
Подробная структура интеллектуального предоставления ликвидности в Uniswap V3
21 декабря 2023 г.Обеспечение ликвидности в Uniswap V3 представляет собой задачу стохастического оптимального управления с четко определенной функцией полезности, которую необходимо максимизировать. В этой статье представлена инновационная платформа для интеллектуального обеспечения ликвидности, использующая сочетание агентного моделирования и обучения с подкреплением. Наша структура обеспечивает надежное и адаптивное решение для оптимизации стратегий предоставления ликвидности. Модель Uniswap V3 имитирует реальные рыночные условия, а модель на основе агентов (ABM) создает среду для моделирования взаимодействия агентов с пулами Uniswap V3. Агент обучения с подкреплением, обученный с использованием глубоких детерминированных политических градиентов (DDPG), изучает оптимальные стратегии, демонстрируя потенциал машинного обучения в расширении участия в DeFi. Этот подход направлен на повышение прибыльности поставщиков ликвидности и улучшение понимания рынков CFMM.
Обзор содержания
- Введение
- Интеллектуальная система обеспечения ликвидности
- Компоненты интеллектуальной системы обеспечения ликвидности
- Агентный симулятор
- Модель обучения с подкреплением
- Ограничения
- Дальнейшая работа
- Заключение
- Ресурсы
- Ссылки
Введение
В моей предыдущей статье о маркет-мейкинге [Механика и стратегии маркет-мейкинга] мы исследовали механику и стратегии маркет-мейкинга на традиционных финансовых рынках. Опираясь на эти идеи, в этой статье представлена инновационная платформа для интеллектуального предоставления ликвидности в контексте Uniswap V3. Как упоминалось в нашем предыдущем исследовании, нашей целью было расширить наше понимание динамики рынка и управления ликвидностью в децентрализованных финансах ( DeFi), в частности посредством разработки системы интеллектуального обеспечения ликвидности.
Децентрализованные финансы (DeFi) претерпели значительный рост, представив инновационные финансовые продукты и услуги, доступные глобальной аудитории. Uniswap V3, находящийся в авангарде этой инновации, произвел революцию в обеспечении ликвидности благодаря своей функции концентрированной ликвидности. Однако это достижение ставит перед поставщиками ликвидности сложные проблемы с принятием решений. В этой статье представлена комплексная структура, предназначенная для решения этих проблем, а также моделируемая среда для изучения и оптимизации стратегий предоставления ликвидности.
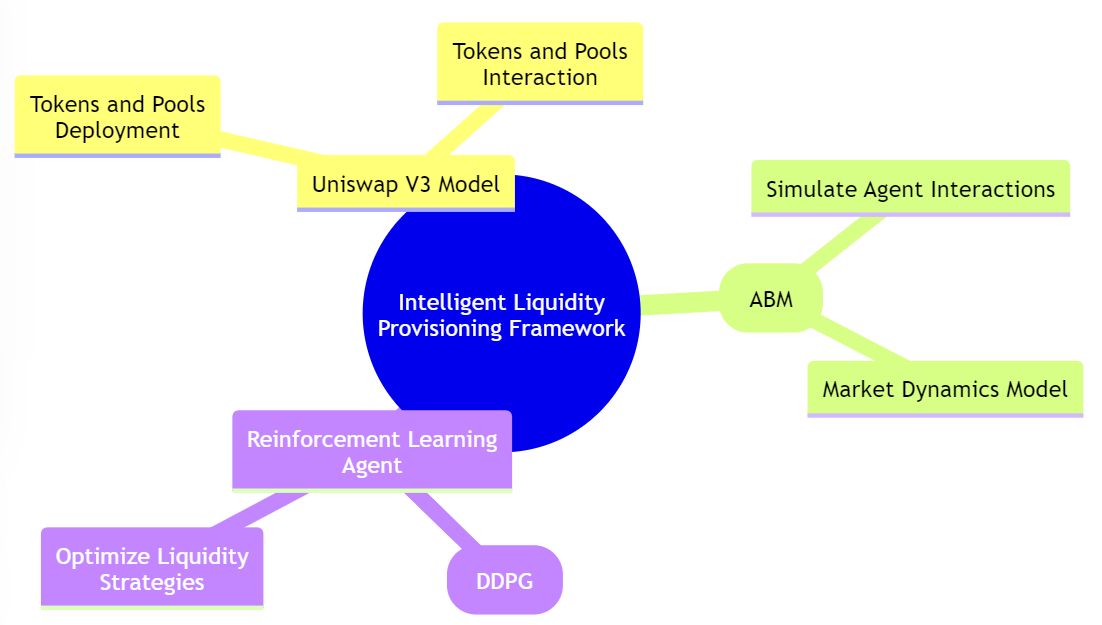
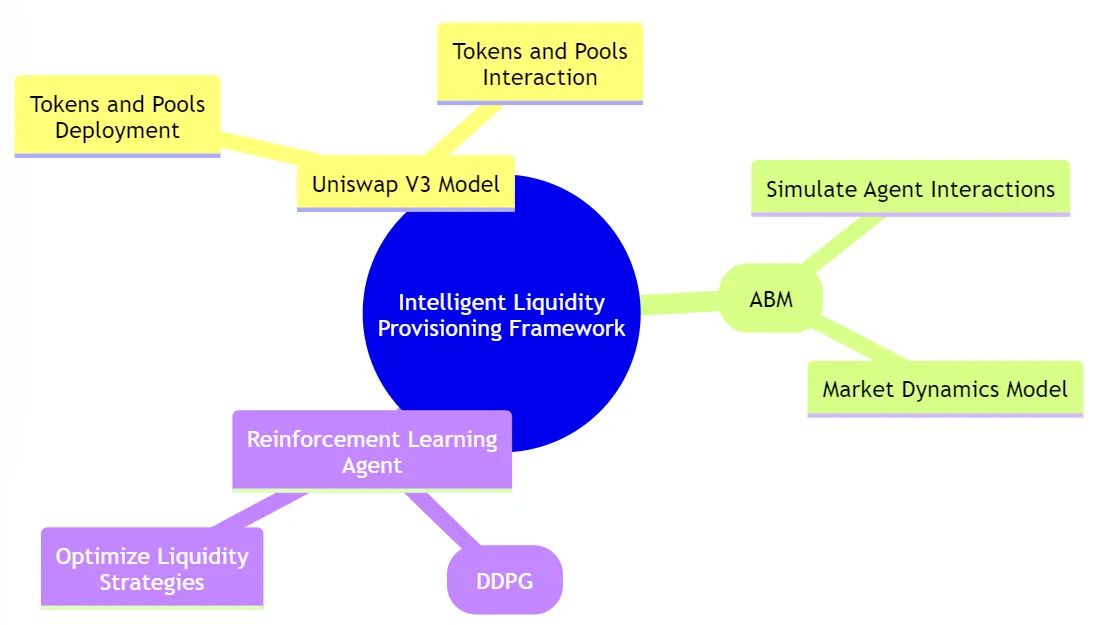
