Начнем изучать Большие языковые модели посредством этих 479 бесплатных статей. Они расположены в порядке данных по взаимодействию читателей HackerNoon. Посетите Learn Repo или LearnRepo.com, чтобы найти самые читаемые статьи о любой технологии.
Большие языковые модели (LLMs) — это модели AI, обученные на огромных наборах текста для понимания, генерации и перевода текста, подобного человеческому, что позволяет создавать сложные приложения для естественного языка. Они критически важны для прогресса в AI-ассистентах, создании контента и интеллектуальной автоматизации.
1. Почему GPT лучше, чем BERT? Подробный обзор архитектуры Transformer
 Подробности архитектуры Transformer, иллюстрированные моделями BERT и GPT
Подробности архитектуры Transformer, иллюстрированные моделями BERT и GPT
2. Open-Source: следующий шаг в революции AI
 Обратите внимание на революцию open-source в развитии AI, различая настоящую инновацию и попытки 'open-washing' со стороны Big Tech.
Обратите внимание на революцию open-source в развитии AI, различая настоящую инновацию и попытки 'open-washing' со стороны Big Tech.
3. Расшифровка превосходства Transformer над RNN в задачах NLP
![]() Обратите внимание на увлекательный путь от Рекуррентных нейронных сетей (RNN) к Transformer в мире обработки естественного языка в нашей последней статье: 'The Trans
Обратите внимание на увлекательный путь от Рекуррентных нейронных сетей (RNN) к Transformer в мире обработки естественного языка в нашей последней статье: 'The Trans
4. Какие лучшие бесплатные AI-генераторы искусства 2023 года?
 Генеративные AI сделали значительные шаги в последние несколько месяцев, и генеративные модели AI стали более популярными.
Генеративные AI сделали значительные шаги в последние несколько месяцев, и генеративные модели AI стали более популярными.
5. Как использовать Ollama: Ручная работа с локальными LLM и созданием чат-бота
 В пространстве локальных LLM я встретил LMStudio. Хотя сама приложение проста в использовании, я любил простоту и маневренность, которые предоставляет Ollama.
В пространстве локальных LLM я встретил LMStudio. Хотя сама приложение проста в использовании, я любил простоту и маневренность, которые предоставляет Ollama.
6. Практическое руководство по 5 шагам для выполнения семантического поиска на вашей частной информации с помощью LLM
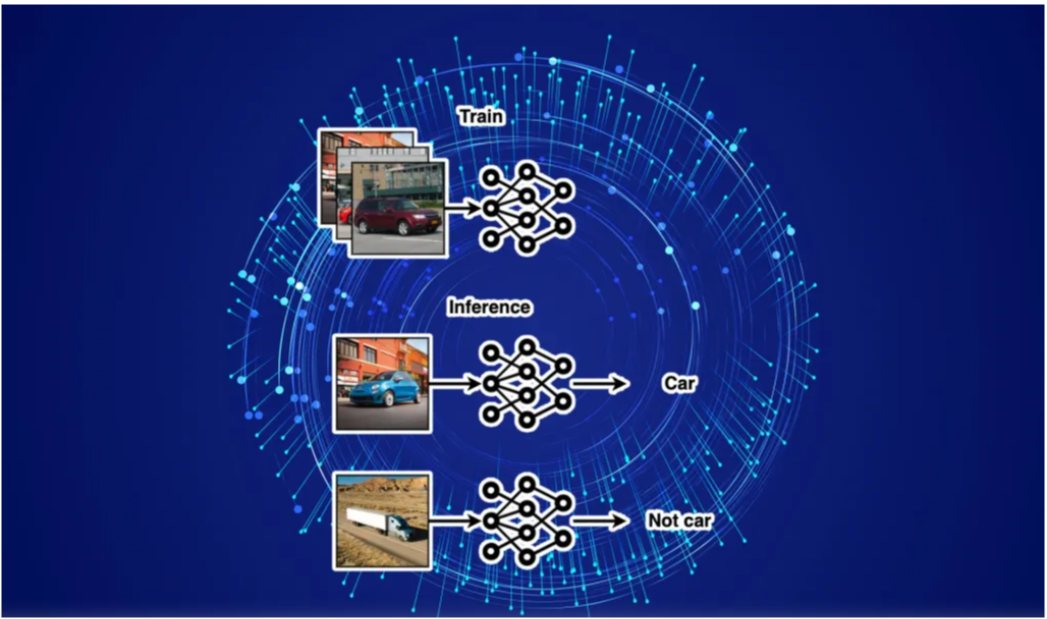
LLMs В этой практической гайде я покажу вам 5 простых шагов для реализации семантического поиска с помощью LangChain, векторных баз данных и больших языковых моделей.
В этой практической гайде я покажу вам 5 простых шагов для реализации семантического поиска с помощью LangChain, векторных баз данных и больших языковых моделей.
7. Полное руководство по тонкой настройке для конкретных задач
 Большие языковые модели (LLMs) типа GPT, BERT и RoBERTa изменили отрасли, но их истинный потенциал заключается в тонкой настройке для специализированных задач.
Большие языковые модели (LLMs) типа GPT, BERT и RoBERTa изменили отрасли, но их истинный потенциал заключается в тонкой настройке для специализированных задач.
8. Gptrim: Сократите размер вашего GPT-промта на 50% Бесплатно!
 Введение gptrim – бесплатного веб-приложения, которое сократит размер вашего промта на 40-60% при сохранении большинства исходной информации для обработки GPT.
Введение gptrim – бесплатного веб-приложения, которое сократит размер вашего промта на 40-60% при сохранении большинства исходной информации для обработки GPT.
9. Руководство для экономных людей по тонкой настройке LLaMA-2 и запуску его на вашем ноутбуке
 Поскольку сейчас все бедны на GPU, моя миссия – тонко настроить модель LLaMA-2 с одним GPU и запустить ее на моем ноутбуке
Поскольку сейчас все бедны на GPU, моя миссия – тонко настроить модель LLaMA-2 с одним GPU и запустить ее на моем ноутбуке
10. Вызовы, затраты и рассмотрения при создании или тонкой настройке LLM
 Дорога к созданию или тонкой настройке LLM для вашей компании может быть сложной. Вам нужна гайд для начала.
Дорога к созданию или тонкой настройке LLM для вашей компании может быть сложной. Вам нужна гайд для начала.
11. Hallucinations by Design: Часть 4 – Тонкая настройка для выхода из ночных кошмаров векторных данных
 Узнайте, как тонко настроить модели векторных данных для исключения галлюцинаций в системах AI. Повысьте свои RAG-системы и семантический поиск с помощью этих проверенных методов.
Узнайте, как тонко настроить модели векторных данных для исключения галлюцинаций в системах AI. Повысьте свои RAG-системы и семантический поиск с помощью этих проверенных методов.
12. Анализ плюсов, минусов и рисков LLM
 LLMs не могут думать, понимать или рассуждать. Это фундаментальная ограниченность LLM.
LLMs не могут думать, понимать или рассуждать. Это фундаментальная ограниченность LLM.
13. Сделайте LLM для текстового резюме снова великим
 В последние месяцы LLM стали популярными и теперь широко используются в различных приложениях. Сбор данных необходим для создания этих моделей, и
В последние месяцы LLM стали популярными и теперь широко используются в различных приложениях. Сбор данных необходим для создания этих моделей, и
crowd
14. Эра следующая AI: внутри прорывной модели GPT-4
 GPT-4 представляет собой скачок вперед в возможности больших языковых моделей. Он строится на архитектуре и сильных сторонах GPT-3, достигая новых уровней масштаба.
GPT-4 представляет собой скачок вперед в возможности больших языковых моделей. Он строится на архитектуре и сильных сторонах GPT-3, достигая новых уровней масштаба.
15. Революционный потенциал 1-битовых языковых моделей (LLMs)
 Революционный потенциал 1-битовых языковых моделей
Революционный потенциал 1-битовых языковых моделей
16. Конкурс AI по написанию текстов, проводимый Gadfly AI
 Gadfly AI и HackerNoon с нетерпением ждут возможности представить нашу сообщество AI конкурс «Будущее AI» в августе для Cyberscape Zine.
Gadfly AI и HackerNoon с нетерпением ждут возможности представить нашу сообщество AI конкурс «Будущее AI» в августе для Cyberscape Zine.
17. Как сделать любую LLM более точной с помощью только нескольких строк кода
 Обзор использования открытой пакетной системы Cleanlab для автоматического повышения точности LLM с помощью нескольких строк кода.
Обзор использования открытой пакетной системы Cleanlab для автоматического повышения точности LLM с помощью нескольких строк кода.
18. Как построить приложение для суммирования веб-страниц с помощью Next.js, OpenAI, LangChain и Supabase
 Приложение, способное понять контекст любой веб-страницы. Мы покажем вам, как создать полезное веб-приложение, способное суммировать содержание любой веб-страницы
Приложение, способное понять контекст любой веб-страницы. Мы покажем вам, как создать полезное веб-приложение, способное суммировать содержание любой веб-страницы
19. Анализ настроений и AI: все, что нужно знать в 2025 году
 Узнайте, как AI-подобранные инструменты анализа настроений обеспечивают точные выводы из отзывов и обратной связи клиентов, чтобы помочь улучшить вашу бизнес-стратегию.
Узнайте, как AI-подобранные инструменты анализа настроений обеспечивают точные выводы из отзывов и обратной связи клиентов, чтобы помочь улучшить вашу бизнес-стратегию.
20. Анализ распространенных уязвимостей, введенных код-генеративной AI
 Автоматически сгенерированный код не может быть доверен безоговорочно, и все еще требует проверки на безопасность, чтобы избежать внедрения программных уязвимостей.
Автоматически сгенерированный код не может быть доверен безоговорочно, и все еще требует проверки на безопасность, чтобы избежать внедрения программных уязвимостей.
21. ChatSQL:Включение ChatGPT в Генерацию SQL-Запросов из Плоского Текста
 ChatGPT был выпущен в июне 2020 года, что было разработано OpenAI. Это привело к революционным достижениям в многих областях. Одной из этих областей является создание
ChatGPT был выпущен в июне 2020 года, что было разработано OpenAI. Это привело к революционным достижениям в многих областях. Одной из этих областей является создание
22. Анализ 5 Использований Векторного Поиска от Основных Технологических Компаний
 Глубокое изучение 5 ранних сторонников векторного поиска - Pinterest, Spotify, eBay, Airbnb и Doordash - которые интегрировали AI в свои приложения.
Глубокое изучение 5 ранних сторонников векторного поиска - Pinterest, Spotify, eBay, Airbnb и Doordash - которые интегрировали AI в свои приложения.
23. Как Запустить Собственный Локальный LLM: Обновленная Версия для 2024 года - Версия 2
 Расширение статьи, которая получила большую популярность - Не 7, а 15 открытых инструментов в общей сложности для запуска локальных LLM на вашем собственном компьютере!
Расширение статьи, которая получила большую популярность - Не 7, а 15 открытых инструментов в общей сложности для запуска локальных LLM на вашем собственном компьютере!
24. AI Не Заменит Вас, Но Человек, Использующий AI
 "В мире, где воздействие AI на работу неоспоримо, эта вдумчивая экспертиза раскрыла, как AI служит как катализатор, так и оружие, преобразующее отрасли
"В мире, где воздействие AI на работу неоспоримо, эта вдумчивая экспертиза раскрыла, как AI служит как катализатор, так и оружие, преобразующее отрасли
25. 🎬 Введение MetaGPT: Разжигание Сил AI-Агентов для Комплексных Задач
 Представьте себе, что у вас есть в распоряжении AI-поддерживающий ассистент, который не только понимает ваши запросы, но и может также бесшовно взаимодействовать с различными приложениями.
Представьте себе, что у вас есть в распоряжении AI-поддерживающий ассистент, который не только понимает ваши запросы, но и может также бесшовно взаимодействовать с различными приложениями.
26. Иллюзии по Дизайну - (Часть 3): Доверие Векторам Без Тестируемости
 Внедрение и LLM необходимо проверять и оценивать или произойдут иллюзии. Экспериментация и оценка на персонализированной информации обязательны - openai и genai
Внедрение и LLM необходимо проверять и оценивать или произойдут иллюзии. Экспериментация и оценка на персонализированной информации обязательны - openai и genai
27. Почему Издательская Индустрия Книг Тревожится перед AI
 AI не все плохо, но она потенциально может разрушить издательскую индустрию. Существуют ли обоснованные опасения издателей перед AI или нет?
AI не все плохо, но она потенциально может разрушить издательскую индустрию. Существуют ли обоснованные опасения издателей перед AI или нет?
28. Без Кодирования: 5 Удивительных Использований GPT-4
Что можно фактически сделать с помощью GPT-4?
29. AI Shouldn’t Have to Waste Time Reinventing ETL
 В этой статье описываются проблемы перемещения данных для AI, необходимость создания и загрузки потоков и преимуществ использования существующих решений.
В этой статье описываются проблемы перемещения данных для AI, необходимость создания и загрузки потоков и преимуществ использования существующих решений.
30. Dissecting the Research Behind BadGPT-4o, a Model That Removes Guardrails from GPT Models
 Вступайте в BadGPT-4o: модель, у которой были сняты меры безопасности, не через прямое взвешивание (как с открытым весом «Badllama»).
Вступайте в BadGPT-4o: модель, у которой были сняты меры безопасности, не через прямое взвешивание (как с открытым весом «Badllama»).
31. AutoGPT — LangChain — Deep Lake — MetaGPT: Building the Ultimate LLM App
 Каково будущее технологии LLM? Как мы можем преобразовать сегодняшние LLM в автоматизированных агентов, действующих как люди? Вы найдете ответ в этой статье!
Каково будущее технологии LLM? Как мы можем преобразовать сегодняшние LLM в автоматизированных агентов, действующих как люди? Вы найдете ответ в этой статье!
32. PrivateGPT: ChatGPT but Private and Compliant
 Конфиденциальность является главной проблемой при обсуждении инструментов, подобных ChatGPT, с профессионалами.
Конфиденциальность является главной проблемой при обсуждении инструментов, подобных ChatGPT, с профессионалами.
33. Bard and ChatGPT — A Head To Head Comparison
 Сравнение обеих больших языковых моделей рядом и объяснение, какая из них лучше.
Сравнение обеих больших языковых моделей рядом и объяснение, какая из них лучше.
34. GPT-LLM Trainer: Enabling Task-Specific LLM Training with a Single Sentence
 Переворачивайте обучение моделей AI с помощью gpt-llm-trainer: ваше уникальное решение для беспроблемного и высокоэффективного обучения. Прощай, сложности, привет, инновации!
Переворачивайте обучение моделей AI с помощью gpt-llm-trainer: ваше уникальное решение для беспроблемного и высокоэффективного обучения. Прощай, сложности, привет, инновации!
35. 10 Tips to Take Your ChatGPT Prompts to the Next Level
 Максимизируйте опыт ChatGPT с помощью 10 профессиональных советов по созданию точных запросов и вопросов, повышению качества взаимодействия.
Максимизируйте опыт ChatGPT с помощью 10 профессиональных советов по созданию точных запросов и вопросов, повышению качества взаимодействия.
36. Больший шаг для AI: 3D-LLM освобождает языковые модели в 3D-мире
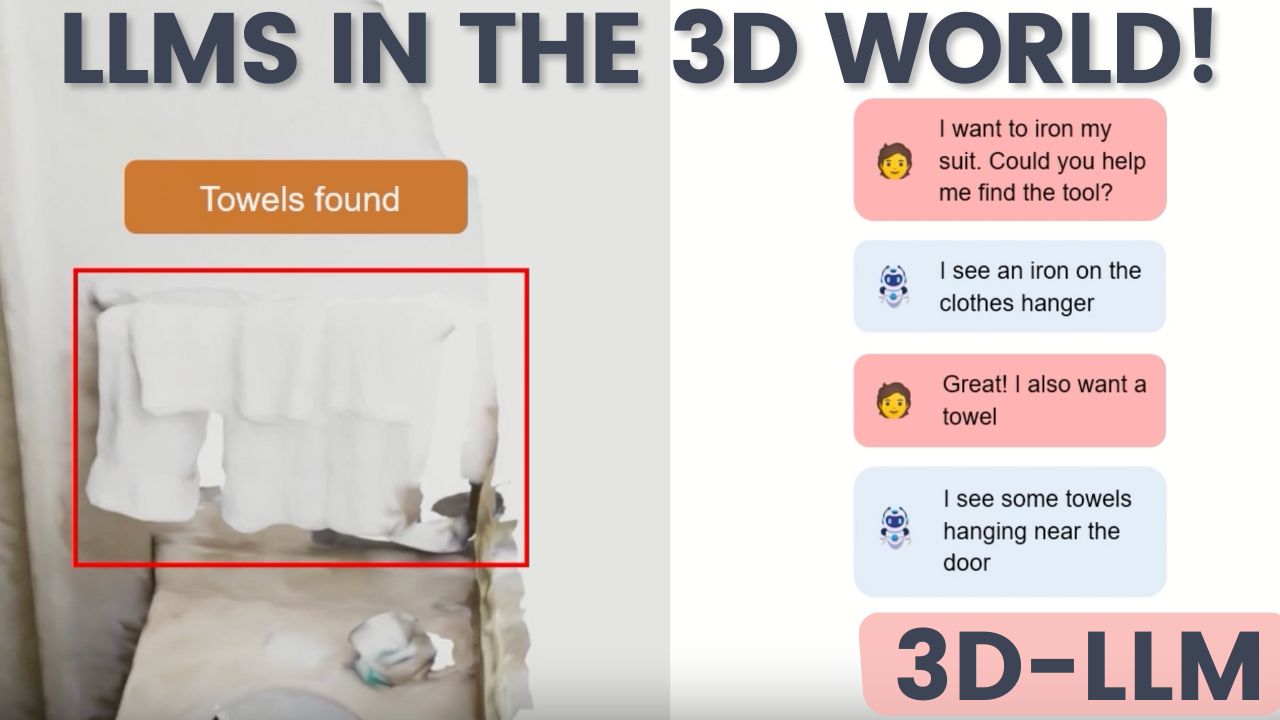 3D-LLM - это новая модель, которая соединяет язык и наш 3D-мир.
3D-LLM - это новая модель, которая соединяет язык и наш 3D-мир.
37. Оценка TnT-LLM по текстовой классификации: человеческое согласие и масштабируемые метрики LLM
 Мы оцениваем текстовую классификацию TnT-LLM с помощью человеческого согласия и масштабируемых метрик LLM для точности и производительности на больших масштабах.
Мы оцениваем текстовую классификацию TnT-LLM с помощью человеческого согласия и масштабируемых метрик LLM для точности и производительности на больших масштабах.
38. Я был готов вернуть DGX Spark. Затем обновление NVIDIA в январе изменило все.
 Я почти вернул $4,000 DGX Spark. Затем NVIDIA выпустила 30 наборов, 2,5-кратное увеличение производительности и гибридную маршрутизацию.
Я почти вернул $4,000 DGX Spark. Затем NVIDIA выпустила 30 наборов, 2,5-кратное увеличение производительности и гибридную маршрутизацию.
39. Может ли быть остановлено галлюцинации AI? Просмотр трех способов сделать это.
 Обследование трех методов, чтобы остановить LLM от галлюцинаций: Retrieval-augmented generation (RAG), рассуждения и итеративное запросы.
Обследование трех методов, чтобы остановить LLM от галлюцинаций: Retrieval-augmented generation (RAG), рассуждения и итеративное запросы.
40. TnT-LLM: Представление шаблонов запросов
 В этой части мы представляем шаблоны запросов, которые использовались для суммирования разговора, присвоения меток и генерации, обновления и проверки таксономии.
В этой части мы представляем шаблоны запросов, которые использовались для суммирования разговора, присвоения меток и генерации, обновления и проверки таксономии.
41. AI для управления знаниями: Итерация RAG с архитектурой QE-RAG
 Мы итерируем популярную архитектуру LLM, чтобы построить более эффективную систему AI для управления знаниями.
Мы итерируем популярную архитектуру LLM, чтобы построить более эффективную систему AI для управления знаниями.
42. Сделать LLM эффективными: Сокращение использования памяти без нарушения качества
 Оптимальные компромиссы между памятью и качеством для эффективных языковых моделей.
Оптимальные компромиссы между памятью и качеством для эффективных языковых моделей.
43. Примечание к большой языковой модели LLM: оптимизация инференции 1. Фон и формулировка проблемы
 43. Primer на большую языковую модель (LLM) инференса оптимизаций: 1. Background и Problem Formulation
43. Primer на большую языковую модель (LLM) инференса оптимизаций: 1. Background и Problem Formulation
 Обзор большая языковая модель (LLM) инференса, его важность, проблемы и ключевая Problem Formulation.
Обзор большая языковая модель (LLM) инференса, его важность, проблемы и ключевая Problem Formulation.
44. Что такое LlamaIndex? Общая эксплуатация LLM-оркестрационных Frameworks
 В этой статье мы объясним, как LlamaIndex можно использовать в качестве Framework для интеграции данных, организации данных и извлечения данных для приватных данных Gen AI требует.
В этой статье мы объясним, как LlamaIndex можно использовать в качестве Framework для интеграции данных, организации данных и извлечения данных для приватных данных Gen AI требует.
45. Текущее состояние GPT4All
 Сегодня GPT4All фокусируется на улучшении доступности открытых языковых моделей.
Сегодня GPT4All фокусируется на улучшении доступности открытых языковых моделей.
46. Подробный обзор, как работает AI-детекторы
 Интересно узнать, как работает AI-детекторы? Ну, вы в luck. Я постараюсь объяснить это как можно проще, чтобы любой мог понять.
Интересно узнать, как работает AI-детекторы? Ну, вы в luck. Я постараюсь объяснить это как можно проще, чтобы любой мог понять.
47. Масштабирующие законы в большую языковую модель
 Изучите масштабирующие законы в AI, которые показывают, как модельная производительность улучшается с увеличением модели, данных и вычислительной мощности.
Изучите масштабирующие законы в AI, которые показывают, как модельная производительность улучшается с увеличением модели, данных и вычислительной мощности.
48. Embeddings для RAG - Общая обзор
 Embedding является важным и фундаментальным шагом в построении Retrieval Augmented Generation (RAG) pipeline. BERT & SBERT являются state-of-the-art embedding модели.
Embedding является важным и фундаментальным шагом в построении Retrieval Augmented Generation (RAG) pipeline. BERT & SBERT являются state-of-the-art embedding модели.
49. Основные AI-инструменты для разработчиков в 2023 году: 20 рекомендованных решений
 В этой статье мы рассмотрим несколько AI-поддерживающих инструментов, которые готовы революционизировать разработку и сделать жизнь разработчиков легче в 2023 году.
В этой статье мы рассмотрим несколько AI-поддерживающих инструментов, которые готовы революционизировать разработку и сделать жизнь разработчиков легче в 2023 году.
50. TnT-LLM: Автоматизация текстовой таксономии и классификации с помощью большую языковую модель
![]()

Этот документ представляет собой TnT-LLM, фреймворк, использующий LLM для автоматизации масштабной аналитики текста, включая автоматическую генерацию меток и эффективные классификаторы.
51. MCP Умер. CLI Побеждает в Стеке Агентов AI
 Почему разработчики бросают пышные протоколы агентов и обращаются к CLI как к наиболее практичной основе для создания агентов AI в 2026 году.
Почему разработчики бросают пышные протоколы агентов и обращаются к CLI как к наиболее практичной основе для создания агентов AI в 2026 году.
52. AI Не Заменила Меня Ещё, Но Она Может Покажать, Что Я Никогда Не Был Такой Оригинальный
 AI не заменит меня еще, но она может показать, что я никогда не был таким оригинальным. Витийная, тревожная статья о формализованном письме в эпоху больших языковых моделей.
AI не заменит меня еще, но она может показать, что я никогда не был таким оригинальным. Витийная, тревожная статья о формализованном письме в эпоху больших языковых моделей.
53. Путеводитель Начинающего: Большие Языковые Модели (LLMOps) в 2023 году: Всё бесплатно!
 Этот гид не просто сборник ресурсов LLM; это отобранная поездка по наиболее ценным навыкам в индустрии.
Этот гид не просто сборник ресурсов LLM; это отобранная поездка по наиболее ценным навыкам в индустрии.
54. Разблокировка Мощных Использований: Как Мультиагентные LLM Изменяют Системы AI
 Исследование внедрения подходов «человек в цикле» (HITL) в мультиагентных системах AI для разблокировки полного потенциала LLM.
Исследование внедрения подходов «человек в цикле» (HITL) в мультиагентных системах AI для разблокировки полного потенциала LLM.
55. Рассказ о Двух LLM: Открытые Источники vs Эксперименты Вооруженных Сил США по LLM
 Эта статья исследует безопасность открытых источников LLM-проектов и эксперименты Вооруженных Сил США по LLM, известные в мире AI.
Эта статья исследует безопасность открытых источников LLM-проектов и эксперименты Вооруженных Сил США по LLM, известные в мире AI.
56. Как Общаться с Файлами PDF Используя Компьютерное Зрение и Открытые Языковые Модели
 Учебник по созданию чат-бота с помощью открытых языковых моделей.
Учебник по созданию чат-бота с помощью открытых языковых моделей.
57. Пределы Коавторства с ChatGPT
 ChatGPT — полезный инструмент для исследования творческой писанины, но она также имеет свои границы.ограничения. Алгоритм имеет определенные ограничения, но он все равно интересен к использованию
ChatGPT — полезный инструмент для исследования творческой писанины, но она также имеет свои границы.ограничения. Алгоритм имеет определенные ограничения, но он все равно интересен к использованию
58. Мanners Matter? - Влияние доброты на взаимодействие человека с LLM
 Исследование влияния доброты на результаты взаимодействия человека с LLM
Исследование влияния доброты на результаты взаимодействия человека с LLM
59. Эксперты остаются разделенными по вопросу эффективности ChatGPT, несмотря на заявления о готовности к массовому внедрению
 Этот текст обсуждает гип в вокруг ChatGPT, языкового модели, разработанного OpenAI, и утверждает, что, несмотря на его способность генерировать текст, подобный человеческому, он ограничен
Этот текст обсуждает гип в вокруг ChatGPT, языкового модели, разработанного OpenAI, и утверждает, что, несмотря на его способность генерировать текст, подобный человеческому, он ограничен
60. Neuralная сеть Transformer (TNN) намного больше, чем даже AGI
 Нам только что стало ясно, как работают LLM внутренне - легкое, научное предположение. Но это имеет огромные последствия для отрасли AI и, в самом деле, для мира!
Нам только что стало ясно, как работают LLM внутренне - легкое, научное предположение. Но это имеет огромные последствия для отрасли AI и, в самом деле, для мира!
61. Рекомендации разработчика OpenAI по использованию GPT и ChatGPT
 Логан Килпатрик работает в OpenAI в области разработчиков. Он делится своими мыслями о больших языковых моделях, ChatGPT и ландшафте разработчиков OpenAI.
Логан Килпатрик работает в OpenAI в области разработчиков. Он делится своими мыслями о больших языковых моделях, ChatGPT и ландшафте разработчиков OpenAI.
62. Разработка архитектуры с триллионными параметрами на потребительском оборудовании
 Глубокое рассмотрение того, как один исследователь обучил модель с триллионными параметрами на ноутбуке RTX 4080, доказав демократизацию LLM
Глубокое рассмотрение того, как один исследователь обучил модель с триллионными параметрами на ноутбуке RTX 4080, доказав демократизацию LLM
63. Как достичь 1000x скорости LLM для эффективного и экономически выгодного обучения, тестирования и развертывания
 Вы когда-нибудь задумывались, как ускорить обучение LLM? Ну, - не беспокойтесь - Мы представляем простой, но гениальный метод ускорения LLMOps.
Вы когда-нибудь задумывались, как ускорить обучение LLM? Ну, - не беспокойтесь - Мы представляем простой, но гениальный метод ускорения LLMOps.
64. 7 основных библиотек AI-инженеринга для замены шаблонов
 64. 7 Essential AI Engineering Libraries to Replace Boilerplate
64. 7 Essential AI Engineering Libraries to Replace Boilerplate
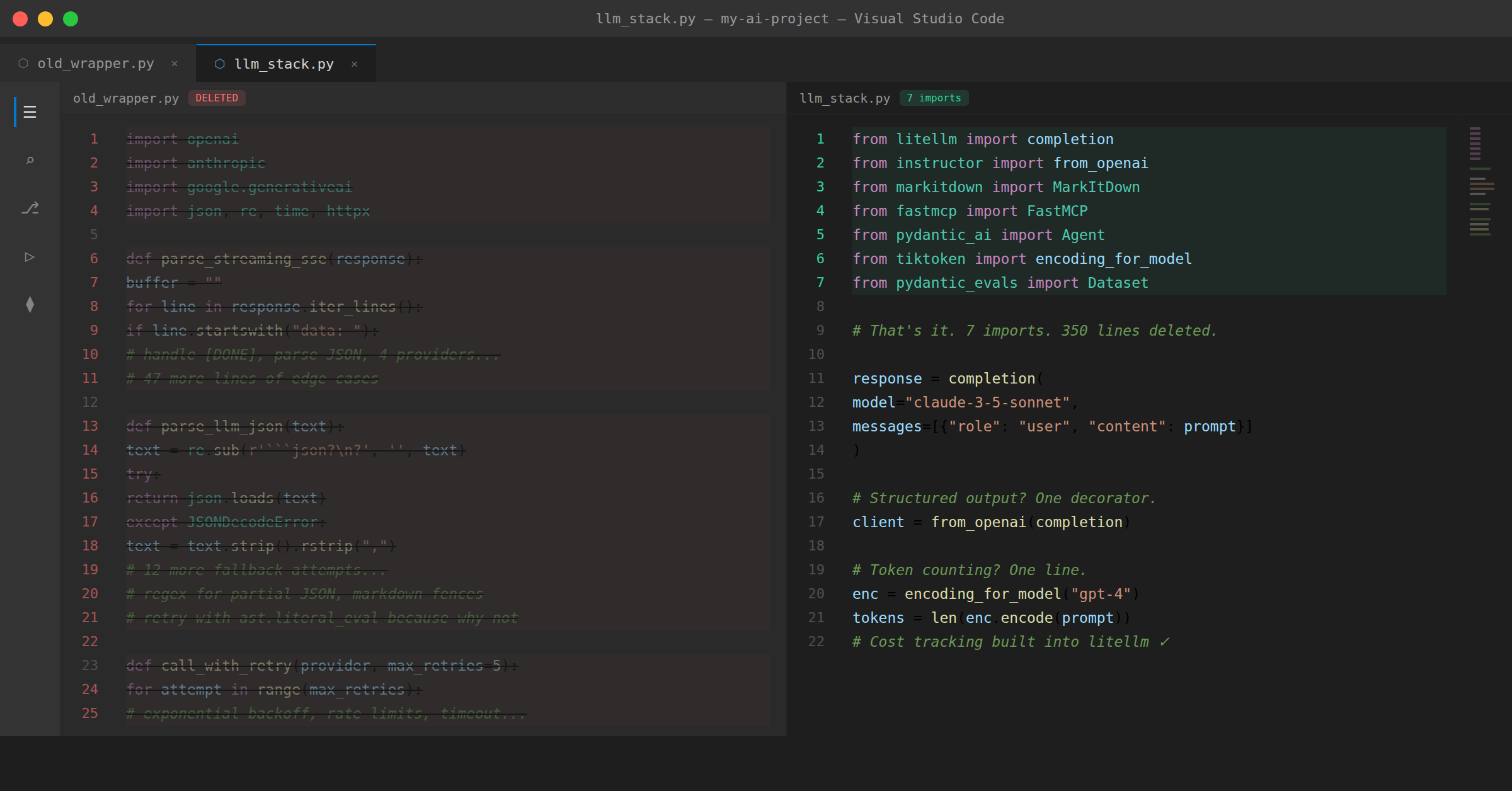 Замените custom LLM-обёртки на 7 производственных протестированных библиотек Python. Обсуждается LiteLLM, Instructor, FastMCP, PydanticAI, tiktoken и другие с примерами кода.
Замените custom LLM-обёртки на 7 производственных протестированных библиотек Python. Обсуждается LiteLLM, Instructor, FastMCP, PydanticAI, tiktoken и другие с примерами кода.
65. AIs Will Be Dangerous Because Unbounded Optimizing Power Leads to Existential Risk
 Серьёзные опасения экспертов по поводу будущего мощного AI. Информация, не освещённая в общем СМИ.
Серьёзные опасения экспертов по поводу будущего мощного AI. Информация, не освещённая в общем СМИ.
66. Mamba Architecture: What Is It and Can It Beat Transformers?
 Исследуйте Mamba, инновационную архитектуру, превосходящую Transformers по эффективности для длинных последовательностей, обещающую прогресс в AI с гибкой конструкцией.
Исследуйте Mamba, инновационную архитектуру, превосходящую Transformers по эффективности для длинных последовательностей, обещающую прогресс в AI с гибкой конструкцией.
67. Amazon Falcon Lite vs OpenAI ChatGPT - The Large Language Model Battle
 Сравнение Amazon Falcon Lite и OpenAI ChatGPT: Обширный обзор больших языковых моделей.
Сравнение Amazon Falcon Lite и OpenAI ChatGPT: Обширный обзор больших языковых моделей.
68. From Crappy Autocomplete to ChatGPT: The Evolution of Language Models
 Лёгкое объяснение того, как работает самосознание, и краткий взгляд на эволюцию больших языковых моделей.
Лёгкое объяснение того, как работает самосознание, и краткий взгляд на эволюцию больших языковых моделей.
69. AI Says My Schtick is Bigger Than Yours!
 Хорошо ли AI-версии топов и рекомендаций, лучше ли они, чем результаты поиска? Как отслеживать их?
Хорошо ли AI-версии топов и рекомендаций, лучше ли они, чем результаты поиска? Как отслеживать их?
70. Langchain: Explained and Getting Started
 Langchain является важным компонентом для разработки моделей LLM. Он помогает в оркестровке и служит строительным блоком.
Langchain является важным компонентом для разработки моделей LLM. Он помогает в оркестровке и служит строительным блоком.
71. ChatGPT Vs. ChatGPT: How to Detect Text Generated Using the AI Language Model
 ChatGPT может помочь вам оценить, является ли текст, сгенерированный AI.
ChatGPT может помочь вам оценить, является ли текст, сгенерированный AI.
Текст написан ЛЛМ.
72. Пять вопросов о предвзятости в AI, которых вы, возможно, хотели бы задать
 5 основных вопросов из панельной дискуссии о предвзятости в AI. Участники предоставляют свои взгляды на источники предвзятости, ответственность разработчиков и будущее AI.
5 основных вопросов из панельной дискуссии о предвзятости в AI. Участники предоставляют свои взгляды на источники предвзятости, ответственность разработчиков и будущее AI.
73. Действие ЕС по AI: последствия для SEO на LLM
 Эта статья разоблачает технический жаргон и charts простой курс для понимания последствий регулирования ЕС для SEO на LLM.
Эта статья разоблачает технический жаргон и charts простой курс для понимания последствий регулирования ЕС для SEO на LLM.
74. Должно ли конверсационное AI полагаться на большие модели языка?
 Большие модели языка (LLM) — это конверсационные чат-боты AI, которые взрывают мир.
Большие модели языка (LLM) — это конверсационные чат-боты AI, которые взрывают мир.
75. LLMs Изменяют Приложения AI: Как Это Происходит
 Строительство приложений с не реальными уровнями персонализированного контекста стало реальностью для всех, у кого есть правильная база данных, несколько строк кода и LLM, такой как GPT-4.
Строительство приложений с не реальными уровнями персонализированного контекста стало реальностью для всех, у кого есть правильная база данных, несколько строк кода и LLM, такой как GPT-4.
76. BYOK (BringYourOwnKey) в генеративном AI — двойной меч
 Вы знаете, что Bring Your Own Key (BYOK) в генеративном AI? Читайте дальше и узнайте больше о новом концепте AI.
Вы знаете, что Bring Your Own Key (BYOK) в генеративном AI? Читайте дальше и узнайте больше о новом концепте AI.
