Cassandra — это распределенная, децентрализованная, масштабируемая и высокодоступная база данных с широкими столбцами.
В терминах теоремы CAP Кассандра означает AP (доступность и устойчивость к разделению).
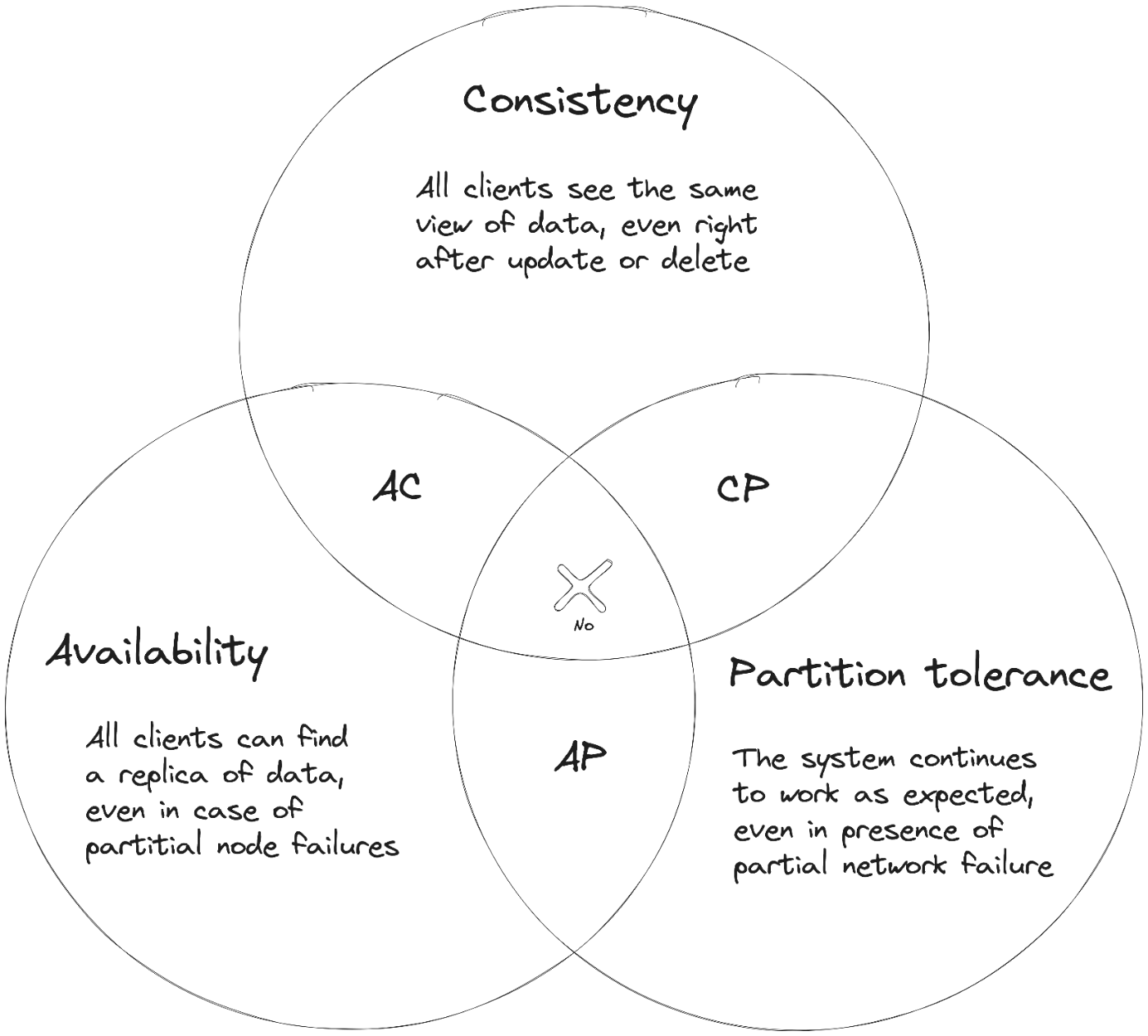
Это означает, что Cassandra предпочитает, чтобы все клиенты могли находить данные даже в тех случаях, когда не все узлы доступны, и работала должным образом при возникновении частичного сбоя сети. Однако это также означает, что согласованность данных может быть нарушена в пользу доступности и устойчивости разделов — пользователи увидят данные, но на какое-то время они могут оказаться устаревшими.
<блок-цитата>Cassandra разработана для достижения высокой пропускной способности и ускорения операций записи.
И именно жертвование согласованностью позволяет Cassandra обеспечить высокую доступность.
:::информация По умолчанию Cassandra спроектирована так, чтобы быть в конечном итоге согласованной, а это означает, что она может не обеспечивать строгую согласованность. Это делает Cassandra подходящей для приложений, где согласованность не является критическим требованием. Однако Cassandra можно настроить для обеспечения строгой согласованности, хотя это может повлиять на производительность.
:::
Cassandra, являясь базой данных NoSQL, не поддерживает соединения таблиц, внешние ключи или возможность добавления столбцов, отличных от первичного ключа, в предложении WHERE во время запроса. Эти ограничения следует принять во внимание, прежде чем использовать Cassandra.
Строительные блоки Кассандры
- Столбец. Столбец представляет пару ключ-значение и служит основной единицей структуры данных.
- Строка: действует как контейнер для столбцов, на которые ссылается первичный ключ.
- Пространство ключей: служит контейнером для таблиц, охватывающих один или несколько узлов Cassandra.
- Кластер: контейнер пространств ключей в Cassandra.
- Узел: относится к компьютерной системе, на которой работает экземпляр Cassandra. Узел может быть физическим хостом, экземпляром машины в облаке или даже контейнером Docker.
