

Отладка потоков: взаимоблокировки и условия гонки
12 мая 2022 г.Отладка потоков имеет репутацию одной из самых сложных задач для разработчиков. Позволю себе не согласиться. Асинхронная отладка намного хуже. Предполагается, что это решает проблемы многопоточности, и в какой-то степени асинхронность помогает… Но это не упрощает отладку. Я расскажу об этом в следующем посте.
В последних двух утятах я говорил о проблемах с многопоточностью:
https://twitter.com/debugagent/status/1521486750505488386?s=20&t=qKZuudKwOoVxT0s4O6kd7Q
Сегодня мы обсудим процесс отладки проблем с многопоточностью, работу с взаимоблокировками и состояниями гонки в отладчике.
Многопоточная отладка
Отладка в многопоточной среде часто воспринимается как сложная, потому что трудно понять, что происходит. Вы ставите точку останова, и поток, который может зайти в тупик, приостанавливается в фоновом режиме. В результате вы больше не сможете воспроизвести проблему с помощью отладчика. Вместо того, чтобы изменить метод отладки, разработчики обвиняют инструменты. Это выплескивание ребенка вместе с водой. У отладчиков так много замечательных инструментов для управления своей средой. Как только вы научитесь осваивать эти ресурсы, такие вещи, как обнаружение взаимоблокировок, станут тривиальными.
Просмотр потока
Если вы использовали IDE JetBrains, такие как IntelliJ, вы, вероятно, знакомы с полем со списком потоков, которое находится над панелью трассировки стека в пользовательском интерфейсе. Этот виджет позволяет нам переключать текущий поток, а вместе с ним и стек, на который мы смотрим. Это очень эффективный инструмент, но он также обеспечивает очень ограниченный обзор. Очень сложно оценить состояние конкретного потока, взглянув на поле со списком. Дополнительные детали, такие как группировка, местоположение и т. д., неясны, если смотреть только на этот виджет.
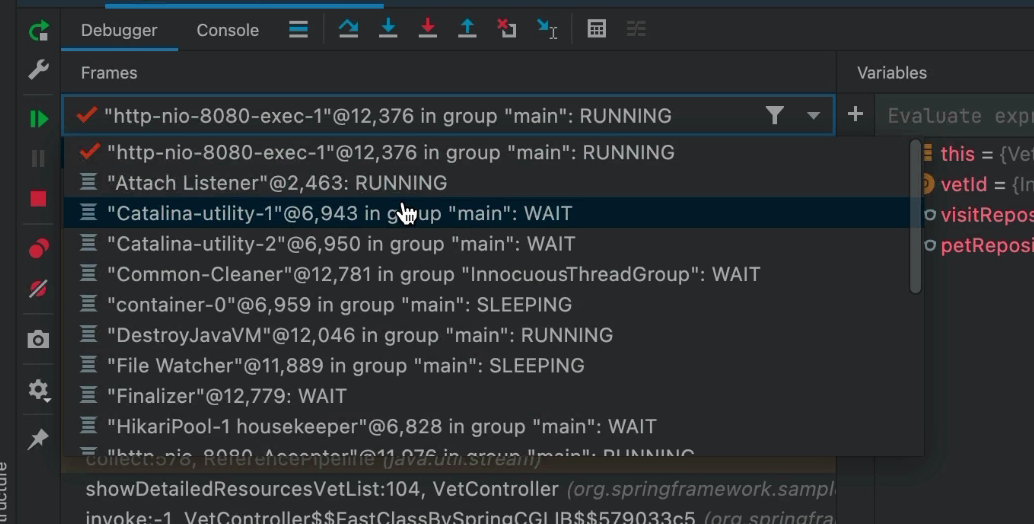
К счастью, большинство IDE поддерживают представление, которое больше ориентировано на многопоточные приложения. Недостатком является то, что он немного шумнее по сравнению с ним. Я предполагаю, что это причина, по которой это не пользовательский интерфейс по умолчанию. Но если процесс, который вы отлаживаете, имеет сложный параллелизм, это может заметно улучшить ваш опыт!