Наша структура состоит из трех ключевых компонентов: модели Uniswap V3, агентной модели (ABM) и агента обучения с подкреплением. Модель Uniswap V3 обеспечивает представление пула, позволяя развертывать токены и пулы и взаимодействовать с ними. ABM усложняет задачу, моделируя взаимодействие агентов и динамику рынка, создавая богатую среду для оценки стратегии. Агент обучения с подкреплением, работающий в этой среде, применяет глубокий детерминированный политический градиентный подход для изучения и адаптации стратегий, стремясь к оптимальной производительности при предоставлении ликвидности.
Это исследование направлено на разработку интеллектуального механизма предоставления ликвидности (ILP) с использованием обучения с подкреплением (RL) для автономного управления и оптимизации ликвидности в среде Uniswap V3. Механизм направлен на максимизацию функции полезности с учетом полученных комиссий, непостоянных потерь и других показателей, основанных на предпочтениях поставщиков ликвидности, при этом адаптируясь к сложной динамике рынка CFMM.
Интеллектуальная система обеспечения ликвидности
В рамках RL проблема обеспечения ликвидности формулируется как Марковский процесс принятия решений (MDP). MDP состоит из состояний, действий и вознаграждений.
* Штаты. Штаты отражают текущие рыночные условия, включая цены на активы, объемы торговли и другие соответствующие переменные.
* Действия: Действия соответствуют решениям, принятым поставщиком ликвидности, например корректировка распределения ликвидности, ребалансировка портфелей и т. д.
* Награды. Вознаграждения количественно определяют желательность результатов на основе целевой функции, предпочтений и ограничений поставщика ликвидности. Награды могут быть положительными за желательные результаты (например, высокую доходность) и отрицательными за нежелательные результаты (например, высокий риск или низкая эффективность).
* Целевая функция: Целевая функция представляет собой желаемый результат поставщика ликвидности, который может представлять собой комбинацию таких факторов, как максимизация доходности, минимизация рисков или достижение определенного компромисса между ними. Ограничения могут включать ограничения на распределение ликвидности, использование капитала, уровни толерантности к риску или другие ограничения, определенные поставщиком ликвидности.
Обучение RL – это итеративный процесс, в ходе которого агент постоянно обновляет свою политику на основе отзывов. Агент учится на своем опыте и со временем совершенствует свои решения, постепенно переходя к более оптимальным стратегиям предоставления ликвидности.
После обучения агента RL его можно протестировать и оценить с использованием исторических данных или смоделированных сред, чтобы оценить его эффективность в сравнении с целевой функцией и ограничениями поставщика ликвидности. Эффективность агента можно измерить с помощью таких показателей, как прибыль, показатели риска или другие соответствующие показатели эффективности.
