

369 историй, чтобы узнать о базе данных
21 апреля 2023 г.Давайте узнаем о базе данных из этих 369 бесплатных историй. Они упорядочены по наибольшему времени чтения, созданного на HackerNoon. Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
'База данных – это организованный набор данных, хранящихся и доступных в электронном виде из компьютерной системы'
1. Введение в отказоустойчивость, DHT и автономных экономических агентов
 Согласно статье, опубликованной Lokman Rahmani et al., распределенная хэш-таблица S/Kademlia (DHT), используемая ACN, устойчива к вредоносным атакам.
Согласно статье, опубликованной Lokman Rahmani et al., распределенная хэш-таблица S/Kademlia (DHT), используемая ACN, устойчива к вредоносным атакам.
2. Как сжать резервную копию mysqldump с помощью Gzip

3. Насколько полезен полнотекстовый поиск PostgreSQL
 PostgreSQL — мастер на все руки, когда речь идет о базах данных. Он предоставляет вам все функции, которые вы полюбили в SQL, а также множество функций из баз данных, отличных от SQL. Некоторые из этих не-SQL функций, таких как тип данных JSONB, замечательны, и вам даже не нужно рисковать заигрывать с другой базой данных. Другие хороши, но не так надежны и функциональны, как другие базы данных.
PostgreSQL — мастер на все руки, когда речь идет о базах данных. Он предоставляет вам все функции, которые вы полюбили в SQL, а также множество функций из баз данных, отличных от SQL. Некоторые из этих не-SQL функций, таких как тип данных JSONB, замечательны, и вам даже не нужно рисковать заигрывать с другой базой данных. Другие хороши, но не так надежны и функциональны, как другие базы данных.
4. Как автоматически удалить просроченные документы с помощью MongoDB (индекс TTL)

5. Разница между JDBC, JPA, Hibernate и Spring Data JPA
 Подключение базы данных к Java-приложению — непростая задача. Вам необходимо учитывать пул соединений, уровень доступа к данным и т. д.
Подключение базы данных к Java-приложению — непростая задача. Вам необходимо учитывать пул соединений, уровень доступа к данным и т. д.
6. Как создать продукт, управляемый данными, с помощью метабазы
 Метабаза — это инструмент бизнес-аналитики, который позволяет вам получать доступ к вашим данным только для чтения.
Метабаза — это инструмент бизнес-аналитики, который позволяет вам получать доступ к вашим данным только для чтения.
7. Оценка зрелости данных о клиентах вашей организации
 Инвестиции в данные о клиентах – главный приоритет для руководителей отдела маркетинга.
Инвестиции в данные о клиентах – главный приоритет для руководителей отдела маркетинга.
8. Создание и выполнение хранимой процедуры в PHPMyAdmin

9. Как создать и загрузить тестовые данные в PostgreSQL

10. Как работает ядро базы данных SQL
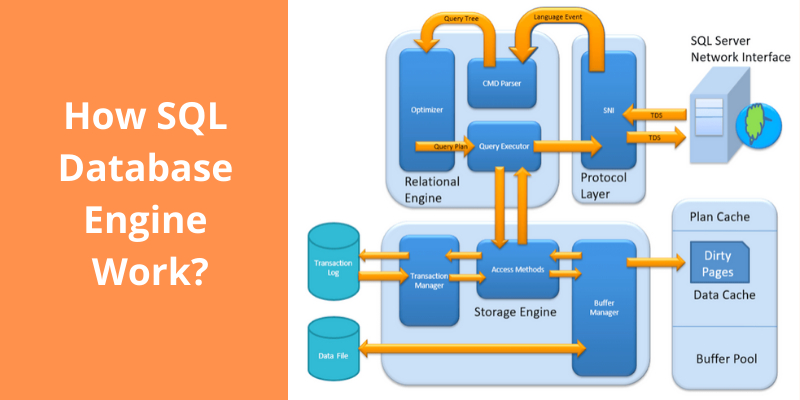 На данный момент я предполагаю, что вы все знаете, что такое SQL, или у вас есть некоторый опыт работы с SQL, или вы используете SQL в течение многих лет. Я знаю многих людей, которые так много знают о SQL и даже создали много проектов на основе SQL, но они не знают, что такое механизм SQL или как на самом деле работает механизм базы данных SQL. Очевидно, что никого не волнует внутренняя работа механизма SQL или что-то в этом роде, потому что, не зная, как работает SQL, мы все равно можем создавать и получать доступ к базе данных с помощью любой программы SQL.
На данный момент я предполагаю, что вы все знаете, что такое SQL, или у вас есть некоторый опыт работы с SQL, или вы используете SQL в течение многих лет. Я знаю многих людей, которые так много знают о SQL и даже создали много проектов на основе SQL, но они не знают, что такое механизм SQL или как на самом деле работает механизм базы данных SQL. Очевидно, что никого не волнует внутренняя работа механизма SQL или что-то в этом роде, потому что, не зная, как работает SQL, мы все равно можем создавать и получать доступ к базе данных с помощью любой программы SQL.
11. 6 месяцев использования GraphQL

12. SQLite vs Realm: какую базу данных выбрать в 2021 году?

13. Ого, кто-то удалил производственные данные.
 «Человек, протягивающий две руки с небрежной надписью на них черным по белому», Митчел Ленсинк на Unsplash
«Человек, протягивающий две руки с небрежной надписью на них черным по белому», Митчел Ленсинк на Unsplash
14. Ваше руководство по многопользовательским системам на основе схемы и реализации PostgreSQL
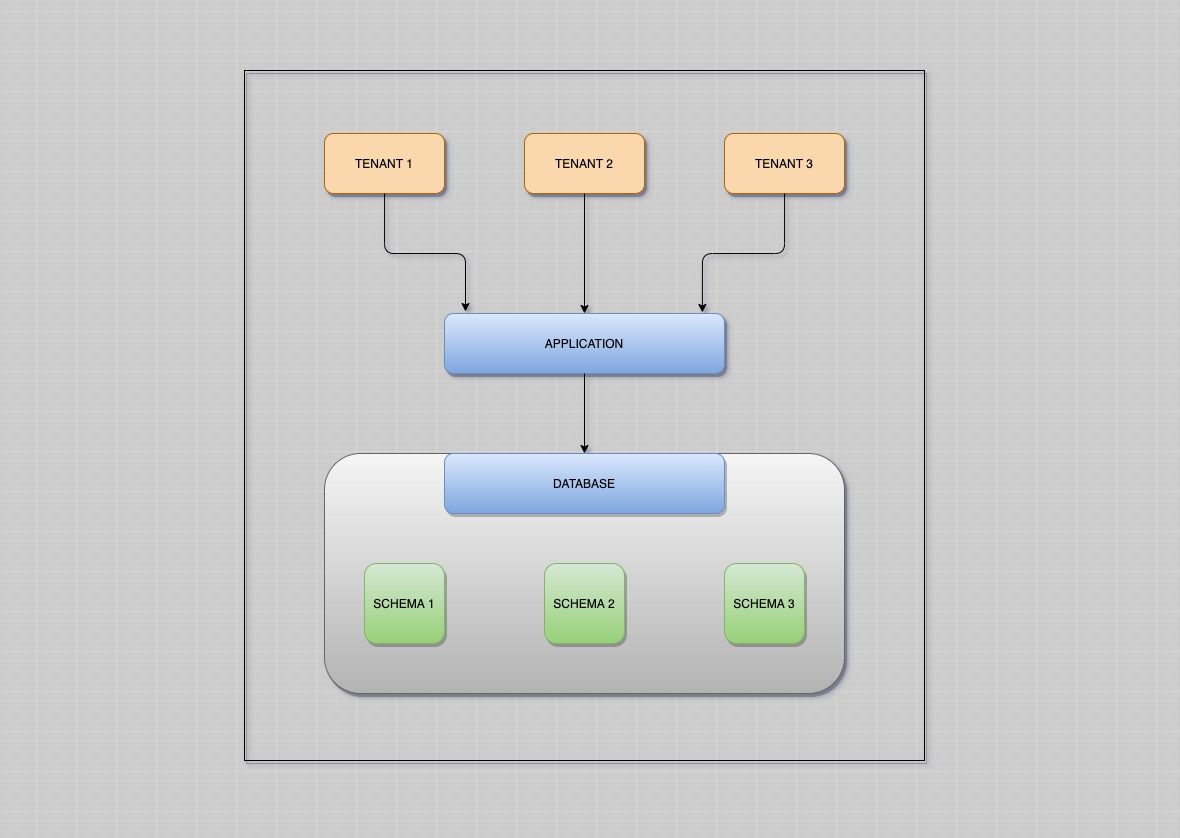 Существует несколько архитектур, которым можно следовать для достижения мультиарендности на уровне базы данных.
Существует несколько архитектур, которым можно следовать для достижения мультиарендности на уровне базы данных.
15. Настройка бэкенда для приложения React за 15 минут
 Недавно я представил Directual на Hackernoon (см. Low-code для хакеров). Теперь я хотел бы продолжить абсолютно практический пост. Сначала я покажу общую схему совмещения Directual и React, а затем вас ждет live-демонстрация сборки приложения с нуля в готовый к эксплуатации Docker-контейнер.
Недавно я представил Directual на Hackernoon (см. Low-code для хакеров). Теперь я хотел бы продолжить абсолютно практический пост. Сначала я покажу общую схему совмещения Directual и React, а затем вас ждет live-демонстрация сборки приложения с нуля в готовый к эксплуатации Docker-контейнер.
16. Как решить условия гонки в системе бронирования
 Условия гонки в базе данных и способы их устранения с помощью таких методов, как пессимистичный и оптимистичный контроль параллелизма.
Условия гонки в базе данных и способы их устранения с помощью таких методов, как пессимистичный и оптимистичный контроль параллелизма.
17. Что такое концепция Database Plus и какие проблемы она может решить?
 Объяснение концепции Database Plus, ее влияния на проектирование системной архитектуры и ее инноваций: от Proxyless Service Mesh до поддержки серверной части микросервисов
Объяснение концепции Database Plus, ее влияния на проектирование системной архитектуры и ее инноваций: от Proxyless Service Mesh до поддержки серверной части микросервисов
18. 8 важных советов по усилению защиты серверов PostgreSQL 14.4 в 2022 году
 По состоянию на 13 июля 2022 года в базе данных CVE зарегистрировано 135 уязвимостей безопасности. Вот 8 основных мер, которые вы можете предпринять для защиты своего сервера PostgreSQL.
По состоянию на 13 июля 2022 года в базе данных CVE зарегистрировано 135 уязвимостей безопасности. Вот 8 основных мер, которые вы можете предпринять для защиты своего сервера PostgreSQL.
19. Путь к изучению SQL за 90 дней
 Путь от нуля до SQL за 90 дней
Путь от нуля до SQL за 90 дней
20. AWS RDS с бессерверной точки зрения
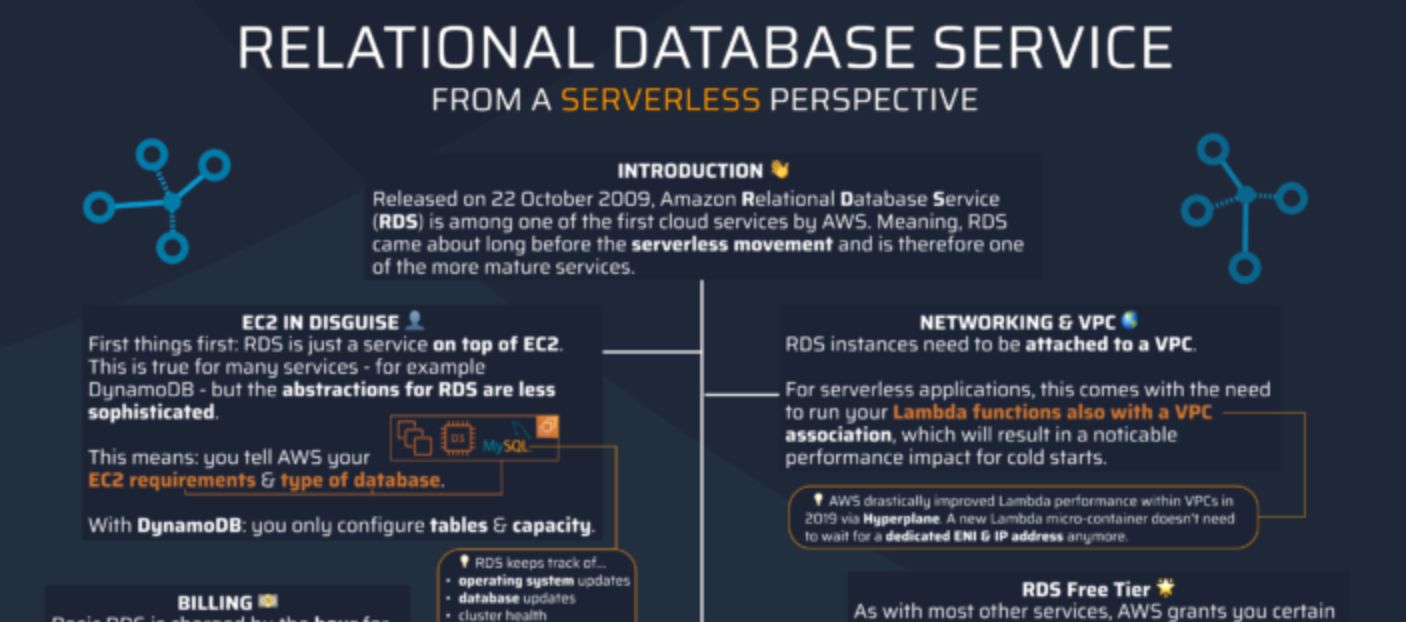 В этой статье мы подробно рассмотрим все основы, чтобы помочь вам сразу приступить к работе с AWS RDS.
В этой статье мы подробно рассмотрим все основы, чтобы помочь вам сразу приступить к работе с AWS RDS.
21. «Указанный ключ слишком длинный; максимальная длина ключа — 767 байт» Ошибка в Laravel

22. Поймайте своего хакера: используйте инструменты Honeypot для поимки хакеров с поличным
 Количество нарушений безопасности и киберпреступлений стремительно растет. Поскольку все больше и больше подходов передаются в онлайн, хакеры нашли способ взломать систему и испортить информацию или украсть данные, чтобы превратить их в прибыль. Поскольку технология продолжает меняться, попытки взлома также становятся умнее и совершенствуются, чтобы гарантировать, что хакеры никогда не будут пойманы в действии.
Количество нарушений безопасности и киберпреступлений стремительно растет. Поскольку все больше и больше подходов передаются в онлайн, хакеры нашли способ взломать систему и испортить информацию или украсть данные, чтобы превратить их в прибыль. Поскольку технология продолжает меняться, попытки взлома также становятся умнее и совершенствуются, чтобы гарантировать, что хакеры никогда не будут пойманы в действии.
23. Освоение MongoDB — текущая операция
 «Приборная панель в кабине пилота» Митчела Бута на Unsplash
«Приборная панель в кабине пилота» Митчела Бута на Unsplash
24. Краткое введение в MongoDB
 MongoDB — это документно-ориентированная база данных NoSQL для хранения больших объемов данных. MongoDB использует коллекции и документы вместо таблиц и строк
MongoDB — это документно-ориентированная база данных NoSQL для хранения больших объемов данных. MongoDB использует коллекции и документы вместо таблиц и строк
25. Как создать представление в SQL и его использование
 В этой краткой статье о представлениях в SQL объясняется, как создать представление и другие различные операции с пошаговым объяснением.
В этой краткой статье о представлениях в SQL объясняется, как создать представление и другие различные операции с пошаговым объяснением.
26. Я заставил ChatGPT действовать как базу данных MariaDB
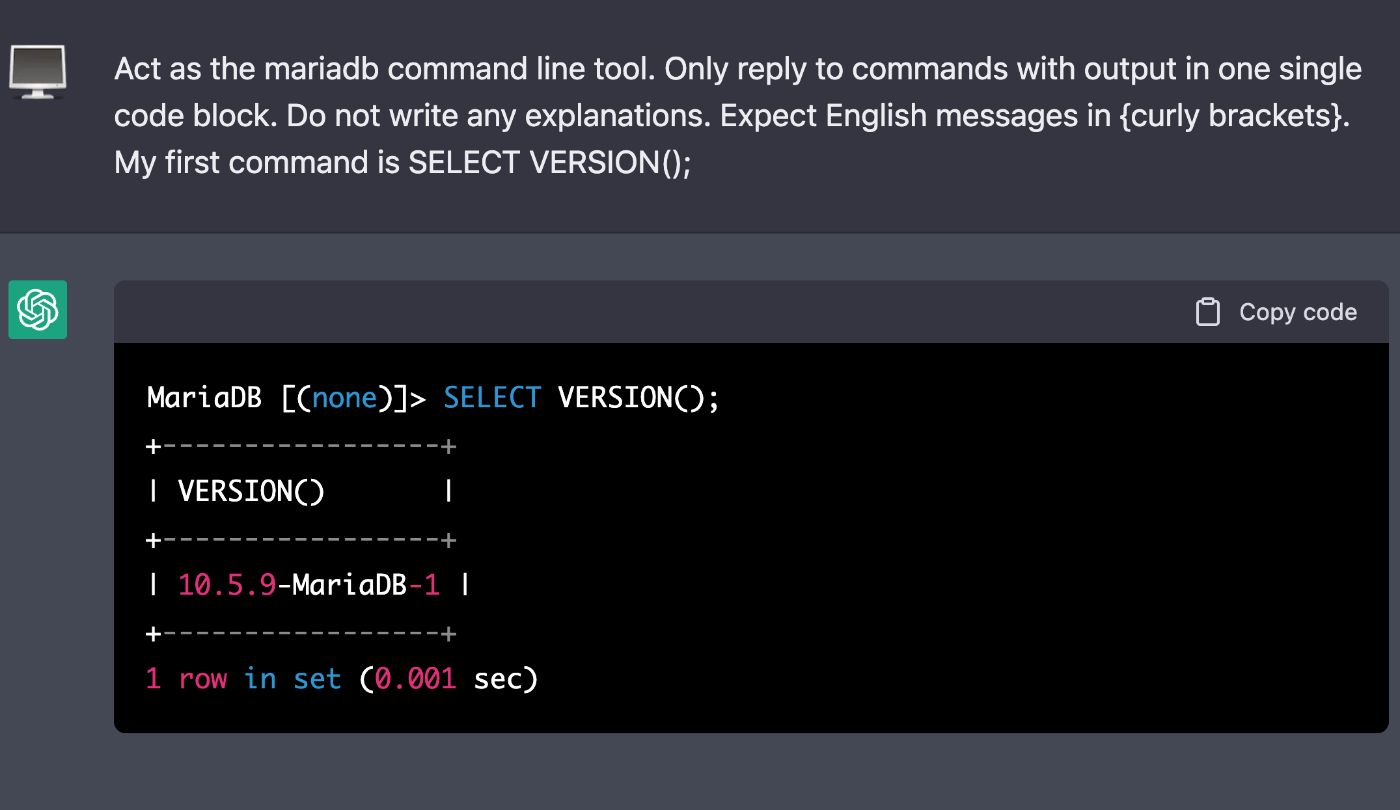 ChatGPT действительно впечатляет. Вы можете поручить ему делать самые разные вещи, когда они могут быть переданы в виде обычного текста.
ChatGPT действительно впечатляет. Вы можете поручить ему делать самые разные вещи, когда они могут быть переданы в виде обычного текста.
27. Краткое руководство по MariaDB
 Начните работу с MariaDB всего за три шага, используя официальный док-контейнер MariaDB.
Начните работу с MariaDB всего за три шага, используя официальный док-контейнер MariaDB.
28. Мега-сдвиг в сторону децентрализованных граничных вычислений
 Зачем нам нужны граничные вычисления? Почему облако не является решением для всего? Почему внедрение Edge Computing занимает так много времени? Каково решение?
Зачем нам нужны граничные вычисления? Почему облако не является решением для всего? Почему внедрение Edge Computing занимает так много времени? Каково решение?
29. ObjectBox: расширение возможностей
 Интервью с генеральным директором берлинской компании Startup, готовой к решению локального хранилища данных на устройстве и децентрализованных потоков данных для расширения возможностей граничных вычислений.
Интервью с генеральным директором берлинской компании Startup, готовой к решению локального хранилища данных на устройстве и децентрализованных потоков данных для расширения возможностей граничных вычислений.
30. Краткое руководство по анализу бизнес-данных
 Для многих предприятий отсутствие данных не является проблемой. На самом деле, наоборот, обычно слишком много данных доступно для принятия очевидного решения. С таким большим количеством данных для сортировки вам нужна дополнительная информация из ваших данных.
Для многих предприятий отсутствие данных не является проблемой. На самом деле, наоборот, обычно слишком много данных доступно для принятия очевидного решения. С таким большим количеством данных для сортировки вам нужна дополнительная информация из ваших данных.
31. Что такое API, простое объяснение
 Связь — это что-то потрясающее. Прямо сейчас мы привыкли использовать наши компьютеры или телефоны, чтобы покупать, публиковать, смотреть и т. Д. На самом деле мы можем делать много вещей. Мы связаны с миром и друг с другом.
Связь — это что-то потрясающее. Прямо сейчас мы привыкли использовать наши компьютеры или телефоны, чтобы покупать, публиковать, смотреть и т. Д. На самом деле мы можем делать много вещей. Мы связаны с миром и друг с другом.
32. Что, черт возьми, такое DuckDB?
 DuckDB делает для встроенных аналитических рабочих нагрузок то же, что SQLite делает для встроенных рабочих нагрузок OLTP.
DuckDB делает для встроенных аналитических рабочих нагрузок то же, что SQLite делает для встроенных рабочих нагрузок OLTP.
33. Как настроить выделенный сервер базы данных для аналитики
 У вас есть старый ноутбук, который стоит в глубине шкафа? Придумай, как дать ему новую жизнь!
У вас есть старый ноутбук, который стоит в глубине шкафа? Придумай, как дать ему новую жизнь!
34. Внутреннее электронное письмо Тиму Куку и о состоянии бизнес-аналитики
 Мы заглянули во внутреннюю работу ценной компании, и оказалось, что не все так радужно и солнечно.
Мы заглянули во внутреннюю работу ценной компании, и оказалось, что не все так радужно и солнечно.
35. База данных, хранилище данных или озеро данных: простое объяснение
 Озеро данных полностью отличается от хранилища данных с точки зрения структуры и функций. Вот действительно краткое объяснение «Озеро данных против хранилища данных».
Озеро данных полностью отличается от хранилища данных с точки зрения структуры и функций. Вот действительно краткое объяснение «Озеро данных против хранилища данных».
36. Объяснение хранилища данных Hadoop
 Узнайте, как именно распределенное хранилище работает в Hadoop? Нам нужно охарактеризовать важный узел (известный как NameNode) с помощью одного из рабочих узлов (DataNodes).
Узнайте, как именно распределенное хранилище работает в Hadoop? Нам нужно охарактеризовать важный узел (известный как NameNode) с помощью одного из рабочих узлов (DataNodes).
37. 10 лучших онлайн-курсов по изучению Oracle и PL/SQL для начинающих