Чтобы включить этот режим, нам нужно проверить параметр «Потоки» в IDE в представлении отладчика:
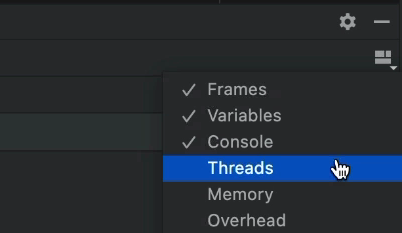
По умолчанию это отключено, так как UX сложен, и большинству разработчиков это не нужно для типичных приложений. Но когда у нас есть многопоточное приложение, это представление становится спасением...
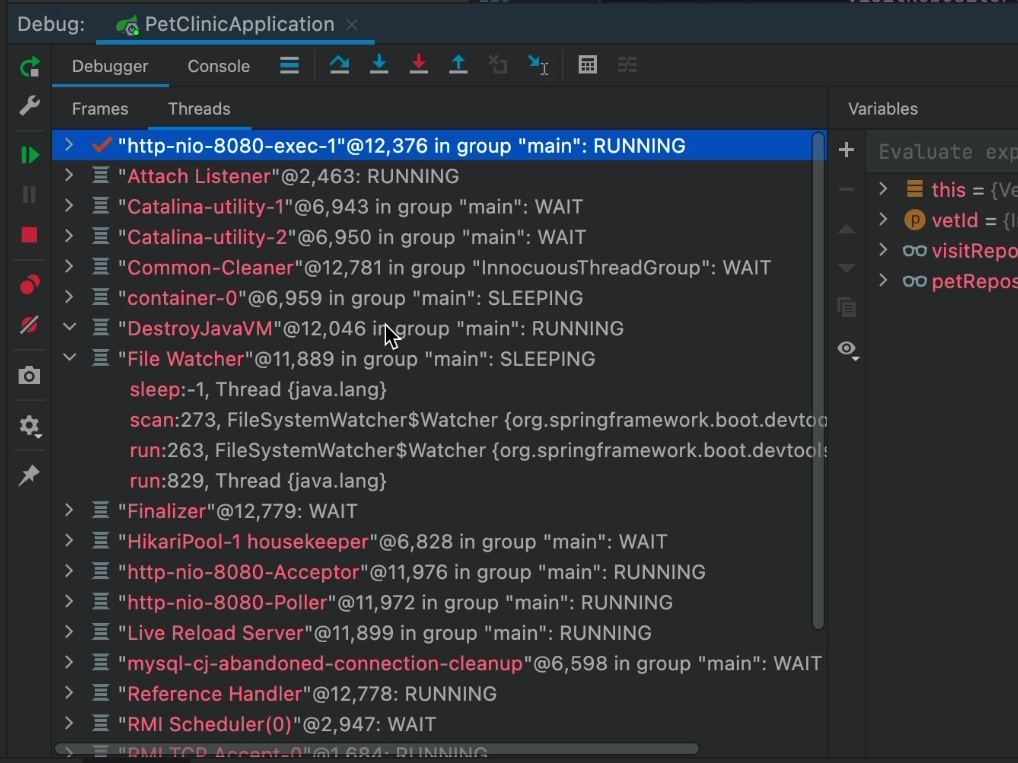
Потоки эффективно становятся элементом верхнего уровня. Мы можем увидеть стек, развернув конкретный поток (например, File Watcher на этом изображении). Здесь у нас есть полный доступ к стеку, как и раньше, но мы можем видеть все потоки. Если у вас есть приложение с очень большим количеством потоков, это может быть проблемой, например. с грядущим проектом Loom это может стать несостоятельным.
Мы можем дополнительно настроить это представление с помощью настроек, это может включить больше детализации и иерархии:

В диалоге настроек упоминается несколько интересных возможностей, но самая интересная из них — группировка по группам потоков. Группы потоков позволяют упаковать поток как часть группы. В результате мы можем создать общее поведение для всех потоков внутри. Например. один обработчик catch и т. д.
