

Как устранить «ненадежность» в сквозном тестировании
29 марта 2023 г.В этом посте мы обсудим общую проблему при разработке набора сквозных (E2E) тестов: нестабильность. Ненадежные тесты — это тесты, которые терпят неудачу, хотя должны пройти. Из-за сложности E2E маловероятно, чтобы они были такими же стабильными, как модульные тесты — всегда будут некоторые ненадежности, но наша задача — убедиться, что это качество не делает тесты бесполезными.
Проблема
Нестабильность E2E создает проблемы на многих уровнях. С одной стороны, это снижает пользу, которую тесты могут принести проекту; и в то же время увеличивает стоимость обслуживания комплекса. Давайте рассмотрим несколько различных способов возникновения этой нестабильности.
Раздражает
В первую очередь членов команды просто раздражает постоянное столкновение со случайными сбоями E2E. В зависимости от настройки непрерывной интеграции (CI) случайные сбои могут потребовать ручного перезапуска тестов; заблокировать последующие шаги в конвейере интеграции; и/или во всех случаях сделать все медленнее. Слишком много этого раздражения еще больше затруднит убеждение ваших коллег-разработчиков в написании и поддержке E2E.
Случайный шум
Помимо раздражения, случайный шум в E2E может затруднить обнаружение проблем, которые проявляются недетерминированным образом. Допустим, какая-то функция в вашем приложении дает сбой каждые 20 попыток: теоретически E2E — идеальный инструмент для обнаружения такого рода проблем. Но автоматические тесты не помогут, если вы и ваша команда имеете привычку повторно запускать тесты, пока они не будут пройдены. Вам нужен небольшой случайный шум, чтобы заметить тонкий сигнал, который появляется случайным образом.
Подрыв доверия
Трудно доверять результатам тестов, если у вас есть привычка перезапускать тесты каждый раз, когда они обнаруживают ошибку. Ненадежные тесты заставляют всех сомневаться в своих результатах и учат команду относиться к неудачной работе E2E CI как к неприятности. Это противоположно тому, что вам нужно, чтобы получить преимущества от добавления автоматических тестов в свой проект.
Математика
Прежде чем двигаться дальше, давайте вернемся к математическим основам тестов E2E. Подобно медицинским тестам, набор E2E можно рассматривать как тест, который выявляет ошибки:
* положительный результат — некоторые тесты не пройдены, что означает регресс в приложении. * отрицательный результат — все тесты пройдены, проблем не обнаружено
Ошибочные срабатывания
Ненадежные тесты — это случаи ложных срабатываний: некоторые тесты дают сбой, хотя регрессии нет.
Для анализа флейки нужны понятия и терминология из теории вероятностей. Мы можем выразить эту вероятность как отношение ложноположительных результатов к общему количеству выполненных тестов. Поддерживая стабильность ветки и многократно перезапуская тесты, мы можем оценить эти значения для:
* набор тестов в целом и * каждый тест отдельно.
Чтобы свести теорию к минимуму, мы можем игнорировать обратную проблему — тесты проходят случайным образом, даже если они должны провалиться. Обычно это означает, что наше тестовое покрытие недостаточно, и проблему можно решить, добавив несколько новых тестовых случаев.
«Парадокс»
Обычно мы считаем, что набор тестов не прошел, если хотя бы один тест не прошел. Это приводит к неинтуитивному влиянию стабильности отдельных тестов на весь набор. Давайте предположим, что наши тесты ненадежны при 1 случайном сбое на 6 тестовых прогонов, поэтому мы можем сопоставить случайный сбой как получение 1 при броске кубика.
Когда у нас есть только один тест в наборе, расчет прост:
* ⅚ — тесты проходят, как и ожидалось (истинно отрицательный результат). * ⅙ — случайный сбой пакета (ложное срабатывание)

Когда у нас есть два теста, мы можем сопоставить нашу проблему с броском двух игральных костей: если некоторые из игральных костей показывают 1, этот тест не пройден, и, следовательно, наш набор не пройден. Чтобы все работало должным образом, нам нужно, чтобы первый тест прошел с вероятностью ⅚, и второй тест тоже прошел — опять же с вероятностью ⅚. Когда мы предполагаем, что оба теста независимы, мы можем перемножить вероятности, чтобы найти общую вероятность прохождения обоих тестов. Итак, окончательные результаты следующие:
* 25/36, примерно 0,69 шанс истинно отрицательных результатов * 1–25/36 = 11/36, или около 0,31 вероятности ложноположительного результата
Как видите, добавление нового теста сделало ложноположительные результаты значительно более вероятными.