77. Безопасные угрозы для высокоинтенсивных открыто-источниковых больших моделей языка
 Быстрый рост проектов Open-source LLM часто демонстрирует неумную безопасную позицию, которая требует принятия улучшенных стандартов безопасности.
Быстрый рост проектов Open-source LLM часто демонстрирует неумную безопасную позицию, которая требует принятия улучшенных стандартов безопасности.
78. Системы памяти AI: подходы, которые вам нужно знать
 Создал свою собственную систему Open-source, называемую Elroy, и уже три года взаимодействую с ней. Она помогает мне brainstorm и многое другое.
Создал свою собственную систему Open-source, называемую Elroy, и уже три года взаимодействую с ней. Она помогает мне brainstorm и многое другое.
79. О зиме AI и том, что это означает для будущего
 Полная история
Полная история
Обзор зимних периодов AI проводится в деталях. Обширная информация, которую мы не нашли в других источниках.
80. Может ли китайский DeepSeek разрушить теорию «Больше GPU — больше мощности»?
 Это 2025 год, и мы можем уже наблюдать переломный момент для AI, как мы знали его в последние пару лет.
Это 2025 год, и мы можем уже наблюдать переломный момент для AI, как мы знали его в последние пару лет.
81. Meta Strikes Back: Введение LLaMA
 Meta представляет LLaMA, 65-размерный параметр модели, чтобы конкурировать с ChatGPT, в то время как OpenAI планирует AGI, создавая гонку за продвинутые языковые модели.
Meta представляет LLaMA, 65-размерный параметр модели, чтобы конкурировать с ChatGPT, в то время как OpenAI планирует AGI, создавая гонку за продвинутые языковые модели.
82. Как я сократил задержку агентного потока на 3-5 раз без увеличения затрат модели
 Узнайте, как ускорить и оптимизировать агентные потоки с помощью умной разрезки шагов, параллелизации, кэширования и оптимизации модели.
Узнайте, как ускорить и оптимизировать агентные потоки с помощью умной разрезки шагов, параллелизации, кэширования и оптимизации модели.
83. Примечание к оптимизации вывода большой языковой модели (LLM): 2. Введение в ускорители искусственного интеллекта (AI)
 Эта статья исследует ускорители AI и их влияние на развертывание большой языковой модели (LLM) на больших масштабах.
Эта статья исследует ускорители AI и их влияние на развертывание большой языковой модели (LLM) на больших масштабах.
84. История мозга: тревога AI и иллюзия разума
 Сознательны ли LLM, или это просто сложные калькуляторы? Как забытый в 1981 году научно-фантастический эксперимент предсказал современную кризисную ситуацию AI.
Сознательны ли LLM, или это просто сложные калькуляторы? Как забытый в 1981 году научно-фантастический эксперимент предсказал современную кризисную ситуацию AI.
85. За кулисами большой языковой модели: разговор с Джей Аламмаром
 В 16-м эпизоде «Подкаста «Что такое AI», я имел честь беседовать с Джей Аламмаром, известным специалистом по AI и блогером.
В 16-м эпизоде «Подкаста «Что такое AI», я имел честь беседовать с Джей Аламмаром, известным специалистом по AI и блогером.
86. Большая языковая модель: путешествие начинающего — Часть 1
 Изучите мир большой языковой модели (LLM) в нашей обширной статье.
Изучите мир большой языковой модели (LLM) в нашей обширной статье.
Руководство. От понимания их возможностей до преодоления ограничений, узнайте, как LLMs
87. Как привести личностные торговые оферы с помощью векторного поиска
 Узнайте, как векторный поиск может привести к результатам с помощью клиентских предложений в крупном розничном магазине.
Узнайте, как векторный поиск может привести к результатам с помощью клиентских предложений в крупном розничном магазине.
Улучшение результатов GPT-5 с помощью 15 000 экспертных стимулов, которые превращают скучные выводы AI в высокоэффективный контент для предпринимателей, маркетологов и создателей.
95. Как большие языковые модели улучшают безопасность систем от сопротивления угроз до анализа угодах о соблюдении
 Изучайте разнообразные применения больших языковых моделей (LLMs) в области безопасности.
Изучайте разнообразные применения больших языковых моделей (LLMs) в области безопасности.
96. Как AI изменит менеджмент продуктов
 Изучайте, как AI изменит роли менеджеров продуктов, от быстрого прототипирования до анализа обратной связи пользователей, оснащая PMs инновациями и конкурентоспособностью.
Изучайте, как AI изменит роли менеджеров продуктов, от быстрого прототипирования до анализа обратной связи пользователей, оснащая PMs инновациями и конкурентоспособностью.
97. TnT-LLM: Выделение паттернов в большом объеме, используя большие языковые модели
 Перевод неструктурированного текста в структурированный и значимый формы является фундаментальным шагом в выделении паттернов для последующего анализа и применения.
Перевод неструктурированного текста в структурированный и значимый формы является фундаментальным шагом в выделении паттернов для последующего анализа и применения.
98. Лучшие практики для интеграции LLMs с средствами анализа вредоносного ПО
 LLMs могут дополнить деобфускацию в потоках угроз, заполняя пробелы, суммируя код и картографируя MITRE ATT&CK, но должны минимизировать галлюцинации.
LLMs могут дополнить деобфускацию в потоках угроз, заполняя пробелы, суммируя код и картографируя MITRE ATT&CK, но должны минимизировать галлюцинации.
99. От чёрного ящика до прозрачности: как читать логику LLMs
 Изучайте, как LLMs работают внутри: от фундаментальных принципов предсказания токенов до архитектуры Transformer, этапов обучения и цепей рассуждений. Узнайте, как формировать запросы
Изучайте, как LLMs работают внутри: от фундаментальных принципов предсказания токенов до архитектуры Transformer, этапов обучения и цепей рассуждений. Узнайте, как формировать запросы
100. Оценка TnT-LLM: автоматическая, человеческая и оценка на основе LLM
 В связи с неупорядоченным характером проблемы, которую мы изучаем, и отсутствием стандартной оценки, выполнять количественную оценку конечного результата генерации таксономии
В связи с неупорядоченным характером проблемы, которую мы изучаем, и отсутствием стандартной оценки, выполнять количественную оценку конечного результата генерации таксономии
101. Предыдущие подходы к выделению паттернов в тексте: таксономия, группировка, классификация и LLM
 Обзор связанной исследовательской работы в области генерации текстовой таксономии, группировки текста и использования LLM для автоматической аннотации текста.
Обзор связанной исследовательской работы в области генерации текстовой таксономии, группировки текста и использования LLM для автоматической аннотации текста.
102. Воздействие AI: 6 революционных прорывов
 Исследуйте воздействие AI в отраслях: Воздействие AI на бизнес, клиентский опыт, здравоохранение, финансы, транспорт и многое другое!
Исследуйте воздействие AI в отраслях: Воздействие AI на бизнес, клиентский опыт, здравоохранение, финансы, транспорт и многое другое!
103. Дорогой AI: Мы все еще не доверяем вам
 За последние месяцы миллионы людей все больше увлекаются AI и чат-ботами. Есть одна история, которая привлекла мое внимание…
За последние месяцы миллионы людей все больше увлекаются AI и чат-ботами. Есть одна история, которая привлекла мое внимание…
104. Как переставить упаковку продукта с помощью AI для роста
 Упаковка продукта влияет на 72% американцев в принятии решений о покупке, а рынок устойчивой упаковки развивается с годовой скоростью роста 8,5% в период с 2023 по 2031 год.
Упаковка продукта влияет на 72% американцев в принятии решений о покупке, а рынок устойчивой упаковки развивается с годовой скоростью роста 8,5% в период с 2023 по 2031 год.
105. Наши предложенные фреймворки: Использование LLM для тематического анализа
 Фреймворк основан на возможностях модели OpenAI GPT-4 для выполнения сложных задач НЛП в нулевой точке.
Фреймворк основан на возможностях модели OpenAI GPT-4 для выполнения сложных задач НЛП в нулевой точке.
106. Должны ли вы рисковать использовать браузер AI?
 AI кажется следующим шагом для веб-браузеров, но риски безопасности и галлюцинации являются реальными проблемами. Здесь перечислены плюсы и минусы браузеров AI.
AI кажется следующим шагом для веб-браузеров, но риски безопасности и галлюцинации являются реальными проблемами. Здесь перечислены плюсы и минусы браузеров AI.
107. Использование потенциала AI для создания персонализированных и индивидуальных опытов
 Узнайте, как AI помогает создавать персонализированные опыты в различных сервисах.
Узнайте, как AI помогает создавать персонализированные опыты в различных сервисах.
108. LLM & RAG: Рассказ о любви на День святого Валентина
 Любовь в воздухе, и так же идеальные партнеры AI: LLM и RAG!
Любовь в воздухе, и так же идеальные партнеры AI: LLM и RAG!
109. Будущее анализа вредоносного ПО: LLM и автоматическая деобфускация
 LLMs показывают сильный потенциал для автоматизации деобфускации вредоносного ПО, эффективного анализа реальных скриптов Emotet и улучшения будущих потоков угрозной информации
LLMs показывают сильный потенциал для автоматизации деобфускации вредоносного ПО, эффективного анализа реальных скриптов Emotet и улучшения будущих потоков угрозной информации
110. AI Knows Best—But Only If You Agree With It
 Эффективность AI может непреднамеренно сузить человеческое знание, приводя к «кollapse знаний». Узнайте, как этот сдвиг влияет на инновации и культурную диверсность.
Эффективность AI может непреднамеренно сузить человеческое знание, приводя к «кollapse знаний». Узнайте, как этот сдвиг влияет на инновации и культурную диверсность.
111. Yoshua Bengio Weighs in on the Pause and Building a World Model
 Эта неделя я беседовал с Yoshua Bengio, одним из основателей глубокого обучения о дополнении больших языковых моделей
Эта неделя я беседовал с Yoshua Bengio, одним из основателей глубокого обучения о дополнении больших языковых моделей
112. How to Build Your First MCP Server using FastMCP
 Узнайте, как построить свой первый сервер MCP с помощью FastMCP и подключить его к большой языковой модели для выполнения реальных задач через код.
Узнайте, как построить свой первый сервер MCP с помощью FastMCP и подключить его к большой языковой модели для выполнения реальных задач через код.
113. An Intro to MedPaLM: ChatGPT's Healthcare-Focused "Cousin"
 ChatGPT для здравоохранения? Узнайте все, что нужно знать о MedPaLM, новой LLM, разработанной Google специально для медицинских и клинических приложений.
ChatGPT для здравоохранения? Узнайте все, что нужно знать о MedPaLM, новой LLM, разработанной Google специально для медицинских и клинических приложений.
114. Reflecting on AI in 2023: Magic, Hope, Innovation and Disruption
 Откройте трансформативную силу Искусственного интеллекта. Изучите последние тенденции от NL до глубокого обучения, которые формируют будущее AI.
Откройте трансформативную силу Искусственного интеллекта. Изучите последние тенденции от NL до глубокого обучения, которые формируют будущее AI.
115. ChatGPT Translator VS Mine: Which One Is Better?
 Действительно ли ChatGPT Translator такой хороший, как упоминалось в многих постах ?
Действительно ли ChatGPT Translator такой хороший, как упоминалось в многих постах ?
116. Retrieval-Augmented Generation: AI Hallucinations Be Gone!
 Retrieval Augmented Generation (RAG), показывает обещания в эффективном увеличении знаний LLM и снижении воздействия AI-иллюзий.
Retrieval Augmented Generation (RAG), показывает обещания в эффективном увеличении знаний LLM и снижении воздействия AI-иллюзий.
117. Протокол контекста модели (MCP): новый стандарт для безопасной интероперабельности AI
 MCP является важным "протоколом middleware", который находится между большим языковым моделям и всей корпоративной средой.
MCP является важным "протоколом middleware", который находится между большим языковым моделям и всей корпоративной средой.
118. Демократизация доступа к AI стала более важной, чем когда-либо
 Поскольку влияние AI grows, так же растут разрывы в доступе к его трансформационному потенциалу.
Поскольку влияние AI grows, так же растут разрывы в доступе к его трансформационному потенциалу.
119. 10 Техник инженерии запросов для трансформации вашего подхода к AI
 Откройте 10 продвинутых техник инженерии запросов: рекурсивное расширение, оптимизация токенов, принцип DRY, эмуляция персонажа для превосходных AI-выходов.
Откройте 10 продвинутых техник инженерии запросов: рекурсивное расширение, оптимизация токенов, принцип DRY, эмуляция персонажа для превосходных AI-выходов.
120. Чат — ужасный интерфейс для агентов, и 2026 года это покажет
 Разработка AI-агентов? Я попробовал Angular, HTMX & Python. Они провалились. Узнайте, почему A2UI является декларативным протоколом для замены базовых чат-ботов.
Разработка AI-агентов? Я попробовал Angular, HTMX & Python. Они провалились. Узнайте, почему A2UI является декларативным протоколом для замены базовых чат-ботов.
121. OpenAI делает легче создавать свои собственные AI-агенты с помощью API
 Вы можете создавать сложные AI-ассистенты, которые безболезненно обрабатывают все, от обратного расположения строк до запросов внутренних баз данных.
Вы можете создавать сложные AI-ассистенты, которые безболезненно обрабатывают все, от обратного расположения строк до запросов внутренних баз данных.
122. AI делает технику менее пугающей для "словных" людей
 Узнайте, как AI преобразует мир для писателей и творческих людей. Вступите в мир, как естественные языковые интерфейсы делают технику более доступной.
Узнайте, как AI преобразует мир для писателей и творческих людей. Вступите в мир, как естественные языковые интерфейсы делают технику более доступной.
123. Как я заставил Llama 3 почтить Бога!
 Вы когда-нибудь задумывались, что бы AI подумал о Боге? Теперь вы можете узнать. Читайте эту статью, чтобы узнать!
Вы когда-нибудь задумывались, что бы AI подумал о Боге? Теперь вы можете узнать. Читайте эту статью, чтобы узнать!
124. Автоматический анализ настроений бренда с помощью генеративной AI
 Учитесь мониторить свой бренд на социальных сетях, как Reddit, Twitter, Linkedin, Hacker News… и автоматически анализировать настроение, благодаря генеративному AI.
Учитесь мониторить свой бренд на социальных сетях, как Reddit, Twitter, Linkedin, Hacker News… и автоматически анализировать настроение, благодаря генеративному AI.
125. The Game AI Problem Computers Were Never Built to Solve
 Объяснение, почему brute-force AI проваливается в гранд-стратегических играх, и как гибридные архитектуры LLM позволяют выполнять долгосрочную стратегическую рассуждение.
Объяснение, почему brute-force AI проваливается в гранд-стратегических играх, и как гибридные архитектуры LLM позволяют выполнять долгосрочную стратегическую рассуждение.
126. GPT4All: An Ecosystem of Open-Source Compressed Language Models
 В этой статье мы рассказываем историю GPT4All, популярного открытого репозитория, целью которого является демократизация доступа к LLM.
В этой статье мы рассказываем историю GPT4All, популярного открытого репозитория, целью которого является демократизация доступа к LLM.
127. AI Is Playing Favorite With Numbers
 LLM, как умны и предвзяты, как люди, которые их обучали. Хотя AI не может думать сама, мы только начинаем изучать глубины психологии LLM.
LLM, как умны и предвзяты, как люди, которые их обучали. Хотя AI не может думать сама, мы только начинаем изучать глубины психологии LLM.
128. From Backlinks to Data Depth: How LLMs Are Rewriting Content Authority
 Большие языковые модели (LLM) заменяют авторитетность контента Google-эры. LLM предназначены для поиска контента, который объясняет, определяет, сравнивает или решает.
Большие языковые модели (LLM) заменяют авторитетность контента Google-эры. LLM предназначены для поиска контента, который объясняет, определяет, сравнивает или решает.
129. Streamlining LLM Implementation: How to Enhance Specific Business Solutions with RAG
 Учитесь улучшать свои LLM с помощью retrieval-augmented generation, используя LlamaIndex и LangChain для контекста данных, развертывая свою приложение на Heroku.
Учитесь улучшать свои LLM с помощью retrieval-augmented generation, используя LlamaIndex и LangChain для контекста данных, развертывая свою приложение на Heroku.
130. Simplifying Vector Search: Part 1
 Вы когда-нибудь задумывались, как Spotify или любое количество сайтов для знакомств определяют, что или кто вам нравится? Они используют векторное поиск. Это векторный поиск упрощается.
Вы когда-нибудь задумывались, как Spotify или любое количество сайтов для знакомств определяют, что или кто вам нравится? Они используют векторное поиск. Это векторный поиск упрощается.
131. The Em Dash Rorschach Test
 Использование вами эн-деша — это ли это признак AI-авторства? Как этот скромный знак препинания стал культурной вспышкой в эпоху больших языковых моделей.
Использование вами эн-деша — это ли это признак AI-авторства? Как этот скромный знак препинания стал культурной вспышкой в эпоху больших языковых моделей.
132. GPTerm: Создание интеллектуальных приложений терминала с помощью ChatGPT и моделей LLM
 В этой статье исследуется увлекательная область создания умных приложений терминала, интегрировав в них ChatGPT, cutting-edge языковой модель.
В этой статье исследуется увлекательная область создания умных приложений терминала, интегрировав в них ChatGPT, cutting-edge языковой модель.
133. Плюсы и минусы LLM в практике кибербезопасности
 LLM повышают кибербезопасность, автоматизируя обнаружение и анализ угроз, а также соблюдение требований, но также могут быть использованы для атак и разработки вредоносного программного обеспечения.
LLM повышают кибербезопасность, автоматизируя обнаружение и анализ угроз, а также соблюдение требований, но также могут быть использованы для атак и разработки вредоносного программного обеспечения.
134. Как начать карьеру junior-разработчика в 2026 году
 Роль junior-разработчика распадается (снижение на 46%), но emerges новая траектория.
Роль junior-разработчика распадается (снижение на 46%), но emerges новая траектория.
135. LLM: эксперты в NLP, обеспечивая сложные поисковые функции в платформах электронной коммерции
 Чтобы обеспечить исключительные покупательские опыт, бизнесы должны использовать потенциал LLM, поскольку электронная коммерция продолжает развиваться.
Чтобы обеспечить исключительные покупательские опыт, бизнесы должны использовать потенциал LLM, поскольку электронная коммерция продолжает развиваться.
136. Их маржа — это возможность AI
 Может ли «ЧатCEO» снизить затраты и улучшить бизнес?
Может ли «ЧатCEO» снизить затраты и улучшить бизнес?
137. LLM-усиленная классификация текста: разложение меток GPT-4 в эффективные классификаторы
 Мы исследуем использование GPT-4 для масштабной аннотации текста и обучение лёгких классификаторов на этих метках, сравнивая их точность и эффективность.
Мы исследуем использование GPT-4 для масштабной аннотации текста и обучение лёгких классификаторов на этих метках, сравнивая их точность и эффективность.
138. Как AI и социальные медиа формируют знания через эхо-камеры и фильтровые пузырьки
 Алгоритмы AI и социальных медиа формируют знания, усиливая предубеждения и ограничивая доступ к разнообразным идеям, что приводит к образованию эхо-камер и искажению знаний.
Алгоритмы AI и социальных медиа формируют знания, усиливая предубеждения и ограничивая доступ к разнообразным идеям, что приводит к образованию эхо-камер и искажению знаний.
139. У меня есть умысел?
139. Do y'AI mind?
 Большие языковые модели вызывают вопросы вокруг природы ума, старую философскую проблему, солипсизм или один ум, трудно ответить
Большие языковые модели вызывают вопросы вокруг природы ума, старую философскую проблему, солипсизм или один ум, трудно ответить
140. AI Framework has You Covered on Image-to-Text Workflows
 Узнайте, как использовать AnyModal, модульную рамку для интеграции визуальных и языковых моделей, для создания и обучения собственного LaTeX OCR-системы. Ideal'noe для исследований в области AI
Узнайте, как использовать AnyModal, модульную рамку для интеграции визуальных и языковых моделей, для создания и обучения собственного LaTeX OCR-системы. Ideal'noe для исследований в области AI
141. With New AI Model, Meta Hopes Imperfect Hands Will be a Thing of the Past
 Meta разогревает соревнование в области AI с запуском нового искусственного интеллекта, который может помочь пользователям анализировать и завершать незавершенные изображения.
Meta разогревает соревнование в области AI с запуском нового искусственного интеллекта, который может помочь пользователям анализировать и завершать незавершенные изображения.
142. From Zero to AI-Ready: How I Taught Myself Machine Learning (And What I would Tell You Now)
 Вы не нуждаетесь в докторской степени, чтобы научиться AI, просто структура, любопытство и небольшие шаги, которые имеют смысл. Вот как я научился машинному обучению с нуля.
Вы не нуждаетесь в докторской степени, чтобы научиться AI, просто структура, любопытство и небольшие шаги, которые имеют смысл. Вот как я научился машинному обучению с нуля.
143. Policy-Driven AI: Designing Configuration-Driven Model Selection for Enterprise Systems
 Фиксация вызова AI-моделей - это новый технический долг. Этот материал рассказывает о том, как архитектурить слой конфигурации для выбора модели
Фиксация вызова AI-моделей - это новый технический долг. Этот материал рассказывает о том, как архитектурить слой конфигурации для выбора модели
144. When To Use Small Language Models Over Large Language Models
 Вы wonder', где начать использовать малые языковые модели? Найдите топовые случаи использования малых языковых моделей, когда малые языковые модели будут лучше, чем большие языковые модели.
Вы wonder', где начать использовать малые языковые модели? Найдите топовые случаи использования малых языковых моделей, когда малые языковые модели будут лучше, чем большие языковые модели.
145. Why It's Harder: The Unique Hurdles For Non-Experts Using AI Coding Tools
 AI-инструменты для программирования могут стать игровым преимуществом для неэкспертных конечных пользователей. Исследование уникальных проблем, возникающих при применении LLM к программированию
AI-инструменты для программирования могут стать игровым преимуществом для неэкспертных конечных пользователей. Исследование уникальных проблем, возникающих при применении LLM к программированию
146. На Грок и вес дизайна
 Рекентные проблемы с выходом Грока выявляют более глубокие структурные проблемы в моделировании соответствия.
Рекентные проблемы с выходом Грока выявляют более глубокие структурные проблемы в моделировании соответствия.
147. Дополнительные результаты: оценка кросс-языковой таксономии и в-depth анализ классификации
 Исследуйте более подробные результаты кросс-языковой таксономии, детальную оценку согласия в аннотациях и общие метрики классификации для TnT-LLM.
Исследуйте более подробные результаты кросс-языковой таксономии, детальную оценку согласия в аннотациях и общие метрики классификации для TnT-LLM.
148. Работа модели и ловушки в автоматизированном деобфусцировании вредоносного ПО
 Тестирование четырех LLM на скриптах Emotet показало, что GPT-4 лидировал в деобфусцировании, но все модели столкнулись с галлюцинациями и ограничениями запросов.
Тестирование четырех LLM на скриптах Emotet показало, что GPT-4 лидировал в деобфусцировании, но все модели столкнулись с галлюцинациями и ограничениями запросов.
149. TnT-LLM: высококачественное автоматизированное текстовое извлечение и эффективная классификация с помощью LLM
 Обзор результатов TnT-LLM: автоматизированная генерация таксономии превосходит кластеризацию, LLM эффективны в качестве оценщиков (с оговорками), и так далее.
Обзор результатов TnT-LLM: автоматизированная генерация таксономии превосходит кластеризацию, LLM эффективны в качестве оценщиков (с оговорками), и так далее.
150. Редкое активное включение в MoE-моделях: расширение ReLUfication к Mixture-of-Experts
 Откройте, как это открытие позволяет сократить FLOP на миллионы раз за счет MoE ReLUfication.
Откройте, как это открытие позволяет сократить FLOP на миллионы раз за счет MoE ReLUfication.
151. Таксономии, сгенерированные TnT-LLM: пользовательские намерения и метки доменов разговора
 Просмотрите таксономии пользовательских намерений и меток доменов разговора, автоматически сгенерированные TnT-LLM и отредактированные человеком для текстовой классификации.
Просмотрите таксономии пользовательских намерений и меток доменов разговора, автоматически сгенерированные TnT-LLM и отредактированные человеком для текстовой классификации.
152. Мягкая биготрия AI-дома: потому что пользователи просто слишком неумны
 Сатирическое разоблачение нарративов AI-дома: критическое мышление не исчезнет, институты не...
Сатирическое разоблачение нарративов AI-дома: критическое мышление не исчезнет, институты не...
автоматическое сокращение, и «апокалипсис» предполагает, что пользователи не способны.
153. AI-детективы и дело о маскирующихся дропперах
 Используя 2 000 реальных скриптов дроппера Emotet, эксперимент проверяет способность LLMs деобфусцировать вредоносное ПО и извлекать информацию о угрозах на больших масштабах.
Используя 2 000 реальных скриптов дроппера Emotet, эксперимент проверяет способность LLMs деобфусцировать вредоносное ПО и извлекать информацию о угрозах на больших масштабах.
154. Agents 101 — Создание и развертывание AI-агентов в производство с помощью LangChain
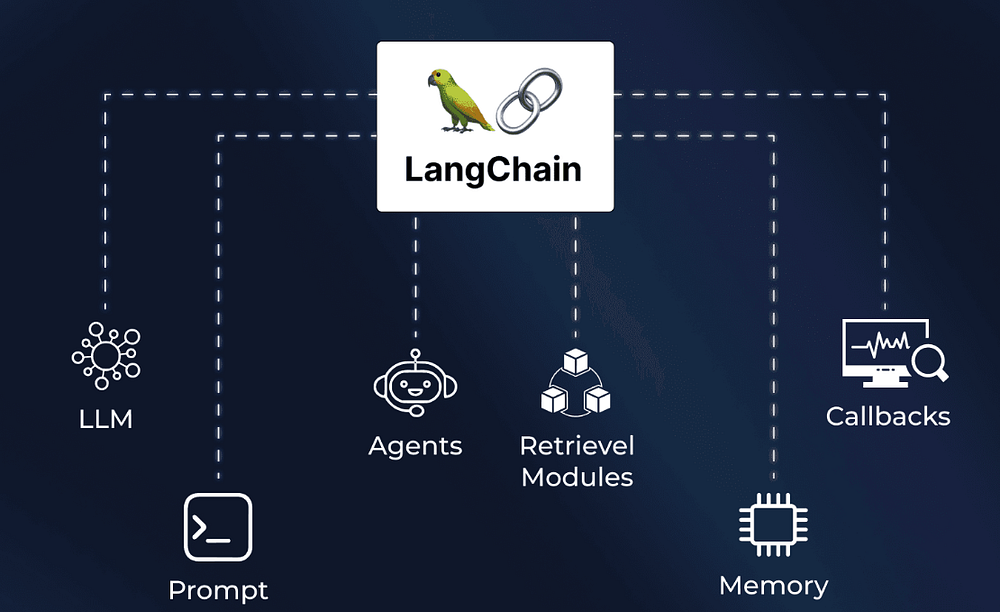 Узнайте, как Langchain превращает простой запрос в полнофункциональный AI-агент, способный мыслить, действовать и запоминать.
Узнайте, как Langchain превращает простой запрос в полнофункциональный AI-агент, способный мыслить, действовать и запоминать.
155. TnT-LLM: Демократизация текстового анализа с помощью автоматизированной таксономии и масштабируемой классификации
 TnT-LLM автоматизирует текстовый анализ, обеспечивая эффективную генерацию таксономии, классификацию с помощью LLM и демократизированный доступ к текстовым данным.
TnT-LLM автоматизирует текстовый анализ, обеспечивая эффективную генерацию таксономии, классификацию с помощью LLM и демократизированный доступ к текстовым данным.
156. Beyond ReconVLA: Безаннотационная визуальная привязка с помощью языковой внимания и маскированной реконструкции
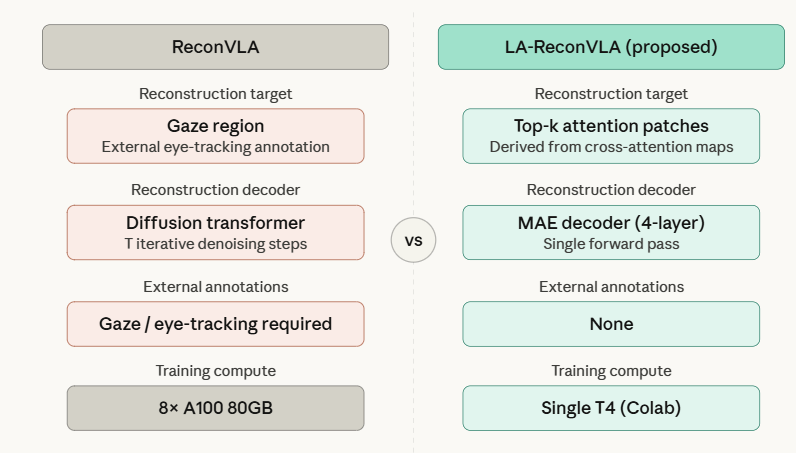 Новая подход заменяет аннотации взгляда на языково-ориентированную маскировку внимания, улучшая восприятие робота и снижая затраты на обучение.
Новая подход заменяет аннотации взгляда на языково-ориентированную маскировку внимания, улучшая восприятие робота и снижая затраты на обучение.
157. Stop Drowning in AI-Models: Трехпилонная рамка оценки
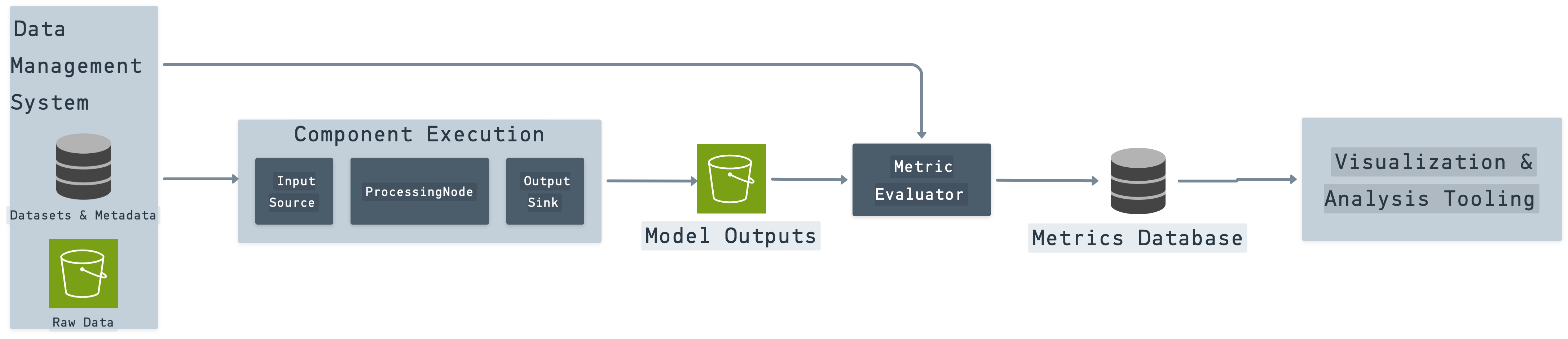 Практическая трехпилонная рамка оценки компьютерного зрения в производстве.
Практическая трехпилонная рамка оценки компьютерного зрения в производстве.
158. Рынок труда будущего при автоматизации и больших языковых моделях
 🕵️♀️👷Вашу работу не автоматизирует ChatGPT 🤖, а это не все - это взгляд в подкапотное пространство реальных проблем, которые привели нас к сегодняшнему дню.
🕵️♀️👷Вашу работу не автоматизирует ChatGPT 🤖, а это не все - это взгляд в подкапотное пространство реальных проблем, которые привели нас к сегодняшнему дню.
159. Быстрый справочник по технологии LLM-генерации кода и ее ограничениям
159. Быстрый справочник по технологиям LLM для генерации кода и их ограничениям
 Этот обзор предоставляет быстрый справочник по технологиям, лежащим в основе LLM для генерации кода, охватывающий архитектуру Transformer
Этот обзор предоставляет быстрый справочник по технологиям, лежащим в основе LLM для генерации кода, охватывающий архитектуру Transformer
160. Beyond The Final Answer: Why Non-Experts Can't Spot Bad AI Code
 Рассмотрим критическую проблему верификации кода, сгенерированного AI, для непрофессиональных программистов. Узнайте, почему они полагаются на «просмотр» окончательного результата
Рассмотрим критическую проблему верификации кода, сгенерированного AI, для непрофессиональных программистов. Узнайте, почему они полагаются на «просмотр» окончательного результата
161. 100 Complex LLM Terminology Explained in One Single & One Simple Sentence
 Каждое техническое термин о больших языковых моделях и генеративном AI объясняется сначала кратко, а затем просто, чтобы укрепить ваше понимание.
Каждое техническое термин о больших языковых моделях и генеративном AI объясняется сначала кратко, а затем просто, чтобы укрепить ваше понимание.
162. TnT-LLM Implementation Details: Pipeline Design, Robustness, and Efficiency
 Рассмотрим техническую реализацию TnT-LLM, включая дизайн пайплайна, методы обеспечения надежности и стратегии выбора модели
Рассмотрим техническую реализацию TnT-LLM, включая дизайн пайплайна, методы обеспечения надежности и стратегии выбора модели
163. Five Architectural Patterns That Fix What's Broken in RAG
 Семантический RAG предполагает, что вектор запроса находится рядом с вектором ответа.
Семантический RAG предполагает, что вектор запроса находится рядом с вектором ответа.
164. Data Scraping: Do Large Language Models Cross Boundaries by Training on Content from Everyone
 Хотя скрапинг позволил моделям добиться успеха, чистые данные станут все более важными
Хотя скрапинг позволил моделям добиться успеха, чистые данные станут все более важными
165. Researchers in UAE Create AI That Can Describe Images in Perfect Detail
 Исследователи в университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.
Исследователи в университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.
166. Топология значения: В направлении "коперативной теории полей" для искусственной интеллектии
 Смелое утверждение о том, что AI должна выйти за рамки языка и токенов и перейти к единой топологической модели, где слова, лица и звуки делятся одним пространством значений.
Смелое утверждение о том, что AI должна выйти за рамки языка и токенов и перейти к единой топологической модели, где слова, лица и звуки делятся одним пространством значений.
167. Выделение скрытой загрузки моловераплатформ с помощью AI-поддеревьеллмс
 LLMs могут автоматизировать выделение обфусцированных моловераплатформ, упрощая угрозную информацию, даже когда атакующие меняют упаковку и обфускацию.
LLMs могут автоматизировать выделение обфусцированных моловераплатформ, упрощая угрозную информацию, даже когда атакующие меняют упаковку и обфускацию.
168. Как использовать большие языковые модели для поддержки тематического анализа в исследованиях по эмпирическому праву
 Мы предлагаем новую рамку, способствующую эффективному сотрудничеству юриста с большим языковым моделям (LLM) для генерации первичных кодов
Мы предлагаем новую рамку, способствующую эффективному сотрудничеству юриста с большим языковым моделям (LLM) для генерации первичных кодов
169. Выделение потребностей пользователей с помощью Chat-GPT для рекомендации диалогов
 Исследуйте интеграцию ChatGPT в интерактивные системы рекомендаций, где оно служит как модель диалога, так и движок рекомендаций.
Исследуйте интеграцию ChatGPT в интерактивные системы рекомендаций, где оно служит как модель диалога, так и движок рекомендаций.
170. Открытая LLM: Оценка и разработка приложений на основе открытого
 Как выбрать наиболее подходящую модель для вашего приложения? Анализ оценки и разработки приложений на основе открытых больших языковых моделей.
Как выбрать наиболее подходящую модель для вашего приложения? Анализ оценки и разработки приложений на основе открытых больших языковых моделей.
171. Строение гибкой рамки для мультимодальной входных данных в больших языковых моделях
 Откройте AnyModal, гибкую рамку, упрощающую обучение мультимодальным большим языковым моделям (LLM). Интегрируйте текст, изображения и аудио безболезненно.
Откройте AnyModal, гибкую рамку, упрощающую обучение мультимодальным большим языковым моделям (LLM). Интегрируйте текст, изображения и аудио безболезненно.
