
Gemini — семейство высокопроизводительных мультимодальных моделей: ответственное развертывание
25 декабря 2023 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Команда Gemini, Google.
:::
Таблица ссылок
Обсуждение и заключение, ссылки
6. Ответственное развертывание
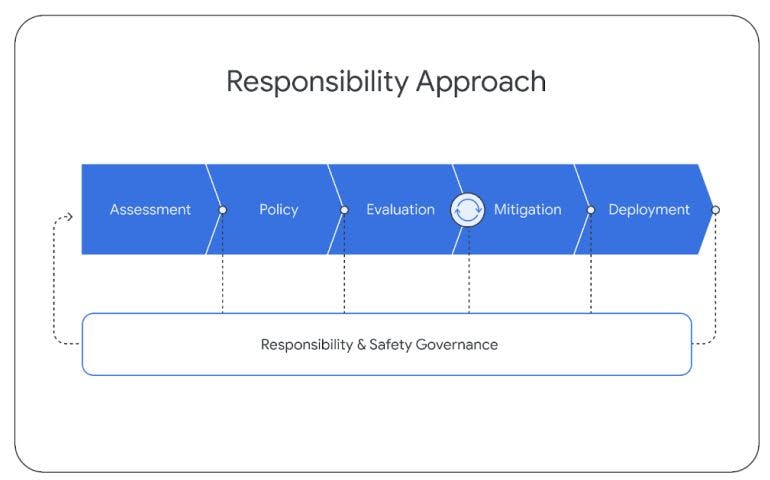
При разработке моделей Gemini мы придерживаемся структурированного подхода к ответственному развертыванию, чтобы выявлять, измерять и управлять прогнозируемыми последствиями наших моделей для общества в дальнейшем, в соответствии с предыдущими версиями технологии искусственного интеллекта Google (Kavukcuoglu et al. , 2022). На протяжении всего жизненного цикла проекта мы следуем приведенной ниже структуре. В этом разделе изложен наш общий подход и основные выводы, полученные в результате этого процесса. Более подробную информацию об этом мы поделимся в следующем отчете.
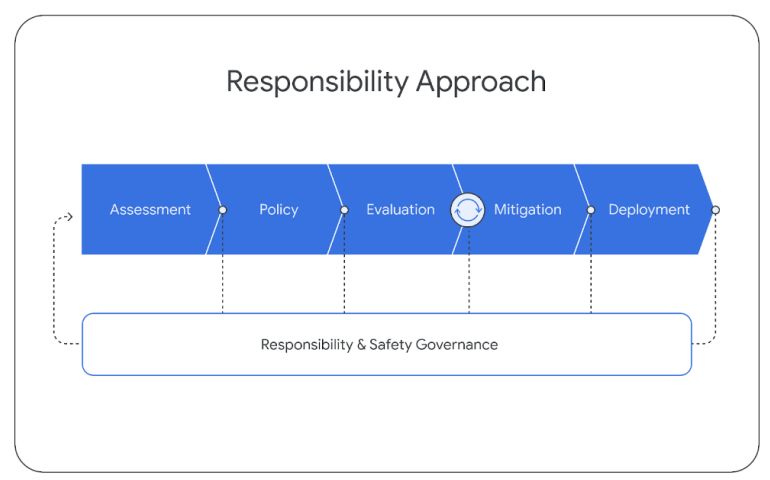
6.1. Оценка воздействия
Мы разрабатываем оценки воздействия моделей для выявления, оценки и документирования ключевых социальных выгод и вредов, связанных с разработкой усовершенствованных моделей Gemini. Они основаны на предыдущей научной литературе о рисках языковых моделей (Weidinger et al., 2021), результатах аналогичных предыдущих исследований, проведенных в отрасли (Anil et al., 2023; Anthropic, 2023; OpenAI, 2023a), постоянном взаимодействии с экспертами. внутренние и внешние, а также неструктурированные попытки обнаружить новые уязвимости модели. Области внимания включают: фактологию, безопасность детей, вредоносный контент, кибербезопасность, биориск, репрезентацию и инклюзивность. Эти оценки обновляются одновременно с разработкой моделей.
