

Составные ключи: руководство по обращению с ними
15 января 2024 г.Составные ключи — это когда комбинация данных требуется для определения «ключа» для вашей карты или поиска в кэше. Примером этого может быть ситуация, когда вам необходимо кэшировать значения на основе имени клиента, а также роли пользователя. В таком случае ваш кеш должен иметь возможность хранить уникальные значения на основе каждого из этих двух (или более) критериев.
Существует несколько способов обработки составных ключей в коде.
Объедините критерии в строку
Первый ответ, к которому чаще всего обращаются, — это объединение критериев в строку, которая будет использоваться в качестве ключа. Это просто и не требует особых усилий:
private String getMapKey(Long userId, String userLocale) {
return userId + "." userLocale;
}
Это довольно простой способ решения проблемы. Использование строкового ключа может упростить отладку и исследование, поскольку ключ кэша имеет удобочитаемый формат. Но при таком подходе есть несколько проблем, о которых следует знать:
- При каждом взаимодействии с картой необходимо создавать новую строку. Хотя это выделение строк, как правило, невелико, если к карте обращаются часто, это может привести к большому количеству выделений, которые занимают время и требуют сборки мусора. Размер выделения строки также может быть больше в зависимости от размера или количества компонентов вашего ключа.
2. Вам необходимо убедиться, что созданный вами составной ключ не может быть подделан другим значением ключа:
public String getMapKey(Integer groupId, Integer accessType) {
return groupId.toString() + accessType.toString();
}
В приведенном выше примере, если у вас groupId = 1 и accessType = 23, это будет тот же ключ кэша, что и groupId = 12 и accessType = 3. Добавляя символ-разделитель между строками, вы можете предотвратить такое перекрытие. Но будьте осторожны с необязательными частями ключа:
public String getMapKey(String userProvidedString, String extensionName) {
return userProvidedString + (extensionName == null ? "" : ("." + extensionName));
}
В приведенном выше примере ExtensionName является необязательной частью ключа. Если расширениеName является необязательным, userProvidedString может включать разделитель и допустимое имя расширения и получить доступ к данным кэша, к которым у него не должно было быть доступа.
При использовании строк вам нужно подумать о том, как вы объединяете данные, чтобы избежать конфликтов в ключах. Особенно в случае ввода ключа пользователем.
Использовать вложенные карты/кеши
Другой вариант — вообще не комбинировать ключи, а вместо этого вложить структуры данных (Карты Карт Карт):
Map<Integer, Map<String, String>> groupAndLocaleMap = new HashMap<>();
groupAndLocaleMap.computeIfAbsent(userId, k -> new HashMap()).put(userLocale, mapValue);
Преимущество этого подхода состоит в том, что при взаимодействии с картами не требуется выделять новую память, поскольку переданные значения для ключей уже выделены. И хотя вам придется выполнить несколько поисков, чтобы получить окончательное значение, карты будут меньше.
Но недостатком этого подхода является то, что чем глубже происходит вложение, тем сложнее он становится. Даже имея всего два уровня, инициализация карты может показаться запутанной. Когда вы начинаете иметь дело с тремя или более фрагментами данных, это может привести к тому, что ваш код станет очень многословным. Кроме того, на каждом уровне требуется проверка на null, чтобы избежать нулевых указателей.
Некоторые «ключевые части» также могут не работать в качестве ключа карты. Массивы или коллекции не имеют методов равенства по умолчанию, которые сравнивают их содержимое. Таким образом, вам придется либо реализовать их, либо использовать другую альтернативу.
Использование вложенных карт также может стать менее эффективным использованием пространства в зависимости от того, насколько уникален каждый уровень ваших ключей.
Создание составного ключевого объекта
Последний вариант — вместо объединения значений ключа в строку создайте собственный объект для ключа:
private class MapKey {
private final int userId;
private final String userLocale;
public MapKey(int userId, String userLocale) {
this.userId = userId;
this.userLocale = userLocale;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MapKey mapKey = (MapKey) o;
return userId == mapKey.userId && Objects.equals(userLocale, mapKey.userLocale);
}
@Override
public int hashCode() {
return Objects.hash(userId, userLocale);
}
}
Хотя каждое взаимодействие по-прежнему требует нового выделения памяти для нового объекта. Распределение ключа объекта значительно меньше, чем необходимое для составной строки. Причина этого в том, что части, составляющие ключ, не нужно перераспределять в виде строк. Вместо этого только ключ объекта-обертки требует новой памяти.