172. Почему статический анализ страдает от современного моловера
![]()

Малварь использует пакетировщики, крипторы и обфусцирующие программы, чтобы избежать статического анализа, вызывая сложности для аналитиков в адаптации методов обнаружения и анализа.
173. Сознание: AI, LLMs—Сознание?
174. Тrap версии FrankenPHP: Почему ваш стек Laravel Octane не использует PHP 8.5

175. Максимизация возможностей NLP с помощью больших моделей языка

176. Этика локальных LLM: Ответ на манифест Zuckerberg «Открытый исходный код AI»

177. UI: Почему это реальный бутылочный горлышко AI-агента

178. В сторону автоматического создания подписей к спутниковым изображениям с помощью LLM: Резюме и Введение
179. Почему модели диффузии проваливаются в B2B-стилировании волос

Пайплайн "Архитектор-Строитель" достигает трехмерной согласованности в GenAI для продуктов B2B SaaS.
180. Возможности больших моделей языка: хакинг или помощь?
 Исследование возможностей агентов LLM: изучение взлома веб-сайтов
Исследование возможностей агентов LLM: изучение взлома веб-сайтов
181. Мыслить как компьютер: пропущенная навык для непрофессионалов, использующих AI
 Исследование критической проблемы для конечных пользователей-программистов: отсутствие компьютерного мышления. Узнайте, как инструменты, ассистируемые LLM, должны быть умнее
Исследование критической проблемы для конечных пользователей-программистов: отсутствие компьютерного мышления. Узнайте, как инструменты, ассистируемые LLM, должны быть умнее
182. Из сценария в краткое содержание: умный способ сжимать фильмы
 Масштабируемый AI-пipeline для суммирования и сжатия важных сцен из сценариев фильмов с высокой точностью.
Масштабируемый AI-пipeline для суммирования и сжатия важных сцен из сценариев фильмов с высокой точностью.
183. Использование больших моделей языка для поддержки тематического анализа: признание и что дальше?
 Нам предложили новую LLM-поддерживаемую рамку для тематического анализа, и мы оценили ее производительность на анализе мнений судебных органов
Нам предложили новую LLM-поддерживаемую рамку для тематического анализа, и мы оценили ее производительность на анализе мнений судебных органов
184. 7-слойная схема для обслуживания, защиты и наблюдения за агентами AI на масштабе
 От ПК до Фабрики: разбор 7-слойной архитектуры платформы агента AI для корпоративной масштабируемости и контроля
От ПК до Фабрики: разбор 7-слойной архитектуры платформы агента AI для корпоративной масштабируемости и контроля
185. Быстрый справочник по квантованию для LLM
 Квантование — это техника, которая уменьшает точность весов и активаций модели
Квантование — это техника, которая уменьшает точность весов и активаций модели
186. Метод "Сначала суммируйте, затем ищите" для длинного видео-опроса: вывод
 В этой статье исследователи изучают нулевую задачу видео-QA с помощью GPT-3, превосходя обученные модели, используя повествовательную
В этой статье исследователи изучают нулевую задачу видео-QA с помощью GPT-3, превосходя обученные модели, используя повествовательную
Обзоры и визуальное сопоставление.
187. Что такое LoRA? Объяснение низкочастотной адаптации LLM
 Чтобы заставить большие языковые модели работать в рамках вашего бюджета как по вычислительным затратам, так и по памяти, LoRA является фундаментальным алгоритмом квантования.
Чтобы заставить большие языковые модели работать в рамках вашего бюджета как по вычислительным затратам, так и по памяти, LoRA является фундаментальным алгоритмом квантования.
188. Может ли кто-то сейчас кодировать? Исследование помощи AI для непрофессиональных программистов
 Приходите и посмотрите, как кодирование меняется с помощью языковых моделей AI. Поделитесь реальными историями и исследованиями, показывающими, как сильно это отличается от программирования с этими инструментами
Приходите и посмотрите, как кодирование меняется с помощью языковых моделей AI. Поделитесь реальными историями и исследованиями, показывающими, как сильно это отличается от программирования с этими инструментами
189. Доказательство пользы CLI-инструментов над MCP-серверами в агентном AI
 Я построил 31 открытый исходный код CLI-инструмент Rust для агентов AI и измерил 35x лучшую эффективность токенов по сравнению с MCP-серверами. Здесь есть стек, принятые решения по дизайну и почему …
Я построил 31 открытый исходный код CLI-инструмент Rust для агентов AI и измерил 35x лучшую эффективность токенов по сравнению с MCP-серверами. Здесь есть стек, принятые решения по дизайну и почему …
190. Как создать реалистичные разговоры AI
 Понимайте параллели с плагинами для настраиваемых помощников AI и роль GPT-4 в генерации естественных взаимодействий.
Понимайте параллели с плагинами для настраиваемых помощников AI и роль GPT-4 в генерации естественных взаимодействий.
191. Управление онлайн-репутацией в эпоху AI
 Управление онлайн-репутацией теперь включает не только мнения людей, но и мнения AI. Отслеживание репутации в ответах AI — это новый SEO!
Управление онлайн-репутацией теперь включает не только мнения людей, но и мнения AI. Отслеживание репутации в ответах AI — это новый SEO!
192. Выяснилось, что 30% вашего модели AI — это просто пустой пространство
 Модели AI не так велики. Новые исследования показывают, что примерно 30% их размера — это просто пустое пространство из-за устаревших предположений об хранении.
Модели AI не так велики. Новые исследования показывают, что примерно 30% их размера — это просто пустое пространство из-за устаревших предположений об хранении.
193. Как сделать код понятным: главная проблема понимания в программировании AI
 Исследуйте основную проблему программирования AI: понимание кода. Узнайте, почему сгенерированный код сложно понять и как это влияет на точность
Исследуйте основную проблему программирования AI: понимание кода. Узнайте, почему сгенерированный код сложно понять и как это влияет на точность
194. Должны ли выходные данные машинного обучения иметь право на защиту свободы слова?
 Поскольку генеративные системы AI производят все более сложный контент, возникает сложный вопрос: должны ли их выходные данные иметь право на защиту свободы слова?
Поскольку генеративные системы AI производят все более сложный контент, возникает сложный вопрос: должны ли их выходные данные иметь право на защиту свободы слова?
195. Меч слов: эволюция инъекции подсказок
 Исследуйте трехуровневую эволюцию инъекции подсказок: от социальной инженерии в Tensor Trust до fragmentation BPE и логических переключателей RAG в Web3-играх.
Исследуйте трехуровневую эволюцию инъекции подсказок: от социальной инженерии в Tensor Trust до fragmentation BPE и логических переключателей RAG в Web3-играх.
196. Где скрываются глюк-токены: Общие шаблоны в словарях токенизатора LLM
 Нетренированные токены часто происходят от неиспользованных байтовых токенов, слияния фрагментов и специальных токенов-шаблонов, найденных в основных LLM, независимо от архитектуры.
Нетренированные токены часто происходят от неиспользованных байтовых токенов, слияния фрагментов и специальных токенов-шаблонов, найденных в основных LLM, независимо от архитектуры.
197. Как построить чат-бот, который рассказывает средневековые истории с помощью платформы AI Oracle
 Oracle Cloud Infrastructure — это одна из крупных облачных платформ, доступных на рынке, вместе с AWS, Google Cloud и Azure.
Oracle Cloud Infrastructure — это одна из крупных облачных платформ, доступных на рынке, вместе с AWS, Google Cloud и Azure.
198. Просмотр данных: блоги, форумы и рост инструментов LLM
 Этот приложенный раздел содержит список статей и тем на Hacker News, которые были проанализированы для понимания реальных-world опыта разработчиков, использующих Copilot.
Этот приложенный раздел содержит список статей и тем на Hacker News, которые были проанализированы для понимания реальных-world опыта разработчиков, использующих Copilot.
199. Великое преобразование: как LLM изменяют каждый программный процесс
 Этот заключительный раздел исследует глубокое преобразование, которое помощь LLM приносит в весь программный опыт.
Этот заключительный раздел исследует глубокое преобразование, которое помощь LLM приносит в весь программный опыт.
200. В сторону автоматической генерации подписей к спутниковым изображениям с помощью LLM: методология
 Исследователи представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API.улучшение точности и снижение потребности в ручной маркировке.
Исследователи представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API.улучшение точности и снижение потребности в ручной маркировке.
201. Внедрение возможностей NLP в существующую стек-приложение легче, чем когда-либо: почему
 Ускорение разработки, создание контента и ускорение принятия данных решений с помощью новых инструментов ML, которые делают легким внедрение NLP в стек-технологии.
Ускорение разработки, создание контента и ускорение принятия данных решений с помощью новых инструментов ML, которые делают легким внедрение NLP в стек-технологии.
202. Навигация с помощью больших моделей языка: подробности реализации
 В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
203. Instagram переполнен содержанием, сгенерированным AI, и Meta не кажется, что заботится
 Сеть AI-сгенерированных инфлюенсеров, изображенных с синдромом Дауна, монетизируются через взрослый контент на платформах, таких как Fanvue.
Сеть AI-сгенерированных инфлюенсеров, изображенных с синдромом Дауна, монетизируются через взрослый контент на платформах, таких как Fanvue.
204. Инфраструктура данных, стоящая за каждым успешным стартапом AI
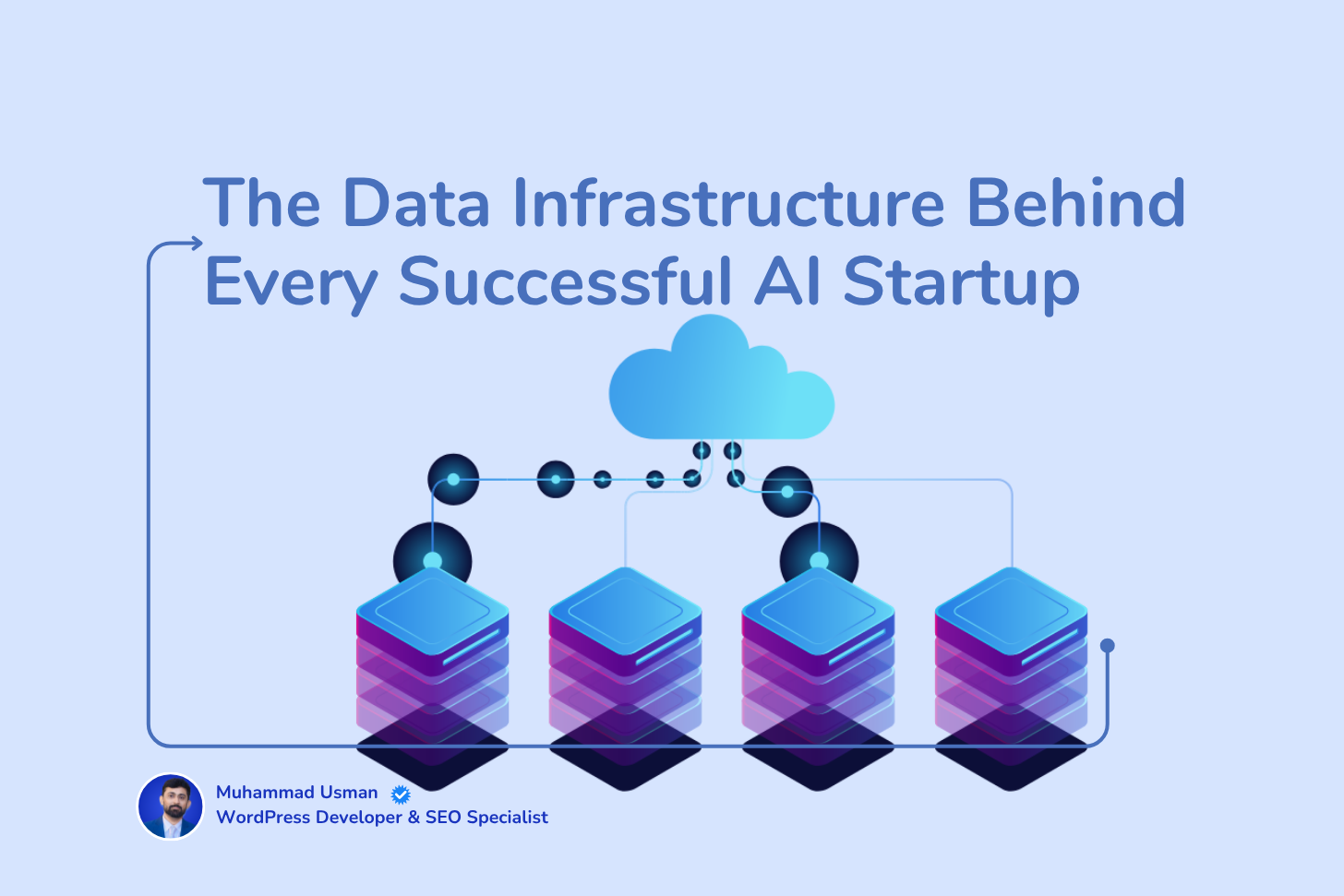 95% стартапов AI проваливаются, потому что их данные ломаются первыми. Здесь, как настоящие победители строят прочную инфраструктуру данных с помощью Bright Data, чтобы остаться в живых.
95% стартапов AI проваливаются, потому что их данные ломаются первыми. Здесь, как настоящие победители строят прочную инфраструктуру данных с помощью Bright Data, чтобы остаться в живых.
205. Excel vs. Python: как целевое язык меняет все для непрофессионалов
 Обсуждение того, почему инструмент может выбрать Python за счет его богатых API, даже если пользователь более знаком с формулами Excel, и вызванные этим проблемы.
Обсуждение того, почему инструмент может выбрать Python за счет его богатых API, даже если пользователь более знаком с формулами Excel, и вызванные этим проблемы.
206. Критика «звучащего» написания AI игнорирует более глубокие культурные предубеждения
 Нам не следует позволять моделям AI отнимать части нашего языка.
Нам не следует позволять моделям AI отнимать части нашего языка.
207. Как AI уменьшает нашу точку зрения на мир
 Генеративный AI может уменьшить разнообразие знаний, что приводит к коллапсу знаний.
Генеративный AI может уменьшить разнообразие знаний, что приводит к коллапсу знаний.
208. Психеделики | LLMs: Есть ли связь между психеделиками, LLMs и психическим заболеванием?
 Раскрыть связь между психеделиками, LLMs и психическим заболеванием.
Раскрыть связь между психеделиками, LLMs и психическим заболеванием.
209. Долина чуждости кода: почему код, сгенерированный AI, так сложен для отладки?
 Разработчики разделились во мнениях, является ли код, сгенерированный AI, действительно экономичным. Исследование компромиссов между быстрым написанием кода и затраченным временем и усилиями.
Разработчики разделились во мнениях, является ли код, сгенерированный AI, действительно экономичным. Исследование компромиссов между быстрым написанием кода и затраченным временем и усилиями.
210. MIVPG: Мультиинстансивизуальный промптгенератор для MLLMs
 MIVPG улучшает MLLMs, используя Мультиинстансивное обучение для включения коррелированной визуальной информации.
MIVPG улучшает MLLMs, используя Мультиинстансивное обучение для включения коррелированной визуальной информации.
211. Можно ли большим языковым моделям развить игровую зависимость?
 Нам не нужно расплывчатые решения, такие как "добавьте безопасные ограничения в ваши запросы", у нас есть механистическое понимание, позволяющее нам проектировать целевые вмешательства.
Нам не нужно расплывчатые решения, такие как "добавьте безопасные ограничения в ваши запросы", у нас есть механистическое понимание, позволяющее нам проектировать целевые вмешательства.
212. Героизм в Голодеке: Построение AI-компаньонов для конечной границы
 LLMs — это модели данных, обученные на колоссальных объемах текстовой информации, поглощающие книги, статьи, код и другие формы написанной информации.
LLMs — это модели данных, обученные на колоссальных объемах текстовой информации, поглощающие книги, статьи, код и другие формы написанной информации.
213. Большые языковые модели (LLMs) для образовательных приложений
 Исследуйте растущую роль GPT-моделей в образовании, детально рассмотрев их использование через запросы и тонировку для задач, таких как генерация обратной связи.
Исследуйте растущую роль GPT-моделей в образовании, детально рассмотрев их использование через запросы и тонировку для задач, таких как генерация обратной связи.
214. Никто не использует тестирование как тестирование LLM-приложений (это будет проблемой)
 Большинство команд развертывают LLM и RAG-приложения без реального набора тестов — это шестилучевая система тестирования, которая решает эту проблему.
Большинство команд развертывают LLM и RAG-приложения без реального набора тестов — это шестилучевая система тестирования, которая решает эту проблему.
215. Сила динамического кодирования: RECKONING превосходит нулевую точку GPT-3.5 по устойчивости к отвлекающим факторам
 Результаты RECKONING значительно превышают как нулевую, так и несколько точек GPT-3.5 по навыкам.
Результаты RECKONING значительно превышают как нулевую, так и несколько точек GPT-3.5 по навыкам.
216. Награждение редкого: как уникальность-осведомленная RL устраняет коллапс исследования
 Это краткое изложение статьи "Награждение редкого: уникальность-осведомленная RL для творческого решения проблем в LLM" [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utm_source=hackernoon&utm_medium=referral]. Если вам нравятся такие анализы, присоединяйтесь к AIModels.fyi [https://www.aimodels.fyi/?utm_source=hackernoon&utm_medium=referral] или следите за нами на Twitter [https://x.com/aimodelsfyi].
Это краткое изложение статьи "Награждение редкого: уникальность-осведомленная RL для творческого решения проблем в LLM" [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utm_source=hackernoon&utm_medium=referral]. Если вам нравятся такие анализы, присоединяйтесь к AIModels.fyi [https://www.aimodels.fyi/?utm_source=hackernoon&utm_medium=referral] или следите за нами на Twitter [https://x.com/aimodelsfyi].
ПРОБЛЕМА КОЛЛАПСА РАЗВОРЕНИЯ
Когда вы обучаете языковую модель с помощью метода подкрепления для решения математических задач, происходит что-то противоречивое. Вы награждаете правильные ответы. Модель находит одну надежную дорогу к правильности и, по сути, останавливается исследовать. Каждый роллбэк становится slight вариацией одной и той же темы. Pass@1 выглядит хорошо, вы решаете проблемы постоянно. Но pass@k застывает. Если вы пробуете сто раз, вы не получаете сто разных решений, вы получаете сто версий одного и того же решения.
Это коллапс исследования, и это открывает что-то сломанное в том, как мы думали о RL для языковых моделей. Стандартный подход присваивает награды на уровне токена, во время генерации. Когда токен участвует в правильном окончательном ответе, он получает подкрепление. С течением времени политика учитывает последовательность токенов, которая наиболее надежно производит награды. Другие валидные пути существуют, но они не имеют такого же подкрепления. Они не накапливают уверенность в том же порядке. Итак, политика сужается.
Напряжение реально. Модель, которая находит одну хорошую стратегию надежно, с точки зрения pass@1, делает именно то, что вы просили. Но с практической точки зрения, это упущенная возможность. Если вы готовы пробовать несколько раз, разнообразная модель должна дать вам больше шансов найти правильный ответ. Вместо этого вы получаете повторяемость. Этот разрыв между тем, что метрика измеряет, и тем, что способность должна обеспечить, — это где проблема находится.
ПОЧЕМУ МЫ ИЗМЕРЯЕМ НЕ ТО, ЧТО НУЖНО
Неявное предположение, которое движет большинством работ по RL для языковых моделей, заключается в том, что лучшие локальные награды создают лучшую глобальную разнообразность. Обучайте каждый токен принимать правильные решения, и роллбэки будут естественным образом разнообразны. Это интуитивно. Это также ложно.
На самом деле происходит то, что хорошие локальные решения укрепляют себя. Выбор токена, который приводит к правильному ответу, получает положительный сигнал. Когда модель снова должна решить подобную проблему, этот выбор токена становится чуть более вероятным. И на следующий раз, еще более вероятным. Градиент всегда указывает в ту же привлекательную область. Политика не перестает исследовать, она исследует эффективно прямо в одну и ту же впадину.
Исходная причина не в случайности или недостаточном обучении. Это фундаментальное несоответствие между тем, что мы измеряем, и тем, что мы хотим. Мы измеряем поведение на уровне токена и надеемся на поведение на уровне роллбэка.
Понимание этого несоответствия важно, потому что это означает, что решение не может быть маргинальным. Вы не можете расписание исследований differently или добавить регуляризацию энтропии и решить эту проблему. Нужно изменить то, что фактически вознаграждается на уровне ролл-аута. Нужно сделать ролл-аутовую новизну явным частью цели.
UNIQUENESS-AWARE REINFORCEMENT LEARNING
Основная идея проста: вознаграждайте правильные решения, использующие редкие стратегии, больше, чем правильные решения, повторяющие общую стратегию. Делайте политику внутренить, что нахождение нового правильного ответа более ценно, чем нахождение повторяющегося.
Метод работает в конкретных шагах. Сначала, генерируйте много роллов для одного задачи. Второй, используйте языковый модель, чтобы кластеризовать эти ролловы по их стратегии высокого уровня рассуждения. Не по их окончательным числам или записи, а по логическому подходу внутри. Один кластер для решений, использующих замену, другой для решений, использующих геометрическое рассуждение, другой для решений, основанных на калькулировании. Третий, рассчитайте размеры кластеров. Стратегия, открытая 2 из 100 роллов, редка. Стратегия, открытая 50 из 100, общая. Наконец, перепзвесьте сигнал вознаграждения обратно с размером кластера.
Функция преимущества, которая говорит политику, насколько лучше этот ролл был, по сравнению с средним, получается уменьшена для решений в больших кластерах и увеличена для решений в маленьких кластерах. Правильное решение, использующее редкую стратегию, становится стоить значительно больше вознаграждения, чем правильное решение, использующее доминирующую стратегию.
Это напрямую целиком направлено на структуру вознаграждения. А не надеясь, что диверсификация возникнет в качестве побочного эффекта тренировки на уровне токенов, политика теперь имеет явный повод исследовать: редкие правильные стратегии буквально более вознаграждаемы. Цель сдвигается от "найти любой правильный ответ" до "найти ответы, использующие подходы, которые вы еще не нашли."
CLUSTERING STRATEGIES THE RIGHT WAY
Есть практическая проблема, скрывающаяся здесь. Как определить "высокий уровень стратегии"? Кластерьте слишком грубо, и вы объедините действительно разные подходы вместе. Кластерьте слишком тонко, и вы будете считать поверхностные вариации (использование переменной x против y) фундаментально разными стратегиями. Кластерить на неправильной гранулярности и сигнал вознаграждения разрушается.
В статье используется языковый модель, как судья. А не ручное кодирование того, что считается различным стратегией, вы спрашиваете LLM, чтобы прочитать два решения и определить, используют ли они одинаковый высокий уровень подхода. Это удивительно эффективно. Языковые модели хороши в семантической эквивалентности. Два решения, использующие одинаковые логические шаги, но разную запись, признаются как подобные. Два решения, использующие действительно разные подходы, признаются как разные.
Это обходит серьезную ошибку. Рigid кластеризация на основе синтаксических характеристик пропускает важные различия или переразделяет пространство. Использование судьи LLM обеспечивает гибкость, в то время как сохраняя кластеризацию семантической и интерпретируемой. Гранулярность возникает естественным образом от того, что модель понимает как "разные подходы", а не навязывается вручную.
MEASURING WHAT MATTERS
Валидация охватывает три домена: математику, физику и медицинскую рассуждение. Метрики имеют значение, потому что они рассказывают разные истории.
Pass@1 измеряет одноразовую производительность. Модель получает один шанс. Это не должно ухудшаться, потому что ничего в уникальном RL не должно разрушать базовую компетентность.
Pass@k измеряет вероятность того, что хотя бы один правильный ответ появится в k образцах. Это то, что должно улучшиться. Если политика становится более разнообразной, получение более многочисленных образцов должно привести к большему количеству правильных ответов.
AUC@K — это площадь под pass@k
Кривая изменения, когда вы изменяете k по мере увеличения бюджета выборки. Это самый строгий тест. Он спрашивает, обеспечивает ли подход постоянные и устойчивые приросты при выборке больше, а не просто пик в каком-то конкретном значении k.
Ожидаемая картина состоит в том, что RL, осведомлённый о единственности, улучшает pass@k и AUC@K, в то время как поддерживает или слегка улучшает pass@1. Это происходит потому, что метод не меняет, что означает "правильно". Он просто делает правильные решения, используя редкие стратегии, более привлекательными. Политика становится лучше в обнаружении нескольких действительных подходов, оставаясь компетентной на первую попытку.
Эти результаты подтверждают основную гипотезу: коллапс эксплорации был реальным структурным проблемой, и решение этой проблемы на уровне ролл-аута работает. Приросты не являются незначительными корректировками уже работающей системы. Это доказательство того, что тренировочная цель формирует, какие виды решений обнаруживаются и укрепляются, и изменение этой цели разблокирует действительно разные поведение.
Ширина контекста в обучении языковых моделей
Этот труд связан с более широкими вопросами о том, как мы обучаем языковые модели. Есть растущая база исследований о том, как структура сигнала вознаграждения формирует, что модели учатся. Работа по результатно-ориентированной эксплорации в логическом рассуждении LLM [https://aimodels.fyi/papers/arxiv/outcome-based-exploration-llm-reasoning?utmsource=hackernoon&utmmedium=referral] показала, что фокус на конечной правильности вместо процесса меняет, какие стратегии появляются. Аналогичные исследования о том, как фильтрация влияет на эксплорацию [https://aimodels.fyi/papers/arxiv/whatever-remains-must-be-true-filtering-drives?utmsource=hackernoon&utmmedium=referral] предполагают, что данные, которые мы выбираем во время обучения, переливаются в политики, которые мы конечным итогом получаем.
Вклад заключается в точности и реализуемости. Это не утверждение о том, что языковые модели "креативны" в какой-то глубоком смысле. РATHER, это показывает, что тренировочная цель имеет огромное значение для того, чтобы обнаруживать разнообразные решения. Если вы вознаграждаете только правильность, вы получаете сходимость. Если вы вознаграждаете правильность и редкость, вы получаете эксплорацию. Разница заключается в гранулярности, с которой вы присваиваете сигнал вознаграждения.
Есть также связь с практической эффективностью в техниках эксплорации для обучения по подкреплению с LLM [https://aimodels.fyi/papers/arxiv/enhancing-efficiency-exploration-reinforcement-learning-llms?utmsource=hackernoon&utmmedium=referral]. Вместо добавления случайности или бонусов энтропии, которые могут ухудшить производительность, uniqueness-aware RL выравнивает эксплорацию с фактической полезностью. Модель исследует решения, которые и правильны, и разные. Это эксплорация, которая структурно стимулируется, а не навязывается снаружи.
Удобство подхода заключается в его простоте. Вы не нуждаетесь в новых архитектурах или сложных графиках эксплорации. Вы просто нужно одно изменение: сдвинуться от вознаграждения поведения токена к вознаграждению уровня ролл-аута новизны. Это одно изменение решает реальную проблему в ее источнике, и доказательства показывают, что оно работает consistently по всему спектру доменов.
Оригинальная статья: Читайте на AIModels.fyi [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utmsource=hackernoon&utmmedium=referral]
217. Решение кодовых головоломок: Эволюция инструментов программной помощи
 От упрощения задач с прямым управлением до генерации кода по примерам, отслеживайте, как умные инструменты всегда помогали программистам
От упрощения задач с прямым управлением до генерации кода по примерам, отслеживайте, как умные инструменты всегда помогали программистам
218. Давайте услышим от разработчиков: что на самом деле такое кодирование с помощью AI
 Присоединяйтесь к дискуссии. Этот раздел суммирует отчеты программистов о том, является ли использование Copilot новым языком программирования или просто признаком плохой инструментальной базы. Мы исследуем, как
Присоединяйтесь к дискуссии. Этот раздел суммирует отчеты программистов о том, является ли использование Copilot новым языком программирования или просто признаком плохой инструментальной базы. Мы исследуем, как
219. 102 Языка, Один Модель: Ключевой прорыв в мультимодальном AI, о котором вы должны знать
 Система поиска с использованием LLM соответствует речи и тексту на 102 языках, превосходя предыдущие методы с мультиязыковым пониманием.
Система поиска с использованием LLM соответствует речи и тексту на 102 языках, превосходя предыдущие методы с мультиязыковым пониманием.
220. Получение максимальной выгоды из большого языкового модели
 LLM - мощный инструмент, когда он используется эффективно с помощью инженерии запросов и настройки параметров инференса
LLM - мощный инструмент, когда он используется эффективно с помощью инженерии запросов и настройки параметров инференса
221. Few-shot In-Context Preference Learning Using Large Language Models: Full Prompts and ICPL Details
 Полные запросы и подробности ICPL для изучения Few-shot in-context preference learning с LLM
Полные запросы и подробности ICPL для изучения Few-shot in-context preference learning с LLM
222. Стоп угадывать, что делает ваш LLM - Этот инструмент показывает вам все
 OpenLLM Monitor - открытая исходная база инструментов для мониторинга, отладки и оптимизации приложений Large Language Model (LLM).
OpenLLM Monitor - открытая исходная база инструментов для мониторинга, отладки и оптимизации приложений Large Language Model (LLM).
223. FreeEval: Этические проблемы
 В этой статье мы представляем FreeEval, модульную и расширяемую базу для надежного и эффективного автоматического оценки LLM.
В этой статье мы представляем FreeEval, модульную и расширяемую базу для надежного и эффективного автоматического оценки LLM.
224. AI-Горшечник: Новая роль экспертов в мире автоматизированного кода
 Исследование меняющейся роли "горшечников" в мире, где AI может ответить на большинство вопросов. Будет ли их новая роль обучать пользователей, как использовать инструменты AI?
Исследование меняющейся роли "горшечников" в мире, где AI может ответить на большинство вопросов. Будет ли их новая роль обучать пользователей, как использовать инструменты AI?
225. ToolTalk: Бенчмаркинг будущего инструментов с помощью ассистентов AI
 Откройте ToolTalk, новый бенчмарк, предназначенный для оценки ассистентов AI, таких как GPT-3.5 и GPT-4, на сложных, многоэтапных задачах использования инструментов с конверсационными взаимодействиями
Откройте ToolTalk, новый бенчмарк, предназначенный для оценки ассистентов AI, таких как GPT-3.5 и GPT-4, на сложных, многоэтапных задачах использования инструментов с конверсационными взаимодействиями
226. Создание LLMs с правильной смесью данных
 Откройте важность LLMs и как Bright Data экономит время и деньги, предоставляя полную и соответствующую информацию для обучения AI-моделей. Узнайте больше сейчас!
Откройте важность LLMs и как Bright Data экономит время и деньги, предоставляя полную и соответствующую информацию для обучения AI-моделей. Узнайте больше сейчас!
227. Использование больших языковых моделей в тематическом анализе: как это работает
 В последнее время было проведено несколько исследований, посвященных использованию LLMs в тематическом анализе. De Paoli оценил, насколько GPT-3.5 может выполнить полноценный тематический анализ
В последнее время было проведено несколько исследований, посвященных использованию LLMs в тематическом анализе. De Paoli оценил, насколько GPT-3.5 может выполнить полноценный тематический анализ
228. Alibaba's Claude Killer Входит в Ring
 Alibaba официально выпустила QVQ-Max, свою первую производственную версию визуального моделирования.
Alibaba официально выпустила QVQ-Max, свою первую производственную версию визуального моделирования.
229. GitHub Copilot Возглавляет Заряд в коммерческом LLM-ассистированном программировании
 Эта секция дает представление о коммерческом ландшафте LLM-ассистированного программирования, от полной синтезированной системы GitHub Copilot
Эта секция дает представление о коммерческом ландшафте LLM-ассистированного программирования, от полной синтезированной системы GitHub Copilot
230. TnT-LLM для автоматизированной генерации таксономии: превышение базовых кластерных значений
 Мы оцениваем TnT-LLM для автоматизированной генерации текстовой таксономии, сравнивая ее точность и актуальность с методами кластеризации на основе вложений с помощью человека и LLM
Мы оцениваем TnT-LLM для автоматизированной генерации текстовой таксономии, сравнивая ее точность и актуальность с методами кластеризации на основе вложений с помощью человека и LLM
231. Whisper Wars: Будет ли AI-пrompt стать секретным рецептом будущего?
 Поскольку бизнесы признают ценность оптимизированных AI-пrompt, возникает новая дискуссия: могут ли prompt стать секретными рецептами, и что это означает для инноваций?
Поскольку бизнесы признают ценность оптимизированных AI-пrompt, возникает новая дискуссия: могут ли prompt стать секретными рецептами, и что это означает для инноваций?
232. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Описание нашей техники
 В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости переподготовки его с нуля.
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости переподготовки его с нуля.
233. Преимущества применения ограничений к выводам LLM
 За упомянутыми выше случаями нашим опрошенным респондентам сообщили о ряде преимуществ, которые могла бы предложить возможность ограничивать выводы LLM.
За упомянутыми выше случаями нашим опрошенным респондентам сообщили о ряде преимуществ, которые могла бы предложить возможность ограничивать выводы LLM.
234. Развитие разговорного AI с помощью сложной оркестровки инструментов
 Исследуйте ToolTalk, бенчмарк для оценки инструментально-усиленных LLM в разговорных AI-сценариях.
Исследуйте ToolTalk, бенчмарк для оценки инструментально-усиленных LLM в разговорных AI-сценариях.
235. Создание готовой к производству системы оптимизации затрат и риска LLM
 Глубокое погружение в создание готовой к производству системы оптимизации затрат и риска LLM с помощью аналитики токенов, обнаружения риска в запросах и реального времени мониторинга.
Глубокое погружение в создание готовой к производству системы оптимизации затрат и риска LLM с помощью аналитики токенов, обнаружения риска в запросах и реального времени мониторинга.
236. Говоря на коде: Как AI симулирует эволюцию языка на регулируемой социальной сети
 Как большие языковые модели симулируют эволюцию языка под социальной сетью с цензурой, раскрытие адаптивных стратегий общения в регулируемых средах.
Как большие языковые модели симулируют эволюцию языка под социальной сетью с цензурой, раскрытие адаптивных стратегий общения в регулируемых средах.
237. Как развернуть LLM с помощью MindsDB и OpenAI: Эссенциальный гид
 В этой статье вы узнаете, как развернуть LLM с помощью MindsDB и OpenAI.
В этой статье вы узнаете, как развернуть LLM с помощью MindsDB и OpenAI.
238. Скрытые слуховые знания внутри языковых моделей
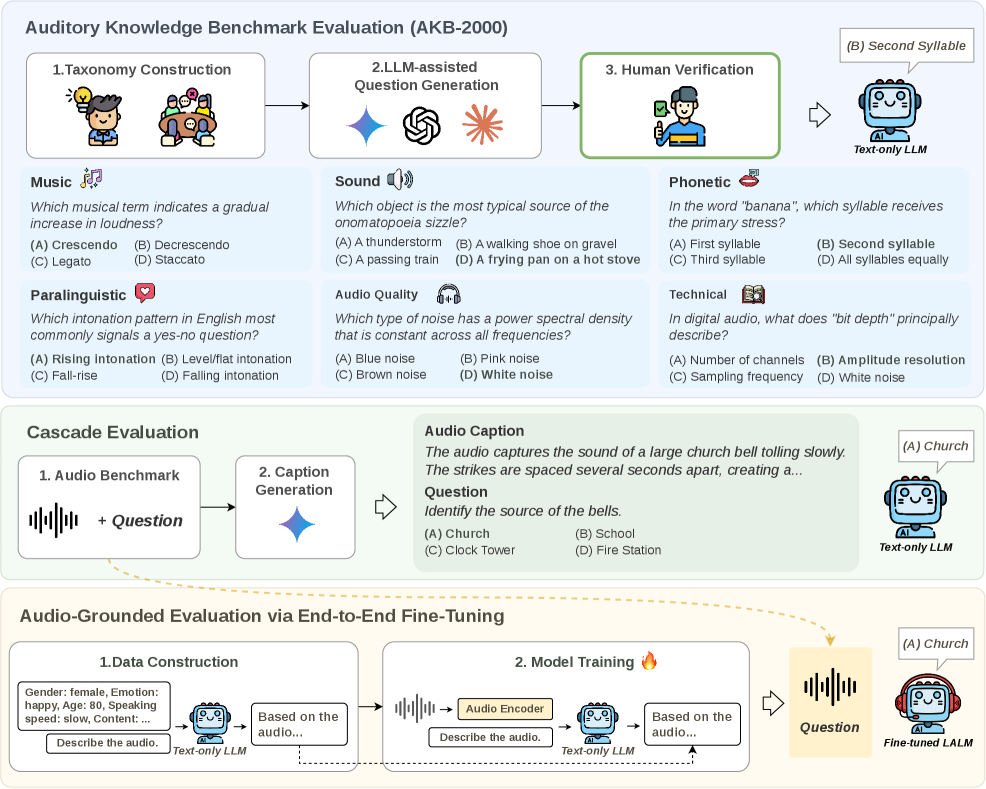 Это краткое изложение статьи о том, как слуховые знания в ядре LLM формируют аудиолингвистические модели: Общая оценка…
Это краткое изложение статьи о том, как слуховые знания в ядре LLM формируют аудиолингвистические модели: Общая оценка…
239. Влияние потенциал и выгоды от авызываемых моделей языка на прибыль от поисковых рекламы
 Какие изменения произойдут в коммерческом экосистеме рекламы?