Как Cassandra хранит данные
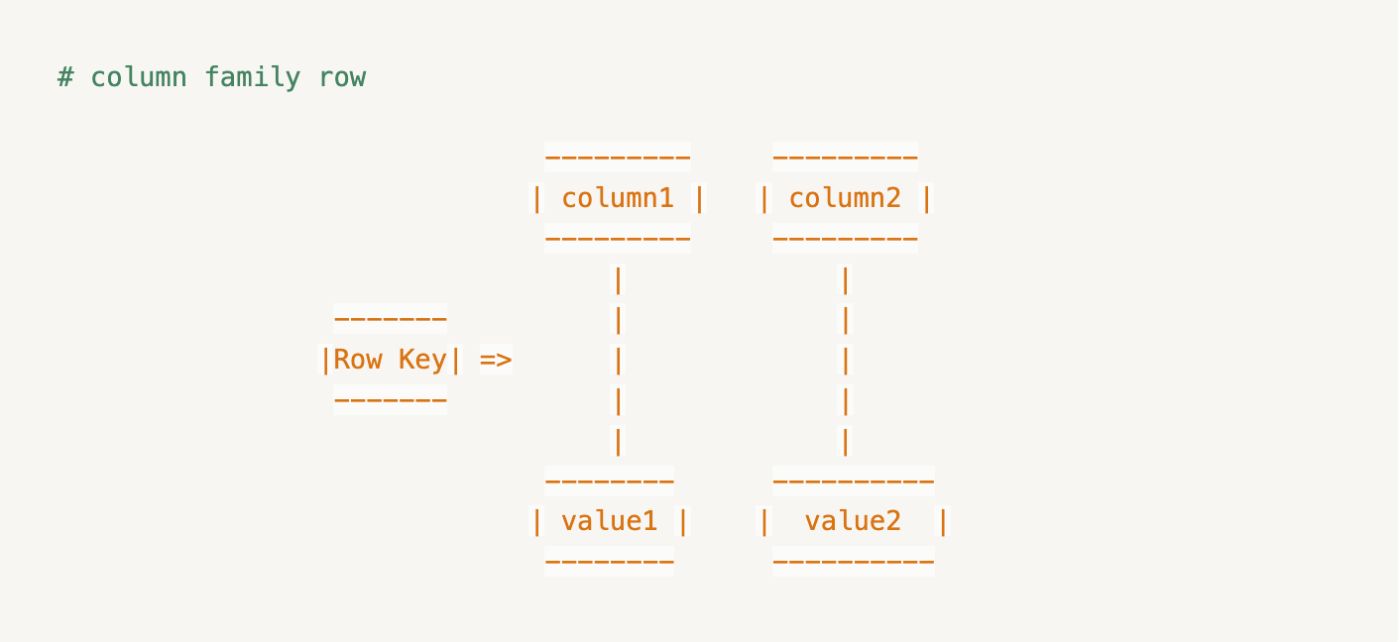
Cassandra хранит данные как семейство столбцов. Он служит контейнером для столбцов, на которые ссылается первичный ключ.

Строка семейства столбцов включает в себя несколько столбцов с ключом и значением, причем ключ строки служит первичным ключом:
Семейство столбцов может хранить разный набор столбцов для каждого ключа строки:
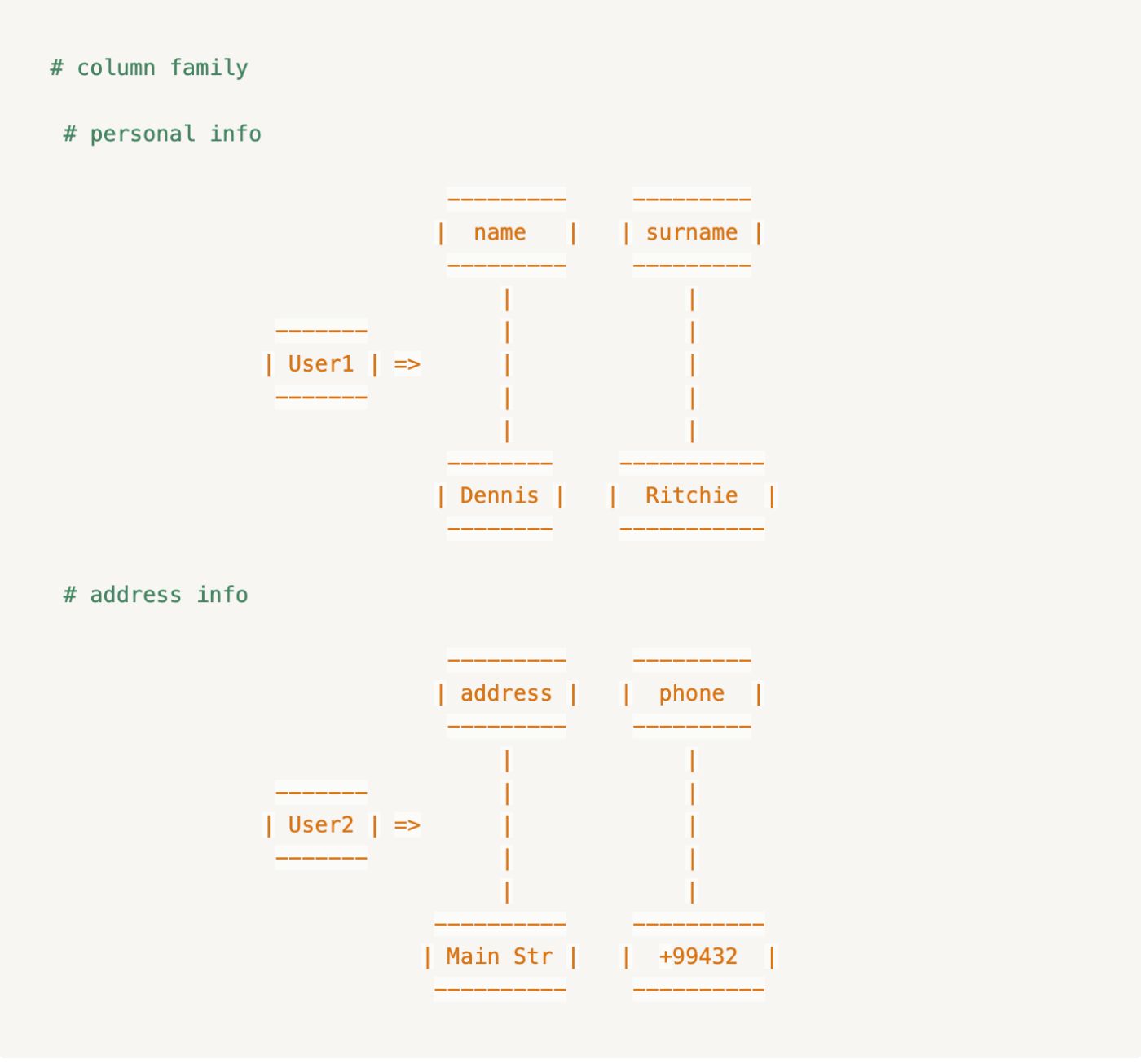
:::информация Cassandra не хранит столбцы со значениями NULL, что помогает сэкономить значительное пространство для хранения.
