

Как аннотировать 100 сканов LIDAR за 1 час: пошаговое руководство
22 марта 2023 г.Беспилотные транспортные средства и другие автономные системы используют системы лидара (обнаружения света и измерения дальности) для сбора трехмерной информации об окружающей среде. Затем автомобиль может выполнять задачи восприятия в режиме реального времени, чтобы избегать препятствий. Однако лидарные данные можно использовать только после того, как они были аннотированы. Это означает, что огромное количество данных должно быть помечено и проверено людьми, что делает аннотацию трехмерного облака точек сложным методом.
В настоящее время я работаю в Evocargo, компании, предоставляющей услуги по перевозке грузов в контролируемых зонах. Для этой услуги мы производим собственные беспилотные электромобили и разрабатываем программное обеспечение.
<цитата>Излишне говорить, что безопасность вождения является нашим главным приоритетом, поэтому нам нужно, чтобы наши автомобили определяли проезжую часть в облаках точек, полученных с помощью лидаров.
Нам не нужно маркировать каждый объект в сцене. Например, нас не так уж интересуют деревья или здания, но нам все равно нужно исключить их из области движения. Аннотирование одного лидарного скана для наших целей может занять до 20 минут. Некоторые задачи можно ускорить с помощью продвинутых (и дорогих) инструментов, но их использование не всегда экономически целесообразно.
Кроме того, инженеры по аннотациям должны маркировать кадры, которые почти идентичны, что приводит к большому количеству повторяющейся работы. Каждый следующий кадр имеет лишь минимальный сдвиг по сравнению с предыдущим, но инструменты не позволяют спроецировать на них ту же аннотацию. Каждый новый кадр необходимо обрабатывать вручную.
Мы поставили перед собой задачу оптимизировать процесс аннотирования без потери качества. Мы использовали алгоритмы и веб-инструмент аннотирования компьютерного зрения (CVAT, открытый исходный код), чтобы сделать аннотирование быстрее и свести к минимуму повторяющиеся операции для наших инженеров. Благодаря этой работе мы увеличили производительность аннотации с нескольких кадров до 100 кадров в час. В этой статье я расскажу, как мы это делаем.
Обзор
Основная идея проста: мы сразу сегментируем целую серию лидарных сканов. Во-первых, мы применяем фильтры и сегментацию к облакам точек в лидарных сканах и строим лидарную карту. Затем мы преобразуем карту в BEV (вид с высоты птичьего полета) и аннотируем проезжую часть на 2D-изображении с помощью CVAT. Наконец, мы проецируем эту аннотацию на лидарные сканы.
Чтобы лучше проиллюстрировать каждый из этапов, я разделил рабочий процесс на отдельные операции. Большинство из них выполняются автоматически в фоновом режиме, и только два — вручную.

Давайте посмотрим, как это работает, когда мы обрабатываем лидарное сканирование сцены, содержащей автомобили, человека, препятствие на проезжей части и различные другие объекты.

Этап 1. Аннотирование динамических объектов
Мы помечаем транспортные средства и людей в облаках точек и определяем, являются ли они динамическими или статичными. Для этого можно использовать инструменты с открытым исходным кодом, такие как SUSTechPoints. Это одна из двух операций, которые наши инженеры по аннотации должны выполнять вручную. Позже мы сможем использовать эти аннотации для обучения нейронных сетей обнаружению людей и автомобилей.

Человек на изображении окрашен в красный цвет, а транспортные средства — в зеленый.
Этап 2 — Сегментация
Мы автоматически экспортируем аннотацию, сделанную на этапе 1, и запускаем алгоритм сегментации — RANSAC или аналогичный — в облаке точек.