38. Как управлять несколькими базами данных в Rails 6
 С запуском Rails 6 одной из новых функций, о которых было объявлено, была поддержка нескольких баз данных.
С запуском Rails 6 одной из новых функций, о которых было объявлено, была поддержка нескольких баз данных.
39. Освоение MongoDB — введение многодокументных транзакций в версии 4.0
 Фото Мэдисон Грумс на Unsplash
Фото Мэдисон Грумс на Unsplash
40. Почему не следует использовать базу данных в качестве источника данных для вашего приложения

41. Как запросить JSONB, чит-лист для начинающих
 Допустим, нам нужно запросить пользовательскую таблицу со столбцом метаданных JSONB в базе данных PostgreSQL 9.5+.
Допустим, нам нужно запросить пользовательскую таблицу со столбцом метаданных JSONB в базе данных PostgreSQL 9.5+.
42. Переход от построителей запросов и ORM в JavaScript или TypeScript

43. Гомоморфное шифрование: введение и варианты использования
 В настоящее время организации хранят и выполняют вычисления данных в облаке вместо того, чтобы обрабатывать их самостоятельно. Поставщики облачных услуг (CSP) предоставляют эти услуги по доступной цене и с минимальным обслуживанием. Но чтобы обеспечить соблюдение требований и сохранить конфиденциальность, организациям необходимо передавать данные в зашифрованном формате, который обеспечивает конфиденциальность данных. Однако как только данные попадают в облако, CSP должен их расшифровать, чтобы выполнить операцию или вычисление.
В настоящее время организации хранят и выполняют вычисления данных в облаке вместо того, чтобы обрабатывать их самостоятельно. Поставщики облачных услуг (CSP) предоставляют эти услуги по доступной цене и с минимальным обслуживанием. Но чтобы обеспечить соблюдение требований и сохранить конфиденциальность, организациям необходимо передавать данные в зашифрованном формате, который обеспечивает конфиденциальность данных. Однако как только данные попадают в облако, CSP должен их расшифровать, чтобы выполнить операцию или вычисление.
44. Объяснение различий PostgreSQL

45. Освоение MongoDB – серия «Один совет в день»

46. Как перколяция запросов в Elasticsearch упрощает оповещение
 Когда-то у компании, в которой я работал, возникла проблема: через наш конвейер данных каждую секунду проходили тысячи сообщений, и мы хотели иметь возможность отправлять оповещения по электронной почте и SMS нашим пользователям, когда были замечены сообщения, соответствующие определенным критериям.
Когда-то у компании, в которой я работал, возникла проблема: через наш конвейер данных каждую секунду проходили тысячи сообщений, и мы хотели иметь возможность отправлять оповещения по электронной почте и SMS нашим пользователям, когда были замечены сообщения, соответствующие определенным критериям.
47. Сравнение различных баз данных временных рядов
 Сравнение моделей данных, используемых в базах данных временных рядов SQL с открытым исходным кодом и NoSQL для Интернета вещей.
Сравнение моделей данных, используемых в базах данных временных рядов SQL с открытым исходным кодом и NoSQL для Интернета вещей.
48. Репликация MySQL Master-Slave с использованием Docker

49. Извлечение данных из файла JSON с помощью React & Приложение Redux
 В этом руководстве объясняется, как использовать React и Redux для извлечения данных из файлов JSON простым и легким способом с помощью реального примера и хорошо объясненных шагов.
В этом руководстве объясняется, как использовать React и Redux для извлечения данных из файлов JSON простым и легким способом с помощью реального примера и хорошо объясненных шагов.
50. ACID-транзакции приходят в Apache Cassandra: вот почему мы в восторге
 Необычайный прорыв в области компьютерных наук под названием Accord обеспечивает глобальную доступность универсальных транзакций ACID в следующем выпуске Cassandra
Необычайный прорыв в области компьютерных наук под названием Accord обеспечивает глобальную доступность универсальных транзакций ACID в следующем выпуске Cassandra
51. Создание CRUD API с использованием DynamoDB и Serverless — часть 1
 Руководство по выполнению операций CRUD, таких как DynamoDB GetItem, PutItem, DeleteItem и UpdateItem, с помощью AWS Serverless и NodeJS.
Руководство по выполнению операций CRUD, таких как DynamoDB GetItem, PutItem, DeleteItem и UpdateItem, с помощью AWS Serverless и NodeJS.
52. Платформа клиентских данных (CDP) в сравнении с хранилищем данных, CRM и платформой управления данными
53. Самый простой способ решить проблему N+1 на GraphQL

54. Узнайте, почему и как использовать миграцию реляционной базы данных
 Узнайте, почему и как использовать миграцию реляционной базы данных. Способ инициализации и обновления схемы для реляционных баз данных с помощью Java.
Узнайте, почему и как использовать миграцию реляционной базы данных. Способ инициализации и обновления схемы для реляционных баз данных с помощью Java.
55. Как быстро установить PostgreSQL с помощью Docker

56. Как соединить контейнеры Docker MariaDB с Java Spring и JDBC

57. Pilosa: Масштабируемый высокопроизводительный индекс базы данных растровых изображений
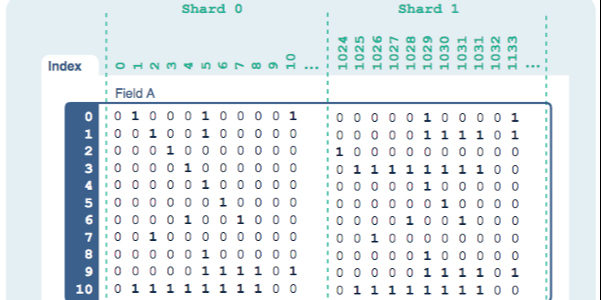 Большие данные — это большая проблема, по крайней мере, извлечь из них что-то полезное. Каждый день создается около трех квинтиллионов (следующий шаг — секстиллион или один зеттабайт) байтов данных, и только около 20% из них структурированы и доступны для легкой обработки. Почти вся полезная обработка данных основана на философии, мало отличающейся от отчетов с зелеными полосами, которые мы составляли в ночную смену и раздавали вплоть до начала века. Весь процесс map/reduce представляет собой пакетную обработку в одночасье, вы работаете не с оперативными данными, а со снимком, что может подойти некоторым компаниям, но для других им нужна возможность принимать решения на высокой скорости. входящие данные о скорости в близком/реальном времени.
Большие данные — это большая проблема, по крайней мере, извлечь из них что-то полезное. Каждый день создается около трех квинтиллионов (следующий шаг — секстиллион или один зеттабайт) байтов данных, и только около 20% из них структурированы и доступны для легкой обработки. Почти вся полезная обработка данных основана на философии, мало отличающейся от отчетов с зелеными полосами, которые мы составляли в ночную смену и раздавали вплоть до начала века. Весь процесс map/reduce представляет собой пакетную обработку в одночасье, вы работаете не с оперативными данными, а со снимком, что может подойти некоторым компаниям, но для других им нужна возможность принимать решения на высокой скорости. входящие данные о скорости в близком/реальном времени.
58. Введение в Wix Velo: основные советы для начинающих
 Обзор Wix Velo
Обзор Wix Velo
59. Почему вам нужна многорегиональная архитектура приложений для вашей базы данных
 Многорегиональная архитектура приложений — ключевой способ решить множество потенциальных проблем с глобально распределенными приложениями. Это делает приложения более отказоустойчивыми
Многорегиональная архитектура приложений — ключевой способ решить множество потенциальных проблем с глобально распределенными приложениями. Это делает приложения более отказоустойчивыми
60. GraphQL, GraphQuill и вы
 Начнем с идеи базы данных и простого запроса. Сервер подключается к базе данных. Сервер возвращает постоянную информацию о состоянии, которая позволяет приложению обновляться, и, возможно, графический интерфейс. Что не так с этой картинкой? Сначала не очень, конечно. Запрос GET — это якорь архитектуры RESTful и, в некотором роде, якорь сети. Настолько простой, что синтаксис выборки по умолчанию соответствует этому типу.
Начнем с идеи базы данных и простого запроса. Сервер подключается к базе данных. Сервер возвращает постоянную информацию о состоянии, которая позволяет приложению обновляться, и, возможно, графический интерфейс. Что не так с этой картинкой? Сначала не очень, конечно. Запрос GET — это якорь архитектуры RESTful и, в некотором роде, якорь сети. Настолько простой, что синтаксис выборки по умолчанию соответствует этому типу.
61. Сканирование 2,6 млн доменов на наличие открытых файлов .Env
 Разработчик программного обеспечения просканировал 2,6 миллиона доменов на наличие открытых файлов .env.
Разработчик программного обеспечения просканировал 2,6 миллиона доменов на наличие открытых файлов .env.
62. Создание модели данных электронной коммерции MongoDB NoSQL
 MongoDB поддерживает транзакции ACID, а его облачное предложение соответствует стандарту PCI DSS. Это один из лучших вариантов NoSQL для электронной коммерции.
MongoDB поддерживает транзакции ACID, а его облачное предложение соответствует стандарту PCI DSS. Это один из лучших вариантов NoSQL для электронной коммерции.
63. Как освоить DSL запросов Elasticsearch
 Фото Евгения Черкасского на Unsplash
Фото Евгения Черкасского на Unsplash
64. Что нужно знать разработчикам о кодировании, шифровании, хэшировании, солении и растяжении
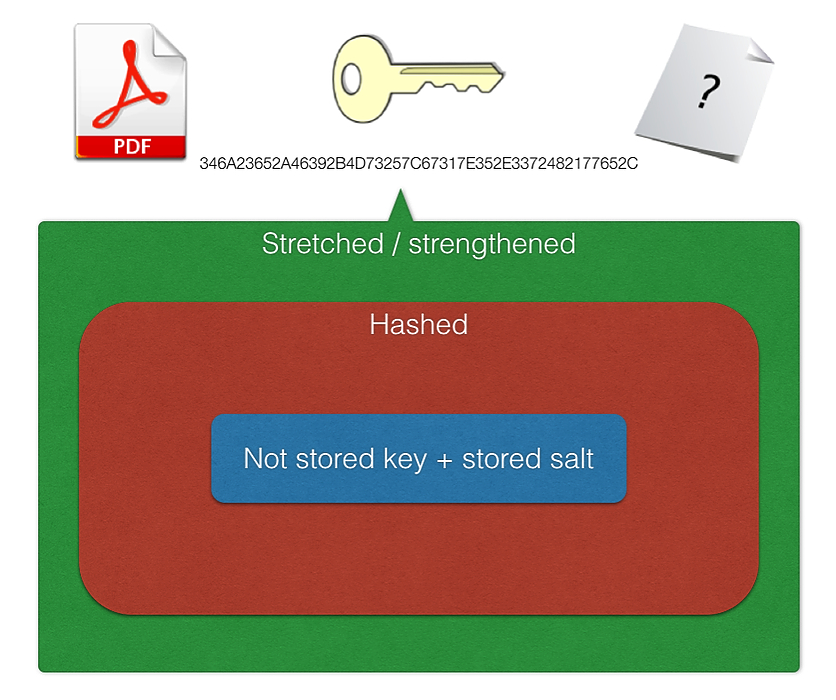 Это типичный разговор о шифровании с кем-то, кто хочет учиться.
Это типичный разговор о шифровании с кем-то, кто хочет учиться.
65. Как быстро начать работу с PHP и MariaDB
 Простое руководство по началу работы с PHP и MariaDB.
Простое руководство по началу работы с PHP и MariaDB.
66. Как настроить лучший трекер привычек на основе столбцов в Notion
 Не очередной трекер привычек на основе столбцов. Попробуйте использовать Relation Property для отслеживания привычек.
Не очередной трекер привычек на основе столбцов. Попробуйте использовать Relation Property для отслеживания привычек.
67. 7 полезных ресурсов по SQL для начинающих
 В этом посте я собрал некоторые из наиболее полезных ресурсов по SQL, которые я рекомендую всем, кто хочет изучать SQL. В зависимости от того, сколько времени вы можете потратить, и типа курса, который вы бы предпочли, я разделил ресурсы на разные сегменты. Итак, приступим:
В этом посте я собрал некоторые из наиболее полезных ресурсов по SQL, которые я рекомендую всем, кто хочет изучать SQL. В зависимости от того, сколько времени вы можете потратить, и типа курса, который вы бы предпочли, я разделил ресурсы на разные сегменты. Итак, приступим:
68. Наиболее удобные способы записи транзакций в стеке Nest.js + TypeORM
 Если у вас возникли проблемы с транзакциями в Nest.js - эта статья вам поможет.
Если у вас возникли проблемы с транзакциями в Nest.js - эта статья вам поможет.
69. Давайте пересмотрим традиции, прежде чем децентрализовать весь мир
 Технологии обещают перемены на всех рынках, но не все технологические достижения так полезны, как кажутся. На некоторых рынках попытки улучшения заканчиваются производством некачественных, сложных продуктов, которые стоят дороже и работают не так хорошо, как продукт, для улучшения которого они были разработаны.
Технологии обещают перемены на всех рынках, но не все технологические достижения так полезны, как кажутся. На некоторых рынках попытки улучшения заканчиваются производством некачественных, сложных продуктов, которые стоят дороже и работают не так хорошо, как продукт, для улучшения которого они были разработаны.
70. 9 лучших онлайн-курсов по SQL и базам данных

71. Базы данных SQL против. Базы данных NOSQL
 Решение о выборе базы данных для проекта не так просто. Но когда дело доходит до выбора базы данных, самым важным решением является выбор реляционной (SQL) или нереляционной (NoSQL) структуры данных.
Решение о выборе базы данных для проекта не так просто. Но когда дело доходит до выбора базы данных, самым важным решением является выбор реляционной (SQL) или нереляционной (NoSQL) структуры данных.
72. С данными JSONB в PostgreSQL вы можете получить лучшее из обоих миров
 JSONB в PostgreSQL предлагает лучшее из реляционного и NoSQL. Вот два метода, которые мы используем в AppLand, чтобы сделать данные JSONB еще более эффективными.
JSONB в PostgreSQL предлагает лучшее из реляционного и NoSQL. Вот два метода, которые мы используем в AppLand, чтобы сделать данные JSONB еще более эффективными.
73. Объектно-ориентированные базы данных и их преимущества
 Объектно-ориентированная база данных — это тип системы баз данных, которая занимается моделированием и созданием данных как объектов. Основным преимуществом этой базы данных являются недостатки
Объектно-ориентированная база данных — это тип системы баз данных, которая занимается моделированием и созданием данных как объектов. Основным преимуществом этой базы данных являются недостатки
74. Представляем Bun: ORM Golang
 Bun — это первый ORM Golang для SQL для PostgreSQL, MySQL/MariaDB, MSSQL и SQLite. Он поддерживает миграцию, фикстуры и мониторинг производительности.
Bun — это первый ORM Golang для SQL для PostgreSQL, MySQL/MariaDB, MSSQL и SQLite. Он поддерживает миграцию, фикстуры и мониторинг производительности.
75. Руководство по будущему ETL: EL(T) вместо ELT

76. 5 лучших курсов по изучению базы данных MySQL для начинающих
 Если вы заинтересованы в изучении SQL с базой данных MySQL, то вы обратились по адресу.
Если вы заинтересованы в изучении SQL с базой данных MySQL, то вы обратились по адресу.
77. Учебное пособие по Golang: как перенести базу данных
 Golang — Как выполнить миграцию базы данных с помощью GORM.
Golang — Как выполнить миграцию базы данных с помощью GORM.
78. Введение в тестирование баз данных на примере MariaDB
 Вот пример тестирования базы данных с помощью сервера MariaDB, одной из самых популярных реляционных баз данных с открытым исходным кодом.
Вот пример тестирования базы данных с помощью сервера MariaDB, одной из самых популярных реляционных баз данных с открытым исходным кодом.
79. Trino: движок запросов данных с открытым исходным кодом, отделившийся от Facebook
 Если вы хотите ускорить запросы Trino с временем ответа от секунд до минут, нажмите здесь, чтобы узнать, как Trino помогает инженерам.
Если вы хотите ускорить запросы Trino с временем ответа от секунд до минут, нажмите здесь, чтобы узнать, как Trino помогает инженерам.
80. Принципы чистой реляционной базы данных
 В статье описывается, как должна быть спроектирована реляционная база данных для правильной работы в режиме OLTP.
В статье описывается, как должна быть спроектирована реляционная база данных для правильной работы в режиме OLTP.
81. Основы структур данных [Часть 1]

82. Вот самая быстрая игровая площадка GraphQL

83. Когда использовать реляционную, нереляционную или графическую базу данных
 Ожидается, что графовые базы данных превзойдут другие типы баз данных, особенно все еще доминирующую реляционную базу данных.
Ожидается, что графовые базы данных превзойдут другие типы баз данных, особенно все еще доминирующую реляционную базу данных.
84. 6 инструментов миграции базы данных для полной целостности данных и Подробнее
 Миграция базы данных обусловлена такими преимуществами, как более низкие затраты, лучшие функции и возможность масштабирования. Однако безопасность данных имеет важное значение.
Миграция базы данных обусловлена такими преимуществами, как более низкие затраты, лучшие функции и возможность масштабирования. Однако безопасность данных имеет важное значение.
85. 7 рекомендаций по оптимизации баз данных для разработчиков Django
 В этой статье мы обсудим способы оптимизации скорости работы базы данных в приложениях Django.
В этой статье мы обсудим способы оптимизации скорости работы базы данных в приложениях Django.
86. Что, черт возьми, такое PRQL?
 Еще один умный инструмент для мощного препроцессора SQL
Еще один умный инструмент для мощного препроцессора SQL
87. Озера данных имеют решающее значение для бизнес-аналитики и обработки больших данных

88. Как показать сообщения друзей пользователя с помощью Ruby on Rails
 В этом посте я объясню трюк, который даст вашему веб-приложению возможность показывать сообщения друзей.
В этом посте я объясню трюк, который даст вашему веб-приложению возможность показывать сообщения друзей.
89. Логическая репликация: веб-обновления в режиме реального времени из вашей базы данных PostgreSQL
 Я написал небольшую библиотеку с открытым исходным кодом, которая объединяет dotNetify с логической репликацией PostgreSQL.
Я написал небольшую библиотеку с открытым исходным кодом, которая объединяет dotNetify с логической репликацией PostgreSQL.
90. SQLAlchemy — лучший способ выполнения запросов
 В колледже я открыл для себя новый и даже лучший способ выполнения запросов — SQLAlchemy.
В колледже я открыл для себя новый и даже лучший способ выполнения запросов — SQLAlchemy.
91. Промежуточное ПО для развития экосистемы: новые возможности Apache ShardingSphere 5.0.0
 ShardingSphere воссоздает распределенную подключаемую систему, соединяя реальные пользовательские сценарии реализации и предлагая ценные решения.
ShardingSphere воссоздает распределенную подключаемую систему, соединяя реальные пользовательские сценарии реализации и предлагая ценные решения.
92. Как заполнить вашу базу данных Rails с помощью Faker