Объект составного ключа также может позволять настраивать реализацию равенства ключей и хэш-кода. Например, игнорирование заглавных букв в строке или использование массива или коллекции как части ключа.
Однако недостатком здесь является то, что для этого, опять же, требуется гораздо больше кода, чем для составной строки. И для этого необходимо убедиться, что у вас есть действительные эквиваленты и контракты хэш-кода в ключевом классе вашей карты.
Так что же мне выбрать?
Вообще говоря, я бы предложил использовать составной строковый ключ. Он прост и понятен, требует минимум кода и его легче отладить в дальнейшем. Хотя это, вероятно, самый медленный вариант, написание простого, читаемого кода, как правило, более важно, чем преимущества, которые вы получите, используя один из двух других вариантов. Помните:
<блок-цитата>«Преждевременная оптимизация — корень всех зол», Дональд Кнут
Если у вас нет доказательств или оснований полагать, что поиск по карте/кэшу станет узким местом в производительности, выберите удобочитаемость.
Но если вы находитесь в ситуации, когда пропускная способность вашей карты или кэша очень высока, возможно, было бы полезно переключиться на один из двух других вариантов. Давайте посмотрим, как все три сравниваются друг с другом по производительности, а также по размеру выделяемой памяти.
Чтобы протестировать три приведенных выше сценария, я написал код, который воспроизводит одну и ту же реализацию всех трех сценариев для составного ключа. Сам ключ состоит из целочисленного значения, строкового значения и длинного значения. Все три реализации использовали одни и те же тестовые данные при каждом запуске для создания ключей.
Все прогоны выполнялись с 1 миллионом записей в карте (использовалась хэш-карта Java). Было выполнено 3 прогона для создания ключа с разными комбинациями размеров ключей:
* 100 целых чисел, 100 строк, 100 длинных значений — 1 миллион уникальных ключей * 1 целое число, 1 строка, 1 000 000 длинных значений — 1 миллион уникальных ключей. * 1 000 000 целых чисел, 1 строка, 1 длина — 1 миллион уникальных ключей
Во-первых, давайте посмотрим, сколько места каждая карта занимает в куче. Это важно, поскольку от этого зависит, сколько памяти потребуется для запуска вашего приложения.
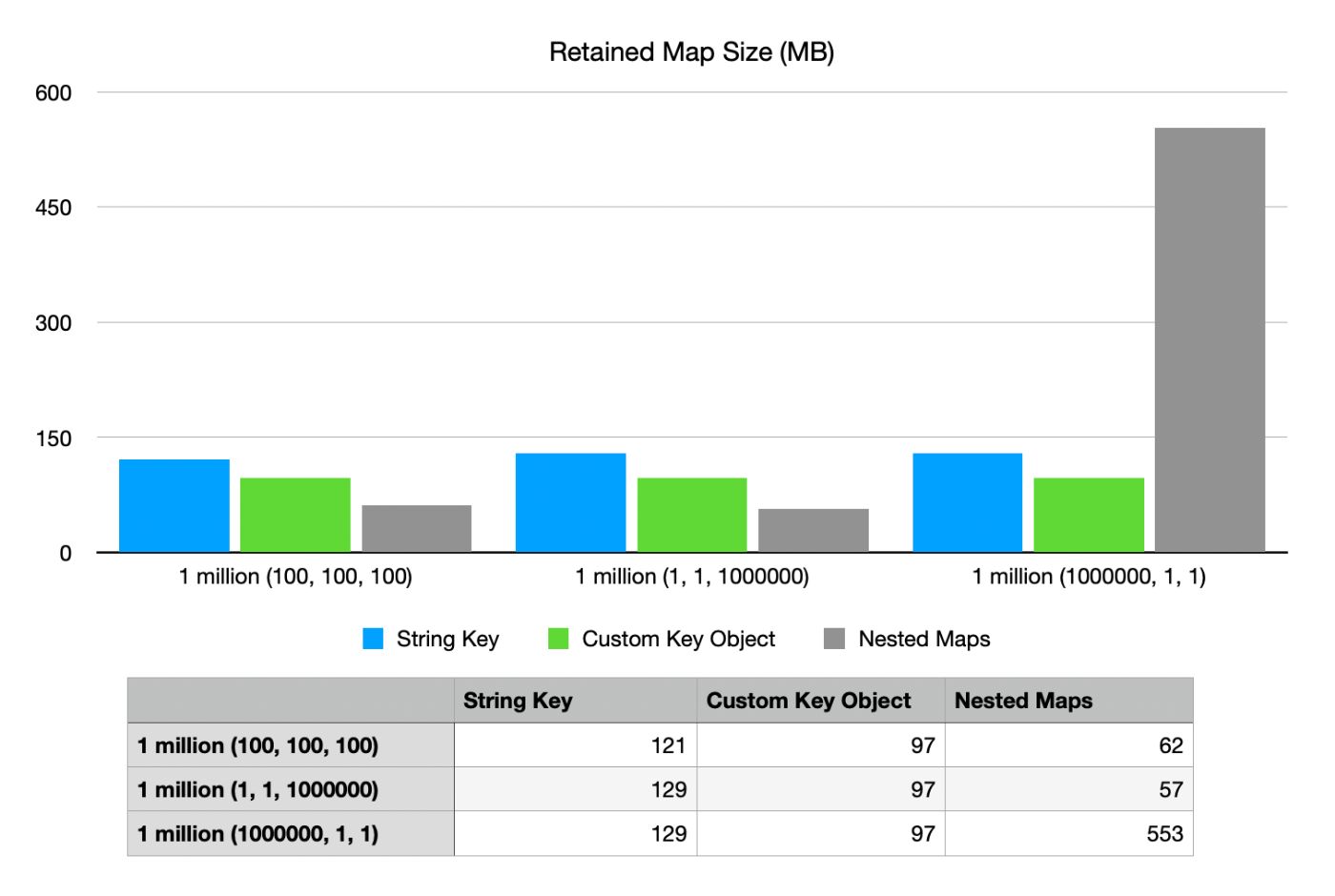
