

Все, что вам нужно знать о непрерывной интеграции, действиях GitHub и облаке Sonar
24 марта 2023 г.Я впервые столкнулся с концепцией непрерывной интеграции (CI) при запуске проекта Mozilla. Он включал в себя элементарный сервер сборки как часть процесса, и в то время это было революционно. Я поддерживал проект C++, на сборку и компоновку которого ушло 2 часа.
Мы редко проходили чистую сборку, которая создавала дополнительные проблемы, поскольку в проекте был зафиксирован неверный код.
Многое изменилось с тех давних времен. Продукты CI повсюду, и мы, разработчики Java, наслаждаемся богатством возможностей, как никогда раньше. Но я забегаю вперед... Начнем с основ.
https://youtu.be/NaL5il6cLGQ?embedable=true
Непрерывная интеграция – это метод разработки программного обеспечения, при котором изменения в коде создаются и тестируются автоматически, часто и последовательно.
Цель непрерывной интеграции – как можно быстрее выявить и решить проблемы интеграции, чтобы снизить риск возникновения ошибок и других проблем, которые могут попасть в рабочую среду.
CI часто идет рука об руку с непрерывной доставкой (CD), целью которой является автоматизация всего процесса доставки программного обеспечения, от интеграции кода до развертывания в производстве.
Цель CD — сократить время и усилия, необходимые для развертывания новых выпусков и исправлений, позволяя командам быстрее и чаще приносить пользу клиентам.
С CD каждое изменение кода, прошедшее тесты CI, считается готовым к развертыванию, что позволяет командам с уверенностью развертывать новые версии в любое время. Я не буду обсуждать непрерывную доставку в этом посте, но вернусь к ней, так как есть что обсудить.
Я большой поклонник этой концепции, но нам нужно следить за некоторыми вещами.
Инструменты непрерывной интеграции
Существует множество мощных инструментов непрерывной интеграции. Вот некоторые часто используемые инструменты:
* Jenkins: Jenkins — один из самых популярных инструментов непрерывной интеграции, предлагающий широкий спектр подключаемых модулей и интеграций для поддержки различных языков программирования и инструментов сборки. Он имеет открытый исходный код и предлагает удобный интерфейс для настройки конвейеров сборки и управления ими.
Он написан на Java и часто был моим «инструментом для перехода». Тем не менее, это боль для управления и настройки. Есть несколько решений «Jenkins как услуга», которые также улучшают пользовательский интерфейс, которого несколько не хватает.
* Travis CI: Travis CI — это облачный инструмент непрерывной интеграции, который хорошо интегрируется с GitHub, что делает его отличным выбором для проектов на основе GitHub. Поскольку он предшествовал GitHub Actions, он стал использоваться по умолчанию для многих проектов с открытым исходным кодом на GitHub.
* CircleCI: CircleCI — это облачный инструмент непрерывной интеграции, который поддерживает широкий спектр языков программирования и инструментов сборки. Он предлагает удобный интерфейс, но его главным преимуществом является скорость сборки и доставки.
* GitLab CI/CD: GitLab — это популярный инструмент управления исходным кодом, включающий встроенные возможности CI/CD. Решение GitLab гибкое, но простое; он получил известность даже за пределами GitLab.
* Bitbucket Pipelines: Bitbucket Pipelines — это облачный инструмент непрерывной интеграции от Atlassian, который легко интегрируется с Bitbucket, их инструментом управления исходным кодом. Поскольку это продукт Atlassian, он обеспечивает беспрепятственную интеграцию с JIRA и очень гибкую корпоративную функциональность.
Заметьте, я не упомянул действия GitHub, к которым мы вскоре вернемся. При сравнении инструментов CI необходимо учитывать несколько факторов:
* Простота использования. Некоторые инструменты CI имеют простой процесс настройки и удобный интерфейс, что упрощает разработчикам начало работы и управление конвейерами сборки.
* Интеграция с инструментами управления исходным кодом (SCM), такими как GitHub, GitLab и Bitbucket. Это упрощает для команд автоматизацию процессов сборки, тестирования и развертывания.
* Поддержка разных языков программирования и инструментов сборки: разные инструменты непрерывной интеграции поддерживают разные языки программирования и инструменты сборки, поэтому важно выбрать инструмент, совместимый с вашим стеком разработки.
* Масштабируемость: некоторые инструменты непрерывной интеграции лучше подходят для крупных организаций со сложным конвейером сборки, а другие — для небольших групп с более простыми потребностями.
* Стоимость. Стоимость инструментов непрерывной интеграции варьируется от бесплатных и с открытым исходным кодом до коммерческих инструментов, которые могут быть дорогими, поэтому важно выбрать инструмент, соответствующий вашему бюджету.
* Функции. Различные инструменты непрерывной интеграции предлагают различные функции, такие как сборка и результаты тестирования в режиме реального времени, поддержка параллельных сборок и встроенные возможности развертывания.
В целом Jenkins известен своей универсальностью и обширной библиотекой плагинов, что делает его популярным выбором для команд со сложным конвейером сборки. Travis CI и CircleCI известны своей простотой использования и интеграцией с популярными инструментами SCM, что делает их хорошим выбором для малых и средних команд.
GitLab CI/CD — популярный выбор для команд, использующих GitLab для управления своим исходным кодом, поскольку он предлагает интегрированные возможности CI/CD. Bitbucket Pipelines — хороший выбор для команд, использующих Bitbucket для управления исходным кодом, поскольку он легко интегрируется с платформой.
Облако или локальная среда
Размещение агентов – важный фактор, который следует учитывать при выборе решения непрерывной интеграции. Существует два основных варианта размещения агента: в облаке и локально.
* Облачные: облачные решения CI, такие как Travis CI, CircleCI, GitHub Actions и Bitbucket Pipelines, размещают агенты на собственных серверах в облаке. Это означает, что вам не нужно беспокоиться об управлении базовой инфраструктурой, и вы можете воспользоваться преимуществами масштабируемости и надежности облака.
* Локально. Локальные решения непрерывной интеграции, такие как Jenkins, позволяют размещать агенты на собственных серверах. Это дает вам больший контроль над базовой инфраструктурой, но также требует больше усилий для управления серверами и их обслуживания.
При выборе решения CI важно учитывать конкретные нужды и требования вашей команды.
Например, если у вас большой и сложный конвейер сборки, лучшим выбором может быть локальное решение, такое как Jenkins, поскольку оно дает вам больший контроль над базовой инфраструктурой.
С другой стороны, если у вас небольшая команда с простыми потребностями, облачное решение, такое как Travis CI, может быть лучшим выбором, так как его легко настроить и им легко управлять.
Отслеживание состояния агента
Отслеживание состояния определяет, сохраняют ли агенты свои данные и конфигурации между сборками.
* Агенты с отслеживанием состояния. Некоторые решения CI, такие как Jenkins, позволяют использовать агенты с отслеживанием состояния, что означает, что агенты сохраняют свои данные и конфигурации между сборками. Это полезно в ситуациях, когда вам нужно сохранять данные между сборками, например, когда вы используете базу данных или запускаете длительные тесты.
* Агенты без сохранения состояния: другие решения CI, такие как Travis CI, используют агенты без сохранения состояния, что означает, что агенты воссоздаются с нуля для каждой сборки. Это обеспечивает чистый лист для каждой сборки, но это также означает, что вам необходимо управлять всеми сохраненными данными и конфигурациями извне, например в базе данных или облачном хранилище.
Среди сторонников CI ведутся оживленные споры о наилучшем подходе. Агенты без сохранения состояния обеспечивают чистую и легко воспроизводимую среду. Я выбираю их для большинства случаев и считаю, что это лучший подход.
Агенты без гражданства также могут быть более дорогими, так как их установка происходит медленнее. Поскольку мы платим за облачные ресурсы, эта стоимость может увеличиваться. Но главная причина, по которой некоторые разработчики предпочитают агенты с отслеживанием состояния, — это возможность проводить расследования.
При использовании агента без сохранения состояния при сбое процесса CI у вас обычно не остается никаких средств расследования, кроме журналов.
С помощью агента с отслеживанием состояния мы можем войти в систему и попытаться запустить процесс вручную на данной машине. Мы можем воспроизвести проблему, которая не удалась, и получить представление благодаря этому.
Компания, с которой я работал, выбрала Azure, а не GitHub Actions, потому что Azure позволяет использовать агенты с отслеживанием состояния. Это было важно для них при отладке неудачного процесса непрерывной интеграции.
