

3 лучших альтернативы Hadoop для миграции
27 января 2023 г.Эта фундаментальная технология хранения и обработки больших данных является проектом верхнего уровня Apache Software Foundation.
По умолчанию для установки Hadoop в кластере требуются предварительно настроенные машины, ручная установка пакетов и множество других движений. Однако документация часто бывает неполной или просто устаревшей. По мере развития технологий компании ищут альтернативы «слону», популярность которого начинает снижаться.
Hadoop прошел через разные этапы: сначала он был инновационным и ценным, а теперь достиг плато производительности.
В этой статье мы обсудим, почему Hadoop теряет популярность и какие другие варианты доступны, которые потенциально могут заменить его.
Hadoop — это не только Hadoop
Экосистема Hadoop — это набор инструментов и сервисов, которые можно использовать для обработки больших наборов данных. Он состоит из четырех основных компонентов: HDFS, MapReduce, YARN и Hadoop Common. Вместе эти компоненты обеспечивают такие функции, как хранение, анализ и обслуживание данных.
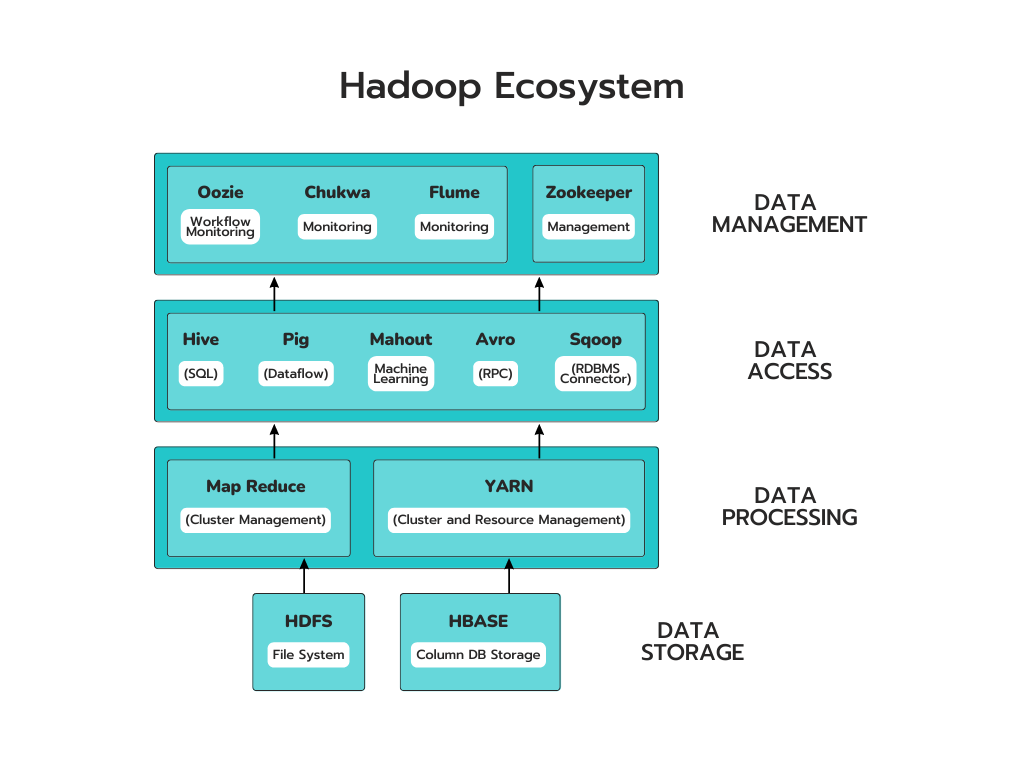
Экосистема Hadoop состоит из следующих элементов:
* HDFS: распределенная файловая система Hadoop * YARN: еще один переговорщик ресурсов * MapReduce: обработка данных на основе программирования * Spark: обработка данных в памяти * PIG, HIVE: обработка данных на основе запросов. * HBase: База данных NoSQL * Mahout, Spark MLLib: библиотеки алгоритмов машинного обучения * Solar, Lucene: поиск и индексирование * Zookeeper: Управление кластером * Узи: планирование работы
Экосистема Hadoop также включает в себя несколько других компонентов, помимо перечисленных выше.
Почему Hadoop снижается?
Согласно данным Google Trends, с 2014 по 2017 год сервис Hadoop был самым востребованным. По прошествии этого периода количество поисковых запросов по нему начало снижаться. Это снижение неудивительно из-за нескольких факторов, предполагающих в конечном итоге падение его популярности.
Новые рыночные требования к новым технологиям и анализу данных
Hadoop был создан для удовлетворения потребностей в хранении больших данных. В настоящее время люди хотят большего от систем управления данными, таких как более быстрый анализ, отдельное хранение и обработка данных, а также возможности искусственного интеллекта и машинного обучения для искусственного интеллекта и машинного обучения.
Hadoop предлагает ограниченную поддержку анализа больших данных по сравнению с другими новыми технологиями, такими как Redis, Elastisearch и ClickHouse. Эти технологии становятся все более популярными благодаря своей способности анализировать большие объемы данных.