Большинство потоков, которые вы получите из пула или фреймворка, уже будут логически сгруппированы. Это означает, что группировка уже должна быть относительно интуитивной и простой в использовании.
Отладка тупиковой ситуации
Википедия определяет тупик как:
- «В [параллельных вычислениях] (https://en.wikipedia.org/wiki/Concurrent_computing) тупик — это любая ситуация, в которой ни один член некоторой группы объектов не может продолжать работу, потому что каждый ожидает другого члена, включая самого себя, чтобы выполнить действие, например отправить сообщение или, чаще, снять блокировку.<a href="< https://en.wikipedia.org/wiki/Deadlock#cite_note-coulouris-1>">[1] Взаимоблокировки — распространенная проблема в многопроцессорной обработке, параллельные вычисления и распределенные системы, потому что в этих контекстах системы часто используют программные или аппаратные блокировки для управления общими ресурсами и реализации синхронизации процессов."*
Звучит сложно, но это не так уж и плохо... К сожалению, если вы поставите точку останова, проблема больше не возникнет, так что вы даже не сможете использовать типичные инструменты отладки для тупиковой ситуации. Причина в том, что точка останова обычно приостанавливает весь процесс, когда он останавливается, и вы не видите, как возникает проблема.
Я не буду говорить о предотвращении взаимоблокировок, которое само по себе является обширной темой. Приятно то, что его довольно легко отлаживать, если воспроизвести его с запущенным отладчиком!
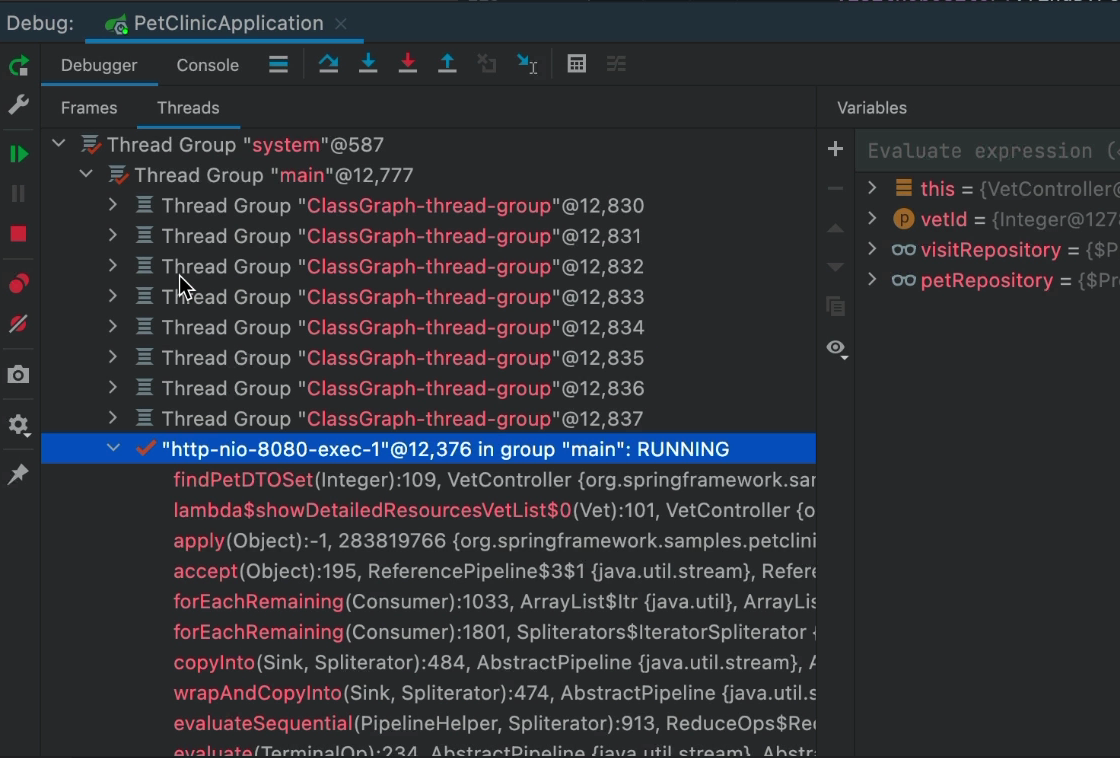
Все, что нам нужно сделать, это нажать паузу в отладчике:
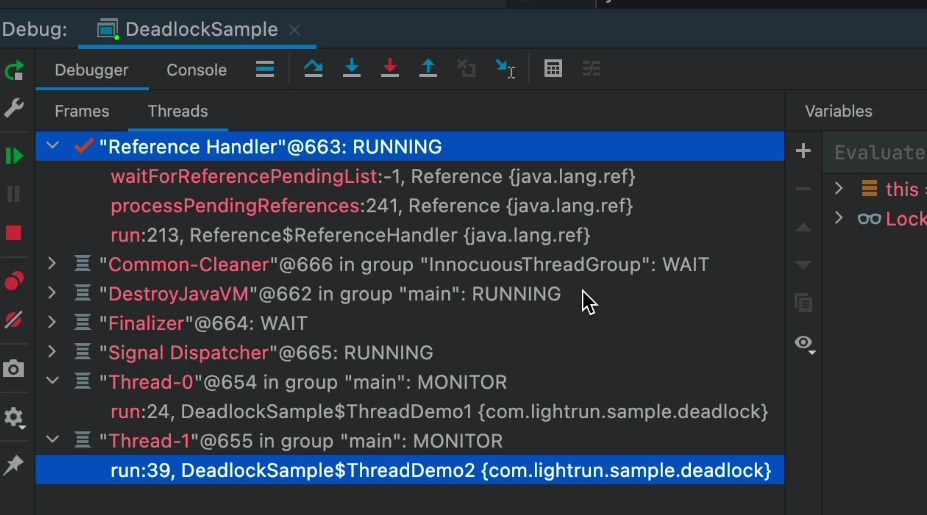
