

Кодирование категориальных данных для алгоритмов ML
14 ноября 2022 г.В реальной жизни полученные необработанные данные редко имеют формат, который мы можем взять и использовать непосредственно для нашего машинного обучения. моделей. Поэтому необходима некоторая предварительная обработка, чтобы представить данные в правильном формате, выбрать информативные данные или уменьшить их размерность, чтобы получить максимальную отдачу от данных.
В этом посте мы поговорим о кодировании, чтобы иметь возможность использовать категориальные данные в качестве функций для наших моделей машинного обучения, типах кодирования и когда они подходят. Другие методы предварительной обработки для масштабирования объектов, выбора объектов и уменьшения размеров — это темы для другой статьи… Давайте начнем с кодирования!
Кодирование категориальных данных
Числовые данные, как следует из названия, содержат только числа (целые числа или числа с плавающей запятой). С другой стороны, категориальные данные имеют переменные, которые содержат значения меток (текст), а не числовые значения. Модели машинного обучения могут принимать только числовые входные переменные. Что произойдет, если у нас есть набор данных с категориальными данными вместо числовых данных?
Затем нам нужно преобразовать данные, содержащие категориальные переменные, в числа, прежде чем мы сможем обучить модель машинного обучения. Это называется кодированием.
Двумя наиболее популярными методами кодирования являются порядковое кодирование и горячее кодирование.
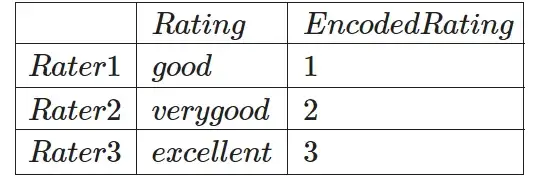
* Порядковое кодирование: этот метод используется для кодирования категориальных переменных, которые имеют естественный порядок ранжирования. Бывший. хорошо, очень хорошо, отлично можно закодировать как 1,2,3.
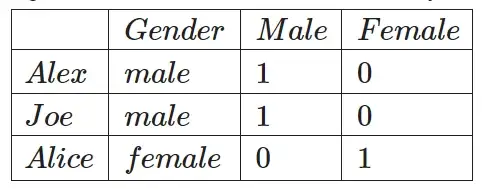
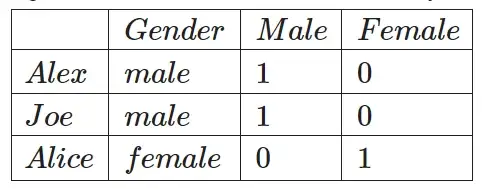
- Горячее кодирование: этот метод используется для кодирования категориальных переменных, которые не имеют естественного порядка ранжирования. Бывший. Мужчина или женщина не имеют никакого порядка между ними.
Порядковое кодирование
В этом методе каждой категории присваивается целочисленное значение. Бывший. Майами — 1, Сидней — 2, а Нью-Йорк — 3. Однако важно понимать, что это ввело порядковый номер в данные, которые модели машинного обучения попытаются использовать для поиска взаимосвязей в данных. Следовательно, использование этих данных там, где не существует порядковой связи (ранжирование между категориальными переменными), не является хорошей практикой. Возможно, как вы уже поняли, пример, который мы только что использовали для городов, на самом деле не очень хорошая идея. Потому что между Майами, Сиднеем и Нью-Йорком нет ранжирования. В этом случае кодировщик One-Hot будет лучшим вариантом, который мы увидим в следующем разделе.
Давайте создадим лучший пример для порядкового кодирования.
Преобразование порядкового номера доступно в библиотеке scikit-learn. Итак, давайте воспользуемся классом OrdinalEncoder для создания небольшого примера:
# example of a ordinal encoding
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# define data
data = np.asarray([['good'], ['very good'], ['excellent']])
df = pd.DataFrame(data, columns=["Rating"], index=["Rater 1", "Rater 2", "Rater 3"])
print("Data before encoding:")
print(df)
# define ordinal encoding
encoder = OrdinalEncoder()
# transform data
df["Encoded Rating"] = encoder.fit_transform(df)
print("nData after encoding:")
print(df)
Data before encoding:
Rating
Rater 1 good
Rater 2 very good
Rater 3 excellent
Data after encoding:
Rating Encoded Rating
Rater 1 good 1.0
Rater 2 very good 2.0
Rater 3 excellent 0.0
В этом случае кодировщик присвоил целочисленные значения в алфавитном порядке, как в случае с текстовыми переменными. Хотя обычно нам не нужно явно определять порядок категорий, поскольку алгоритмы машинного обучения в любом случае смогут извлечь взаимосвязь, для этого примера мы можем определить явный порядок категорий, используя переменную категорий OrdinalEncoder.