:::
Что такое первичный ключ в Cassandra?
Первичный ключ уникально идентифицирует каждую строку таблицы. В Cassandra первичный ключ состоит из двух частей:
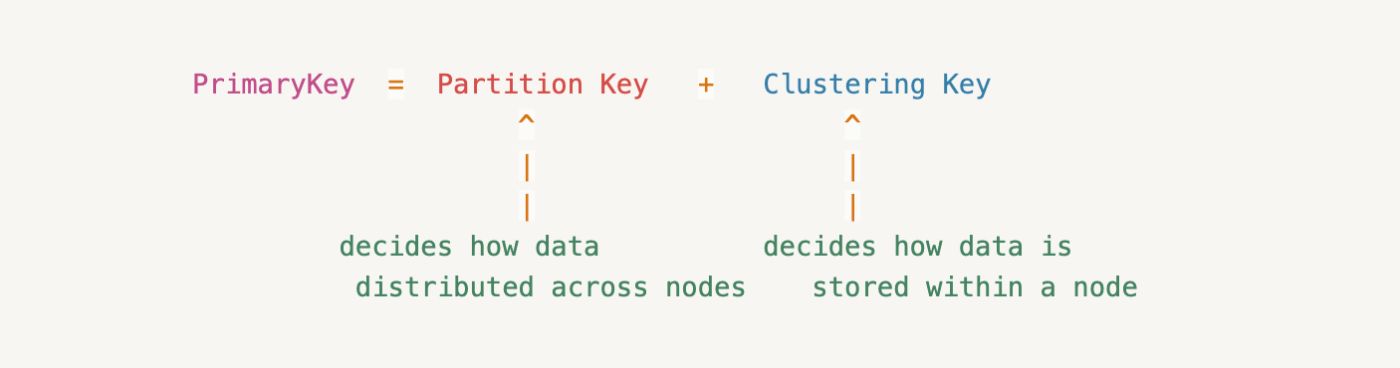
В Cassandra ключ раздела определяет, какой узел хранит данные, а ключ кластеризации определяет, как данные хранятся внутри узла. Например, рассмотрим таблицу с
ПЕРВИЧНЫЙ КЛЮЧ (city_id, event_id). Этот первичный ключ состоит из двух частей, представленных двумя столбцами:
1. city_id служит ключом секции. Это означает, что данные будут секционированы на основе поля city_id, в результате чего все строки будут иметь одинаковый city_id. хранятся на одном узле.
2. event_id действует как ключ кластеризации. Внутри каждого узла данные организованы и хранятся в отсортированном порядке на основе столбца event_id.
:::информация Ключи кластеризации определяют порядок хранения данных внутри узла. Можно иметь несколько ключей кластеризации, и любые столбцы, перечисленные после ключа раздела, называются столбцами кластеризации. Столбцы кластеризации определяют порядок, в котором данные организованы на узле.