Быстрорастущие поставщики и услуги облачных сервисов
За последнее десятилетие облачные вычисления быстро продвинулись вперед, обогнав традиционные компании-разработчики программного обеспечения, такие как IBM и HP. В первые дни поставщики облачных услуг использовали инфраструктуру как услугу (IaaS) для развертывания Hadoop на AWS EMR, который утверждал, что является наиболее широко используемым кластером Hadoop в мире. С помощью облачных сервисов пользователи могут в любой момент легко развернуть или отключить кластер, а также воспользоваться преимуществами услуги безопасного резервного копирования данных.
Кроме того, поставщики облачных услуг предоставляют ряд услуг для создания общей экосистемы для сценариев больших данных. К ним относятся AWS S3 для экономичного хранилища, Amazon DynamoDB для быстрого доступа к данным типа «ключ-значение» и Athena в качестве бессерверного сервиса запросов для анализа больших данных.
Усложнение экосистемы Hadoop
Экосистема Hadoop становится все более сложной из-за появления новых технологий и поставщиков облачных услуг, что затрудняет пользователям использование всех ее компонентов. Альтернативой является использование строительных блоков; однако это добавляет дополнительный уровень сложности.
На приведенном выше рисунке показано, что в Hadoop часто используется не менее тринадцати компонентов, что затрудняет его изучение и управление.
Каковы альтернативы?
Технологическая отрасль адаптируется к проблемам, связанным с Hadoop, таким как сложность и отсутствие обработки в реальном времени. Появились другие решения, направленные на решение этих проблем. Эти альтернативы предлагают различные варианты в зависимости от того, нужна ли вам локальная или облачная инфраструктура.
Google BigQuery
Google BigQuery – это платформа, помогающая пользователям анализировать большие объемы данных, не беспокоясь о базе данных. или управление инфраструктурой. Он позволяет пользователям использовать SQL и использует Google Storage для интерактивного анализа данных.
Вам не нужно вкладывать средства в дополнительное оборудование для обработки больших объемов данных. Его алгоритмы помогают выявлять в данных модели поведения пользователей, которые трудно идентифицировать с помощью стандартных отчетов.
BigQuery — мощная альтернатива Hadoop, поскольку она легко интегрируется с MapReduce. Google постоянно добавляет функции и обновляет BigQuery, чтобы предоставить пользователям исключительный опыт анализа данных. Они упростили импорт пользовательских наборов данных и их использование с такими службами, как Google Analytics.
Апач Спарк
Apache Spark — популярный и мощный вычислительный механизм, используемый для обработки данных Hadoop. Это обновление Hadoop, обеспечивающее более высокую скорость и поддерживающее различные приложения, которые можно использовать.
Spark — это инструмент, который можно применять независимо от Hadoop, и он становится все более популярным для целей аналитики. Он более практичен, чем Hadoop, что делает его хорошим выбором для многих предприятий. IBM и другие компании приняли его из-за его гибкости и способности работать с различными источниками данных.
Spark — это платформа с открытым исходным кодом, которая обеспечивает быструю обработку данных в реальном времени, до 100 раз быстрее, чем MapReduce от Hadoop. Его можно запускать на различных платформах, таких как Apache Mesos, EC2 и Hadoop, — либо из облака, либо из выделенного кластера. Благодаря этому он хорошо подходит для приложений, основанных на машинном обучении.
Снежинка
Snowflake – это облачная служба, предоставляющая такие услуги, как хранение данных, проектирование , наука и разработка приложений. Это также обеспечивает безопасный обмен и использование данных в реальном времени.
Облачное хранилище данных может предоставить вам преимущества хранения и управления вашими данными в облаке. Хотя Hadoop — отличный инструмент для анализа больших объемов данных, его настройка и использование могут быть сложными. Более того, оно не предлагает всех функций, обычно связанных с хранилищем данных.
Snowflake может снизить сложность и стоимость развертывания Hadoop локально или в облаке. Это устраняет необходимость в Hadoop, поскольку не требует подготовки оборудования, программного обеспечения, сертификации программного обеспечения для распространения или настройки конфигурации.
Когда рассматривать альтернативы Hadoop?
Hadoop — это одно из множества решений для работы с большими данными. По мере роста размера, сложности и объема данных компании изучают альтернативы, которые могут предложить производительность, масштабируемость и экономическую выгоду. Принимая эти решения, важно учитывать конкретные варианты использования, бюджеты и цели организации, прежде чем выбирать решение для работы с большими данными.
Во многих случаях могут быть лучшие варианты, чем миграция с Hadoop. Многие клиенты вложили значительные средства в платформу, что сделало ее миграцию и тестирование новой слишком дорогостоящей. Поэтому отказываться от платформы нельзя. Однако следует учитывать альтернативы для новых вариантов использования и компонентов решений для работы с большими данными.
Подводя итоги
Не существует одной лучшей альтернативы Hadoop, потому что Hadoop никогда не был чем-то одним. Вместо того, чтобы верить утверждениям, что Hadoop устарел, подумайте, что вам нужно от технологии и какие части не соответствуют вашим требованиям.
В конечном счете решение остаться с Hadoop или перейти на другое решение для работы с большими данными должно основываться на сценарии использования и конкретных потребностях организации. Важно учитывать преимущества стоимости, масштабируемости и производительности, которые могут обеспечить различные технологии.
Благодаря тщательной оценке и исследованиям компании могут сделать осознанный выбор, который наилучшим образом удовлетворит их потребности.
н
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)