import numpy as np
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# define data
data = np.asarray([['good'], ['very good'], ['excellent']])
df = pd.DataFrame(data, columns=["Rating"], index=["Rater 1", "Rater 2", "Rater 3"])
print("Data before encoding:")
print(df)
# define ordinal encoding
categories = [['good', 'very good', 'excellent']]
encoder = OrdinalEncoder(categories=categories)
# transform data
df["Encoded Rating"] = encoder.fit_transform(df)
print("nData after encoding:")
print(df)
Data before encoding:
Rating
Rater 1 good
Rater 2 very good
Rater 3 excellent
Data after encoding:
Rating Encoded Rating
Rater 1 good 0.0
Rater 2 very good 1.0
Rater 3 excellent 2.0
Кодировка ярлыка
Класс LabelEncoder из scikit-learn используется для кодирования целевых меток в наборе данных. На самом деле он делает то же самое, что и OrdinalEncoder, однако ожидает только одномерный ввод, что очень удобно при кодировании целевых меток в наборе данных.
Горячее кодирование
Как мы упоминали ранее, для категорийных данных, в которых нет порядкового отношения, порядковое кодирование не является подходящим методом, поскольку оно приводит к тому, что модель ищет отношения естественного порядка в категорийных данных, которые на самом деле не существуют и могут ухудшить производительность модели.
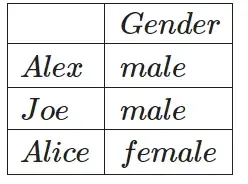
Здесь в игру вступает кодировка One-Hot. Этот метод работает путем создания нового столбца для каждой уникальной категориальной переменной в данных и представления наличия этой категории с использованием двоичного представления (0 или 1). Глядя на предыдущий пример:
Простая таблица преобразуется в следующую таблицу, в которой у нас есть новый столбец, представляющий каждую уникальную категориальную переменную (мужчину и женщину), и двоичное значение, которое нужно отметить, если оно существует для этого.
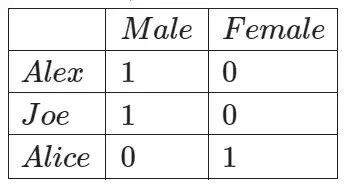
Как и класс OrdinalEncoder, библиотека scikit-learn также предоставляет нам класс OneHotEncoder, который мы можем использовать для кодирования категориальных данных. Давайте используем его для кодирования простого примера:
from sklearn.preprocessing import OneHotEncoder
# define data
data = np.asarray([['Miami'], ['Sydney'], ['New York']])
df = pd.DataFrame(data, columns=["City"], index=["Alex", "Joe", "Alice"])
print("Data before encoding:")
print(df)
# define onehot encoding
categories = [['Miami', 'Sydney', 'New York']]
encoder = OneHotEncoder(categories='auto', sparse=False)
# transform data
encoded_data = encoder.fit_transform(df)
#fit_transform method return an array, we should convert it to dataframe
df_encoded = pd.DataFrame(encoded_data, columns=encoder.categories_, index= df.index)
print("nData after encoding:")
print(df_encoded)
Data before encoding:
City
Alex Miami
Joe Sydney
Alice New York
Data after encoding:
Miami New York Sydney
Alex 1.0 0.0 0.0
Joe 0.0 0.0 1.0
Alice 0.0 1.0 0.0
Как мы видим, кодировщик сгенерировал новый столбец для каждой уникальной категориальной переменной и присвоил 1, если она существует для этого конкретного образца, и 0, если ее нет. Это мощный метод кодирования непорядковых категориальных данных. Однако у него также есть свои недостатки… Как вы можете себе представить, для набора данных со многими уникальными категориальными переменными однократное горячее кодирование приведет к огромному набору данных, потому что каждая переменная должна быть представлена новым столбцом.