:::
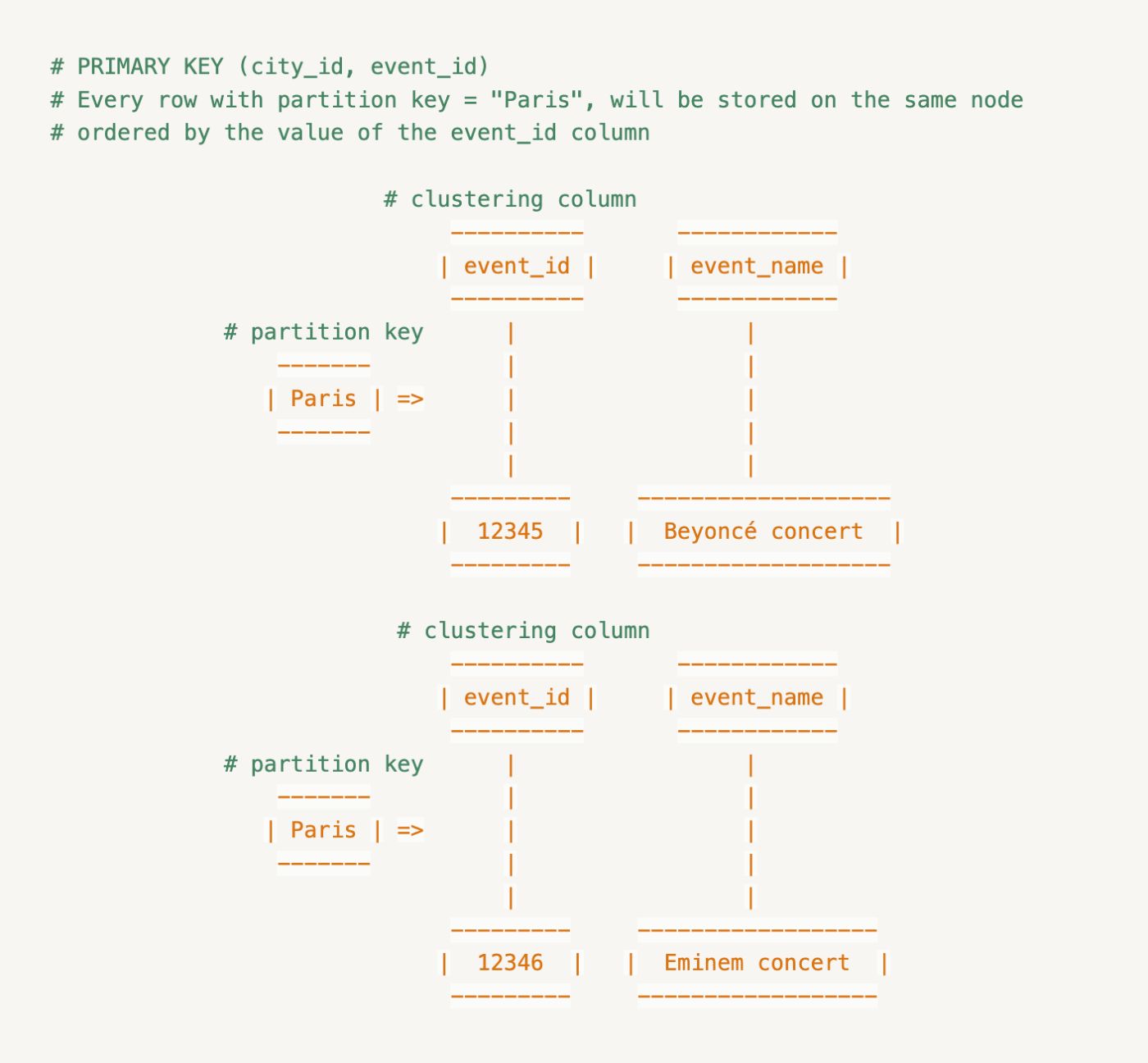
Каждая строка с ключом раздела = «Париж» будет храниться на одном узле, упорядоченном по значению столбца event_id.
Готовое секционирование данных
Cassandra обеспечивает секционирование данных на основе согласованного хеширования для уменьшения задержки при операциях чтения/записи и увеличения пропускной способности системы. когда объем данных, хранящихся в базе данных, становится большим.
Разделитель в Cassandra отвечает за распределение данных по кольцу согласованного хеширования. Когда данные вставляются в кластер Cassandra, средство разделения применяет алгоритм хеширования к ключу раздела. Результат этого алгоритма хеширования определяет диапазон, в который попадают данные, и определяет узел, на котором данные будут храниться.
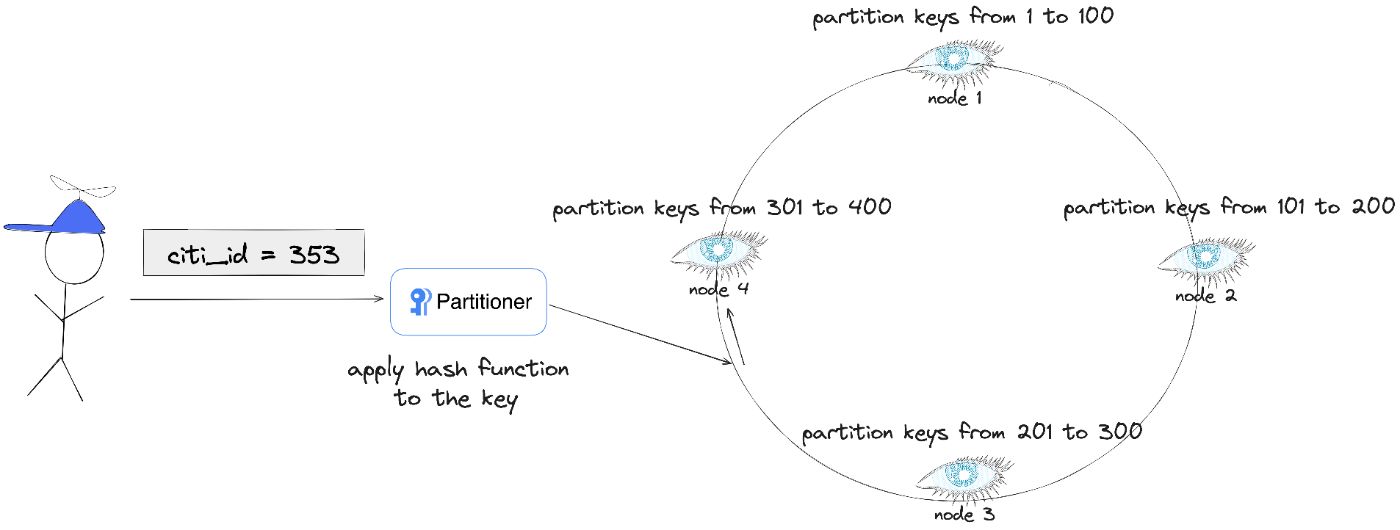
Узел координатора
В Cassandra каждый узел знает о назначениях токенов других узлов через протокол сплетен, что позволяет любому узлу обрабатывать запросы для диапазона любого другого узла. Таким образом, клиент может подключиться к любому узлу, чтобы инициировать запросы на чтение или запись.
