
Как реализовать сопоставление показателей склонности: пошаговое руководство
5 ноября 2024 г.Недавно я работал над экспериментом, основанным наСопоставление показателей склонностии при поиске информации я столкнулся с отсутствием материалов по теме. Большинство статей, которые я нашел, посвящены эффективности метода, и они не очень подробны с точки зрения теории. Поэтому я решил поделиться с вами всеобъемлющим руководством поСопоставление показателей склонностиструктура и ее шаги
Что такое сопоставление показателей склонности и зачем его применять?
«Соответствие показателя склонности подразумевает формирование соответствующих наборов леченных и нелеченных субъектов, которые разделяют схожее значение показателя склонности. После формирования соответствующей выборки эффект лечения можно оценить путем прямого сравнения результатов».
Определение впервые было дано Розенбаумом П.Р., Рубином Д.Б. в статье «Оценка чувствительности к ненаблюдаемому бинарному ковариату в наблюдательном исследовании с бинарным результатом» в 1983 году.
Проще говоря,это дополнительный метод A/B-тестирования, используемый в случаях, когда рандомизация выборки не работает. Оценка склонности (вероятность отнесения к тестовой группе) группы лечения подсчитывается для каждого пользователя, а затем пользователь сопоставляется с другим пользователем на основе исторических данных об использовании продукта, образуя контрольную группу. После этого результаты двух групп сравниваются с помощью статистического теста, и измеряется эффект эксперимента.
Но зачем использовать сложную технику поиска контрольной группы, если вместо этого это может сделать платформа A/B? В некоторых случаях невозможно использовать платформу A/B со встроенной функцией разделения. Вот возможные случаи:
- Реализация A/B-тестирования для бизнеса требует больших затрат денег и времени из-за разнообразной кросс-функциональной работы и коммуникаций (да, такое может случиться).
- Компания может не получить прибыль при тестировании монетизационных или маркетинговых функций/стратегий в случае реализации классического тестового/контрольного эксперимента.
- В офлайн-экспериментах часто невозможно провести рандомизированную выборку, которая необходима для A/B-тестирования.
- Также невозможно применять A/B-тестирование в онлайн-экспериментах, если тестируемый объект не распределен случайным образом.
В моей практике был четвертый случай, и он произошел при работе с продуктом электронной коммерции. Команда продукта готовилась к тестированию функции предоставления бонусов пользователям после оформления первого заказа. Проблема была в том, что функция работала не у всех пользователей, оформляющих первый заказ. Необходимо было соблюсти определенные условия, такие как стоимость заказа и т. д. В этом случае разделить трафик между тестовой и контрольной группами выходит за рамки платформы A/B-тестирования. Вот почемуСопоставление показателей склонностибыл вариант.
Структура сопоставления показателей склонности
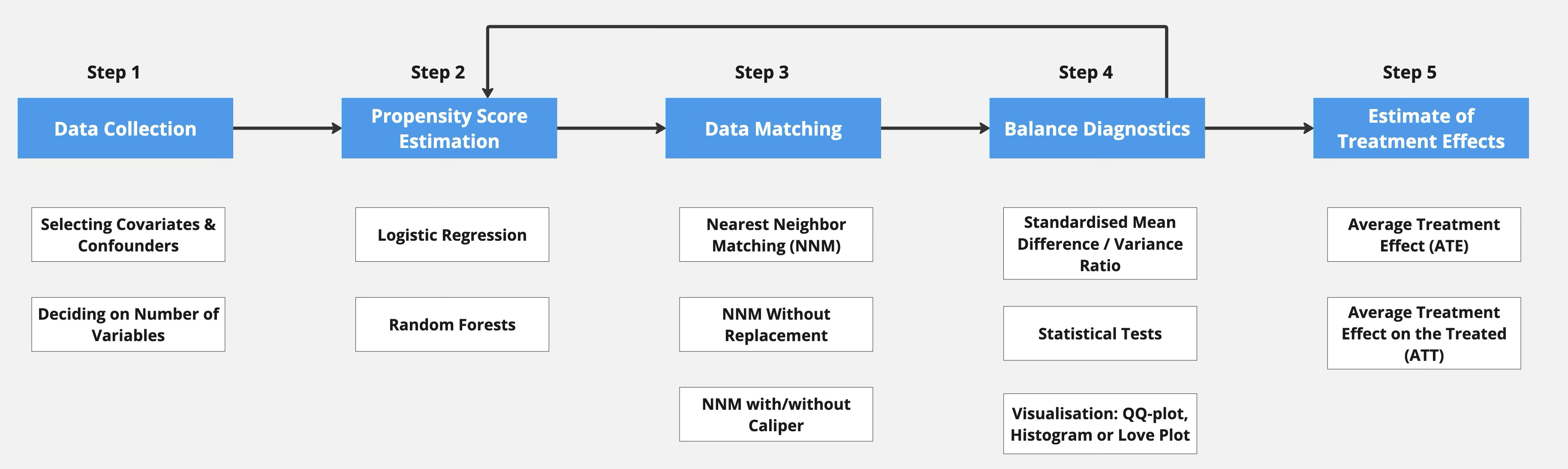
АсПолная структура примерно основана на статье «Сопоставление показателей склонности с R: традиционные методы и новые возможности» и состоит из пяти шагов (рисунок 2).