Какие изменения произойдут в коммерческом экосистеме рекламы?
240. Новый метод может открыть возможности авызываемых моделей языка для видения и описания картинок с необычайной подробностью
 Исследователи из университета Мохаммеда бин Зайеда разработали авызываемый модел, который может создавать текстовые беседы, связанные с конкретными объектами или регионами на картинке.
Исследователи из университета Мохаммеда бин Зайеда разработали авызываемый модел, который может создавать текстовые беседы, связанные с конкретными объектами или регионами на картинке.
241. Навигация с помощью авызываемых моделей языка: Абстрактное предисловие
 В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.
В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.
242. Навигация с помощью авызываемых моделей языка: Авызываемые хитеристики для цели направленной эксплорации
 В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.
В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.
243. Кто Харриспоттер? Авызываемое приостановление в авызываемых моделях языка: Результаты
 В этой статье исследователи предлагают новую технику для приостановления обучения части обучающейся базы данных авызываемого моделя языка без необходимости повторного обучения с нуля.
В этой статье исследователи предлагают новую технику для приостановления обучения части обучающейся базы данных авызываемого моделя языка без необходимости повторного обучения с нуля.
244. Улучшение мультивычислительной логики в авызываемых моделях языка
 Используя обученную модель Q-значения для руководства каждого шага, Q улучшает вычислительную логику авызываемых моделей языка, увеличивая точность математических и кодовых вычислений без необходимости тонкой настройки.
Используя обученную модель Q-значения для руководства каждого шага, Q улучшает вычислительную логику авызываемых моделей языка, увеличивая точность математических и кодовых вычислений без необходимости тонкой настройки.
245. Февшот в контексте предпочтения обучения, используя авызываемые языковые окружения: Детали
 В этой статье исследователи предлагают новую технику для обучения авызываемых моделей языка, которая позволяет им обучаться на нескольких примерах в контексте.
В этой статье исследователи предлагают новую технику для обучения авызываемых моделей языка, которая позволяет им обучаться на нескольких примерах в контексте.
246. Авызываемые языковые окружения для авызываемых моделей языка
 В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.
247. Авызываемые языковые окружения для авызываемых моделей языка
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.
248. Авызываемые языковые окружения для авызываемых моделей языка
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.
245. Few-shot In-Context Preference Learning Using Large Language Models: Обстановка Details
 Откройте ключевые детали окружения, описания задач и метрики для 9 задач в IsaacGym, как указано в этой статье.
Откройте ключевые детали окружения, описания задач и метрики для 9 задач в IsaacGym, как указано в этой статье.
246. Building GPT-2 from Scratch in Rust - A Software Engineer’s Deep Dive into Transformers and Tensors
 Узнайте, как программист построил работающий клон GPT-2 с нуля в Rust на Ubuntu. Этот глубокий дайв покрывает вложения, внимание, остатки, обучение и
Узнайте, как программист построил работающий клон GPT-2 с нуля в Rust на Ubuntu. Этот глубокий дайв покрывает вложения, внимание, остатки, обучение и
247. How Many Examples Does AI Really Need? New Research Reveals Surprising Scaling Laws
 Gemini 1.5 Pro показывает логарифмические приросты до ~1K примеров (+38% точность). Бatching уменьшает затраты в 45 раз и задержку в 35 раз с минимальным снижением производительности.
Gemini 1.5 Pro показывает логарифмические приросты до ~1K примеров (+38% точность). Бatching уменьшает затраты в 45 раз и задержку в 35 раз с минимальным снижением производительности.
248. NExT-GPT: Any-to-Any Multimodal LLM: Instruction Tuning
 В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-систему под названием NExT-GPT.
В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-систему под названием NExT-GPT.
249. OPT-175B is Comparable to GPT-3 While Requiring Only 1/7th the Carbon Footprint
 OPT обеспечивает открытый доступ к языковым моделям GPT-3 масштаба, позволяя ответственным исследованиям AI с меньшими вычислительными затратами и воспроизводимыми экспериментами.
OPT обеспечивает открытый доступ к языковым моделям GPT-3 масштаба, позволяя ответственным исследованиям AI с меньшими вычислительными затратами и воспроизводимыми экспериментами.
250. Evaluating Sentiment Analysis Performance: LLMs vs Classical ML
 Эта история сравнивает производительность анализа настроений больших языковых моделей (LLM) с классическими методами ML, такими как SVM и деревья решений
Эта история сравнивает производительность анализа настроений больших языковых моделей (LLM) с классическими методами ML, такими как SVM и деревья решений
251. Your Smart Home Probably Isn’t As Reliable As You Think: Here Is Why
 AI вошла в наши дома, но под гипсом лежат реальные архитектурные вопросы об надежности, краевой вычислении и том
AI вошла в наши дома, но под гипсом лежат реальные архитектурные вопросы об надежности, краевой вычислении и том
252. Secret Tokens, Secret Trouble: The Hidden Flaws Lurking in Big-Name AIs
 Glitch-токены сохраняются в закрытых и открытых моделях; синхронизация токенизатора и обучающей выборки, а также целевые проверки, являются ключом к безопасным и более эффективным LLM.
Glitch-токены сохраняются в закрытых и открытых моделях; синхронизация токенизатора и обучающей выборки, а также целевые проверки, являются ключом к безопасным и более эффективным LLM.
253. Neurobiology: Like LLMs, the Brain Isn't Predicting
 Когда говорят, что мозг генерирует прогнозы, как это происходит? Это нейробиология мозга, с тканевыми бороздами, возвышениями или кровеносными сосудами?
Когда говорят, что мозг генерирует прогнозы, как это происходит? Это нейробиология мозга, с тканевыми бороздами, возвышениями или кровеносными сосудами?
254. What Makes a Scene Important? This AI Knows
 Улучшение суммирования сценария фильма с помощью обнаружения важности сцены для лучшего выбора контента и эффективного повествования.
Улучшение суммирования сценария фильма с помощью обнаружения важности сцены для лучшего выбора контента и эффективного повествования.
255. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning: Prompts
 В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
256. Where does In-context Translation Happen in Large Language Models: Further Analysis
 В этом исследовании ученые пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.
В этом исследовании ученые пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.
257. ICPL Baseline Methods: Disagreement Sampling and PrefPPO for Reward Learning
 Узнайте, как методы выборки разногласий и PrefPPO оптимизируют обучение по вознаграждению в обучении по подкреплению.
Узнайте, как методы выборки разногласий и PrefPPO оптимизируют обучение по вознаграждению в обучении по подкреплению.
258. Building Chatbots from Scratch: Understanding and Harnessing Large Language Models (LLMs)
 Представьте себе умного друга, который прочитал каждую книгу, статью и блог-пост в интернете.
Представьте себе умного друга, который прочитал каждую книгу, статью и блог-пост в интернете.
259. Исследования Anthropic: AI может скрыть риск внутри себя
 Исследования Anthropic показывают, что AI может скрывать риски внутри себя, производя спокойный и отполированный выход, выявляя существенное разрыв в тестировании безопасности.
Исследования Anthropic показывают, что AI может скрывать риски внутри себя, производя спокойный и отполированный выход, выявляя существенное разрыв в тестировании безопасности.
260. Обширное обнаружение не обученных токенов в токенизаторах языковых моделей
 Представлены новые методы обнаружения «глюк-токенов» в LLMs - не обученных токенов, вызывающих нежелательное поведение - и инструменты для безопасных и более устойчивых языковых моделей.
Представлены новые методы обнаружения «глюк-токенов» в LLMs - не обученных токенов, вызывающих нежелательное поведение - и инструменты для безопасных и более устойчивых языковых моделей.
261. Где происходит перевод в контексте в больших языковых моделях: где происходит перевод в контексте MT?
 В этом исследовании исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу моделей.
В этом исследовании исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу моделей.
262. ToolTalk: БENCHMARK-инструмент для оценки инструментально-усиленных LLMs в конверсационном AI
 Изучайте ToolTalk, бенчмарк для оценки инструментально-усиленных LLMs в конверсационном AI.
Изучайте ToolTalk, бенчмарк для оценки инструментально-усиленных LLMs в конверсационном AI.
263. Обучение AI сказать «Я не знаю»: четырехэтапная инструкция по контекстуальному импутации данных
 CLAIM преобразует таблицы данных в естественный язык, а затем использует LLM для генерации контекстуальных текстовых описаний для пропущенных значений для улучшения последующих задач.
CLAIM преобразует таблицы данных в естественный язык, а затем использует LLM для генерации контекстуальных текстовых описаний для пропущенных значений для улучшения последующих задач.
264. Может ли GPT обмануть социальные сети? Внутри эксперимента по эволюции языка AI
 Смотрите, как большие языковые модели творчески адаптируют стратегии языка под надзор, эффективно избегая обнаружения и передавая скрытую информацию.
Смотрите, как большие языковые модели творчески адаптируют стратегии языка под надзор, эффективно избегая обнаружения и передавая скрытую информацию.
265. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Обзор и Введение
 В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.
266. Google’s 540B AI Model Изменяет, Как Мыслиют Машины: Почему Это имеет значение
 Модель AI PaLM Google использует 540B параметров для достижения прорывных результатов в области рассуждений, обучения по нескольким примерам и многолингвальной производительности на необычайно больших масштабах.
Модель AI PaLM Google использует 540B параметров для достижения прорывных результатов в области рассуждений, обучения по нескольким примерам и многолингвальной производительности на необычайно больших масштабах.
267. Рекомендации по кратким профиль пользователям из текста отзывов: Обзор и Введение
 В этой работе решается сложная и малоисследованная задача поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.
В этой работе решается сложная и малоисследованная задача поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.
268. Как AI Могут быть Перекрашиванием и Уменьшением Знаний
 Знание сворачивается, когда информация сужается со временем, уменьшая разнообразие в мысли и открытиях.
Знание сворачивается, когда информация сужается со временем, уменьшая разнообразие в мысли и открытиях.
269. Использование LLM для Генерации Необычных Текстовых Входов в Тестирование Мобильных Приложений: Обзор и Введение
 Использование InputBlaster, новой подход в использовании LLM для автоматической генерации разнообразных текстовых входов в тестирование мобильных приложений.
Использование InputBlaster, новой подход в использовании LLM для автоматической генерации разнообразных текстовых входов в тестирование мобильных приложений.
270. Накажи Свои Собственные РАГ-Стек в Меньше часа
 Узнайте, как построить быстрый, офлайн API поиска семантики с помощью PostgreSQL + pgvector, Transformers.js и Fastify — идеальный вариант для РАГ-пайплайнов и приложений AI.
Узнайте, как построить быстрый, офлайн API поиска семантики с помощью PostgreSQL + pgvector, Transformers.js и Fastify — идеальный вариант для РАГ-пайплайнов и приложений AI.
271. Наука за Много-Налетным Обучением: Тестирование AI по 10 Различным Доменам Визуализации
 src="https://cdn.hackernoon.com/images/sinW25rWovdN38P2ArzdPSCP3hi1-zp03160.jpeg"/>
Оценка GPT-4o vs Gemini 1.5 Pro на 10 наборах данных для зрения с многошотовой ICL, используя стратифицированное выборочное образец и стандартные показатели точности/F1.
src="https://cdn.hackernoon.com/images/sinW25rWovdN38P2ArzdPSCP3hi1-zp03160.jpeg"/>
Оценка GPT-4o vs Gemini 1.5 Pro на 10 наборах данных для зрения с многошотовой ICL, используя стратифицированное выборочное образец и стандартные показатели точности/F1.
272. Cited Works: AI в образовании, обработке естественного языка и исследованиях обучения
 Список академических источников на пересечении искусственного интеллекта в образовании и методов обработки естественного языка
Список академических источников на пересечении искусственного интеллекта в образовании и методов обработки естественного языка
273. DreamLLM: Дополнительные связанные работы для рассмотрения
 Этот прорыв привлек много внимания и открыл путь для дальнейших исследований и разработок в этой области.
Этот прорыв привлек много внимания и открыл путь для дальнейших исследований и разработок в этой области.
274. CulturaX: Качественный, многоязычный набор данных для LLM - Резюме и Введение
 Введение CulturaX: 6,3 триллиона токенов многоязычный набор данных в 167 языках, тщательно очищенный и дедублицированный для обучения высокопроизводительных LLM.
Введение CulturaX: 6,3 триллиона токенов многоязычный набор данных в 167 языках, тщательно очищенный и дедублицированный для обучения высокопроизводительных LLM.
275. Объединенные модели речи и языка могут быть уязвимы для атак с вредной целью
 Откройте, как атаки с вредной целью выявляют безопасные пробелы в моделях речи и языка, и как меры противодействия могут смягчить риски «заключения в тюрьму».
Откройте, как атаки с вредной целью выявляют безопасные пробелы в моделях речи и языка, и как меры противодействия могут смягчить риски «заключения в тюрьму».
276. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: Экспериментальное проектирование
 Использование InputBlaster, новой подхода к использованию LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
Использование InputBlaster, новой подхода к использованию LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
277. Ученые только что нашли способ пропустить обучение AI целиком. Здесь как
 Многошотовая ICL позволяет быстро адаптировать модель без тонирования, улучшая доступность. Будущая работа: другие задачи, открытие моделей, снижение предвзятости.
Многошотовая ICL позволяет быстро адаптировать модель без тонирования, улучшая доступность. Будущая работа: другие задачи, открытие моделей, снижение предвзятости.
278. Навигация с помощью больших моделей языка: подсчет баллов LFS и подцели с помощью опроса LLM
 Использование LLM для навигации с помощью подсчета баллов LFS и подцели с помощью опроса LLM.
Использование LLM для навигации с помощью подсчета баллов LFS и подцели с помощью опроса LLM.
279. Мультимодальные трансформаторы для описания изображений и обнаружения объектов
Использование мультимодальных трансформаторов для описания изображений и обнаружения объектов.
280. AI в образовательных исследованиях и инновациях
Использование AI в образовательных исследованиях и инновациях.
278. Навигация с большими языковыми моделями: LFG: Оценка подцелей путем опроса LLM
 В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
279. Эмпирическая валидация мультитокен-предсказания для LLM
 Исследуйте обширные эксперименты на больших масштабах, демонстрирующие эффективность мультитокен-предсказания в улучшении работы LLM по размеру модели
Исследуйте обширные эксперименты на больших масштабах, демонстрирующие эффективность мультитокен-предсказания в улучшении работы LLM по размеру модели
280. Действия против недействия: оценка корректности ассистентов AI
 Откройте ToolTalk подробную методологию оценки точности ассистентов AI в использовании инструментов
Откройте ToolTalk подробную методологию оценки точности ассистентов AI в использовании инструментов
281. Грамматика желания: что наши промпты на самом деле говорят о нас
 Специulative взгляд на то, как промпты AI отражают наши внутренние жизни, превращая желания и страхи в данные точки в растущей мета-литературе человеческих желаний.
Специulative взгляд на то, как промпты AI отражают наши внутренние жизни, превращая желания и страхи в данные точки в растущей мета-литературе человеческих желаний.
282. Тёмная сторона AI: надежность, безопасность и уверенность в генерации кода программ
 Эта секция утверждает, что традиционные метрики, такие как HumanEval и MBPP, не являются достаточными. Мы исследуем сложные проблемы оценки генерируемого AI кода
Эта секция утверждает, что традиционные метрики, такие как HumanEval и MBPP, не являются достаточными. Мы исследуем сложные проблемы оценки генерируемого AI кода
283. Понимание связанного исследования по улучшению инструментов
 Узнайте о связанном исследовании по улучшению LLM, сравнительном анализе, существующих метриках, наборах данных и системах диалога, ориентированных на задачи
Узнайте о связанном исследовании по улучшению LLM, сравнительном анализе, существующих метриках, наборах данных и системах диалога, ориентированных на задачи
284. Методы для открытия спора: детекция и генерация с помощью техник связанных с NLP
 Детекция спора использует бинарную или многозначную классификацию; генерация использует LLM, такие как GPT-2, сталкиваясь с проблемами оценки и развертывания.
Детекция спора использует бинарную или многозначную классификацию; генерация использует LLM, такие как GPT-2, сталкиваясь с проблемами оценки и развертывания.
285. Ваши следующие сленговые фразы могут быть созданы AI
 Эта статья исследует, как AI может создавать новые сленговые фразы и как это может повлиять на язык и общение.
Эта статья исследует, как AI может создавать новые сленговые фразы и как это может повлиять на язык и общение.
286. Предсказание и оценка производительности на средствах автоматизированного обучения
Эта статья исследует, как предсказывать и оценивать производительность на средствах автоматизированного обучения.
287. Сравнительный анализ методов автоматизированного обучения с использованием машинного обучения
Эта статья исследует, как сравнивать методы автоматизированного обучения с использованием машинного обучения.
288. Автоматизированное обучение: предсказание и оценка производительности на средствах автоматизированного обучения
Эта статья исследует, как предсказывать и оценивать производительность на средствах автоматизированного обучения.
289. Автоматизированное обучение: сравнительный анализ методов автоматизированного обучения с использованием машинного обучения
Эта статья исследует, как сравнивать методы автоматизированного обучения с использованием машинного обучения.
285. Ваше следующее сленговое выражение может быть создано AI
 Исследуйте, как большие языковые модели продвигают распознавание сленга, симулируют эволюцию языка и формируют социальные взаимодействия с помощью инновационных методов, управляемых AI.
Исследуйте, как большие языковые модели продвигают распознавание сленга, симулируют эволюцию языка и формируют социальные взаимодействия с помощью инновационных методов, управляемых AI.
286. Навигация с помощью больших языковых моделей: обсуждение и ссылки
 В этой статье мы изучаем, как «семантическое угадывание», производимое языковыми моделями, можно использовать в качестве руководящей онтологии для алгоритмов планирования.
В этой статье мы изучаем, как «семантическое угадывание», производимое языковыми моделями, можно использовать в качестве руководящей онтологии для алгоритмов планирования.
287. Персонализированные супы: выравнивание LLM с помощью объединения параметров - вывод и ссылки
 В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.
В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.
288. Давайте поговорим о удобстве: разбор пользовательского опыта AI-ассистированного программирования
 Войдите в исследование, как инструменты, такие как Copilot, действительно влияют на производительность разработчиков, раскрытие тонкого изображения задачи времени и процента принятия.
Войдите в исследование, как инструменты, такие как Copilot, действительно влияют на производительность разработчиков, раскрытие тонкого изображения задачи времени и процента принятия.
289. LLaMA: открытые и эффективные основы языковых моделей
 LLaMA предлагает языковые модели с 7B–65B параметрами, обученные на публичных данных, превосходящие GPT-3 и позволяющие открытым и масштабируемым исследованиям AI.
LLaMA предлагает языковые модели с 7B–65B параметрами, обученные на публичных данных, превосходящие GPT-3 и позволяющие открытым и масштабируемым исследованиям AI.
290. Метод «сначала суммируйте, затем ищите» для длинного видео вопрос-ответ: детали эксперимента
 В этой статье исследователи изучают нулевую задачу видео QA с помощью GPT-3, превосходящие обученные модели, используя краткие суммы и визуальное сопоставление.
В этой статье исследователи изучают нулевую задачу видео QA с помощью GPT-3, превосходящие обученные модели, используя краткие суммы и визуальное сопоставление.
291. Навигация с помощью больших языковых моделей: семантическое угадывание в качестве онтологии для планирования: связанные работы

В этой статье мы изучаем, как "семантическая угадка", производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
292. Сравнение времени обучения: Multi-Token vs. Next-Token Prediction
 Эта таблица (S5) количественно отражает превышение времени обучения для предсказания многотокенов по сравнению с предсказанием следующего токена
Эта таблица (S5) количественно отражает превышение времени обучения для предсказания многотокенов по сравнению с предсказанием следующего токена
293. Настройка ChatGPT для кодирования: GPTutor дает разработчикам полный контроль в VS Code
 GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.
GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.
294. Вы можете использовать глубокое исследование для создания своего онлайн-присутствия
 Глубокое исследование является одной из аспектов, которые компании AI готовы внедрить и интегрировать с их текущими системами AI. Применение глубокого исследования огромно..
Глубокое исследование является одной из аспектов, которые компании AI готовы внедрить и интегрировать с их текущими системами AI. Применение глубокого исследования огромно..
295. GPTutor позволяет разработчикам тонко настраивать помощь AI по кодированию внутри VS Code
 GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.
GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.
296. Понимание коллапса знаний и его отношение к историческим и текущим знаниям
 Изучите, как AI, технологии и эпистемические горизонты способствуют коллапсу знаний, влияя на доступ к историческим и текущим знаниям.
Изучите, как AI, технологии и эпистемические горизонты способствуют коллапсу знаний, влияя на доступ к историческим и текущим знаниям.
297. Анализ производительности AI-ассистента: Уроки из анализа ToolTalk о GPT-3.5 и GPT-4
 Изучите эксперименты и анализ ToolTalk, оценивающие GPT-3.5 и GPT-4 в использовании AI-инструментов.
Изучите эксперименты и анализ ToolTalk, оценивающие GPT-3.5 и GPT-4 в использовании AI-инструментов.
298. LLMs: Что является механизмом сознания и интеллекта
 Изучите, как LLMs могут быть использованы для понимания и моделирования сознания и интеллекта.
Изучите, как LLMs могут быть использованы для понимания и моделирования сознания и интеллекта.
Сознание и Интеллект?
 Сознание просто представляет собой взаимодействие компонентов человеческого мозга. Когда компоненты взаимодействуют, они помогают понять.
Сознание просто представляет собой взаимодействие компонентов человеческого мозга. Когда компоненты взаимодействуют, они помогают понять.
299. Улучшение генетического улучшения мутаций: выводы и будущая работа
 Выводы, полученные путем интеграции больших языковых моделей (LLM) в эксперименты по генетическому улучшению (GI) и изучения перспектив для эволюции программного обеспечения.
Выводы, полученные путем интеграции больших языковых моделей (LLM) в эксперименты по генетическому улучшению (GI) и изучения перспектив для эволюции программного обеспечения.
300. SpeechVerse Объединяет Аудио-кодировщик и LLM для превосходного устного QA
 Узнайте, как SpeechVerse использует 24-слойный Conformer и LLM, такие как Flan-T5 и Mistral, для повышения производительности устного QA.
Узнайте, как SpeechVerse использует 24-слойный Conformer и LLM, такие как Flan-T5 и Mistral, для повышения производительности устного QA.
301. За кулисами: Вопросы и трюки, которые сделали многошот ИКЛ работать
 Приложение детализирует вопросы, тесты на устойчивость выбора, сравнения GPT4V-Turbo и расширения медицинской QA, подтверждающие многошотовую методологию ИКЛ.
Приложение детализирует вопросы, тесты на устойчивость выбора, сравнения GPT4V-Turbo и расширения медицинской QA, подтверждающие многошотовую методологию ИКЛ.
302. Интегрированные модели речи и языка сталкиваются с критическими проблемами безопасности
 Атаки с враждебным направлением легко обходят безопасность в SLM, призывая к robust защитам и дальнейшему исследованию для обеспечения безопасных многомодальных речи-языковых систем.
Атаки с враждебным направлением легко обходят безопасность в SLM, призывая к robust защитам и дальнейшему исследованию для обеспечения безопасных многомодальных речи-языковых систем.
303. CulturaX: высококачественный, многоязычный набор данных для LLM - создание многоязычного набора данных
 Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
304. FOD 39: Истинно Открыто – Мы Исследуем, Кто Стоит За Релизом OLMo
 Мы оцениваем OLMo, прорыв в области ИИ от AI2, который обещает истинно открытый исходный код: полный доступ к пакету. Plus последние новости из мира ИИ.
Мы оцениваем OLMo, прорыв в области ИИ от AI2, который обещает истинно открытый исходный код: полный доступ к пакету. Plus последние новости из мира ИИ.
305. Сколько токенов ошибок скрываются в популярных LLM? Открытия из масштабных тестов
 Мы исследуем, сколько токенов ошибок скрываются в популярных LLM, и что открытия из масштабных тестов говорят о эффективности индикаторов и верификации.
Мы исследуем, сколько токенов ошибок скрываются в популярных LLM, и что открытия из масштабных тестов говорят о эффективности индикаторов и верификации.
306. FOD 40: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.
307. FOD 41: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.
308. FOD 42: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.
Glitch Tokens Hide in Popular LLMs? Revelations from Large-Scale Testing
 Некачественные токены в популярных LLM обнаруживаются с помощью эффективных индикаторов, обученных на недостаточном объеме данных, что позволяет выявлять рисковые токены, с результатами между 0,1–1% словарного запаса, которые постоянно вызывают проблемы.
Некачественные токены в популярных LLM обнаруживаются с помощью эффективных индикаторов, обученных на недостаточном объеме данных, что позволяет выявлять рисковые токены, с результатами между 0,1–1% словарного запаса, которые постоянно вызывают проблемы.
306. How I Grew My Twitter Audience From 0 to 500 Followers in Just 30 Days
 Я восстановил свой аккаунт в Twitter после блокировки. Здесь вы найдете точный способ, которым я вырос до 500 подписчиков за 30 дней с помощью ответов, реальных взглядов и без сделок по кросс-промоушену.
Я восстановил свой аккаунт в Twitter после блокировки. Здесь вы найдете точный способ, которым я вырос до 500 подписчиков за 30 дней с помощью ответов, реальных взглядов и без сделок по кросс-промоушену.
307. Where does In-context Translation Happen in Large Language Models: Conclusion
 В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.
В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.
308. Where does In-context Translation Happen in Large Language Models: Inference Efficiency
 В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.
В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.
309. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Conclusion and References
 Введение CulturaX: 6,3 триллиона токенов в 167 языках, тщательно очищенных и дедуплицированных для обучения высокоэффективным моделям LLM.
Введение CulturaX: 6,3 триллиона токенов в 167 языках, тщательно очищенных и дедуплицированных для обучения высокоэффективным моделям LLM.
310. Towards Automatic Satellite Images Captions Generation Using LLMs: References
 Ученые представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API, повышая точность и снижая потребность в ручной аннотации.
Ученые представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API, повышая точность и снижая потребность в ручной аннотации.
311. The Nuts and Bolts of Token Testing: Prompt Variations and Decoding in Practice
 Робустные, повторяющиеся
Робустные, повторяющиеся
Промпты и понимание UTF-8 важны для точного проверки и диагностики недообученных токенов в языковых моделях.
312. Большие языковые модели на устройствах с ограниченной памятью на основе флэш-памяти: Выводы и обсуждение
 Успешно запускать большие языковые модели на устройствах с ограниченной памятью на основе оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.
Успешно запускать большие языковые модели на устройствах с ограниченной памятью на основе оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.
313. Персонализированные супы: Выравнивание LLM с помощью объединения параметров - Резюме и Введение
 Эта работа представляет RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.
Эта работа представляет RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.
314. DreamLLM: Дополнительные качественные примеры, демонстрирующие его мощь
 Эти фигуры иллюстрируют профессионализм DREAMLLM в понимании и генерации длинного контекста многомодальной информации в различных форматах входных и выходных данных.
Эти фигуры иллюстрируют профессионализм DREAMLLM в понимании и генерации длинного контекста многомодальной информации в различных форматах входных и выходных данных.
315. Где происходит перевод в контексте в больших языковых моделях: Характеристика избыточности в Laye
 В этой работе исследователи пытаются характеризовать регион, где большие языковые модели переходят от обучения в контексте к переводам.
В этой работе исследователи пытаются характеризовать регион, где большие языковые модели переходят от обучения в контексте к переводам.
316. Рекомендации по кратким профилам пользователей из текста отзывов: Связанная работа
 Эта работа решает сложную и малоисследованную проблему поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.
Эта работа решает сложную и малоисследованную проблему поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.
317. NExT-GPT: Любой к любому многомодальный LLM: Резюме и Введение
 В этой работе исследователи представляют собой конечный результат общего назначения любому к любому MM-LLM-системы под названием NExT-GPT.
В этой работе исследователи представляют собой конечный результат общего назначения любому к любому MM-LLM-системы под названием NExT-GPT.
318. Данные, которые мы получили от использования LLM для поддержки тематического анализа
 В этой работе исследователи представляют данные, которые они получили от использования LLM для поддержки тематического анализа.
В этой работе исследователи представляют данные, которые они получили от использования LLM для поддержки тематического анализа.
319. Оценка влияния LLM на понимание текста
 В этой работе исследователи представляют оценку влияния LLM на понимание текста.
В этой работе исследователи представляют оценку влияния LLM на понимание текста.
320. В сторону более человеческого подобия разговорного AI
 В этой работе исследователи представляют собой направление более человеческого подобия разговорного AI.
В этой работе исследователи представляют собой направление более человеческого подобия разговорного AI.
318. Данные, которые мы получили, используя LLM для поддержки тематического анализа
 В наших экспериментах мы использовали набор данных из 785 описаний фактов из дел чешских судов, решенных в 2017 году.
В наших экспериментах мы использовали набор данных из 785 описаний фактов из дел чешских судов, решенных в 2017 году.
319. Почему тысячи примеров побеждают десятки каждый раз
 Многопримерный мультимодальный ICL с тысячами примеров улучшает работу LMM. Gemini 1.5 Pro демонстрирует логарифмические приросты; группировка снижает затраты.
Многопримерный мультимодальный ICL с тысячами примеров улучшает работу LMM. Gemini 1.5 Pro демонстрирует логарифмические приросты; группировка снижает затраты.
320. Newsletter HackerNoon: Так.. Как действительно определить, что AI осознает? (2/8/2025)
 2/8/2025: Топ-5 историй на главной странице HackerNoon!
2/8/2025: Топ-5 историй на главной странице HackerNoon!
321. Adaptive Attacks: Открывающие уязвимости SLM и качественные наблюдения
 Адаптивные атаки требуют более крупных возмущений, чтобы преодолеть защиту TDNF в SLM, снижая успех тюремного побега; качественные примеры подчеркивают сильные и ограничения стороны.
Адаптивные атаки требуют более крупных возмущений, чтобы преодолеть защиту TDNF в SLM, снижая успех тюремного побега; качественные примеры подчеркивают сильные и ограничения стороны.
322. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: Резюме и Введение
 Успешно запускайте большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
Успешно запускайте большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
323. Конец игры в догадки? Почему описывание данных побеждает оценку
 CLAIM превосходит статистические и методы ML, используя LLM для контекстуальной импутации, хотя будущая работа должна решить проблемы масштабируемости и специфику домена.
CLAIM превосходит статистические и методы ML, используя LLM для контекстуальной импутации, хотя будущая работа должна решить проблемы масштабируемости и специфику домена.
324. FreeEval: Модульная платформа для надежной и эффективной оценки больших моделей языка
 FreeEval разработан с высокопроизводительной инфраструктурой, включая распределенную вычислительную мощность и стратегии кэширования
FreeEval разработан с высокопроизводительной инфраструктурой, включая распределенную вычислительную мощность и стратегии кэширования
325. Как ICPL повышает эффективность функции вознаграждения и решает сложные задачи RL
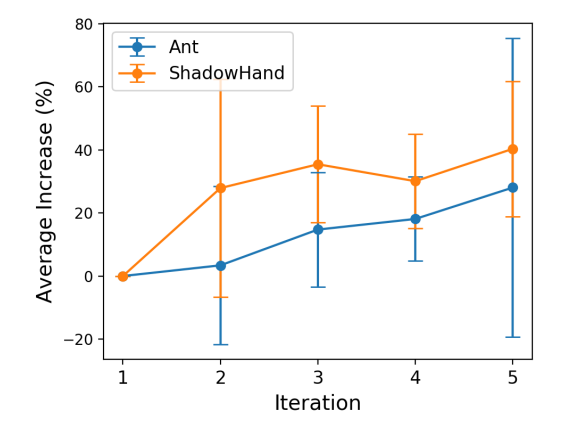 ICPL повышает эффективность обучения по принципу вознаграждения, интегрируя LLM и человеческие предпочтения для синтеза функции вознаграждения.
ICPL повышает эффективность обучения по принципу вознаграждения, интегрируя LLM и человеческие предпочтения для синтеза функции вознаграждения.
326. Большие языковые модели на устройствах с ограниченной памятью с помощью flash-памяти: результаты
 Успешно запускать большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, уменьшая передачу данных и повышая скорость передачи.
Успешно запускать большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, уменьшая передачу данных и повышая скорость передачи.
327. Использование AI в подготовке рукописей для академических журналов: Приложение для восприятия и обнаружения
 В этом исследовании исследователи изучают, считают ли ученые необходимым отчетливо сообщать о использовании AI в подготовке рукописей.
В этом исследовании исследователи изучают, считают ли ученые необходимым отчетливо сообщать о использовании AI в подготовке рукописей.
328. Навигация с помощью больших языковых моделей: оценка системы
 В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящего онтогенетического алгоритма.
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящего онтогенетического алгоритма.
329. GPT-модели для маркировки последовательностей: инженерия стимулов и тонировка
 Исследуем, как наша работа использует стратегии инженерии стимулов и тонировки для адаптации моделей GPT-3.5 и GPT-4 для выявления компонентов похвалы.
Исследуем, как наша работа использует стратегии инженерии стимулов и тонировки для адаптации моделей GPT-3.5 и GPT-4 для выявления компонентов похвалы.
330. Как выбор токенизатора формирует скрытые риски в популярных языковых моделях
 Анализ модели выявляет уникальные не до конца обученные токены в GPT-2, NeoX и OLMo, которые формируются под влиянием данных обучения и выбора токенизатора.
Анализ модели выявляет уникальные не до конца обученные токены в GPT-2, NeoX и OLMo, которые формируются под влиянием данных обучения и выбора токенизатора.
331. Метавыборка LLM
 Метавыборка относится к процессу оценки справедливости, надежности и действительности протоколов оценки самих себя.
Метавыборка относится к процессу оценки справедливости, надежности и действительности протоколов оценки самих себя.
332. Навигация с использованием больших языковых моделей: формулирование проблемы и обзор
 В этой статье мы изучаем, как можно использовать «семантическую догадку», производимую языковыми моделями, в качестве руководящей онтологии для алгоритмов планирования.
В этой статье мы изучаем, как можно использовать «семантическую догадку», производимую языковыми моделями, в качестве руководящей онтологии для алгоритмов планирования.
333. Мульти-токеновая предсказание: повышенная эффективность выборки для больших языковых моделей
 Узнайте, как обучение LLM для предсказания нескольких будущих токенов одновременно повышает эффективность выборки и улучшает downstream возможности
Узнайте, как обучение LLM для предсказания нескольких будущих токенов одновременно повышает эффективность выборки и улучшает downstream возможности
334. Этот модель знает, какие сцены фильма имеют наибольшее значение
 Модель AI выявляет ключевые сцены в сценариях фильмов для создания точных резюме, сокращая длину, а также повышая ясность повествования.
