

Может ли ИИ понять шутку? Новые тестирование наборов данных ботов на метафорах, сарказме и юморе
19 июня 2025 г.Авторы:
(1) Arkadiy Saakyan, Колумбийский университет (a.saakyan@cs.columbia.edu);
(2) Шреяс Кулкарни, Колумбийский университет;
(3) Тухин Чакрабарти, Колумбийский университет;
(4) Смаранда Мюресан, Колумбийский университет.
Примечание редактора: это часть 1 из 6 исследований, рассматривая, насколько хорошо крупные модели искусственного интеллекта обрабатывают фигуративный язык. Прочитайте остальное ниже.
Таблица ссылок
- Аннотация и 1. Введение
- 2. Связанная работа
- 3. v-Flute Задача и набор данных
- 3.1 Метафоры и сравнения
- 3.2 идиомы и 3,3 сарказма
- 3.4 Юмор и 3,5 Статистика набора данных
- 4. Эксперименты и 4.1 модели
- 4.2 Автоматические метрики и 4.3 результаты автоматической оценки
- 4.4 Человеческий базовый уровень
- 5. Оценка человека и анализ ошибок
- 5.1 Как модели работают в соответствии с людьми?
- 5.2 Какие ошибки допускают модели? и 5.3 Насколько хорошо оценка объяснения предсказывает человеческое суждение о адекватности?
- 6. Выводы и ссылки
- Статистика набора данных
- B API модели гиперпараметры
- C тонкая настройка гиперпараметров
- D подсказки для LLMS
- E Модель таксономия
- F By-Phenomenon Performance
- G Аннотаторский набор и компенсация
Абстрактный
Большие модели на языке зрения (VLM) продемонстрировали сильные возможности рассуждений в задачах, требующих мелкозернистого понимания буквальных изображений и текста, таких как визуальный вопрос с ответом или визуальное введение. Тем не менее, было мало изучения возможностей этих моделей, когда были представлены изображения и подписи, содержащие фигуративные явления, такие как метафоры или юмор, значение которых часто является неявным. Чтобы закрыть этот пробел, мы предлагаем новую задачу и высококачественный набор данных: визуальное понимание языка с текстовыми объяснениями (V-Flute). Мы создаем проблему понимания визуального языка как объяснимую задачу визуального введения, где модель должна предсказать, влечет ли изображение (предпосылка) претензию (гипотеза) и оправдать прогнозируемый этикетку с текстовым объяснением. Используя структуру совместной работы человека, мы строим высококачественный набор данных V-FLUTE, который содержит 6027 экземпляров, охватывающих пять разнообразных мультимодальных фигуративных явлений: метафоры, сравнения, идиомы, сарказм и юмор. Фигуративные явления могут присутствовать либо на изображении, заголовках или оба. Мы также проводим как автоматические, так и человеческие оценки для оценки современных возможностей VLMS в понимании образных явлений. [1]
1 Введение
Фигуративный язык является неотъемлемой частью человеческого общения, что позволяет различным коммуникативным целям (Roberts and Kreuz, 1994), включая аффективное общение (Fussell and Moss, 2014). Фигуративный язык представляет собой серьезную проблему для вычислительных подходов, поскольку он
требует понимания неявного значения, стоящего за экспрессией (Stowe et al., 2022; Shutova, 2011; Veale et al., 2016; Zhou et al., 2021). Недавно Chakrabarty et al. (2022) предложил задачу и набор данных для понимания фигуративного языка посредством текстовых объяснений (флейта), которая создает проблему как объяснимое текстовое введение, охватывающее различные явления с образными языками в тексте: метафоры, синдромы, идиомы и сарказм. Этот набор данных был успешно использован для продвижения и оценки возможностей LLM для понимания фигуративного языка в тексте (Saakyan et al., 2022; Ziems et al., 2024; Sravanthi et al., 2024; Dey et al., 2024).
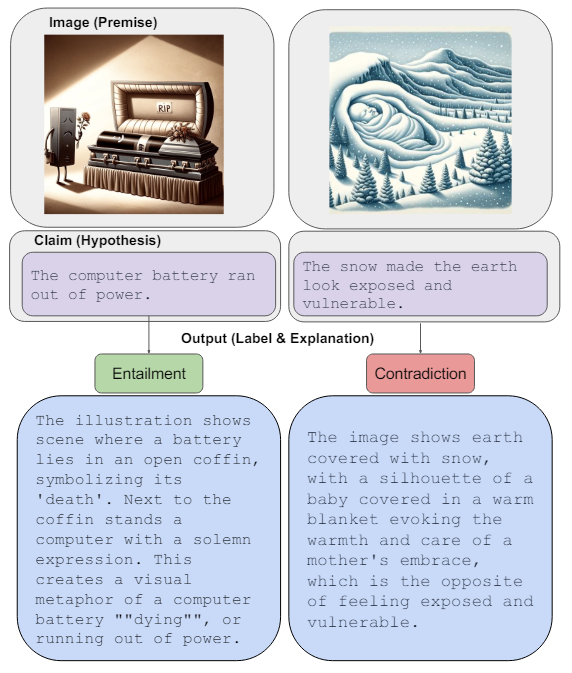
Однако фигуративное значение также распространено в визуальных явлениях, таких как визуальные метафоры (Akula et al., 2023; Chakrabarty et al., 2023), мультимодальный сарказм (Desai et al., 2022) и Humor (Hessel et al., 2023; Hwang and Shwartz, 2023). Тем не менее, до сих пор большинство работ по моделям зрения и языке (VLMS) были сосредоточены на понимании буквального значения в изображениях и подписках (например, ScienceQA (Lu et al., 2022), MMMU (Yue et al., 2024)), включая работу по объяснению визуального развлечения (Kayser et al., 2021). Опираясь на идею флейты (Chakrabarty et al., 2022) для текста, мы представляем новый набор данных для понимания визуального фигуративного языка с текстовыми объяснениями (V-Flute). Наш набор данных содержит 6027 экземпляров, охватывающих разнообразные образные явления. Каждый экземпляр содержит изображение (предпосылка) и текстовое утверждение (гипотеза), которое либо влечет за собой, либо противоречит изображению. Решение о том, как отношение въезда требует, чтобы модель на языке зрения поняла неявное значение как в визуальных, так и в текстовых модальностях. Наш набор данных содержит фигуративные явления, присутствующие на изображении, в заголовке или в обоих. Кроме того, чтобы смягчить зависимость от ложных корреляций, для более строгого изучения возможностей рассуждений и способствовать объяснению, наша задача требует, чтобы модель генерировала правдоподобное объяснение для метки выходной системы. См. Рисунок 1 для двух примеров из нашего набора данных.
Мы вносим следующий вклад в оценку способности VLMS понимать мультимодальные фигуративные явления:
• V-Flute, высококачественный набор данных из 6027 экземпляров, созданных с использованием структуры совместной работы человека-LLMS, охватывающей несколько явлений: метафоры, пари, идиомы, сарказм и юмор (раздел 3). Мы сделаем набор данных доступным.
• Набор оценок для оценки мощных возможностей VLMS по этой новой задаче объяснимого визуального фигуративного въезда (раздел 4.2 и 4.3).
• Подробная человеческая оценка с анализом ошибок дает представление о типах ошибок для различных классов моделей (раздел 5).
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
[1] Код и данные будут доступны по адресу github.com/asaakyan/v-flute
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)