

Deepmind AI выпускает DeepNash: The Stratego Conqueror!
3 декабря 2022 г.Настольные игры исторически служили оценкой развития ИИ, потому что они дают нам контролируемую среду для анализа того, как люди и роботы формулируют и осуществляют тактику. ИИ обыграл людей в го, шахматах, покере и нардах.

Ли Седол, южнокорейский профессиональный игрок в го с рангом 9 дан, потерпел поражение от Google Deepmind AI. программное обеспечение, AlphaGo, 19 марта 2016 г. Это стало историческим достижением для ИИ; AlphaGo выиграла серию из пяти игр со счетом 4:1.

Но это еще не все!😉
В июле 2022 года компания DeepMind представила DeepNash — многоагентную систему обучения с подкреплением без использования моделей, которая может превзойти людей в настольной игре Stratego.
Классическая настольная игра Stratego, которая сложнее, чем покер, и сложнее, чем шахматы и го, теперь усовершенствована.
Что такое Stratego?
Стратего — это игра со скрытой информацией, более сложная, чем шахматы, го и покер.
Стратего — одна из немногих известных настольных игр, в которых искусственный интеллект еще не довел до совершенства. Это сложная игра, которая требует как долгосрочного стратегического мышления, так и умения работать с неполной информацией, как в покере.
Настольная игра Stratego, впервые опубликованная в 1947 году, с тех пор претерпела несколько изменений и уже давно привлекает внимание исследователей искусственного интеллекта.

Примечание. Цель игры — захватить флаг противника, которым владеет каждая армия.
Настройка игры
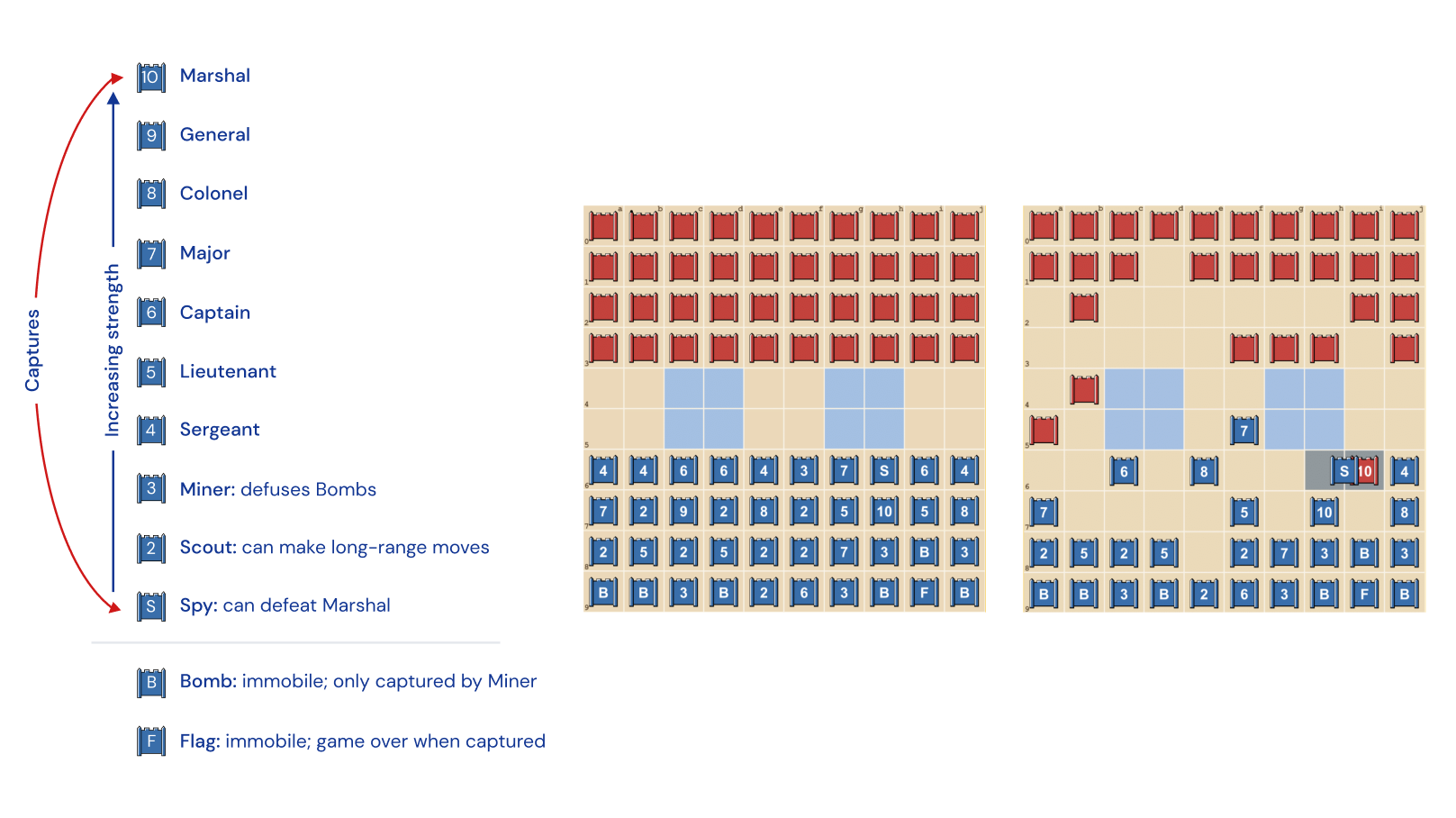
- Слева: рейтинг работы. 10 (Маршал) проигрывают в битвах, когда на них нападает Шпион, а Бомбы всегда побеждают, если они не взяты в плен Шахтером. Части более высокого ранга всегда преобладают.
- Посередине: возможный стартовый состав. Обратите внимание, как флаг надежно спрятан на заднем плане, окруженный беспомощными бомбами. В «озера» двух бледно-голубых секций никто не заходит.
- Справа: кадры, на которых Шпион Синих ловит 10 Красных в игре.