Как только приложение будет приостановлено, мы сможем просмотреть записи в списке. Обратите внимание, что две записи застряли в потоках «МОНИТОР», ожидающих монитора. Фактически это означает, что они, вероятно, застряли в синхронизированном блоке или каком-либо другом вызове API синхронизации.
Это может ничего не значить, но довольно легко просмотреть этот список и стек, чтобы увидеть ресурс, которого они ждут. Если одна запись ожидает ресурса, удерживаемого другой... Это, вероятно, риск тупиковой ситуации. Если оба содержат ресурсы, необходимые другому, это довольно очевидный тупик.
Вы можете переключаться между потоками и ходить по стеку. На этом снимке экрана стек имеет глубину в один метод, поэтому он не является репрезентативным для «реальных случаев». Тем не менее, это простой способ обнаружить такие проблемы.
Отладка условий гонки
Наиболее распространенной проблемой многопоточности являются условия гонки. Википедия определяет условия гонки как:
"Состояние гонки или опасность гонки — это состояние электроники, программного обеспечения или другую систему, где основное поведение системы зависит на последовательность или время других неконтролируемых событий. Это становится ошибкой, когда одно или несколько возможных действий нежелательны."
Это гораздо более коварная проблема, поскольку ее почти невозможно обнаружить. Я писал об этом в прошлом и о [отладке с помощью Lightrun здесь] (https://lightrun.com/tutorials/debug-race-condition-production/). Деррик также написал об этом в блоге Lightrun, но рассказал об этом немного по-другому. Моя техника проще, на мой взгляд...
Точки останова метода выполнены правильно
Раньше я уже говорил несколько резких вещей о точках останова методов. Они неэффективны и проблематичны. Но для этого грузовика они нам нужны. Они дают нам необходимый тип контроля над положением точки останова.