Применяя алгоритм RL, механизм обеспечения ликвидности может учиться и адаптироваться к изменяющимся рыночным условиям, определять оптимальные стратегии обеспечения ликвидности, а также ограничения баланса и предпочтения, указанные поставщиком ликвидности. RL позволяет механизму найти решения, которые максимизируют целевую функцию поставщика ликвидности, рассматривая различные компромиссы и ограничения автономно и динамически.
Компоненты интеллектуальной структуры обеспечения ликвидности
Система состоит из трех основных компонентов:
Модель UniswapV3
Модель Uniswap V3, реализованная на Python, предлагает детальное и функциональное моделирование протокола Uniswap V3, отражающее его тонкую механику и предоставляющее пользователям комплексный набор инструментов для взаимодействия с протоколом. Класс UniswapV3_Model управляет развертыванием токенов и пулов, инициализирует пулы и предоставляет интерфейс для действий пула и получения состояния пула.
Обзор
Модель Uniswap служит основой интеллектуальной системы обеспечения ликвидности, в которой заключена основная механика Uniswap V3. Он использует скомпилированные смарт-контракты из Uniswap V3-Core, развернутые в локальной среде Ganache с помощью Brownie, для создания реалистичной и интерактивной симуляции.
Составление и развертывание контракта
Среда интегрируется с Brownie, средой разработки и тестирования смарт-контрактов на основе Python, для компиляции и развертывания смарт-контрактов Uniswap V3. Эти контракты затем развертываются в локальной среде Ganache, предоставляя «песочницу» для тестирования и разработки. Такая настройка гарантирует, что пользователи могут взаимодействовать со средой Uniswap без необходимости использования реальных активов или сетевых транзакций, создавая безопасное и контролируемое пространство для экспериментов.
Агентный симулятор
Симулятор на основе агента Tokenspice используется для моделирования среды Uniswap V3, политика агентов определяется с учетом динамики рынка Uniswap. участники. Для моделирования динамической среды Uniswap используются различные типы агентов
Введение
Агентная модель Tokenspice (ABM) моделирует действия и взаимодействие отдельных агентов в экосистеме Uniswap V3. Моделируя сложное поведение различных участников, ABM обеспечивает комплексный интерфейс динамической среды Uniswap V3, позволяющий анализировать и оптимизировать стратегии предоставления ликвидности.
Типы и поведение агентов
ABM включает в себя различные типы агентов, каждый из которых представляет определенную роль в экосистеме Uniswap V3. Двумя основными агентами являются агент поставщика ликвидности и агент обмена, которые взаимодействуют с пулами Uniswap для обеспечения ликвидности и выполнения обмена токенов соответственно. Поведение этих агентов определяется политиками, определенными в файле agents_policies.py, что гарантирует соответствие их действий реальным стратегиям и рыночным условиям.
* Агент поставщика ликвидности: Этот агент добавляет и удаляет ликвидность из пулов Uniswap. Он следует набору политик, которые диктуют его действия на основе текущего состояния рынка и предпочтений агента.
* Агент обмена: Агент обмена выполняет обмен токенов внутри пулов Uniswap, используя разницу в ценах и возможности арбитража. Его поведение определяется политикой, которая оценивает потенциальную прибыльность сделок с учетом комиссий за транзакции и проскальзываний.
Конфигурация и выполнение моделирования
Файл netlist.py занимает центральное место в ABM, настраивая взаимодействие агентов друг с другом и с пулами Uniswap. Он определяет отношения между агентами, политиками и средой моделирования.
Модули SimEngine.py, SimStateBase.py и SimStrategyBase.py предоставляют базовые элементы для запуска моделирования. SimEngine организует моделирование, управляет течением времени и выполнением действий агента. SimStateBase поддерживает текущее состояние моделирования, сохраняя данные о наличии агентов, состояниях пулов и других соответствующих переменных. SimStrategyBase определяет всеобъемлющие стратегии, которые определяют поведение агента на протяжении всего моделирования.
Модель обучения с подкреплением
Введение
Агент обучения с подкреплением (RL) — это ключевой компонент интеллектуальной системы обеспечения ликвидности, предназначенный для взаимодействия с экосистемой Uniswap V3 через модель Uniswap Model, основанную на агентах. В этом разделе подробно рассматривается агент RL, его среда и алгоритм DDPG (глубокий детерминированный политический градиент), используемый для обучения.
Среда агента RL
Агент RL работает в специальной среде DiscreteSimpleEnv, которая взаимодействует с моделью Uniswap и моделью на основе агентов для моделирования рынка DeFi. Эта среда облегчает взаимодействие агента с пулами Uniswap, позволяя ему добавлять и удалять ликвидность, а также наблюдать за последствиями своих действий. Агент RL взаимодействует с моделью Uniswap и ABM для имитации реального предоставления ликвидности в Uniswap V3. Он выбирает действия, которые приводят к добавлению или удалению ликвидности, с помощью политик и конфигураций моделирования, определенных в ABM, что обеспечивает реалистичное взаимодействие.