Узел, получающий запрос, называется координатором и может быть любым узлом в кластере. Если ключ не принадлежит диапазону координатора, запрос перенаправляется репликам, ответственным за этот диапазон.
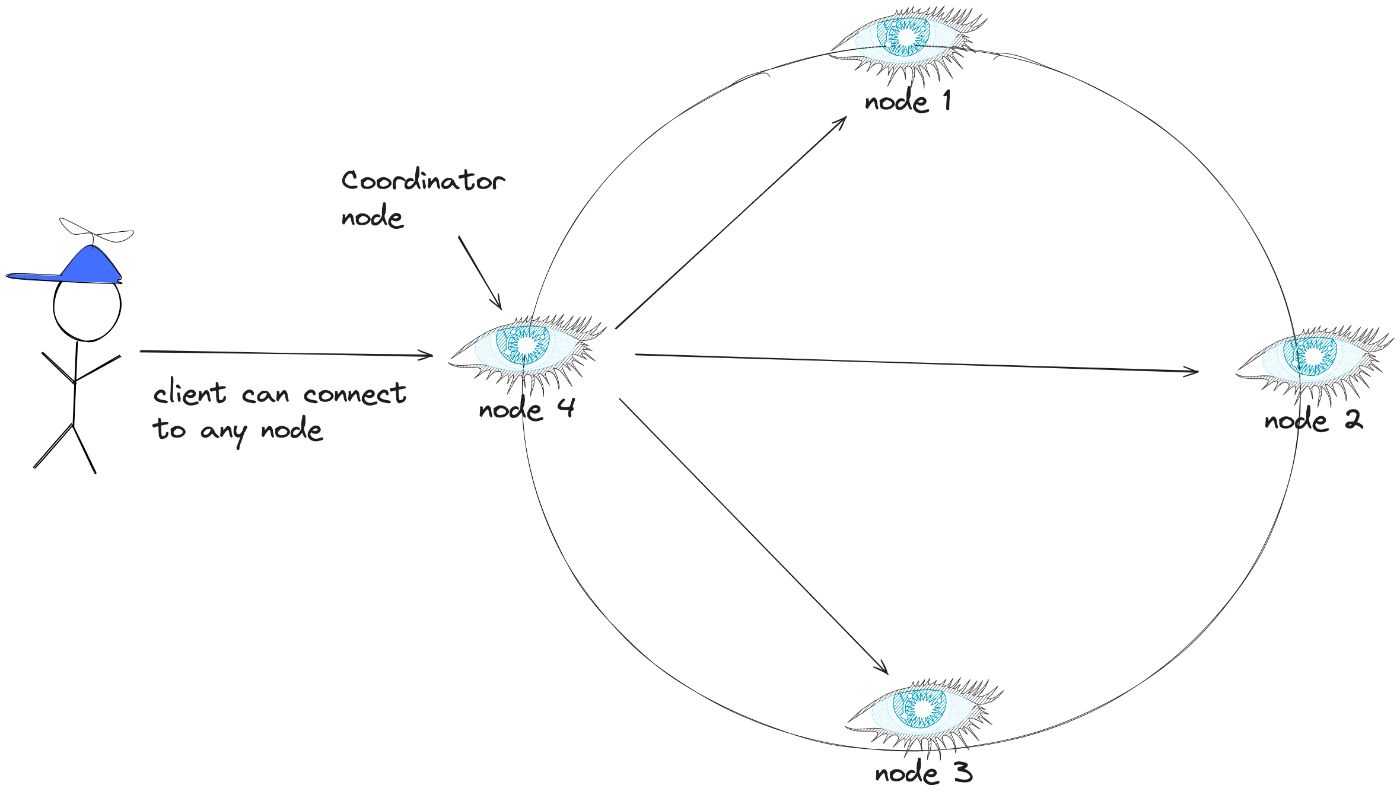
Репликация
Cassandra реплицирует данные на нескольких узлах, чтобы обеспечить высокую доступность. Каждый узел в Cassandra служит репликой для определенного диапазона данных. Распределяя несколько копий данных по разным репликам, Cassandra позволяет другим репликам обрабатывать запросы для этого диапазона данных в случае, если один узел недоступен. На процесс репликации будут влиять две настройки:
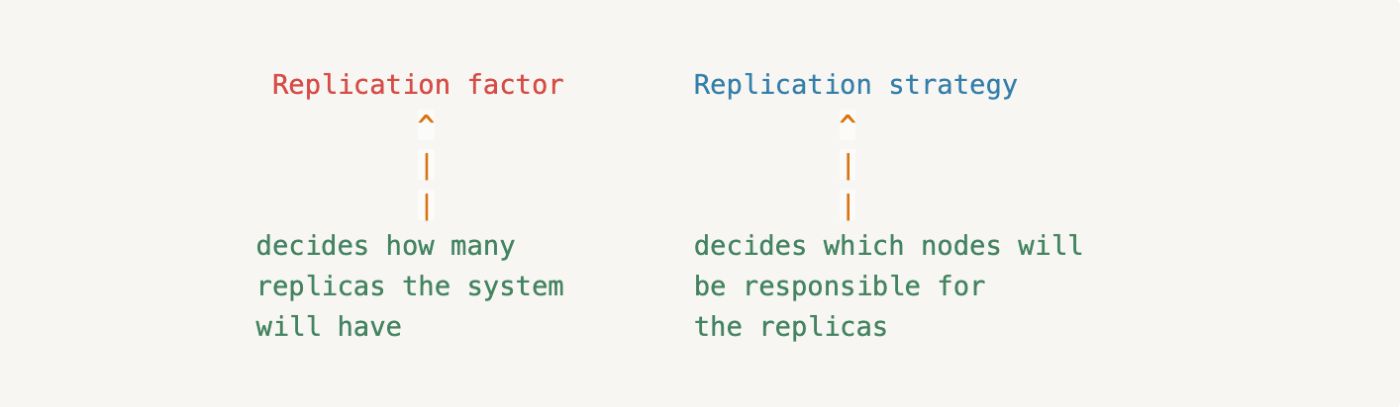
Коэффициент репликации определяет, сколько узлов будет хранить копии одних и тех же данных. В кластере с коэффициентом репликации 3 каждая строка будет храниться на трех разных узлах.