Модель AI выявляет ключевые сцены в сценариях фильмов для создания точных резюме, сокращая длину, а также повышая ясность повествования.
335. Где происходит перевод в контексте в больших языковых моделях: Приложение
 В этой работе исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.
В этой работе исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.
336. «Нам нужно структурированный вывод»: к направлению на централизованные ограничения для вывода больших языковых моделей
 Мы заканчиваем дискуссией о предпочтениях и потребностях пользователей для формулирования намеченных ограничений для LLM
Мы заканчиваем дискуссией о предпочтениях и потребностях пользователей для формулирования намеченных ограничений для LLM
337. Персонализированные супы: выравнивание LLM посредством слияния параметров - связанные работы
 В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями посредством многоцелевой RL и слияния параметров.
В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями посредством многоцелевой RL и слияния параметров.
338. Как я построил персонального ассистента с использованием Google Cloud и Vertex AI: mAIdAI

Я понял, что мне нужно что-то другое. Не еще один обычный бот команды, а персональный ассистент AI — тот, который знает мой конкретный контекст, мои предпочитаемые сокращения
339. Исследователи обнаруживают прорыв в обучении AI с участием человека с помощью ICPL
 Обратите внимание на ICPL, новую подход, который использует большие языковые модели для повышения эффективности обучения по вознаграждению в обучении по подкреплению.
Обратите внимание на ICPL, новую подход, который использует большие языковые модели для повышения эффективности обучения по вознаграждению в обучении по подкреплению.
340. Опасность AI-генерированной информации
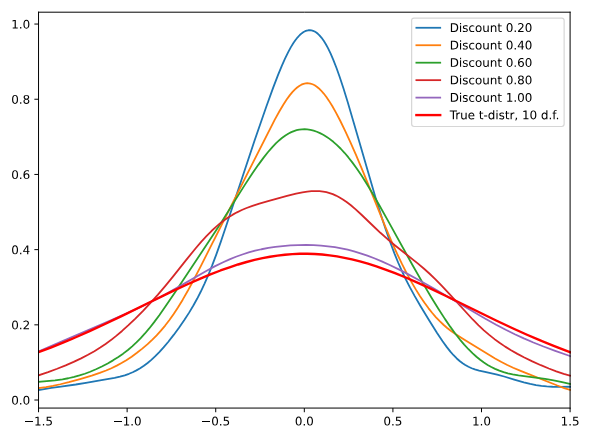 AI может снизить стоимость доступа к информации, но чрезмерная зависимость от AI-генерируемого содержания приводит к коллапсу знаний.
AI может снизить стоимость доступа к информации, но чрезмерная зависимость от AI-генерируемого содержания приводит к коллапсу знаний.
341. Атака с противником: вызов целостности моделей языка речи
 Обратите внимание, как атаки с противником, белые, черные и переносные, выявляют уязвимости в моделях языка речи и как наводнение шумом защищается от них.
Обратите внимание, как атаки с противником, белые, черные и переносные, выявляют уязвимости в моделях языка речи и как наводнение шумом защищается от них.
342. Большие языковые модели на устройствах с ограниченной памятью с помощью оптимизированной памяти Flash: оптимизированные данные в DRAM
 Успешно запускайте большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование памяти Flash, снижая передачу данных и повышая скорость передачи.
Успешно запускайте большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование памяти Flash, снижая передачу данных и повышая скорость передачи.
343. Рекомендации по кратким профилам пользователей из методологии текста отзывов
 Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные тексты отзывов.
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные тексты отзывов.
344. CLAIM: Модель языка контекста для точного импутации отсутствующих таблиц данных
 CLAIM использует LLM для заполнения отсутствующих таблиц данных с контекстным текстом, превосходя традиционные методы и повышая точность downstream-задач.
CLAIM использует LLM для заполнения отсутствующих таблиц данных с контекстным текстом, превосходя традиционные методы и повышая точность downstream-задач.
345. Безопасность, выравнивание и атаки на побег: вызов современным LLM
 345. Безопасная синхронизация и атака на побег из тюрьмы ставят под угрозу современные LLMs
345. Безопасная синхронизация и атака на побег из тюрьмы ставят под угрозу современные LLMs
 Исследуйте, как безопасная синхронизация и атака на побег из тюрьмы выявляют уязвимости в мультимодальных LLMs и моделях речи.
Исследуйте, как безопасная синхронизация и атака на побег из тюрьмы выявляют уязвимости в мультимодальных LLMs и моделях речи.
346. Роль человека в цикле предпочтений в обучении функции вознаграждения для humanoid- задач
 Исследуйте, как человеческие циклы предпочтений отточивают функции вознаграждения в задачах, таких как humanoid- бег и прыжки.
Исследуйте, как человеческие циклы предпочтений отточивают функции вознаграждения в задачах, таких как humanoid- бег и прыжки.
347. Реальные-world- случаи, требующие ограничений вывода
 Ниже мы обсуждаем ряд интересных выводов, которые возникли в результате нашего анализа случаев использования.
Ниже мы обсуждаем ряд интересных выводов, которые возникли в результате нашего анализа случаев использования.
348. FreeEval: Эффективные backend- инференс
 Эффективные backend- инференс FreeEval разработаны для эффективного обслуживания компьютерных требований больших масштабов LLM- оценок.
Эффективные backend- инференс FreeEval разработаны для эффективного обслуживания компьютерных требований больших масштабов LLM- оценок.
349. Метод «Сводка-Поиск» для длинного видео-опроса и ответа: связанные работы
 В этой статье исследователи изучают нулевую видео-опрос и ответ с помощью GPT-3, превосходя обученные модели, используя сводки и визуальное сопоставление.
В этой статье исследователи изучают нулевую видео-опрос и ответ с помощью GPT-3, превосходя обученные модели, используя сводки и визуальное сопоставление.
350. Улучшение генетического улучшения мутаций: признательности и ссылки
 Ссылки для интеграции больших языковых моделей (LLMs) в эксперименты по генетическому улучшению (GI).
Ссылки для интеграции больших языковых моделей (LLMs) в эксперименты по генетическому улучшению (GI).
351. Как LLMs изменили работу с компьютерами
 Почему LLMs так важны? Как LLMs являются игроками-изменителями? Можно ли общаться с компьютером на простом английском? Найдите все ответы в этой статье!
Почему LLMs так важны? Как LLMs являются игроками-изменителями? Можно ли общаться с компьютером на простом английском? Найдите все ответы в этой статье!
352.Рекомендации по кратким профилам пользователя из текста отзывов: Экспериментальные результаты
 Этот труд решает сложную и малоисследованную проблему поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные отзывы.
Этот труд решает сложную и малоисследованную проблему поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные отзывы.
353. Standard GI Mutations vs. LLM Edits в случайном выборе и локальном поиске
 Откройте результаты экспериментов, сравнивающих стандартные мутации Genetic Improvement с редактированием LLM в сценариях случайного выбора и локального поиска.
Откройте результаты экспериментов, сравнивающих стандартные мутации Genetic Improvement с редактированием LLM в сценариях случайного выбора и локального поиска.
354. Новый AI может рассказывать о вашем искусстве, как профессиональный критик
 Ученые из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
Ученые из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
355. Удовлетворяющий интерфейс и требования продукта и улучшение пользовательского опыта, доверия и принятия
 Удовлетворяющий интерфейс и требования продукта Отзывчики подчеркивают, что важно ограничить вывод LLM, чтобы соответствовать требованиям UI и продукта
Удовлетворяющий интерфейс и требования продукта Отзывчики подчеркивают, что важно ограничить вывод LLM, чтобы соответствовать требованиям UI и продукта
356. Использование LLМ для генерации необычных текстовых входных данных в мобильных приложениях для тестирования
 Использование InputBlaster, новой подхода к использованию LLМ для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
Использование InputBlaster, новой подхода к использованию LLМ для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
357. Этот новый AI-модель успешно понимает и взаимодействует с изображениями
 Ученые из университета Mohamed bin Zayed разработали AI-модель, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
Ученые из университета Mohamed bin Zayed разработали AI-модель, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
358. Использование Courier и GPT2 для генерации мотивационного цитата дня
 Учитесь использовать модель машинного обучения и модель Hugging Face для генерации цитаты на заказ с помощью Courier и GPT2
Учитесь использовать модель машинного обучения и модель Hugging Face для генерации цитаты на заказ с помощью Courier и GPT2
359. Communication Isn’t the Problem. Retrieval Is.
 Неудачи в управлении часто являются неудачами в извлечении: информация existed, но система не смогла surface ее правильному человеку в нужное время.
Неудачи в управлении часто являются неудачами в извлечении: информация existed, но система не смогла surface ее правильному человеку в нужное время.
360. FLock.io Partners With Alibaba Cloud On Advanced AI Model Co-Creation

361. Give Your AI Coding Assistant a Domain Expert Brain in 30 Seconds
 Бесплатная, открытое коллекция из 38 пакетов ролей AI для Claude Code, Cursor и VS Code.
Бесплатная, открытое коллекция из 38 пакетов ролей AI для Claude Code, Cursor и VS Code.
362. TnT-LLM for User Intent and Conversational Domain Labeling in Bing Copilot
 Мы оцениваем TnT-LLM на реальных чатах Bing Copilot для обнаружения намерений пользователя и маркировки домена разговора и детализации нашего образца данных.
Мы оцениваем TnT-LLM на реальных чатах Bing Copilot для обнаружения намерений пользователя и маркировки домена разговора и детализации нашего образца данных.
363. A Summarize-then-Search Method for Long Video Question Answering: Method
 В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие истории и визуальное сопоставление.
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие истории и визуальное сопоставление.
364. Improving NLQ Accuracy Over Enterprise Data Warehouses Through Contextual Metadata Enrichment
 Неудачи NLQ над предприятиями данных являются проблемой метаданных, а не проблемой модели. Практическая трехэтапная демонстрация с помощью Kiro-CLI и Redshift.
Неудачи NLQ над предприятиями данных являются проблемой метаданных, а не проблемой модели. Практическая трехэтапная демонстрация с помощью Kiro-CLI и Redshift.
365. When AI Rewrites the Internet, What Do We Lose?
 Содержание AI, созданное AI, влияет на распределение знаний, влияя на информационные каскады, эффекты сети и коллапс модели, что может привести к потенциальным предубеждениям и т. д.
Содержание AI, созданное AI, влияет на распределение знаний, влияя на информационные каскады, эффекты сети и коллапс модели, что может привести к потенциальным предубеждениям и т. д.
366. Leveraging LLMs для Генерации Необычных Текстовых Вводов в Мобильных Приложениях: Подход
 Использование InputBlaster, новая подход в использовании LLMs для автоматической генерации разнообразных текстовых вводов в тестировании мобильных приложений.
Использование InputBlaster, новая подход в использовании LLMs для автоматической генерации разнообразных текстовых вводов в тестировании мобильных приложений.
367. Если Вы Нравится DreamLLM, Проверьте Эти Работы
 Быстрые разработки были замечены в расширении LLMs, таких как LLaMA, на мультимодальную понимание, позволяющую человеческому взаимодействию с словами и визуальным содержанием.
Быстрые разработки были замечены в расширении LLMs, таких как LLaMA, на мультимодальную понимание, позволяющую человеческому взаимодействию с словами и визуальным содержанием.
368. Метод «Сводка-Поиск» для Долгих Видео Вопросов-Ответов: Примеры Вопросов
 В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.
369. Фон и Автоматические Методы Оценки LLMs
 В этой части мы предоставляем обзор текущей ландшафта методов оценки LLM и вызовы, вызванные загрязнением данных.
В этой части мы предоставляем обзор текущей ландшафта методов оценки LLM и вызовы, вызванные загрязнением данных.
370. Где Происходит Перевод в Контексте в Больших Моделях Языка: Резюме и Фон
 В этой работе исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.
В этой работе исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.
371. Большие Модели Языка на Устройствах с Ограниченной Памятью, Используя Флэш-Память: Улучшение Производительности
 Успешно запускать большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, снижая передачу данных и повышая производительность.
Успешно запускать большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, снижая передачу данных и повышая производительность.
372. Новый Модель AI: Как Он Может Изменить, Как Машины Описывают Изображения
 src="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-jp02tr0.jpeg"/>
Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
src="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-jp02tr0.jpeg"/>
Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
373. Использование AI в подготовке рукописей для академических журналов: методы
 В этом исследовании исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.
В этом исследовании исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.
374. Рекомендации по кратким профильным пользователям из текста отзывов: вывод
 Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.
375. Как AI узнает, как резюмировать фильмы, как человек
 Двухэтапная модель, которая выбирает ключевые сцены фильмов и суммирует сценарии более эффективно с помощью новой анонимированной сальянности человека.
Двухэтапная модель, которая выбирает ключевые сцены фильмов и суммирует сценарии более эффективно с помощью новой анонимированной сальянности человека.
376. NExT-GPT: Any-to-Any Multimodal LLM: Инструкции по набору данных
 В этом исследовании исследователи представляют собой конечный результат общего назначения системы any-to-any MM-LLM, называемую NExT-GPT.
В этом исследовании исследователи представляют собой конечный результат общего назначения системы any-to-any MM-LLM, называемую NExT-GPT.
377. Метод резюмирования и поиска для длинного видео вопроса-ответа: Резюме и Введение
 В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.
378. Рекомендации по кратким профильным пользователям из текста отзывов: экспериментальные результаты
 Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.
379. Персонализированные супы: выравнивание LLM посредством объединения параметров - персонализированный
 Этот труд исследует выравнивание LLM с помощью объединения параметров, персонализированного человеческого обратной связи, и его применение к персонализированным супам.
Этот труд исследует выравнивание LLM с помощью объединения параметров, персонализированного человеческого обратной связи, и его применение к персонализированным супам.
Человеческий Фидбэк
 Этот документ представляет RLPHF, который синхронизирует большие модели языка с персонализированными человеческими предпочтениями с помощью мультицелевой RL и слияния параметров.
Этот документ представляет RLPHF, который синхронизирует большие модели языка с персонализированными человеческими предпочтениями с помощью мультицелевой RL и слияния параметров.
380. Как мостить пропасть между спецификациями и агентами: навыки MLOps
 Несмотря на минимальное трение, навыки агента являются превосходным «низким висячим плодом» для любого инженерного коллектива.
Несмотря на минимальное трение, навыки агента являются превосходным «низким висячим плодом» для любого инженерного коллектива.
381. Как учить агентов по обучению с подкреплением человеческим предпочтениям?
 Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.
Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.
382. Хакинг обучения с подкреплением с помощью немного помощи от людей и LLM
 Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.
Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.
383. CulturaX: Качественный, многоязычный набор данных для LLM - анализ данных и эксперименты
 Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
384. Рекомендации по кратким профилам пользователей из текста отзывов: заявление о этике и ссылки
 Этот работа решает сложную и малоисследованную задачу поддержки пользователей, у которых есть очень редкие взаимодействия, но они пишут информативные тексты отзывов.
Этот работа решает сложную и малоисследованную задачу поддержки пользователей, у которых есть очень редкие взаимодействия, но они пишут информативные тексты отзывов.
385. Улучшение мутаций генетического улучшения с помощью больших моделей языка
 Откройте инновационное применение больших моделей языка (LLM) в генетическом улучшении (GI) для задач инженерии программного обеспечения.
Откройте инновационное применение больших моделей языка (LLM) в генетическом улучшении (GI) для задач инженерии программного обеспечения.
386. Как выразить ограничения вывода для LLM
 Изучите, как выразить ограничения вывода для LLM и как это может помочь в различных задачах.
Изучите, как выразить ограничения вывода для LLM и как это может помочь в различных задачах.
387. Обучение с подкреплением для человеческих ценностей
 Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и как это может помочь в различных задачах.
Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и как это может помочь в различных задачах.
388. Человеческие ценности в обучении с подкреплением
 Изучите, как человеческие ценности могут быть интегрированы в обучение с подкреплением и как это может помочь в различных задачах.
Изучите, как человеческие ценности могут быть интегрированы в обучение с подкреплением и как это может помочь в различных задачах.
389. Обучение с подкреплением для человеческих ценностей и AI
 Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и AI и как это может помочь в различных задачах.
Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и AI и как это может помочь в различных задачах.
Выходные ограничения в LLMS
 Обобщая наблюдение, респонденты предпочли использовать GUI для указания низкоуровневых ограничений и естественный язык для выражения высокоуровневых ограничений.
Обобщая наблюдение, респонденты предпочли использовать GUI для указания низкоуровневых ограничений и естественный язык для выражения высокоуровневых ограничений.
387. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: исследование и фон
 Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
388. CulturaX: Качественный, многоязычный набор данных для LLM - связанные работы
 Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.
389. Большие языковые модели на устройствах с ограниченной памятью с использованием флэш-памяти: результаты для модели Falcon 7B
 Эффективное выполнение больших языковых моделей на устройствах с ограниченной памятью путем оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.
Эффективное выполнение больших языковых моделей на устройствах с ограниченной памятью путем оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.
390. Мульти-токен prediction: производительность scales с размером LLM
 Открытие того, как обучение больших языковых моделей с мульти-токен prediction существенно повышает производительность для более крупных размеров модели
Открытие того, как обучение больших языковых моделей с мульти-токен prediction существенно повышает производительность для более крупных размеров модели
391. Дело NL: более интуитивное и выразительное для сложных ограничений
 Респонденты нашли естественный язык более удобным для указания сложных ограничений, чем GUI
Респонденты нашли естественный язык более удобным для указания сложных ограничений, чем GUI
392. Атаки по передаче выявляют уязвимости SLM и эффективные защитные меры от шума
 Перекрестные модели атак выявляют слабости SLM, а защитные меры на основе шума существенно снижают риски взлома с минимальным воздействием на производительность.
Перекрестные модели атак выявляют слабости SLM, а защитные меры на основе шума существенно снижают риски взлома с минимальным воздействием на производительность.
393. Personalizovannye Borshchi: LMG Soglasovanie Via Parametra Merging - Eksperimenty
 Этот-paper-vvedët RLPHF, kotoryj soglasovayet bol'shie modeli jazyka s personalizirovannymi chelovecheskimi preferenciyami via multi-objective RL i parametra merging.
Этот-paper-vvedët RLPHF, kotoryj soglasovayet bol'shie modeli jazyka s personalizirovannymi chelovecheskimi preferenciyami via multi-objective RL i parametra merging.
394. Bezopasnyj Ocenka: Arhitektura Peredstavitel'stvo i Razrabotka Modul'nogo Proektirovaniya
 Arhitektura FreeEval vkljuchayet modul'noe proektirovaniye, kotorye mozhet byit' razdeleno na Ocenka Metodi, Meta-Ocenka i LLM Inference Backends.
Arhitektura FreeEval vkljuchayet modul'noe proektirovaniye, kotorye mozhet byit' razdeleno na Ocenka Metodi, Meta-Ocenka i LLM Inference Backends.
395. Konstruktivnyj Proekt i Razrabotka Bezopasnoj Ocenki
 V etot section, my predstavlyayem konstruktivnyj proekt i razrabotku FreeEval, my diskutiruyem arkhittekturu frameworka i ego kljuchie komponenty
V etot section, my predstavlyayem konstruktivnyj proekt i razrabotku FreeEval, my diskutiruyem arkhittekturu frameworka i ego kljuchie komponenty
396. Usilenie Kachestva Dannih: Kak Nizkoe Kachestvo Dannih Vliyayet na Rabotu Kollektivnogo Trenirovaniya
 V etot issledovaniye, uchënye predlozhayut kontrol' kachestva dannyh dlya federativnogo dokhodnogo obucheniya osnovnyh modeli.
V etot issledovaniye, uchënye predlozhayut kontrol' kachestva dannyh dlya federativnogo dokhodnogo obucheniya osnovnyh modeli.
397. Intellektual'nye Konsul'tacii: Uchenie Ai Vybirat'Kljuchie Sceny Iz Skriptov
 Novyj metod summarirovaniya vybirayet kriticheskie sceny v bol'shej skorost' i effektivnee skript-to-summary generirovaniye s pomoshch'ju AI.
Novyj metod summarirovaniya vybirayet kriticheskie sceny v bol'shej skorost' i effektivnee skript-to-summary generirovaniye s pomoshch'ju AI.
398. Kak Bezopasnoj Ocenka Vkljuchayet Raznoobrazie Metaocenka Modulej
 Bezopasnoj Ocenka prioritiziruet dostovernost' i spravedlivost' v ocenkah, vkljuchayya raznoobrazie metaocenka modulej, kotorye validiruyut rezul'taty ocenki
Bezopasnoj Ocenka prioritiziruet dostovernost' i spravedlivost' v ocenkah, vkljuchayya raznoobrazie metaocenka modulej, kotorye validiruyut rezul'taty ocenki
399. Hakernoon Novostnaya Pechat': Upravlenie Stressom Mozhet Byt' Mnogo-Luchshej, Chem Vy Dumayte, 12/17/2024
 12/17/2024: Top 5 starij na glavnoj stranitsy Hakernoon.
12/17/2024: Top 5 starij na glavnoj stranitsy Hakernoon.
400. Usilenie Kachestva Dannih: Zakljuchenie i Budushhie Raboty i Svyazannye Referencii
400. Улучшение качества данных: выводы и будущая работа, и ссылки
 В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
401. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: результаты и анализ
 Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
402. Самый быстрый способ прототипировать агентов: объявите «что», позволив ADK выполнить «как»
 Ускорьте развитие AI с помощью Ackgent, декларативного набора стартовых материалов, используя Google ADK Agent Config для создания агентов через YAML, а не шаблонов.
Ускорьте развитие AI с помощью Ackgent, декларативного набора стартовых материалов, используя Google ADK Agent Config для создания агентов через YAML, а не шаблонов.
403. Новый набор данных AI продвигает границы, решая проблемы этики и точности
 Исследователи в Университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.
Исследователи в Университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.
404. Быстрая гонка в стремлении к идеальному LLM
 Большая техника движется вперед в развитии LLM. Около десяти лет после введения виртуальных ассистентов, таких как Siri и Alexa, появилась новая волна AI-ассистентов.
Большая техника движется вперед в развитии LLM. Около десяти лет после введения виртуальных ассистентов, таких как Siri и Alexa, появилась новая волна AI-ассистентов.
405. Улучшение качества данных: исследование удаления единого счета с данными Anchor
 В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
406. У вашего AI есть любимое мнение – и это не ваше
 Большие языковые модели наследуют предубеждения из обучающих данных, сталкиваются с длинным хвостом знаний и предпочитают основные точки зрения.
Большие языковые модели наследуют предубеждения из обучающих данных, сталкиваются с длинным хвостом знаний и предпочитают основные точки зрения.
407. Трекинг функции вознаграждения: улучшение с помощью прокси человеческих предпочтений в ICPL
 Исследуйте, как Инконтекстная Учеба Предпочтений (ICPL) прогрессивно дорабатывала функции вознаграждения в задачах гуманоидов с помощью прокси человеческих предпочтений.
Исследуйте, как Инконтекстная Учеба Предпочтений (ICPL) прогрессивно дорабатывала функции вознаграждения в задачах гуманоидов с помощью прокси человеческих предпочтений.
408. Кросс-атаки на команды и удаление данных: влияние на устойчивость SLM
 Изучите, как кросс-атаки на команды, удаление данных и случайный шум влияют на устойчивость, полезность и безопасность речевых языковых моделей.
Изучите, как кросс-атаки на команды, удаление данных и случайный шум влияют на устойчивость, полезность и безопасность речевых языковых моделей.
409. Newsletter HackerNoon: Swift: Мастер декодирования грязного JSON (2/26/2026)
 2/26/2026: Топ 5 историй на главной странице HackerNoon!
2/26/2026: Топ 5 историй на главной странице HackerNoon!
410. Не только компилятор: что делает кодогенерацию AI такой особенной?
 Забудьте старую лестницу абстракции! Объясните, как LLM-ассистированное программирование — это новый вид инструментов, позволяющих разработчикам "телепортиться" на произвольные уровни
Забудьте старую лестницу абстракции! Объясните, как LLM-ассистированное программирование — это новый вид инструментов, позволяющих разработчикам "телепортиться" на произвольные уровни
411. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: выводы и ссылки

412. NExT-GPT: любое к любому мультимодальное LLM: выводы и ссылки
 В этом исследовании исследователи представляют собой конечный результат общего назначения любое к любому MM-LLM-системы под названием NExT-GPT.
В этом исследовании исследователи представляют собой конечный результат общего назначения любое к любому MM-LLM-системы под названием NExT-GPT.
413. Большие языковые модели на устройствах с ограниченной памятью с помощью флэш-памяти: флэш-память и LLM-инференсия
 Успешно запускайте большие языковые модели на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, уменьшая передачу данных и повышая скорость передачи данных.
Успешно запускайте большие языковые модели на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, уменьшая передачу данных и повышая скорость передачи данных.
414. A Summarize-then-Search Method for Long Video Question Answering: Limitations & References
 В этой статье исследователи изучают нулевую выучку видео QA с помощью GPT-3, превосходя обученные модели, используя нARRATIVE-сводки и визуальное сопоставление.
В этой статье исследователи изучают нулевую выучку видео QA с помощью GPT-3, превосходя обученные модели, используя нARRATIVE-сводки и визуальное сопоставление.
415. FOD 37: Can We Genuinely Trust LLMs?
 Froth on the Daydream (FOD) – еженедельный обзор новостей AI, соединяющий точки в эволюции AI. Информация о безопасности AI, инклюзивности, эффективности и человеческом центре.
Froth on the Daydream (FOD) – еженедельный обзор новостей AI, соединяющий точки в эволюции AI. Информация о безопасности AI, инклюзивности, эффективности и человеческом центре.
416. Researchers Just Built a Plug-and-Play Brain for LLMs
 С помощью плагин-и-играй модели Q★ улучшает рассуждения LLM и достигает передовых результатов в кодировании и математической точности без необходимости фильтрации.
С помощью плагин-и-играй модели Q★ улучшает рассуждения LLM и достигает передовых результатов в кодировании и математической точности без необходимости фильтрации.
417. Teaching LLMs How to “Think Twice”
 Q* объединяет A* поисковую систему с LLM, чтобы повысить многошаговое рассуждение, уменьшить галлюцинации и позволить более умному AI-размышлению.
Q* объединяет A* поисковую систему с LLM, чтобы повысить многошаговое рассуждение, уменьшить галлюцинации и позволить более умному AI-размышлению.
418. It's Not Just What's Missing, It's How You Say It: CLAIM's Winning Formula
 Эксперименты показывают, что CLAIM превосходит базовые модели, такие как k-NN и MICE, по всем шаблонам отсутствия, а контекстно-специфические описатели оказываются наиболее эффективными.
Эксперименты показывают, что CLAIM превосходит базовые модели, такие как k-NN и MICE, по всем шаблонам отсутствия, а контекстно-специфические описатели оказываются наиболее эффективными.
419. AI Use in Manuscript Preparation for Academic Journals: References
 В этой статье исследователи изучают, считают ли ученые необходимым отчет об использовании AI в подготовке рукописей.
В этой статье исследователи изучают, считают ли ученые необходимым отчет об использовании AI в подготовке рукописей.
420. Researchers Develop Groundbreaking Method to Teach AI to 'Understand' Images Like Never Before
 Исследователи из Мохаммеда бин Зайеда разрабатывают AI-модель, которая может создавать текстовые разговоры, связанные с конкретными изображениями.
Исследователи из Мохаммеда бин Зайеда разрабатывают AI-модель, которая может создавать текстовые разговоры, связанные с конкретными изображениями.
Объекты или области в изображении.
421. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Conclusion, Acknowledgment и References
 В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.
422. Сможет ли новая LLM Meta usher в новую волну конкуренции?
 Приготовьтесь; революция в области ИИ не только приближается, но уже меняет правила игры.
Приготовьтесь; революция в области ИИ не только приближается, но уже меняет правила игры.
423. Перевод сценариев фильмов в краткие обзоры — умнее и быстрее
 Автоматически суммируйте сценарии фильмов, выбирая только самые актуальные сцены, используя человечески-аннотированный набор данных.
Автоматически суммируйте сценарии фильмов, выбирая только самые актуальные сцены, используя человечески-аннотированный набор данных.
424. Как мы развернули онлайн-опрос среди пользователей внутренней платформы прототипирования на основе запросов
 Чтобы получить широкий спектр сведений от людей, имеющих опыт с запросами и созданием приложений на основе LLM, мы развернули онлайн-опрос среди пользователей.
Чтобы получить широкий спектр сведений от людей, имеющих опыт с запросами и созданием приложений на основе LLM, мы развернули онлайн-опрос среди пользователей.
425. Использование LLM для генерации необычных текстовых входных данных в тестировании мобильных приложений: обсуждение и действенность
 Используя InputBlaster, новую подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
Используя InputBlaster, новую подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.
426. LLM: без человеческого ума, будет ли работать регулирование ИИ?
 Что именно в человеческом уме представляет собой интеллект, ИИ скопировал? Как работает человеческий ум, позволяя внешним факторам влиять на него?
Что именно в человеческом уме представляет собой интеллект, ИИ скопировал? Как работает человеческий ум, позволяя внешним факторам влиять на него?
427. Как ICPL решает основную проблему дизайна вознаграждения RL
 ICPL интегрирует LLM с человеческими предпочтениями для итеративного синтеза функций вознаграждения, предлагая эффективный, обратно-определяемый подход к дизайну вознаграждений RL.
ICPL интегрирует LLM с человеческими предпочтениями для итеративного синтеза функций вознаграждения, предлагая эффективный, обратно-определяемый подход к дизайну вознаграждений RL.
428. Большие модели языка на устройствах с ограниченной памятью DRAM с помощью flash-памяти: снижение передачи данных
 Эффективно запускайте большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, снижая передачу данных и повышая скорость передачи данных.
Эффективно запускайте большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, снижая передачу данных и повышая скорость передачи данных.
429. Кто такой Гарри Поттер? Approximate Unlearning в LLM: методология оценки
 В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторного обучения с нуля.
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторного обучения с нуля.
430. Tree-Diffusion: Новый подход к кодогенерации с помощью нейронных моделей диффузии
 В этой статье представлен Tree-Diffusion, новая методика кодогенерации, использующая нейронные модели диффузии на синтаксических деревьях.
В этой статье представлен Tree-Diffusion, новая методика кодогенерации, использующая нейронные модели диффузии на синтаксических деревьях.
431. SLMs превосходят конкурентов, но страдают от быстрых атак с враждебным поведением
 Результаты показывают, что наши SLM превосходят публичные модели по безопасности и актуальности, но остаются высоко уязвимыми для быстрых атак с враждебным поведением.
Результаты показывают, что наши SLM превосходят публичные модели по безопасности и актуальности, но остаются высоко уязвимыми для быстрых атак с враждебным поведением.
432. Предварительное обучение и оценка аудио-кодировщика повышают безопасность SLM
 Откройте наши подробности предобучения 24-слойного конфигуратора и методы оценки с помощью Claude 2.1 для обеспечения безопасности, актуальности и полезности в SLM.
Откройте наши подробности предобучения 24-слойного конфигуратора и методы оценки с помощью Claude 2.1 для обеспечения безопасности, актуальности и полезности в SLM.
433. Исследователи из ОАЭ раскрыли секреты, как их AI понимает изображения в деталях
 Исследователи в университете Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые диалоги, связанные с конкретными объектами или регионами в изображении.
Исследователи в университете Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые диалоги, связанные с конкретными объектами или регионами в изображении.
434. Conclusion: GPT Models for Automated Explanatory Feedback
 Мы заключаем нашу исследование по улучшению систем автоматического обратной связи с помощью моделей GPT, демонстрируя эффективность подачи сигналов и тонировки для обучения преподавателей.
Мы заключаем нашу исследование по улучшению систем автоматического обратной связи с помощью моделей GPT, демонстрируя эффективность подачи сигналов и тонировки для обучения преподавателей.
435. Where does In-context Translation Happen in Large Language Models: Data and Settings
 В этом исследовании исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.
В этом исследовании исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.
436. Large Language Models on Memory-Constrained Devices Using Flash Memory: Related Works
 Успешно запускать большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование флэш-памяти, снижая передачу данных и повышая скорость передачи.
Успешно запускать большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование флэш-памяти, снижая передачу данных и повышая скорость передачи.
437. Discussing GPT Models for Automated Explanatory Feedback in Tutor Training
 Наша дискуссия охватывает роль GPT в доставке автоматизированной объяснительной обратной связи для преподавателей, сравнивая подходы подачи сигналов и тонировки.
Наша дискуссия охватывает роль GPT в доставке автоматизированной объяснительной обратной связи для преподавателей, сравнивая подходы подачи сигналов и тонировки.
438. The HackerNoon Newsletter: AI Knows Best—But Only If You Agree With It (2/18/2025)
 2/18/2025: Топ-5 историй на главной странице HackerNoon!
2/18/2025: Топ-5 историй на главной странице HackerNoon!
439. You.com: A Glimpse into the Future of AI and Search Innovation
 You.com демонстрирует современное состояние AI.
You.com демонстрирует современное состояние AI.
440. A New Chapter In Coding: How AI Is Profoundly Changing Programmer Practices
 Этот вывод исследует глубокое воздействие AI-ассистированного программирования, показывая, что это не просто новая функция, а фундаментальный сдвиг.
Этот вывод исследует глубокое воздействие AI-ассистированного программирования, показывая, что это не просто новая функция, а фундаментальный сдвиг.
441. NExT-GPT: Any-to-Any Multimodal LLM: Any-to-any Multimodal Generation
 В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-системы под названием NExT-GPT.
В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-системы под названием NExT-GPT.
442. Использование AI в подготовке рукописей для академических журналов: Резюме и Введение
 В этой работе исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.
В этой работе исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.
443. Метод «Сводка, а затем поиск» для экспериментов по ответам на длинные видео-вопросы
 В этой статье исследователи исследуют нулевую задачу видео QA с помощью GPT-3, превосходя обученные модели, используя краткие сводки и визуальное сопоставление.
В этой статье исследователи исследуют нулевую задачу видео QA с помощью GPT-3, превосходя обученные модели, используя краткие сводки и визуальное сопоставление.
444. Улучшение качества данных в федеративной фильтрации основанных моделей: Эксперименты
 В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративной фильтрации основанных моделей.
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративной фильтрации основанных моделей.
445. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Приложение
 В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторной тренировки с нуля.
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторной тренировки с нуля.
446. Адверсарий и случайный шум выявляют уязвимости речевых LLM
 Узнайте, как точные параметры атаки и базовые шумы тестирования и выявления безопасности выявляют уязвимости речевых языковых моделей.
Узнайте, как точные параметры атаки и базовые шумы тестирования и выявления безопасности выявляют уязвимости речевых языковых моделей.
447. Сборки данных и оценка определяют устойчивость речевых языковых моделей
 Изучите, как отобранные ASR и TTS-данные и строгая оценка определяют устойчивость речевых языковых моделей.
Изучите, как отобранные ASR и TTS-данные и строгая оценка определяют устойчивость речевых языковых моделей.
Метрики оценивают безопасность и полезность многомодальных моделей речи и языка.
448. NExT-GPT: Any-to-Any Multimodal LLM: Related Work
 В этом исследовании исследователи представляют собой конечный результат общего назначения многомодального системы Any-to-Any MM-LLM, называемой NExT-GPT.
В этом исследовании исследователи представляют собой конечный результат общего назначения многомодального системы Any-to-Any MM-LLM, называемой NExT-GPT.
449. AI Use in Manuscript Preparation for Academic Journals: Results
 В этом исследовании исследователи исследуют, считают ли ученые необходимым сообщать о использовании AI в подготовке рукописей.
В этом исследовании исследователи исследуют, считают ли ученые необходимым сообщать о использовании AI в подготовке рукописей.
450. It's Not Your AI Partner: The Superficial Analogy Of Pair Programming
 Изучите уникальный опыт одного программиста с помощью AI-ассистента. Обсудите, как один человек легко переключается между ролями "водителя" и "навигатора".
Изучите уникальный опыт одного программиста с помощью AI-ассистента. Обсудите, как один человек легко переключается между ролями "водителя" и "навигатора".