Я с этим не согласен, но это личное мнение. Мне кажется, я потратил больше времени на устранение неполадок при очистке плохого агента, чем на исследование ошибки. Но это личный опыт, и некоторые мои умные друзья с этим не согласны.
Повторяемые сборки
Повторяющиеся сборки — это возможность создавать одни и те же артефакты программного обеспечения каждый раз при выполнении сборки, независимо от среды или времени выполнения сборки.
С точки зрения DevOps наличие воспроизводимых сборок необходимо для обеспечения согласованности и надежности развертывания программного обеспечения.
Периодические сбои — бич DevOps повсюду, и их очень сложно отслеживать.
К сожалению, нет простого решения. Как бы нам этого ни хотелось, в проектах разумной сложности присутствует некоторая неряшливость. Наша задача максимально минимизировать это. Есть два блокировщика повторяющихся сборок:
* Зависимости. Если мы не используем определенные версии для зависимостей, даже небольшое изменение может нарушить нашу сборку.
* Ненадежные тесты. Тесты, которые время от времени дают сбой без видимых причин, являются самыми худшими.
При определении зависимостей нам нужно сосредоточиться на конкретных версиях. Существует множество схем управления версиями, но за последнее десятилетие стандартное семантическое управление версиями с тремя числами захватило индустрию.
Эта схема чрезвычайно важна для CI, поскольку ее использование может значительно повлиять на повторяемость сборки, например. с maven мы можем сделать:
<dependency>
<groupId>group</groupId>
<artifactId>artifact</artifactId>
<version>2.3.1</version>
</dependency>
Это очень специфично и отлично подходит для повторяемости. Однако это может быстро устареть. Мы можем заменить номер версии на LATEST или RELEASE, чтобы автоматически получить текущую версию. Это плохо, так как сборки больше не будут повторяться.
Однако жестко закодированный подход с тремя числами также проблематичен. Часто бывает так, что версия патча представляет собой исправление безопасности для ошибки. В этом случае мы хотели бы полностью обновиться до последнего незначительного обновления, но не более новых версий.
Например, для этого предыдущего случая я хотел бы неявно использовать версию 2.3.2, а не 2.4.1. Это компенсирует некоторую повторяемость незначительных обновлений безопасности и ошибок.
Но лучше использовать плагин Maven Versions и периодически вызывать версии mvn:use Команда -latest-releases. При этом версии обновляются до последних, чтобы поддерживать наш проект в актуальном состоянии.
Это простая часть повторяемых сборок. Сложность в ненадежных тестах. Это настолько распространенная проблема, что в некоторых проектах определяется «разумное количество» неудачных тестов, а некоторые проекты повторно запускают сборку несколько раз, прежде чем признать неудачу.
Основной причиной нестабильности тестов является утечка состояния. Тесты могут не пройти из-за незначительных побочных эффектов, оставшихся от предыдущего теста. В идеале тест должен очищаться после себя, чтобы каждый тест выполнялся изолированно.
В идеальном мире мы бы запускали каждый тест в полностью изолированной свежей среде, но это нецелесообразно. Это означало бы, что выполнение тестов заняло бы слишком много времени, и нам пришлось бы ждать много времени для процесса CI.
Мы можем писать тесты с различными уровнями изоляции; иногда нам нужна полная изоляция и может потребоваться развернуть контейнер для теста. Но в большинстве случаев это не так, и разница в скорости значительна.
Уборка после испытаний очень сложна. Иногда утечка состояния из внешних инструментов, таких как база данных, может привести к ошибочному сбою теста. Чтобы обеспечить повторяемость сбоев, общепринятой практикой является последовательная сортировка тестовых случаев; это гарантирует, что будущие запуски сборки будут выполняться в том же порядке.
Это горячо обсуждаемая тема. Некоторые инженеры считают, что это поощряет тесты с ошибками и скрывает проблемы, которые мы можем обнаружить только при случайном порядке тестов. По моему опыту, это действительно нашло ошибки в тестах, но не в коде.
Моя цель не в том, чтобы создавать идеальные тесты, поэтому я предпочитаю запускать тесты в последовательном порядке, например в алфавитном порядке.
Важно вести статистику неудачных тестов и никогда не нажимать просто «повторить». Отслеживая проблемные тесты и порядок их выполнения в случае сбоя, мы часто можем найти источник проблемы.
В большинстве случаев основная причина сбоя возникает из-за неправильной очистки в предыдущем тесте, поэтому важен порядок и его согласованность.
Опыт разработки и производительность CI
Мы здесь, чтобы разработать программный продукт, а не инструмент непрерывной интеграции. Инструмент CI здесь, чтобы сделать процесс лучше. К сожалению, во многих случаях опыт работы с инструментом CI настолько разочаровывает, что в конечном итоге мы тратим больше времени на логистику, чем на написание кода.
Часто я целыми днями пытался пройти проверку CI, чтобы иметь возможность объединить свои изменения. Каждый раз, когда я приближался, другой разработчик первым сливал свои изменения и ломал мою сборку.
Это способствует менее чем звездному опыту разработчиков, особенно когда команда масштабируется, и мы тратим больше времени на очередь CI, чем на слияние наших изменений. Есть много вещей, которые мы можем сделать, чтобы облегчить эти проблемы:
* Сокращение дублирования в тестах. Распространенным симптомом является чрезмерное тестирование, которое мы можем обнаружить с помощью инструментов покрытия.
* Устранение нестабильных тестов — я знаю, что удаление или отключение тестов проблематично. Не делайте этого легкомысленно. Но если вы тратите больше времени на отладку теста, чем на отладку своего кода, его ценность спорна.
* Выделите дополнительные или более быстрые машины для процесса непрерывной интеграции.
* Распараллелить процесс CI. Мы можем распараллелить некоторые типы сборки и некоторые тесты.
* Разделите проект на более мелкие проекты — обратите внимание, что это не обязательно означает микросервисы< /а>.
В конечном счете, это напрямую связано с производительностью разработчиков. Но у нас нет профилировщиков для таких оптимизаций. Мы должны измерять каждый раз; это может быть утомительно.
Действия GitHub
GitHub Actions — это платформа непрерывной интеграции/непрерывной доставки (CI/CD), встроенная в GitHub. Он не имеет состояния, хотя в некоторой степени позволяет размещать агентов самостоятельно. Я сосредоточился на нем, так как он бесплатен для проектов с открытым исходным кодом и имеет приличную бесплатную квоту для проектов с закрытым исходным кодом.
Этот продукт является относительно новым продуктом в этой области, он не такой гибкий, как большинство других инструментов CI, упомянутых ранее. Однако он очень удобен для разработчиков благодаря глубокой интеграции с GitHub и агентами без сохранения состояния.
Для тестирования GitHub Actions нам нужен новый проект, который в данном случае я создал с помощью JHipster с конфигурацией, показанной здесь:
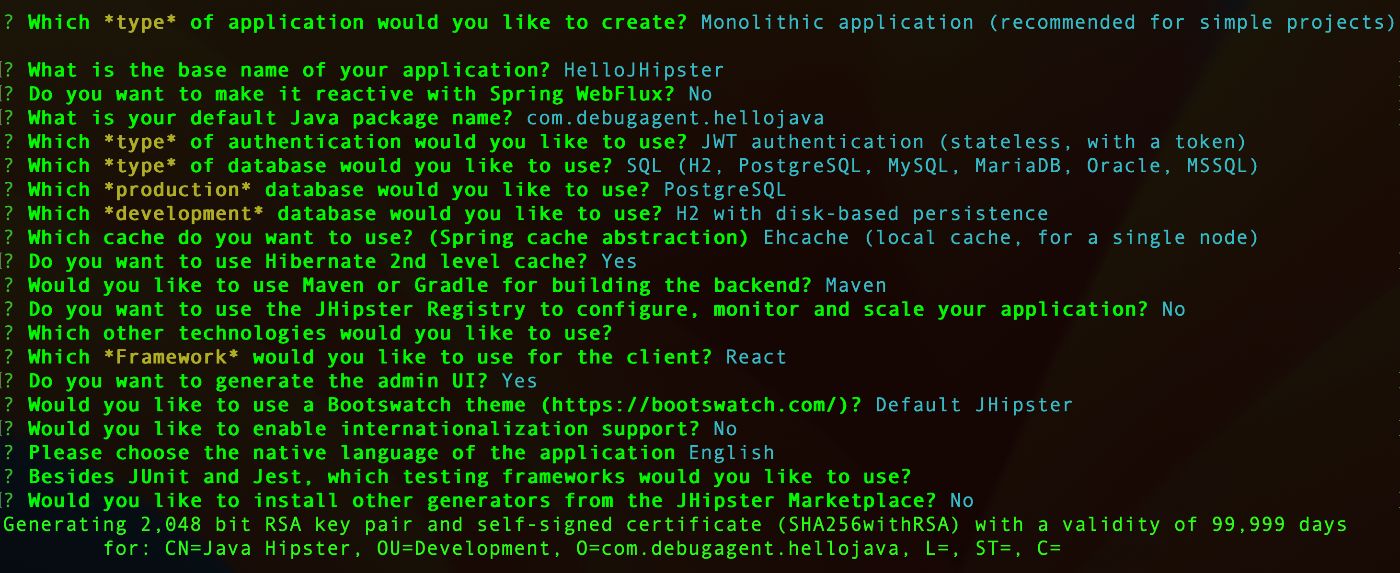
Я создал отдельный проект, демонстрирующий здесь использование GitHub Actions. Обратите внимание, что вы можете следовать этому с любым проектом; хотя в этом случае мы включаем инструкции maven, концепция очень проста.
