

Как очистить результаты новостей Google с помощью Node JS
28 ноября 2022 г.Этот пост научит нас парсить результаты Google News с помощью Node JS, используя Unirest и Cheerio.
Требования:
Веб-анализ с помощью селекторов CSS
Извлечение тегов из HTML-файлов не только сложно, но и требует много времени. Лучше использовать гаджет CSS-селекторов для выбора идеальных тегов, которые упростят ваш поиск в Интернете.
Этот гаджет может помочь вам создать идеальный селектор CSS для ваших нужд. Вот ссылка на руководство, которое научит вас использовать этот гаджет для выбора лучших селекторов CSS в соответствии с вашими потребностями.
Агенты пользователя
User-Agent используется для идентификации приложения, операционной системы, поставщика и версии запрашивающего пользовательского агента, что может помочь в поддельном посещении Google, действуя как реальный пользователь.
Вы также можете чередовать пользовательские агенты, подробнее об этом читайте в этой статье: Как подделывать и чередовать пользовательские агенты с помощью Python 3.
Если вы хотите дополнительно защитить свой IP-адрес от блокировки Google, вы можете попробовать эти 10 советов, которых следует избегать. получение блокировки при очистке данных Google.
Установить библиотеки
Чтобы начать парсинг результатов Google News, нам нужно установить некоторые библиотеки NPM.
- JS-узел
- Юнирест JS
- Cheerio JS
Поэтому перед началом мы должны убедиться, что мы настроили наш проект Node JS и установили оба пакета — Unirest JS и Cheerio JS. Вы можете установить оба пакета по приведенной выше ссылке.
Цель:
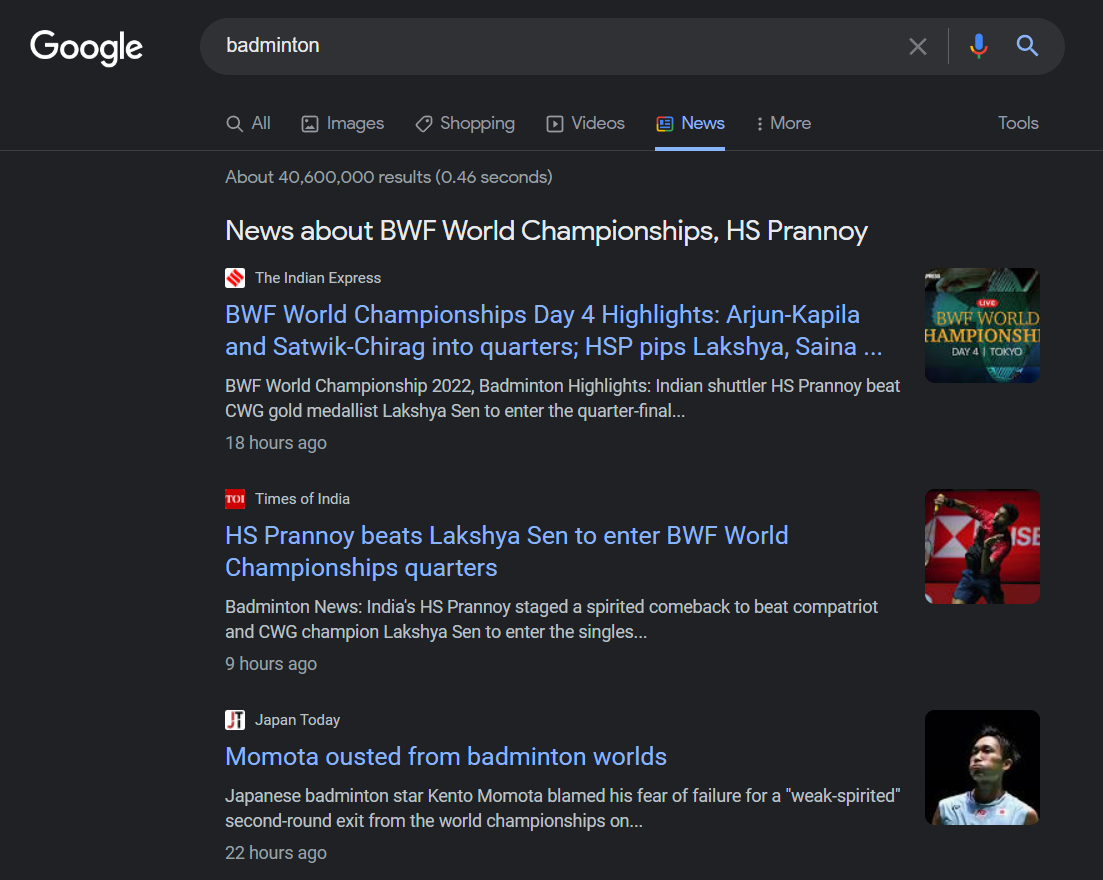
Процесс:
Как указано выше в разделе Требования, мы будем использовать Unirest JS для извлечения данных HTML и Cheerio JS для анализа извлеченных данных HTML.