Здесь следует сделать одно интересное и очевидное замечание: в последнем сценарии (1 000 000 целых чисел) размер вложенных карт значительно больше, чем в остальных. Это связано с тем, что в этом сценарии вложенные карты создают 1 карту первого уровня с 1 миллионом записей. Затем для второго и третьего уровней создается 1 миллион карт только с одной записью.
Все эти вложенные карты содержат дополнительные накладные расходы и по большей части пусты. Очевидно, это крайний случай, но я хотел показать его, чтобы подчеркнуть свою точку зрения. При использовании реализации карт гнезд уникальность (и порядок этой уникальности) имеет большое значение.
Если вы измените порядок на 1, 1, 1 миллион, вы фактически получите наименьшие требования к объему памяти.
В двух других сценариях вложенное сопоставление является наиболее эффективным: объект пользовательского ключа идет на втором месте, а строковые ключи — на последнем.
Далее давайте посмотрим, сколько времени потребуется на создание каждой из этих карт с нуля:
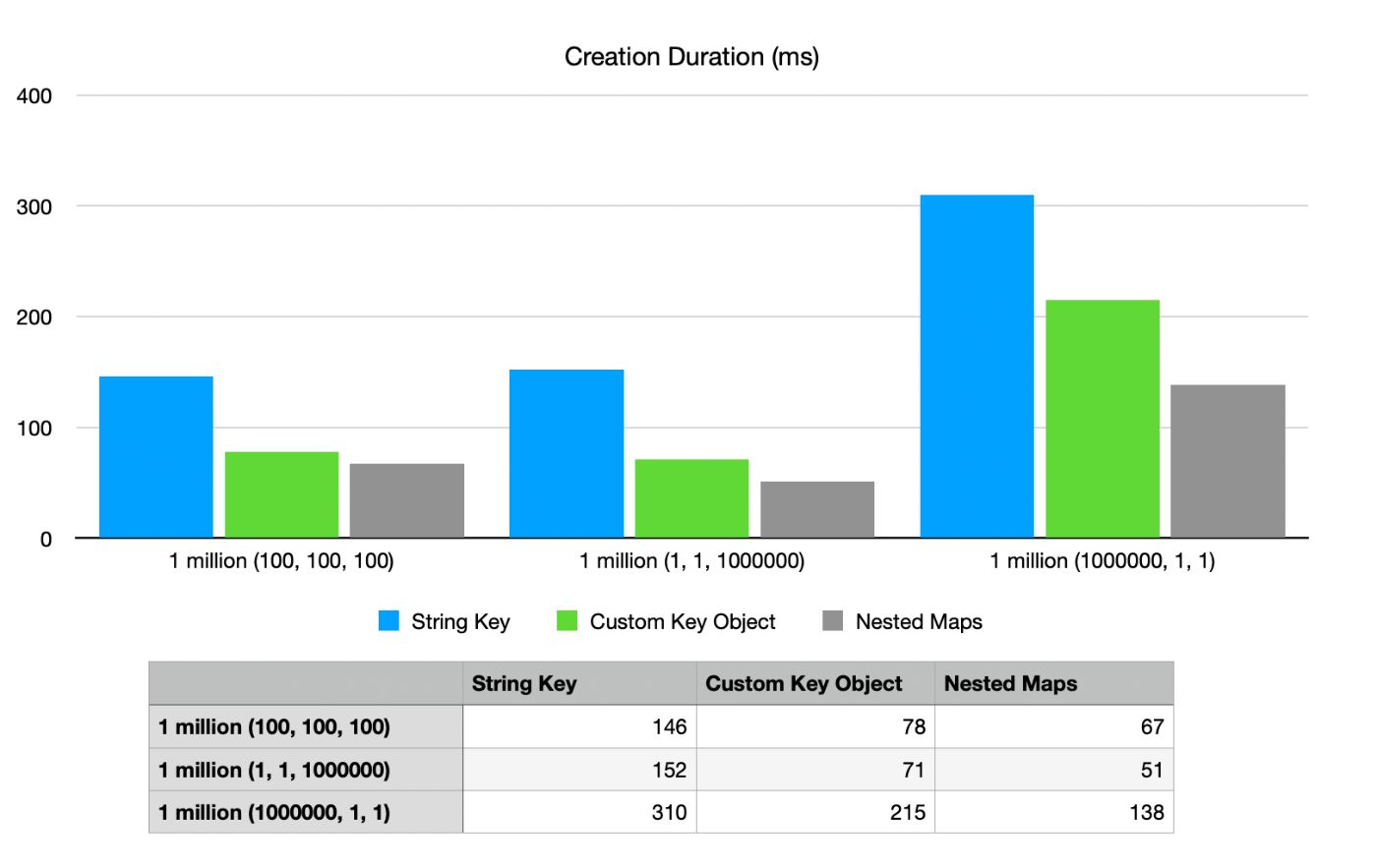
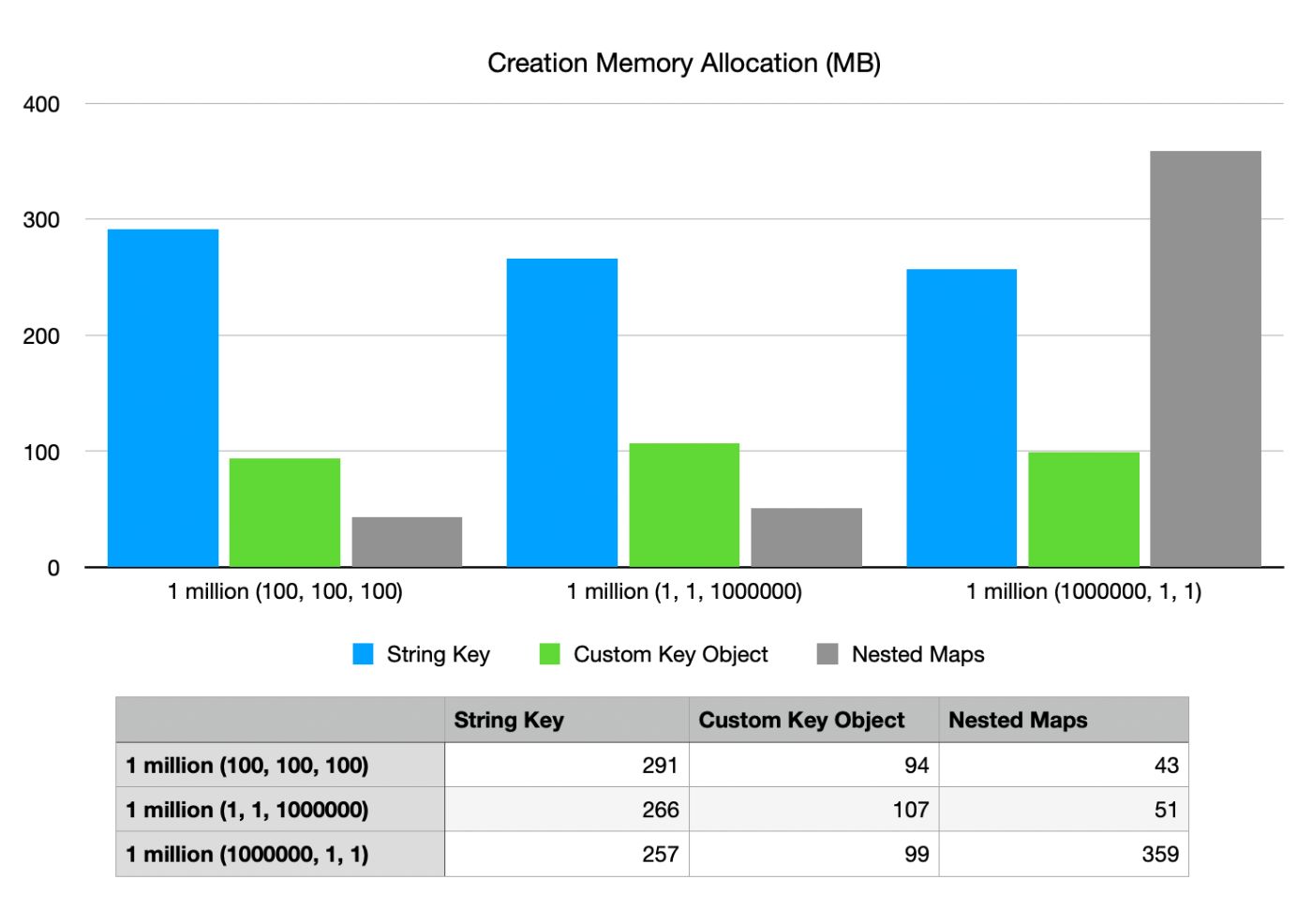
Опять же, мы видим, что вложенные карты показывают худшие результаты в сценарии 1 миллион-1–1 при распределении памяти, но даже в этом случае они превосходят другие по процессорному времени. В приведенном выше примере мы также можем видеть, что ключ String работает хуже всего во всех случаях, в то время как использование объекта пользовательского ключа немного медленнее и требует большего выделения памяти, чем вложенные ключи.
