

Отладка памяти и просмотр аннотаций
9 мая 2022 г.Прежде чем углубиться в отладку проблем с памятью и другие удивительные запущенные процессы, возможности отладки памяти (которые потрясающие)... Я хочу обсудить вопрос, который я оставил открытым в последнем посте с утёнком.
Там мы обсуждали настройку рендерера часов. Это супер круто!
Но это также утомительно.
Прежде чем мы продолжим, если хотите, я расскажу о большинстве этих тем в видеороликах. К сожалению, я не нашел достойного способа встроить их с помощью редактора здесь, поэтому вы можете увидеть их, [щелкнув эту ссылку] (https://twitter.com/debugagent/status/1516497057573388294?s=20&t=Y_KG2jDuc-aLrzZhvZ8IYw).
Смотреть аннотации
В прошлый раз мы обсуждали настройку пользовательского интерфейса часов для более эффективной визуализации сложных объектов. Но есть одна проблема: «Мы не одиноки».
Мы часть команды. Делать это для каждой машины сложно и неприятно. Что делать, если вы создаете библиотеку или API и хотите, чтобы это поведение использовалось по умолчанию?
Именно здесь JetBrains предлагает уникальное решение: пользовательские аннотации. Просто аннотируйте свой код подсказками для отладчика, и настройка будет беспроблемной для всей вашей команды/пользователей. Для этого нам нужно добавить аннотации JetBrains к пути к проекту. Вы можете сделать это, добавив это в файл Maven POM:
```xml
<зависимость>
<версия>23.0.0
Как только это будет сделано, мы можем аннотировать класс из предыдущего утенка, чтобы добиться того же эффекта.
```java
импортировать org.jetbrains.annotations.Debug.Renderer;
// вырезанный код...
@Renderer(text = "\"В репозитории есть\" + count() + \"элементы\",",
дочерний массив = "finaAll()",
hasChildren = "количество() > 0")
открытый интерфейс VisitRepository расширяет JpaRepository
// вырезанный код...