Например. в этом методе:
```java
public Set
Список посещений
возврат посещений.поток().различный().карта(посещение -> {
Текущий питомец = petRepository.findById(visit.getPetId());
вернуть новый PetDTO(current.getName(), current.getOwner().getLastName(),
visitRepository.findByPetId(current.getId()));
}).collect(Коллекторы.toSet());
Если мы поместим точку останова в последнюю строку, мы упустим функциональность метода. Но если мы поместим точку останова метода, которая отслеживает выход из метода, она сработает после того, как все в методе будет выполнено.
В идеале мы могли бы отслеживать вход и выход метода, но тогда мы не сможем их различить...
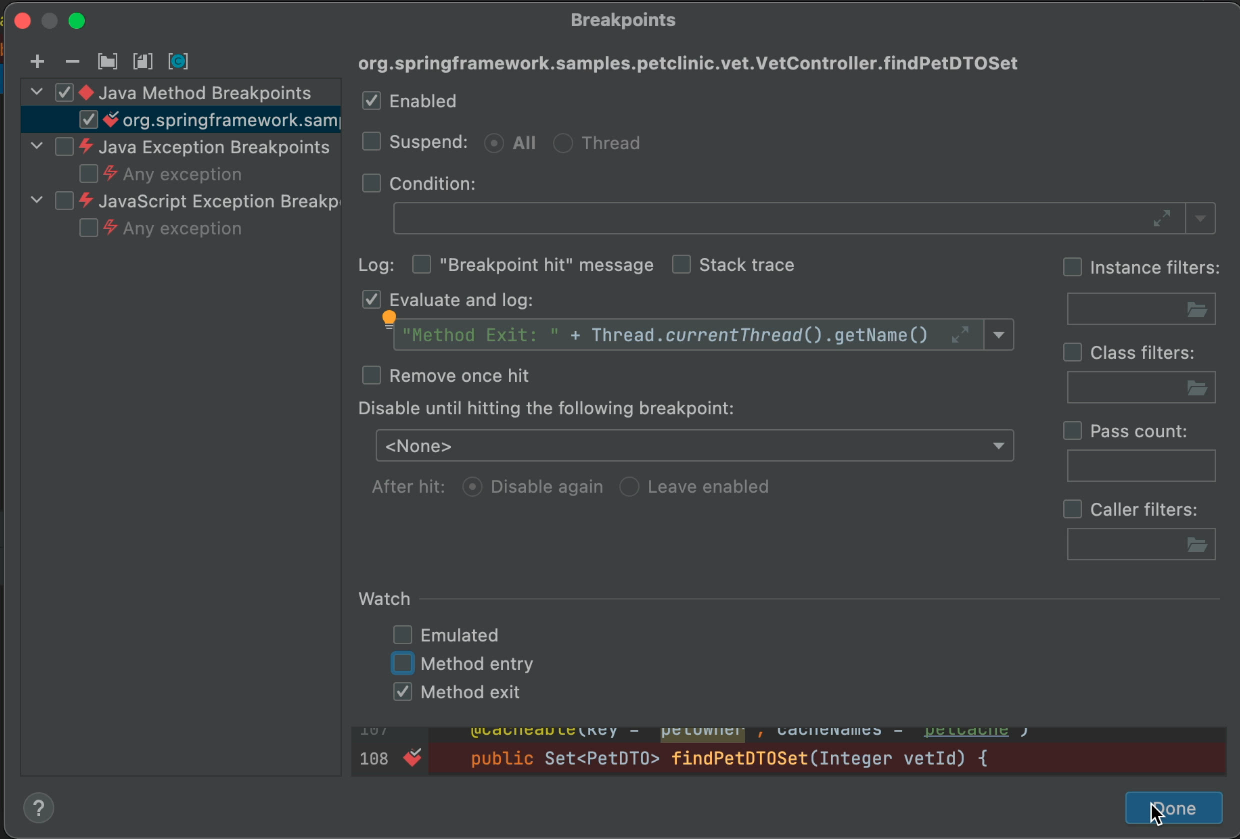
После того, как мы создадим точку останова метода, мы установим, чтобы она не приостанавливалась и включала ведение журнала. Мы эффективно создали точку трассировки. Теперь мы можем зарегистрировать выход из метода и имя потока. Это будет печатать каждый выход из метода.