Вот полный код:
const unirest = require("unirest");
const cheerio = require("cheerio");
const getNewsData = () => {
return unirest
.get("https://www.google.com/search?q=football&gl=us&tbm=nws")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36",
})
.then((response) => {
let $ = cheerio.load(response.body);
let news_results = [];
$(".BGxR7d").each((i,el) => {
news_results.push({
link: $(el).find("a").attr('href'),
title: $(el).find("div.mCBkyc").text(),
snippet: $(el).find(".GI74Re").text(),
date: $(el).find(".ZE0LJd span").text(),
thumbnail: $(el).find(".NUnG9d img").attr("src")
})
})
console.log(news_results)
});
};
getNewsData();
Или вы можете скопировать этот код по следующей ссылке для лучшего понимания: GoogleNewsScraper.
Пояснение кода:
Сначала мы объявляем константы из библиотек:
const unirest = require("unirest");
const cheerio = require("cheerio"); `
Затем мы использовали Unirest JS для отправки запроса на получение нашего целевого URL-адреса, который в данном случае:
https://www.google.com/search?q=Badminton&gl=us&tbm=nws
Мы сделаем этот запрос, передав заголовки URL-адресу, который в данном случае является User-Agent.
User-Agent используется для идентификации приложения, операционной системы, поставщика и версии запрашивающего пользовательского агента, что может помочь в поддельном посещении Google под видом реального пользователя.
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
})
Вы также можете передать URL-адрес прокси-сервера при выполнении запроса следующим образом:
.get("https://www.google.com/search?q=Badminton&gl=us&tbm=nws")
.headers({
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
})
.proxy("PROXY URL")
Здесь "URL-ПРОКСИ" означает URL-адрес прокси-сервера, который вы будете использовать для отправки запросов. Это может помочь вам скрыть ваш фактический IP-адрес, что означает, что веб-сайт, который вы очищаете, не сможет идентифицировать ваш фактический IP-адрес, что спасет вас от блокировки. Затем мы загружаем наш ответ в переменную Cheerio и инициализируем пустой массив «news_results» для хранения наших данных.
Затем мы загружаем наш ответ в переменную Cheerio и инициализируем пустой массив news_results для хранения наших данных.