Наконец, давайте посмотрим на сценарий с самой высокой пропускной способностью и на то, насколько эффективно его чтение. Мы выполнили 1 миллион операций чтения (по 1 на каждый созданный ключ); мы не включили несуществующие ключи.
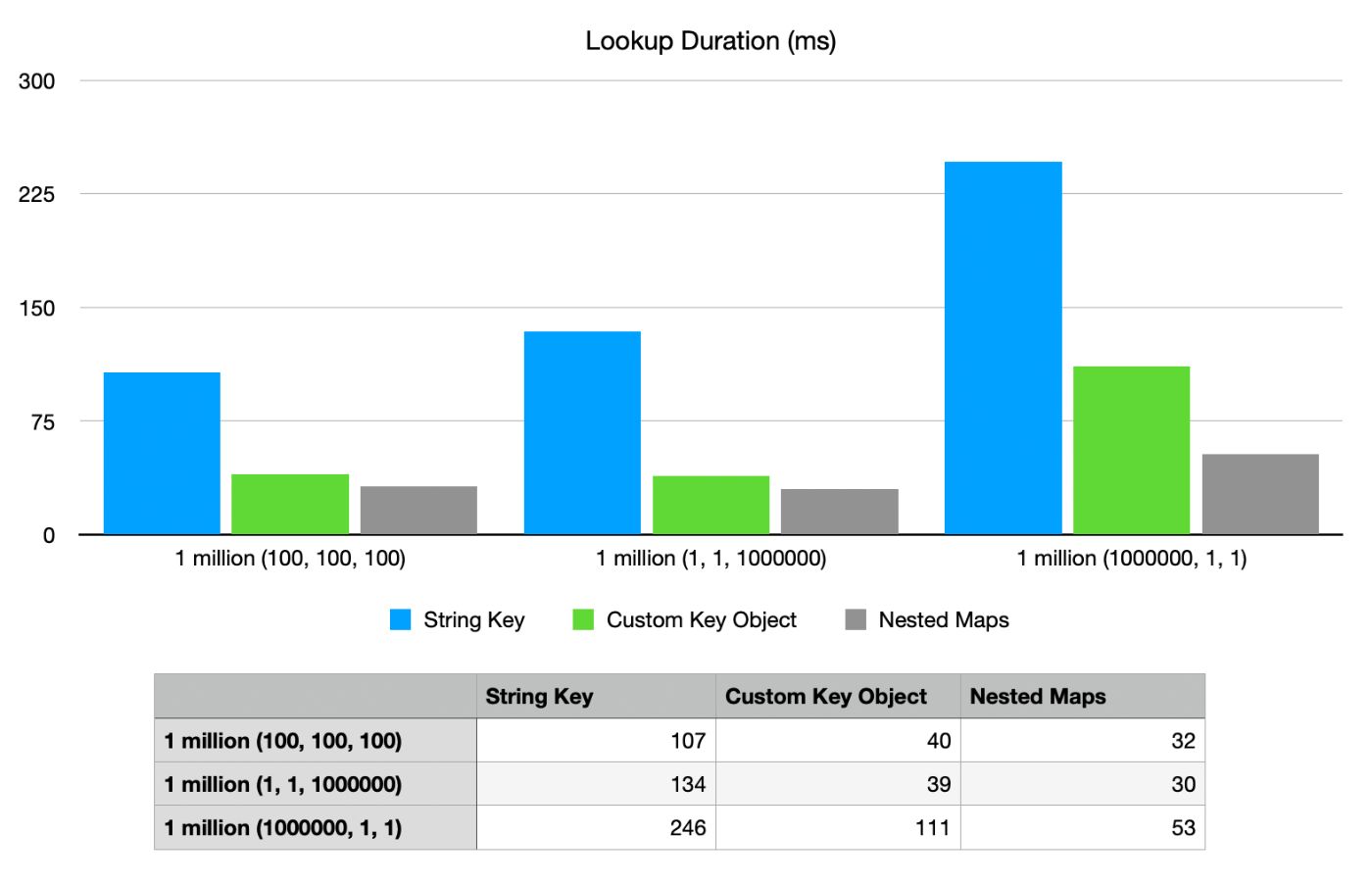
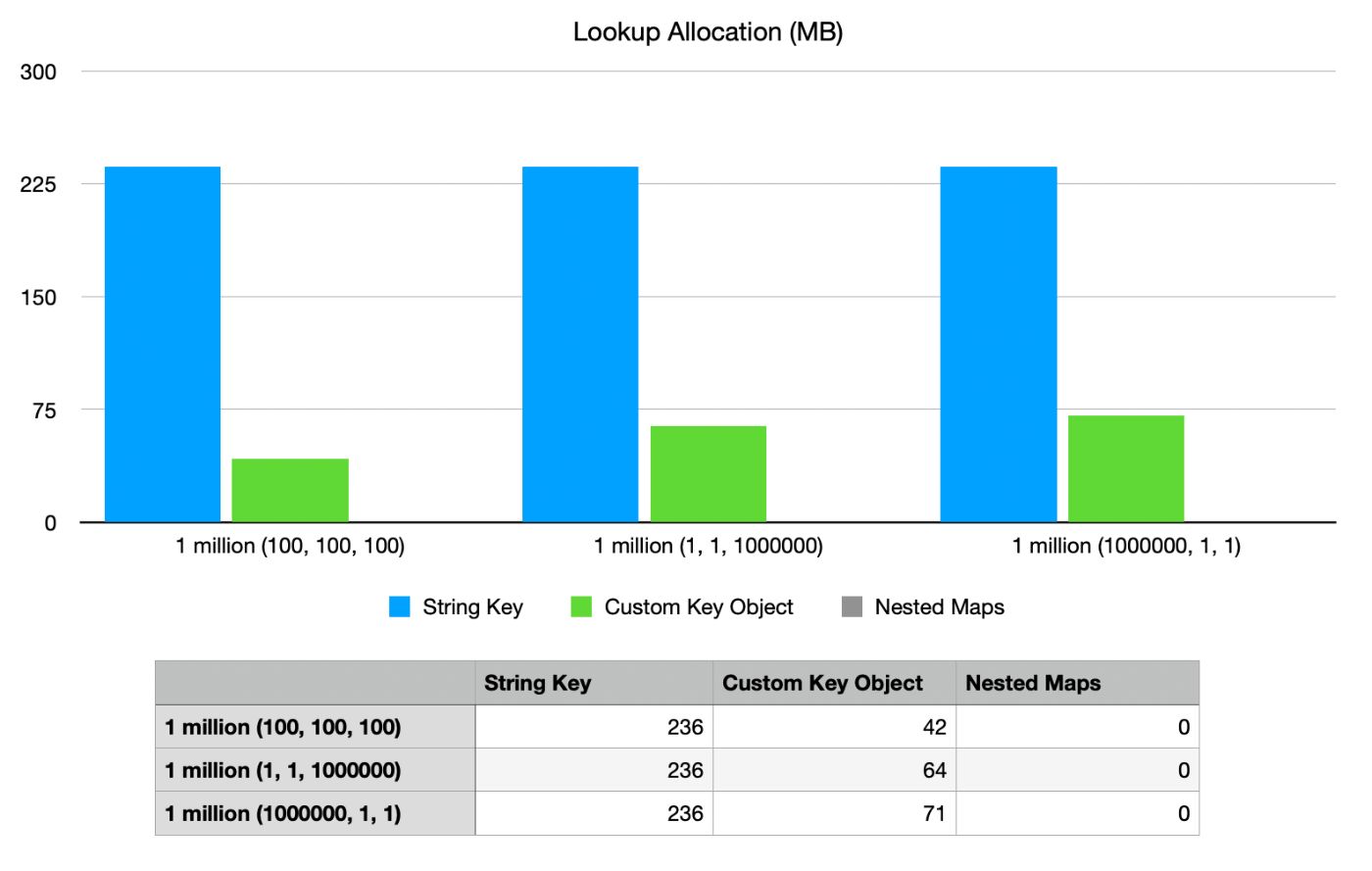
Именно здесь мы действительно видим, насколько медленным является поиск ключей на основе строк. Он, безусловно, самый медленный и выделяет больше всего памяти из всех трех вариантов. Пользовательский ключевой объект работает «близко» к реализации вложенных карт, но все же немного медленнее.
Однако при распределении памяти при поиске обратите внимание, насколько хорошо выглядят вложенные карты. Нет, это не сбой в графике; поиск значения во вложенных картах не требует дополнительного выделения памяти для поиска. Как это возможно?
Итак, при объединении составных объектов в строковый ключ вам нужно каждый раз выделять память для нового строкового объекта:
private String lookup(int key1, String key2, long key3) {
return map.get(key1 + "." + key2 + "." + key3);