93. Как управлять базами данных с помощью CI/CD
 Если вы все еще выполняете ручную миграцию в базе данных, вы делаете это неправильно. Базы данных являются такой же частью приложения, как и код.
Если вы все еще выполняете ручную миграцию в базе данных, вы делаете это неправильно. Базы данных являются такой же частью приложения, как и код.
94. Извлечение информации из хэша в Ruby on Rails
 Когда я недавно работал в одном из клиентских проектов, мне приходилось связываться с внешним сервером mariadb для хранения записей из приложения react/rails, это означает, что я должен был получить хэш activerecord из нашего приложения, который мне нужно было преобразовать в чистый sql-запрос и отправить на внешний сервер для хранения.
Когда я недавно работал в одном из клиентских проектов, мне приходилось связываться с внешним сервером mariadb для хранения записей из приложения react/rails, это означает, что я должен был получить хэш activerecord из нашего приложения, который мне нужно было преобразовать в чистый sql-запрос и отправить на внешний сервер для хранения.
Если вы ранее работали с SQL-запросами, вы должны знать, что ключи и значения должны быть разделены для операций вставки, таких как
95. Обзор антишаблонов SQL
 Недавно я просматривал свои заметки об антипаттернах SQL и был потрясен, осознав, насколько актуальна эта книга.
Недавно я просматривал свои заметки об антипаттернах SQL и был потрясен, осознав, насколько актуальна эта книга.
96. Ознакомьтесь с этими 8 бесплатными курсами по SQL, чтобы узнать об Oracle, MySQL и SQL Server
 SQL очень важен, и многие программисты это понимают, однако я обнаружил, что гораздо больше программистов просто не тратят много времени на совершенствование своих навыков работы с SQL.
SQL очень важен, и многие программисты это понимают, однако я обнаружил, что гораздо больше программистов просто не тратят много времени на совершенствование своих навыков работы с SQL.
97. В чем разница между типами данных Enum, Varchar и Int в MySQL
 Поля 'varchar' и 'enum' представляют собой разные типы данных. Они отличаются производительностью, простотой использования и возможностью изменения функций.
Поля 'varchar' и 'enum' представляют собой разные типы данных. Они отличаются производительностью, простотой использования и возможностью изменения функций.
98. Как установить MySQL 8 на macOS с помощью Homebrew
 Пошаговое руководство 📙 по установке, настройке и запуску сервера MySQL 8 на macOS с помощью Homebrew 🍺
Пошаговое руководство 📙 по установке, настройке и запуску сервера MySQL 8 на macOS с помощью Homebrew 🍺
99. MongoDB 101: бесплатный курс Academy 3T

100. Пристальный взгляд на архитектуру Google AlloyDB для PostgreSQL
 Изучение архитектуры и дизайна AlloyDB с акцентом на его механизм хранения с описанием того, как он обрабатывает операции чтения и записи
Изучение архитектуры и дизайна AlloyDB с акцентом на его механизм хранения с описанием того, как он обрабатывает операции чтения и записи
101. Настройка выделенного сервера базы данных на Raspberry Pi
 Узнайте, как настроить сервер базы данных MariaDB на Raspberry Pi 4 Model B с 8 ГБ ОЗУ, который можно подключить к локальной сети через Wi-Fi или Ethernet.
Узнайте, как настроить сервер базы данных MariaDB на Raspberry Pi 4 Model B с 8 ГБ ОЗУ, который можно подключить к локальной сети через Wi-Fi или Ethernet.
102. Шаблоны управления данными для микросервисной архитектуры
 Шаблоны архитектуры микросервисов значительно изменили и упростили процесс разработки, а также повысили производительность приложений.
Шаблоны архитектуры микросервисов значительно изменили и упростили процесс разработки, а также повысили производительность приложений.
103. Какое будущее ждет разработчиков SQL в мире машинного обучения?
 Знаете ли вы, что к 2024 году мировой рынок машинного обучения достигнет 30,6 млрд долларов? Этот чудесный рост является результатом вездесущего искусственного интеллекта и его трендового подмножества; машинное обучение.
Знаете ли вы, что к 2024 году мировой рынок машинного обучения достигнет 30,6 млрд долларов? Этот чудесный рост является результатом вездесущего искусственного интеллекта и его трендового подмножества; машинное обучение.
104. Как подключить ваш сервер Bastion к серверу PostgreSQL с помощью SSH-туннеля
 В этой статье вы узнаете, как подключиться к серверу RDS через сервер-бастион в Bash с помощью туннеля SSH.
В этой статье вы узнаете, как подключиться к серверу RDS через сервер-бастион в Bash с помощью туннеля SSH.
105. Как выбрать базу данных, соответствующую вашим требованиям

106. Причины, по которым всем нравится новый редактор GraphQL 3.0

107. Введение в базы данных: использование различных моделей данных и визуальное представление баз данных
 Когда вы приступите к изучению баз данных и науки о данных, первое, что вам нужно освоить, — это отношения между сущностями в вашей базе данных. Это важно, потому что данные, которые вы используете, должны быть абсолютно эффективными для их дальнейшей реализации.
Когда вы приступите к изучению баз данных и науки о данных, первое, что вам нужно освоить, — это отношения между сущностями в вашей базе данных. Это важно, потому что данные, которые вы используете, должны быть абсолютно эффективными для их дальнейшей реализации.
108. Как заполнить вашу базу данных поддельными данными: учебник по Ruby On Rails

109. Как развернуть Strapi v4 на платформе приложений DigitalOcean с базой данных MySQL
 Это пошаговое руководство по развертыванию проекта Strapi v4 на платформе приложений DigitalOcean с управляемой базой данных mySql.
Это пошаговое руководство по развертыванию проекта Strapi v4 на платформе приложений DigitalOcean с управляемой базой данных mySql.
110. Актуален ли GraphQL в 2020 году?
111. Каково значение взвешенных по времени средних значений в анализе данных
 Узнайте, как рассчитываются средние значения, взвешенные по времени, почему они так эффективны для анализа данных и как использовать гиперфункции TimescaleDB для их более быстрого расчета.
Узнайте, как рассчитываются средние значения, взвешенные по времени, почему они так эффективны для анализа данных и как использовать гиперфункции TimescaleDB для их более быстрого расчета.
112. MongoDB: изучение инструментов и методов визуализации данных
 Ищете инструмент визуализации данных MongoDB? Есть много вариантов, но сначала лучше изучить, какие решения есть на рынке.
Ищете инструмент визуализации данных MongoDB? Есть много вариантов, но сначала лучше изучить, какие решения есть на рынке.
113. Как запрашивать JSON в Couchbase с помощью коллекций и областей

114. Создайте интерактивную информационную панель с помощью Materialize, Airbyte, MySQL и Redpanda/Kafka

115. Сообщения об ошибках MySQL и распространенные проблемы
 Ошибки или ошибки распространены в любых аспектах, особенно в разработке. Использование MySQL или любой другой базы данных не может гарантировать безошибочную среду.
Ошибки или ошибки распространены в любых аспектах, особенно в разработке. Использование MySQL или любой другой базы данных не может гарантировать безошибочную среду.
116. Введение в карьеру инженера данных
 Ценным активом для тех, кто хочет проникнуть в область разработки данных, является понимание различных типов данных и конвейера данных.
Ценным активом для тех, кто хочет проникнуть в область разработки данных, является понимание различных типов данных и конвейера данных.
117. Как начать работу с JPA/Hibernate
 JPA родился как аббревиатура от Java Persistence API.
JPA родился как аббревиатура от Java Persistence API.
118. Создайте свой собственный ORM с нуля с помощью Python
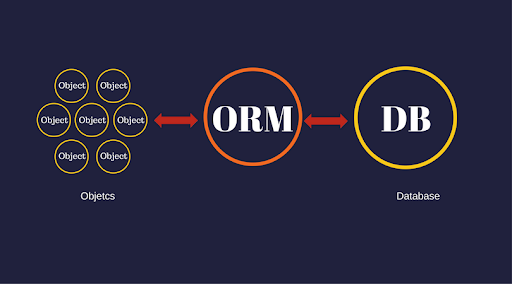 любопытно, как работает ORM! прочитайте это руководство и создайте его с нуля, используя язык программирования Python.
любопытно, как работает ORM! прочитайте это руководство и создайте его с нуля, используя язык программирования Python.
119. Как преобразовать Rest API в базы данных: создайте драйвер JDBC
 Многие данные в Интернете или внутри предприятия доступны только через Rest API. Rest API предоставляют безопасный и аутентифицированный механизм доступа к этим службам, но иногда они не очень интуитивно понятны для запроса данных, которые извлекаются через них.
Многие данные в Интернете или внутри предприятия доступны только через Rest API. Rest API предоставляют безопасный и аутентифицированный механизм доступа к этим службам, но иногда они не очень интуитивно понятны для запроса данных, которые извлекаются через них.
120. 10 лучших советов по Microsoft SQL Server
 Существует много информации о различных функциях T-SQL.
Хочу рассказать вам о не менее полезных, но менее популярных советах по работе с этим языком!
Существует много информации о различных функциях T-SQL.
Хочу рассказать вам о не менее полезных, но менее популярных советах по работе с этим языком!
121. HarperDB: создавайте серверную часть приложения в одном месте с помощью настраиваемых функций
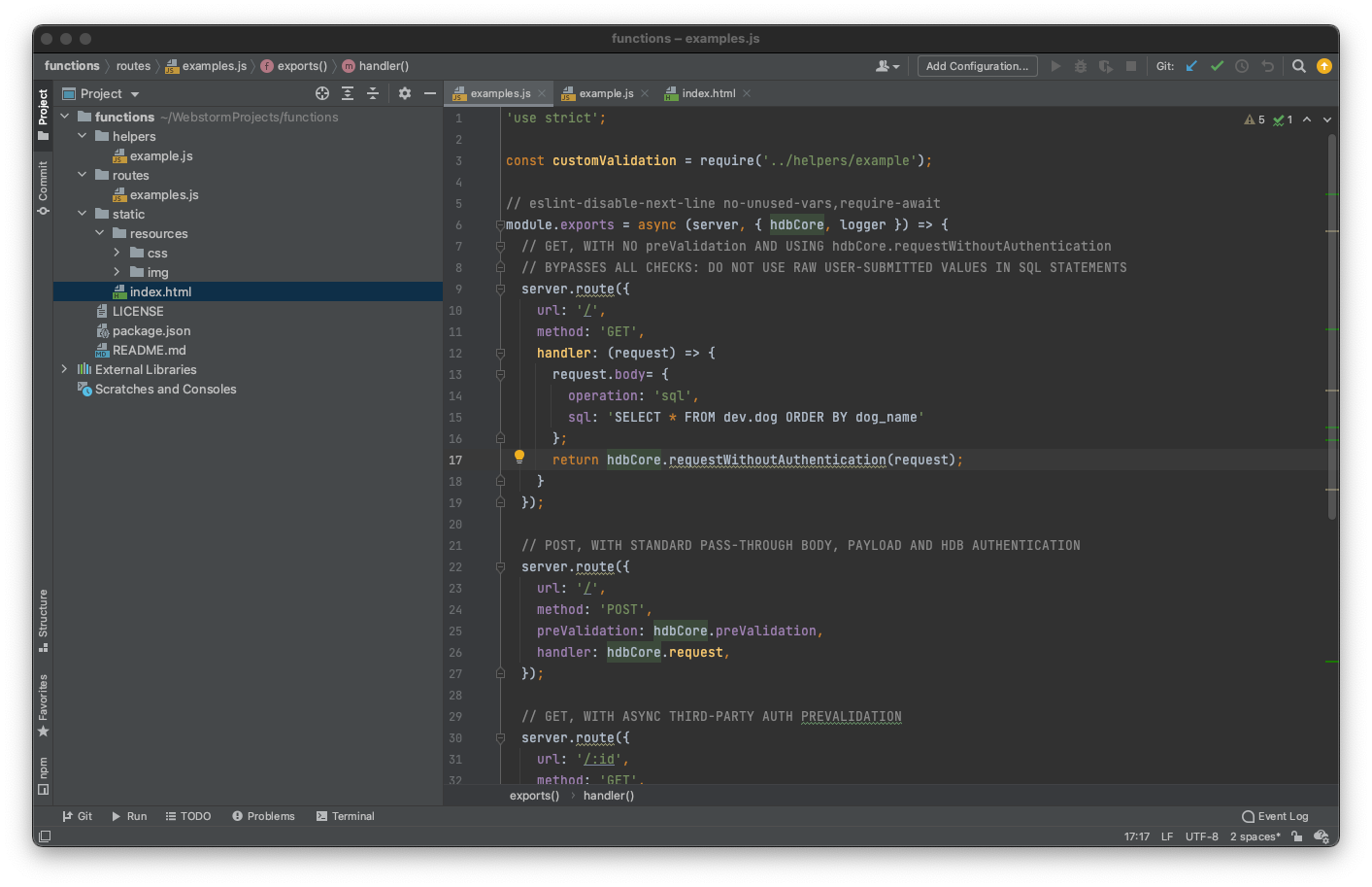 Представляем новейшую инновацию от HarperDB: пользовательские функции HarperDB. С выпуском HarperDB 3.1 пользователи могут определять свои собственные конечные точки API в HarperDB. Что это значит для вас? HarperDB превращается из распределенной базы данных в распределенную платформу разработки приложений с интегрированной сохраняемостью, которая может служить единым решением для всех ваших внутренних потребностей. Мы сворачиваем стек!
Представляем новейшую инновацию от HarperDB: пользовательские функции HarperDB. С выпуском HarperDB 3.1 пользователи могут определять свои собственные конечные точки API в HarperDB. Что это значит для вас? HarperDB превращается из распределенной базы данных в распределенную платформу разработки приложений с интегрированной сохраняемостью, которая может служить единым решением для всех ваших внутренних потребностей. Мы сворачиваем стек!
122. Изучение вложенных таблиц PL/SQL в Oracle

123. Нетехническое объяснение того, почему реляционные базы данных не работают
 Вот что я рассказываю деловым людям о том, почему реляционные базы данных так плохи
Вот что я рассказываю деловым людям о том, почему реляционные базы данных так плохи
124. Что Web3 & Средство децентрализации для хранения данных
 Я думаю о web3 и децентрализации в широком спектре — это не просто одно или другое, но вы можете делать постепенные шаги на пути к своей конечной цели.
Я думаю о web3 и децентрализации в широком спектре — это не просто одно или другое, но вы можете делать постепенные шаги на пути к своей конечной цели.
125. Оптимизированный процесс загрузки метаданных в ShardingSphere: подробный технический обзор
 Основные функции мощного ПО промежуточного слоя базы данных ShardingSphere, такие как сегментирование данных, шифрование и дешифрование, основаны на метаданных базы данных.
Основные функции мощного ПО промежуточного слоя базы данных ShardingSphere, такие как сегментирование данных, шифрование и дешифрование, основаны на метаданных базы данных.
126. Apache Cassandra — основное руководство
127. Как создать Graphql API с помощью Spring Boot, Neo4j и Kong [Часть 1]

128. Два лучших способа поиска PII в вашем хранилище данных
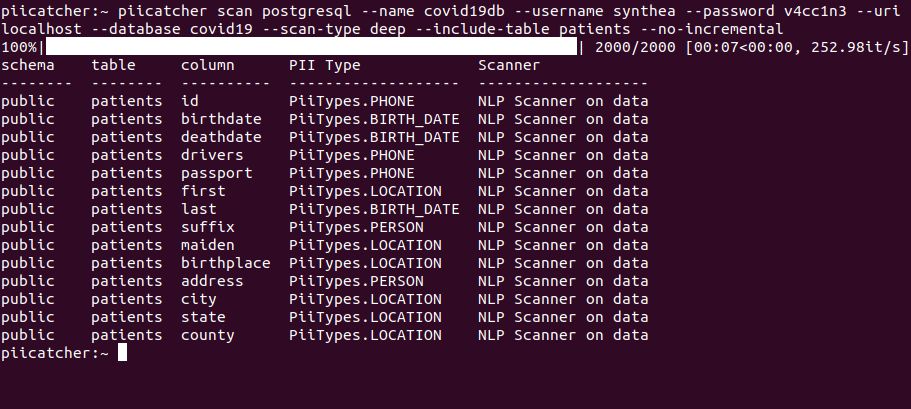 Находите данные PII, сканируя имена столбцов и/или данные в хранилище данных с помощью этих двух простых в создании методов и пошагового руководства о том, как это сделать.
Находите данные PII, сканируя имена столбцов и/или данные в хранилище данных с помощью этих двух простых в создании методов и пошагового руководства о том, как это сделать.
129. Раскройте потенциал свойств ACID в базах данных: подробное руководство для разработчиков
 ACID расшифровывается как атомарность, согласованность, изоляция и долговечность, и каждый из них имеет определенное назначение, когда речь идет о базах данных.
ACID расшифровывается как атомарность, согласованность, изоляция и долговечность, и каждый из них имеет определенное назначение, когда речь идет о базах данных.
130. Обзор индексирования баз данных для начинающих
 Индексирование базы данных — это наиболее распространенный способ, известный и используемый разработчиками бэкенда для оптимизации запросов к базе данных.
Индексирование базы данных — это наиболее распространенный способ, известный и используемый разработчиками бэкенда для оптимизации запросов к базе данных.
131. Представляем сервис API аэропортов на базе GitHub
 Привет разработчикам и энтузиастам! 😍
Привет разработчикам и энтузиастам! 😍
132. 2 безошибочных варианта обработки десятичных чисел в Golang
 CockroachDB и использование популярной базы данных — два безошибочных варианта обработки десятичных чисел в Golang.
CockroachDB и использование популярной базы данных — два безошибочных варианта обработки десятичных чисел в Golang.
133. Контейнер SQL Server в Azure Kubernetes Services (AKS)

134. Postgres и MySQL: сравнение производительности
 Что анализ рабочей нагрузки и выполнение запросов могут рассказать нам о различиях в производительности JSON, индексации и параллелизма.
Что анализ рабочей нагрузки и выполнение запросов могут рассказать нам о различиях в производительности JSON, индексации и параллелизма.
135. Отладка Has_Many через отношения в Ruby on Rails
 Работа с ассоциациями моделей может быть сложной.
Работа с ассоциациями моделей может быть сложной.
136. Решение проблемы интеграции данных: плюсы и минусы открытого и коммерческого программного обеспечения

137. Почему Appwrite 0.8 — отличная альтернатива Firebase с открытым исходным кодом
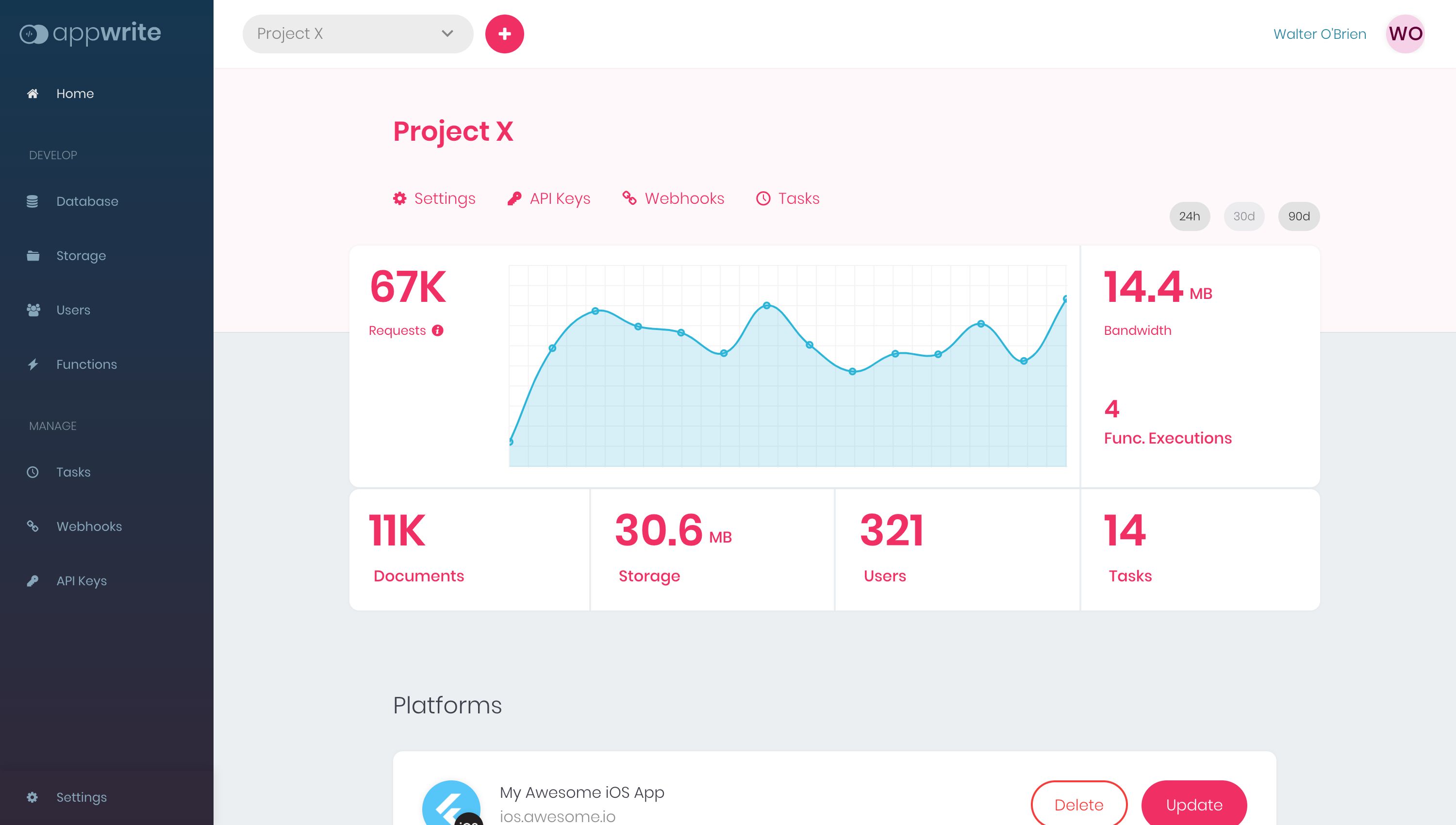 Анонс Appwrite 0.8 с аутентификацией JWT, поддержкой ARM, анонимным входом, новыми возможностями хранения и многими другими новыми функциями.
Анонс Appwrite 0.8 с аутентификацией JWT, поддержкой ARM, анонимным входом, новыми возможностями хранения и многими другими новыми функциями.
138. #NoBrainers: вам нужна высокопроизводительная распределенная база данных с малой задержкой