* Пространство состояний. Пространство состояний среды включает в себя различные рыночные индикаторы, такие как текущая цена, ликвидность и рост комиссий. Эти параметры нормализуются и передаются агенту на каждом временном шаге.
* Пространство действий. Пространство действий агента состоит из непрерывных значений, представляющих границы цен для добавления ликвидности в пул Uniswap. Эти действия преобразуются во взаимодействие с пулами Uniswap, влияя на состояние среды.
* Функция вознаграждения: Функция вознаграждения имеет решающее значение для обучения агента RL. Он учитывает комиссионный доход, непостоянные убытки, стоимость портфеля и потенциальные штрафы, обеспечивая скалярный сигнал вознаграждения, который поможет агенту в процессе обучения.
Агент DDPG
Агент DDPG — это немодальный, внеполитический алгоритм, использующий аппроксиматоры глубоких функций. Он может обрабатывать многомерные пространства состояний и пространства непрерывных действий, что делает его хорошо подходящим для нашей среды Uniswap V3.
* Сеть актеров: Эта сеть отвечает за обеспечение наиболее ожидаемого действия в данном состоянии. Он имеет сигмовидный выходной слой, выводящий относительные значения для price_lower и price_upper, которые затем масштабируются до желаемого диапазона в среде агента, представляя ценовые границы для добавления ликвидности. * Сеть критиков. Эта сеть оценивает функцию ценности действия, оценивая ожидаемую отдачу от выполнения действия в заданном состоянии. * Целевые сети: DDPG использует целевые сети как для актера, так и для критика, которые медленно обновляются для стабилизации обучения. * Воспроизведение опыта. Этот метод используется для хранения буфера воспроизведения прошлого опыта, позволяя агенту учиться на разнообразном наборе образцов, разрушая корреляции в наблюдениях и сглаживая обучение.
Взаимодействие с моделью Uniswap и ABM
Агент RL использует модель Uniswap и модель на основе агентов для имитации реального предоставления ликвидности в Uniswap V3. Он взаимодействует с пулами Uniswap через DiscreteSimpleEnv, выполняя действия, которые приводят к добавлению или удалению ликвидности. Политики агента и конфигурация моделирования определяются в компоненте ABM, что обеспечивает реалистичную и согласованную динамическую среду.
* Обучение и оценка агента: Агент обучается в ходе серии эпизодов, каждый из которых представляет отдельный рыночный сценарий (различный пул). Эффективность агента оценивается на основе его способности максимизировать прибыль при минимизации рисков, связанных с предоставлением ликвидности. Эффективность системы интеллектуальной системы обеспечения ликвидности оценивается посредством оценки эффективности агента обучения с подкреплением (RL).
