

Менеджеры продуктов данных и сетка данных
2 марта 2022 г.В 2019 году распределенная сетка данных была предложена компаниям как способ масштабного использования данных. Было предложено, чтобы архитектура платформы корпоративных данных следующего поколения представляла собой конвергенцию распределенной архитектуры, управляемой предметной областью, дизайна платформы самообслуживания и мышления продукта с данными. Одной из центральных идей этой парадигмы является обращение с «данными предметной области» как с продуктом и внедрение архитектуры сетки данных.

Однако для предприятий с крупными централизованными ИТ-организациями распределение платформы данных по доменам будет длительным процессом или даже немыслимым. Для этих организаций создание продуктов данных без «сетки» является более практичным и выполнимым.
В следующих абзацах концепция продукта данных заимствована и адаптирована у Zhamak Dehgani с использованием существующих архитектур озер и хранилищ данных.
Центральное место в создании информационных продуктов занимает идентификация их жизненного цикла. Взяв за основу SDLC, жизненный цикл продукта данных имеет схожие этапы, включая сбор требований и технико-экономическое обоснование, разработку конвейера данных, тестирование, развертывание и постоянное улучшение.
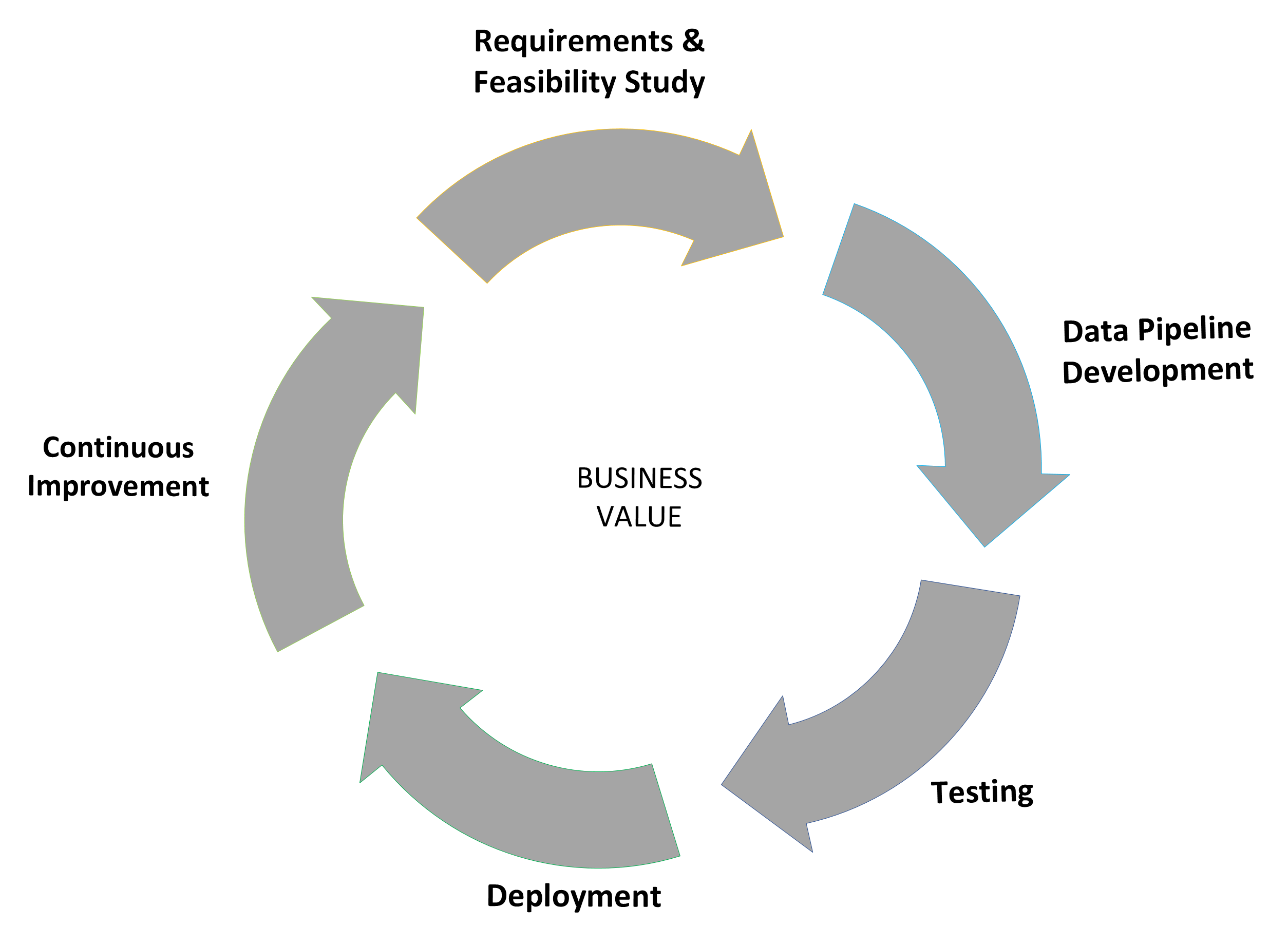
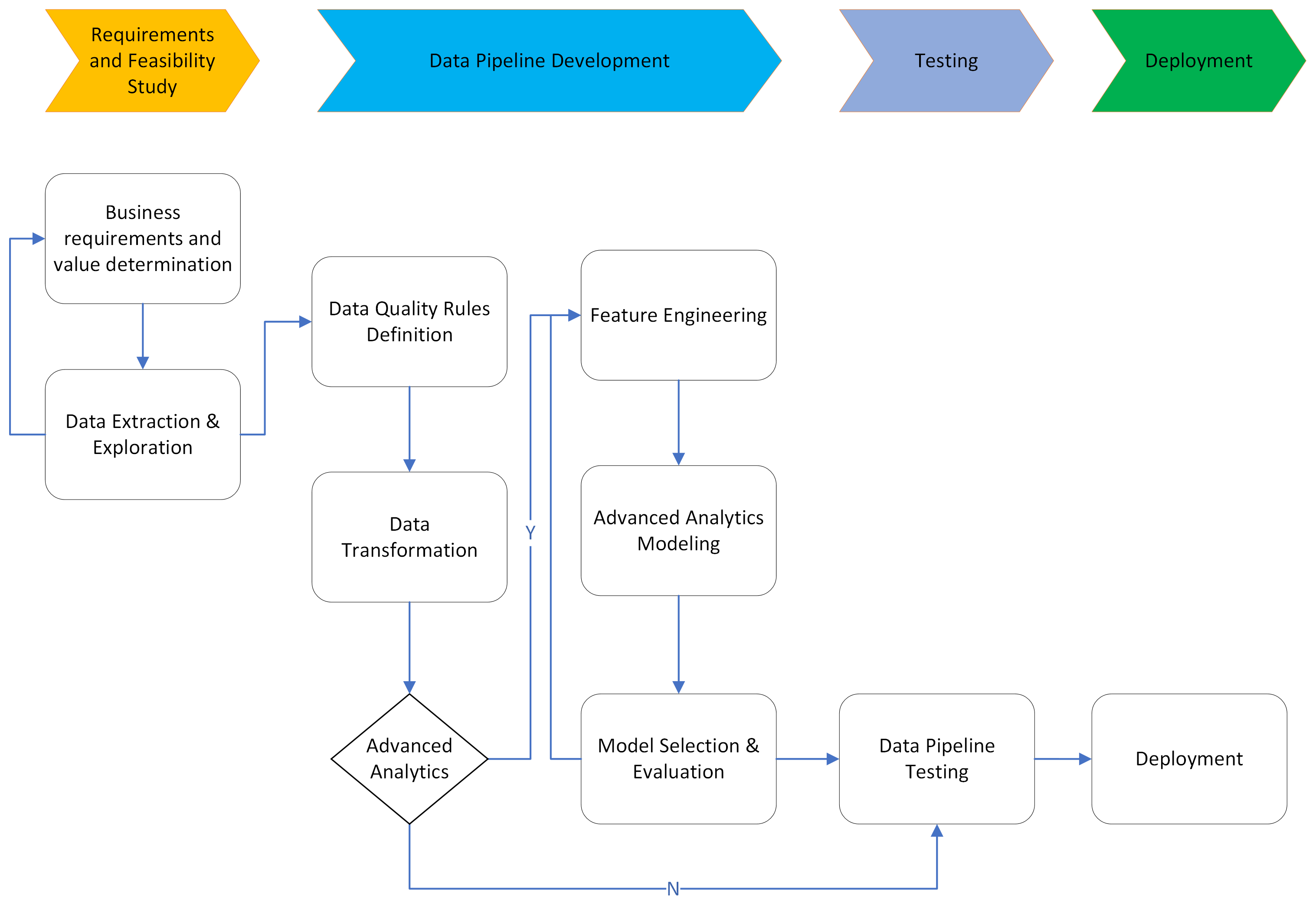
Процесс разработки продукта данных может быть доработан для поддержки продуктов: открытых необработанных или преобразованных данных, операциональных идей, открытой аналитической модели и автоматизированного принятия решений.
Чтобы раскрыть тайну состава продукта данных — ниже показана его структура, состоящая из входных данных (могут быть в нескольких форматах), кода или конвейера данных для доставки выходных данных (также может быть в нескольких форматах), и среда, в которой находятся эти три компонента.