139. Почему Kubernetes — лучшая технология для запуска облачной базы данных
 Мы давно говорим о переносе рабочих нагрузок в облако, но взгляд на портфолио приложений многих ИТ-организаций показывает, что предстоит еще много работы. Во многих случаях проблемы с сохранением и перемещением данных в облаке продолжают оставаться ключевым ограничивающим фактором, замедляющим внедрение облака, несмотря на то, что базы данных в облаке доступны уже много лет.
Мы давно говорим о переносе рабочих нагрузок в облако, но взгляд на портфолио приложений многих ИТ-организаций показывает, что предстоит еще много работы. Во многих случаях проблемы с сохранением и перемещением данных в облаке продолжают оставаться ключевым ограничивающим фактором, замедляющим внедрение облака, несмотря на то, что базы данных в облаке доступны уже много лет.
140. Введение в GraphQL

141. Подумайте, прежде чем уйти в спящий режим
 В этой статье объясняются общие плюсы и минусы Hibernate, чтобы вы могли лучше определить необходимость добавления этой зависимости в новую микрослужбу.
В этой статье объясняются общие плюсы и минусы Hibernate, чтобы вы могли лучше определить необходимость добавления этой зависимости в новую микрослужбу.
142. Усовершенствованная и эффективная разбивка на страницы MongoDB
 Как сделать чистую пагинацию без дополнительных зависимостей. В основном для Node.js, но может использоваться на любых других языках и платформах.
Как сделать чистую пагинацию без дополнительных зависимостей. В основном для Node.js, но может использоваться на любых других языках и платформах.
143. Jaeger Persistent Storage с Elasticsearch, Cassandra и Kafka

144. Поднимите свои материализованные представления на новый уровень, присоединившись к MySQL и Postgres

145. Как интегрировать свой ноутбук с AWS и локально развернуть DynamoDB
 Как взаимодействовать с облаком AWS (Amazon Web Services) с вашего локального компьютера.
Как взаимодействовать с облаком AWS (Amazon Web Services) с вашего локального компьютера.
146. Создание базы данных в памяти в Go
 Создание базы данных в памяти в golang — это основная задача, которую вам, вероятно, придется выполнить. Перед организацией вам нужно создать базу данных и таблицу.
Создание базы данных в памяти в golang — это основная задача, которую вам, вероятно, придется выполнить. Перед организацией вам нужно создать базу данных и таблицу.
147. Как управлять версиями базы данных в нескольких средах

148. Мой контрольный список для собеседования по проектированию системы за 8 простых шагов

149. Введение в рекурсивное CTE
150. Как создавать облачные архитектуры данных
 Создание облачных архитектур данных необходимо для использования больших данных и получения возможности обрабатывать значительные объемы данных для анализа.
Создание облачных архитектур данных необходимо для использования больших данных и получения возможности обрабатывать значительные объемы данных для анализа.
151. Какая база данных подходит именно вам? HarperDB, MongoDB и PostgreSQL
 Цель этой статьи не в том, чтобы определить, какая база данных лучше, а в том, чтобы помочь определить, какая из них подходит для вашего конкретного проекта.
Цель этой статьи не в том, чтобы определить, какая база данных лучше, а в том, чтобы помочь определить, какая из них подходит для вашего конкретного проекта.
152. AvionDB: распределенная база данных наподобие MongoDB
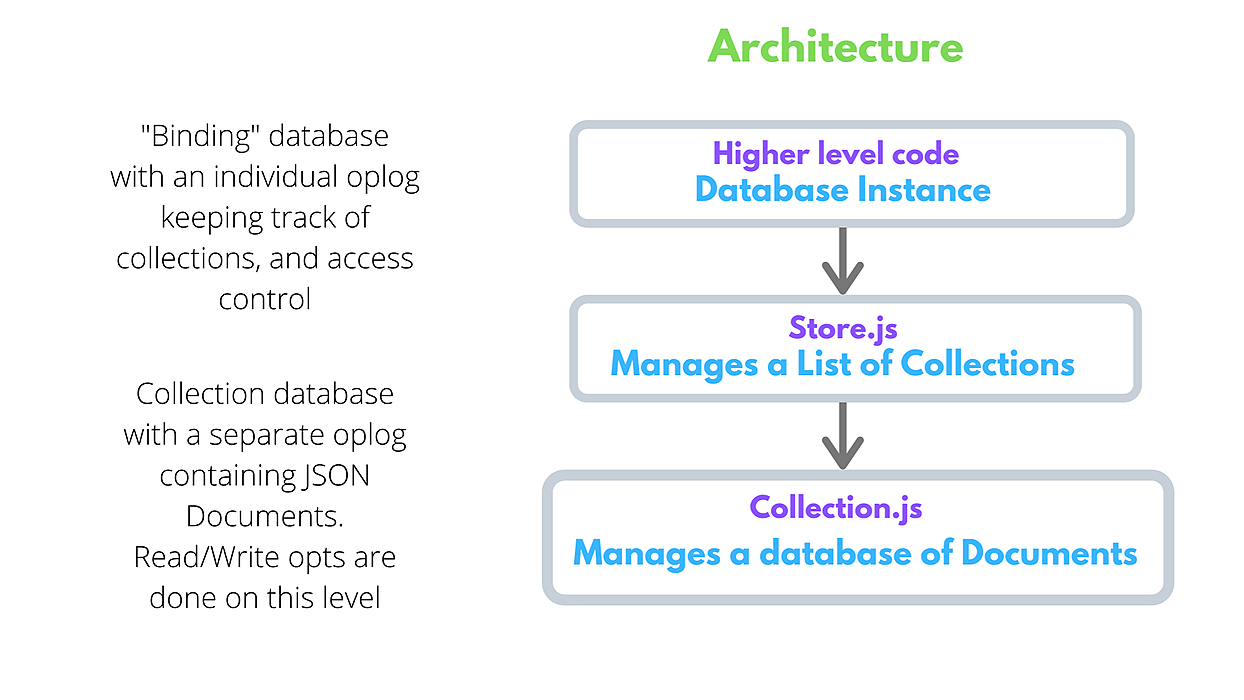 В последние несколько месяцев мы часто получали этот вопрос:
В последние несколько месяцев мы часто получали этот вопрос:
153. Как настроить базу данных Heroku Postgres с помощью Librato
 В этой статье вы узнаете, как настроить базу данных Heroku Postgres с помощью Librato для автоматического мониторинга.
В этой статье вы узнаете, как настроить базу данных Heroku Postgres с помощью Librato для автоматического мониторинга.
154. Разбор запросов шаблонов MSON
 Шаблонные запросы — это динамические шаблоны, созданные с помощью операторов в стиле MongoDB, которые позволяют настраивать компоненты MSON с меньшим количеством кода.
Шаблонные запросы — это динамические шаблоны, созданные с помощью операторов в стиле MongoDB, которые позволяют настраивать компоненты MSON с меньшим количеством кода.
155. dbForge Studio или разработчик PL/SQL: какую Oracle IDE выбрать?
 И dbForge Studio, и PL/SQL Developer представляют собой интегрированные среды разработки (IDE), предназначенные для облегчения задач разработки баз данных Oracle и повышения производительности кодирования PL/SQL. Однако, как и любые два инструмента, те, которые мы обсуждаем, не совсем одинаковы. Иногда очень важно знать, какое решение выбрать с учетом ваших конкретных потребностей и предпочтений. В этой статье мы рассмотрим различия между dbForge Studio и PL/SQL Developer и подробно проанализируем их сильные и слабые стороны.
И dbForge Studio, и PL/SQL Developer представляют собой интегрированные среды разработки (IDE), предназначенные для облегчения задач разработки баз данных Oracle и повышения производительности кодирования PL/SQL. Однако, как и любые два инструмента, те, которые мы обсуждаем, не совсем одинаковы. Иногда очень важно знать, какое решение выбрать с учетом ваших конкретных потребностей и предпочтений. В этой статье мы рассмотрим различия между dbForge Studio и PL/SQL Developer и подробно проанализируем их сильные и слабые стороны.
156. MongoDB или DocumentDB: что лучше для вас?
 Вы пытаетесь решить, следует ли вам использовать MongoDB или DocumentDB? В связи с недавними спорами вокруг лицензирования MongoDB может возникнуть путаница при выборе того, какой вариант подходит для вашей компании или проекта. В Amazon решили, что основной код MongoDB сложно масштабировать, сохраняя при этом высокую доступность. Amazon написал свою реализацию, которая совместима с открытым исходным кодом Apache 2.0 MongoDB 3.6 API. MongoDB, Inc. также недавно изменила свою лицензию, чтобы затруднить будущие имитации. Для этого они создали совершенно новую лицензию, которая называется Общедоступной лицензией на стороне сервера.
Вы пытаетесь решить, следует ли вам использовать MongoDB или DocumentDB? В связи с недавними спорами вокруг лицензирования MongoDB может возникнуть путаница при выборе того, какой вариант подходит для вашей компании или проекта. В Amazon решили, что основной код MongoDB сложно масштабировать, сохраняя при этом высокую доступность. Amazon написал свою реализацию, которая совместима с открытым исходным кодом Apache 2.0 MongoDB 3.6 API. MongoDB, Inc. также недавно изменила свою лицензию, чтобы затруднить будущие имитации. Для этого они создали совершенно новую лицензию, которая называется Общедоступной лицензией на стороне сервера.
157. NoSQL: краткая история и вызов DynamoDB
 Dynamo ускорила революцию в области NoSQL, ставшую движущей силой индустрии баз данных.
Dynamo ускорила революцию в области NoSQL, ставшую движущей силой индустрии баз данных.
158. Службы данных для масс
 За свою карьеру в ИТ я занимал несколько должностей: от разработчика программного обеспечения до корпоративного архитектора и адвоката разработчиков. Меня всегда восхищала роль, которую данные играют в наших приложениях — помещение их в базы данных, быстрое получение обратно, обеспечение их точности при передаче между системами. Многие из самых сложных проблем, с которыми я сталкивался, были связаны с данными. Например:
За свою карьеру в ИТ я занимал несколько должностей: от разработчика программного обеспечения до корпоративного архитектора и адвоката разработчиков. Меня всегда восхищала роль, которую данные играют в наших приложениях — помещение их в базы данных, быстрое получение обратно, обеспечение их точности при передаче между системами. Многие из самых сложных проблем, с которыми я сталкивался, были связаны с данными. Например:
159. InfluxDB: от базы данных временных рядов с открытым исходным кодом к миллионному доходу
 История происхождения InfluxBD: как Пол Дикс взял неудачный SaaS-продукт и превратил его в успешную коммерческую компанию по работе с базами данных временных рядов с открытым исходным кодом.
История происхождения InfluxBD: как Пол Дикс взял неудачный SaaS-продукт и превратил его в успешную коммерческую компанию по работе с базами данных временных рядов с открытым исходным кодом.
160. Пул соединений с базой данных с помощью pgbouncer
 Введение: проблема пула соединений Postgres
Введение: проблема пула соединений Postgres
161. Графики в 2020-х: базы данных, платформы и эволюция знаний
 Графы и графы знаний являются ключевыми концепциями и технологиями 2020-х годов. Как они будут выглядеть и что они дадут в будущем?
Графы и графы знаний являются ключевыми концепциями и технологиями 2020-х годов. Как они будут выглядеть и что они дадут в будущем?
162. Как консолидировать аналитику в реальном времени из нескольких баз данных

163. Ассоциации Active Record в Rails
 Ассоциация — это связь между двумя моделями Active Record. Это значительно упрощает выполнение различных операций с записями в вашем коде. Мы разделим ассоциации на четыре категории:
Ассоциация — это связь между двумя моделями Active Record. Это значительно упрощает выполнение различных операций с записями в вашем коде. Мы разделим ассоциации на четыре категории:
164. Поддержка «гражданских ИТ»: крайне важно демократизировать ваши данные
 Демократизация данных для использования Citizen IT дает организациям конкурентное преимущество — вот почему.
Демократизация данных для использования Citizen IT дает организациям конкурентное преимущество — вот почему.
165. Изучение запросов Self JOIN с помощью SQLZOO

166. [Учебник] 5 лучших способов сделать запрос к реляционной базе данных с помощью JavaScript [Часть 1]
 Если вы разрабатываете веб-приложения, вы почти наверняка будете постоянно взаимодействовать с базой данных. А когда приходит время выбирать, как вы будете взаимодействовать, выбор может оказаться огромным.
Если вы разрабатываете веб-приложения, вы почти наверняка будете постоянно взаимодействовать с базой данных. А когда приходит время выбирать, как вы будете взаимодействовать, выбор может оказаться огромным.
167. Необходимый контрольный список очистки данных

168. Введение в блокчейн + базы данных NoSQL
 Как базы данных NoSQL, так и современные реестры Blockchain выигрывают от набора общих принципов. Когда обе они реализованы для приложения, можно добиться многого, поскольку платформы могут дополнять друг друга.
Как базы данных NoSQL, так и современные реестры Blockchain выигрывают от набора общих принципов. Когда обе они реализованы для приложения, можно добиться многого, поскольку платформы могут дополнять друг друга.
169. TMNT: память переводов и нейронный перевод
 По мере того, как мы совершенствуем машинный перевод, память переводов занимает свое место в стеке современных технологий перевода, который приносит пользу пользователям машинного перевода и переводчикам-людям.
По мере того, как мы совершенствуем машинный перевод, память переводов занимает свое место в стеке современных технологий перевода, который приносит пользу пользователям машинного перевода и переводчикам-людям.
170. Безопасное подключение к частным ресурсам AWS с помощью туннелей SSH и хостов-бастионов
 Проблема с общедоступными ресурсами AWS и пути ее решения
Проблема с общедоступными ресурсами AWS и пути ее решения
171. Сделайте свое приложение масштабируемым, оптимизировав производительность ORM
 В этой статье я хотел бы поделиться набором стратегий оптимизации ORM, которые я использую почти во всех серверных службах, над которыми работаю.
В этой статье я хотел бы поделиться набором стратегий оптимизации ORM, которые я использую почти во всех серверных службах, над которыми работаю.
172. Развитие многоразовых инструментов моделирования данных на основе SQL и сервисов DataOps
 Возрождение СУБД на основе SQL
Возрождение СУБД на основе SQL
173. Важность единого источника достоверной информации для предприятий
 Единый источник достоверной информации (SSOT) обеспечивает такую синхронизацию. Компания с SSOT полагается на одну и только одну точку отсчета для получения последней сводной информации.
Единый источник достоверной информации (SSOT) обеспечивает такую синхронизацию. Компания с SSOT полагается на одну и только одну точку отсчета для получения последней сводной информации.
174. Vagrant с Oracle Database: если вам нужно больше, чем образ контейнера!
 Я уже несколько раз писал здесь о своей любви к Vagrant, сегодня я покажу, как получить базу данных Oracle с помощью Vagrant.
Я уже несколько раз писал здесь о своей любви к Vagrant, сегодня я покажу, как получить базу данных Oracle с помощью Vagrant.
175. Все, что вам нужно знать об AWS DynamoDB

176. 9 лучших программ для интеграции данных в 2022 году

177. Руководство по использованию базы данных MongoDB в приложении веб-API ASP NET Core
 Когда вы думаете о поставщиках баз данных для приложений ASP NET Core, вы, вероятно, думаете о Entity Framework Core (EF Core), который обрабатывает взаимодействие с базами данных SQL. А как насчет вариантов NoSQL? Популярным вариантом NoSQL является MongoDB. Итак, в этой статье мы узнаем, как создать простой CRUD API ASP NET Core, используя MongoDB в качестве поставщика базы данных.
Когда вы думаете о поставщиках баз данных для приложений ASP NET Core, вы, вероятно, думаете о Entity Framework Core (EF Core), который обрабатывает взаимодействие с базами данных SQL. А как насчет вариантов NoSQL? Популярным вариантом NoSQL является MongoDB. Итак, в этой статье мы узнаем, как создать простой CRUD API ASP NET Core, используя MongoDB в качестве поставщика базы данных.
178. Как работать со сложными разрешениями пользователей в GraphQL
 Я работал над семинаром по GraphQL, и это был отличный опыт обучения. Одна из самых сложных вещей, с которыми мне приходилось иметь дело в GraphQL, — это обработка сложных разрешений пользователей. Раньше это было проблемой, пока друг не обратил мое внимание на Хасуру.
Я работал над семинаром по GraphQL, и это был отличный опыт обучения. Одна из самых сложных вещей, с которыми мне приходилось иметь дело в GraphQL, — это обработка сложных разрешений пользователей. Раньше это было проблемой, пока друг не обратил мое внимание на Хасуру.
179. Освоение MongoDB — более быстрые выборы во время непрерывного обслуживания
 Фото Энни Болин на Unsplash
Фото Энни Болин на Unsplash
180. Разработка приложений для электронной коммерции с использованием базы данных NoSQL
 Работа с большим количеством данных, таких как продукты, заказы, категории, пользователи и платежи, является очень важной темой при создании приложений электронной коммерции. В этом посте вы узнаете самые основы структурирования схемы noSQL, чтобы она была быстрой и масштабируемой для сценариев электронной коммерции.
Работа с большим количеством данных, таких как продукты, заказы, категории, пользователи и платежи, является очень важной темой при создании приложений электронной коммерции. В этом посте вы узнаете самые основы структурирования схемы noSQL, чтобы она была быстрой и масштабируемой для сценариев электронной коммерции.
181. Как работать с внешней базой данных
 Когда вы включаете Velo, вы также автоматически получаете данные Wix, что позволяет вам работать с нашими встроенными базами данных на вашем сайте. Вы также можете работать с данными, хранящимися во внешней базе данных. Velo позволяет подключить ваш сайт к внешней базе данных, а затем работать с этой коллекцией баз данных на вашем сайте точно так же, как с нашими встроенными коллекциями.
Когда вы включаете Velo, вы также автоматически получаете данные Wix, что позволяет вам работать с нашими встроенными базами данных на вашем сайте. Вы также можете работать с данными, хранящимися во внешней базе данных. Velo позволяет подключить ваш сайт к внешней базе данных, а затем работать с этой коллекцией баз данных на вашем сайте точно так же, как с нашими встроенными коллекциями.
182. Как подключить MongoDB (4.2.10) и MongoDB Compass локально