* Настройка среды. Для оценки агента RL мы настроили специализированную среду оценки DiscreteSimpleEnvEval, которая расширяет базовую среду DiscreteSimpleEnv. Эта среда предназначена для оценки политик агентов.
* Базовый агент: В нашей настройке оценки мы сравниваем производительность агента RL с производительностью базового агента. Действия базового агента определяются базовой политикой, которая опирается на текущее состояние пула ликвидности. Целью этого агента является предоставление ориентира для оценки эффективности агента RL.
Результаты
Обучение
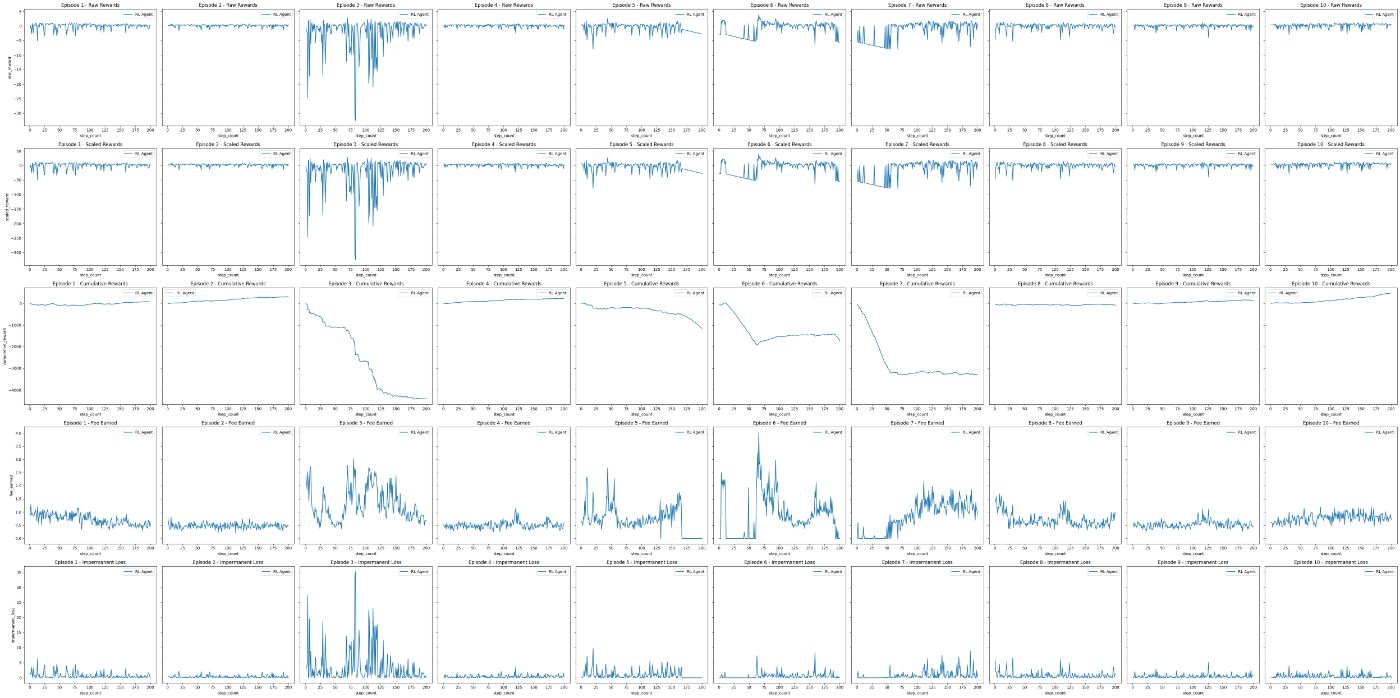
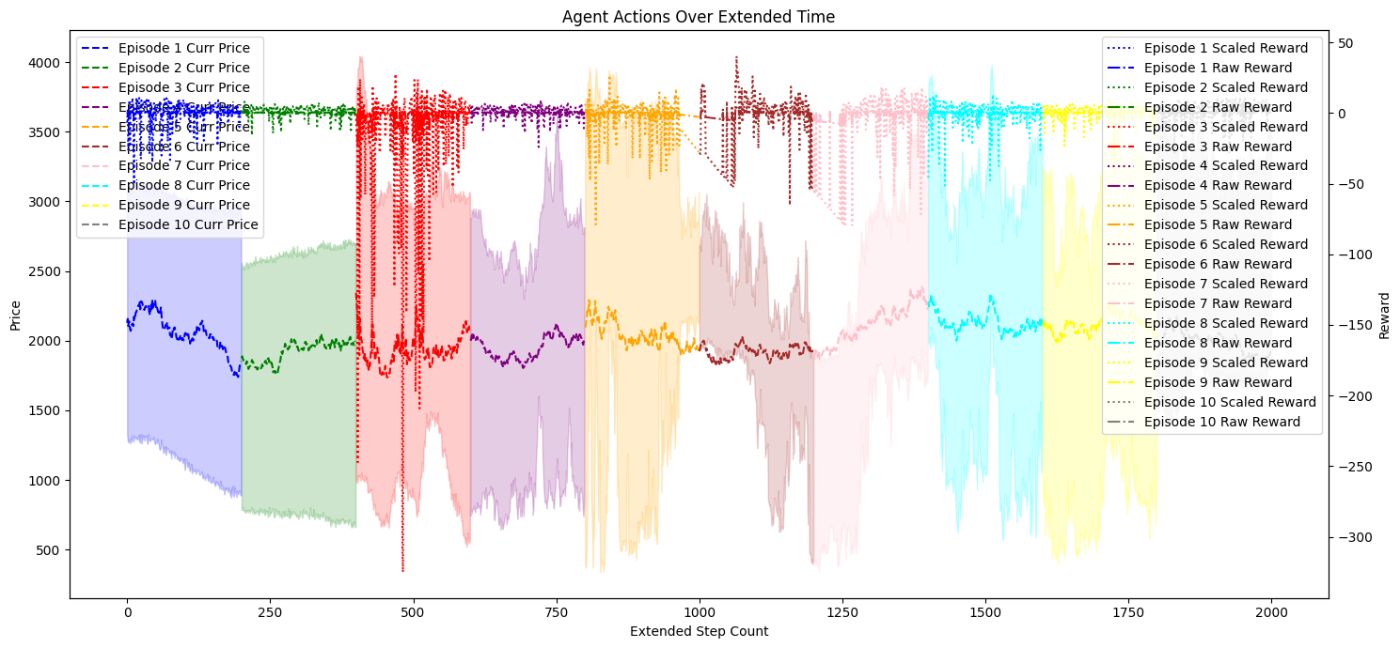
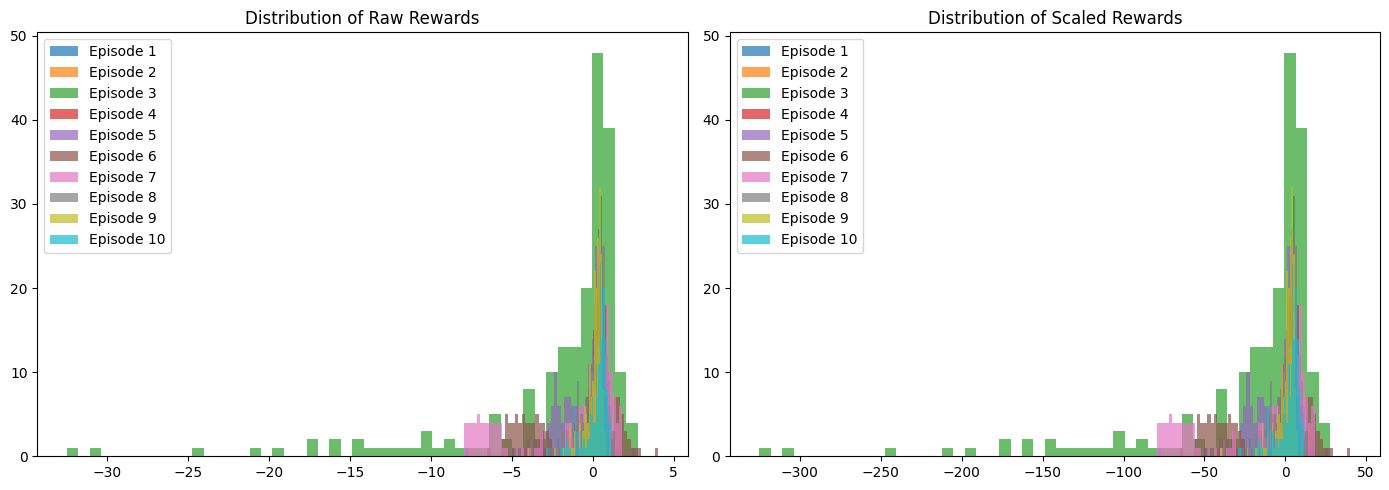
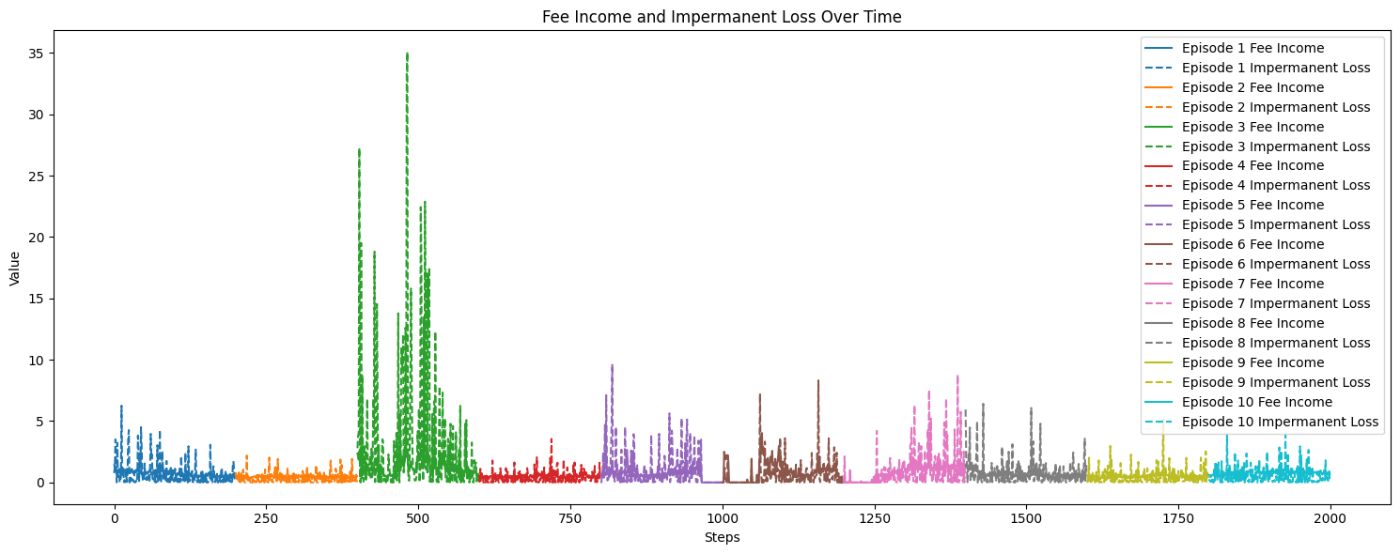
Оценка
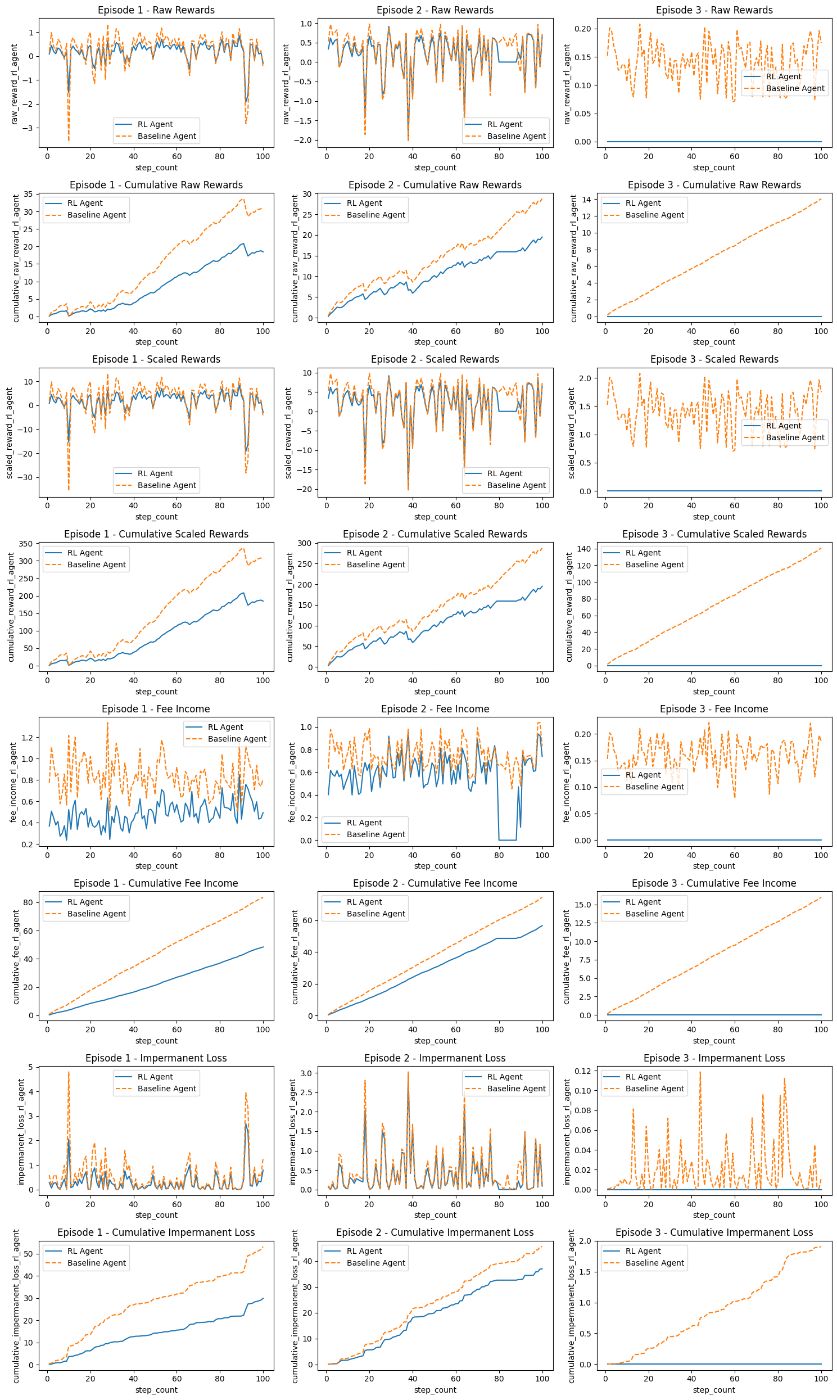
Ограничения
- Синхронизация пулов. В настоящее время платформа не полностью фиксирует синхронизацию пулов в реальном времени, что может привести к расхождениям в моделировании реальной динамики Uniswap V3. Будущая работа должна быть сосредоточена на внедрении механизмов для лучшей синхронизации пулов, возможно, с использованием данных или событий тиков/позиций для повышения реалистичности.
* Наивные политики агентов: Политики агентов, используемые в текущей структуре, относительно просты и наивны. Чтобы добиться более точного моделирования, будущие итерации должны быть направлены на определение более комплексных политик агентов. Эти политики могут моделировать различные типы агентов Uniswap, такие как шумовые трейдеры, информированные трейдеры, розничные поставщики ликвидности и институциональные поставщики ликвидности. В качестве альтернативы, статистические модели, обученные на исторических данных пула, могут обеспечить более реалистичное поведение агентов.
* Разреженное пространство наблюдения. В пространстве наблюдения, предоставляемом агентам, отсутствует исчерпывающая информация о состоянии пула. Чтобы улучшить возможности принятия решений, будущие улучшения должны включать данные о тиках и позициях, а также специальные функции, которые позволят агентам более полное представление о состоянии пула.
* Ограниченное пространство действий: Пространство действий агентов в настоящее время ограничено: фиксированные суммы ликвидности и ограниченный диапазон цен. Расширение пространства действий для обеспечения большей гибкости в предоставлении ликвидности, а также рассмотрение нескольких позиций на каждом этапе может повысить точность моделирования.
