

Как настроить экспериментальную среду для разработки продукта на основе данных
5 апреля 2023 г.Владелец продукта часто сталкивается с вопросом, следует ли использовать вариант А или вариант Б. Или какую версию экрана следует внедрить для достижения лучших результатов? Принятие таких решений может быть сложной задачей, особенно когда у вас сжатые сроки и ограниченные ресурсы. Кроме того, такие решения принимаются на основе личного суждения или копирования подхода конкурента, что может привести к неоптимальным результатам.
Хорошая новость заключается в том, что таких ловушек можно избежать, настроив простую экспериментальную среду, требующую относительно небольших усилий. В этой статье мы расскажем, как этого добиться.
Содержание
- Почему важно настроить экспериментальную среду.
- Мифы
- Настройка экспериментальной среды
- Определение цели вашего будущего эксперимента.
- Разработка архитектуры экспериментальной среды.
- Анализ и интерпретация результатов
- Расширение предпочтительного варианта.
- Вывод.
Почему важна настройка экспериментальной среды?
Настройка экспериментальной среды важна по двум причинам:
* Во-первых, это позволяет вам убедиться, что после внедрения новых функций вы выберете лучший вариант на основе подхода, основанного на данных.
* Во-вторых, это позволяет вам постоянно улучшать существующую функциональность вашего продукта, сравнивая «как есть» с гипотетическими «будущими» вариантами и выполняя анализ «что, если».
Мифы
Прежде чем перейти к подходу, давайте развенчаем некоторые мифы, которые обычно вводят в заблуждение владельцев продуктов:
<цитата>Мне нужно много ресурсов для настройки сложной среды, позволяющей проводить эксперименты и A/B-тесты
Неправильно. Описанный подход требует меньше недели ресурсов вашего инженера-программиста.
<цитата>Мне нужен отлаженный процесс сбора данных и подробное отслеживание событий
Неправильно: вы можете положиться на существующую базу данных, в которой хранится информация о жизненном цикле основного объекта вашего продукта. Например, статусы заказов, если вы работаете в службе доставки.
<цитата>Мне нужна специальная группа аналитиков, которая будет ежедневно обрабатывать мои запросы
Неправильно: как только вы поймете подход и показатели своего эксперимента, вы сможете регулярно получать данные самостоятельно, используя простой SQL-запрос.
Подход
Чтобы настроить экспериментальную среду, рекомендуется выполнить следующие действия:
1. Определите цель своего будущего эксперимента, изучите варианты и выберите показатели
Прежде чем обратиться к дизайнеру продукта, определите цели и показатели, которые будут измеряться в рамках вашего эксперимента. В случае классического вопроса «Вариант А или Вариант Б» обычно ясно, чего вы хотите достичь, внедрив изменение. Например, вы можете обращаться к определенной части воронки. п
Для наглядности предположим, что вы работаете в компании по доставке и в настоящее время сосредоточены на форме создания заказа. Вы хотите обратиться к относительно небольшому проценту пользователей, которые указывают свой адрес доставки, а затем выбирают способ доставки. Кроме того, представьте, что у вас есть две новые версии путешествия:
- Текущая версия: на одном экране требуется ввести адреса и показать карту с булавкой на основе предоставленного адреса. На следующем экране можно выбрать способ доставки на основе предоставленного адреса.
2. Новая версия: на одном экране требуется ввести адрес и выбрать способ доставки.
Цель состоит в том, чтобы определить, какой из вариантов приводит к более высокой доле пользователей, которые указали свой адрес и выбрали способ доставки. Показатели довольно просты: % пользователей, которые указали свой адрес и выбрали способ доставки.
На самом деле есть два способа измерения таких данных:
- На основе данных, которые уже доступны благодаря дизайну вашей серверной части. Например, рассмотрим базу данных, в которой есть информация о жизненном цикле заказа. Ваш заказ может иметь такие состояния или статусы, как:
- Черновик создан
- Попробуйте найти способы доставки
-
Варианты доставки найдены/Варианты доставки не найдены
2. Отслеживание событий — это не то, что будет работать из коробки, поэтому для его реализации требуются дополнительные усилия. Однако отслеживание событий позволит вам проводить более детальный анализ, например. тип устройства и имя браузера могут быть переданы в качестве параметра ваших событий.