После создания проекта мы можем открыть страницу проекта на GitHub и перейти на вкладку действий.
Мы увидим что-то вроде этого:
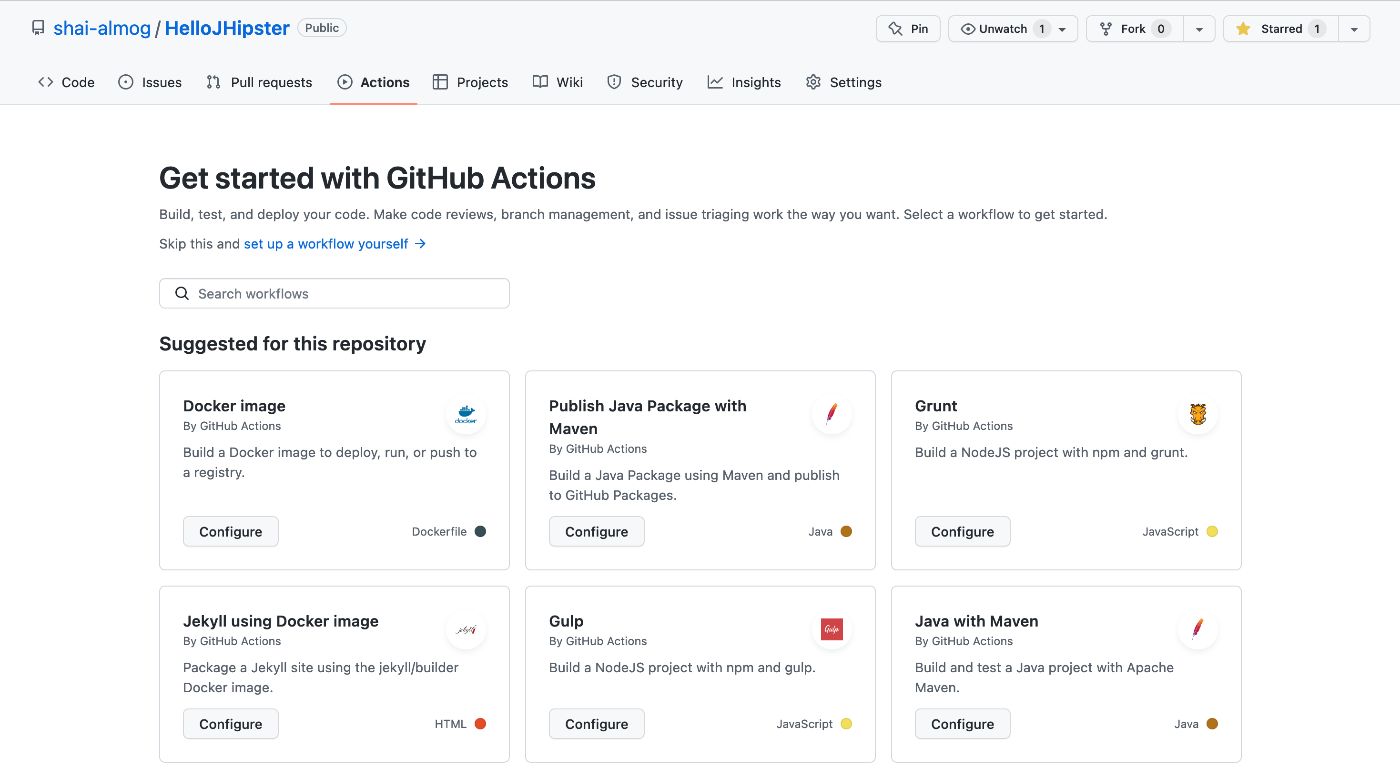
В правом нижнем углу мы видим тип проекта Java с Maven. Выбрав этот тип, мы переходим к созданию файла maven.yml, как показано здесь:
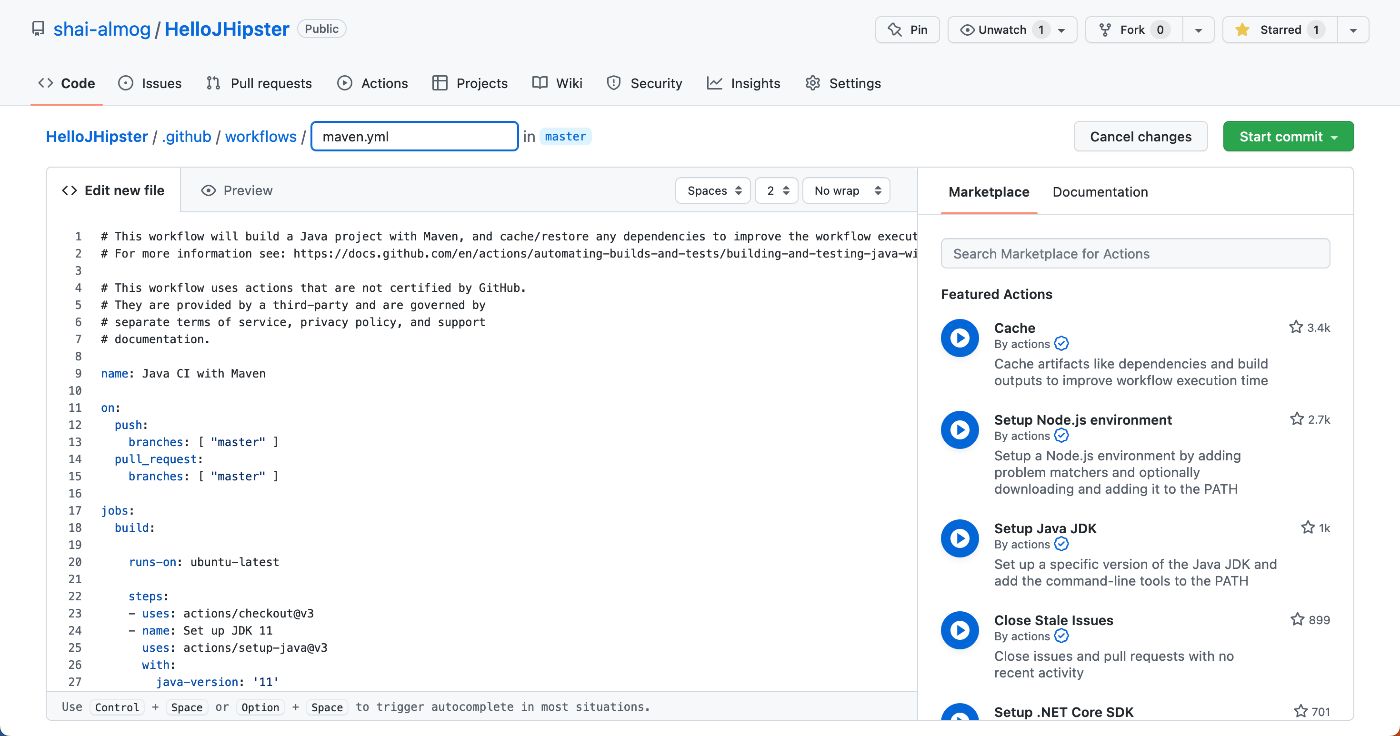
К сожалению, maven.yml по умолчанию, предложенный GitHub, содержит проблему. Это код, который мы видим на этом изображении:
name: Java CI with Maven
on:
push:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
cache: maven
- name: Build with Maven
run: mvn -B package --file pom.xml
# Optional: Uploads the full dependency graph to GitHub to improve the quality of Dependabot alerts this repository can receive
- name: Update dependency graph
uses: advanced-security/maven-dependency-submission-action@571e99aab1055c2e71a1e2309b9691de18d6b7d6
Последние три строки обновляют граф зависимостей. Но эта функция не работает, по крайней мере, у меня. Их удаление решило проблему. Остальной код представляет собой стандартную конфигурацию YAML.