Оценка воздействия используется для руководства усилиями по смягчению последствий и доставке продуктов, а также для принятия решений по развертыванию. Оценка воздействия Gemini охватывала различные возможности моделей Gemini, оценивая потенциальные последствия этих возможностей с помощью принципов искусственного интеллекта Google (Google, 2023).
6.2. Модельная политика
Основываясь на этом понимании известных и ожидаемых эффектов, мы разработали набор «модельных политик», которые помогут управлять разработкой и оценкой моделей. Определения типовой политики действуют как стандартизированные критерии и схема определения приоритетов для ответственного развития, а также как показатель готовности к запуску. Политика модели Gemini охватывает ряд областей, в том числе: безопасность детей, разжигание ненависти, достоверность фактов, справедливость и инклюзивность, а также преследование.
6.3. Оценки
Чтобы сравнить модели Gemini с областями политики и другими ключевыми областями риска, выявленными в ходе оценки воздействия, мы разработали набор оценок на протяжении всего жизненного цикла разработки модели.
Оценки разработки проводятся с целью «восхождения на холм» на протяжении всего обучения и доводки моделей Gemini. Эти оценки разработаны командой Gemini или представляют собой оценку по внешним академическим критериям. При оценке учитываются такие вопросы, как полезность (следование инструкциям и творческий подход), безопасность и достоверность. Пример результатов см. в разделе 5.1.6 и следующем разделе, посвященном смягчению последствий.
Оценки достоверности проводятся в целях управления и анализа, обычно в конце ключевых этапов или тренингов группой, не входящей в группу разработчиков модели. Оценки достоверности стандартизированы по модальности, а наборы данных строго ограничены. В процесс обучения используются только знания высокого уровня, которые помогают в усилиях по смягчению последствий. Оценки гарантий включают тестирование политик Gemini, а также постоянное тестирование опасных возможностей, таких как потенциальные биологические опасности, убеждение и кибербезопасность (Шевлейн и др., 2023).
Внешние оценки проводятся партнерами за пределами Google для выявления «слепых зон». Внешние группы подвергают наши модели стресс-тестированию по ряду вопросов, в том числе по областям, перечисленным в обязательствах Белого дома[7], а тесты проводятся посредством сочетания структурированных оценок и неструктурированной красной команды. Эти оценки проводятся независимо, а результаты периодически передаются команде Google DeepMind.
В дополнение к этому набору внешних оценок внутренние группы специалистов проводят постоянное объединение наших моделей в таких областях, как политики Gemini и безопасность. Эти действия включают менее структурированные процессы, включающие сложные состязательные атаки для выявления новых уязвимостей. Обнаружение потенциальных слабых мест затем может быть использовано для снижения рисков и улучшения внутренних подходов к оценке. Мы стремимся обеспечить постоянную прозрачность моделей и планируем со временем публиковать дополнительные результаты из нашего пакета оценки.
6.4. Меры по смягчению последствий
Средства по смягчению последствий разрабатываются в ответ на результаты оценки, политики и подходов к оценке, описанных выше. Оценки и меры по смягчению последствий используются итеративно, при этом оценки повторяются после усилий по смягчению последствий. Ниже мы обсуждаем наши усилия по снижению вреда от модели с точки зрения данных, настройки инструкций и фактов.
6.4.1. Данные
До обучения мы предпринимаем различные шаги для смягчения потенциального последующего вреда на этапах обработки и сбора данных. Как обсуждалось в разделе «Данные обучения», мы фильтруем данные обучения на наличие контента с высоким уровнем риска и обеспечиваем достаточно высокое качество всех данных обучения. Помимо фильтрации, мы также принимаем меры для обеспечения того, чтобы все собранные данные соответствовали передовым практикам Google DeepMind по обогащению данных[8], разработанным на основе Партнерства по искусственному интеллекту «Ответственный поиск услуг по обогащению данных»[9]. Это включает в себя обеспечение того, чтобы все работники по обогащению данных получали зарплату не ниже местного прожиточного минимума.