Будущая работа
Среда агента:
- Синхронизированные пулы. Реализуйте механизмы синхронизации пулов, возможно, с использованием данных или событий тиков/позиций, чтобы создать более реалистичную динамику в среде Uniswap V3.
- Настройка гиперпараметров. Дальнейшее уточнение и оптимизация гиперпараметров агента обучения с подкреплением для повышения эффективности обучения.
- https://kth.diva-portal.org/smash/get/diva2 :1695877/FULLTEXT01.pdf
- https://arxiv.org/pdf/2305.15821.pdf
- https://github.com/KodAgge/Reinforcement-Learning-for-Market -Изготовление/дерева/основного
- https://arxiv.org/ftp/arxiv/papers/2211/2211.01346.pdf
- https://arxiv.org/pdf/2004.06985.pdf
- https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9682687
- https://journals.plos.org/plosone/article?id=10.1371 /journal.pone.0277042
- https://deliverypdf.ssrn.com/delivery.php?ID =104119098102026014120072084014107007042068069003049020126088025087121115103007084028042013055035009000054122074096068089064 07010205202600301406908207609801608006602608806603902709302000612206709310409206507002012606906810611807912708800809807710603 1120&EXT=pdf&INDEX=TRUE
- https://medium.com/blockapex/market-making-mechanics-and-strategies-4daf2122121c< /ли>
- https://www.gauntlet.xyz/resources/uniswap-user-cohort-anaанализ
- https://gov.uniswap.org/t/uniswap-incentive-design-anaанализ /21662
- https://arxiv.org/pdf/2108.07806.pdf
- https://www.researchgate.net/publication/341848292_Market_makers_activity_behavioural_and_agent_based_approach
- https://fruct.org/publications/volume-29/fruct29/files/Struc .pdf
- https://www.arxiv-vanity.com/papers/1911.03380/
- https://insights.glassnode.com/the-week-onchain-week- 31-2023/
2. Настройка гиперпараметров: сетевая архитектура актера/критика, альфа, бета, тау, размер пакета, шаги, эпизоды, параметры масштабирования (награды, действия, пространство наблюдения)
3. Комплексная политика агентов. Определите более сложные аналитические политики, которые точно моделируют различных агентов Uniswap или используют статистические модели, обученные на исторических данных пула, для информирования о поведении агентов.
4. Информативное пространство наблюдения. Расширьте пространство наблюдения, включив в него данные о тиках и положении, а также разработайте функции, которые предоставляют агентам полное представление о состоянии пула.
5. Улучшенная функция вознаграждения. Разработайте улучшенную функцию вознаграждения, учитывающую более широкий спектр факторов, что приведет к более эффективному обучению агентов.
6. Несколько должностей. Вместо одной позиции с фиксированным бюджетом на каждом временном этапе реализуйте более комплексный механизм, в котором агенту выделяется бюджет один раз в начале моделирования, а затем он учится его использовать. оптимально распределить бюджет на последующих этапах.
7. Базовые политики. Определите более комплексные базовые политики для оценки производительности агента RL
Алгоритм агента
* Эксперименты с другими агентами RL: изучите альтернативные модели агентов RL, такие как оптимизация проксимальной политики (PPO) или мягкий актер-критик (SAC), чтобы определить, дают ли они преимущества в конкретных сценариях.
* Многоагентное RL (MARL): изучите применение методов многоагентного обучения с подкреплением, которые могут быть полезны для моделирования взаимодействия между несколькими поставщиками ликвидности и свопперами.
* Онлайн-обучение. Внедряйте стратегии онлайн-обучения, которые позволяют агентам адаптироваться к меняющимся рыночным условиям в режиме реального времени, обеспечивая более динамичное и адаптивное решение по обеспечению ликвидности.
Заключение
В быстро развивающейся среде децентрализованных финансов (DeFi) предоставление ликвидности играет ключевую роль в обеспечении эффективной и безопасной торговли. Uniswap V3 с инновационной функцией концентрированной ликвидности раздвинул границы возможного в управлении ликвидностью DeFi. Однако сложности оптимизации стратегий предоставления ликвидности в этой динамичной экосистеме требуют инновационных решений.
Наша система интеллектуального обеспечения ликвидности представляет собой значительный шаг вперед в решении этих проблем. Объединив агентное моделирование и обучение с подкреплением, мы создали мощный набор инструментов для поставщиков ликвидности и участников рынка. Эта структура предлагает надежное и адаптивное решение для оптимизации стратегий предоставления ликвидности с упором на максимизацию функций полезности, которые включают полученные комиссии, смягчение непостоянных потерь и другие показатели, адаптированные к индивидуальным предпочтениям.
Ресурсы
:::совет Github: https://github.com/idrees535/Intelligent-Liquidity-Provisioning-Framework-V1
:::
Ссылки
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27116)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)