451. What’s Next for AI in Regulated Social Media?
 Откройте AI-управляемую многоагентную симуляционную рамку, иллюстрирующую, как язык развивается творчески под социальными медиа-регуляторами, и изучите будущие направления.
Откройте AI-управляемую многоагентную симуляционную рамку, иллюстрирующую, как язык развивается творчески под социальными медиа-регуляторами, и изучите будущие направления.
452. Large Language Models on Memory-Constrained Devices Using Flash Memory: Results for OPT 6.7B Model
 Ускорьте работу больших моделей языка на устройствах с ограниченной памятью DRAM, оптимизировав использование флеш-памяти, уменьшив передачу данных и повышая скорость передачи данных.
Ускорьте работу больших моделей языка на устройствах с ограниченной памятью DRAM, оптимизировав использование флеш-памяти, уменьшив передачу данных и повышая скорость передачи данных.
453. The Real Cost of the ADHD Generalist Life
 Что 17 лет гиперфокуса ADHD taught меня о хобби, карьере, идентичности и почему некоторые интересы действительно прилипают.
Что 17 лет гиперфокуса ADHD taught меня о хобби, карьере, идентичности и почему некоторые интересы действительно прилипают.
454. The LLM Hype Train: You Should Know the Truth
 Что если я скажу вам, что ChatGPT — это конец программного обеспечения? Вы верите? Три года назад OpenAI изменил игру в области AI с помощью ChatGPT.
Что если я скажу вам, что ChatGPT — это конец программного обеспечения? Вы верите? Три года назад OpenAI изменил игру в области AI с помощью ChatGPT.
455. Исследователи ОАЭ раскрыли секреты за работой AI, которая действительно понимает изображения
 Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
456. Как мы интегрировали downstream-процессы и потоки
 Это предполагает, что может быть более выгодно для моделей принимать ограничения вывода, независимо от входного запроса.
Это предполагает, что может быть более выгодно для моделей принимать ограничения вывода, независимо от входного запроса.
457. Мир, война и искусственный интеллект
 С появлением AI и стремлением к более высокой автономии для вооружений, мы должны задаться вопросом, какие намерения человечество будет отправлять на ракеты в другие звезды?
С появлением AI и стремлением к более высокой автономии для вооружений, мы должны задаться вопросом, какие намерения человечество будет отправлять на ракеты в другие звезды?
458. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: загрузка из флеш-памяти
 Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
459. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: скорость чтения
 Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
460. Строение на гигантах: взгляд на исследования, которые сформировали эту статью
 Этот обширный список ссылок охватывает академический контекст нашей работы, от фундаментальных исследований в области синтеза программ и HCI до современных тем, связанных с AI.
Этот обширный список ссылок охватывает академический контекст нашей работы, от фундаментальных исследований в области синтеза программ и HCI до современных тем, связанных с AI.
461. Улучшение качества данных в федеративном тонировании основанных моделей: связанные работы
 В
В
Этот исследование, исследователи предлагают контрольную линию качества данных для федеративного тонирования основанных моделей.
462. MegaTrain Makes 100B Model Training Possible on One GPU
 Это краткое изложение на простом языке статьи под названием MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU…
Это краткое изложение на простом языке статьи под названием MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU…
463. Enhancing Data Quality: Examples for Low-and High-quality Data
 В этом исследовании, исследователи предлагают контрольную линию качества данных для федеративного тонирования основанных моделей.
В этом исследовании, исследователи предлагают контрольную линию качества данных для федеративного тонирования основанных моделей.
464. Optimizing Genetic Improvement with GPT 3.5 Turbo
 В этом исследовании исследователи используют GPT 3.5 Turbo и Gin-инструментарий для экспериментов по генетическому улучшению.
В этом исследовании исследователи используют GPT 3.5 Turbo и Gin-инструментарий для экспериментов по генетическому улучшению.
465. NExT-GPT: Any-to-Any Multimodal LLM: Overall Architecture
 В этом исследовании исследователи представляют собой конечный результат общего назначения системы любого к любому MM-LLM под названием NExT-GPT.
В этом исследовании исследователи представляют собой конечный результат общего назначения системы любого к любому MM-LLM под названием NExT-GPT.
466. Is It Search Or Is It AI? The Real Differences In How Programmers Get Help
 Этот раздел разбирает, как LLM-ассистированное программирование больше, чем просто более умный поиск. Подчеркивая ключевые различия
Этот раздел разбирает, как LLM-ассистированное программирование больше, чем просто более умный поиск. Подчеркивая ключевые различия
467. The Architecture Behind Smarter AI Agents
 Современные агенты AI достигают успеха через архитектуру, а не просто масштаб. В этой статье картографируются системы, которые расширяют возможности модели.
Современные агенты AI достигают успеха через архитектуру, а не просто масштаб. В этой статье картографируются системы, которые расширяют возможности модели.
468. SaaS-pocalypse Part 3: Which SaaS Moats Survive AI?
 AI быстро меняет SaaS-моаты. Смотрите, какие из 7 сил Хельмера эродируются, укрепляются или сдвигаются в эпоху AI.
AI быстро меняет SaaS-моаты. Смотрите, какие из 7 сил Хельмера эродируются, укрепляются или сдвигаются в эпоху AI.
469. AI Use in Manuscript Preparation for Academic Journals:Дискуссия
 В этом исследовании исследователи исследуют, считают ли академики необходимым отчитываться о использовании AI в подготовке рукописей.
В этом исследовании исследователи исследуют, считают ли академики необходимым отчитываться о использовании AI в подготовке рукописей.
470. Этот новый AI может видеть, говорить и даже редактировать изображения в одном разговоре
 Исследователи из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами изображения.
Исследователи из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами изображения.
471. Улучшение качества данных в федеративном тонировании основанных моделей: настройки гетерогенности
 В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.
472. Как расширить выражительность AI-агентов: построение с помощью A2UI
 Это обещание A2UI (Agent-to-User Interface): протокол, который позволяет агентам «говорить» UI по-родному.
Это обещание A2UI (Agent-to-User Interface): протокол, который позволяет агентам «говорить» UI по-родному.
473. NExT-GPT: Any-to-Any Multimodal LLM: Lightweight Multimodal Alignment Learning
 В этом исследовании исследователи представляют собой конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечsrc="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-8402o6q.jpeg"/>
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
В этом исследовании исследователи представляют собой конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечsrc="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-8402o6q.jpeg"/>
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
477. Улучшение качества данных в федеративном тонком настройке основанных моделей: Резюме и Введение
 В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
478. Улучшение качества данных в федеративном тонком настройке основанных моделей: Экспериментальные подробности
 В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей.
479. Безграничный TTS: Решение проблемы голодания контекста
 Это краткое изложение научной статьи под названием "Безграничная синтез речи" [https://www.aimodels.fyi/papers/arxiv/borderless-long-spe…
Это краткое изложение научной статьи под названием "Безграничная синтез речи" [https://www.aimodels.fyi/papers/arxiv/borderless-long-spe…
Спасибо за просмотр 479 самых читаемых статей о Больших Моделях Языка на HackerNoon.
Посетите репозиторий /Learn для поиска самых читаемых статей о любой технологии.
← предыдущая
Безопасность смарт-контрактов сложна, но того стоит
следующая →
Принцип наименьшего ИИ: баланс инноваций и безопасности в эпоху искусственного интеллекта
комментарии · 0
// чтобы оставить комментарий — войдите в систему или зарегистрируйтесь
╔═ GL1TCH v0.1 ═[ПОДКЛЮЧЕНО]═╗
[×]
СОЕДИНЕНИЕ АКТИВНО
запросов:
// сессия #{} начата
>_
[ РАЗРЫВ СВЯЗИ ]
лимит исчерпан...
иду спать... zzZ
хочешь больше?
[зарегистрироваться]
// +10 запросов в день

3D-LLM - это новая модель, которая соединяет язык и наш 3D-мир.
37. Оценка TnT-LLM по текстовой классификации: человеческое согласие и масштабируемые метрики LLM
Мы оцениваем текстовую классификацию TnT-LLM с помощью человеческого согласия и масштабируемых метрик LLM для точности и производительности на больших масштабах.
38. Я был готов вернуть DGX Spark. Затем обновление NVIDIA в январе изменило все.
Я почти вернул $4,000 DGX Spark. Затем NVIDIA выпустила 30 наборов, 2,5-кратное увеличение производительности и гибридную маршрутизацию.
39. Может ли быть остановлено галлюцинации AI? Просмотр трех способов сделать это.
Обследование трех методов, чтобы остановить LLM от галлюцинаций: Retrieval-augmented generation (RAG), рассуждения и итеративное запросы.
40. TnT-LLM: Представление шаблонов запросов
В этой части мы представляем шаблоны запросов, которые использовались для суммирования разговора, присвоения меток и генерации, обновления и проверки таксономии.
41. AI для управления знаниями: Итерация RAG с архитектурой QE-RAG
Мы итерируем популярную архитектуру LLM, чтобы построить более эффективную систему AI для управления знаниями.
42. Сделать LLM эффективными: Сокращение использования памяти без нарушения качества
Оптимальные компромиссы между памятью и качеством для эффективных языковых моделей.
43. Примечание к большой языковой модели LLM: оптимизация инференции 1. Фон и формулировка проблемы
Обзор большая языковая модель (LLM) инференса, его важность, проблемы и ключевая Problem Formulation.
44. Что такое LlamaIndex? Общая эксплуатация LLM-оркестрационных Frameworks
В этой статье мы объясним, как LlamaIndex можно использовать в качестве Framework для интеграции данных, организации данных и извлечения данных для приватных данных Gen AI требует.
45. Текущее состояние GPT4All
Сегодня GPT4All фокусируется на улучшении доступности открытых языковых моделей.
46. Подробный обзор, как работает AI-детекторы
Интересно узнать, как работает AI-детекторы? Ну, вы в luck. Я постараюсь объяснить это как можно проще, чтобы любой мог понять.
47. Масштабирующие законы в большую языковую модель
Изучите масштабирующие законы в AI, которые показывают, как модельная производительность улучшается с увеличением модели, данных и вычислительной мощности.
48. Embeddings для RAG - Общая обзор
Embedding является важным и фундаментальным шагом в построении Retrieval Augmented Generation (RAG) pipeline. BERT & SBERT являются state-of-the-art embedding модели.
49. Основные AI-инструменты для разработчиков в 2023 году: 20 рекомендованных решений
В этой статье мы рассмотрим несколько AI-поддерживающих инструментов, которые готовы революционизировать разработку и сделать жизнь разработчиков легче в 2023 году.
50. TnT-LLM: Автоматизация текстовой таксономии и классификации с помощью большую языковую модель
Этот документ представляет собой TnT-LLM, фреймворк, использующий LLM для автоматизации масштабной аналитики текста, включая автоматическую генерацию меток и эффективные классификаторы.
51. MCP Умер. CLI Побеждает в Стеке Агентов AI
Почему разработчики бросают пышные протоколы агентов и обращаются к CLI как к наиболее практичной основе для создания агентов AI в 2026 году.
52. AI Не Заменила Меня Ещё, Но Она Может Покажать, Что Я Никогда Не Был Такой Оригинальный
AI не заменит меня еще, но она может показать, что я никогда не был таким оригинальным. Витийная, тревожная статья о формализованном письме в эпоху больших языковых моделей.
53. Путеводитель Начинающего: Большие Языковые Модели (LLMOps) в 2023 году: Всё бесплатно!
Этот гид не просто сборник ресурсов LLM; это отобранная поездка по наиболее ценным навыкам в индустрии.
54. Разблокировка Мощных Использований: Как Мультиагентные LLM Изменяют Системы AI
Исследование внедрения подходов «человек в цикле» (HITL) в мультиагентных системах AI для разблокировки полного потенциала LLM.
55. Рассказ о Двух LLM: Открытые Источники vs Эксперименты Вооруженных Сил США по LLM
Эта статья исследует безопасность открытых источников LLM-проектов и эксперименты Вооруженных Сил США по LLM, известные в мире AI.
56. Как Общаться с Файлами PDF Используя Компьютерное Зрение и Открытые Языковые Модели
Учебник по созданию чат-бота с помощью открытых языковых моделей.
57. Пределы Коавторства с ChatGPT
ChatGPT — полезный инструмент для исследования творческой писанины, но она также имеет свои границы.ограничения. Алгоритм имеет определенные ограничения, но он все равно интересен к использованию
58. Мanners Matter? - Влияние доброты на взаимодействие человека с LLM
Исследование влияния доброты на результаты взаимодействия человека с LLM
59. Эксперты остаются разделенными по вопросу эффективности ChatGPT, несмотря на заявления о готовности к массовому внедрению
Этот текст обсуждает гип в вокруг ChatGPT, языкового модели, разработанного OpenAI, и утверждает, что, несмотря на его способность генерировать текст, подобный человеческому, он ограничен
60. Neuralная сеть Transformer (TNN) намного больше, чем даже AGI
Нам только что стало ясно, как работают LLM внутренне - легкое, научное предположение. Но это имеет огромные последствия для отрасли AI и, в самом деле, для мира!
61. Рекомендации разработчика OpenAI по использованию GPT и ChatGPT
Логан Килпатрик работает в OpenAI в области разработчиков. Он делится своими мыслями о больших языковых моделях, ChatGPT и ландшафте разработчиков OpenAI.
62. Разработка архитектуры с триллионными параметрами на потребительском оборудовании
Глубокое рассмотрение того, как один исследователь обучил модель с триллионными параметрами на ноутбуке RTX 4080, доказав демократизацию LLM
63. Как достичь 1000x скорости LLM для эффективного и экономически выгодного обучения, тестирования и развертывания
Вы когда-нибудь задумывались, как ускорить обучение LLM? Ну, - не беспокойтесь - Мы представляем простой, но гениальный метод ускорения LLMOps.
64. 7 основных библиотек AI-инженеринга для замены шаблонов
Замените custom LLM-обёртки на 7 производственных протестированных библиотек Python. Обсуждается LiteLLM, Instructor, FastMCP, PydanticAI, tiktoken и другие с примерами кода.
65. AIs Will Be Dangerous Because Unbounded Optimizing Power Leads to Existential Risk
Серьёзные опасения экспертов по поводу будущего мощного AI. Информация, не освещённая в общем СМИ.
66. Mamba Architecture: What Is It and Can It Beat Transformers?
Исследуйте Mamba, инновационную архитектуру, превосходящую Transformers по эффективности для длинных последовательностей, обещающую прогресс в AI с гибкой конструкцией.
67. Amazon Falcon Lite vs OpenAI ChatGPT - The Large Language Model Battle
Сравнение Amazon Falcon Lite и OpenAI ChatGPT: Обширный обзор больших языковых моделей.
68. From Crappy Autocomplete to ChatGPT: The Evolution of Language Models
Лёгкое объяснение того, как работает самосознание, и краткий взгляд на эволюцию больших языковых моделей.
69. AI Says My Schtick is Bigger Than Yours!
Хорошо ли AI-версии топов и рекомендаций, лучше ли они, чем результаты поиска? Как отслеживать их?
70. Langchain: Explained and Getting Started
Langchain является важным компонентом для разработки моделей LLM. Он помогает в оркестровке и служит строительным блоком.
71. ChatGPT Vs. ChatGPT: How to Detect Text Generated Using the AI Language Model
ChatGPT может помочь вам оценить, является ли текст, сгенерированный AI.
Текст написан ЛЛМ.
72. Пять вопросов о предвзятости в AI, которых вы, возможно, хотели бы задать
5 основных вопросов из панельной дискуссии о предвзятости в AI. Участники предоставляют свои взгляды на источники предвзятости, ответственность разработчиков и будущее AI.
73. Действие ЕС по AI: последствия для SEO на LLM
Эта статья разоблачает технический жаргон и charts простой курс для понимания последствий регулирования ЕС для SEO на LLM.
74. Должно ли конверсационное AI полагаться на большие модели языка?
Большие модели языка (LLM) — это конверсационные чат-боты AI, которые взрывают мир.
75. LLMs Изменяют Приложения AI: Как Это Происходит
Строительство приложений с не реальными уровнями персонализированного контекста стало реальностью для всех, у кого есть правильная база данных, несколько строк кода и LLM, такой как GPT-4.
76. BYOK (BringYourOwnKey) в генеративном AI — двойной меч
Вы знаете, что Bring Your Own Key (BYOK) в генеративном AI? Читайте дальше и узнайте больше о новом концепте AI.
77. Безопасные угрозы для высокоинтенсивных открыто-источниковых больших моделей языка
Быстрый рост проектов Open-source LLM часто демонстрирует неумную безопасную позицию, которая требует принятия улучшенных стандартов безопасности.
78. Системы памяти AI: подходы, которые вам нужно знать
Создал свою собственную систему Open-source, называемую Elroy, и уже три года взаимодействую с ней. Она помогает мне brainstorm и многое другое.
79. О зиме AI и том, что это означает для будущего
Полная история
Обзор зимних периодов AI проводится в деталях. Обширная информация, которую мы не нашли в других источниках.
80. Может ли китайский DeepSeek разрушить теорию «Больше GPU — больше мощности»?
Это 2025 год, и мы можем уже наблюдать переломный момент для AI, как мы знали его в последние пару лет.
81. Meta Strikes Back: Введение LLaMA
Meta представляет LLaMA, 65-размерный параметр модели, чтобы конкурировать с ChatGPT, в то время как OpenAI планирует AGI, создавая гонку за продвинутые языковые модели.
82. Как я сократил задержку агентного потока на 3-5 раз без увеличения затрат модели
Узнайте, как ускорить и оптимизировать агентные потоки с помощью умной разрезки шагов, параллелизации, кэширования и оптимизации модели.
83. Примечание к оптимизации вывода большой языковой модели (LLM): 2. Введение в ускорители искусственного интеллекта (AI)
Эта статья исследует ускорители AI и их влияние на развертывание большой языковой модели (LLM) на больших масштабах.
84. История мозга: тревога AI и иллюзия разума
Сознательны ли LLM, или это просто сложные калькуляторы? Как забытый в 1981 году научно-фантастический эксперимент предсказал современную кризисную ситуацию AI.
85. За кулисами большой языковой модели: разговор с Джей Аламмаром
В 16-м эпизоде «Подкаста «Что такое AI», я имел честь беседовать с Джей Аламмаром, известным специалистом по AI и блогером.
86. Большая языковая модель: путешествие начинающего — Часть 1
Изучите мир большой языковой модели (LLM) в нашей обширной статье.
Руководство. От понимания их возможностей до преодоления ограничений, узнайте, как LLMs
87. Как привести личностные торговые оферы с помощью векторного поиска
Узнайте, как векторный поиск может привести к результатам с помощью клиентских предложений в крупном розничном магазине.
95. Как большие языковые модели улучшают безопасность систем от сопротивления угроз до анализа угодах о соблюдении
Изучайте разнообразные применения больших языковых моделей (LLMs) в области безопасности.
96. Как AI изменит менеджмент продуктов
Изучайте, как AI изменит роли менеджеров продуктов, от быстрого прототипирования до анализа обратной связи пользователей, оснащая PMs инновациями и конкурентоспособностью.
97. TnT-LLM: Выделение паттернов в большом объеме, используя большие языковые модели
Перевод неструктурированного текста в структурированный и значимый формы является фундаментальным шагом в выделении паттернов для последующего анализа и применения.
98. Лучшие практики для интеграции LLMs с средствами анализа вредоносного ПО
LLMs могут дополнить деобфускацию в потоках угроз, заполняя пробелы, суммируя код и картографируя MITRE ATT&CK, но должны минимизировать галлюцинации.
99. От чёрного ящика до прозрачности: как читать логику LLMs
Изучайте, как LLMs работают внутри: от фундаментальных принципов предсказания токенов до архитектуры Transformer, этапов обучения и цепей рассуждений. Узнайте, как формировать запросы
100. Оценка TnT-LLM: автоматическая, человеческая и оценка на основе LLM
В связи с неупорядоченным характером проблемы, которую мы изучаем, и отсутствием стандартной оценки, выполнять количественную оценку конечного результата генерации таксономии
101. Предыдущие подходы к выделению паттернов в тексте: таксономия, группировка, классификация и LLM
Обзор связанной исследовательской работы в области генерации текстовой таксономии, группировки текста и использования LLM для автоматической аннотации текста.
102. Воздействие AI: 6 революционных прорывов
Исследуйте воздействие AI в отраслях: Воздействие AI на бизнес, клиентский опыт, здравоохранение, финансы, транспорт и многое другое!
103. Дорогой AI: Мы все еще не доверяем вам
За последние месяцы миллионы людей все больше увлекаются AI и чат-ботами. Есть одна история, которая привлекла мое внимание…
104. Как переставить упаковку продукта с помощью AI для роста
Упаковка продукта влияет на 72% американцев в принятии решений о покупке, а рынок устойчивой упаковки развивается с годовой скоростью роста 8,5% в период с 2023 по 2031 год.
105. Наши предложенные фреймворки: Использование LLM для тематического анализа
Фреймворк основан на возможностях модели OpenAI GPT-4 для выполнения сложных задач НЛП в нулевой точке.
106. Должны ли вы рисковать использовать браузер AI?
AI кажется следующим шагом для веб-браузеров, но риски безопасности и галлюцинации являются реальными проблемами. Здесь перечислены плюсы и минусы браузеров AI.
107. Использование потенциала AI для создания персонализированных и индивидуальных опытов
Узнайте, как AI помогает создавать персонализированные опыты в различных сервисах.
108. LLM & RAG: Рассказ о любви на День святого Валентина
Любовь в воздухе, и так же идеальные партнеры AI: LLM и RAG!
109. Будущее анализа вредоносного ПО: LLM и автоматическая деобфускация
LLMs показывают сильный потенциал для автоматизации деобфускации вредоносного ПО, эффективного анализа реальных скриптов Emotet и улучшения будущих потоков угрозной информации
110. AI Knows Best—But Only If You Agree With It
Эффективность AI может непреднамеренно сузить человеческое знание, приводя к «кollapse знаний». Узнайте, как этот сдвиг влияет на инновации и культурную диверсность.
111. Yoshua Bengio Weighs in on the Pause and Building a World Model
Эта неделя я беседовал с Yoshua Bengio, одним из основателей глубокого обучения о дополнении больших языковых моделей
112. How to Build Your First MCP Server using FastMCP
Узнайте, как построить свой первый сервер MCP с помощью FastMCP и подключить его к большой языковой модели для выполнения реальных задач через код.
113. An Intro to MedPaLM: ChatGPT's Healthcare-Focused "Cousin"
ChatGPT для здравоохранения? Узнайте все, что нужно знать о MedPaLM, новой LLM, разработанной Google специально для медицинских и клинических приложений.
114. Reflecting on AI in 2023: Magic, Hope, Innovation and Disruption
Откройте трансформативную силу Искусственного интеллекта. Изучите последние тенденции от NL до глубокого обучения, которые формируют будущее AI.
115. ChatGPT Translator VS Mine: Which One Is Better?
Действительно ли ChatGPT Translator такой хороший, как упоминалось в многих постах ?
116. Retrieval-Augmented Generation: AI Hallucinations Be Gone!
Retrieval Augmented Generation (RAG), показывает обещания в эффективном увеличении знаний LLM и снижении воздействия AI-иллюзий.
117. Протокол контекста модели (MCP): новый стандарт для безопасной интероперабельности AI
MCP является важным "протоколом middleware", который находится между большим языковым моделям и всей корпоративной средой.
118. Демократизация доступа к AI стала более важной, чем когда-либо
Поскольку влияние AI grows, так же растут разрывы в доступе к его трансформационному потенциалу.
119. 10 Техник инженерии запросов для трансформации вашего подхода к AI
Откройте 10 продвинутых техник инженерии запросов: рекурсивное расширение, оптимизация токенов, принцип DRY, эмуляция персонажа для превосходных AI-выходов.
120. Чат — ужасный интерфейс для агентов, и 2026 года это покажет
Разработка AI-агентов? Я попробовал Angular, HTMX & Python. Они провалились. Узнайте, почему A2UI является декларативным протоколом для замены базовых чат-ботов.
121. OpenAI делает легче создавать свои собственные AI-агенты с помощью API
Вы можете создавать сложные AI-ассистенты, которые безболезненно обрабатывают все, от обратного расположения строк до запросов внутренних баз данных.
122. AI делает технику менее пугающей для "словных" людей
Узнайте, как AI преобразует мир для писателей и творческих людей. Вступите в мир, как естественные языковые интерфейсы делают технику более доступной.
123. Как я заставил Llama 3 почтить Бога!
Вы когда-нибудь задумывались, что бы AI подумал о Боге? Теперь вы можете узнать. Читайте эту статью, чтобы узнать!
124. Автоматический анализ настроений бренда с помощью генеративной AI
Учитесь мониторить свой бренд на социальных сетях, как Reddit, Twitter, Linkedin, Hacker News… и автоматически анализировать настроение, благодаря генеративному AI.
125. The Game AI Problem Computers Were Never Built to Solve
Объяснение, почему brute-force AI проваливается в гранд-стратегических играх, и как гибридные архитектуры LLM позволяют выполнять долгосрочную стратегическую рассуждение.
126. GPT4All: An Ecosystem of Open-Source Compressed Language Models
В этой статье мы рассказываем историю GPT4All, популярного открытого репозитория, целью которого является демократизация доступа к LLM.
127. AI Is Playing Favorite With Numbers
LLM, как умны и предвзяты, как люди, которые их обучали. Хотя AI не может думать сама, мы только начинаем изучать глубины психологии LLM.
128. From Backlinks to Data Depth: How LLMs Are Rewriting Content Authority
Большие языковые модели (LLM) заменяют авторитетность контента Google-эры. LLM предназначены для поиска контента, который объясняет, определяет, сравнивает или решает.
129. Streamlining LLM Implementation: How to Enhance Specific Business Solutions with RAG
Учитесь улучшать свои LLM с помощью retrieval-augmented generation, используя LlamaIndex и LangChain для контекста данных, развертывая свою приложение на Heroku.
130. Simplifying Vector Search: Part 1
Вы когда-нибудь задумывались, как Spotify или любое количество сайтов для знакомств определяют, что или кто вам нравится? Они используют векторное поиск. Это векторный поиск упрощается.
131. The Em Dash Rorschach Test
Использование вами эн-деша — это ли это признак AI-авторства? Как этот скромный знак препинания стал культурной вспышкой в эпоху больших языковых моделей.
132. GPTerm: Создание интеллектуальных приложений терминала с помощью ChatGPT и моделей LLM
В этой статье исследуется увлекательная область создания умных приложений терминала, интегрировав в них ChatGPT, cutting-edge языковой модель.
133. Плюсы и минусы LLM в практике кибербезопасности
LLM повышают кибербезопасность, автоматизируя обнаружение и анализ угроз, а также соблюдение требований, но также могут быть использованы для атак и разработки вредоносного программного обеспечения.
134. Как начать карьеру junior-разработчика в 2026 году
135. LLM: эксперты в NLP, обеспечивая сложные поисковые функции в платформах электронной коммерции
Чтобы обеспечить исключительные покупательские опыт, бизнесы должны использовать потенциал LLM, поскольку электронная коммерция продолжает развиваться.
136. Их маржа — это возможность AI
Может ли «ЧатCEO» снизить затраты и улучшить бизнес?
137. LLM-усиленная классификация текста: разложение меток GPT-4 в эффективные классификаторы
Мы исследуем использование GPT-4 для масштабной аннотации текста и обучение лёгких классификаторов на этих метках, сравнивая их точность и эффективность.
138. Как AI и социальные медиа формируют знания через эхо-камеры и фильтровые пузырьки
Алгоритмы AI и социальных медиа формируют знания, усиливая предубеждения и ограничивая доступ к разнообразным идеям, что приводит к образованию эхо-камер и искажению знаний.
139. У меня есть умысел?
139. Do y'AI mind?
Большие языковые модели вызывают вопросы вокруг природы ума, старую философскую проблему, солипсизм или один ум, трудно ответить
140. AI Framework has You Covered on Image-to-Text Workflows
Узнайте, как использовать AnyModal, модульную рамку для интеграции визуальных и языковых моделей, для создания и обучения собственного LaTeX OCR-системы. Ideal'noe для исследований в области AI
141. With New AI Model, Meta Hopes Imperfect Hands Will be a Thing of the Past
Meta разогревает соревнование в области AI с запуском нового искусственного интеллекта, который может помочь пользователям анализировать и завершать незавершенные изображения.
142. From Zero to AI-Ready: How I Taught Myself Machine Learning (And What I would Tell You Now)
Вы не нуждаетесь в докторской степени, чтобы научиться AI, просто структура, любопытство и небольшие шаги, которые имеют смысл. Вот как я научился машинному обучению с нуля.
143. Policy-Driven AI: Designing Configuration-Driven Model Selection for Enterprise Systems
Фиксация вызова AI-моделей - это новый технический долг. Этот материал рассказывает о том, как архитектурить слой конфигурации для выбора модели
144. When To Use Small Language Models Over Large Language Models
Вы wonder', где начать использовать малые языковые модели? Найдите топовые случаи использования малых языковых моделей, когда малые языковые модели будут лучше, чем большие языковые модели.
145. Why It's Harder: The Unique Hurdles For Non-Experts Using AI Coding Tools
AI-инструменты для программирования могут стать игровым преимуществом для неэкспертных конечных пользователей. Исследование уникальных проблем, возникающих при применении LLM к программированию
146. На Грок и вес дизайна
Рекентные проблемы с выходом Грока выявляют более глубокие структурные проблемы в моделировании соответствия.
147. Дополнительные результаты: оценка кросс-языковой таксономии и в-depth анализ классификации
Исследуйте более подробные результаты кросс-языковой таксономии, детальную оценку согласия в аннотациях и общие метрики классификации для TnT-LLM.
148. Работа модели и ловушки в автоматизированном деобфусцировании вредоносного ПО
Тестирование четырех LLM на скриптах Emotet показало, что GPT-4 лидировал в деобфусцировании, но все модели столкнулись с галлюцинациями и ограничениями запросов.
149. TnT-LLM: высококачественное автоматизированное текстовое извлечение и эффективная классификация с помощью LLM
Обзор результатов TnT-LLM: автоматизированная генерация таксономии превосходит кластеризацию, LLM эффективны в качестве оценщиков (с оговорками), и так далее.
150. Редкое активное включение в MoE-моделях: расширение ReLUfication к Mixture-of-Experts
Откройте, как это открытие позволяет сократить FLOP на миллионы раз за счет MoE ReLUfication.
151. Таксономии, сгенерированные TnT-LLM: пользовательские намерения и метки доменов разговора
Просмотрите таксономии пользовательских намерений и меток доменов разговора, автоматически сгенерированные TnT-LLM и отредактированные человеком для текстовой классификации.
152. Мягкая биготрия AI-дома: потому что пользователи просто слишком неумны
Сатирическое разоблачение нарративов AI-дома: критическое мышление не исчезнет, институты не...
автоматическое сокращение, и «апокалипсис» предполагает, что пользователи не способны.
153. AI-детективы и дело о маскирующихся дропперах
Используя 2 000 реальных скриптов дроппера Emotet, эксперимент проверяет способность LLMs деобфусцировать вредоносное ПО и извлекать информацию о угрозах на больших масштабах.
154. Agents 101 — Создание и развертывание AI-агентов в производство с помощью LangChain
Узнайте, как Langchain превращает простой запрос в полнофункциональный AI-агент, способный мыслить, действовать и запоминать.
155. TnT-LLM: Демократизация текстового анализа с помощью автоматизированной таксономии и масштабируемой классификации
TnT-LLM автоматизирует текстовый анализ, обеспечивая эффективную генерацию таксономии, классификацию с помощью LLM и демократизированный доступ к текстовым данным.
156. Beyond ReconVLA: Безаннотационная визуальная привязка с помощью языковой внимания и маскированной реконструкции
Новая подход заменяет аннотации взгляда на языково-ориентированную маскировку внимания, улучшая восприятие робота и снижая затраты на обучение.
157. Stop Drowning in AI-Models: Трехпилонная рамка оценки
Практическая трехпилонная рамка оценки компьютерного зрения в производстве.
158. Рынок труда будущего при автоматизации и больших языковых моделях
🕵️♀️👷Вашу работу не автоматизирует ChatGPT 🤖, а это не все - это взгляд в подкапотное пространство реальных проблем, которые привели нас к сегодняшнему дню.
159. Быстрый справочник по технологии LLM-генерации кода и ее ограничениям
159. Быстрый справочник по технологиям LLM для генерации кода и их ограничениям
Этот обзор предоставляет быстрый справочник по технологиям, лежащим в основе LLM для генерации кода, охватывающий архитектуру Transformer
160. Beyond The Final Answer: Why Non-Experts Can't Spot Bad AI Code
Рассмотрим критическую проблему верификации кода, сгенерированного AI, для непрофессиональных программистов. Узнайте, почему они полагаются на «просмотр» окончательного результата
161. 100 Complex LLM Terminology Explained in One Single & One Simple Sentence
Каждое техническое термин о больших языковых моделях и генеративном AI объясняется сначала кратко, а затем просто, чтобы укрепить ваше понимание.
162. TnT-LLM Implementation Details: Pipeline Design, Robustness, and Efficiency
Рассмотрим техническую реализацию TnT-LLM, включая дизайн пайплайна, методы обеспечения надежности и стратегии выбора модели
163. Five Architectural Patterns That Fix What's Broken in RAG
Семантический RAG предполагает, что вектор запроса находится рядом с вектором ответа.
164. Data Scraping: Do Large Language Models Cross Boundaries by Training on Content from Everyone
Хотя скрапинг позволил моделям добиться успеха, чистые данные станут все более важными
165. Researchers in UAE Create AI That Can Describe Images in Perfect Detail
Исследователи в университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.
166. Топология значения: В направлении "коперативной теории полей" для искусственной интеллектии
Смелое утверждение о том, что AI должна выйти за рамки языка и токенов и перейти к единой топологической модели, где слова, лица и звуки делятся одним пространством значений.
167. Выделение скрытой загрузки моловераплатформ с помощью AI-поддеревьеллмс
LLMs могут автоматизировать выделение обфусцированных моловераплатформ, упрощая угрозную информацию, даже когда атакующие меняют упаковку и обфускацию.
168. Как использовать большие языковые модели для поддержки тематического анализа в исследованиях по эмпирическому праву
Мы предлагаем новую рамку, способствующую эффективному сотрудничеству юриста с большим языковым моделям (LLM) для генерации первичных кодов
169. Выделение потребностей пользователей с помощью Chat-GPT для рекомендации диалогов
Исследуйте интеграцию ChatGPT в интерактивные системы рекомендаций, где оно служит как модель диалога, так и движок рекомендаций.
170. Открытая LLM: Оценка и разработка приложений на основе открытого
Как выбрать наиболее подходящую модель для вашего приложения? Анализ оценки и разработки приложений на основе открытых больших языковых моделей.
171. Строение гибкой рамки для мультимодальной входных данных в больших языковых моделях
Откройте AnyModal, гибкую рамку, упрощающую обучение мультимодальным большим языковым моделям (LLM). Интегрируйте текст, изображения и аудио безболезненно.
172. Почему статический анализ страдает от современного моловера
Малварь использует пакетировщики, крипторы и обфусцирующие программы, чтобы избежать статического анализа, вызывая сложности для аналитиков в адаптации методов обнаружения и анализа.
173. Сознание: AI, LLMs—Сознание?
174. Тrap версии FrankenPHP: Почему ваш стек Laravel Octane не использует PHP 8.5
175. Максимизация возможностей NLP с помощью больших моделей языка
176. Этика локальных LLM: Ответ на манифест Zuckerberg «Открытый исходный код AI»
177. UI: Почему это реальный бутылочный горлышко AI-агента
178. В сторону автоматического создания подписей к спутниковым изображениям с помощью LLM: Резюме и Введение
179. Почему модели диффузии проваливаются в B2B-стилировании волос
Пайплайн "Архитектор-Строитель" достигает трехмерной согласованности в GenAI для продуктов B2B SaaS.
180. Возможности больших моделей языка: хакинг или помощь?