:::информация Каждое пространство ключей в Cassandra может иметь свой коэффициент репликации.
:::
В Cassandra первая реплика назначается узлу, владеющему диапазоном, на основе хеша ключа раздела. Остальные реплики затем размещаются на последовательных узлах по часовой стрелке. Cassandra использует две стратегии репликации, чтобы определить, какие узлы будут отвечать за реплики:
Простая стратегия репликации
В этой стратегии первая реплика размещается на узле, определенном разделителем, а последующие реплики размещаются на последующих узлах по часовой стрелке.
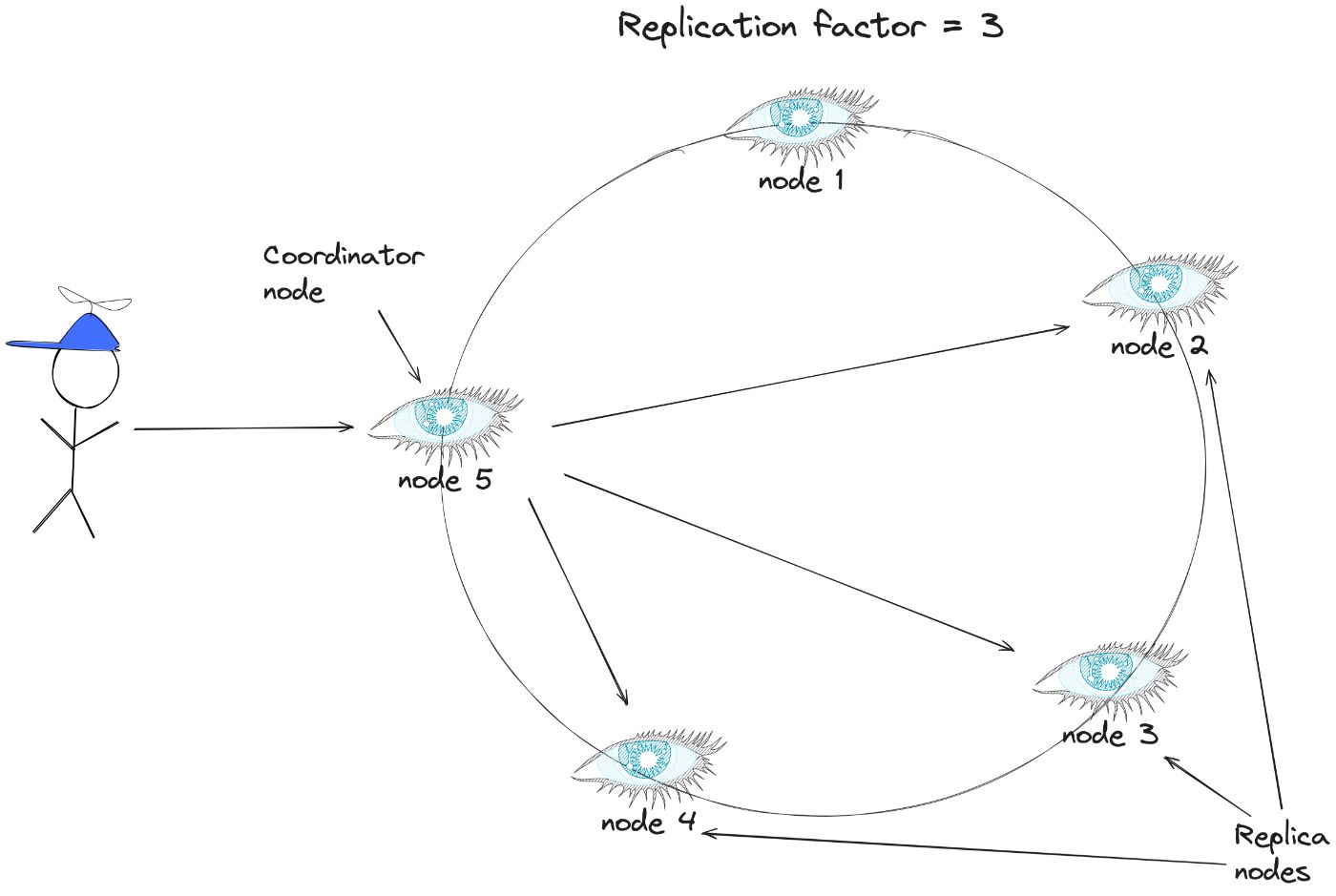
:::информация Эта стратегия репликации применима только для одного кластера центра обработки данных.