Первым шагом является сбор данных, на основе которых оценивается показатель склонности и находится соответствующий пользователь.
Вторым шагом является оценка показателя склонности с использованием таких методов, как логистическая регрессия, и обучение на наборе данных для прогнозирования того, будет ли пользователь назначен в тестовую группу. Для каждого пользователя обученная модель генерирует вероятность попадания в тестовую группу.
Третий шаг относится к сопоставлению на основе показателя склонности, где пробуются различные методы сопоставления, такие как метод ближайшего соседа.
На четвертом этапе проверяется баланс ковариатов между группами лечения и контроля путем расчета балансовых статистик и построения графиков. Плохой баланс указывает на то, что модель оценки склонности должна быть переопределена.
На пятом заключительном этапе оцениваются эффекты теста с использованием сопоставленных данных и проводится статистический тест.
Сбор данных
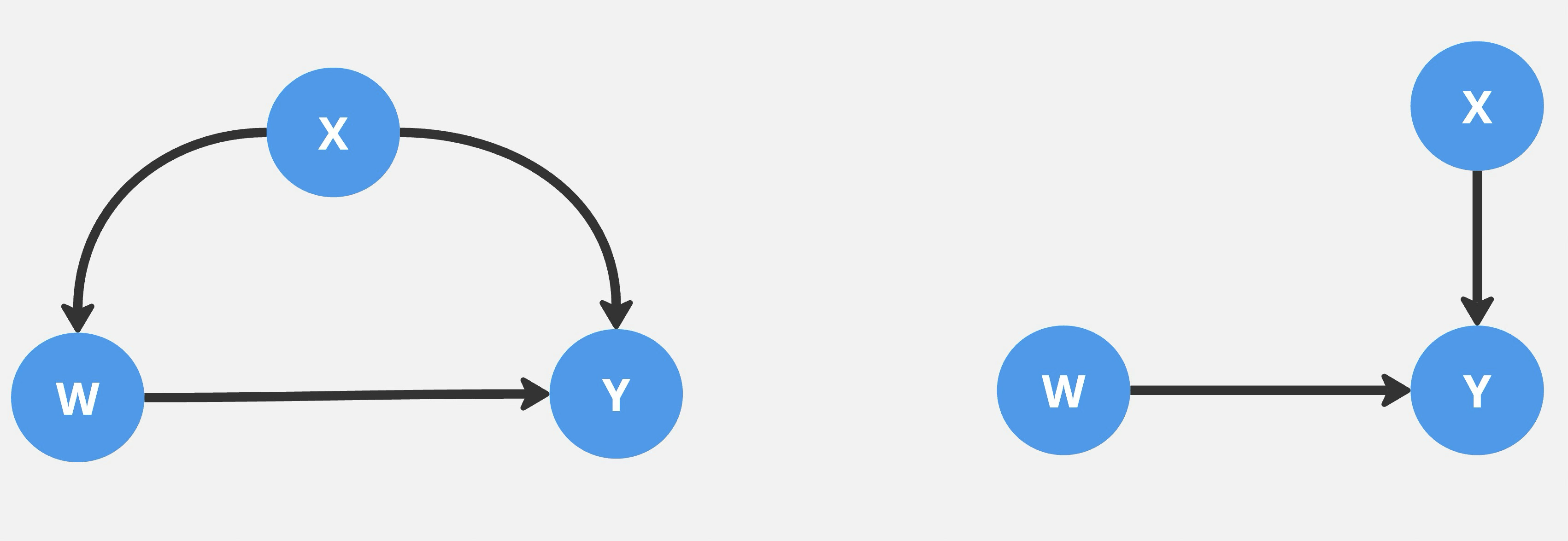
На этом этапе происходит сбор необходимых переменных, ковариатов и конфаундеров. Ковариат (X) — это независимая переменная, которая может влиять на результат эксперимента (Y), но не представляет прямого интереса. Конфаундер — это фактор, отличный от изучаемого, который связан как с распределением по тестовой группе (W), так и с результатом эксперимента (Y).
