратов к наземным нейронным сетям


](/@jstutorial?source=post_internal_links---------2--------------)
Преподаватель JavaScript (Инкогнито)
](/@jstutorial?source=post_internal_links---------2--------------)
ИИ — «Машинное обучение» — «Изучай визуально»

](/@umdfirecoml?source=post_internal_links----------3--------------)
FIRE Capital One Машинное обучение UMD.edu
](/@umdfirecoml?source=post_internal_links----------3--------------)
Обучение модели Mask R-CNN с использованием данных ядра


](/@mathanrajsharma?source=post_internal_links----------4--------------)
Матханрадж Шарма
](/@mathanrajsharma?source=post_internal_links----------4--------------)
в
На пути к науке о данных
](https://medium.com/towards-data-science?source=post_internal_links---------4--------------------- -------)
Настройка Tensorflow-GPU с Cuda и Anaconda в Windows


](/@wiseai?source=post_internal_links----------5-------------------------------------------)
Махмуд Хармуш
](/@wiseai?source=post_internal_links----------5-------------------------------------------)
в
Стартап
](https://medium.com/swlh?source=post_internal_links----------5----------- ---)
Распознавание лиц с использованием порога тона кожи (RGB-YCrCb): реализация Python.


](/@suryanshtrivedi1?source=post_internal_links----------6--------------)
Сурьянш Триведи
](/@suryanshtrivedi1?source=post_internal_links----------6--------------)
Экскурсия по Студии машинного обучения Azure

](/@luiscarlosduarte95?source=post_internal_links----------7-------------------------------------------)
Луис Дуарте
](/@luiscarlosduarte95?source=post_internal_links----------7-------------------------------------------)
Создание собственного сервиса встраивания Bert с помощью TorchServe

](/@дэвис-дэвид)
Дэвис Дэвид
](/@дэвис-дэвид)
356 подписчиков
Специалист по данным | ИИ-практик | Разработчик программного обеспечения. Преподавание, преподавание, письмо. Свяжитесь со мной для сотрудничества davisdavid179@gmail.com
Следовать
Еще от Medium

](/@Mikolaj_Maslanka?source=read_next_recirc---------0-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Миколай Масланка
](/@Mikolaj_Maslanka?source=read_next_recirc---------0-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
MLOps — нежное введение. Понятия и примеры.

](/@maciejbalawejder?source=read_next_recirc---------1-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Мацей Балавейдер
](/@maciejbalawejder?source=read_next_recirc---------1-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
в
Ботаник для техники
](https://medium.com/nerd-for-tech?source=read_next_recirc----------1--------------------- 9cf8a229_d922_4d83_b98d_ca62b7e2e863-------)
Обзор методов нормализации в глубоком обучении

](/@giskard_ai?source=read_next_recirc---------2-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Жискар
](/@giskard_ai?source=read_next_recirc---------2-------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Как тестировать модели машинного обучения? (3/n): дрейф числовых данных


](/@bobrupakroy?source=read_next_recirc---------3---------------------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Боб Рупак Рой - II
](/@bobrupakroy?source=read_next_recirc---------3---------------------9cf8a229_d922_4d83_b98d_ca62b7e2e863--------)
Интервью по науке о данных. Вопросы — V

Помощь
](https://help.medium.com/hc/en-us)
Статус
](https://medium.statuspage.io)
Писатели
](https://about.medium.com/creators/)
Блог
](https://blog.medium.com)
Карьера
] (/ работа-в-среде/работа-в-среде-959d1a85284e)
Конфиденциальность
](https://policy.medium.com/medium-privacy-policy-f03bf92035c9)
Условия
](https://policy.medium.com/medium-terms-of-service-9db0094a1e0f)
О
](https://medium.com/about?autoplay=1)
Познаваемый
](https://knowable.fyi)
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27234)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)