Событие входа в метод
Мы можем сделать то же самое для входа в метод, но здесь мы можем использовать обычную точку останова:

Опять же, мы не приостанавливаем поток и используем то, что фактически является точкой трассировки. Это позволяет нам увидеть, являемся ли мы жертвой взаимоблокировки, просматривая журналы. Если они включают два журнала записей подряд... Это может быть состоянием гонки. Поскольку потоки не приостанавливаются, процесс отладки не должен мешать процессу.

В некоторых случаях вывод может быть очень подробным и из одного потока. В этом случае мы можем использовать простой условный оператор для фильтрации шума:
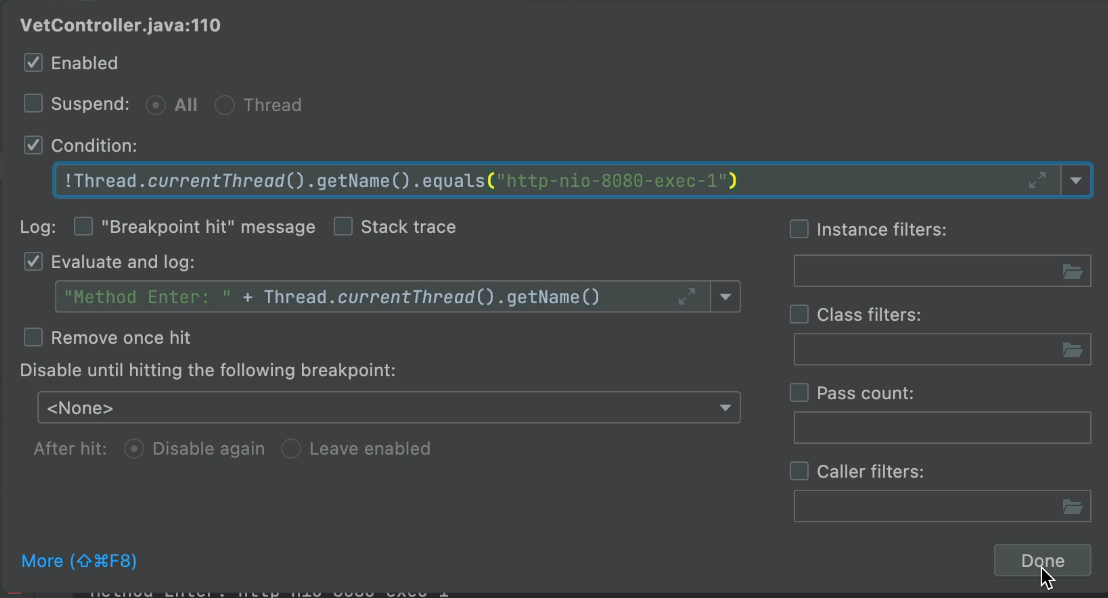
Мы также можем построить детектор взаимоблокировок для бедняков, используя аналогичную технику. Это может дать нам представление об использовании общих ресурсов, чтобы мы могли правильно оценить потенциал взаимоблокировки.
TL;DR
Возможность взаимоблокировки кода делает отладку процесса довольно сложной задачей. Блокировка ресурсов может ухудшить ситуацию, а традиционное использование точек останова просто не работает... Каждый раз, когда мы сталкиваемся с проблемой, которая, как мы подозреваем, связана с гонкой или взаимоблокировкой в многозадачности, нам нужно остановиться. Используйте эти методы для проверки возникновения взаимоблокировок или состязаний.
Многопоточная отладка не так сложна, как это часто представляется. Возможно, вы не получите ошибок, которые укажут вам прямо на строку, но с правильным контролем параллелизма вы можете значительно сузить круг задач.
Эта статья была впервые опубликована [здесь] (https://talktotheduck.dev/debugging-deadlocks-and-race-conditions)
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)