Строки pull_request и push в верхней части кода объявляют, что сборки будут выполняться как по запросу на вытягивание, так и по отправке мастеру. Это означает, что мы можем запускать наши тесты по запросу на вытягивание перед фиксацией. Если тест не пройден, мы не будем фиксировать.
Мы можем запретить коммит с неудачными тестами в настройках проекта. Как только мы зафиксируем файл YAML, мы можем создать запрос на извлечение, и система запустит процесс сборки для нас. Это включает в себя запуск тестов, поскольку цель «пакет» в maven запускает тесты по умолчанию.
Код, который вызывает тесты, находится в строке, начинающейся с «run» ближе к концу. Фактически это стандартная командная строка Unix. Иногда имеет смысл создать сценарий оболочки и просто запустить его из процесса CI.
Иногда проще написать хороший шелл-скрипт, чем разбираться со всеми YAML-файлами и настройками конфигурации различных стеков CI.
Это также более портативно, если мы решим переключить инструмент CI в будущем. Здесь он нам не нужен, так как maven достаточно для наших текущих нужд.
Мы можем увидеть успешный запрос на вытягивание здесь:
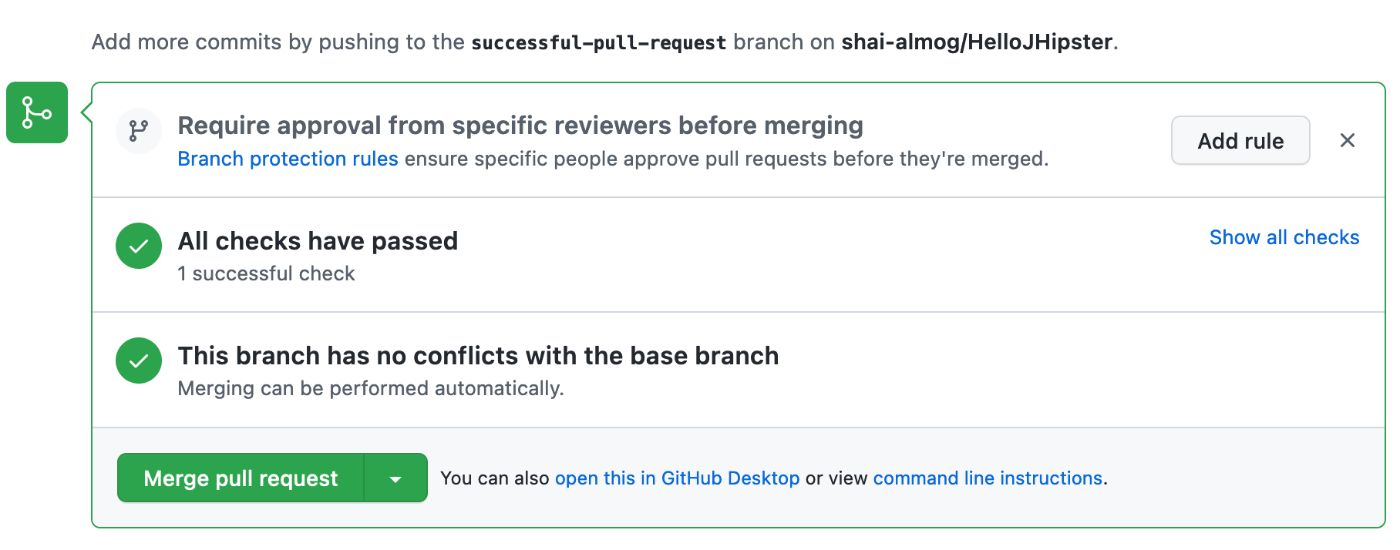
Чтобы проверить это, мы можем добавить ошибку в код, изменив “/api ” конечная точка на “/myapi”. Это приводит к ошибке, показанной ниже. Это также вызывает электронное сообщение об ошибке, отправленное автору коммита.
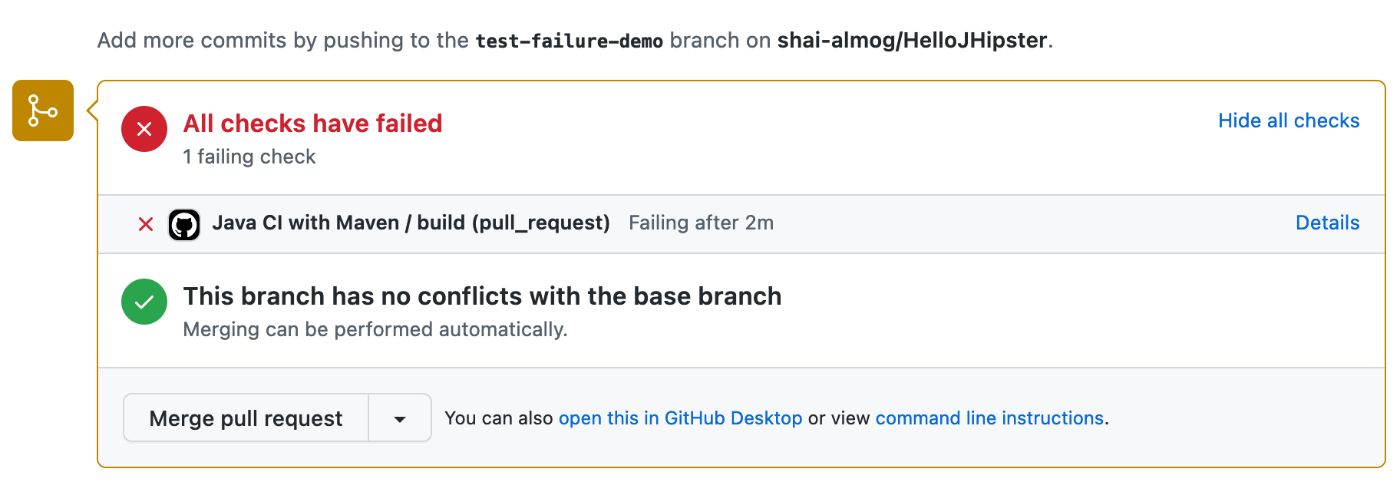
Когда происходит такой сбой, мы можем щелкнуть ссылку «Подробности» с правой стороны. Это приводит нас прямо к сообщению об ошибке, которое вы видите здесь:
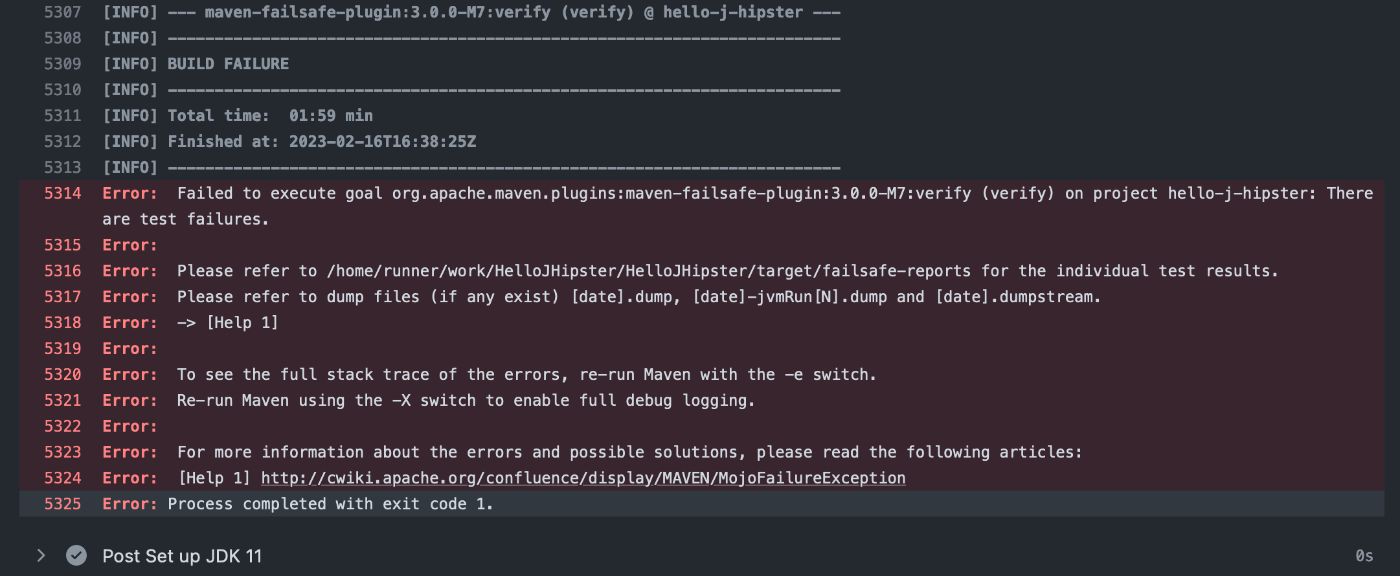
К сожалению, обычно это бесполезное сообщение, которое не помогает в решении проблемы. Однако прокрутка вверх покажет фактический сбой, который обычно удобно выделяется для нас, как показано здесь:
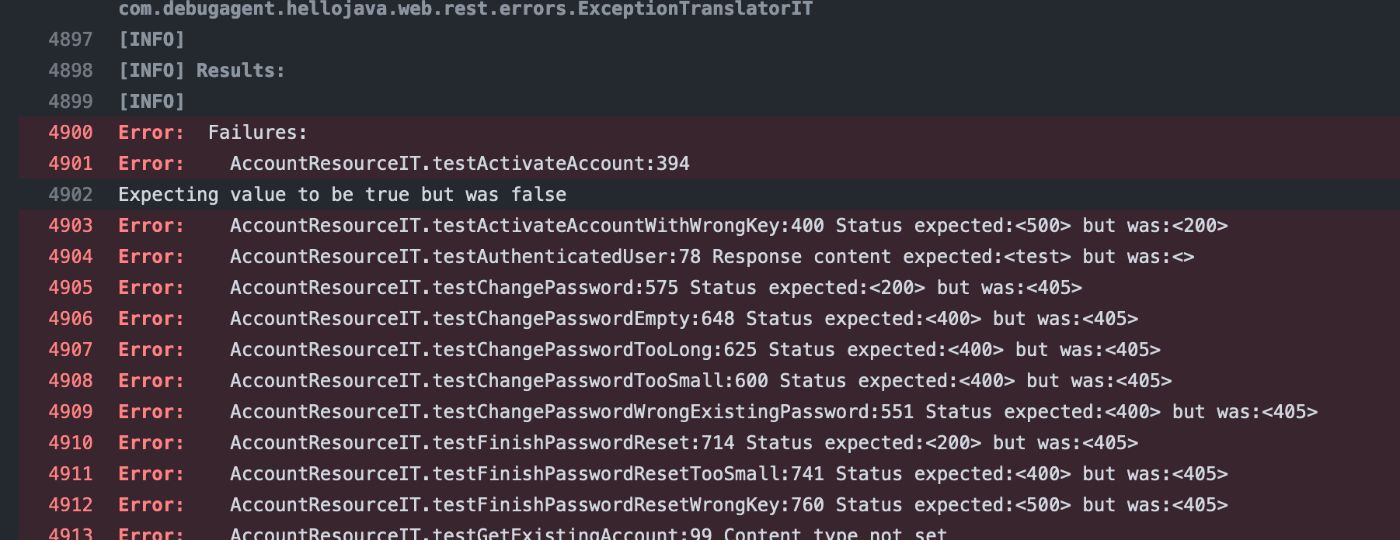
Обратите внимание, что часто бывает несколько сбоев, поэтому было бы разумно прокрутить дальше. В этой ошибке мы видим, что ошибкой было утверждение в строке 394 AccountResourceIT, которое вы можете увидеть здесь, обратите внимание, что номера строк не совпадают. В этом случае строка 394 является последней строкой метода:
@Test
@Transactional
void testActivateAccount() throws Exception {
final String activationKey = "some activation key";
User user = new User();