Однако алгоритм работает неидеально и идентифицирует некоторые части бордюра и автомобилей как землю.
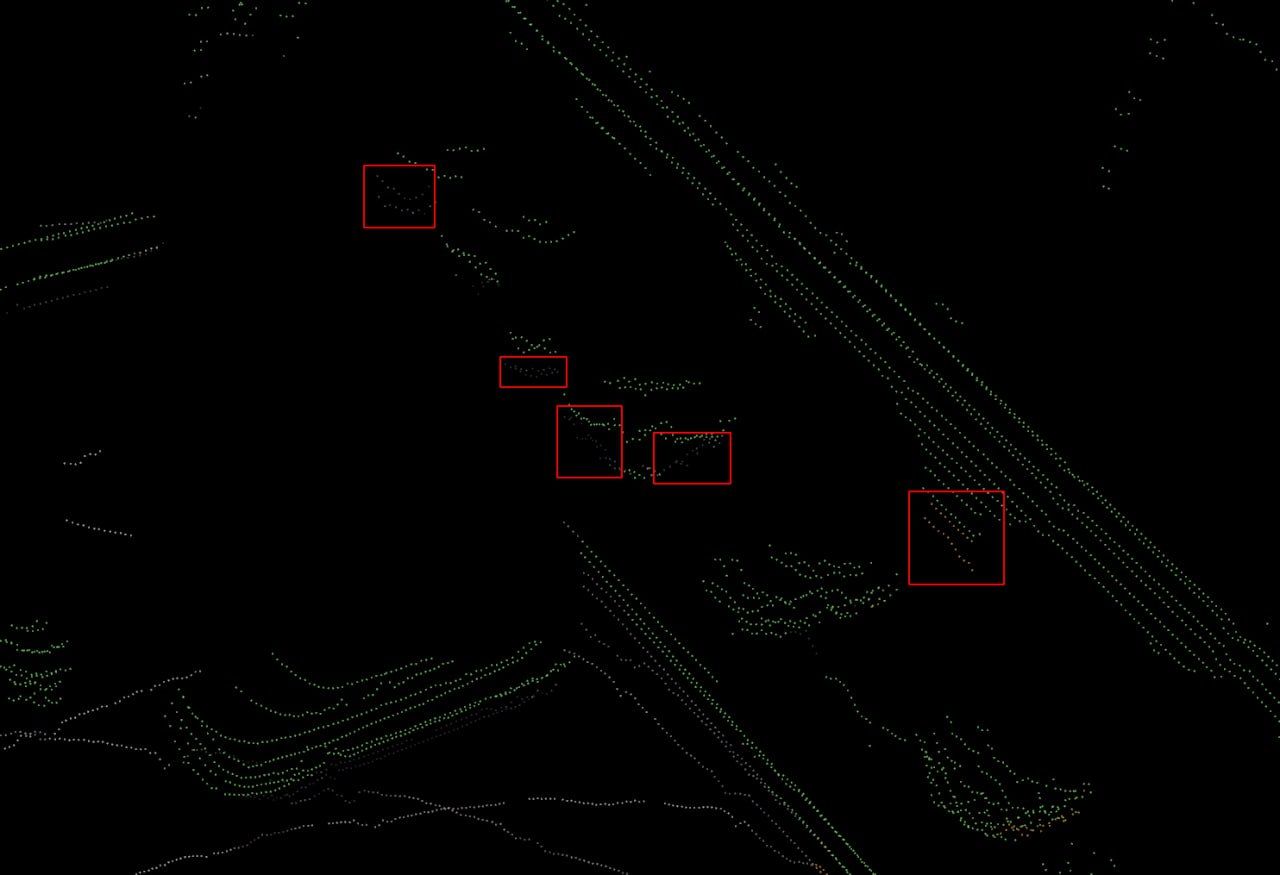
Качество недостаточно хорошее для использования в AV, поэтому мы дополнительно улучшаем результат сегментации.
Этап 3 — Добавление цвета
Мы проецируем цвета с изображений камеры одной и той же сцены на точки земли. Это облегчает обнаружение мелких объектов и точек, таких как бордюр и поддон, которые алгоритм ошибочно отнес к проезжей части.

Теперь часть проезжей части имеет цвет — в основном светло-серый, так как у нас дорога покрыта тонким слоем снега. Некоторые зоны оставлены желтыми, потому что они находятся вне поля зрения камер или изображения с камер слишком шумные, и мы не хотим на них полагаться. Мы помним об этом, когда вернемся к раскрашиванию на этапе 5.
Этап 4. Создание 3D-карты
С помощью Open3D мы вырезаем динамические объекты и запускаем алгоритм регистрации ICP, который точно объединяет все цветные облака точек в одно большое облако точек.

Этап 5. Добавьте больше цвета
У нас все еще есть желтые точки, которые не совпадают с изображением камеры по цвету. Мы знаем, что они принадлежат управляемой области, потому что они были определены алгоритмом сегментации на этапе 2, а также потому, что они находились в пределах досягаемости камеры и были окрашены на других сканах. Поэтому после объединения сканов в одну карту мы ищем ближайшую цветную точку для каждой бесцветной точки. Если расстояние до окрашенной точки меньше заданного нами порога (несколько сантиметров), мы проецируем ее цвет на точку.

Этап 6. Фильтрация по высоте
Верхушки деревьев, провода и другие объекты, расположенные высоко над землей, могут мешать обзору проезжей части при взгляде сверху и затруднять работу инженеров-аннотаторов. Итак, мы фильтруем все точки, находящиеся выше 1 метра над землей, и удаляем их с карты. Все точки выше 30 сантиметров и ниже 1 метра окрашиваем в фиолетовый цвет.
Этап 7 — преобразование в BEV
В то же время мы преобразуем облако точек в BEV, чтобы получить 2D-изображение, которое наши инженеры по аннотациям могут позже обработать в CVAT.

Этап 8 — Выровнять дорожное полотно
После преобразования изображения в BEV мы применяем медианный фильтр, который удаляет крошечные пробелы. в дорожном полотне и делает изображение более плавным. Эффект трудно увидеть на изображении заснеженной дороги, с которым мы работаем в этой статье, поэтому вот изображения дорожного полотна из другой сцены, которые лучше его иллюстрируют.

Этап 9. Аннотирование управляемой области
Наши инженеры по аннотациям маркируют проезжую часть в CVAT. Это вторая операция, которую им приходится выполнять вручную.

Этап 10. Преобразование из 2D в 3D
Мы проецируем 2D-полигон из аннотации CVAT на облако точек. Для этого мы преобразуем 2D-полигон CVAT в полигональную сетку. Нас интересуют только точки, принадлежащие управляемой области. Поэтому мы помечаем точки ниже 0,7 метра и выше -0,3 метра как землю и удаляем все другие точки, которые находятся вне этого диапазона.

Это наше итоговое облако точек с сегментацией проезжей части.
Заключение
Описанный в этой статье рабочий процесс пакетного добавления аннотаций можно применить к любой автономной системе. Это ускоряет аннотацию в несколько раз. Мы увеличили производительность с нескольких до ста лидарных сканирований в час. Небольшие проекты также могут извлечь выгоду из этого метода рабочего процесса, который не требует дорогостоящих инструментов для сегментации управляемой области в облаках точек.
Нашим инженерам по аннотациям больше не нужно выполнять повторяющуюся работу, а аннотированный набор данных можно использовать для обучения нейронных сетей обнаружению объектов.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)