Общая формула для оценки ложноположительных результатов пакета выглядит следующим образом:
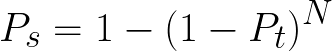
Где:
* Ps — вероятность случайного отказа пакета * Pt — вероятность случайного провала одного теста. * N — количество тестов
Имея в виду эту формулу, мы видим, что нестабильность отдельных тестов оказывает огромное влияние на стабильность всего набора тестов:
| Н ⟍ Пт | 1/6 | 1/10 | 1/100 | 1/1000 | 1/10000 | |----|----|----|----|----|----| | 5 | 0,59812 | 0,10331 | 0,01866 | 0,00340 | 0,00062 | | 25 | 0,98952 | 0,42030 | 0,08988 | 0,01687 | 0,00309 | | 100 | 1.00000 | 0,93454 | 0,37557 | 0,08154 | 0,01536 | | 500 | 1.00000 | 1.00000 | 0,90507 | 0,34641 | 0,07448 |
Строки показывают различное количество тестов в наборе, а столбцы показывают вероятность того, что каждый тест не пройден. Ячейки на поперечном сечении показывают вероятность отказа пакета по случайной ошибке. Как видите, когда вы добавляете больше тестов, их нестабильность накапливается очень быстро.
Причины
Теперь мы знаем, как количество тестов и стабильность работают вместе в пакете. Давайте рассмотрим возможные причины случайного сбоя теста.
Отсутствие изоляции
В зависимости от архитектуры вашей системы может быть сложно идеально изолировать тесты, особенно в местах, где вы подключаетесь к внешним системам. Приложение, над которым я работаю, имеет следующие серверные части:
* современный сервер, работающий из контейнера Docker * устаревший сервер, который нам так и не удалось поместить в контейнер * скрипты обработки данных, создающие статические файлы, используемые приложением * некоторые сторонние интеграции — некоторые связываются напрямую, другие — через прокси-сервер, предоставляемый современным сервером
Каждый неизолированный сервер, используемый вашим E2E, может вызывать проблемы:
* если сервер не работает, то ваши тесты не пройдут по причине, не связанной с вашими изменениями кода * если на сервере хранятся состояния, то параллельное выполнение тестов может вызвать случайные проблемы при конфликте данных
Решение: изоляция и насмешки
Чтобы обеспечить необходимую изоляцию от этих внешних систем, у вас есть несколько вариантов:
- переместить дополнительную инфраструктуру для запуска специально для каждого задания, выполняющего E2E, — это можно легко сделать с помощью Docker
- внедрите фиктивные прокси-серверы в серверную часть и убедитесь, что фиктивные реализации используются только в тестах.
- моделирование внутренних запросов с помощью вашей платформы E2E.
Вариант 1 позволяет по-настоящему охватить тестами как внутреннюю, так и внешнюю часть. Варианты 2 и 3 позволяют тестировать интерфейс без проверки серверной части — это отход от идеи E2E-тестирования, но иногда это необходимо.
Состояние утечки
Обмен данными между тестами может привести к неожиданным сбоям, особенно если вы объединяете две вещи:
* тесты выполняются параллельно или в случайном порядке * данные остались после тестов
Обычно при создании теста я пытаюсь очистить созданные данные. Итак, если я хочу протестировать создание и удаление функций своего приложения, я объединяю их в один тест. Для других операций я также пытаюсь отменить их в тесте.
Создание специальных данных в тестах
В какой-то момент я запускал несколько экземпляров средства выполнения тестов для одного и того же бэкэнда и базы данных. Любой обмен данными между этими тестами вызывал случайные сбои в некоторых тестах. Чтобы решить эту проблему, я перевел свои тесты так, чтобы они в основном зависели от данных, которые я создаю на лету, непосредственно перед запуском теста. Миграция заняла довольно много времени, но позволила выполнять тесты параллельно, сохраняя их все в одном задании CI.
Случайные проблемы в тестах
Несколько лет назад E2E-тесты было сложно писать, потому что инструменты не очень хорошо отслеживали состояние приложения, поэтому приходилось вручную программировать ожидания, чтобы гарантировать, что средство выполнения тестов не попытается взаимодействовать с приложением. в то время как данные все еще загружались. Современные инструменты, такие как Cypress, намного лучше ожидают, пока приложение загрузит данные. Но даже сейчас я иногда борюсь со случайными проблемами, созданными тестами. Ниже приведены некоторые примеры.
* в более медленной части приложения превышение времени ожидания теста в некоторых запусках * не добавляя ожидания там, где это необходимо: * запутанная логика загрузки, которая по умолчанию неправильно обрабатывается, ждет * не дожидаясь завершения ручной очистки в конце теста, поэтому иногда веб-сайт перезагружался для нового теста до завершения очистки файлов cookie * CI спешит запустить тест до того, как сервер и база данных будут полностью готовы
Случайные проблемы в приложении
Самое главное, иногда это вызвано случайным сбоем приложения. Такая проблема довольно раздражает пользователей и разработчиков. Даже при автоматизированных тестах вам нужно повторять один и тот же тест снова и снова, чтобы увидеть, как возникает ошибка.