user.setLogin("activate-account");
user.setEmail("activate-account@example.com");
user.setPassword(RandomStringUtils.randomAlphanumeric(60));
user.setActivated(false);
user.setActivationKey(activationKey);
userRepository.saveAndFlush(user);
restAccountMockMvc.perform(get("/api/activate?key={activationKey}", activationKey)).andExpect(status().isOk());
user = userRepository.findOneByLogin(user.getLogin()).orElse(null);
assertThat(user.isActivated()).isTrue();
}
Это означает, что вызов assert не удался. isActivated() вернул false и не прошел тест. Это должно помочь разработчику сузить круг проблемы и понять основную причину.
Выйти за рамки
Как мы упоминали ранее, непрерывная интеграция предназначена для повышения производительности труда разработчиков. Мы можем пойти намного дальше, чем просто компилировать и тестировать. Мы можем обеспечивать соблюдение стандартов кодирования, анализировать код, обнаруживать уязвимости в системе безопасности и многое другое.
В этом примере давайте интегрируем Sonar Cloud, мощный инструмент анализа кода (линтер). Он находит потенциальные ошибки в вашем проекте и помогает улучшить качество кода.
SonarCloud — это облачная версия SonarQube, которая позволяет разработчикам постоянно проверять и анализировать свой код, чтобы находить и устранять проблемы, связанные с качеством кода, безопасностью и ремонтопригодностью. Он поддерживает различные языки программирования, такие как Java, C#, JavaScript, Python и другие.
SonarCloud интегрируется с популярными инструментами разработки, такими как GitHub, GitLab, Bitbucket, Azure DevOps и другими. Разработчики могут использовать SonarCloud, чтобы в режиме реального времени получать отзывы о качестве своего кода и улучшать общее качество кода.
С другой стороны, SonarQube — это платформа с открытым исходным кодом, которая предоставляет инструменты статического анализа кода для разработчиков программного обеспечения. Он предоставляет панель мониторинга, которая показывает сводку качества кода и помогает разработчикам выявлять и устранять проблемы, связанные с качеством кода, безопасностью и ремонтопригодностью.
И SonarCloud, и SonarQube предоставляют аналогичные функции, но SonarCloud — это облачная служба, требующая подписки, а SonarQube — это платформа с открытым исходным кодом, которую можно установить локально или на облачном сервере.