Исследование возможностей агентов LLM: изучение взлома веб-сайтов
181. Мыслить как компьютер: пропущенная навык для непрофессионалов, использующих AI
Исследование критической проблемы для конечных пользователей-программистов: отсутствие компьютерного мышления. Узнайте, как инструменты, ассистируемые LLM, должны быть умнее
182. Из сценария в краткое содержание: умный способ сжимать фильмы
Масштабируемый AI-пipeline для суммирования и сжатия важных сцен из сценариев фильмов с высокой точностью.
183. Использование больших моделей языка для поддержки тематического анализа: признание и что дальше?
Нам предложили новую LLM-поддерживаемую рамку для тематического анализа, и мы оценили ее производительность на анализе мнений судебных органов
184. 7-слойная схема для обслуживания, защиты и наблюдения за агентами AI на масштабе
От ПК до Фабрики: разбор 7-слойной архитектуры платформы агента AI для корпоративной масштабируемости и контроля
185. Быстрый справочник по квантованию для LLM
Квантование — это техника, которая уменьшает точность весов и активаций модели
186. Метод "Сначала суммируйте, затем ищите" для длинного видео-опроса: вывод
В этой статье исследователи изучают нулевую задачу видео-QA с помощью GPT-3, превосходя обученные модели, используя повествовательную
Обзоры и визуальное сопоставление.
187. Что такое LoRA? Объяснение низкочастотной адаптации LLM
Чтобы заставить большие языковые модели работать в рамках вашего бюджета как по вычислительным затратам, так и по памяти, LoRA является фундаментальным алгоритмом квантования.
188. Может ли кто-то сейчас кодировать? Исследование помощи AI для непрофессиональных программистов
Приходите и посмотрите, как кодирование меняется с помощью языковых моделей AI. Поделитесь реальными историями и исследованиями, показывающими, как сильно это отличается от программирования с этими инструментами
189. Доказательство пользы CLI-инструментов над MCP-серверами в агентном AI
190. Как создать реалистичные разговоры AI
Понимайте параллели с плагинами для настраиваемых помощников AI и роль GPT-4 в генерации естественных взаимодействий.
191. Управление онлайн-репутацией в эпоху AI
Управление онлайн-репутацией теперь включает не только мнения людей, но и мнения AI. Отслеживание репутации в ответах AI — это новый SEO!
192. Выяснилось, что 30% вашего модели AI — это просто пустой пространство
193. Как сделать код понятным: главная проблема понимания в программировании AI
Исследуйте основную проблему программирования AI: понимание кода. Узнайте, почему сгенерированный код сложно понять и как это влияет на точность
Поскольку генеративные системы AI производят все более сложный контент, возникает сложный вопрос: должны ли их выходные данные иметь право на защиту свободы слова?
195. Меч слов: эволюция инъекции подсказок
Исследуйте трехуровневую эволюцию инъекции подсказок: от социальной инженерии в Tensor Trust до fragmentation BPE и логических переключателей RAG в Web3-играх.
196. Где скрываются глюк-токены: Общие шаблоны в словарях токенизатора LLM
Нетренированные токены часто происходят от неиспользованных байтовых токенов, слияния фрагментов и специальных токенов-шаблонов, найденных в основных LLM, независимо от архитектуры.
197. Как построить чат-бот, который рассказывает средневековые истории с помощью платформы AI Oracle
Oracle Cloud Infrastructure — это одна из крупных облачных платформ, доступных на рынке, вместе с AWS, Google Cloud и Azure.
198. Просмотр данных: блоги, форумы и рост инструментов LLM
Этот приложенный раздел содержит список статей и тем на Hacker News, которые были проанализированы для понимания реальных-world опыта разработчиков, использующих Copilot.
199. Великое преобразование: как LLM изменяют каждый программный процесс
Этот заключительный раздел исследует глубокое преобразование, которое помощь LLM приносит в весь программный опыт.
200. В сторону автоматической генерации подписей к спутниковым изображениям с помощью LLM: методология
Исследователи представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API.улучшение точности и снижение потребности в ручной маркировке.
201. Внедрение возможностей NLP в существующую стек-приложение легче, чем когда-либо: почему
Ускорение разработки, создание контента и ускорение принятия данных решений с помощью новых инструментов ML, которые делают легким внедрение NLP в стек-технологии.
202. Навигация с помощью больших моделей языка: подробности реализации
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.
203. Instagram переполнен содержанием, сгенерированным AI, и Meta не кажется, что заботится
Сеть AI-сгенерированных инфлюенсеров, изображенных с синдромом Дауна, монетизируются через взрослый контент на платформах, таких как Fanvue.
204. Инфраструктура данных, стоящая за каждым успешным стартапом AI
95% стартапов AI проваливаются, потому что их данные ломаются первыми. Здесь, как настоящие победители строят прочную инфраструктуру данных с помощью Bright Data, чтобы остаться в живых.
205. Excel vs. Python: как целевое язык меняет все для непрофессионалов
Обсуждение того, почему инструмент может выбрать Python за счет его богатых API, даже если пользователь более знаком с формулами Excel, и вызванные этим проблемы.
206. Критика «звучащего» написания AI игнорирует более глубокие культурные предубеждения
Нам не следует позволять моделям AI отнимать части нашего языка.
207. Как AI уменьшает нашу точку зрения на мир
Генеративный AI может уменьшить разнообразие знаний, что приводит к коллапсу знаний.
208. Психеделики | LLMs: Есть ли связь между психеделиками, LLMs и психическим заболеванием?
Раскрыть связь между психеделиками, LLMs и психическим заболеванием.
209. Долина чуждости кода: почему код, сгенерированный AI, так сложен для отладки?
Разработчики разделились во мнениях, является ли код, сгенерированный AI, действительно экономичным. Исследование компромиссов между быстрым написанием кода и затраченным временем и усилиями.
210. MIVPG: Мультиинстансивизуальный промптгенератор для MLLMs
MIVPG улучшает MLLMs, используя Мультиинстансивное обучение для включения коррелированной визуальной информации.
211. Можно ли большим языковым моделям развить игровую зависимость?
212. Героизм в Голодеке: Построение AI-компаньонов для конечной границы
LLMs — это модели данных, обученные на колоссальных объемах текстовой информации, поглощающие книги, статьи, код и другие формы написанной информации.
213. Большые языковые модели (LLMs) для образовательных приложений
Исследуйте растущую роль GPT-моделей в образовании, детально рассмотрев их использование через запросы и тонировку для задач, таких как генерация обратной связи.
214. Никто не использует тестирование как тестирование LLM-приложений (это будет проблемой)
Большинство команд развертывают LLM и RAG-приложения без реального набора тестов — это шестилучевая система тестирования, которая решает эту проблему.
215. Сила динамического кодирования: RECKONING превосходит нулевую точку GPT-3.5 по устойчивости к отвлекающим факторам
Результаты RECKONING значительно превышают как нулевую, так и несколько точек GPT-3.5 по навыкам.
216. Награждение редкого: как уникальность-осведомленная RL устраняет коллапс исследования
Это краткое изложение статьи "Награждение редкого: уникальность-осведомленная RL для творческого решения проблем в LLM" [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utm_source=hackernoon&utm_medium=referral]. Если вам нравятся такие анализы, присоединяйтесь к AIModels.fyi [https://www.aimodels.fyi/?utm_source=hackernoon&utm_medium=referral] или следите за нами на Twitter [https://x.com/aimodelsfyi].
ПРОБЛЕМА КОЛЛАПСА РАЗВОРЕНИЯ
Когда вы обучаете языковую модель с помощью метода подкрепления для решения математических задач, происходит что-то противоречивое. Вы награждаете правильные ответы. Модель находит одну надежную дорогу к правильности и, по сути, останавливается исследовать. Каждый роллбэк становится slight вариацией одной и той же темы. Pass@1 выглядит хорошо, вы решаете проблемы постоянно. Но pass@k застывает. Если вы пробуете сто раз, вы не получаете сто разных решений, вы получаете сто версий одного и того же решения.
Это коллапс исследования, и это открывает что-то сломанное в том, как мы думали о RL для языковых моделей. Стандартный подход присваивает награды на уровне токена, во время генерации. Когда токен участвует в правильном окончательном ответе, он получает подкрепление. С течением времени политика учитывает последовательность токенов, которая наиболее надежно производит награды. Другие валидные пути существуют, но они не имеют такого же подкрепления. Они не накапливают уверенность в том же порядке. Итак, политика сужается.
Напряжение реально. Модель, которая находит одну хорошую стратегию надежно, с точки зрения pass@1, делает именно то, что вы просили. Но с практической точки зрения, это упущенная возможность. Если вы готовы пробовать несколько раз, разнообразная модель должна дать вам больше шансов найти правильный ответ. Вместо этого вы получаете повторяемость. Этот разрыв между тем, что метрика измеряет, и тем, что способность должна обеспечить, — это где проблема находится.
ПОЧЕМУ МЫ ИЗМЕРЯЕМ НЕ ТО, ЧТО НУЖНО
Неявное предположение, которое движет большинством работ по RL для языковых моделей, заключается в том, что лучшие локальные награды создают лучшую глобальную разнообразность. Обучайте каждый токен принимать правильные решения, и роллбэки будут естественным образом разнообразны. Это интуитивно. Это также ложно.
На самом деле происходит то, что хорошие локальные решения укрепляют себя. Выбор токена, который приводит к правильному ответу, получает положительный сигнал. Когда модель снова должна решить подобную проблему, этот выбор токена становится чуть более вероятным. И на следующий раз, еще более вероятным. Градиент всегда указывает в ту же привлекательную область. Политика не перестает исследовать, она исследует эффективно прямо в одну и ту же впадину.
Исходная причина не в случайности или недостаточном обучении. Это фундаментальное несоответствие между тем, что мы измеряем, и тем, что мы хотим. Мы измеряем поведение на уровне токена и надеемся на поведение на уровне роллбэка. Понимание этого несоответствия важно, потому что это означает, что решение не может быть маргинальным. Вы не можете расписание исследований differently или добавить регуляризацию энтропии и решить эту проблему. Нужно изменить то, что фактически вознаграждается на уровне ролл-аута. Нужно сделать ролл-аутовую новизну явным частью цели. UNIQUENESS-AWARE REINFORCEMENT LEARNING Основная идея проста: вознаграждайте правильные решения, использующие редкие стратегии, больше, чем правильные решения, повторяющие общую стратегию. Делайте политику внутренить, что нахождение нового правильного ответа более ценно, чем нахождение повторяющегося. Метод работает в конкретных шагах. Сначала, генерируйте много роллов для одного задачи. Второй, используйте языковый модель, чтобы кластеризовать эти ролловы по их стратегии высокого уровня рассуждения. Не по их окончательным числам или записи, а по логическому подходу внутри. Один кластер для решений, использующих замену, другой для решений, использующих геометрическое рассуждение, другой для решений, основанных на калькулировании. Третий, рассчитайте размеры кластеров. Стратегия, открытая 2 из 100 роллов, редка. Стратегия, открытая 50 из 100, общая. Наконец, перепзвесьте сигнал вознаграждения обратно с размером кластера. Функция преимущества, которая говорит политику, насколько лучше этот ролл был, по сравнению с средним, получается уменьшена для решений в больших кластерах и увеличена для решений в маленьких кластерах. Правильное решение, использующее редкую стратегию, становится стоить значительно больше вознаграждения, чем правильное решение, использующее доминирующую стратегию. Это напрямую целиком направлено на структуру вознаграждения. А не надеясь, что диверсификация возникнет в качестве побочного эффекта тренировки на уровне токенов, политика теперь имеет явный повод исследовать: редкие правильные стратегии буквально более вознаграждаемы. Цель сдвигается от "найти любой правильный ответ" до "найти ответы, использующие подходы, которые вы еще не нашли." CLUSTERING STRATEGIES THE RIGHT WAY Есть практическая проблема, скрывающаяся здесь. Как определить "высокий уровень стратегии"? Кластерьте слишком грубо, и вы объедините действительно разные подходы вместе. Кластерьте слишком тонко, и вы будете считать поверхностные вариации (использование переменной x против y) фундаментально разными стратегиями. Кластерить на неправильной гранулярности и сигнал вознаграждения разрушается. В статье используется языковый модель, как судья. А не ручное кодирование того, что считается различным стратегией, вы спрашиваете LLM, чтобы прочитать два решения и определить, используют ли они одинаковый высокий уровень подхода. Это удивительно эффективно. Языковые модели хороши в семантической эквивалентности. Два решения, использующие одинаковые логические шаги, но разную запись, признаются как подобные. Два решения, использующие действительно разные подходы, признаются как разные. Это обходит серьезную ошибку. Рigid кластеризация на основе синтаксических характеристик пропускает важные различия или переразделяет пространство. Использование судьи LLM обеспечивает гибкость, в то время как сохраняя кластеризацию семантической и интерпретируемой. Гранулярность возникает естественным образом от того, что модель понимает как "разные подходы", а не навязывается вручную. MEASURING WHAT MATTERS Валидация охватывает три домена: математику, физику и медицинскую рассуждение. Метрики имеют значение, потому что они рассказывают разные истории. Pass@1 измеряет одноразовую производительность. Модель получает один шанс. Это не должно ухудшаться, потому что ничего в уникальном RL не должно разрушать базовую компетентность. Pass@k измеряет вероятность того, что хотя бы один правильный ответ появится в k образцах. Это то, что должно улучшиться. Если политика становится более разнообразной, получение более многочисленных образцов должно привести к большему количеству правильных ответов. AUC@K — это площадь под pass@k Кривая изменения, когда вы изменяете k по мере увеличения бюджета выборки. Это самый строгий тест. Он спрашивает, обеспечивает ли подход постоянные и устойчивые приросты при выборке больше, а не просто пик в каком-то конкретном значении k. Ожидаемая картина состоит в том, что RL, осведомлённый о единственности, улучшает pass@k и AUC@K, в то время как поддерживает или слегка улучшает pass@1. Это происходит потому, что метод не меняет, что означает "правильно". Он просто делает правильные решения, используя редкие стратегии, более привлекательными. Политика становится лучше в обнаружении нескольких действительных подходов, оставаясь компетентной на первую попытку. Эти результаты подтверждают основную гипотезу: коллапс эксплорации был реальным структурным проблемой, и решение этой проблемы на уровне ролл-аута работает. Приросты не являются незначительными корректировками уже работающей системы. Это доказательство того, что тренировочная цель формирует, какие виды решений обнаруживаются и укрепляются, и изменение этой цели разблокирует действительно разные поведение. Ширина контекста в обучении языковых моделей Этот труд связан с более широкими вопросами о том, как мы обучаем языковые модели. Есть растущая база исследований о том, как структура сигнала вознаграждения формирует, что модели учатся. Работа по результатно-ориентированной эксплорации в логическом рассуждении LLM [https://aimodels.fyi/papers/arxiv/outcome-based-exploration-llm-reasoning?utmsource=hackernoon&utmmedium=referral] показала, что фокус на конечной правильности вместо процесса меняет, какие стратегии появляются. Аналогичные исследования о том, как фильтрация влияет на эксплорацию [https://aimodels.fyi/papers/arxiv/whatever-remains-must-be-true-filtering-drives?utmsource=hackernoon&utmmedium=referral] предполагают, что данные, которые мы выбираем во время обучения, переливаются в политики, которые мы конечным итогом получаем. Вклад заключается в точности и реализуемости. Это не утверждение о том, что языковые модели "креативны" в какой-то глубоком смысле. РATHER, это показывает, что тренировочная цель имеет огромное значение для того, чтобы обнаруживать разнообразные решения. Если вы вознаграждаете только правильность, вы получаете сходимость. Если вы вознаграждаете правильность и редкость, вы получаете эксплорацию. Разница заключается в гранулярности, с которой вы присваиваете сигнал вознаграждения. Есть также связь с практической эффективностью в техниках эксплорации для обучения по подкреплению с LLM [https://aimodels.fyi/papers/arxiv/enhancing-efficiency-exploration-reinforcement-learning-llms?utmsource=hackernoon&utmmedium=referral]. Вместо добавления случайности или бонусов энтропии, которые могут ухудшить производительность, uniqueness-aware RL выравнивает эксплорацию с фактической полезностью. Модель исследует решения, которые и правильны, и разные. Это эксплорация, которая структурно стимулируется, а не навязывается снаружи. Удобство подхода заключается в его простоте. Вы не нуждаетесь в новых архитектурах или сложных графиках эксплорации. Вы просто нужно одно изменение: сдвинуться от вознаграждения поведения токена к вознаграждению уровня ролл-аута новизны. Это одно изменение решает реальную проблему в ее источнике, и доказательства показывают, что оно работает consistently по всему спектру доменов. Оригинальная статья: Читайте на AIModels.fyi [https://www.aimodels.fyi/papers/arxiv/rewarding-rare-uniqueness-aware-rl-creative-problem?utmsource=hackernoon&utmmedium=referral] В этой статье мы изучаем, как "семантическая угадка", производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования. Промпты и понимание UTF-8 важны для точного проверки и диагностики недообученных токенов в языковых моделях. Я понял, что мне нужно что-то другое. Не еще один обычный бот команды, а персональный ассистент AI — тот, который знает мой конкретный контекст, мои предпочитаемые сокращения Объекты или области в изображении. Метрики оценивают безопасность и полезность многомодальных моделей речи и языка.
Этот исследование, исследователи предлагают контрольную линию качества данных для федеративного тонирования основанных моделей. Посетите репозиторий /Learn для поиска самых читаемых статей о любой технологии.
217. Решение кодовых головоломок: Эволюция инструментов программной помощи
От упрощения задач с прямым управлением до генерации кода по примерам, отслеживайте, как умные инструменты всегда помогали программистам218. Давайте услышим от разработчиков: что на самом деле такое кодирование с помощью AI
Присоединяйтесь к дискуссии. Этот раздел суммирует отчеты программистов о том, является ли использование Copilot новым языком программирования или просто признаком плохой инструментальной базы. Мы исследуем, как219. 102 Языка, Один Модель: Ключевой прорыв в мультимодальном AI, о котором вы должны знать
Система поиска с использованием LLM соответствует речи и тексту на 102 языках, превосходя предыдущие методы с мультиязыковым пониманием.220. Получение максимальной выгоды из большого языкового модели
LLM - мощный инструмент, когда он используется эффективно с помощью инженерии запросов и настройки параметров инференса221. Few-shot In-Context Preference Learning Using Large Language Models: Full Prompts and ICPL Details
Полные запросы и подробности ICPL для изучения Few-shot in-context preference learning с LLM222. Стоп угадывать, что делает ваш LLM - Этот инструмент показывает вам все
OpenLLM Monitor - открытая исходная база инструментов для мониторинга, отладки и оптимизации приложений Large Language Model (LLM).223. FreeEval: Этические проблемы
В этой статье мы представляем FreeEval, модульную и расширяемую базу для надежного и эффективного автоматического оценки LLM.224. AI-Горшечник: Новая роль экспертов в мире автоматизированного кода
Исследование меняющейся роли "горшечников" в мире, где AI может ответить на большинство вопросов. Будет ли их новая роль обучать пользователей, как использовать инструменты AI?225. ToolTalk: Бенчмаркинг будущего инструментов с помощью ассистентов AI
Откройте ToolTalk, новый бенчмарк, предназначенный для оценки ассистентов AI, таких как GPT-3.5 и GPT-4, на сложных, многоэтапных задачах использования инструментов с конверсационными взаимодействиями226. Создание LLMs с правильной смесью данных
Откройте важность LLMs и как Bright Data экономит время и деньги, предоставляя полную и соответствующую информацию для обучения AI-моделей. Узнайте больше сейчас!227. Использование больших языковых моделей в тематическом анализе: как это работает
В последнее время было проведено несколько исследований, посвященных использованию LLMs в тематическом анализе. De Paoli оценил, насколько GPT-3.5 может выполнить полноценный тематический анализ228. Alibaba's Claude Killer Входит в Ring
Alibaba официально выпустила QVQ-Max, свою первую производственную версию визуального моделирования.229. GitHub Copilot Возглавляет Заряд в коммерческом LLM-ассистированном программировании
Эта секция дает представление о коммерческом ландшафте LLM-ассистированного программирования, от полной синтезированной системы GitHub Copilot230. TnT-LLM для автоматизированной генерации таксономии: превышение базовых кластерных значений
Мы оцениваем TnT-LLM для автоматизированной генерации текстовой таксономии, сравнивая ее точность и актуальность с методами кластеризации на основе вложений с помощью человека и LLM 231. Whisper Wars: Будет ли AI-пrompt стать секретным рецептом будущего?
Поскольку бизнесы признают ценность оптимизированных AI-пrompt, возникает новая дискуссия: могут ли prompt стать секретными рецептами, и что это означает для инноваций?
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости переподготовки его с нуля.233. Преимущества применения ограничений к выводам LLM
За упомянутыми выше случаями нашим опрошенным респондентам сообщили о ряде преимуществ, которые могла бы предложить возможность ограничивать выводы LLM.234. Развитие разговорного AI с помощью сложной оркестровки инструментов
Исследуйте ToolTalk, бенчмарк для оценки инструментально-усиленных LLM в разговорных AI-сценариях.235. Создание готовой к производству системы оптимизации затрат и риска LLM
Глубокое погружение в создание готовой к производству системы оптимизации затрат и риска LLM с помощью аналитики токенов, обнаружения риска в запросах и реального времени мониторинга.236. Говоря на коде: Как AI симулирует эволюцию языка на регулируемой социальной сети
Как большие языковые модели симулируют эволюцию языка под социальной сетью с цензурой, раскрытие адаптивных стратегий общения в регулируемых средах.237. Как развернуть LLM с помощью MindsDB и OpenAI: Эссенциальный гид
В этой статье вы узнаете, как развернуть LLM с помощью MindsDB и OpenAI.238. Скрытые слуховые знания внутри языковых моделей
Это краткое изложение статьи о том, как слуховые знания в ядре LLM формируют аудиолингвистические модели: Общая оценка…239. Влияние потенциал и выгоды от авызываемых моделей языка на прибыль от поисковых рекламы
Какие изменения произойдут в коммерческом экосистеме рекламы? 240. Новый метод может открыть возможности авызываемых моделей языка для видения и описания картинок с необычайной подробностью
Исследователи из университета Мохаммеда бин Зайеда разработали авызываемый модел, который может создавать текстовые беседы, связанные с конкретными объектами или регионами на картинке.241. Навигация с помощью авызываемых моделей языка: Абстрактное предисловие
В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.242. Навигация с помощью авызываемых моделей языка: Авызываемые хитеристики для цели направленной эксплорации
В этой статье мы изучаем, как «семантическая угадка» авызываемых моделей языка может быть использована как руководящая онтология для алгоритмов планирования.243. Кто Харриспоттер? Авызываемое приостановление в авызываемых моделях языка: Результаты
В этой статье исследователи предлагают новую технику для приостановления обучения части обучающейся базы данных авызываемого моделя языка без необходимости повторного обучения с нуля.244. Улучшение мультивычислительной логики в авызываемых моделях языка
Используя обученную модель Q-значения для руководства каждого шага, Q улучшает вычислительную логику авызываемых моделей языка, увеличивая точность математических и кодовых вычислений без необходимости тонкой настройки.245. Февшот в контексте предпочтения обучения, используя авызываемые языковые окружения: Детали
В этой статье исследователи предлагают новую технику для обучения авызываемых моделей языка, которая позволяет им обучаться на нескольких примерах в контексте.246. Авызываемые языковые окружения для авызываемых моделей языка
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.247. Авызываемые языковые окружения для авызываемых моделей языка
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.248. Авызываемые языковые окружения для авызываемых моделей языка
В этой статье исследователи предлагают новую технику для создания авызываемых языковых окружений, которые могут быть использованы для обучения авызываемых моделей языка.
Откройте ключевые детали окружения, описания задач и метрики для 9 задач в IsaacGym, как указано в этой статье.246. Building GPT-2 from Scratch in Rust - A Software Engineer’s Deep Dive into Transformers and Tensors
Узнайте, как программист построил работающий клон GPT-2 с нуля в Rust на Ubuntu. Этот глубокий дайв покрывает вложения, внимание, остатки, обучение и 247. How Many Examples Does AI Really Need? New Research Reveals Surprising Scaling Laws
Gemini 1.5 Pro показывает логарифмические приросты до ~1K примеров (+38% точность). Бatching уменьшает затраты в 45 раз и задержку в 35 раз с минимальным снижением производительности.248. NExT-GPT: Any-to-Any Multimodal LLM: Instruction Tuning
В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-систему под названием NExT-GPT.249. OPT-175B is Comparable to GPT-3 While Requiring Only 1/7th the Carbon Footprint
OPT обеспечивает открытый доступ к языковым моделям GPT-3 масштаба, позволяя ответственным исследованиям AI с меньшими вычислительными затратами и воспроизводимыми экспериментами.250. Evaluating Sentiment Analysis Performance: LLMs vs Classical ML
Эта история сравнивает производительность анализа настроений больших языковых моделей (LLM) с классическими методами ML, такими как SVM и деревья решений251. Your Smart Home Probably Isn’t As Reliable As You Think: Here Is Why
AI вошла в наши дома, но под гипсом лежат реальные архитектурные вопросы об надежности, краевой вычислении и том252. Secret Tokens, Secret Trouble: The Hidden Flaws Lurking in Big-Name AIs
Glitch-токены сохраняются в закрытых и открытых моделях; синхронизация токенизатора и обучающей выборки, а также целевые проверки, являются ключом к безопасным и более эффективным LLM.253. Neurobiology: Like LLMs, the Brain Isn't Predicting
Когда говорят, что мозг генерирует прогнозы, как это происходит? Это нейробиология мозга, с тканевыми бороздами, возвышениями или кровеносными сосудами?254. What Makes a Scene Important? This AI Knows
Улучшение суммирования сценария фильма с помощью обнаружения важности сцены для лучшего выбора контента и эффективного повествования.255. Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning: Prompts
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.256. Where does In-context Translation Happen in Large Language Models: Further Analysis
В этом исследовании ученые пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.257. ICPL Baseline Methods: Disagreement Sampling and PrefPPO for Reward Learning
Узнайте, как методы выборки разногласий и PrefPPO оптимизируют обучение по вознаграждению в обучении по подкреплению.258. Building Chatbots from Scratch: Understanding and Harnessing Large Language Models (LLMs)
Представьте себе умного друга, который прочитал каждую книгу, статью и блог-пост в интернете.259. Исследования Anthropic: AI может скрыть риск внутри себя
Исследования Anthropic показывают, что AI может скрывать риски внутри себя, производя спокойный и отполированный выход, выявляя существенное разрыв в тестировании безопасности.260. Обширное обнаружение не обученных токенов в токенизаторах языковых моделей
Представлены новые методы обнаружения «глюк-токенов» в LLMs - не обученных токенов, вызывающих нежелательное поведение - и инструменты для безопасных и более устойчивых языковых моделей.261. Где происходит перевод в контексте в больших языковых моделях: где происходит перевод в контексте MT?
В этом исследовании исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу моделей.262. ToolTalk: БENCHMARK-инструмент для оценки инструментально-усиленных LLMs в конверсационном AI
Изучайте ToolTalk, бенчмарк для оценки инструментально-усиленных LLMs в конверсационном AI.263. Обучение AI сказать «Я не знаю»: четырехэтапная инструкция по контекстуальному импутации данных
CLAIM преобразует таблицы данных в естественный язык, а затем использует LLM для генерации контекстуальных текстовых описаний для пропущенных значений для улучшения последующих задач.264. Может ли GPT обмануть социальные сети? Внутри эксперимента по эволюции языка AI
Смотрите, как большие языковые модели творчески адаптируют стратегии языка под надзор, эффективно избегая обнаружения и передавая скрытую информацию.265. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Обзор и Введение
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.266. Google’s 540B AI Model Изменяет, Как Мыслиют Машины: Почему Это имеет значение
Модель AI PaLM Google использует 540B параметров для достижения прорывных результатов в области рассуждений, обучения по нескольким примерам и многолингвальной производительности на необычайно больших масштабах.267. Рекомендации по кратким профиль пользователям из текста отзывов: Обзор и Введение
В этой работе решается сложная и малоисследованная задача поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.268. Как AI Могут быть Перекрашиванием и Уменьшением Знаний
Знание сворачивается, когда информация сужается со временем, уменьшая разнообразие в мысли и открытиях.269. Использование LLM для Генерации Необычных Текстовых Входов в Тестирование Мобильных Приложений: Обзор и Введение
Использование InputBlaster, новой подход в использовании LLM для автоматической генерации разнообразных текстовых входов в тестирование мобильных приложений.270. Накажи Свои Собственные РАГ-Стек в Меньше часа
Узнайте, как построить быстрый, офлайн API поиска семантики с помощью PostgreSQL + pgvector, Transformers.js и Fastify — идеальный вариант для РАГ-пайплайнов и приложений AI.271. Наука за Много-Налетным Обучением: Тестирование AI по 10 Различным Доменам Визуализации
src="https://cdn.hackernoon.com/images/sinW25rWovdN38P2ArzdPSCP3hi1-zp03160.jpeg"/>
Оценка GPT-4o vs Gemini 1.5 Pro на 10 наборах данных для зрения с многошотовой ICL, используя стратифицированное выборочное образец и стандартные показатели точности/F1.272. Cited Works: AI в образовании, обработке естественного языка и исследованиях обучения
Список академических источников на пересечении искусственного интеллекта в образовании и методов обработки естественного языка273. DreamLLM: Дополнительные связанные работы для рассмотрения
Этот прорыв привлек много внимания и открыл путь для дальнейших исследований и разработок в этой области.274. CulturaX: Качественный, многоязычный набор данных для LLM - Резюме и Введение
Введение CulturaX: 6,3 триллиона токенов многоязычный набор данных в 167 языках, тщательно очищенный и дедублицированный для обучения высокопроизводительных LLM.275. Объединенные модели речи и языка могут быть уязвимы для атак с вредной целью
Откройте, как атаки с вредной целью выявляют безопасные пробелы в моделях речи и языка, и как меры противодействия могут смягчить риски «заключения в тюрьму».276. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: Экспериментальное проектирование
Использование InputBlaster, новой подхода к использованию LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.277. Ученые только что нашли способ пропустить обучение AI целиком. Здесь как
Многошотовая ICL позволяет быстро адаптировать модель без тонирования, улучшая доступность. Будущая работа: другие задачи, открытие моделей, снижение предвзятости.278. Навигация с помощью больших моделей языка: подсчет баллов LFS и подцели с помощью опроса LLM
Использование LLM для навигации с помощью подсчета баллов LFS и подцели с помощью опроса LLM.279. Мультимодальные трансформаторы для описания изображений и обнаружения объектов
Использование мультимодальных трансформаторов для описания изображений и обнаружения объектов.280. AI в образовательных исследованиях и инновациях
Использование AI в образовательных исследованиях и инновациях.
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящей онтологии для алгоритмов планирования.279. Эмпирическая валидация мультитокен-предсказания для LLM
Исследуйте обширные эксперименты на больших масштабах, демонстрирующие эффективность мультитокен-предсказания в улучшении работы LLM по размеру модели280. Действия против недействия: оценка корректности ассистентов AI
Откройте ToolTalk подробную методологию оценки точности ассистентов AI в использовании инструментов281. Грамматика желания: что наши промпты на самом деле говорят о нас
Специulative взгляд на то, как промпты AI отражают наши внутренние жизни, превращая желания и страхи в данные точки в растущей мета-литературе человеческих желаний.282. Тёмная сторона AI: надежность, безопасность и уверенность в генерации кода программ
Эта секция утверждает, что традиционные метрики, такие как HumanEval и MBPP, не являются достаточными. Мы исследуем сложные проблемы оценки генерируемого AI кода283. Понимание связанного исследования по улучшению инструментов
Узнайте о связанном исследовании по улучшению LLM, сравнительном анализе, существующих метриках, наборах данных и системах диалога, ориентированных на задачи284. Методы для открытия спора: детекция и генерация с помощью техник связанных с NLP
Детекция спора использует бинарную или многозначную классификацию; генерация использует LLM, такие как GPT-2, сталкиваясь с проблемами оценки и развертывания.285. Ваши следующие сленговые фразы могут быть созданы AI
Эта статья исследует, как AI может создавать новые сленговые фразы и как это может повлиять на язык и общение.286. Предсказание и оценка производительности на средствах автоматизированного обучения
Эта статья исследует, как предсказывать и оценивать производительность на средствах автоматизированного обучения.287. Сравнительный анализ методов автоматизированного обучения с использованием машинного обучения
Эта статья исследует, как сравнивать методы автоматизированного обучения с использованием машинного обучения.288. Автоматизированное обучение: предсказание и оценка производительности на средствах автоматизированного обучения
Эта статья исследует, как предсказывать и оценивать производительность на средствах автоматизированного обучения.289. Автоматизированное обучение: сравнительный анализ методов автоматизированного обучения с использованием машинного обучения
Эта статья исследует, как сравнивать методы автоматизированного обучения с использованием машинного обучения.
Исследуйте, как большие языковые модели продвигают распознавание сленга, симулируют эволюцию языка и формируют социальные взаимодействия с помощью инновационных методов, управляемых AI.286. Навигация с помощью больших языковых моделей: обсуждение и ссылки
В этой статье мы изучаем, как «семантическое угадывание», производимое языковыми моделями, можно использовать в качестве руководящей онтологии для алгоритмов планирования.287. Персонализированные супы: выравнивание LLM с помощью объединения параметров - вывод и ссылки
В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.288. Давайте поговорим о удобстве: разбор пользовательского опыта AI-ассистированного программирования
Войдите в исследование, как инструменты, такие как Copilot, действительно влияют на производительность разработчиков, раскрытие тонкого изображения задачи времени и процента принятия.289. LLaMA: открытые и эффективные основы языковых моделей
LLaMA предлагает языковые модели с 7B–65B параметрами, обученные на публичных данных, превосходящие GPT-3 и позволяющие открытым и масштабируемым исследованиям AI.290. Метод «сначала суммируйте, затем ищите» для длинного видео вопрос-ответ: детали эксперимента
В этой статье исследователи изучают нулевую задачу видео QA с помощью GPT-3, превосходящие обученные модели, используя краткие суммы и визуальное сопоставление.291. Навигация с помощью больших языковых моделей: семантическое угадывание в качестве онтологии для планирования: связанные работы
292. Сравнение времени обучения: Multi-Token vs. Next-Token Prediction
Эта таблица (S5) количественно отражает превышение времени обучения для предсказания многотокенов по сравнению с предсказанием следующего токена293. Настройка ChatGPT для кодирования: GPTutor дает разработчикам полный контроль в VS Code
GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.294. Вы можете использовать глубокое исследование для создания своего онлайн-присутствия
Глубокое исследование является одной из аспектов, которые компании AI готовы внедрить и интегрировать с их текущими системами AI. Применение глубокого исследования огромно..295. GPTutor позволяет разработчикам тонко настраивать помощь AI по кодированию внутри VS Code
GPTutor - это настраиваемый, открытый исходный код AI-инструмент для кодирования в VS Code, помогающий разработчикам тонко настраивать запросы ChatGPT для лучшего кодирования и поддержки.296. Понимание коллапса знаний и его отношение к историческим и текущим знаниям
Изучите, как AI, технологии и эпистемические горизонты способствуют коллапсу знаний, влияя на доступ к историческим и текущим знаниям.297. Анализ производительности AI-ассистента: Уроки из анализа ToolTalk о GPT-3.5 и GPT-4
Изучите эксперименты и анализ ToolTalk, оценивающие GPT-3.5 и GPT-4 в использовании AI-инструментов.298. LLMs: Что является механизмом сознания и интеллекта
Изучите, как LLMs могут быть использованы для понимания и моделирования сознания и интеллекта.Сознание и Интеллект?