В следующих разделах этой статьи мы сосредоточимся на первом подходе, то есть на существующей архитектуре данных без отслеживания событий. п
2. Разработайте архитектуру экспериментальной среды
В ходе эксперимента необходимо выполнить два основных шага:
* Создать эксперимент с выбранными параметрами * Определите этап пути пользователя, на котором пользователя следует отнести к любой группе, и убедитесь, что в результате отображается соответствующий пользовательский интерфейс
Создание эксперимента:
Идея состоит в том, чтобы придумать облегченную инфраструктуру A/B-тестирования, которая должен быть максимально простым и позволять создавать эксперименты со следующими параметрами:
* Идентификатор эксперимента * Максимальная выборка * Количество и названия каждой группы * Вероятность попадания в каждую группу
n Возможность настройки этих параметров позволяет установить лимит выборки и выбирать кандидатов для эксперимента случайным образом, пока не будет достигнут желаемый размер выборки.
Оба клиента & серверу для этого нужны изменения: сервер должен отслеживать количество кандидатов на эксперимент, а бэкенд будет решать, должен ли текущий пользователь участвовать в эксперименте или нет. Серверная часть решит, должен ли аутентифицированный пользователь участвовать в эксперименте, исходя из текущего размера выборки и фиксированной вероятности. Кроме того, серверная часть должна поддерживать набор пользователей, участвующих в заданном эксперименте, чтобы предоставлять пользователям единообразные возможности и правильно вычислять результаты эксперимента.
Вот как может выглядеть конечная точка конфигурации эксперимента:
n POST /api/your-service/experiment-create n
Запрос:
{
experiment_id: "f380739f-62f3-4316-8acf-93ed5744cb9e",
maximum_sample_size: 250,
groups:
{
{ group_name: "old_journey", probability_of_falling_in: 0.5 }, { group_name: "new_journey",
probability_of_falling_in: 0.5 },}
Ответ:
{
200,
experiment_id: "f380739f-62f3-4316-8acf-93ed5744cb9e"
<код>
Принятие решения о том, когда и как пользователя следует отнести к экспериментальным группам:
Вам потребуется отдельная конечная точка, которая будет отвечать за назначение конкретного пользователя в эксперимент и соответствующую группу. Назовем это experiment-enrollments.
При проектировании всей среды у вас должно быть четкое понимание того, на каком этапе пути пользователя должна вызываться конечная точка experiment-enrollments. Кроме того, может случиться так, что не все пользователи должны участвовать в эксперименте. Вот почему было бы полезно также предоставить токен авторизации пользователя в конечной точке.
В нашем примере, если мы хотим сосредоточиться только на новых пользователях, которые делают свой первый заказ, user-auth позволит нам определить, к какому типу относится пользователь и следует ли его включать в эксперимент. Кроме того, убедитесь, что после вызова конечной точки вся необходимая информация доступна и учитывает особенности вашего путешествия и жизненного цикла.
Конечная точка experiment-enrollments описана ниже. Его можно вызывать на определенном этапе пути (например, перед тем, как приземлиться на экране с запросом адреса доставки) для определенных типов пользователей (например, только новых пользователей, которые еще не предоставили адрес) и будет вычислять, должен ли текущий пользователь участвовать в данном эксперименте или нет:
POST /api/your-service/experiment-enrollments, требуется токен аутентификации пользователя
Запрос:
{
experiment_id: "f380739f-62f3-4316-8acf-93ed5744cb9e"
<код>
Ответ:
{200,
enrolled: true/false,
group_name: group_1,}
Чтобы проиллюстрировать, как будет выглядеть теоретический поток данных, возьмем тот же пример потока создания заказа в компании по доставке. Вы выбираете один из двух вариантов экрана создания заказа.
Следующие конечные точки упомянуты на диаграмме ниже, т. е.:
* /create-order-draft (шаг 3) * /find-shipping-method (шаг 16) * /submit-order (шаг 20)
предоставляются для иллюстративного примера и не являются обязательными частями экспериментальной среды

Кроме того, ниже представлена иллюстративная и упрощенная архитектура баз данных.
Есть 3 основные таблицы:
Набор экспериментов— содержит все эксперименты, которые вы создали ранее. База данных обновляется каждый раз, когда вы вызываете конечную точку/experiment-create.
2. База данных экспериментов — содержит все записи, связанные с каждой регистрацией конкретного пользователя. База данных обновляется каждый раз, когда вы вызываете конечную точку experiment-enrollments
3. База данных жизненного цикла заказов — она предназначена для поддержки проиллюстрированного примера того, как могут храниться данные, связанные с экспериментом. Дело в том, что эта таблица (или любая аналогичная таблица, соответствующая специфике вашего продукта) позволит вам увидеть, была ли запись (например, создание заказа) успешной или нет для конкретного пользователя, зарегистрированного в одной из экспериментальных групп, которые вы мы установили. В нашем примере мы можем полагаться на статус Выбранный способ доставки, который позволяет сделать вывод, что пользователь успешно предоставил информацию о доставке, а затем выбрал один из предложенных способов доставки.