}
При использовании составного ключа вам все равно необходимо выделить память для нового ключевого объекта. Но поскольку члены этого объекта уже созданы и на них есть ссылки, он все равно выделяет гораздо меньше места, чем новая строка:
private String lookup(int key1, String key2, long key3) {
return map.get(new MapKey(key1, key2, key3));
}
Но реализация вложенных карт не требует нового выделения памяти при поиске. Вы повторно используете данные части в качестве ключей к каждой из вложенных карт:
private String lookup(int key1, String key2, long key3) {
return map.get(key1).get(key2).get(key3);
}
Итак, исходя из вышесказанного, что является наиболее эффективным?
Легко заметить, что вложенные карты выходят на первое место практически во всех сценариях. Если вам нужна высокая производительность в большинстве случаев использования, это, вероятно, лучший вариант. Однако вам следует провести собственное тестирование, чтобы подтвердить свои варианты использования.
Ключевой объект является очень хорошим вариантом общего назначения, когда вложенные карты становятся непрактичными или невозможными для использования в вашей реализации. А составной строковый ключ, хотя его и проще всего реализовать, почти всегда будет самым медленным.
Последний момент, который следует учитывать при реализации составных ключей, — это то, что вы можете комбинировать вышеперечисленное. Например, вы можете использовать вложенные карты для первого или двух уровней, а затем использовать составной ключевой объект для упрощения более глубоких уровней.
При этом ваши данные по-прежнему могут быть разделены для быстрого поиска, при этом оптимизируя хранение и производительность поиска. И следите за тем, чтобы ваш код был читабельным.
TLDR;
В большинстве случаев делайте это просто. Объедините составные ключи в строковый ключ для хранения на карте или в кеше, если это самый простой вариант и производительность не является серьезной проблемой.
В сценариях, где производительность имеет решающее значение, обязательно проведите собственное тестирование. Но в большинстве случаев использование вложенных карт будет наиболее эффективным. Он также, вероятно, будет иметь наименьшие требования к хранению. А составные ключи по-прежнему остаются эффективной альтернативой, когда вложенные сопоставления становятся непрактичными.
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27037)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)