График ниже иллюстрирует взаимосвязи переменных. X — это ковариата, W — индикатор назначения лечения, а Y — результат. График слева изображает взаимосвязь конфаундера, а график справа — независимую связь ковариаты с результатом эксперимента (Y) и с распределением по тестовым группам (W).
Здесь важно подчеркнуть, что не рекомендуется выбирать только те переменные, которые связаны с отнесением пользователей к тестовой группе (W), поскольку это может снизить точность оценки разницы в группах без уменьшения смещения (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1513192/ ).
Вы можете спросить, сколько переменных мне нужно выбрать? Ответ прост -чем больше, тем лучше, чтобы получить высокую оценку результатов и минимизировать предвзятость исследования. И здесь я говорю о больших числах, как 20-50 и даже больше.
Оценка показателя склонности
Переходя к следующему шагу, необходимо собрать данные и установить флаг принадлежности к группе лечения. Все остальные пользователи потенциально образуют контрольную группу. После этого показатель склонности оценивается с использованием различных методов, таких как логистическая регрессия или случайные леса.
Большинство прочитанных мной статейпредлагаем придерживаться логистической регрессии и не использовать другие более сложные модели, поскольку высокая точность не имеет решающего значениял. Тем не менее, последующая техника сопоставления концентрируется на точности.
После выбора метода на данных обучается предиктивная модель с использованием выбранных ковариатов для прогнозирования принадлежности пользователя к тестовой группе. Наконец, модель делает прогнозы для каждого пользователя, и вычисляется показатель склонности, вероятность нахождения в тестовой группе. Что касается программного обеспечения, в Python вы можете использовать любую библиотеку прогнозирования, начиная с базовой scikit-learn и заканчивая Prophet.
Сопоставление данных
Следующее действие заключается в реализации метода сопоставления для поиска сопоставленного пользователя пользователю из тестовой группы. Таким образом, формируется контрольная группа.
Существуют различные методы сопоставления на выбор, например, точное сопоставление или сопоставление расстояния Махаланобиса. В этой статье я в основном собираюсь обсудить распространенную технику сопоставления ближайшего соседа и ее вариации.
Соответствие ближайшего соседа (NNM) состоит из двух фаз. Сначала алгоритм выбирает пользователей, одного за другим, из группы лечения в указанном порядке. Затем для каждого пользователя тестовой группы алгоритм находит пользователя в контрольной группе с ближайшим показателем склонности. Эти шаги повторяются до тех пор, пока в тестовой или контрольной группах не останется ни одного пользователя. В Python есть специальные библиотеки для PSM, такие как PyTorch,Psmpy, каузалиб. Или вы всегда можете использовать любую классическую библиотеку с соответствующими алгоритмами.
Важно подчеркнуть, что в случае создания контрольной группы, аналогичной классическому тесту A/B, где пользователи в группе уникальны, а размеры выборки равны, необходимо реализовать метод NNM без замены. Метод подразумевает, что после сопоставления сопоставленная пара будет удалена, так что пользователь в контрольной группе будет использован только один раз.
Также есть возможность выбрать модель NNM с калипером или без него. Калипер устанавливает верхний предел расстояния оценок склонности в сопоставленной паре. Таким образом, каждый пользователь может быть сопоставлен только с пользователями с оценкой склонности в пределах ограниченного диапазона. Если подходящие пользователи не могут быть сопоставлены, пользователь будет отброшен.