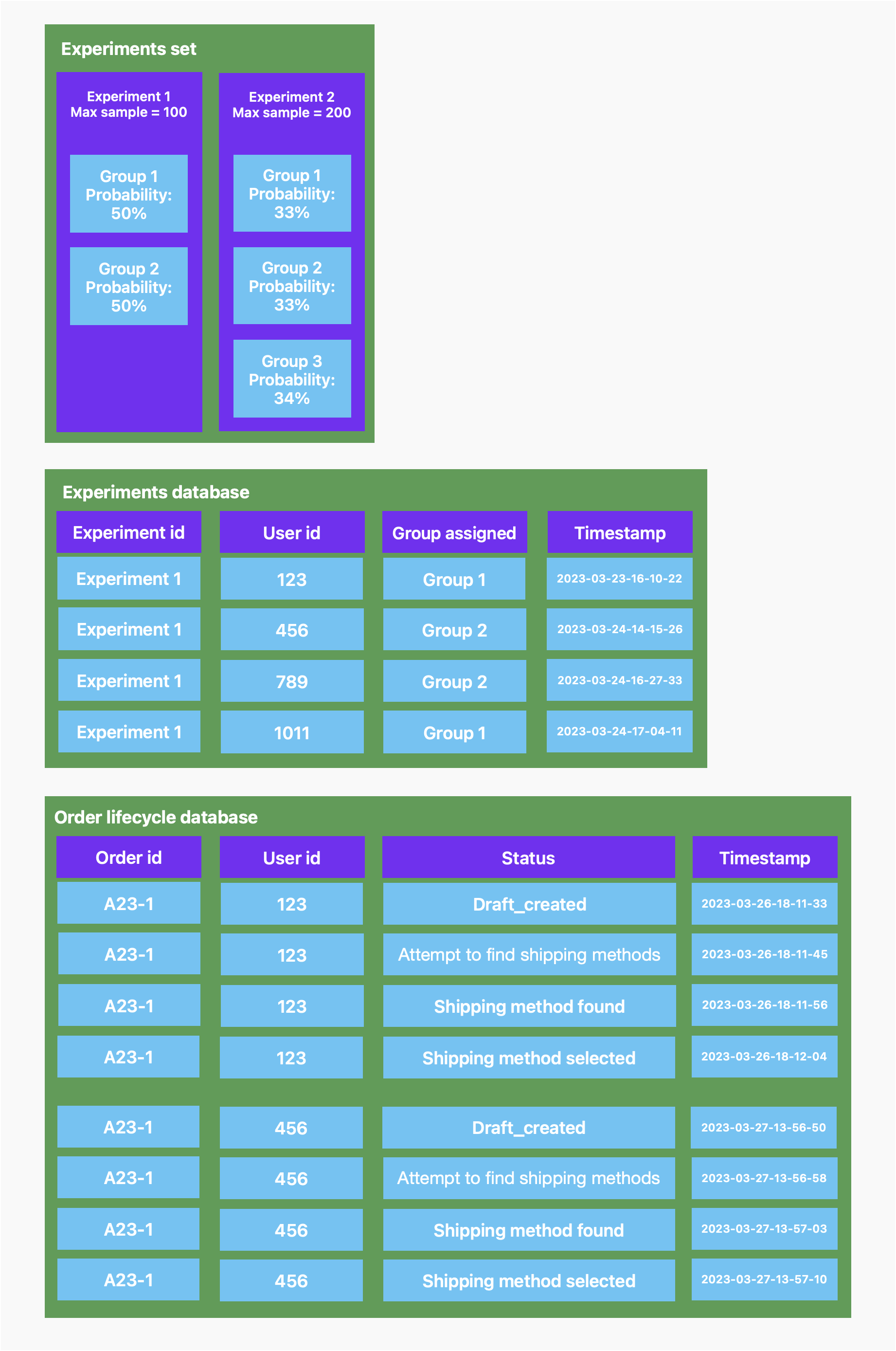
Обзор дизайна и подхода к реализации
Плюсы:
- Полученная выборка неоднородна
- Размер выборки известен заранее.
- Результаты могут быть вычислены быстро, в зависимости от фиксированной вероятности выборки.
Минусы:
- Требуются изменения как внешнего, так и внутреннего интерфейса.
- Вычисление результатов будет основываться на нескольких базах данных, некоторые из которых изначально не могли быть предназначены для аналитических целей.