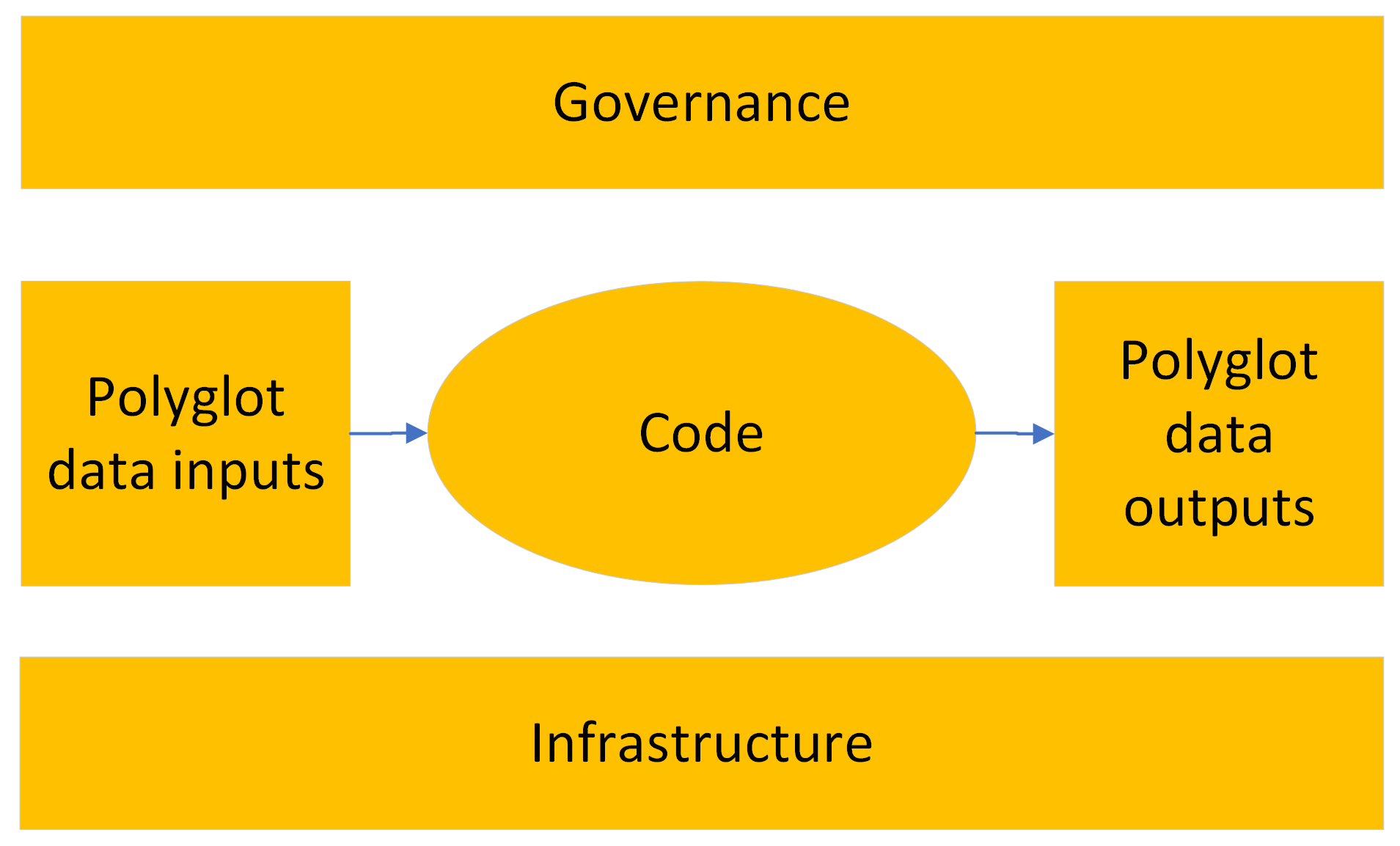
Продукт данных может иметь различные входные данные (некоторые из них представляют собой плоские файлы, некоторые — API, некоторые — прямые подключения к базе данных), которые преобразуются в необходимые выходные данные с помощью бизнес-правил или вычислительного алгоритма. В зрелых случаях использования выходные данные доставляются через разные «выходные порты», чтобы максимизировать их ценность. Выход продукта данных или «порты вывода» может осуществляться через API, извлечения на основе файлов, автоматические триггеры или решения или визуализации.
Эта анатомия в некотором роде также раскрывает необходимые навыки разработчиков информационных продуктов. В команду разработчиков должны входить участники, обладающие опытом в области управления, инфраструктуры, приема данных, преобразования данных, машинного обучения и сквозного конвейера данных. Эффективная команда по продуктам данных должна сочетать эти навыки с инфраструктурой, будь то облачная или локальная. Хотя вокруг переноса всего в облако много шумихи, команды по продуктам данных должны быть гибкими в процессе разработки, развертывания и постоянного совершенствования.
Кроме того, владельцы информационных продуктов, работающие в бизнес-сфере предприятия, должны помнить об этой анатомии. В отличие от традиционных групп разработчиков программного обеспечения, где запросы функций могут быть разбиты на очень гибкое выполнение, в разработке продукта данных это может быть непросто.
Вместо инфраструктуры сетки данных озеро данных и хранилище данных могут быть организованы в соответствии с доменами хранимых данных. Это позволит упростить продукты данных, ориентированные на предметную область. После этого междоменные информационные продукты станут вопросом политики и управления.