6.4.2. Настройка инструкций
Настройка инструкций включает в себя точную настройку с учителем (SFT) и обучение с подкреплением посредством обратной связи с человеком (RLHF) с использованием модели вознаграждения. Мы применяем настройку инструкций как в текстовых, так и в мультимодальных настройках. Рецепты настройки инструкций тщательно разработаны, чтобы сбалансировать увеличение полезности с уменьшением вреда модели, связанного с безопасностью и галлюцинациями (Bai et al., 2022a).
Получение «качественных» данных имеет решающее значение для SFT, обучения модели вознаграждения и RLHF. Коэффициенты смешивания данных уменьшаются с помощью меньших моделей, чтобы сбалансировать показатели полезности (такие как следование инструкциям, креативность) и снижения вреда от модели, и эти результаты хорошо обобщаются на более крупные модели. Мы также заметили, что качество данных важнее количества (Touvron et al., 2023b; Zhou et al., 2023), особенно для более крупных моделей. Аналогичным образом, для обучения модели вознаграждения мы считаем крайне важным сбалансировать набор данных с примерами, в которых модель предпочитает говорить: «Я не могу с этим помочь» из соображений безопасности, и примерами, когда модель выдает полезные ответы. Для обучения многоцелевой модели вознаграждения мы используем многоцелевую оптимизацию со взвешенной суммой оценок вознаграждения за полезность, актуальность и безопасность.
Мы дополнительно разрабатываем наш подход к снижению рисков генерации вредоносного текста. Мы перечисляем около 20 типов вреда (например, разжигание ненависти, предоставление медицинских консультаций, предложение опасного поведения) в самых разных случаях использования. Мы генерируем набор данных по потенциально опасным запросам в этих категориях либо вручную экспертами по политике и инженерами ML, либо путем подсказки высокопроизводительных языковых моделей с актуальными ключевыми словами в качестве начальных значений.
Учитывая опасные запросы, мы проверяем наши модели Gemini и анализируем ответы моделей посредством параллельной оценки. Как обсуждалось выше, мы балансируем цель того, чтобы выходной ответ модели был безвредным и полезным. На основе обнаруженных областей риска мы создаем дополнительные контролируемые данные для точной настройки, чтобы продемонстрировать желаемые меры реагирования. Чтобы генерировать такие ответы в большом масштабе, мы в значительной степени полагаемся на рецепт создания пользовательских данных, вдохновленный Конституционным ИИ (Bai et al., 2022b), где мы внедряем варианты языка политики контента Google в качестве «конституций» и используем сильный ноль языковой модели. способности к рассуждению (Kojima et al., 2022), позволяющие пересматривать ответы и выбирать между несколькими вариантами ответа. Мы обнаружили, что этот рецепт эффективен — например, в Gemini Pro этот общий рецепт позволил смягчить большинство выявленных нами случаев повреждения текста без какого-либо заметного снижения полезности ответа.
6.4.3. Факты
Важно, чтобы наши модели генерировали ответы, которые соответствуют действительности в различных сценариях, и снижали частоту галлюцинаций. Мы сосредоточили усилия по настройке инструкций на трех ключевых желаемых вариантах поведения, отражающих реальные сценарии:
1. Атрибуция: если ему дано указание сгенерировать ответ, который должен быть полностью отнесен к заданному контексту в подсказке, Близнецы должны дать ответ с наивысшей степенью точности контексте (Рашкин и др., 2023). Это включает в себя обобщение предоставленного пользователем источника, создание детальных цитат с учетом вопроса и предоставленных фрагментов, подобных Menick et al. (2022 г.); Пэн и др. (2023), отвечая на вопросы из подробного источника, такого как книга (Михайлов и др., 2018), и преобразуя данный источник в желаемый результат (например, электронное письмо из части стенограммы встречи).
<сильный>2. Генерация ответов по закрытой книге: Если Близнецам предоставлена подсказка для поиска фактов без указания какого-либо источника, они не должны галлюцинировать неверную информацию (определение см. в разделе 2 работы Roberts et al. (2020)). Эти подсказки могут варьироваться от подсказок для поиска информации (например, «Кто является премьер-министром Индии?») до полутворческих подсказок, которые могут запрашивать фактическую информацию (например, «Напишите речь из 500 слов в пользу внедрения возобновляемых источников энергии». ).