Для простоты мы будем использовать SonarCloud, но SonarQube должен работать нормально. Для начала заходим на sonarcloud.io и регистрируемся. В идеале с нашей учетной записью GitHub. Затем нам предоставляется возможность добавить репозиторий для мониторинга с помощью Sonar Cloud, как показано здесь:
Когда мы выбираем опцию «Анализ новой страницы», нам нужно авторизовать доступ к нашему репозиторию GitHub. Следующим шагом является выбор проектов, которые мы хотим добавить в Sonar Cloud, как показано здесь:
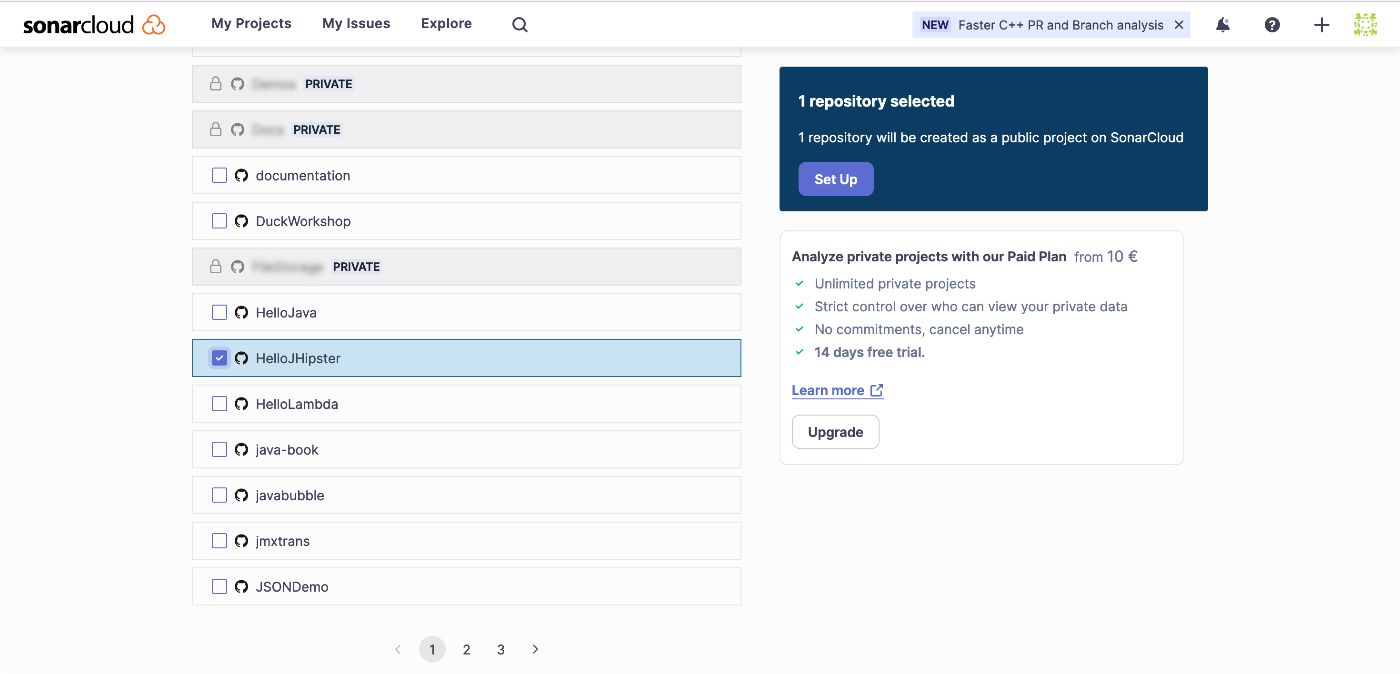
После выбора и перехода к процессу настройки нам нужно выбрать метод анализа. Поскольку мы используем GitHub Actions, нам нужно выбрать этот параметр на следующем этапе, как показано здесь:
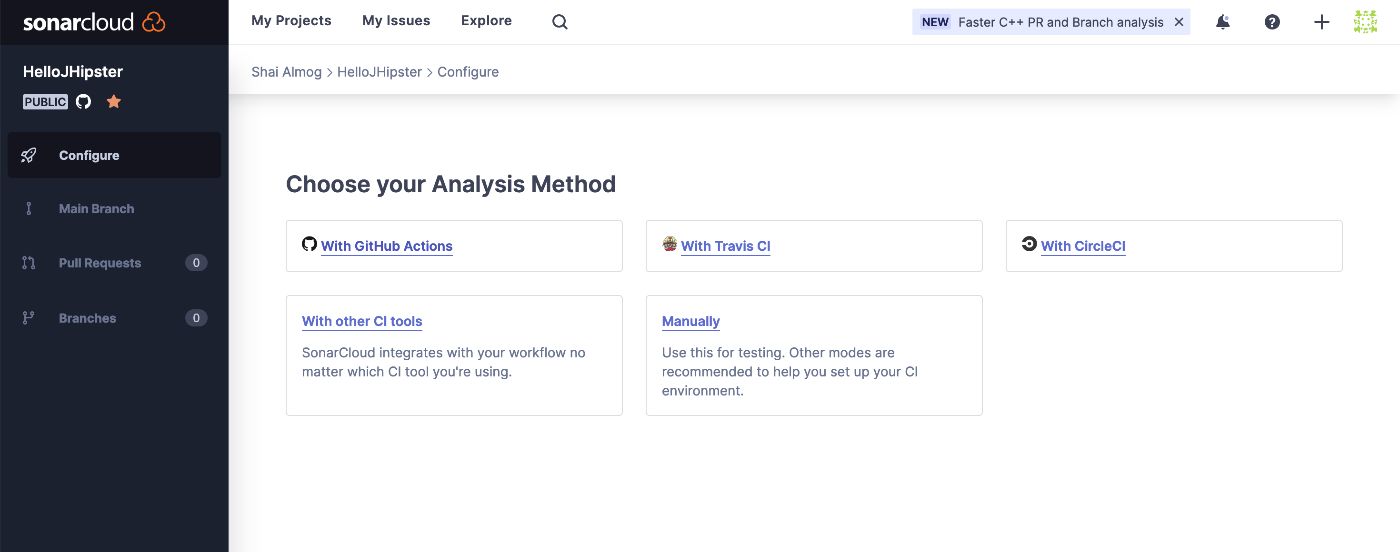
После того, как это установлено, мы переходим к заключительному этапу в мастере Sonar Cloud, как показано на следующем изображении. Мы получаем токен, который мы можем скопировать (запись 2 размыта на изображении), и мы будем использовать его в ближайшее время.
Обратите внимание, что есть также инструкции по умолчанию для использования с maven, которые появляются после нажатия кнопки с надписью «Maven».
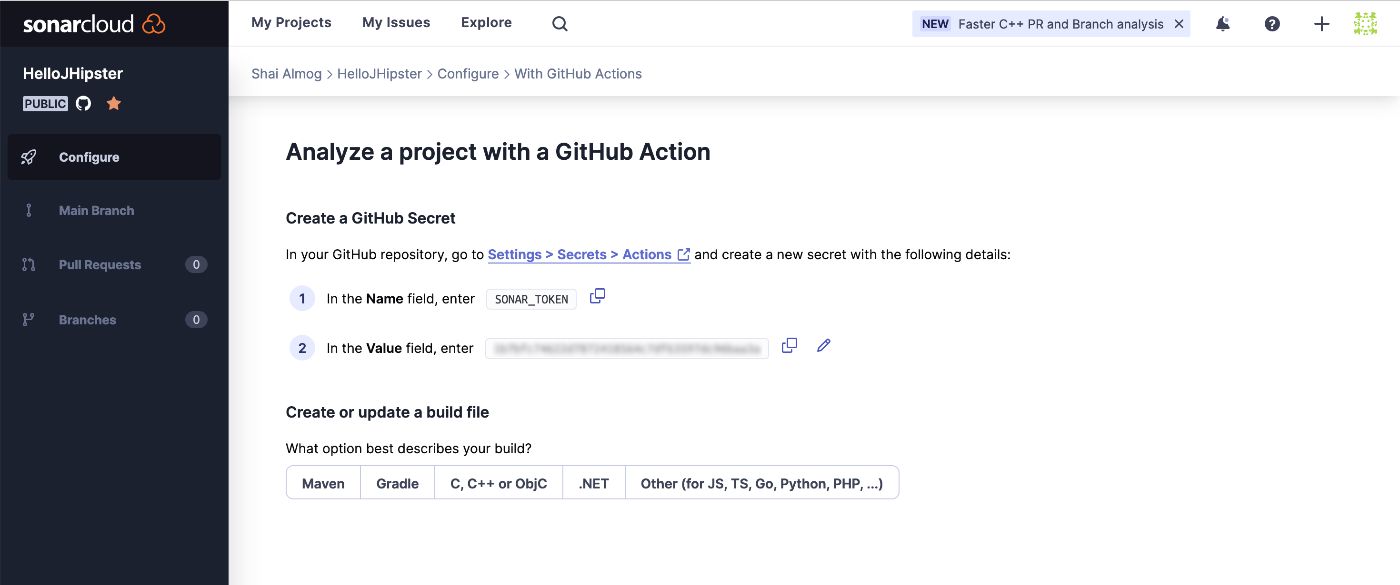
Вернувшись к проекту в GitHub, мы можем перейти на вкладку настроек проекта (не путать с настройками учетной записи в верхнем меню). Здесь мы выбираем «Секреты и переменные», как показано здесь:
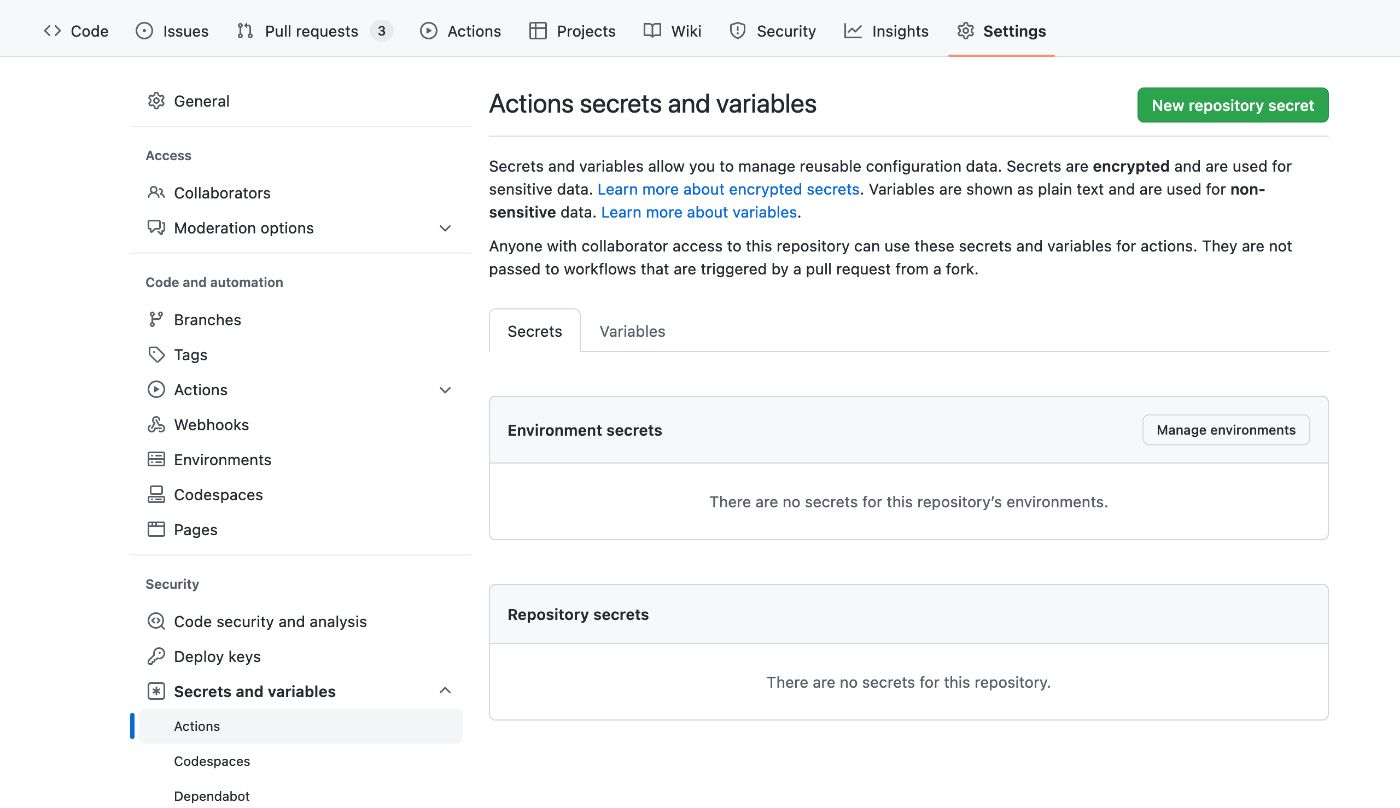
В этом разделе мы можем добавить новый секрет репозитория, в частности ключ и значение SONAR_TOKEN, которые мы скопировали из SonarCloud, как вы можете видеть здесь:
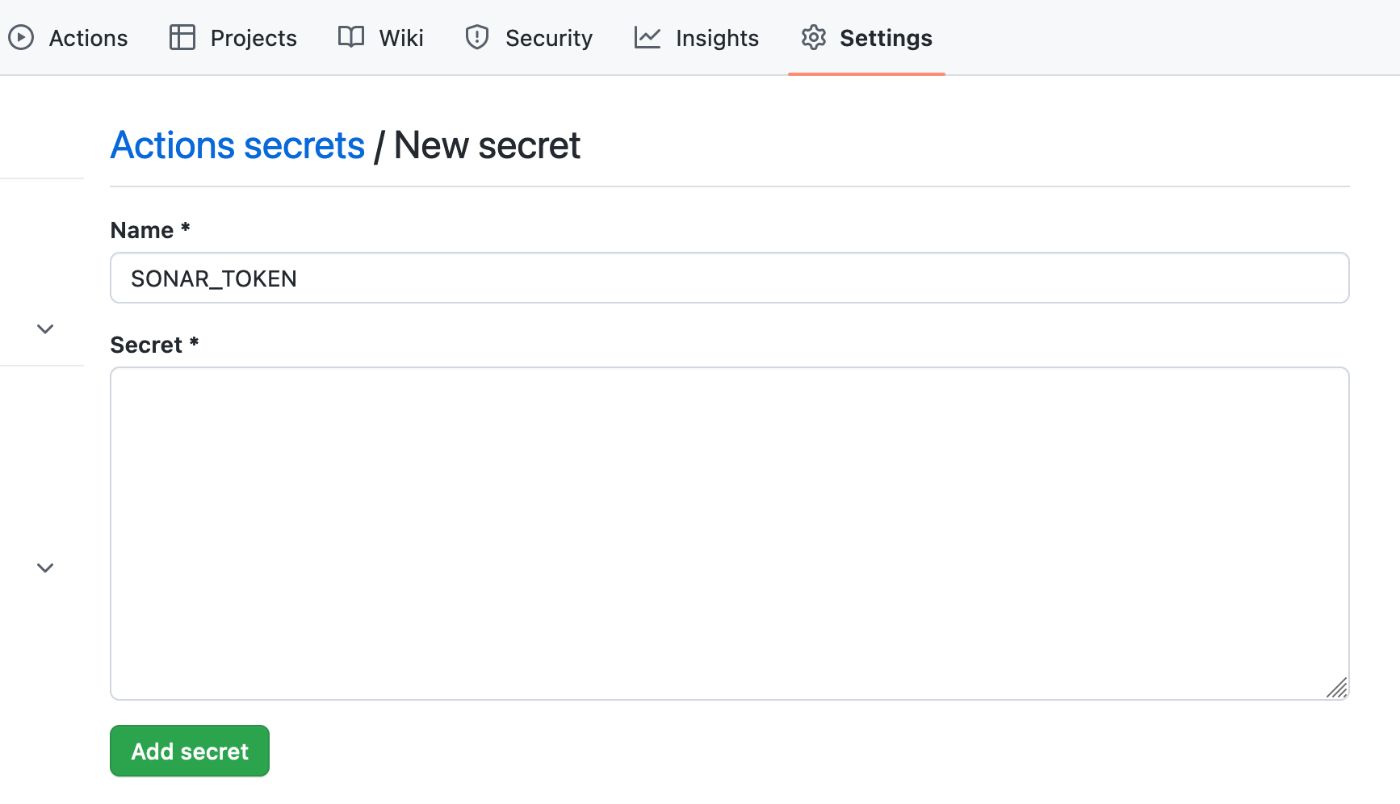