Правила: как играть в Stratego
- Выберите, кто из игроков будет командовать Красной армией, а кто — Синей армией.
- Красная Армия всегда наносит удар первой.
- Поставьте синего игрока синей стороной игрового поля вперед, а красного игрока — красной стороной.
- Каждый игрок размещает по одной из своих 30 фишек в каждом из первых трех рядов перед собой на доске (10 в ширину и 3 в глубину). Свободны только две центральные строки.
- Только командующий каждой армией должен иметь возможность видеть, где находится его или ее фишка, потому что каждая фишка стороной "S" должна быть обращена к противостоящему игроку.
https://youtube.com/shorts/zBEBpuRAuBE?feature=share?embedable=true
Примечание. Исходное расположение вашей армии имеет решающее значение и может повлиять на победу или поражение.
<цитата>Чтобы увидеть больше, нажмите здесь
DeepNash: искусственный интеллект Stratego
Глубокое обучение с подкреплением и теория игр без моделей являются основой инновационной методологии DeepNash. Его стиль игры сходится к равновесию Нэша, из-за чего противнику очень трудно им воспользоваться. DeepNash так усердно работала, что в настоящее время входит в тройку лучших экспертов по людям на Gravon< /strong>, крупнейшая онлайн-платформа Stratego в мире. Игроки в Stratego не имеют прямого доступа к фигурам своих противников, что делает игру идеальной информацией.
В Stratego информацию нужно зарабатывать. Обычно фигура, принадлежащая противнику, не раскрывается до тех пор, пока она не соприкоснется с этим игроком на поле боя. Это резко контрастирует с играми с полной информацией, такими как шахматы или го, где оба игрока знают о местонахождении и идентичности каждой фигуры. Рассуждения в Stratego должны выполняться на основе большого количества последовательных действий без очевидного понимания того, как каждое действие влияет на результат.
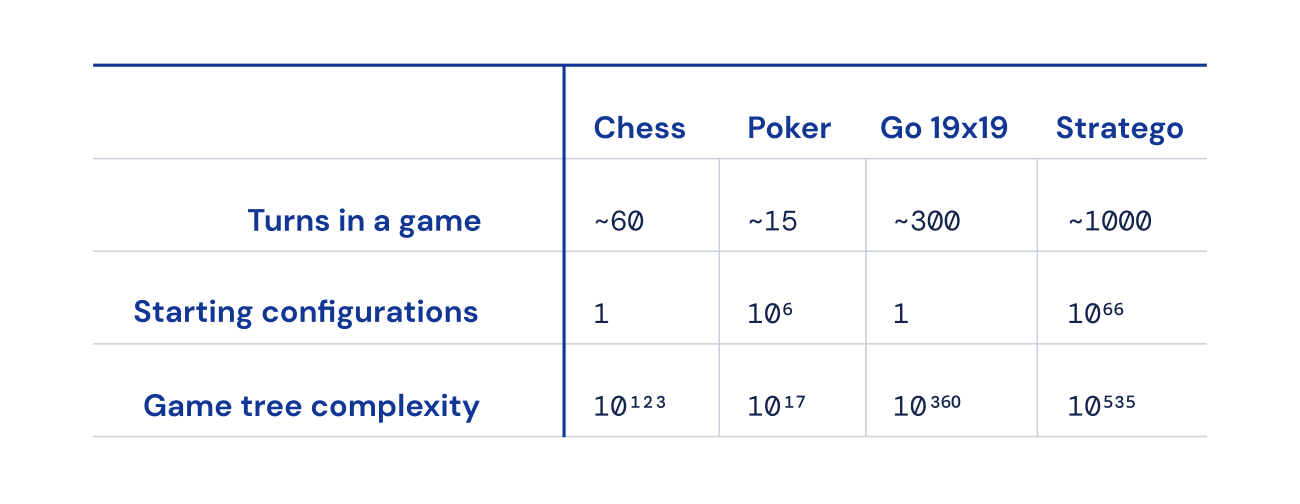
Стратего чрезвычайно сложно решить, поскольку может возникнуть очень много различных игровых состояний (представленных как «сложность игрового дерева» по сравнению с шахматами, го и покером). Вот почему он понравился DeepMind и вот почему на протяжении многих лет он бросал вызов сообществу ИИ.
В реальном мире DeepNash может изменить правила игры. Его методы могут быть обобщены, чтобы помочь решить проблемы, часто характеризующиеся несовершенными знаниями и непредсказуемыми сценариями, такими как оптимизация управления дорожным движением для сокращения времени вождения и т.д. выбросы транспортных средств.
<цитата>Чтобы узнать больше о DeepNash: нажмите . Здесь
п
н
п
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27556)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)