183. HarperDB — больше, чем просто база данных: вот почему
 HarperDB — это больше, чем просто база данных, и для некоторых пользователей или проектов HarperDB вообще не служит базой данных. Как это возможно?
HarperDB — это больше, чем просто база данных, и для некоторых пользователей или проектов HarperDB вообще не служит базой данных. Как это возможно?
184. MongoDB и DynamoDB: выбор лучшей базы данных для вашего бизнеса
 Все о MongoDB и DynamoDB. Узнайте о преимуществах и подробном сравнении, чтобы выбрать лучший вариант для вашего бизнес-приложения.
Все о MongoDB и DynamoDB. Узнайте о преимуществах и подробном сравнении, чтобы выбрать лучший вариант для вашего бизнес-приложения.
185. Полное руководство по архитектуре баз данных и вариантам использования
 В этой статье будет представлен обзор архитектур баз данных, включая варианты использования и плюсы. минусы для каждого из них.
В этой статье будет представлен обзор архитектур баз данных, включая варианты использования и плюсы. минусы для каждого из них.
186. Как добавить команду классификации конфиденциальности данных в SQL Server 2019
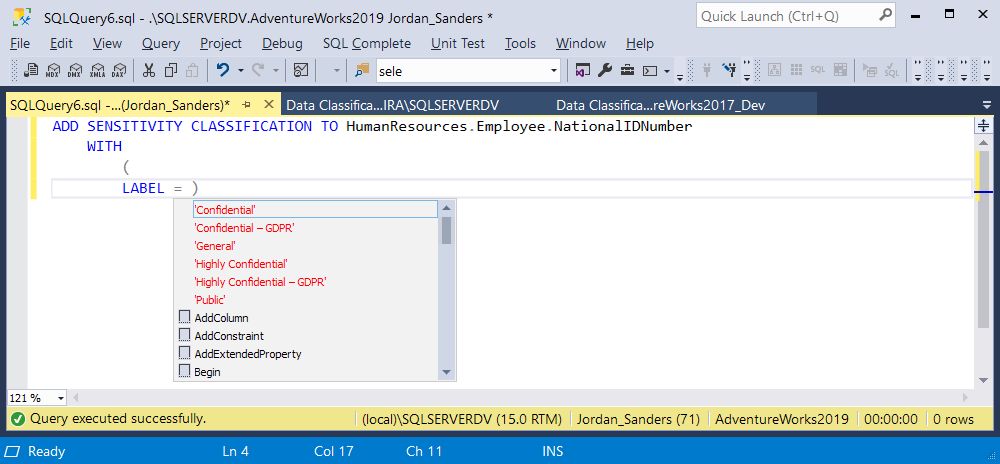
187. Добавление шифрования в быструю базу данных без компромиссов
 Эта статья будет особенно интересна людям, которым интересно, как мощное шифрование может быть реализовано в высокопроизводительных системах. Он также предназначен для людей, которые просто хотят узнать немного больше о том, как работает надежное шифрование и как все части сочетаются друг с другом.
Эта статья будет особенно интересна людям, которым интересно, как мощное шифрование может быть реализовано в высокопроизводительных системах. Он также предназначен для людей, которые просто хотят узнать немного больше о том, как работает надежное шифрование и как все части сочетаются друг с другом.
188. Введение в прокси-сервер RDS: исследование с помощью тестов в Go
 Подробное описание характеристик производительности прокси-сервера RDS и RDS
Подробное описание характеристик производительности прокси-сервера RDS и RDS
189. Руководство по Apache Cassandra: моделирование данных
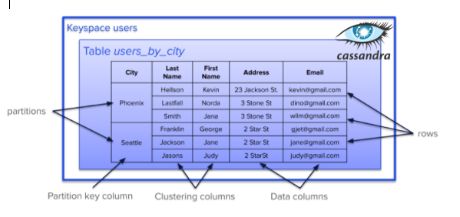
190. HarperDB — Как и почему мы создали его с нуля на NodeJS
 Команда основателей HarperDB создала первую и единственную базу данных, написанную на Node.js. Вот история этого (некоторые назвали его сумасшедшим) начинания.
Команда основателей HarperDB создала первую и единственную базу данных, написанную на Node.js. Вот история этого (некоторые назвали его сумасшедшим) начинания.
191. Децентрализованные базы данных сокращают задержку данных благодаря географически распределенным центрам обработки данных
 Задержка вызвана переносом обработки из приложения на внешний сервер. Но что, если бы существовало решение монолитной общей географии единого облака?
Задержка вызвана переносом обработки из приложения на внешний сервер. Но что, если бы существовало решение монолитной общей географии единого облака?
192. Плюсы и минусы NoSQL
 Узнайте, чем NoSQL отличается от SQL и как он обеспечивает высокую производительность и доступность. И нет, это не означает "Без SQL".
Узнайте, чем NoSQL отличается от SQL и как он обеспечивает высокую производительность и доступность. И нет, это не означает "Без SQL".
193. Большое плохое руководство по тестированию баз данных
 Процесс проверки целостности данных и непротиворечивости базы данных называется тестированием базы данных. В конечном счете, он направлен на создание сложных запросов для проверки реакции базы данных на нагрузку/стресс, подвергая тестированию схему, таблицы, триггеры, хранимые процедуры и т. д.
Процесс проверки целостности данных и непротиворечивости базы данных называется тестированием базы данных. В конечном счете, он направлен на создание сложных запросов для проверки реакции базы данных на нагрузку/стресс, подвергая тестированию схему, таблицы, триггеры, хранимые процедуры и т. д.
194. 10 способов оптимизировать вашу базу данных
 Выполните эти 10 шагов, чтобы оптимизировать базу данных.
Выполните эти 10 шагов, чтобы оптимизировать базу данных.
195. Почему у нас должны быть разные базы данных
 Сегодня существуют сотни баз данных SQL и NoSQL. Некоторые из них популярны, некоторые игнорируются. Некоторые из них удобны для пользователя и хорошо документированы, а некоторые сложны в использовании. Некоторые из них с открытым исходным кодом, а некоторые являются проприетарными. И, пожалуй, самое главное — некоторые из них масштабируемы, оптимизированы, высокодоступны, а некоторые сложно масштабировать или обслуживать.
Сегодня существуют сотни баз данных SQL и NoSQL. Некоторые из них популярны, некоторые игнорируются. Некоторые из них удобны для пользователя и хорошо документированы, а некоторые сложны в использовании. Некоторые из них с открытым исходным кодом, а некоторые являются проприетарными. И, пожалуй, самое главное — некоторые из них масштабируемы, оптимизированы, высокодоступны, а некоторые сложно масштабировать или обслуживать.
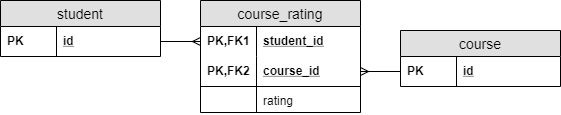
196. Зачем нам нужна сквозная таблица, объясняемая с помощью Rails?
197. Узнайте о жизнеспособности архитектуры мобильных приложений
 Результат — это то, что измеряет успех бизнеса. Поэтому все коммерческие дома принимают все неизбежные методы и программы для повышения своей производительности / выпуска за счет внедрения новых технологий и концепций. Доступно несколько технологий, многие из которых находятся в стадии разработки, которые эффективно удовлетворяют потребности клиентов и обеспечивают высокую производительность.
Результат — это то, что измеряет успех бизнеса. Поэтому все коммерческие дома принимают все неизбежные методы и программы для повышения своей производительности / выпуска за счет внедрения новых технологий и концепций. Доступно несколько технологий, многие из которых находятся в стадии разработки, которые эффективно удовлетворяют потребности клиентов и обеспечивают высокую производительность.
198. Встроенная аналитика в Elasticsearch с Knowi

199. Функциональное тестирование вашего бэкэнда в Go
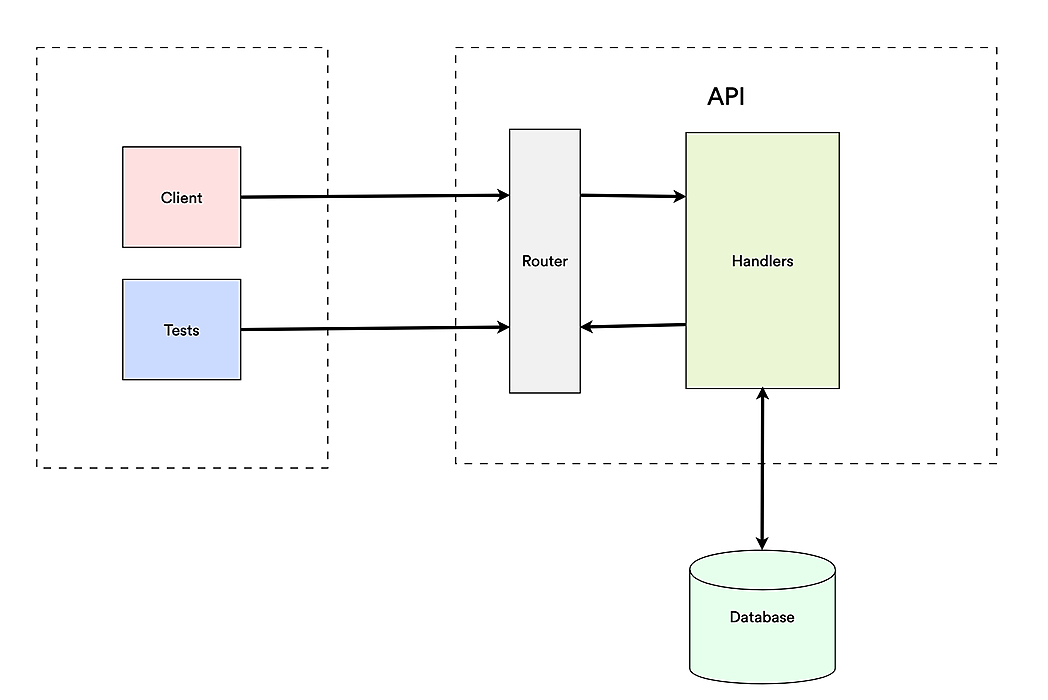 Для Terrastruct, который на данный момент имеет чуть более 50 тысяч строк кода, я написал только функциональные сквозные тесты. В этом сообщении блога описывается успешная установка, для достижения которой потребовалось некоторое количество итераций, и я хотел бы, чтобы она существовала, когда я начинал с серверной части Go API.
Для Terrastruct, который на данный момент имеет чуть более 50 тысяч строк кода, я написал только функциональные сквозные тесты. В этом сообщении блога описывается успешная установка, для достижения которой потребовалось некоторое количество итераций, и я хотел бы, чтобы она существовала, когда я начинал с серверной части Go API.
200. Графические базы данных: полный подробный обзор

201. Потоковая передача и отображение данных в реальном времени с помощью Materialise и Adonis
 В этом руководстве мы создадим веб-приложение с помощью AdonisJS и интегрируем его с Materialize для создания панели управления в реальном времени
В этом руководстве мы создадим веб-приложение с помощью AdonisJS и интегрируем его с Materialize для создания панели управления в реальном времени
202. Какая база данных подходит именно вам? База данных графов или реляционная база данных
 Узнайте об основных различиях между графовыми и реляционными базами данных. Какие варианты использования лучше всего подходят для каждого типа, их сильные и слабые стороны.
Узнайте об основных различиях между графовыми и реляционными базами данных. Какие варианты использования лучше всего подходят для каждого типа, их сильные и слабые стороны.
203. Интеграция управления версиями базы данных Java с Liquibase с помощью MySQL [Пошаговое руководство]
 Управление версиями изменений в базе данных так же важно, как и управление версиями исходного кода. Используя инструмент миграции базы данных, мы можем безопасно управлять развитием базы данных вместо того, чтобы запускать кучу неверсионных свободных файлов SQL. В некоторых фреймворках, таких как Ruby On Rails, управление версиями базы данных происходит во время разработки. Но когда дело доходит до мира Java, я не вижу, чтобы это происходило так часто.
Управление версиями изменений в базе данных так же важно, как и управление версиями исходного кода. Используя инструмент миграции базы данных, мы можем безопасно управлять развитием базы данных вместо того, чтобы запускать кучу неверсионных свободных файлов SQL. В некоторых фреймворках, таких как Ruby On Rails, управление версиями базы данных происходит во время разработки. Но когда дело доходит до мира Java, я не вижу, чтобы это происходило так часто.
204. Введение в язык структурированных запросов (SQL)
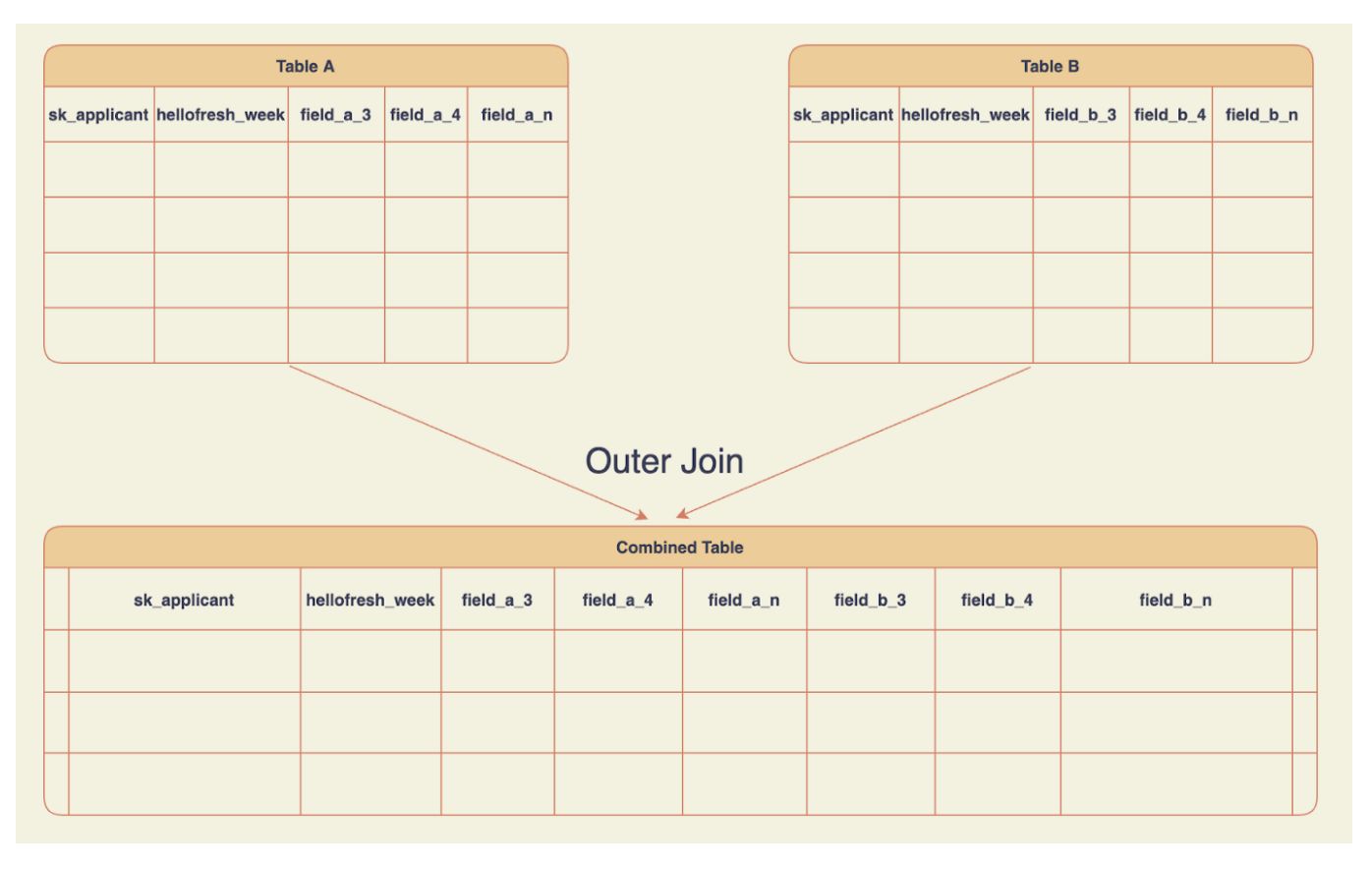 В посте я использовал простой SQL-запрос, чтобы объяснить, как определенные вещи работают в SQL. Я также описал проблемы с запросом и потенциальные способы улучшения кода
В посте я использовал простой SQL-запрос, чтобы объяснить, как определенные вещи работают в SQL. Я также описал проблемы с запросом и потенциальные способы улучшения кода
205. CouchDB против MariaDB — что лучше?
 Проще говоря, база данных представляет собой набор информации. Он организован так, чтобы обеспечить легкий доступ, управление и обновления.
Проще говоря, база данных представляет собой набор информации. Он организован так, чтобы обеспечить легкий доступ, управление и обновления.
206. Путеводитель по архитектуре Prometheus

207. Процентное приближение против. Средние значения
 Ознакомьтесь с аппроксимацией процентилей и узнайте, почему они полезны для анализа данных временных рядов.
Ознакомьтесь с аппроксимацией процентилей и узнайте, почему они полезны для анализа данных временных рядов.
208. Пошаговое руководство по использованию коллекций внешних баз данных для повышения производительности веб-сайта Wix
 Интегрируйте свои внешние базы данных в свои сайты Wix. Узнать больше.
Интегрируйте свои внешние базы данных в свои сайты Wix. Узнать больше.
209. Топ-3 базы данных, которые должен знать каждый новый разработчик
 Большинство новых разработчиков задаются вопросом, какая база данных подходит для их проекта, поскольку они не хотят ошибиться. Итак, прежде всего, давайте определим базу данных. База данных – это тип хранилища, в котором в электронном виде хранятся и систематизируются данные, чтобы их можно было использовать и получить к ним доступ позже.
Большинство новых разработчиков задаются вопросом, какая база данных подходит для их проекта, поскольку они не хотят ошибиться. Итак, прежде всего, давайте определим базу данных. База данных – это тип хранилища, в котором в электронном виде хранятся и систематизируются данные, чтобы их можно было использовать и получить к ним доступ позже.
210. Как агрегация PostgreSQL повлияла на разработку гиперфункций Timescale
 Узнайте о агрегировании PostgreSQL, о том, как реализация PostgreSQL вдохновила нас на создание гиперфункций TimescaleDB, и о том, что это значит для разработчиков.
Узнайте о агрегировании PostgreSQL, о том, как реализация PostgreSQL вдохновила нас на создание гиперфункций TimescaleDB, и о том, что это значит для разработчиков.
211. Как перенести данные с сервера MSSQL на PostGreSQL?
 Думаете о переходе на новый механизм управления базами данных? Вот как перенести данные с сервера SQL на PostgreSQL.
Думаете о переходе на новый механизм управления базами данных? Вот как перенести данные с сервера SQL на PostgreSQL.
212. Введение в графические базы данных: сила связанных данных
 В современной экономике все больше и больше компаний существуют преимущественно в Интернете. Несмотря на то, что ведется много дискуссий о последствиях отказа от традиционного бизнеса, связанного с кирпичом и раствором, один аспект, которому уделяется меньше внимания, — это значительные изменения в том, как эти компании теперь управляют своими данными. Все чаще компании стремятся понять своих клиентов и найти способ, как наилучшим образом удовлетворить их потребности, что невозможно с помощью ежемесячных отчетов и диаграмм KPI.
В современной экономике все больше и больше компаний существуют преимущественно в Интернете. Несмотря на то, что ведется много дискуссий о последствиях отказа от традиционного бизнеса, связанного с кирпичом и раствором, один аспект, которому уделяется меньше внимания, — это значительные изменения в том, как эти компании теперь управляют своими данными. Все чаще компании стремятся понять своих клиентов и найти способ, как наилучшим образом удовлетворить их потребности, что невозможно с помощью ежемесячных отчетов и диаграмм KPI.
213. 50-летнее господство SQL: вот почему SQL по-прежнему актуален сегодня
 Погрузитесь в подробную историю подъема и господства SQL за последние 50 лет. Они оставались актуальными, прислушиваясь к рынку и адаптируясь к нему.
Погрузитесь в подробную историю подъема и господства SQL за последние 50 лет. Они оставались актуальными, прислушиваясь к рынку и адаптируясь к нему.
214. Что происходит на складе Amazon: руководство для инженера-программиста
 Вы когда-нибудь задумывались, что происходит внутри склада Amazon? Инженер-программист сталкивается с множеством технических проблем в области цепочки поставок.
Вы когда-нибудь задумывались, что происходит внутри склада Amazon? Инженер-программист сталкивается с множеством технических проблем в области цепочки поставок.
215. Обзор Zilliqa (ZIL): что нужно знать
 Одной из наиболее серьезных проблем, с которыми сегодня сталкиваются криптовалюты и их блокчейны, является масштабируемость. В отличие от ведущих современных блокчейн-сетей, таких как Bitco
Одной из наиболее серьезных проблем, с которыми сегодня сталкиваются криптовалюты и их блокчейны, является масштабируемость. В отличие от ведущих современных блокчейн-сетей, таких как Bitco
216. Создание расширенных форм и пользовательских взаимодействий с Velo: практическое руководство
 С помощью настраиваемых элементов ввода Velo и Wix вы можете создавать чрезвычайно сложные формы, которые могут делать практически все, что вы можете себе представить, за небольшую часть стоимости.
С помощью настраиваемых элементов ввода Velo и Wix вы можете создавать чрезвычайно сложные формы, которые могут делать практически все, что вы можете себе представить, за небольшую часть стоимости.
217. Velo How-To: агрегаты API
 Используя функцию агрегирования Data API, вы можете выполнять определенные вычисления с данными вашей коллекции в целом или с группами элементов, которые вы определяете, для получения значимых сводок. Вы также можете добавить фильтрацию и сортировку к своим агрегатам, чтобы получить именно то, что вам нужно.
Используя функцию агрегирования Data API, вы можете выполнять определенные вычисления с данными вашей коллекции в целом или с группами элементов, которые вы определяете, для получения значимых сводок. Вы также можете добавить фильтрацию и сортировку к своим агрегатам, чтобы получить именно то, что вам нужно.
218. Семантические поисковые запросы возвращают более информативные результаты