Зачем мне использовать штангенциркуль? Его целесообразно применять, когда расстояние между показателями склонности в паре может быть большим. При выборе размера штангенциркуля учтите следующее: если качество сопоставления неудовлетворительное, сопоставление можно провести с более узким штангенциркулем, а если сопоставление прошло успешно, но количество сопоставленных пар невелико, штангенциркуль можно расширить (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8246231/ ).
Диагностика баланса
На этом этапе проверяется, сбалансированы ли ковариаты тестовой и сопоставленной контрольной групп, таким образом, утверждается, является ли сопоставление точным.
Это важный шаг, поскольку несбалансированные ковариаты приведут к неверному сравнению результатов A/B-тестирования.
Существует три способа диагностики баланса:
- описательная статистика: стандартизированная средняя разность (SMD) или дисперсионное отношение (VR)
- статистические тесты
- визуализация: график qq, гистограмма или график любви
В статье я в основном концентрируюсь на первом и третьем вариантах.
Сначала давайте обсудим стандартизированную разницу средних и отношение дисперсии. Какие значения указывают на то, что ковариата сбалансирована?Я рекомендую, чтобы значение SMD было ниже 0,1. С точки зрения VR, значение, близкое к 1,0, указывает на баланс..
Во-вторых, что касается методов визуализации, одна из вышеприведенных описательных статистик рассчитывается для каждого ковариата и отображается графически. Лично я предпочитаю любовный график, поскольку все ковариаты можно разместить на одном графике, а ковариаты до и после сопоставления можно легко сравнить. Ниже я привожу пример графика.
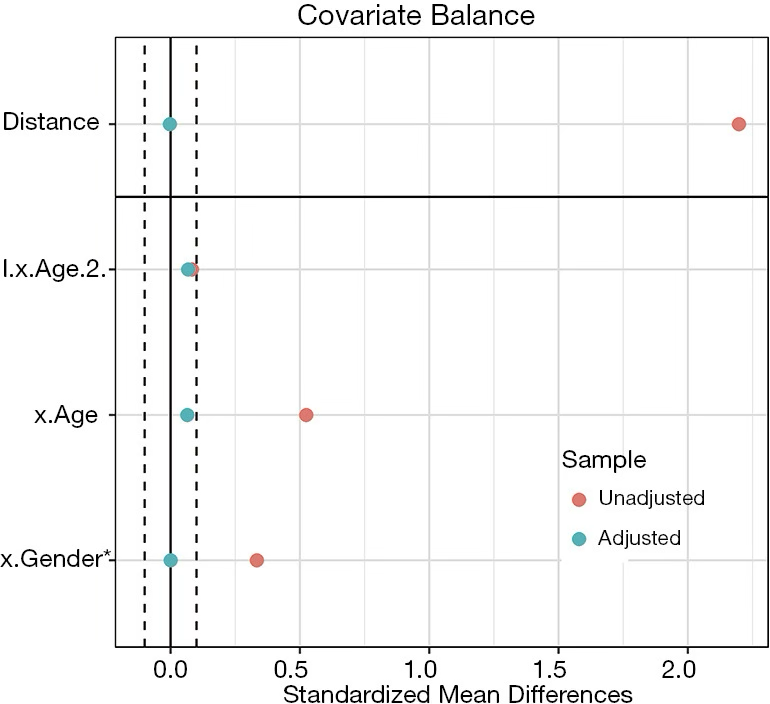
Что делать, если ковариаты все еще не сбалансированы после сопоставления? Для иллюстрации, стандартизированная средняя разница (SMD) ковариатов частоты покупок и AOV составляет около 0,5, что выше требуемых 0,1. Это означает, что ковариаты несбалансированы и необходимо повторное сопоставление.
Несбалансированный сигнал ковариатов Модель PSM неэффективна и нуждается в перестройке. Поэтому необходимо вернуться на несколько шагов назад и повторить сопоставление.
Существует четыре способа повторного сопоставления:
1. Добавить новые ковариаты
2. Просто измените метод сопоставления, так как их много.
3. ОбъединитьСопоставление показателей склонностис методом точного соответствия
4. Увеличить размер выборки
Оценка эффективности лечения
Наконец, мы приближаемся к последнему этапу, когда оценивается эффект эксперимента. Существует три основных типа оценки эффекта: средний эффект лечения (ATE), средний эффект лечения на леченных (ATT) и средний эффект лечения на контроле (ATC). По сути, ATE — это вычисленная разница в ключевой метрике между тестовой и контрольной группами (аналогично измерению основной метрики в тесте A/B). Она рассчитывается как среднее значение эффекта лечения, ATE = avg (Y1 - Y1), как показано ниже на рисунке.