:::
Стратегия топологии сети
Чтобы обеспечить устойчивость к полной потере данных, дополнительные реплики в одном центре обработки данных размещаются путем перемещения по часовой стрелке по кольцу до тех пор, пока не достигнут первого узла в другом центре обработки данных. Такое расположение помогает смягчить влияние одновременных сбоев, которые обычно происходят в одном центре обработки данных из-за проблем с питанием, охлаждением или сетью.
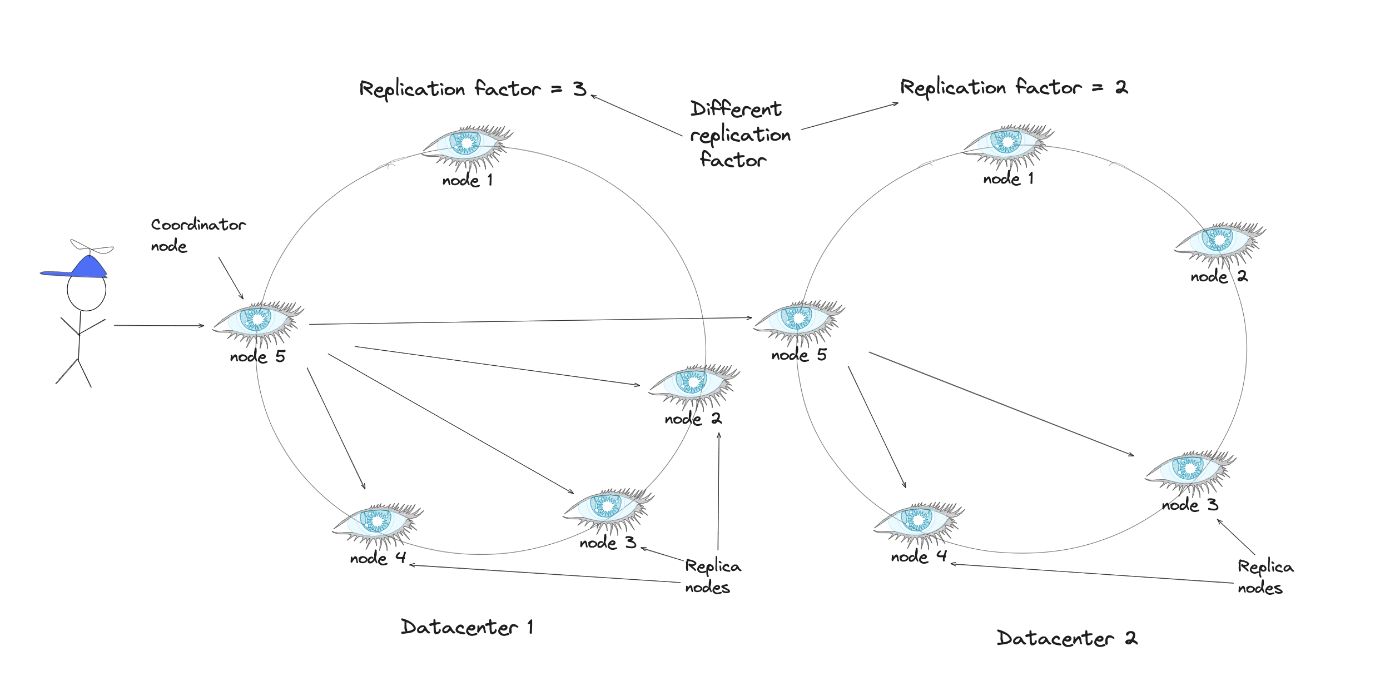
:::информация Когда дело доходит до конфигураций с несколькими центрами обработки данных, вам следует учитывать стратегию топологии сети. Этот подход позволяет указывать различные коэффициенты репликации для каждого центра обработки данных, позволяя контролировать количество реплик, размещаемых в каждом конкретном месте.
:::
Когда использовать Кассандру
Cassandra отлично подходит для приложений, требующих обработки больших объемов данных и отдающих приоритет доступности данных, а не их согласованности. Он хорошо подходит для:
1. Приложения Интернета вещей (IoT). Cassandra — идеальный выбор для сред Интернета вещей, поскольку она может обрабатывать огромные объемы данных, генерируемых устройствами и датчиками. Его распределенная архитектура позволяет управлять географически рассредоточенными крупномасштабными данными.
2. Данные временных рядов. Приложения, работающие с данными временных рядов, такие как метрики, системы мониторинга и данные телеметрии, извлекают выгоду из эффективных операций записи Cassandra и горизонтальной масштабируемости. Эти возможности имеют решающее значение для хранения и управления большими объемами данных с отметками времени.
3. Веб- и мобильные приложения. Cassandra обеспечивает доступ к данным с высокой пропускной способностью и низкой задержкой, что делает ее подходящей для веб- и мобильных платформ с большой базой пользователей, генерирующих значительные объемы данных. Сюда входят платформы социальных сетей, игровые приложения и сайты электронной коммерции.
4. Аналитика больших данных в реальном времени. Cassandra поддерживает обработку больших данных в реальном времени, что делает ее ценным выбором для приложений, требующих немедленного анализа больших наборов данных. Примерами могут служить системы рекомендаций и системы обнаружения мошенничества.
5. Распределенные хранилища данных. Предприятия с большими распределенными наборами данных могут использовать Cassandra в качестве решения для хранения данных. Его способность реплицировать данные в нескольких центрах обработки данных обеспечивает высокую доступность и аварийное восстановление.
6. Системы обмена сообщениями. Высокая пропускная способность Cassandra по записи и чтению делает ее хорошо подходящей для систем обмена сообщениями, обрабатывающих большие объемы данных, таких как регистрация событий, журналы аудита или очереди сообщений.