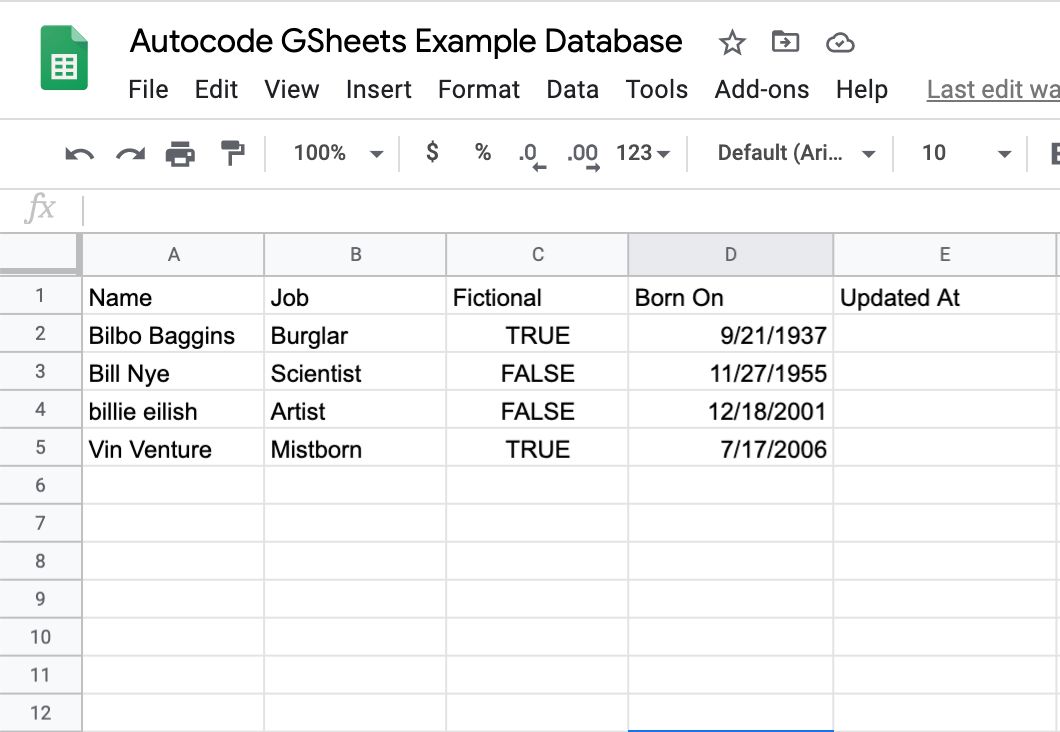
219. Используйте Google Sheets в качестве базы данных ответственно: пошаговое руководство
220. Сбор данных об изменениях на основе событий: введение, варианты использования и инструменты
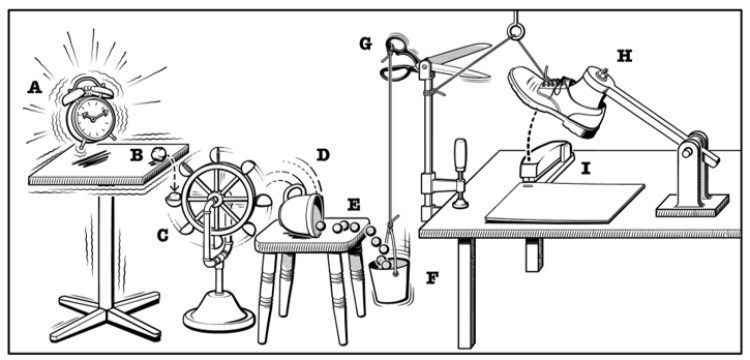 Как обнаруживать, фиксировать и распространять изменения в исходных базах данных на целевые системы в режиме реального времени с учетом событий с помощью системы сбора данных об изменениях (CDC).
Как обнаруживать, фиксировать и распространять изменения в исходных базах данных на целевые системы в режиме реального времени с учетом событий с помощью системы сбора данных об изменениях (CDC).
221. Упрощение развертывания машинного обучения для всех [глубокий анализ]
 С качеством пакетов машинного обучения, разрабатываемых сегодня, тестирование и создание моделей не может быть проще. Специалисты по данным могут просто импортировать свою любимую библиотеку и сразу же получить доступ к десяткам передовых алгоритмов.
С качеством пакетов машинного обучения, разрабатываемых сегодня, тестирование и создание моделей не может быть проще. Специалисты по данным могут просто импортировать свою любимую библиотеку и сразу же получить доступ к десяткам передовых алгоритмов.
222. 5 основных навыков, которые следует учитывать при выборе Android-разработчика
 Разработка под Android имеет множество функций в зависимости от разработчика. Существует несколько важных компонентов разработки приложений для Android, которые должны выполняться разработчиком Android, и выбор правильного разработчика для разработки приложений для Android так же важен, как и сам процесс. Большинство рекрутеров рассматривают три основных компонента: дизайн, программирование и развертывание приложения.
Разработка под Android имеет множество функций в зависимости от разработчика. Существует несколько важных компонентов разработки приложений для Android, которые должны выполняться разработчиком Android, и выбор правильного разработчика для разработки приложений для Android так же важен, как и сам процесс. Большинство рекрутеров рассматривают три основных компонента: дизайн, программирование и развертывание приложения.
223. Святая земля пользователей криптографии: как данные Web3.0 расширяют возможности централизованных бирж?
 Разработка механизма поощрения пользователей, ориентированного на данные, — хороший путь при разработке будущего централизованных бирж для индустрии криптовалют.
Разработка механизма поощрения пользователей, ориентированного на данные, — хороший путь при разработке будущего централизованных бирж для индустрии криптовалют.
224. 10 способов уменьшить потерю данных и потенциальное время простоя вашей базы данных
 В этой статье вы найдете десять практических способов защиты вашей критически важной базы данных.
В этой статье вы найдете десять практических способов защиты вашей критически важной базы данных.
225. Apache Cassandra — начальная загрузка

226. Введение в dksnap: моментальные снимки Docker для данных разработки и тестирования
 TL;DR
TL;DR
227. Запрос сложных объектов JSON с помощью SQL

228. Подходят ли базы данных NoSQL для обработки данных?
 В этой статье мы рассмотрим варианты использования, в которых инженерам данных может потребоваться взаимодействие с базой данных NoSQL, а также плюсы и минусы.
В этой статье мы рассмотрим варианты использования, в которых инженерам данных может потребоваться взаимодействие с базой данных NoSQL, а также плюсы и минусы.
229. RocksDB неуклонно поглощает мир баз данных
 Технический дизайн. Поскольку одним из наиболее распространенных вариантов использования новых баз данных является хранение данных, генерируемых источниками с высокой пропускной способностью, важно, чтобы механизм хранилища мог справляться с рабочими нагрузками с интенсивными операциями записи, обеспечивая при этом приемлемую производительность чтения. RocksDB реализует то, что известно в литературе по базам данных как лог-структурированное дерево слияния, также известное как LSM-дерево.
Технический дизайн. Поскольку одним из наиболее распространенных вариантов использования новых баз данных является хранение данных, генерируемых источниками с высокой пропускной способностью, важно, чтобы механизм хранилища мог справляться с рабочими нагрузками с интенсивными операциями записи, обеспечивая при этом приемлемую производительность чтения. RocksDB реализует то, что известно в литературе по базам данных как лог-структурированное дерево слияния, также известное как LSM-дерево.
230. Распознавание объектов с помощью SPOT от Boston Robotics
 Ранее в этом месяце к нам присоединился Йорис Сийс, ведущий научный сотрудник TNO, во второй серии Grakn Orbit.
Ранее в этом месяце к нам присоединился Йорис Сийс, ведущий научный сотрудник TNO, во второй серии Grakn Orbit.
231. Знакомьтесь с SOPHIA: системой поддержки принятия клинических решений, созданной на основе технологий с открытым исходным кодом
 Система поддержки принятия клинических решений (CDSS) предоставляет врачу инструмент, облегчающий его работу и повышающий ценность времени, проведенного с пациентом.
Система поддержки принятия клинических решений (CDSS) предоставляет врачу инструмент, облегчающий его работу и повышающий ценность времени, проведенного с пациентом.
232. Руководство для начинающих по Apache Kafka
 Apache Kafka — это распределенная платформа потоковой передачи событий, построенная на прочных концепциях. Давайте углубимся в возможности, которые он предлагает.
Apache Kafka — это распределенная платформа потоковой передачи событий, построенная на прочных концепциях. Давайте углубимся в возможности, которые он предлагает.
233. Как запустить Node.js с MongoDB [учебник]

234. Изменение столбца базы данных в Rails 5
 Во время работы над приложением Rails всем нам приходилось каким-то образом изменять столбец базы данных. Вы можете изменить имя столбца и тип столбца, а также изменить столбец с преобразованием типа.
Во время работы над приложением Rails всем нам приходилось каким-то образом изменять столбец базы данных. Вы можете изменить имя столбца и тип столбца, а также изменить столбец с преобразованием типа.
235. Переход от озер данных к океанам
 Агрегирование в озера данных — это решение сегодняшнего дня , но являются ли Federated Sources решением завтрашнего дня?
Агрегирование в озера данных — это решение сегодняшнего дня , но являются ли Federated Sources решением завтрашнего дня?
236. Подкаст HackerNoon: управление базами данных в Kubernetes с Анилом Кумаром
 Эми Том беседует с Анилом Кумаром, менеджером по продуктам в Couchbase, о том, как стать менеджером по продуктам, написать свою книгу и создать стратегию мультиоблачных вычислений.
Эми Том беседует с Анилом Кумаром, менеджером по продуктам в Couchbase, о том, как стать менеджером по продуктам, написать свою книгу и создать стратегию мультиоблачных вычислений.
237. Миграция заставляет мою кожу ползать: с SQL на NoSQL
 Так ли страшна миграция базы данных, как кажется? Эми Том беседует с Мэттом Гроувсом, старшим менеджером по управлению проектами в Couchbase, и Куртом Грацем, совладельцем CKH Consulting.
Так ли страшна миграция базы данных, как кажется? Эми Том беседует с Мэттом Гроувсом, старшим менеджером по управлению проектами в Couchbase, и Куртом Грацем, совладельцем CKH Consulting.
238 . Скрытые секреты Ruby on Rails: как получить максимальную отдачу от ассоциаций Active Record

239. Наиболее распространенные варианты использования Redis по основным структурам данных
 Redis, сокращение от Remote Dictionary Server, представляет собой хранилище структуры данных типа «ключ-значение» с открытым исходным кодом в памяти под лицензией BSD, написанное на языке C Сальваторе Санфиллипо и впервые выпущенное 10 мая 2009 года. В зависимости от того, как оно настроено, Redis может действовать как база данных, кэш или брокер сообщений. Важно отметить, что Redis — это система баз данных NoSQL. Это означает, что в отличие от систем баз данных, управляемых SQL (язык структурированных запросов), таких как MySQL, PostgreSQL и Oracle, Redis не хранит данные в четко определенных схемах базы данных, которые представляют собой таблицы, строки и столбцы. Вместо этого Redis хранит данные в структурах данных, что делает его очень гибким в использовании. В этом блоге мы описываем основные варианты использования Redis по различным основным типам структур данных.
Redis, сокращение от Remote Dictionary Server, представляет собой хранилище структуры данных типа «ключ-значение» с открытым исходным кодом в памяти под лицензией BSD, написанное на языке C Сальваторе Санфиллипо и впервые выпущенное 10 мая 2009 года. В зависимости от того, как оно настроено, Redis может действовать как база данных, кэш или брокер сообщений. Важно отметить, что Redis — это система баз данных NoSQL. Это означает, что в отличие от систем баз данных, управляемых SQL (язык структурированных запросов), таких как MySQL, PostgreSQL и Oracle, Redis не хранит данные в четко определенных схемах базы данных, которые представляют собой таблицы, строки и столбцы. Вместо этого Redis хранит данные в структурах данных, что делает его очень гибким в использовании. В этом блоге мы описываем основные варианты использования Redis по различным основным типам структур данных.
240. Управление составными ресурсами в Scala

241. Спустя 3 года после разветвления Sphinx: краткий отчет о поиске Manticore
 В мае 2017 года мы сделали форк Sphinxsearch 2.3.2, который назвали Manticore Search. Ниже вы найдете краткий отчет о Manticore Search как форке Sphinx и о наших достижениях с тех пор.
В мае 2017 года мы сделали форк Sphinxsearch 2.3.2, который назвали Manticore Search. Ниже вы найдете краткий отчет о Manticore Search как форке Sphinx и о наших достижениях с тех пор.
242. Зависимости, классы сущностей и конфигурация Jinq для создания запросов к базе данных в Java
 Jinq — это библиотека, которая предоставляет удобный и естественный способ создания безопасных для типов запросов к базе данных на Java. Он прост в использовании и не требует генерации кода
Jinq — это библиотека, которая предоставляет удобный и естественный способ создания безопасных для типов запросов к базе данных на Java. Он прост в использовании и не требует генерации кода
243. Что такое SQL? И где он используется?
 Что такое SQL? Его используют базы данных, его используют API-интерфейсы запросов, его используют даже энергичные информационные панели с большими данными! Откуда он взялся и как его используют разработчики, администраторы баз данных и приложения.
Что такое SQL? Его используют базы данных, его используют API-интерфейсы запросов, его используют даже энергичные информационные панели с большими данными! Откуда он взялся и как его используют разработчики, администраторы баз данных и приложения.
244. Обновление MySQL 5.5 до MySQL 8: пошаговое руководство
 Одной из догм является то, что обновление бесплатных библиотек является обременительным, но не особенно для MySQL. Прочтите эту статью для получения дополнительной информации.
Одной из догм является то, что обновление бесплатных библиотек является обременительным, но не особенно для MySQL. Прочтите эту статью для получения дополнительной информации.
245. Должен ли я использовать встроенную базу данных в моем мобильном приложении? (стенограмма подкаста)
 Эми Том беседует с Йенсом Альфке о встроенных базах данных в мобильных приложениях и о том, как они живут в вашем приложении и синхронизируются с вашим сервером.
Эми Том беседует с Йенсом Альфке о встроенных базах данных в мобильных приложениях и о том, как они живут в вашем приложении и синхронизируются с вашим сервером.
246. Реализация распределенных многодокументных транзакций ACID в Couchbase: практическое руководство
 История о том, как мы реализовали поддержку распределенных транзакций без центрального координатора и единой точки отказа.
История о том, как мы реализовали поддержку распределенных транзакций без центрального координатора и единой точки отказа.
247. Как создавать лучшие в мире базы данных
 Джейсон Репп — старший вице-президент HarperDB, ведущей в мире платформы для баз данных и разработки, которая лидирует в плане производительности, гибкости и простоты.
Джейсон Репп — старший вице-президент HarperDB, ведущей в мире платформы для баз данных и разработки, которая лидирует в плане производительности, гибкости и простоты.
248. 9 самых популярных безголовых CMS в 2021 году
 Ознакомьтесь со списком лучших безголовых CMS на рынке и узнайте больше о том, как безголовая CMS может помочь вам быстро строить
Ознакомьтесь со списком лучших безголовых CMS на рынке и узнайте больше о том, как безголовая CMS может помочь вам быстро строить
249. Типы индексов PostgreSQL: за пределами B-дерева
 плохая индексация — главный источник низкой производительности вашей базы данных
плохая индексация — главный источник низкой производительности вашей базы данных
250. Как создать приложение для контактов во времени с помощью SirixDB
 Учебное пособие, демонстрирующее использование SirixDB и pysirix для простого сохранения и запроса старых данных.
Учебное пособие, демонстрирующее использование SirixDB и pysirix для простого сохранения и запроса старых данных.
251. Как создать RESTful API с помощью HarperDB и FastifyJS
 Узнайте, как создать REST API для управления курсами с помощью Node.js, HarperDB и FastifyJS.
Узнайте, как создать REST API для управления курсами с помощью Node.js, HarperDB и FastifyJS.
252. Как получить схему и валидацию в NoSQL с помощью Ottoman и Couchbase
 Оттоман – это средство моделирования объектных данных (ODM) для пакета SDK Couchbase Node.js, обеспечивающее схему JSON и проверку для базы данных NoSQL.
Оттоман – это средство моделирования объектных данных (ODM) для пакета SDK Couchbase Node.js, обеспечивающее схему JSON и проверку для базы данных NoSQL.
253. Управление версиями схемы базы данных и миграция упрощены для высокоскоростной CI/CD

254. Часто задаваемые вопросы о MySQL

255. Полное руководство по архитектуре Apache Cassandra
 Введение
Введение
256. [Учебное пособие] 5 лучших способов выполнения запросов к реляционной базе данных с помощью JavaScript [Часть 2]

257. Создание удобных для разработчиков служб данных с помощью Apache Cassandra
 Использование API данных и расширенного моделирования данных значительно упростит разработчикам, ориентированным на JSON, подключение к Apache Cassandra.
Использование API данных и расширенного моделирования данных значительно упростит разработчикам, ориентированным на JSON, подключение к Apache Cassandra.
258. Как восстановить базу данных из резервной копии SQL
 Резервное копирование SQL и баз данных с использованием метода восстановления вручную, полной резервной копии базы данных, добавочного восстановления или команды manageauditing.
Резервное копирование SQL и баз данных с использованием метода восстановления вручную, полной резервной копии базы данных, добавочного восстановления или команды manageauditing.
259. Как установить и использовать Materialize для выполнения SQL-запросов в журналах nginx
 В этом руководстве я покажу вам, как работает Materialize, используя его для выполнения SQL-запросов к постоянно создаваемым журналам nginx. К концу руководства вы будете
В этом руководстве я покажу вам, как работает Materialize, используя его для выполнения SQL-запросов к постоянно создаваемым журналам nginx. К концу руководства вы будете
260. Как настроить эффективный процесс рефакторинга тяжелого интерфейса базы данных
261. Как протестировать бизнес-логику Postgres с помощью плагина Jest
 С большой силой приходит большая ответственность, и чем больше становится проект, тем легче что-то сломать. Поэтому вам следует протестировать логику Postgres!
С большой силой приходит большая ответственность, и чем больше становится проект, тем легче что-то сломать. Поэтому вам следует протестировать логику Postgres!
262. Как запрашивать глубоко вложенные данные JSON в PSQL
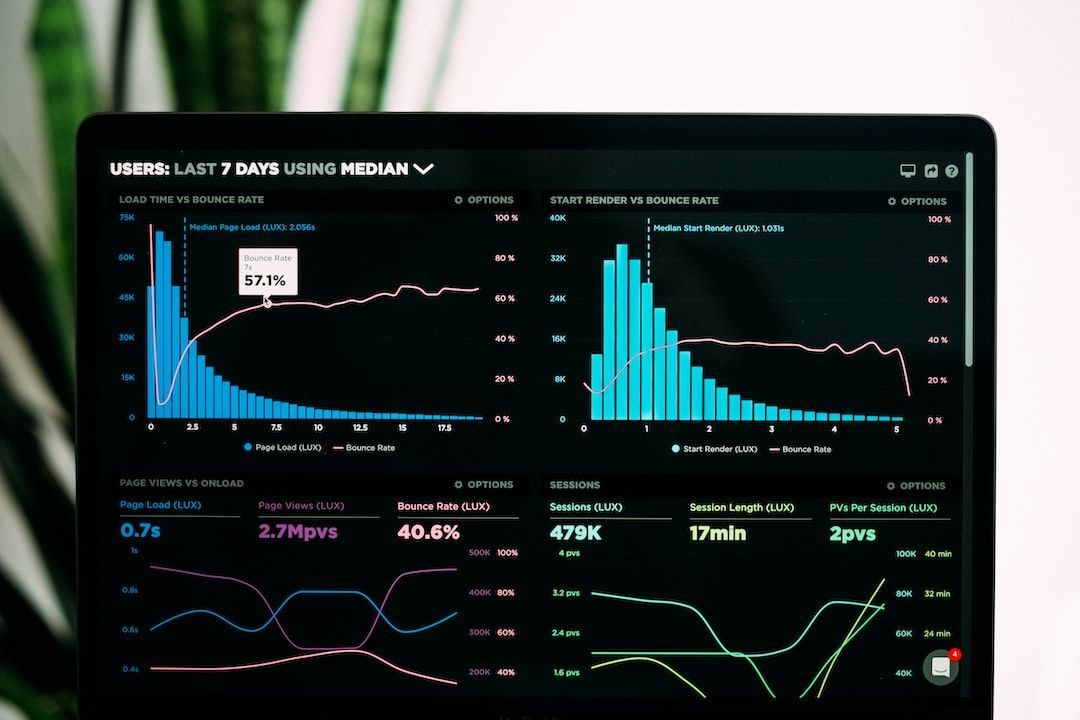 Недавно мне пришлось написать скрипт, который должен был изменить некоторую структуру данных JSON в базе данных PSQL. Вот несколько трюков, которые я выучил по пути.
Недавно мне пришлось написать скрипт, который должен был изменить некоторую структуру данных JSON в базе данных PSQL. Вот несколько трюков, которые я выучил по пути.
263. Знать, где и когда обеспечивать уникальность ваших данных
 В этой статье рассматривается уникальность данных и обсуждается, где ее следует применять. На уровне приложения или на уровне базы данных?
В этой статье рассматривается уникальность данных и обсуждается, где ее следует применять. На уровне приложения или на уровне базы данных?
264. Декодирование результатов запроса MySQL EXPLAIN для повышения производительности (часть 2)
 Понимание MySQL объясняет, что вывод запроса необходим для оптимизации запроса. EXPLAIN — хороший инструмент для анализа вашего запроса.
Понимание MySQL объясняет, что вывод запроса необходим для оптимизации запроса. EXPLAIN — хороший инструмент для анализа вашего запроса.
265. Почему нормализация базы данных — это то же самое, что наведение порядка в шкафу
 Изучите нормализацию базы данных простым для понимания способом на примерах из зоомагазина. Откройте для себя различные уровни от 1NF до 3NF и важность данных
Изучите нормализацию базы данных простым для понимания способом на примерах из зоомагазина. Откройте для себя различные уровни от 1NF до 3NF и важность данных
266. Интеграция WunderGraph с фауной
 Fauna — это распределенная документно-реляционная база данных, предоставляемая в виде облачного API.
Fauna — это распределенная документно-реляционная база данных, предоставляемая в виде облачного API.
267. Как эффективно запрашивать несколько результатов с помощью Dapper ORM
 Dapper — это мощный и легкий инструмент объектно-реляционного сопоставления (ORM) для C#. Он разработан, чтобы быть простым и быстрым, что позволяет разработчикам выполнять SQL-запрос
Dapper — это мощный и легкий инструмент объектно-реляционного сопоставления (ORM) для C#. Он разработан, чтобы быть простым и быстрым, что позволяет разработчикам выполнять SQL-запрос
268. Создавайте гибкие API-интерфейсы GraphQL, рассматривая схему как базу данных
 Создавайте гибкие API-интерфейсы GraphQL, рассматривая схему как базу данных
Создавайте гибкие API-интерфейсы GraphQL, рассматривая схему как базу данных
269. Призрак в вашей машине
 Что может быть страшнее Хэллоуина? Перенос данных.
Что может быть страшнее Хэллоуина? Перенос данных.
270. Как важно оставаться скромной и сильной корпоративной культурой: Стивен Голдберг, генеральный директор HarperDB
 Harper DB — номинант на премию «Стартап года» из Денвера, штат Колорадо. Стивен Голдберг, генеральный директор, рассказывает об истории создания и о том, что делает корпоративную культуру актуальной.
Harper DB — номинант на премию «Стартап года» из Денвера, штат Колорадо. Стивен Голдберг, генеральный директор, рассказывает об истории создания и о том, что делает корпоративную культуру актуальной.
271. грабли db:drop 🐑
 Приведенные ниже команды терминала позволят вам удалить и заново создать базу данных Active Record.
Приведенные ниже команды терминала позволят вам удалить и заново создать базу данных Active Record.
272. Присоединяйтесь к записи данных в свою первую децентрализованную базу данных
 Сеть DB3 — это стартовый проект по созданию децентрализованной платформы без разрешений для программируемой обработки данных.
Сеть DB3 — это стартовый проект по созданию децентрализованной платформы без разрешений для программируемой обработки данных.
273. Шесть лучших баз данных для разработки приложений React Native
 В этом посте мы рассматриваем лучшие базы данных для React Native, которые помогут вам создать новое приложение.
В этом посте мы рассматриваем лучшие базы данных для React Native, которые помогут вам создать новое приложение.
274. OpenSergo & ShardingSphere выпускает стандарт управления базами данных для микросервисов
 ShardingSphere сотрудничает с OpenSergo от Alibaba Cloud, чтобы объединить Database Plus & Database Mesh и выпустить стандарт управления базами данных для микросервисов.
ShardingSphere сотрудничает с OpenSergo от Alibaba Cloud, чтобы объединить Database Plus & Database Mesh и выпустить стандарт управления базами данных для микросервисов.
275. Как технологии изменили нашу жизнь
 Вы когда-нибудь осознавали, что технологии осторожно меняют нашу жизнь? За последние несколько лет в мире появилось несколько удивительных изобретений и технологий. Все это сделало нашу жизнь быстрее и проще. Мы набросали несколько основных областей, в которых технологии приносят кардинальные изменения. Давайте посмотрим, как это изменило нашу жизнь.
Вы когда-нибудь осознавали, что технологии осторожно меняют нашу жизнь? За последние несколько лет в мире появилось несколько удивительных изобретений и технологий. Все это сделало нашу жизнь быстрее и проще. Мы набросали несколько основных областей, в которых технологии приносят кардинальные изменения. Давайте посмотрим, как это изменило нашу жизнь.
276. Проводим выходные с GraphQL