.then((response) => {
console.log(response.body)
let $ = cheerio.load(response.body);
let news_results = [];
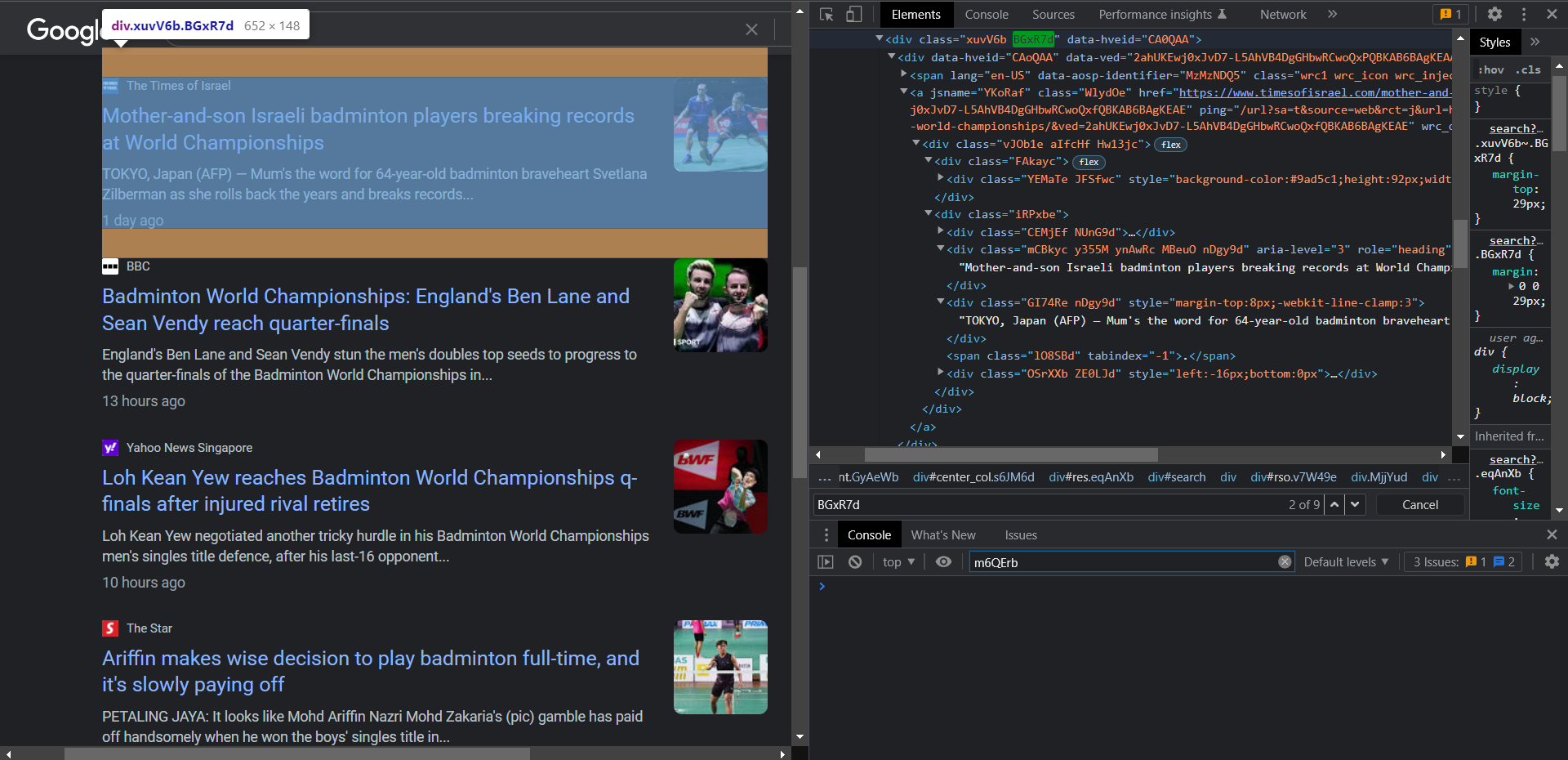
Вы можете видеть, что каждая новостная статья содержит этот тег BGxR7d. Выполняя поиск в этом контейнере, вы получите тег для заголовка как mCBkyc, описание как GI74Re, дату как ZE0LJd span и для изображение как NUnG9d img.
А затем парсер для получения необходимой информации:
$(".BGxR7d").each((i,el) => {
news_results.push({
link: $(el).find("a").attr('href'),
title: $(el).find("div.mCBkyc").text().replace("n",""),
snippet: $(el).find(".GI74Re").text().replace("n",""),
date: $(el).find(".ZE0LJd span").text(),
thumbnail: $(el).find(".NUnG9d img").attr("src")
})
})
Результат:

Наш результат должен выглядеть так 👆🏻.
С API Новостей Google
Если вы не хотите программировать и поддерживать парсер в долгосрочной перспективе, вы определенно можете попробовать поисковый API Google.
const axios = require('axios');
axios.get('https://api.serpdog.io/news?api_key=APIKEY&q=football&gl=us')
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
});
Результат:

Вывод:
В этом руководстве мы научились очищать результаты Google News с помощью Node JS. Не стесняйтесь сообщать мне все, что вам нужно разъяснить. Подпишитесь на меня в Твиттере. Спасибо за прочтение!
Дополнительные ресурсы
- Как очистить результаты обычного поиска Google с помощью Node JS?
- Очистить результаты картинок Google
- Очистить отзывы Google Карт
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)