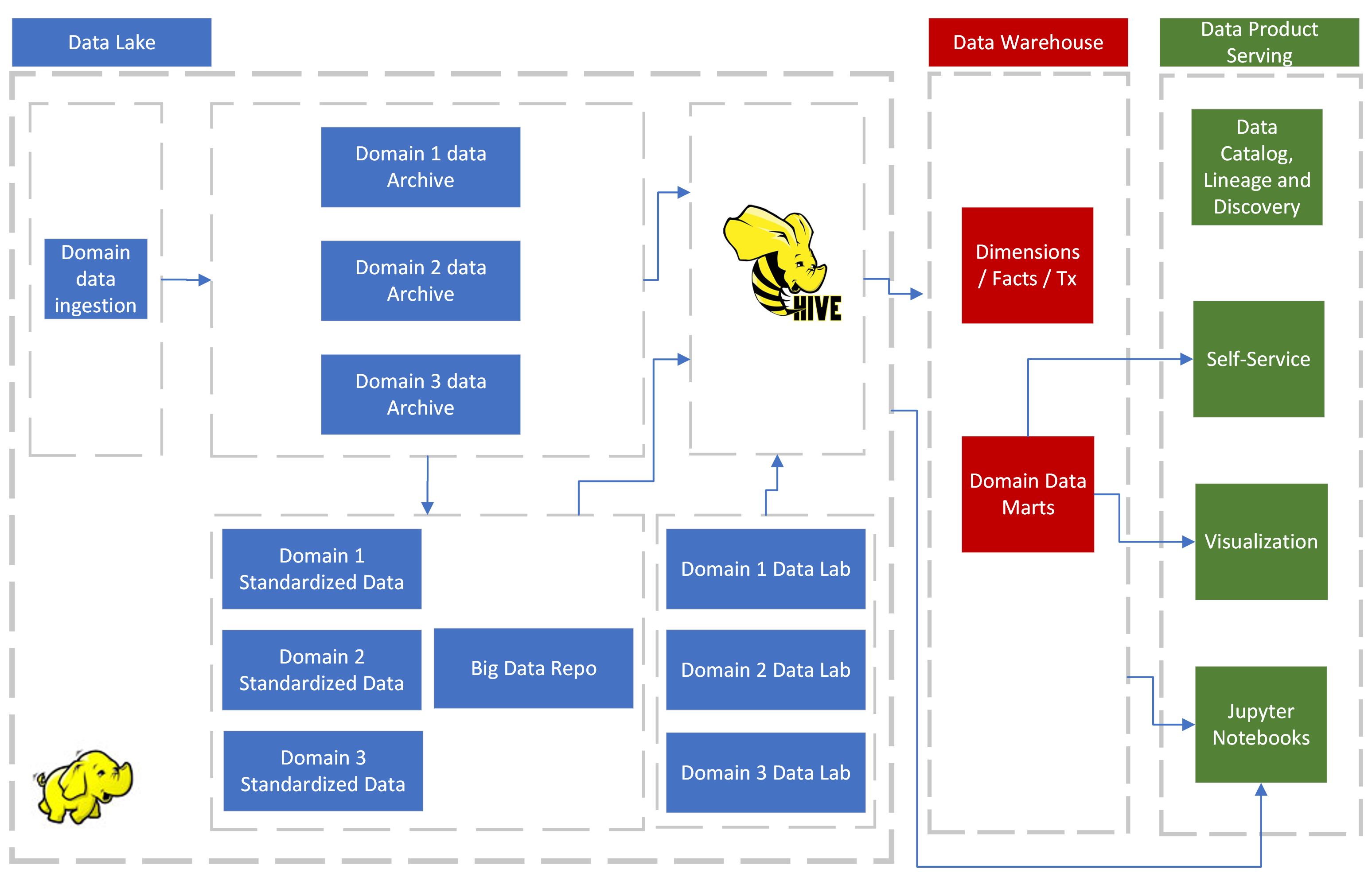
Без перераспределения существующих централизованных озер и хранилищ данных продукты, ориентированные на предметные области, могут поставляться с тщательно продуманной организацией данных. Hive можно использовать для виртуализации данных для организации данных по доменам.
Поскольку данные становятся очень распространенными на предприятии, правильное определение продукта данных, его жизненного цикла и процесса разработки теперь должно быть частью корпоративного процесса. При этом можно измерить реальную ценность данных через ценность продуктов данных, можно внедрить управление (при поддержке индивидуальных экспериментов), а также можно обнаружить возможности для монетизации.
- Впервые опубликовано [здесь] (https://medium.com/@rbahaguejr/building-data-products-without-the-mesh-5a1d5c617637?source=rss)*
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)