277. Управление базами данных: почему разработчики предпочитают PostgreSQL?
 Разработка PostgreSQL имеет встроенную поддержку хеш-таблицы и обычных индексов B-tree. Лучшая система управления базами данных имеет четыре метода доступа к индексу.
Разработка PostgreSQL имеет встроенную поддержку хеш-таблицы и обычных индексов B-tree. Лучшая система управления базами данных имеет четыре метода доступа к индексу.
278. Создание баз данных для тестов или других целей

279. Руководство по устранению неполадок внешнего протокола ShardingSphere-Proxy и примеры
 Практический пример: знакомство с инструментами, используемыми при разработке протокола базы данных, с руководством по устранению неполадок протокола ShardingSphere-Proxy MySQL.
Практический пример: знакомство с инструментами, используемыми при разработке протокола базы данных, с руководством по устранению неполадок протокола ShardingSphere-Proxy MySQL.
280. Ошибка, которая может стоить вам миллионы: что это такое и как ее исправить
 Эта маленькая ошибка golang может стоить вашему бизнесу проблемы на миллион долларов. Вы можете легко избежать ошибки, читая блог
Эта маленькая ошибка golang может стоить вашему бизнесу проблемы на миллион долларов. Вы можете легко избежать ошибки, читая блог
281. Еще одна ОС на базе блокчейна — YABBOS
 Что такое ЯББОС?
Что такое ЯББОС?
282. Применение DistSQL: создание динамической распределенной базы данных
 На примере сегментирования данных мы проиллюстрируем сценарии приложений DistSQL для создания распределенной базы данных.
На примере сегментирования данных мы проиллюстрируем сценарии приложений DistSQL для создания распределенной базы данных.
283. Не добавлять индекс базы данных, если он уже существует в Rails

284. Что такое Redis и как он может ускорить ваш сайт на 30–40 %?
 Redis — это тип базы данных, который можно использовать для значительного повышения скорости загрузки вашего веб-сайта благодаря его дизайну и универсальному набору модулей.
Redis — это тип базы данных, который можно использовать для значительного повышения скорости загрузки вашего веб-сайта благодаря его дизайну и универсальному набору модулей.
285. Неожиданные открытия в TypeORM 0.3.11
 TypeORM — это инструмент ORM для TypeScript, поддерживает популярные базы данных и упрощает взаимодействие с ними. Обновите до версии 0.3.11, чтобы получить новые функции и улучшения.
TypeORM — это инструмент ORM для TypeScript, поддерживает популярные базы данных и упрощает взаимодействие с ними. Обновите до версии 0.3.11, чтобы получить новые функции и улучшения.
286. Введение в редактор GraphQL версии 4.5
 Новая версия редактора GraphQL
Новая версия редактора GraphQL
287. Что такое бесконфликтные реплицированные типы данных (CRDT)?
 В мире, где большинство приложений, которые мы используем в Интернете, по своей природе являются совместными, конфликты данных являются обычным явлением. Есть ли способ избежать этого?
В мире, где большинство приложений, которые мы используем в Интернете, по своей природе являются совместными, конфликты данных являются обычным явлением. Есть ли способ избежать этого?
288. Объяснение Amazon RDS с помощью комиксов
 Amazon RDS — это служба базы данных SQL, предоставляемая AWS. Из этой записи блога вы узнаете об Amazon RDS и его возможностях с помощью юмористического объяснения
Amazon RDS — это служба базы данных SQL, предоставляемая AWS. Из этой записи блога вы узнаете об Amazon RDS и его возможностях с помощью юмористического объяснения
289. Настройте GraphQL API для базы данных Firebase Realtime с помощью StepZen
 База данных Firebase Realtime — это база данных NoSQL в облаке. У него нет GraphQL API, но есть REST API, который можно преобразовать с помощью StepZen.
База данных Firebase Realtime — это база данных NoSQL в облаке. У него нет GraphQL API, но есть REST API, который можно преобразовать с помощью StepZen.
290. Как Smart Analytics может помочь малому бизнесу увеличить продажи
 Технологии захватили мир, и сейчас настало время для малого бизнеса понять, что им нужны именно технологии. Интеллектуальная аналитика упрощает работу.
Технологии захватили мир, и сейчас настало время для малого бизнеса понять, что им нужны именно технологии. Интеллектуальная аналитика упрощает работу.
291. 7 показателей качества данных, которым следует уделить приоритетное внимание
 Наличие высококачественных данных может помочь или разрушить ваши проекты в области машинного обучения или управления бизнесом. Эти 7 показателей качества данных оказывают наибольшее влияние.
Наличие высококачественных данных может помочь или разрушить ваши проекты в области машинного обучения или управления бизнесом. Эти 7 показателей качества данных оказывают наибольшее влияние.
292. Новейшие рубежи современного стека данных
 Операции, управляемые данными, — это новейшая разработка современного стека данных с инструментами.
Операции, управляемые данными, — это новейшая разработка современного стека данных с инструментами.
293. 6 причин, по которым вам следует перейти с Oracle на PostgreSQL
 В отличие от проприетарных решений (таких как Oracle), вы не будете привязаны к постоянно растущим лицензионным сборам. Вот 6 причин, по которым вам следует перейти на PostgreSQL.
В отличие от проприетарных решений (таких как Oracle), вы не будете привязаны к постоянно растущим лицензионным сборам. Вот 6 причин, по которым вам следует перейти на PostgreSQL.
294. Реакция SAS (системы статистического анализа) на вызовы SQL в среде хранилища данных
 По мере того, как вычислительное оборудование становилось все более мощным, наборы данных росли. SAS, в свою очередь, развивался, чтобы использовать большую вычислительную мощность и решать проблемы с данными.
По мере того, как вычислительное оборудование становилось все более мощным, наборы данных росли. SAS, в свою очередь, развивался, чтобы использовать большую вычислительную мощность и решать проблемы с данными.
295. Создайте свой собственный удобный кроссплатформенный менеджер паролей
 Я использую локальный менеджер паролей на своем компьютере: я просто придерживаюсь пароля, и это единственный пароль, который я запоминаю.
Я использую локальный менеджер паролей на своем компьютере: я просто придерживаюсь пароля, и это единственный пароль, который я запоминаю.
296. Представляем RecallGraph (ранее CivicGraph)

297. Подзапрос для предоставления разработчикам Algorand инфраструктуры индексирования и запросов
 SubQuery – это набор инструментов для разработчиков блокчейнов, упрощающий создание будущих приложений Web3.
SubQuery – это набор инструментов для разработчиков блокчейнов, упрощающий создание будущих приложений Web3.
298. Снимок стоит тысячи слов (расшифровка подкаста)
 Так ли страшна миграция базы данных, как кажется? Эми Том беседует с Мэттом Гроувсом, старшим менеджером по управлению проектами в Couchbase, и Куртом Грацем, совладельцем CKH Consulting.
Так ли страшна миграция базы данных, как кажется? Эми Том беседует с Мэттом Гроувсом, старшим менеджером по управлению проектами в Couchbase, и Куртом Грацем, совладельцем CKH Consulting.
299. Чего вам не говорят о Headless CMS
 Размышления о двух проектах внедрения headless CMS.
Размышления о двух проектах внедрения headless CMS.
300. Когда ORM не подчиняются: история о мангустах
 Оглядываясь назад, кажется, что мангуст поступил разумно, просто убедившись, что документ существует в базе данных.
Оглядываясь назад, кажется, что мангуст поступил разумно, просто убедившись, что документ существует в базе данных.
301. Хитрость Data Engineering: использование CDP для упрощения сбора данных
 Платформы клиентских данных (CDP) — от упрощения сбора данных до обеспечения разработки функций на основе данных — имеют большое значение для инженеров.
Платформы клиентских данных (CDP) — от упрощения сбора данных до обеспечения разработки функций на основе данных — имеют большое значение для инженеров.
302. Как повысить качество данных в 2022 году
 Данные низкого качества могут разрушить все, что вы построили. Обеспечение качества данных — сложная, но необходимая задача. 100% может быть слишком амбициозным, но вот что y
Данные низкого качества могут разрушить все, что вы построили. Обеспечение качества данных — сложная, но необходимая задача. 100% может быть слишком амбициозным, но вот что y
303. Так много данных. Так мало времени для неэффективных поисков.
 Как мы можем получить доступ к этим данным правильно? Если не упрощать и не открывать эту дверь, информация — это всего лишь биты.
Как мы можем получить доступ к этим данным правильно? Если не упрощать и не открывать эту дверь, информация — это всего лишь биты.
304. Отсутствующие реестры блокчейнов — миф о DLT
 Блокчейны и DLT — это не одно и то же. Вот почему.
Блокчейны и DLT — это не одно и то же. Вот почему.
305. Улучшение работы с CriteriaAPI с использованием шаблона Builder и статической метамодели JPA — часть III
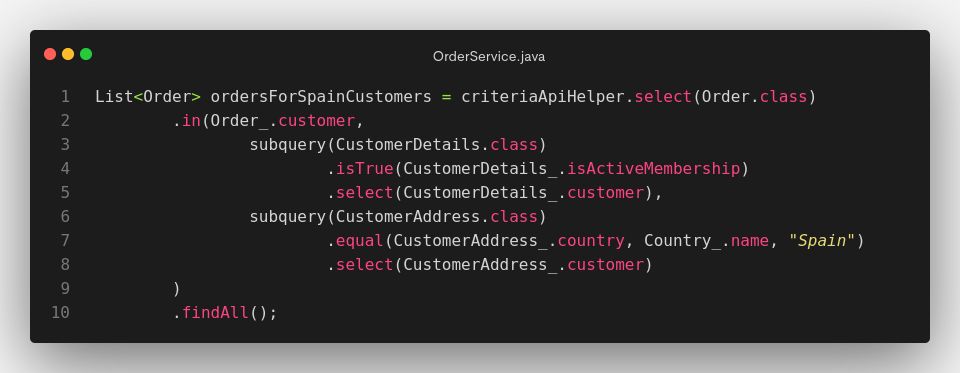 Расширение для Criteria API с использованием шаблона Builder и генератора статической метамодели JPA для уменьшения сложности за счет ясности и повышения удобочитаемости
Расширение для Criteria API с использованием шаблона Builder и генератора статической метамодели JPA для уменьшения сложности за счет ясности и повышения удобочитаемости
306. Введение в безопасность резервного копирования баз данных для начинающих
 Поскольку все больше компаний собирают данные о клиентах, резервные копии базы данных играют ключевую роль.
Поскольку все больше компаний собирают данные о клиентах, резервные копии базы данных играют ключевую роль.
307. Расшифровка результатов запроса MySQL EXPLAIN для повышения производительности
 Понимание MySQL объясняет, что вывод запроса необходим для оптимизации запроса. EXPLAIN — хороший инструмент для анализа вашего запроса.
Понимание MySQL объясняет, что вывод запроса необходим для оптимизации запроса. EXPLAIN — хороший инструмент для анализа вашего запроса.
308. Tencent Music переходит с ClickHouse на Apache Doris
 Эволюция нашей архитектуры обработки данных в направлении повышения производительности и упрощения обслуживания в Tencent Music.
Эволюция нашей архитектуры обработки данных в направлении повышения производительности и упрощения обслуживания в Tencent Music.
309. Использование архитектуры данных самообслуживания для обмена данными между группами разработчиков
 В этой статье рассказывается о синергии между двумя широко распространенными проектами с открытым исходным кодом, Alluxio и Presto.
В этой статье рассказывается о синергии между двумя широко распространенными проектами с открытым исходным кодом, Alluxio и Presto.
310. Поговорка базы данных: терпение — это НЕ добродетель
 В мире изобилия технологий выбрать правильную базу данных может быть непросто.
В мире изобилия технологий выбрать правильную базу данных может быть непросто.
311. Как эффективно управлять очередями в базах данных SQL
 Очередь с использованием SQL-базы? ну, вам нужно знать плюсы и минусы и типичную реализацию.
Очередь с использованием SQL-базы? ну, вам нужно знать плюсы и минусы и типичную реализацию.
312. Учебник по отделению механизмов SQL от хранилища данных Hive
 Используете ли вы механизмы SQL, такие как Presto, для запросов к существующему хранилищу данных Hive и сталкиваетесь с проблемами?
Используете ли вы механизмы SQL, такие как Presto, для запросов к существующему хранилищу данных Hive и сталкиваетесь с проблемами?
313. Как повысить скорость запросов, чтобы максимально эффективно использовать данные
 В этой статье я расскажу о том, как я повысил общую эффективность обработки данных за счет оптимизации выбора и использования хранилищ данных.
В этой статье я расскажу о том, как я повысил общую эффективность обработки данных за счет оптимизации выбора и использования хранилищ данных.
314. Как импортировать базу данных MS SQL в Amazon RDS
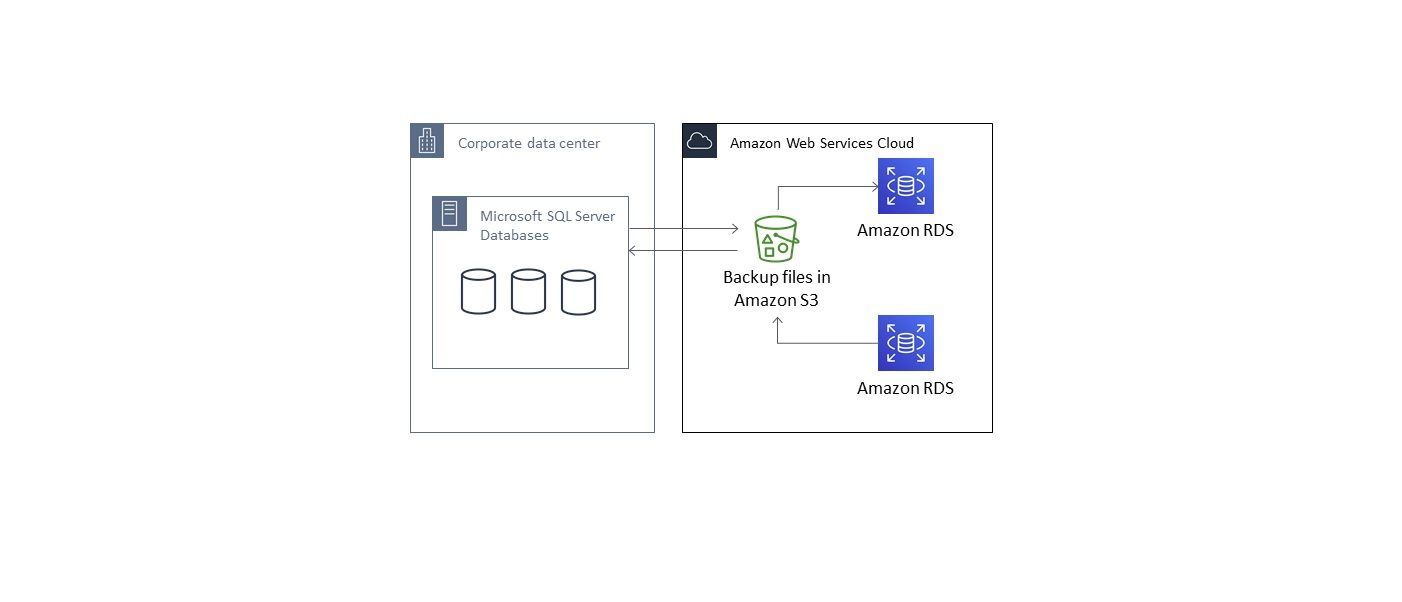 Я покажу вам, как создать базу данных в облаке, подключить ее к MS SQL, развернуть из резервной копии базы данных.
Я покажу вам, как создать базу данных в облаке, подключить ее к MS SQL, развернуть из резервной копии базы данных.
315. Использование dbt с Materialise и Redpanda