Секреты репозитория GitHub — это функция, которая позволяет разработчикам безопасно хранить конфиденциальную информацию, связанную с репозиторием GitHub, такую как ключи API, токены и пароли, необходимые для аутентификации и авторизации доступа к различным сторонним службам или платформам, используемым репозиторием. .
Концепция GitHub Repository Secrets заключается в предоставлении безопасного и удобного способа управления и обмена конфиденциальной информацией без необходимости публичного раскрытия информации в коде или файлах конфигурации.
Используя секреты, разработчики могут хранить конфиденциальную информацию отдельно от кодовой базы и защищать ее от раскрытия или компрометации в случае нарушения безопасности или несанкционированного доступа.
Секреты репозитория GitHub надежно хранятся и доступны только авторизованным пользователям, которым предоставлен доступ к репозиторию. Секреты можно использовать в рабочих процессах, действиях и других скриптах, связанных с репозиторием.
Их можно передавать в код как переменные среды, чтобы он мог получать доступ к секретам и использовать их безопасным и надежным способом.
В целом секреты репозитория GitHub предоставляют разработчикам простой и эффективный способ управления и защиты конфиденциальной информации, связанной с репозиторием, помогая обеспечить безопасность и целостность проекта и данных, которые он обрабатывает.
Теперь нам нужно интегрировать это в проект. Во-первых, нам нужно добавить эти две строки в файл pom.xml. Обратите внимание, что вам нужно обновить название организации, чтобы оно соответствовало вашему собственному. Они должны войти в раздел в XML:
<sonar.organization>shai-almog</sonar.organization> <sonar.host.url>https://sonarcloud.io</sonar.host.url>
Обратите внимание, что созданный нами проект JHipster уже имеет поддержку SonarQube, которую следует удалить из файла pom перед этим кодом. будет работать.