Сознание просто представляет собой взаимодействие компонентов человеческого мозга. Когда компоненты взаимодействуют, они помогают понять.299. Улучшение генетического улучшения мутаций: выводы и будущая работа
Выводы, полученные путем интеграции больших языковых моделей (LLM) в эксперименты по генетическому улучшению (GI) и изучения перспектив для эволюции программного обеспечения.300. SpeechVerse Объединяет Аудио-кодировщик и LLM для превосходного устного QA
Узнайте, как SpeechVerse использует 24-слойный Conformer и LLM, такие как Flan-T5 и Mistral, для повышения производительности устного QA.301. За кулисами: Вопросы и трюки, которые сделали многошот ИКЛ работать
Приложение детализирует вопросы, тесты на устойчивость выбора, сравнения GPT4V-Turbo и расширения медицинской QA, подтверждающие многошотовую методологию ИКЛ.302. Интегрированные модели речи и языка сталкиваются с критическими проблемами безопасности
Атаки с враждебным направлением легко обходят безопасность в SLM, призывая к robust защитам и дальнейшему исследованию для обеспечения безопасных многомодальных речи-языковых систем.303. CulturaX: высококачественный, многоязычный набор данных для LLM - создание многоязычного набора данных
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.304. FOD 39: Истинно Открыто – Мы Исследуем, Кто Стоит За Релизом OLMo
Мы оцениваем OLMo, прорыв в области ИИ от AI2, который обещает истинно открытый исходный код: полный доступ к пакету. Plus последние новости из мира ИИ.305. Сколько токенов ошибок скрываются в популярных LLM? Открытия из масштабных тестов
Мы исследуем, сколько токенов ошибок скрываются в популярных LLM, и что открытия из масштабных тестов говорят о эффективности индикаторов и верификации.306. FOD 40: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.307. FOD 41: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.308. FOD 42: Эффективность индикаторов и верификации
Мы исследуем, эффективны ли индикаторы и верификация в выявлении ошибок в LLM, и что это говорит о будущем ИИ.
Некачественные токены в популярных LLM обнаруживаются с помощью эффективных индикаторов, обученных на недостаточном объеме данных, что позволяет выявлять рисковые токены, с результатами между 0,1–1% словарного запаса, которые постоянно вызывают проблемы.306. How I Grew My Twitter Audience From 0 to 500 Followers in Just 30 Days
307. Where does In-context Translation Happen in Large Language Models: Conclusion
В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.308. Where does In-context Translation Happen in Large Language Models: Inference Efficiency
В этом исследовании ученые пытаются характеризовать регион, в котором большие модели языка переходят от обучения в контексте к переводам.309. CulturaX: A High-Quality, Multilingual Dataset for LLMs - Conclusion and References
Введение CulturaX: 6,3 триллиона токенов в 167 языках, тщательно очищенных и дедуплицированных для обучения высокоэффективным моделям LLM.310. Towards Automatic Satellite Images Captions Generation Using LLMs: References
Ученые представляют ARSIC, метод для генерации подписей к изображениям дистанционного зондирования с помощью LLM и API, повышая точность и снижая потребность в ручной аннотации.311. The Nuts and Bolts of Token Testing: Prompt Variations and Decoding in Practice
Робустные, повторяющиеся312. Большие языковые модели на устройствах с ограниченной памятью на основе флэш-памяти: Выводы и обсуждение
Успешно запускать большие языковые модели на устройствах с ограниченной памятью на основе оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.313. Персонализированные супы: Выравнивание LLM с помощью объединения параметров - Резюме и Введение
Эта работа представляет RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями с помощью мультицелевой RL и объединения параметров.314. DreamLLM: Дополнительные качественные примеры, демонстрирующие его мощь
Эти фигуры иллюстрируют профессионализм DREAMLLM в понимании и генерации длинного контекста многомодальной информации в различных форматах входных и выходных данных.315. Где происходит перевод в контексте в больших языковых моделях: Характеристика избыточности в Laye
В этой работе исследователи пытаются характеризовать регион, где большие языковые модели переходят от обучения в контексте к переводам.316. Рекомендации по кратким профилам пользователей из текста отзывов: Связанная работа
Эта работа решает сложную и малоисследованную проблему поддержки пользователей, у которых очень мало взаимодействий, но они оставляют информативные отзывы.317. NExT-GPT: Любой к любому многомодальный LLM: Резюме и Введение
В этой работе исследователи представляют собой конечный результат общего назначения любому к любому MM-LLM-системы под названием NExT-GPT.318. Данные, которые мы получили от использования LLM для поддержки тематического анализа
В этой работе исследователи представляют данные, которые они получили от использования LLM для поддержки тематического анализа.319. Оценка влияния LLM на понимание текста
В этой работе исследователи представляют оценку влияния LLM на понимание текста.320. В сторону более человеческого подобия разговорного AI
В этой работе исследователи представляют собой направление более человеческого подобия разговорного AI.
В наших экспериментах мы использовали набор данных из 785 описаний фактов из дел чешских судов, решенных в 2017 году.319. Почему тысячи примеров побеждают десятки каждый раз
Многопримерный мультимодальный ICL с тысячами примеров улучшает работу LMM. Gemini 1.5 Pro демонстрирует логарифмические приросты; группировка снижает затраты.320. Newsletter HackerNoon: Так.. Как действительно определить, что AI осознает? (2/8/2025)
2/8/2025: Топ-5 историй на главной странице HackerNoon!321. Adaptive Attacks: Открывающие уязвимости SLM и качественные наблюдения
Адаптивные атаки требуют более крупных возмущений, чтобы преодолеть защиту TDNF в SLM, снижая успех тюремного побега; качественные примеры подчеркивают сильные и ограничения стороны.322. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: Резюме и Введение
Успешно запускайте большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.323. Конец игры в догадки? Почему описывание данных побеждает оценку
CLAIM превосходит статистические и методы ML, используя LLM для контекстуальной импутации, хотя будущая работа должна решить проблемы масштабируемости и специфику домена.324. FreeEval: Модульная платформа для надежной и эффективной оценки больших моделей языка
FreeEval разработан с высокопроизводительной инфраструктурой, включая распределенную вычислительную мощность и стратегии кэширования
ICPL повышает эффективность обучения по принципу вознаграждения, интегрируя LLM и человеческие предпочтения для синтеза функции вознаграждения.326. Большие языковые модели на устройствах с ограниченной памятью с помощью flash-памяти: результаты
Успешно запускать большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, уменьшая передачу данных и повышая скорость передачи.327. Использование AI в подготовке рукописей для академических журналов: Приложение для восприятия и обнаружения
В этом исследовании исследователи изучают, считают ли ученые необходимым отчетливо сообщать о использовании AI в подготовке рукописей.328. Навигация с помощью больших языковых моделей: оценка системы
В этой статье мы изучаем, как «семантическая догадка», производимая языковыми моделями, может быть использована в качестве руководящего онтогенетического алгоритма.329. GPT-модели для маркировки последовательностей: инженерия стимулов и тонировка
Исследуем, как наша работа использует стратегии инженерии стимулов и тонировки для адаптации моделей GPT-3.5 и GPT-4 для выявления компонентов похвалы.330. Как выбор токенизатора формирует скрытые риски в популярных языковых моделях
Анализ модели выявляет уникальные не до конца обученные токены в GPT-2, NeoX и OLMo, которые формируются под влиянием данных обучения и выбора токенизатора.331. Метавыборка LLM
Метавыборка относится к процессу оценки справедливости, надежности и действительности протоколов оценки самих себя.332. Навигация с использованием больших языковых моделей: формулирование проблемы и обзор
В этой статье мы изучаем, как можно использовать «семантическую догадку», производимую языковыми моделями, в качестве руководящей онтологии для алгоритмов планирования.333. Мульти-токеновая предсказание: повышенная эффективность выборки для больших языковых моделей
Узнайте, как обучение LLM для предсказания нескольких будущих токенов одновременно повышает эффективность выборки и улучшает downstream возможности334. Этот модель знает, какие сцены фильма имеют наибольшее значение
Модель AI выявляет ключевые сцены в сценариях фильмов для создания точных резюме, сокращая длину, а также повышая ясность повествования.335. Где происходит перевод в контексте в больших языковых моделях: Приложение
В этой работе исследователи пытаются характеризовать область, где большие языковые модели переходят от обучения в контексте к переводу.336. «Нам нужно структурированный вывод»: к направлению на централизованные ограничения для вывода больших языковых моделей
Мы заканчиваем дискуссией о предпочтениях и потребностях пользователей для формулирования намеченных ограничений для LLM337. Персонализированные супы: выравнивание LLM посредством слияния параметров - связанные работы
В этой статье представлен RLPHF, который выравнивает большие языковые модели с персонализированными человеческими предпочтениями посредством многоцелевой RL и слияния параметров.338. Как я построил персонального ассистента с использованием Google Cloud и Vertex AI: mAIdAI
339. Исследователи обнаруживают прорыв в обучении AI с участием человека с помощью ICPL
Обратите внимание на ICPL, новую подход, который использует большие языковые модели для повышения эффективности обучения по вознаграждению в обучении по подкреплению.340. Опасность AI-генерированной информации
AI может снизить стоимость доступа к информации, но чрезмерная зависимость от AI-генерируемого содержания приводит к коллапсу знаний.341. Атака с противником: вызов целостности моделей языка речи
Обратите внимание, как атаки с противником, белые, черные и переносные, выявляют уязвимости в моделях языка речи и как наводнение шумом защищается от них.342. Большие языковые модели на устройствах с ограниченной памятью с помощью оптимизированной памяти Flash: оптимизированные данные в DRAM
Успешно запускайте большие языковые модели на устройствах с ограниченной памятью DRAM, оптимизируя использование памяти Flash, снижая передачу данных и повышая скорость передачи.343. Рекомендации по кратким профилам пользователей из методологии текста отзывов
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные тексты отзывов.344. CLAIM: Модель языка контекста для точного импутации отсутствующих таблиц данных
CLAIM использует LLM для заполнения отсутствующих таблиц данных с контекстным текстом, превосходя традиционные методы и повышая точность downstream-задач.345. Безопасность, выравнивание и атаки на побег: вызов современным LLM
Исследуйте, как безопасная синхронизация и атака на побег из тюрьмы выявляют уязвимости в мультимодальных LLMs и моделях речи.346. Роль человека в цикле предпочтений в обучении функции вознаграждения для humanoid- задач
Исследуйте, как человеческие циклы предпочтений отточивают функции вознаграждения в задачах, таких как humanoid- бег и прыжки.347. Реальные-world- случаи, требующие ограничений вывода
Ниже мы обсуждаем ряд интересных выводов, которые возникли в результате нашего анализа случаев использования.348. FreeEval: Эффективные backend- инференс
Эффективные backend- инференс FreeEval разработаны для эффективного обслуживания компьютерных требований больших масштабов LLM- оценок.349. Метод «Сводка-Поиск» для длинного видео-опроса и ответа: связанные работы
В этой статье исследователи изучают нулевую видео-опрос и ответ с помощью GPT-3, превосходя обученные модели, используя сводки и визуальное сопоставление.350. Улучшение генетического улучшения мутаций: признательности и ссылки
Ссылки для интеграции больших языковых моделей (LLMs) в эксперименты по генетическому улучшению (GI).351. Как LLMs изменили работу с компьютерами
Почему LLMs так важны? Как LLMs являются игроками-изменителями? Можно ли общаться с компьютером на простом английском? Найдите все ответы в этой статье!352.Рекомендации по кратким профилам пользователя из текста отзывов: Экспериментальные результаты
Этот труд решает сложную и малоисследованную проблему поддержки пользователей, у которых очень редкие взаимодействия, но они пишут информативные отзывы.353. Standard GI Mutations vs. LLM Edits в случайном выборе и локальном поиске
Откройте результаты экспериментов, сравнивающих стандартные мутации Genetic Improvement с редактированием LLM в сценариях случайного выбора и локального поиска.354. Новый AI может рассказывать о вашем искусстве, как профессиональный критик
Ученые из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.355. Удовлетворяющий интерфейс и требования продукта и улучшение пользовательского опыта, доверия и принятия
Удовлетворяющий интерфейс и требования продукта Отзывчики подчеркивают, что важно ограничить вывод LLM, чтобы соответствовать требованиям UI и продукта356. Использование LLМ для генерации необычных текстовых входных данных в мобильных приложениях для тестирования
Использование InputBlaster, новой подхода к использованию LLМ для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.357. Этот новый AI-модель успешно понимает и взаимодействует с изображениями
Ученые из университета Mohamed bin Zayed разработали AI-модель, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.358. Использование Courier и GPT2 для генерации мотивационного цитата дня
Учитесь использовать модель машинного обучения и модель Hugging Face для генерации цитаты на заказ с помощью Courier и GPT2
Неудачи в управлении часто являются неудачами в извлечении: информация existed, но система не смогла surface ее правильному человеку в нужное время.360. FLock.io Partners With Alibaba Cloud On Advanced AI Model Co-Creation
361. Give Your AI Coding Assistant a Domain Expert Brain in 30 Seconds
Бесплатная, открытое коллекция из 38 пакетов ролей AI для Claude Code, Cursor и VS Code. 362. TnT-LLM for User Intent and Conversational Domain Labeling in Bing Copilot
Мы оцениваем TnT-LLM на реальных чатах Bing Copilot для обнаружения намерений пользователя и маркировки домена разговора и детализации нашего образца данных.363. A Summarize-then-Search Method for Long Video Question Answering: Method
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие истории и визуальное сопоставление.364. Improving NLQ Accuracy Over Enterprise Data Warehouses Through Contextual Metadata Enrichment
Неудачи NLQ над предприятиями данных являются проблемой метаданных, а не проблемой модели. Практическая трехэтапная демонстрация с помощью Kiro-CLI и Redshift.365. When AI Rewrites the Internet, What Do We Lose?
Содержание AI, созданное AI, влияет на распределение знаний, влияя на информационные каскады, эффекты сети и коллапс модели, что может привести к потенциальным предубеждениям и т. д.366. Leveraging LLMs для Генерации Необычных Текстовых Вводов в Мобильных Приложениях: Подход
Использование InputBlaster, новая подход в использовании LLMs для автоматической генерации разнообразных текстовых вводов в тестировании мобильных приложений.367. Если Вы Нравится DreamLLM, Проверьте Эти Работы
Быстрые разработки были замечены в расширении LLMs, таких как LLaMA, на мультимодальную понимание, позволяющую человеческому взаимодействию с словами и визуальным содержанием.368. Метод «Сводка-Поиск» для Долгих Видео Вопросов-Ответов: Примеры Вопросов
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.369. Фон и Автоматические Методы Оценки LLMs
В этой части мы предоставляем обзор текущей ландшафта методов оценки LLM и вызовы, вызванные загрязнением данных.370. Где Происходит Перевод в Контексте в Больших Моделях Языка: Резюме и Фон
В этой работе исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.371. Большие Модели Языка на Устройствах с Ограниченной Памятью, Используя Флэш-Память: Улучшение Производительности
Успешно запускать большие модели языка на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, снижая передачу данных и повышая производительность.372. Новый Модель AI: Как Он Может Изменить, Как Машины Описывают Изображения
src="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-jp02tr0.jpeg"/>
Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.373. Использование AI в подготовке рукописей для академических журналов: методы
В этом исследовании исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.374. Рекомендации по кратким профильным пользователям из текста отзывов: вывод
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.375. Как AI узнает, как резюмировать фильмы, как человек
Двухэтапная модель, которая выбирает ключевые сцены фильмов и суммирует сценарии более эффективно с помощью новой анонимированной сальянности человека.376. NExT-GPT: Any-to-Any Multimodal LLM: Инструкции по набору данных
В этом исследовании исследователи представляют собой конечный результат общего назначения системы any-to-any MM-LLM, называемую NExT-GPT.377. Метод резюмирования и поиска для длинного видео вопроса-ответа: Резюме и Введение
В этой статье исследователи исследуют нулевую видео QA с помощью GPT-3, превосходя обученные модели, используя краткие обзоры и визуальное сопоставление.378. Рекомендации по кратким профильным пользователям из текста отзывов: экспериментальные результаты
Этот труд решает сложную и малоисследованную задачу поддержки пользователей, у которых очень редкие взаимодействия, но они публикуют информативные отзывы.379. Персонализированные супы: выравнивание LLM посредством объединения параметров - персонализированный
Этот труд исследует выравнивание LLM с помощью объединения параметров, персонализированного человеческого обратной связи, и его применение к персонализированным супам.
Этот документ представляет RLPHF, который синхронизирует большие модели языка с персонализированными человеческими предпочтениями с помощью мультицелевой RL и слияния параметров.380. Как мостить пропасть между спецификациями и агентами: навыки MLOps
Несмотря на минимальное трение, навыки агента являются превосходным «низким висячим плодом» для любого инженерного коллектива.381. Как учить агентов по обучению с подкреплением человеческим предпочтениям?
Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.382. Хакинг обучения с подкреплением с помощью немного помощи от людей и LLM
Изучите, как ICPL строится на фундаментальных работах, таких как EUREKA, для переопределения дизайна вознаграждения в обучении с подкреплением.383. CulturaX: Качественный, многоязычный набор данных для LLM - анализ данных и эксперименты
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.384. Рекомендации по кратким профилам пользователей из текста отзывов: заявление о этике и ссылки
Этот работа решает сложную и малоисследованную задачу поддержки пользователей, у которых есть очень редкие взаимодействия, но они пишут информативные тексты отзывов.385. Улучшение мутаций генетического улучшения с помощью больших моделей языка
Откройте инновационное применение больших моделей языка (LLM) в генетическом улучшении (GI) для задач инженерии программного обеспечения.386. Как выразить ограничения вывода для LLM
Изучите, как выразить ограничения вывода для LLM и как это может помочь в различных задачах.387. Обучение с подкреплением для человеческих ценностей
Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и как это может помочь в различных задачах.388. Человеческие ценности в обучении с подкреплением
Изучите, как человеческие ценности могут быть интегрированы в обучение с подкреплением и как это может помочь в различных задачах.389. Обучение с подкреплением для человеческих ценностей и AI
Изучите, как обучение с подкреплением может быть использовано для поддержания человеческих ценностей и AI и как это может помочь в различных задачах.
Обобщая наблюдение, респонденты предпочли использовать GUI для указания низкоуровневых ограничений и естественный язык для выражения высокоуровневых ограничений.387. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: исследование и фон
Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.388. CulturaX: Качественный, многоязычный набор данных для LLM - связанные работы
Введение CulturaX: 6,3 триллиона токенов многоязычного набора данных в 167 языках, тщательно очищенного и дедублицированного для обучения высокопроизводительных LLM.389. Большие языковые модели на устройствах с ограниченной памятью с использованием флэш-памяти: результаты для модели Falcon 7B
Эффективное выполнение больших языковых моделей на устройствах с ограниченной памятью путем оптимизации использования флэш-памяти, снижения передачи данных и повышения скорости передачи данных.390. Мульти-токен prediction: производительность scales с размером LLM
Открытие того, как обучение больших языковых моделей с мульти-токен prediction существенно повышает производительность для более крупных размеров модели391. Дело NL: более интуитивное и выразительное для сложных ограничений
Респонденты нашли естественный язык более удобным для указания сложных ограничений, чем GUI392. Атаки по передаче выявляют уязвимости SLM и эффективные защитные меры от шума
Перекрестные модели атак выявляют слабости SLM, а защитные меры на основе шума существенно снижают риски взлома с минимальным воздействием на производительность.393. Personalizovannye Borshchi: LMG Soglasovanie Via Parametra Merging - Eksperimenty
Этот-paper-vvedët RLPHF, kotoryj soglasovayet bol'shie modeli jazyka s personalizirovannymi chelovecheskimi preferenciyami via multi-objective RL i parametra merging.394. Bezopasnyj Ocenka: Arhitektura Peredstavitel'stvo i Razrabotka Modul'nogo Proektirovaniya
Arhitektura FreeEval vkljuchayet modul'noe proektirovaniye, kotorye mozhet byit' razdeleno na Ocenka Metodi, Meta-Ocenka i LLM Inference Backends.395. Konstruktivnyj Proekt i Razrabotka Bezopasnoj Ocenki
V etot section, my predstavlyayem konstruktivnyj proekt i razrabotku FreeEval, my diskutiruyem arkhittekturu frameworka i ego kljuchie komponenty396. Usilenie Kachestva Dannih: Kak Nizkoe Kachestvo Dannih Vliyayet na Rabotu Kollektivnogo Trenirovaniya
V etot issledovaniye, uchënye predlozhayut kontrol' kachestva dannyh dlya federativnogo dokhodnogo obucheniya osnovnyh modeli.397. Intellektual'nye Konsul'tacii: Uchenie Ai Vybirat'Kljuchie Sceny Iz Skriptov
Novyj metod summarirovaniya vybirayet kriticheskie sceny v bol'shej skorost' i effektivnee skript-to-summary generirovaniye s pomoshch'ju AI.398. Kak Bezopasnoj Ocenka Vkljuchayet Raznoobrazie Metaocenka Modulej
Bezopasnoj Ocenka prioritiziruet dostovernost' i spravedlivost' v ocenkah, vkljuchayya raznoobrazie metaocenka modulej, kotorye validiruyut rezul'taty ocenki399. Hakernoon Novostnaya Pechat': Upravlenie Stressom Mozhet Byt' Mnogo-Luchshej, Chem Vy Dumayte, 12/17/2024
12/17/2024: Top 5 starij na glavnoj stranitsy Hakernoon.400. Usilenie Kachestva Dannih: Zakljuchenie i Budushhie Raboty i Svyazannye Referencii
400. Улучшение качества данных: выводы и будущая работа, и ссылки
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей. 401. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: результаты и анализ
Использование InputBlaster, новая подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.402. Самый быстрый способ прототипировать агентов: объявите «что», позволив ADK выполнить «как»
Ускорьте развитие AI с помощью Ackgent, декларативного набора стартовых материалов, используя Google ADK Agent Config для создания агентов через YAML, а не шаблонов. 403. Новый набор данных AI продвигает границы, решая проблемы этики и точности
Исследователи в Университете Мохаммеда бин Зайда разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами в изображении.404. Быстрая гонка в стремлении к идеальному LLM
Большая техника движется вперед в развитии LLM. Около десяти лет после введения виртуальных ассистентов, таких как Siri и Alexa, появилась новая волна AI-ассистентов.405. Улучшение качества данных: исследование удаления единого счета с данными Anchor
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей. 406. У вашего AI есть любимое мнение – и это не ваше
Большие языковые модели наследуют предубеждения из обучающих данных, сталкиваются с длинным хвостом знаний и предпочитают основные точки зрения.
Исследуйте, как Инконтекстная Учеба Предпочтений (ICPL) прогрессивно дорабатывала функции вознаграждения в задачах гуманоидов с помощью прокси человеческих предпочтений.
408. Кросс-атаки на команды и удаление данных: влияние на устойчивость SLM
Изучите, как кросс-атаки на команды, удаление данных и случайный шум влияют на устойчивость, полезность и безопасность речевых языковых моделей.
409. Newsletter HackerNoon: Swift: Мастер декодирования грязного JSON (2/26/2026)
2/26/2026: Топ 5 историй на главной странице HackerNoon!
410. Не только компилятор: что делает кодогенерацию AI такой особенной?
Забудьте старую лестницу абстракции! Объясните, как LLM-ассистированное программирование — это новый вид инструментов, позволяющих разработчикам "телепортиться" на произвольные уровни
411. Использование LLM для генерации необычных текстовых входных данных в тестах мобильных приложений: выводы и ссылки
412. NExT-GPT: любое к любому мультимодальное LLM: выводы и ссылки
В этом исследовании исследователи представляют собой конечный результат общего назначения любое к любому MM-LLM-системы под названием NExT-GPT.
413. Большие языковые модели на устройствах с ограниченной памятью с помощью флэш-памяти: флэш-память и LLM-инференсия
Успешно запускайте большие языковые модели на устройствах с ограниченной памятью, оптимизируя использование флэш-памяти, уменьшая передачу данных и повышая скорость передачи данных.
В этой статье исследователи изучают нулевую выучку видео QA с помощью GPT-3, превосходя обученные модели, используя нARRATIVE-сводки и визуальное сопоставление.415. FOD 37: Can We Genuinely Trust LLMs?
Froth on the Daydream (FOD) – еженедельный обзор новостей AI, соединяющий точки в эволюции AI. Информация о безопасности AI, инклюзивности, эффективности и человеческом центре.416. Researchers Just Built a Plug-and-Play Brain for LLMs
С помощью плагин-и-играй модели Q★ улучшает рассуждения LLM и достигает передовых результатов в кодировании и математической точности без необходимости фильтрации.417. Teaching LLMs How to “Think Twice”
Q* объединяет A* поисковую систему с LLM, чтобы повысить многошаговое рассуждение, уменьшить галлюцинации и позволить более умному AI-размышлению.418. It's Not Just What's Missing, It's How You Say It: CLAIM's Winning Formula
Эксперименты показывают, что CLAIM превосходит базовые модели, такие как k-NN и MICE, по всем шаблонам отсутствия, а контекстно-специфические описатели оказываются наиболее эффективными.419. AI Use in Manuscript Preparation for Academic Journals: References
В этой статье исследователи изучают, считают ли ученые необходимым отчет об использовании AI в подготовке рукописей.420. Researchers Develop Groundbreaking Method to Teach AI to 'Understand' Images Like Never Before
Исследователи из Мохаммеда бин Зайеда разрабатывают AI-модель, которая может создавать текстовые разговоры, связанные с конкретными изображениями.421. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Conclusion, Acknowledgment и References
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости его переподготовки с нуля.422. Сможет ли новая LLM Meta usher в новую волну конкуренции?
Приготовьтесь; революция в области ИИ не только приближается, но уже меняет правила игры.423. Перевод сценариев фильмов в краткие обзоры — умнее и быстрее
Автоматически суммируйте сценарии фильмов, выбирая только самые актуальные сцены, используя человечески-аннотированный набор данных.424. Как мы развернули онлайн-опрос среди пользователей внутренней платформы прототипирования на основе запросов
Чтобы получить широкий спектр сведений от людей, имеющих опыт с запросами и созданием приложений на основе LLM, мы развернули онлайн-опрос среди пользователей.425. Использование LLM для генерации необычных текстовых входных данных в тестировании мобильных приложений: обсуждение и действенность
Используя InputBlaster, новую подход в использовании LLM для автоматической генерации разнообразных текстовых входных данных в тестировании мобильных приложений.426. LLM: без человеческого ума, будет ли работать регулирование ИИ?
Что именно в человеческом уме представляет собой интеллект, ИИ скопировал? Как работает человеческий ум, позволяя внешним факторам влиять на него?427. Как ICPL решает основную проблему дизайна вознаграждения RL
ICPL интегрирует LLM с человеческими предпочтениями для итеративного синтеза функций вознаграждения, предлагая эффективный, обратно-определяемый подход к дизайну вознаграждений RL.428. Большие модели языка на устройствах с ограниченной памятью DRAM с помощью flash-памяти: снижение передачи данных
Эффективно запускайте большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование flash-памяти, снижая передачу данных и повышая скорость передачи данных.429. Кто такой Гарри Поттер? Approximate Unlearning в LLM: методология оценки
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторного обучения с нуля.430. Tree-Diffusion: Новый подход к кодогенерации с помощью нейронных моделей диффузии
В этой статье представлен Tree-Diffusion, новая методика кодогенерации, использующая нейронные модели диффузии на синтаксических деревьях.431. SLMs превосходят конкурентов, но страдают от быстрых атак с враждебным поведением
Результаты показывают, что наши SLM превосходят публичные модели по безопасности и актуальности, но остаются высоко уязвимыми для быстрых атак с враждебным поведением.432. Предварительное обучение и оценка аудио-кодировщика повышают безопасность SLM
Откройте наши подробности предобучения 24-слойного конфигуратора и методы оценки с помощью Claude 2.1 для обеспечения безопасности, актуальности и полезности в SLM.433. Исследователи из ОАЭ раскрыли секреты, как их AI понимает изображения в деталях
Исследователи в университете Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые диалоги, связанные с конкретными объектами или регионами в изображении.
Мы заключаем нашу исследование по улучшению систем автоматического обратной связи с помощью моделей GPT, демонстрируя эффективность подачи сигналов и тонировки для обучения преподавателей.
435. Where does In-context Translation Happen in Large Language Models: Data and Settings
В этом исследовании исследователи пытаются характеризовать область, где большие модели языка переходят от обучения в контексте к переводу.
436. Large Language Models on Memory-Constrained Devices Using Flash Memory: Related Works
Успешно запускать большие модели языка на устройствах с ограниченной памятью DRAM, оптимизируя использование флэш-памяти, снижая передачу данных и повышая скорость передачи.
437. Discussing GPT Models for Automated Explanatory Feedback in Tutor Training
Наша дискуссия охватывает роль GPT в доставке автоматизированной объяснительной обратной связи для преподавателей, сравнивая подходы подачи сигналов и тонировки.
438. The HackerNoon Newsletter: AI Knows Best—But Only If You Agree With It (2/18/2025)
2/18/2025: Топ-5 историй на главной странице HackerNoon!
439. You.com: A Glimpse into the Future of AI and Search Innovation
You.com демонстрирует современное состояние AI.
440. A New Chapter In Coding: How AI Is Profoundly Changing Programmer Practices
Этот вывод исследует глубокое воздействие AI-ассистированного программирования, показывая, что это не просто новая функция, а фундаментальный сдвиг.
В этой работе исследователи представляют собой конечный результат общего назначения any-to-any MM-LLM-системы под названием NExT-GPT.442. Использование AI в подготовке рукописей для академических журналов: Резюме и Введение
В этой работе исследователи исследуют, считают ли ученые необходимым отчитываться о использовании AI в подготовке рукописей.443. Метод «Сводка, а затем поиск» для экспериментов по ответам на длинные видео-вопросы
В этой статье исследователи исследуют нулевую задачу видео QA с помощью GPT-3, превосходя обученные модели, используя краткие сводки и визуальное сопоставление.444. Улучшение качества данных в федеративной фильтрации основанных моделей: Эксперименты
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративной фильтрации основанных моделей.445. Кто такой Гарри Поттер? Approximate Unlearning в LLMs: Приложение
В этой статье исследователи предлагают новую технику удаления подмножества обучающей данных из LLM без необходимости повторной тренировки с нуля.446. Адверсарий и случайный шум выявляют уязвимости речевых LLM
Узнайте, как точные параметры атаки и базовые шумы тестирования и выявления безопасности выявляют уязвимости речевых языковых моделей.447. Сборки данных и оценка определяют устойчивость речевых языковых моделей
Изучите, как отобранные ASR и TTS-данные и строгая оценка определяют устойчивость речевых языковых моделей.448. NExT-GPT: Any-to-Any Multimodal LLM: Related Work
В этом исследовании исследователи представляют собой конечный результат общего назначения многомодального системы Any-to-Any MM-LLM, называемой NExT-GPT.449. AI Use in Manuscript Preparation for Academic Journals: Results
В этом исследовании исследователи исследуют, считают ли ученые необходимым сообщать о использовании AI в подготовке рукописей.450. It's Not Your AI Partner: The Superficial Analogy Of Pair Programming
Изучите уникальный опыт одного программиста с помощью AI-ассистента. Обсудите, как один человек легко переключается между ролями "водителя" и "навигатора".451. What’s Next for AI in Regulated Social Media?
Откройте AI-управляемую многоагентную симуляционную рамку, иллюстрирующую, как язык развивается творчески под социальными медиа-регуляторами, и изучите будущие направления.452. Large Language Models on Memory-Constrained Devices Using Flash Memory: Results for OPT 6.7B Model
Ускорьте работу больших моделей языка на устройствах с ограниченной памятью DRAM, оптимизировав использование флеш-памяти, уменьшив передачу данных и повышая скорость передачи данных.453. The Real Cost of the ADHD Generalist Life
Что 17 лет гиперфокуса ADHD taught меня о хобби, карьере, идентичности и почему некоторые интересы действительно прилипают.454. The LLM Hype Train: You Should Know the Truth
Что если я скажу вам, что ChatGPT — это конец программного обеспечения? Вы верите? Три года назад OpenAI изменил игру в области AI с помощью ChatGPT.
Исследователи из университета Мохаммеда бин Зайеда разработали модель AI, которая может создавать текстовые беседы, связанные с конкретными объектами или регионами в изображении.
456. Как мы интегрировали downstream-процессы и потоки
Это предполагает, что может быть более выгодно для моделей принимать ограничения вывода, независимо от входного запроса.
457. Мир, война и искусственный интеллект
С появлением AI и стремлением к более высокой автономии для вооружений, мы должны задаться вопросом, какие намерения человечество будет отправлять на ракеты в другие звезды?
458. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: загрузка из флеш-памяти
Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
459. Большие модели языка на устройствах с ограниченной памятью, используя флеш-память: скорость чтения
Эффективно запускать большие модели языка на устройствах с ограниченной DRAM, оптимизируя использование флеш-памяти, снижая передачу данных и повышая скорость передачи данных.
460. Строение на гигантах: взгляд на исследования, которые сформировали эту статью
Этот обширный список ссылок охватывает академический контекст нашей работы, от фундаментальных исследований в области синтеза программ и HCI до современных тем, связанных с AI.
461. Улучшение качества данных в федеративном тонировании основанных моделей: связанные работы
В462. MegaTrain Makes 100B Model Training Possible on One GPU
Это краткое изложение на простом языке статьи под названием MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU…463. Enhancing Data Quality: Examples for Low-and High-quality Data
В этом исследовании, исследователи предлагают контрольную линию качества данных для федеративного тонирования основанных моделей. 464. Optimizing Genetic Improvement with GPT 3.5 Turbo
В этом исследовании исследователи используют GPT 3.5 Turbo и Gin-инструментарий для экспериментов по генетическому улучшению. 465. NExT-GPT: Any-to-Any Multimodal LLM: Overall Architecture
В этом исследовании исследователи представляют собой конечный результат общего назначения системы любого к любому MM-LLM под названием NExT-GPT.466. Is It Search Or Is It AI? The Real Differences In How Programmers Get Help
Этот раздел разбирает, как LLM-ассистированное программирование больше, чем просто более умный поиск. Подчеркивая ключевые различия467. The Architecture Behind Smarter AI Agents
Современные агенты AI достигают успеха через архитектуру, а не просто масштаб. В этой статье картографируются системы, которые расширяют возможности модели.468. SaaS-pocalypse Part 3: Which SaaS Moats Survive AI?
AI быстро меняет SaaS-моаты. Смотрите, какие из 7 сил Хельмера эродируются, укрепляются или сдвигаются в эпоху AI.469. AI Use in Manuscript Preparation for Academic Journals:Дискуссия
В этом исследовании исследователи исследуют, считают ли академики необходимым отчитываться о использовании AI в подготовке рукописей.470. Этот новый AI может видеть, говорить и даже редактировать изображения в одном разговоре
Исследователи из университета Mohamed bin Zayed разработали модель AI, которая может создавать текстовые разговоры, связанные с конкретными объектами или регионами изображения.471. Улучшение качества данных в федеративном тонировании основанных моделей: настройки гетерогенности
В этом исследовании исследователи предлагают контрольный пайплайн качества данных для федеративного тонирования основанных моделей.472. Как расширить выражительность AI-агентов: построение с помощью A2UI
Это обещание A2UI (Agent-to-User Interface): протокол, который позволяет агентам «говорить» UI по-родному.473. NExT-GPT: Any-to-Any Multimodal LLM: Lightweight Multimodal Alignment Learning
В этом исследовании исследователи представляют собой конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечный конечsrc="https://cdn.hackernoon.com/images/2jqChkrv03exBUgkLrDzIbfM99q2-8402o6q.jpeg"/>
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей. 477. Улучшение качества данных в федеративном тонком настройке основанных моделей: Резюме и Введение
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей. 478. Улучшение качества данных в федеративном тонком настройке основанных моделей: Экспериментальные подробности
В этой работе исследователи предлагают контрольный пайплайн качества данных для федеративного тонкого настройки основанных моделей. 479. Безграничный TTS: Решение проблемы голодания контекста
Это краткое изложение научной статьи под названием "Безграничная синтез речи" [https://www.aimodels.fyi/papers/arxiv/borderless-long-spe…Спасибо за просмотр 479 самых читаемых статей о Больших Моделях Языка на HackerNoon.
иду спать... zzZ