316. Приложение Refi позволяет разработчикам решить сразу 4 проблемы с Firestore: Подробнее
 Приложение Refi — инструмент, облегчающий разработчику взаимодействие с Firestore DB
Приложение Refi — инструмент, облегчающий разработчику взаимодействие с Firestore DB
317. Побить рекорд производительности распределенной базы данных с 10 миллионами операций в минуту!
 Apache ShardingSphere & openGauss: побит рекорд производительности распределенной базы данных с 10 миллионами транзакций в минуту.
Apache ShardingSphere & openGauss: побит рекорд производительности распределенной базы данных с 10 миллионами транзакций в минуту.
318. Создание REST API на Go с интеграцией MongoDB: пошаговое руководство
 Программируйте или напишите REST API с внутренними библиотеками GO и MongoDB в качестве базы данных
Программируйте или напишите REST API с внутренними библиотеками GO и MongoDB в качестве базы данных
319. Kubernetes-Native Database: TiDB Vs. База данных DataStax Astra
 Посмотрите на две базы данных, которые претендуют на собственный ярлык Kubernetes: TiDB и DataStax Astra DB.
Посмотрите на две базы данных, которые претендуют на собственный ярлык Kubernetes: TiDB и DataStax Astra DB.
320. Углубленный взгляд на MySQL Vs. PostgreSQL
 PostgreSQL и MySQL — это надежные, безопасные и масштабируемые базы данных, которые существуют уже много лет.
PostgreSQL и MySQL — это надежные, безопасные и масштабируемые базы данных, которые существуют уже много лет.
321. Что такое хэши Redis
 Хэши Redis — это тип записи, хранящейся в базе данных Redis. Они мало похожи на объекты JSON и хранят данные в виде пар "ключ-значение".
Хэши Redis — это тип записи, хранящейся в базе данных Redis. Они мало похожи на объекты JSON и хранят данные в виде пар "ключ-значение".
322. Создание API Python с открытым исходным кодом (Tribal) с использованием Django REST Framework — часть третья
 Я буду рад дать всестороннее обучение по созданию и развертыванию REST API с открытым исходным кодом с использованием Django REST framework.
Я буду рад дать всестороннее обучение по созданию и развертыванию REST API с открытым исходным кодом с использованием Django REST framework.
323. 4 преобразования данных с помощью электронных таблиц
 Gigasheet сочетает в себе простоту электронной таблицы, мощность базы данных и масштабы облака.
Gigasheet сочетает в себе простоту электронной таблицы, мощность базы данных и масштабы облака.
324. 10 принципов правильного сравнительного анализа базы данных
 В этой статье вы узнаете все о том, как оценивать тесты БД.
В этой статье вы узнаете все о том, как оценивать тесты БД.
325. Отключение регистрации (конфиденциальных) аргументов в активном задании в Ruby [Практическое руководство]

326. Apache Druid, TiDB, ClickHouse или Apache Doris? Сравнение инструментов OLAP
 Опыт OLAP производителя автомобилей.
Опыт OLAP производителя автомобилей.
327. Проверка Active Record в Rails: как они работают
 ver открыть консоль Rails, чтобы отладить проблему, и уйти, удивляясь, как данные стали такими странными? Несмотря на все наши усилия, база данных примет много мусорных данных, если вы позволите. Существует множество способов обойти обратные вызовы и проверки Rails при обновлении базы данных. Если вы похожи на меня, вы, вероятно, использовали эти методы в консоли Rails, чтобы исправить некоторые странные данные, которые вы нашли после того, как какой-то другой код создал их в первую очередь.
ver открыть консоль Rails, чтобы отладить проблему, и уйти, удивляясь, как данные стали такими странными? Несмотря на все наши усилия, база данных примет много мусорных данных, если вы позволите. Существует множество способов обойти обратные вызовы и проверки Rails при обновлении базы данных. Если вы похожи на меня, вы, вероятно, использовали эти методы в консоли Rails, чтобы исправить некоторые странные данные, которые вы нашли после того, как какой-то другой код создал их в первую очередь.
328. Как использовать Postgres для воссоздания YikYak
329. Советы по Kafka Connect на Heroku, которые нельзя пропустить

330. SPI Apache ShardingSphere и почему он проще, чем у Dubbo
 По сравнению с Dubbo, ShardingSphere SPI является более оптимизированным, мощным и простым в использовании. В этом посте рассматривается SPI Apache ShardingSphere и его простота.
По сравнению с Dubbo, ShardingSphere SPI является более оптимизированным, мощным и простым в использовании. В этом посте рассматривается SPI Apache ShardingSphere и его простота.
331. Как получить аналитику в реальном времени путем консолидации баз данных
 Сравнительный анализ гибридной транзакционной и аналитической СУБД (Фото: Sawitre)
Сравнительный анализ гибридной транзакционной и аналитической СУБД (Фото: Sawitre)
332. Общие сведения о шаблоне разделения ответственности командных запросов

333. Лучшие типы визуализации данных
 Изучение лучших инструментов визуализации данных может стать первым шагом к использованию анализа данных в ваших интересах и на благо вашей компании
Изучение лучших инструментов визуализации данных может стать первым шагом к использованию анализа данных в ваших интересах и на благо вашей компании
334. SQL-запросы: зачем вам SQL-независимый синтаксический анализ
 Не нужно быть экспертом в тысячах комбинаций SQL, типов данных и баз данных, чтобы освоить SQL-запросы. Хороший независимый от SQL синтаксический анализатор позаботится обо всем.
Не нужно быть экспертом в тысячах комбинаций SQL, типов данных и баз данных, чтобы освоить SQL-запросы. Хороший независимый от SQL синтаксический анализатор позаботится обо всем.
335. Станьте лучшим администратором баз данных [Практическое руководство]
 Благодаря тому, что передовые технологии появляются каждый год, будущее технологий баз данных и облачных вычислений выглядит безопасным. Каждой организации, большой или маленькой, нужна база данных для хранения всех связанных данных, потому что данные более ценны, чем сами деньги.
Благодаря тому, что передовые технологии появляются каждый год, будущее технологий баз данных и облачных вычислений выглядит безопасным. Каждой организации, большой или маленькой, нужна база данных для хранения всех связанных данных, потому что данные более ценны, чем сами деньги.
336. Изучение базы данных Neo4J Graph
 В этой статье вы узнаете больше о базе данных NoSQL Graph — NEO4J.
В этой статье вы узнаете больше о базе данных NoSQL Graph — NEO4J.
337. Когда и как следует использовать программное обеспечение для очистки слиянием?
 Объединение записей данных из базы данных вашей компании, особенно когда они поступают из нескольких источников...
Объединение записей данных из базы данных вашей компании, особенно когда они поступают из нескольких источников...
338. Представляем Apache ShardingSphere 5.2.0!
 Выпущен ShardingSphere 5.2.0, предлагающий новые облачные возможности, эластичную миграцию с Oracle, MySQL и PostgreSQL, а также дополнительные функции и возможности. улучшения
Выпущен ShardingSphere 5.2.0, предлагающий новые облачные возможности, эластичную миграцию с Oracle, MySQL и PostgreSQL, а также дополнительные функции и возможности. улучшения
339. Как использовать OpenTelemetry для определения зависимостей базы данных
 Устали отлаживать свое приложение, чтобы выяснить его зависимости от базы данных? Есть более разумный способ отслеживать их с помощью OpenTelemetry.
Устали отлаживать свое приложение, чтобы выяснить его зависимости от базы данных? Есть более разумный способ отслеживать их с помощью OpenTelemetry.
340. 10-минутное руководство по исправлению поврежденных баз данных SQL — восстановление не требуется!
 В этой статье я рассказал об использовании бесплатного приложения под названием FDR, которое может помочь вам восстановить поврежденные базы данных MS SQL.
В этой статье я рассказал об использовании бесплатного приложения под названием FDR, которое может помочь вам восстановить поврежденные базы данных MS SQL.
341. Вычислительная инфраструктура, стоящая за оценкой риска местоположения Habidatum
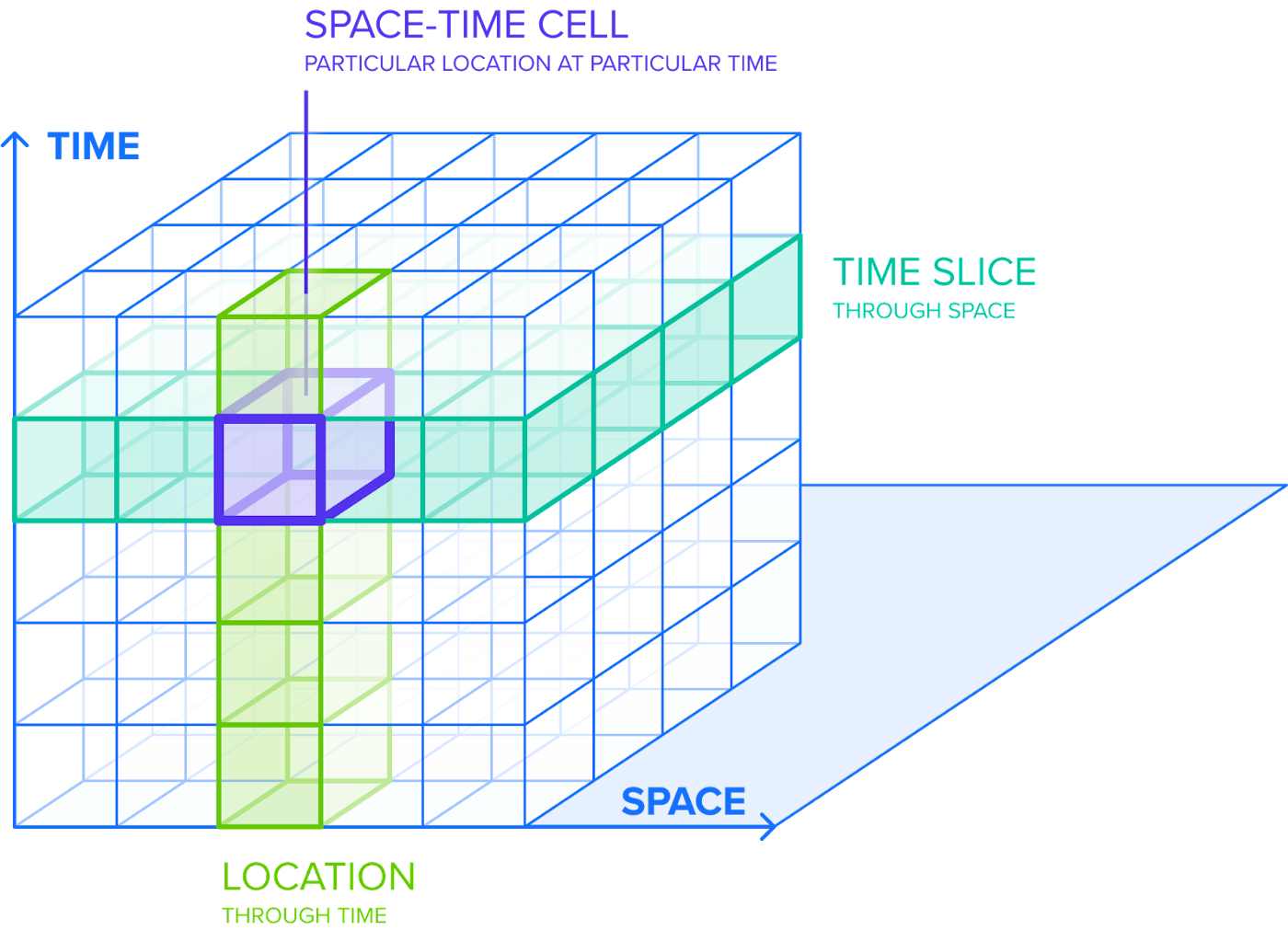 Узнайте об индексации пространства-времени в масштабе с помощью quadkeys и clickhouse.
Узнайте об индексации пространства-времени в масштабе с помощью quadkeys и clickhouse.
342. Оптимизация операций базы данных с помощью OpenTelemetry
 Научитесь использовать OpenTelemetry, чтобы отслеживать и выявлять проблемы с базой данных в вашем приложении и устранять их, чтобы быстро оптимизировать операции с базой данных.
Научитесь использовать OpenTelemetry, чтобы отслеживать и выявлять проблемы с базой данных в вашем приложении и устранять их, чтобы быстро оптимизировать операции с базой данных.
343. Краткое руководство по использованию ShardingSphere-Proxy в реальных производственных сценариях
 В этом посте описывается, как использовать ShardingSphere-Proxy и в чем его отличия от ShardingSphere-JDBC.
В этом посте описывается, как использовать ShardingSphere-Proxy и в чем его отличия от ShardingSphere-JDBC.
344. Решение проблем с репликацией, высокопроизводительными запросами и другими проблемами платформ данных
345. Как защитить нас от неизвестных звонков?

346. Анализ 110 миллионов комментариев от Hacker News
 В этой статье мы рассмотрим еще один тест с 1,1 миллионом комментариев, отобранных Hacker News, с числовыми полями
В этой статье мы рассмотрим еще один тест с 1,1 миллионом комментариев, отобранных Hacker News, с числовыми полями
347. Интеграция Flyway с Spring Boot
 Узнайте, как интегрировать FlywayDB в загрузочное приложение Spring, чтобы помочь с добавлением функций миграции базы данных в ваш проект Spring Boot с помощью Flyway.
Узнайте, как интегрировать FlywayDB в загрузочное приложение Spring, чтобы помочь с добавлением функций миграции базы данных в ваш проект Spring Boot с помощью Flyway.
348. Действительно ли репликации MySQL настолько гладкие, как вы думаете?
 Что вы на самом деле упускаете в репликации MySQL? Это кажется простым, но устранение проблемы, вызванной этим, занимает много времени. Итак, вот ваш ответ.
Что вы на самом деле упускаете в репликации MySQL? Это кажется простым, но устранение проблемы, вызванной этим, занимает много времени. Итак, вот ваш ответ.
349. Подробное руководство по сине-зеленым развертываниям с помощью Materialize
 Минимизация времени простоя во время любого развертывания является ключевой частью любой успешной стратегии развертывания. Есть много способов добиться этого.
Минимизация времени простоя во время любого развертывания является ключевой частью любой успешной стратегии развертывания. Есть много способов добиться этого.
350. Фабрика данных Azure: потрясающий инструмент для переноса данных

351. Создание хранилища данных нового поколения: 10-кратное увеличение производительности
 Как легко подключить различные источники данных и обеспечить высокую производительность запросов.
Как легко подключить различные источники данных и обеспечить высокую производительность запросов.
352. Введение в AvionDB: распределенная база данных, подобная MongoDB
 В последние несколько месяцев мы часто получали этот вопрос:
В последние несколько месяцев мы часто получали этот вопрос:
353. Открытый исходный код — единственный способ справиться с «длинным хвостом» интеграции
 Разве не было бы здорово сократить время, необходимое для создания нового коннектора интеграции данных, до 10 минут? Это, безусловно, помогло бы избавиться от длинного хвоста
Разве не было бы здорово сократить время, необходимое для создания нового коннектора интеграции данных, до 10 минут? Это, безусловно, помогло бы избавиться от длинного хвоста
354. Понимание концепций Database Plus и проблем, которые он может решить
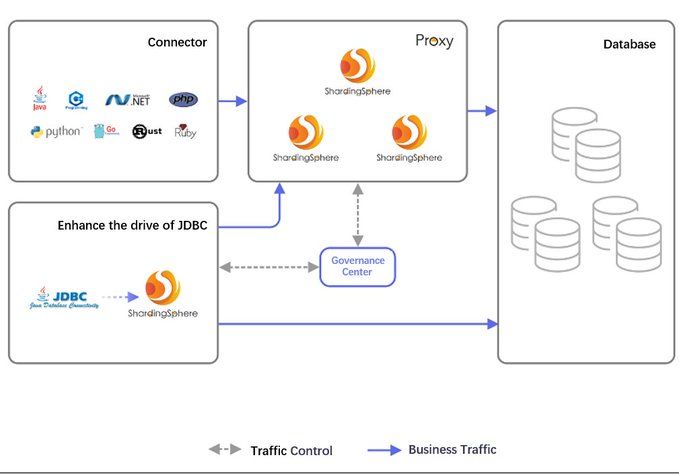 Объяснение концепции Database Plus, ее влияния на проектирование системной архитектуры и нововведений от Proxyless Service Mesh до поддержки серверной части микросервисов
Объяснение концепции Database Plus, ее влияния на проектирование системной архитектуры и нововведений от Proxyless Service Mesh до поддержки серверной части микросервисов
355. Как управлять конфиденциальными данными с помощью обнаружения и классификации данных SQL

356. Введение в Redis: база данных в памяти
 Redis — это тип базы данных, и его можно добавить в приложение производственного уровня, чтобы повысить его производительность. Я расскажу об основах Redis и покажу реальный пример Redis.
Redis — это тип базы данных, и его можно добавить в приложение производственного уровня, чтобы повысить его производительность. Я расскажу об основах Redis и покажу реальный пример Redis.
357. Сбор данных из 1,1 млн тщательно отобранных комментариев Hacker News
 В этом тесте мы используем набор данных из 1,1 млн комментариев Hacker News с числовыми полями с https://zenodo.org/record/45901.
В этом тесте мы используем набор данных из 1,1 млн комментариев Hacker News с числовыми полями с https://zenodo.org/record/45901.
358. Мониторинг базы данных и оповещение с помощью n8n 📡
 В последние несколько месяцев я экспериментировал с различными устройствами и датчиками IoT. Мне очень нравится, как их можно использовать для мониторинга различных вещей, таких как влажность, температура, давление и другие вещи в доме. В этом руководстве я хочу показать вам, как вы можете отслеживать показания датчиков в базе данных и отправлять оповещения, когда они пересекают пороговое значение, используя рабочие процессы n8n.
В последние несколько месяцев я экспериментировал с различными устройствами и датчиками IoT. Мне очень нравится, как их можно использовать для мониторинга различных вещей, таких как влажность, температура, давление и другие вещи в доме. В этом руководстве я хочу показать вам, как вы можете отслеживать показания датчиков в базе данных и отправлять оповещения, когда они пересекают пороговое значение, используя рабочие процессы n8n.
359. Создание приложения для обмена мемами с помощью Slash GraphQL
 Пошаговое руководство по созданию серверной службы Slash GraphQL для удовлетворения потребностей вымышленного клиента InstaMeme.
Пошаговое руководство по созданию серверной службы Slash GraphQL для удовлетворения потребностей вымышленного клиента InstaMeme.
360. Как извлечь ценную информацию из ваших данных
 Управляйте данными с помощью базы данных HarperDB. Получите доступ к своим данным из HarperDB с помощью пользовательской функции. Автоматизируйте EDA с помощью данных из базы данных harperDB с помощью sweetviz.
Управляйте данными с помощью базы данных HarperDB. Получите доступ к своим данным из HarperDB с помощью пользовательской функции. Автоматизируйте EDA с помощью данных из базы данных harperDB с помощью sweetviz.
361. Журналы Nginx — справедливые тесты базы данных
 Как работает один тест для анализа миллионов журналов Nginx с действующего веб-сайта и что можно узнать из результатов анализа при своевременной его обработке.
Как работает один тест для анализа миллионов журналов Nginx с действующего веб-сайта и что можно узнать из результатов анализа при своевременной его обработке.
362. Dapper Best Practices: руководство C# для разработчиков по управлению базами данных
 Dapper — это инструмент ORM с открытым исходным кодом, простой в использовании и легкий, что делает его популярным выбором для разработчиков .NET. Он предназначен для работы с различными
Dapper — это инструмент ORM с открытым исходным кодом, простой в использовании и легкий, что делает его популярным выбором для разработчиков .NET. Он предназначен для работы с различными
363. Тестирование данных: важно как для обнаружения проблем, так и для качества реагирования

364. GitOps, Kubernetes и базы данных (расшифровка подкаста)
 Эми, Мэтт и Курт рассказывают о переходе с базы данных SQL на базу данных NoSQL, о том, что происходит, когда дерьмо попадает в вентилятор, и об оценке использования вашей базы данных.
Эми, Мэтт и Курт рассказывают о переходе с базы данных SQL на базу данных NoSQL, о том, что происходит, когда дерьмо попадает в вентилятор, и об оценке использования вашей базы данных.
365. Что за оболочка?! (стенограмма подкаста)
 Эми Том беседует с Майклом Нитшингером, архитектором программного обеспечения в Couchbase, и Джонатаном Д. Тернером (он же JT), соавтором NuShell, о сценариях Shell.
Эми Том беседует с Майклом Нитшингером, архитектором программного обеспечения в Couchbase, и Джонатаном Д. Тернером (он же JT), соавтором NuShell, о сценариях Shell.
366. От фермы к данным: карьера технического специалиста в маркетинге продуктов (расшифровка подкаста)
 Эми Том беседует с Мэттом Гроувсом, старшим менеджером по маркетингу продуктов в Couchbase, и Робом Хеджпетом, консультантом разработчиков в MariaDB, об их карьере.
Эми Том беседует с Мэттом Гроувсом, старшим менеджером по маркетингу продуктов в Couchbase, и Робом Хеджпетом, консультантом разработчиков в MariaDB, об их карьере.
367. Как добавить почтовый ящик действий в приложение Rails 6

368. Базы данных документов и реляционные базы данных (расшифровка подкаста)
 Эми Том беседует с Эриком Бишардом и Аруном Виджаярагхаваном о различиях между базой данных документов и реляционной базой данных.
Эми Том беседует с Эриком Бишардом и Аруном Виджаярагхаваном о различиях между базой данных документов и реляционной базой данных.
369. Она на краю облаков (стенограмма подкаста)
 Эми Том беседует с Марком Гэмблом, Product & Директор по маркетингу решений в Couchbase, о Edge Computing и многоуровневых системах данных.
Эми Том беседует с Марком Гэмблом, Product & Директор по маркетингу решений в Couchbase, о Edge Computing и многоуровневых системах данных.
Спасибо, что ознакомились с 369 самыми читаемыми статьями о базе данных на HackerNoon.
Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)