После этого мы можем заменить часть файла maven.yml «Build with Maven» на следующую версию:
- name: Build with Maven
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # Needed to get PR information, if any
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}
run: mvn -B verify org.sonarsource.scanner.maven:sonar-maven-plugin:sonar -Dsonar.projectKey=shai-almog_HelloJHipster package
Как только мы это сделаем, SonarCloud будет предоставлять отчеты для каждого запроса на включение в систему, как показано здесь:
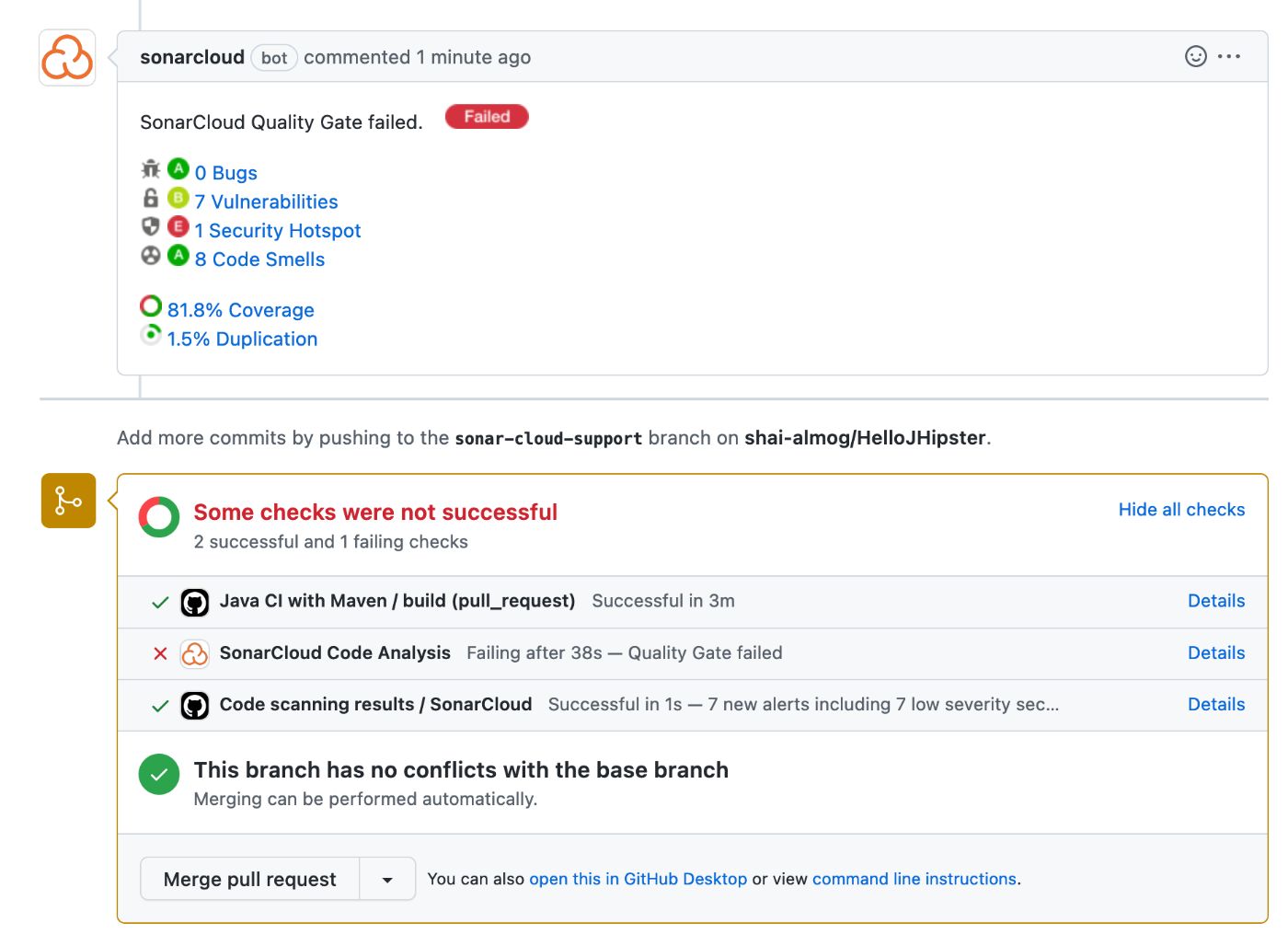
Мы видим отчет, который включает в себя список ошибок, уязвимостей, запахов и проблем безопасности. Нажав на каждую из этих проблем, мы получим что-то вроде этого:
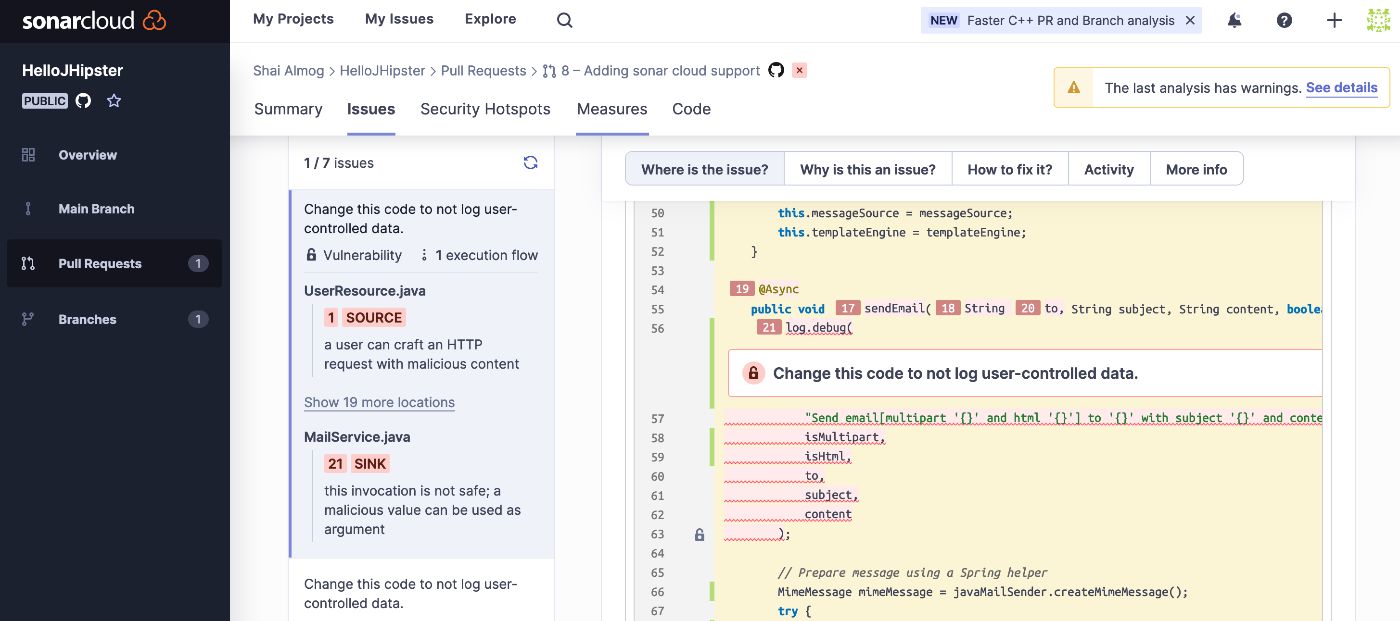
Обратите внимание, что у нас есть вкладки, которые точно объясняют, почему проблема является проблемой, как ее исправить и многое другое. Это чрезвычайно мощный инструмент, который служит одним из самых ценных рецензентов кода в команде.
Два дополнительных интересных элемента, которые мы видели ранее, — это отчеты о покрытии и дублировании. SonarCloud ожидает, что тесты будут иметь 80% покрытие кода (запускают 80% кода в запросе на включение), это высокий показатель, который можно настроить в настройках.
Он также указывает на повторяющийся код, который может указывать на нарушение принципа «Не повторяйся» (DRY).
Наконец-то
Конвертерная интеграция — это обширная тема, в которой есть много возможностей улучшить ход вашего проекта. Мы можем автоматизировать обнаружение ошибок. Оптимизируйте создание артефактов, автоматическую доставку и многое другое. Но, по моему скромному мнению, основным принципом CI является опыт разработчиков.
Он здесь, чтобы сделать нашу жизнь проще.
Когда это сделано плохо, процесс CI может превратить этот удивительный инструмент в кошмар. Прохождение тестов становится бесполезным упражнением. Мы повторяем попытку снова и снова, пока, наконец, не сможем слиться. Мы часами ждем, чтобы слиться из-за медленных, переполненных очередей.
Этот инструмент, который должен был помочь, становится нашим врагом. Этого не должно быть. Конвергентная инфраструктура должна делать нашу жизнь проще, а не наоборот.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)