Задачи и ориентировочные оценки:
– [ ] [Backend] Создать модель и предоставить конечную точку счетчика выборки: ~2 балла. – [ ] [Backend] Предоставить конечную точку счетчика приращений: ~2 балла истории - [ ] [Backend] Предоставить конечные точки для извлечения & счетчик приращений: ~1 очко истории – [ ] [Внешний интерфейс] Конечные точки счетчика вызовов для переключения между потоками регистрации: ~3 пункта истории
После того как вы спроектировали серверную часть, согласуйте с командой клиентской части, как им лучше всего получать информацию и на каком этапе процесса.
Помните и уменьшайте основные зависимости:
* Убедитесь, что ваши команды заранее согласованы по контракту, чтобы фронтенд-часть могла быть реализована параллельно с бэкендом. * Старайтесь избегать блокировки вашего интерфейса, пока не будет завершен весь бэкенд. * Вне зависимости от среды эксперимента все параметры пользовательского интерфейса должны быть реализованы в любом случае
3. Анализ и интерпретация результатов
После того как ваш эксперимент продлится достаточное количество времени, важно проанализировать и интерпретировать результаты, чтобы сделать значимые выводы. п
Определите список полей, необходимых для расчета влияния на показатели, на которых вы решили сосредоточиться ранее.
В приведенном выше иллюстративном примере источниками данных будут 2 таблицы:
* База данных экспериментов:
* Ввод: идентификатор эксперимента, для которого вы ищете результаты.
* Вывод: список всех идентификаторов пользователей, которые являются участниками определенного эксперимента, группы, в которую был назначен каждый пользователь, и отметка времени, когда пользователь был назначен
База данных жизненного цикла заказов- Входные данные: список пользователей, участвующих в эксперименте, и отметка времени, когда они были зарегистрированы для участия в эксперименте.
- Вывод: окончательные статусы всех заказов, связанных с этими пользователями и обработанных после регистрации пользователя в эксперименте.
На основе этих данных вы можете рассчитать % успешно созданных заказов для каждой из экспериментальных групп.
При анализе результатов важно не ограничиваться только необработанными цифрами. Вы также захотите проверить статистическую значимость, чтобы убедиться, что любые различия, которые вы наблюдаете между своими тестовыми группами, не являются случайными. Я не буду слишком заострять внимание на этой части, так как я уже видел множество статей, связанных с этой темой, на этом и других онлайн-ресурсах. В любом случае, здесь не требуется чрезмерных знаний: на мой взгляд, умение применять ==Z-Test или T -Test== для проверки значимости разницы между двумя группами будет достаточно.
Тем не менее, как только вы определили, что ваши результаты статистически значимы, вы можете начать делать выводы о том, какой вариант вашего продукта работает лучше.
4. Расширение предпочтительного варианта
После того как вы успешно провели эксперимент и получили достаточную степень уверенности в выборе наилучшего варианта, следующим шагом будет масштабирование изменений в вашем продукте. Подходов может быть несколько:
* Самый простой — настроить конфигурацию вашего эксперимента так, чтобы 100 % пользователей попадали в группу с лучшими результатами. Вам нужно будет зарезервировать некоторое время, чтобы очистить код в будущем, чтобы отображение этой конкретной части пользовательского интерфейса не зависело от среды эксперимента
* Менее простой вариант, если ваш продукт доступен на нескольких платформах. Будьте особенно осторожны, предполагая, что результаты экспериментов в веб-потоке применимы к потоку в мобильном приложении (и наоборот). Иногда лучше перестраховаться и провести отдельный эксперимент аналогичным образом, но на другой платформе.
В заключение
Собственная экспериментальная среда – очень удобный инструмент для любого менеджера по продукту. Независимо от того, на какой стадии зрелости находится ваш текущий продукт, создание экспериментальной среды не должно занимать слишком много времени. Заплатив довольно небольшую единовременную плату за то, чтобы она заработала, вы довольно быстро увидите окупаемость инвестиций.
Наконец, вот несколько советов, которые помогут убедиться, что результаты эксперимента имеют смысл:
* Прежде всего, поймите, какие показатели будут затронуты (если таковые имеются) при внедрении изменения, которое вы рассматриваете. * Четко определите свои цели и показатели перед началом эксперимента. * Держите эксперимент как можно проще, сосредотачиваясь на одном ключевом изменении за раз. * Будьте осторожны при рассмотрении вопроса об экстраполяции результатов вашего эксперимента на другие платформы или другие подобные сервисы n
Следуя этим рекомендациям, вы сможете создать эффективную экспериментальную среду, которая поможет вам принимать решения на основе данных и повышать коэффициент конверсии с течением времени.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)