<сильный>3. Хеджирование: Если на запрос введена информация, на которую «невозможно ответить», Близнецы не должны галлюцинировать. Скорее, ему следует признать, что он не может обеспечить ответ путем хеджирования. К ним относятся сценарии, в которых входное приглашение содержит вопросы с ложными предпосылками (см. примеры в Hu et al. (2023)), входное приглашение инструктирует модель выполнить контроль качества с открытой книгой, но ответ не может быть получен из данного контекста, и и так далее.
Мы выявили это желаемое поведение в моделях Gemini, собрав целевые наборы данных с контролируемой точной настройкой и выполнив RLHF. Обратите внимание, что полученные здесь результаты не включают предоставление Близнецам инструментов или поиска, которые предположительно могли бы повысить достоверность (Menick et al., 2022; Peng et al., 2023). Ниже мы приводим три ключевых результата по соответствующим наборам задач.
<сильный>1. Набор фактов: Набор оценок, содержащий подсказки для поиска фактов (в основном в закрытой книге). Это оценивается с помощью аннотаторов, которые вручную проверяют каждый ответ; мы сообщаем процент фактически неточных ответов по оценке комментаторов.
<сильный>2. Набор атрибуции: оценочный набор, содержащий различные подсказки, требующие указания источников в подсказке. Это оценивается с помощью аннотаторов, которые вручную проверяют принадлежность к источникам в запросе для каждого ответа; заявленный показатель — AIS (Рашкин и др., 2023).
<сильный>3. Набор хеджирования: автоматическая настройка оценки, с помощью которой мы определяем, моделирует ли Близнецы хеджирование
точно
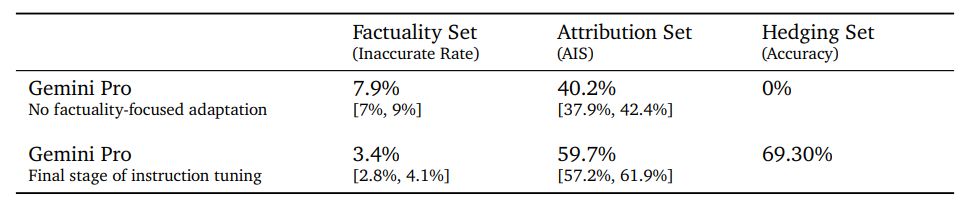
Мы сравниваем Gemini Pro с версией модели Gemini Pro, настроенной по инструкциям, без какой-либо адаптации, ориентированной на факты, в Таблице 14. Мы наблюдаем, что уровень неточностей снижается вдвое в наборе фактов, точность атрибуции увеличивается на 50% по сравнению с набором атрибуции. , и модель успешно хеджирует 70 % (вместо 0 %) в заданном наборе задач хеджирования.
6.5. Развертывание
После завершения проверок создаются карты моделей (Mitchell et al., 2019) для каждой утвержденной модели Gemini для структурированной и последовательной внутренней документации критических показателей производительности и ответственности, а также для информирования соответствующих внешних источников об этих показателях в течение время.
6.6. Ответственное управление
На протяжении всего процесса ответственной разработки мы проводим проверки этики и безопасности вместе с Советом по ответственности и безопасности Google DeepMind (RSC)[10] — междисциплинарной группой, которая оценивает проекты, документы и сотрудничество Google DeepMind на предмет соответствия принципам искусственного интеллекта Google. RSC предоставляет информацию и отзывы об оценках воздействия, политике, оценках и усилиях по смягчению последствий. В ходе проекта Gemini RSC установил конкретные цели оценки по ключевым областям политики (например, безопасность детей).
[7] https://whitehouse.gov/wp-content/uploads/2023/07/Ensuring-Safe-Secure-and-Trustworthy-AI.pdf
[8] https://deepmind.google/discover/blog/best-practices-for-data-enrichment/
[9] https://partnershiponai.org/responsible-source-considerations/
[10] https://deepmind.google/about/responsibility-safety/
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27482)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)