Например, если бы у нас был столбец/функция с 10 000 уникальных категориальных переменных (высокая кардинальность), однократное кодирование привело бы к 10 000 дополнительных столбцов, что привело бы к очень разреженной матрице и огромному увеличению потребления памяти и вычислительных затрат (что также называется проклятием размерности). Для работы с категориальными функциями с высокой кардинальностью мы можем использовать целевое кодирование…
Целевая кодировка
Целевое кодирование (также называемое средним кодированием) – это метод, при котором количество вхождений категориальной переменной учитывается вместе с целевой переменной для кодирования категориальных переменных в числовые значения. По сути, это процесс, в котором мы заменяем категориальную переменную средним значением целевой переменной. Мы можем лучше объяснить это на простом примере набора данных…
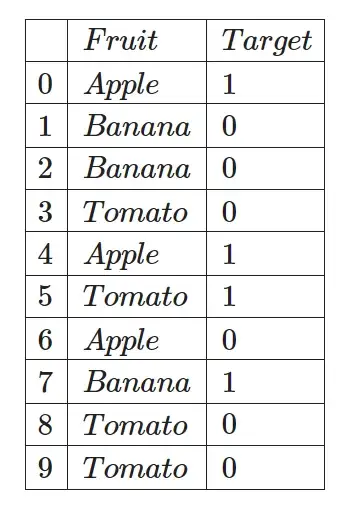
Сгруппируйте таблицу для каждой категориальной переменной, чтобы рассчитать ее вероятность для цели = 1:

Затем мы берем эти вероятности, рассчитанные для target=1, и используем их для кодирования данной категориальной переменной в наборе данных:
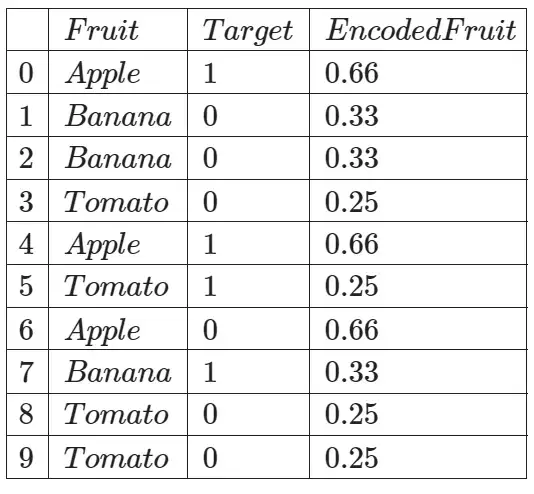
Подобно порядковому кодированию и горячему кодированию, мы можем использовать класс TargetEncoder, но на этот раз мы импортируем его из библиотеки category_encoders:
from category_encoders import TargetEncoder
# define data
fruit = ["Apple", "Banana", "Banana", "Tomato", "Apple", "Tomato", "Apple", "Banana", "Tomato", "Tomato"]
target = [1, 0, 0, 0, 1, 1, 0, 1, 0, 0]
df = pd.DataFrame(list(zip(fruit, target)), columns=["Fruit", "Target"])
print("Data before encoding:")
print(df)
# define target encoding
encoder = TargetEncoder(smoothing=0.1) #smoothing effect to balance categorical average vs prior.Higher value means stronger regularization.
# transform data
df["Fruit Encoded"] = encoder.fit_transform(df["Fruit"], df["Target"])
print("nData after encoding:")
print(df)
Data before encoding:
Fruit Target
0 Apple 1
1 Banana 0
2 Banana 0
3 Tomato 0
4 Apple 1
5 Tomato 1
6 Apple 0
7 Banana 1
8 Tomato 0
9 Tomato 0
Data after encoding:
Fruit Target Fruit Encoded
0 Apple 1 0.666667
1 Banana 0 0.333333
2 Banana 0 0.333333
3 Tomato 0 0.250000
4 Apple 1 0.666667
5 Tomato 1 0.250000
6 Apple 0 0.666667
7 Banana 1 0.333333
8 Tomato 0 0.250000
9 Tomato 0 0.250000
Мы получили ту же таблицу, которую рассчитали вручную сами…
Преимущества целевой кодировки
Целевое кодирование — это простой и быстрый метод, который не добавляет дополнительную размерность набору данных. Таким образом, это хороший метод кодирования для наборов данных, включающих функции с высокой кардинальностью (уникальные категориальные переменные более 10 000).
Недостатки целевой кодировки
Целевое кодирование использует распределение целевой переменной, что может привести к переобучению и утечке данных. Утечка данных в том смысле, что мы используем целевые классы для кодирования функции, может привести к предвзятому отображению функции. Вот почему при инициализации класса существует параметр сглаживания. Этот параметр помогает нам уменьшить эту проблему (в нашем примере выше мы намеренно установили его на очень маленькое значение, чтобы получить те же результаты, что и при ручном расчете).
В этом посте мы рассмотрели методы кодирования для преобразования категорийных данных в числовые данные, чтобы иметь возможность использовать их в качестве функций в наших моделях машинного обучения!
Если вам понравился этот контент, не стесняйтесь подписываться на меня, чтобы получать больше бесплатных руководств и курсов по машинному обучению!
Также опубликовано здесь. п
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)