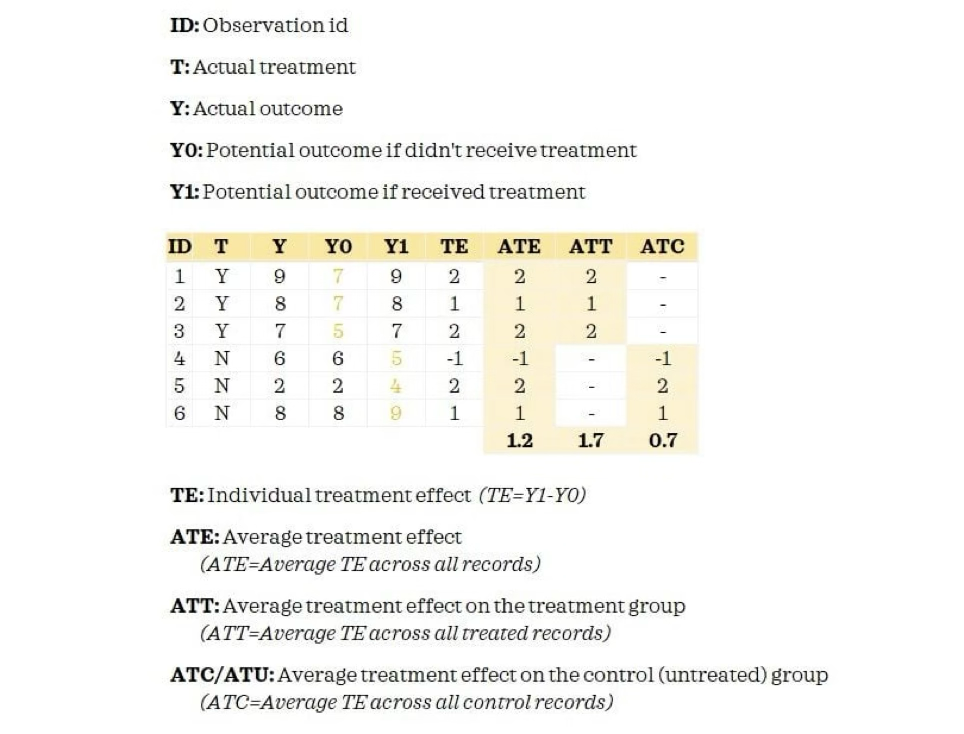
В то время как ATT и ATC являются средним эффектом лечения тестовой и контрольной группы соответственно. Все они являются простыми и понятными методами оценки.
ATE является наиболее распространенным типом и используется, когда сравнивается основная метрика контрольной и тестовой групп и измеряется тестируемый эффект. В то время как ATT и ATC предпочтительны, когда требуются абсолютные метрики для каждой группы. В конечном счете, проводится соответствующий статистический тест для проверки статистической значимости результатов.
Ограничения сопоставления показателей склонности
После подробного объясненияСопоставление показателей склонностиметода, возможно, пришло время начать внедрять его в свою работу, но следует учитывать определенные ограничения.
1. Не рекомендуется использовать Bootstrap с Propensity Score Matching, так как это увеличивает дисперсию.https://economics.mit.edu/sites/default/files/publications/О ПРОВАЛЕ БУТСТРАПА ДЛЯ.pdf)
2. Stable unit treatment value assumption (SUTVA) principle must be met.
3. Propensity Score Matching implies using two machine learning algorithms (one for propensity score calculations and the second one for matching), which can be a pricy method to use for a company. On that account, it’s advisable to negotiate with your team on A/B test conduction.
4. Finally, as discussed above, a big number of covariates are suggested to be used in the models. Thus, it requires a high-powered machine(-s) to calculate the results of the models. Again, it’s a costly method to implement.
Однако, если это возможно реализоватьСопоставление показателей склонности, делайте это и не стесняйтесь повышать свой опыт и практические знания. Удачи в ваших будущих экспериментах и открытиях в области машинного обучения
Хотите попробовать ответить на некоторые из этих вопросов? Ссылка на шаблон:
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)