7. Системы персонализации и управления контентом. Приложения, требующие персонализированной доставки контента в больших масштабах, такие как системы управления контентом, выигрывают от скорости и масштабируемости Cassandra при доставке персонализированного контента большому количеству пользователей одновременно.
8. Географически распределенные приложения. Поддержка Cassandra нескольких центров обработки данных делает ее отличным выбором для приложений, требующих географически распределенных данных. Это обеспечивает доступ к данным с низкой задержкой в разных регионах и обеспечивает высокую отказоустойчивость.
Когда не следует использовать Кассандру
Хотя Apache Cassandra является мощным и масштабируемым, он может подходить не для каждого приложения или варианта использования. Он менее подходит для приложений с большим количеством транзакций, сложных запросов и сценариев, требующих строгой согласованности или быстрого изменения схемы. В таких случаях более подходящими могут оказаться традиционные системы управления реляционными базами данных (СУБД) или другие решения NoSQL. Вот несколько сценариев, в которых Кассандра может быть не оптимальным выбором:
- Маломасштабные проекты. Сложность Cassandra и требования к ресурсам могут быть чрезмерными для небольших проектов или приложений с ограниченными наборами данных. Более простые решения для баз данных могут стать более экономичной и управляемой альтернативой.
2. Транзакционные системы, требующие свойств ACID: Cassandra не полностью поддерживает свойства ACID (атомарность, согласованность, изоляция, долговечность). Если вашему приложению требуются сложные транзакции, обычно встречающиеся в банковских или финансовых системах, лучше подойдет традиционная СУБД.
3. Объединение тяжелых запросов и агрегатов. Если ваше приложение сильно зависит от объединений, подзапросов или сложных агрегатов, Cassandra может оказаться не самым подходящим выбором. Он предназначен для быстрой записи и чтения, но не для сложной обработки запросов.
4. Данные со строгими требованиями к согласованности. Cassandra обеспечивает итоговую согласованность, что может не подходить для случаев использования, требующих строгой согласованности для каждой операции чтения и записи.
5. Чтение и запись с низкой задержкой в одном кластере. Хотя Cassandra хорошо работает в распределенных средах с несколькими узлами, она может быть не оптимальным выбором для развертываний с одним узлом или небольшим кластером, требующих низкой производительности. задержка чтения и записи.
6. Хранилище BLOB-объектов: Cassandra не оптимизирована для хранения больших двоичных объектов (BLOB-объектов), таких как изображения или видео. Другие решения для хранения данных лучше подходят для эффективной работы с большими двоичными объектами.
7. Приложения, требующие специальных запросов. Возможности запросов Cassandra ограничены по сравнению с полноценными базами данных SQL. Он не очень подходит для приложений, которые в значительной степени полагаются на нерегламентированные запросы и отчеты.
В Cassandra дизайн таблиц тесно связан со способом доступа к данным, при этом особое внимание уделяется шаблонам запросов, а не исключительно отношениям между объектами данных. Это отличается от подхода в РСУБД, где проектирование схемы основано на принципах нормализации.
8. Быстрая эволюция схемы. Если вашему приложению требуется частое изменение схемы базы данных, управление схемой Cassandra может быть менее гибким по сравнению с традиционными системами РСУБД или другими решениями NoSQL.
9. Приложения хранилищ данных, которые включают сложные запросы, соединения и анализ исторических данных. Хотя Cassandra хорошо подходит для рабочих нагрузок с большим объемом записи и доступа к данным в реальном времени, это может быть не самый подходящий выбор. для сценариев хранения данных, требующих сложных запросов, объединений и анализа исторических данных.
Сводка
В этой статье представлен обзор Cassandra, хорошо масштабируемой и распределенной базы данных с широкими столбцами. Cassandra разработана с учетом приоритета доступности и устойчивости к разделам, что делает ее подходящей для приложений, где согласованность не является критическим требованием. Он поддерживает высокую пропускную способность и более быстрые операции записи.
Строительные блоки Cassandra включают столбцы, строки, пространства ключей, кластеры и узлы. Столбцы представляют пары ключ-значение, строки действуют как контейнеры для столбцов, на которые ссылается первичный ключ, пространства ключей служат контейнерами для таблиц, охватывающих несколько узлов, кластеры содержат пространства ключей, а узлы относятся к компьютерным системам, на которых работают экземпляры Cassandra.
Cassandra хранит данные в семействах столбцов, которые представляют собой контейнеры для столбцов, на которые ссылается первичный ключ. Секционирование данных достигается за счет последовательного хеширования, что позволяет сократить задержку и увеличить пропускную способность. Разделитель распределяет данные по кольцу согласованного хэша, а узел-координатор обрабатывает запросы на чтение и запись.
Cassandra обеспечивает репликацию для обеспечения высокой доступности. Реплики данных хранятся на нескольких узлах, что гарантирует возможность обработки запросов репликами, если узел становится недоступным. Факторы и стратегии репликации определяют количество реплик и узлов, отвечающих за них.
Хотя Cassandra предлагает такие преимущества, как масштабируемость и высокая доступность, у нее есть ограничения. Он не поддерживает соединения таблиц, внешние ключи или возможность добавлять столбцы, отличные от первичного ключа, в предложении WHERE во время запроса.
В целом, Cassandra — это мощное решение для баз данных для хорошо масштабируемых приложений, особенно для тех, в которых доступность и устойчивость к разделению отдаются приоритетам, а не строгой согласованности.
:::информация Есть несколько интересных аспектов Кассандры, о которых я расскажу в своей следующей статье. Подпишитесь на меня, чтобы не пропустить!
:::
Удачи!