Подобные проблемы могут вызывать недоумение у пользователей, потому что мы обычно ожидаем, что одни и те же действия приведут к одним и тем же результатам. Эта путаница также появится в отчетах об ошибках — не самое лучшее начало для устранения неполадок.
Серьезное отношение к устранению нестабильности E2E помогает найти и устранить эти проблемы до того, как они затронут клиентов. Преимущество затрат всех этих усилий заключается в том, что мы можем избежать впечатления, что наше приложение ненадежно.
Решения
У нас есть еще два варианта повышения стабильности E2E наших проектов.
Требуется высокое качество
Как видно из приведенной выше таблицы, даже тесты, которые дают сбой только один раз на тысячу запусков, могут стать довольно нестабильными, когда их будет 500. К счастью, из того, что я видел на практике, неустойчивость никогда не распределяется столь равномерно. Обычно это несколько нестабильных тестов, которые приводят к сбою пакета. Это означает, что вы можете сосредоточиться на устранении неполадок в тестах, которые, по вашему мнению, чаще всего не работают, и достаточно повысить общую стабильность, чтобы избежать случайных сбоев, вызывающих слишком много проблем.
Сплит-тесты CI
Недавно я перенес свой проект с запуска всего E2E в одном задании на выполнение отдельных заданий для выполнения задач, связанных с E2E, в разных частях приложения. Это изменение принесло несколько улучшений:
* распараллеливание достигается гораздо более чистым способом — серверная часть и БД не распределяются между разными исполнителями E2E, поэтому нет риска утечки данных из одного теста в другой * вы можете увидеть, какая часть дает сбой, непосредственно в пользовательском интерфейсе CI — это упрощает оценку того, является ли данный сбой теста ложным или истинно положительным. * это упрощает получение результатов при повторном запуске тестов — мне нужно перезапустить только неудачно завершившиеся задания, а не все тесты
Искушения
Помимо решения, которое я использую и которое рекомендую, есть несколько подходов, которые мне больше напоминают "взломы".
Автоматические повторы
Я всегда выступал против автоматического повторного запуска тестов. Моя главная проблема заключается в том, что разработчикам не составляет труда просто игнорировать все, что происходит в тестах недетерминированным образом. Таким образом, он предлагает оставить нерешенные, раздражающие проблемы E2E и фактические проблемы с кодом, которые могут повлиять на пользователей.
Сосредоточенный E2E
При разработке кода я вручную выбираю, какие E2E-тесты я хочу запустить — те, на которые могут повлиять мои изменения. По мере роста вашего набора тестов время выполнения увеличивается, а увеличение количества тестов усугубляет проблемы со стабильностью. Может возникнуть соблазн подумать о том, чтобы стать умнее и на стороне CI. Вы можете подумать о некоторых способах автоматического определения того, какие тесты могут быть затронуты изменением, и запускать только тесты, в которых должны быть заметны значимые изменения.
Я вижу здесь следующие проблемы:
* Ваш код или тест могут ухудшиться, даже если вы не вносите в них активные изменения — иногда в браузеры вносятся критические изменения, возможно, какое-то обновление библиотеки влияет больше, чем ожидалось, или серверная часть меняет свое поведение. Постоянное выполнение тестов позволит вам обнаружить любую из этих проблем, как только она появится. * Выполнение тестов для кода, в котором нет изменений, помогает оценить стабильность ваших тестов и выявить наиболее проблемные тесты. * Когда вы пытаетесь разумно подбирать тесты, вы определенно время от времени будете делать некоторые ошибки, эффективно обходя контроль качества.
Быстрый сбой
Если вы считаете, что набор тестов не пройден, когда у вас не пройден только один тест, нужно ли продолжать выполнение тестов после того, как один из них не пройден? Более быстрый сбой позволит вам повторно запускать тесты раньше и сэкономить некоторые ресурсы CI. При этом я по-прежнему избегаю завершения E2E после первого провала теста по следующим причинам:
* Когда я начинаю устранять неполадки в тестах, я хочу иметь полную картину, особенно знать, нужно ли исправить 1 или 10 тестов. * Я хотел бы получить общее представление о том, как часто мои тесты терпят неудачу в целом и по отношению друг к другу. Ранние сбои могут скрывать нестабильность в тестах, которые выполняются позже в наборе. * Однажды у меня возникла проблема, из-за которой база данных инициализировалась в одном из двух состояний. Одно состояние привело к сбою некоторых тестов; другое состояние привело к сбою различных тестов. Из-за ранних сбоев я не понимал, что сбои зависели от третьего фактора, и потратил слишком много времени на изучение обоих сбоев как независимых проблем.
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27052)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)