Обратите внимание, что нам нужно экранировать строки в аннотации, чтобы они были действительными строками Java. Нам нужно экранировать символы кавычек и использовать их для записи «правильной» строки.
Опять же, все остальное соответствует содержанию и результату, который мы видели в предыдущем утенке.
Отладчик памяти
Основное внимание в этом посте уделяется возможностям отладки памяти. По умолчанию JetBrains отключает большинство этих возможностей, чтобы повысить производительность выполнения программы. Мы можем включить представление отладчика памяти, проверив его в правой части нижнего окна инструментов.
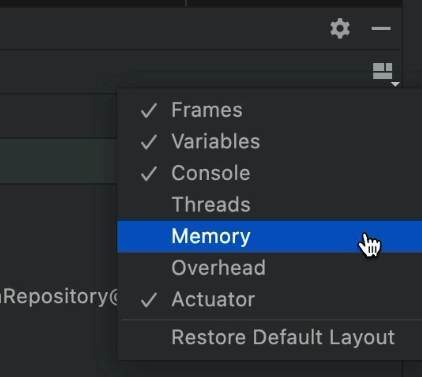
Хуже. Это оказывает такое влияние на производительность, что IntelliJ не загружает фактическое содержимое этого класса, пока мы явно не нажмем кнопку «Загрузить классы» в центре монитора памяти:
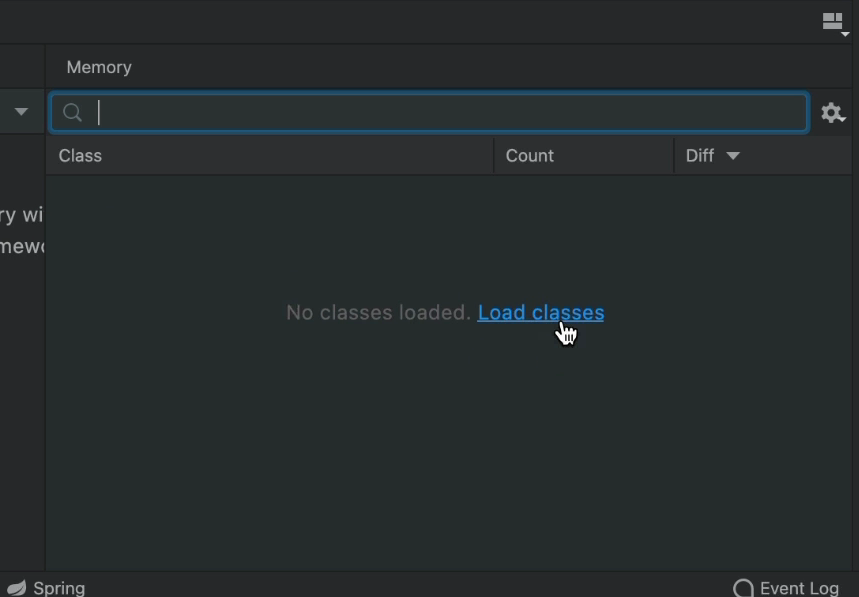
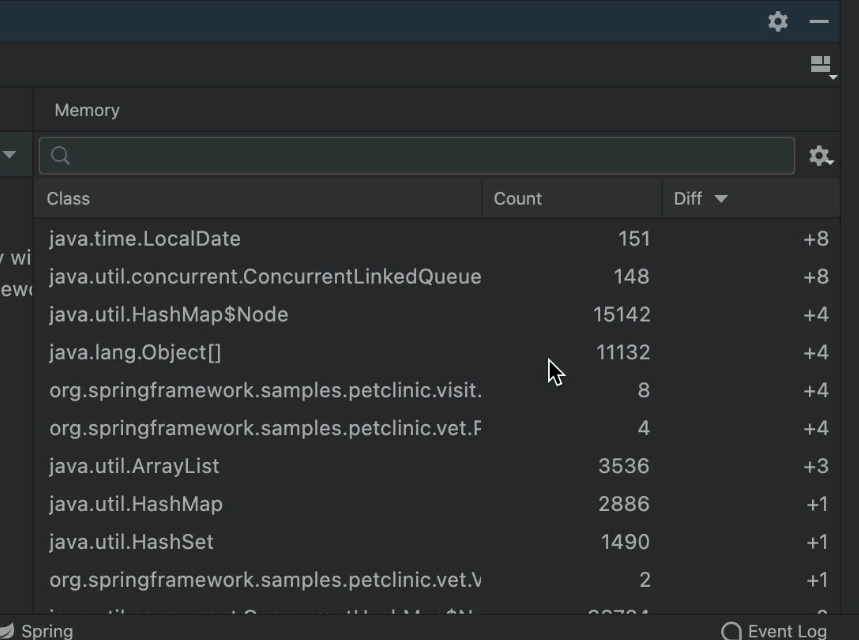
Как вы понимаете, это быстро надоедает. Если ваша машина медленная, то это отличная вещь. Но если у вас исключительно мощная машина, вы можете включить «Обновлять загруженные классы при остановке отладчика»:
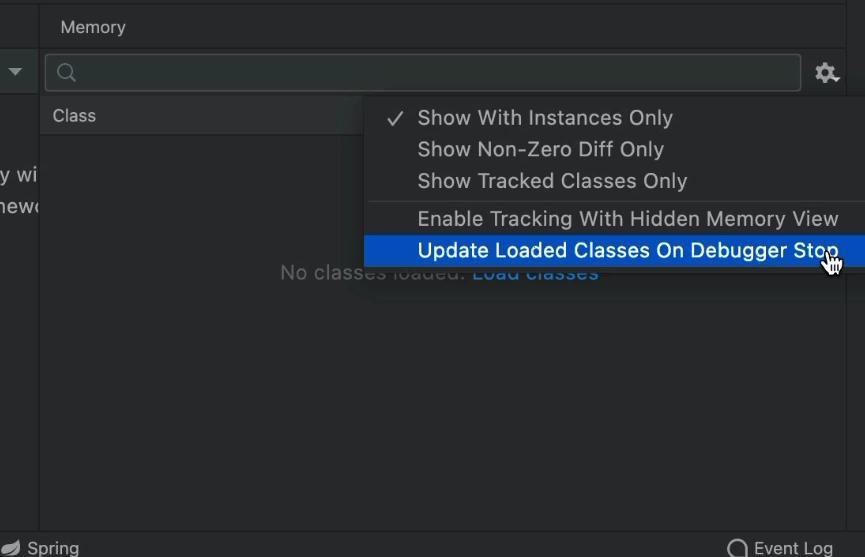
Это эффективно отключает требование щелчка за счет более медленных шагов по сравнению с выполнением. Но что мы получаем в результате?
Использование памяти
Панель показывает нам, где используется блок памяти при обходе кода или переходе между точками останова. Объем памяти не так очевиден, но масштаб выделения памяти очевиден.
Столбец diff особенно полезен при отслеживании таких проблем, как утечка памяти. Вы можете получить представление о том, где был размещен объект с утечкой, и о типах объектов, которые были добавлены между двумя точками. Вы можете получить очень низкоуровневое ощущение памяти с течением времени. Это низкоуровневое представление, более совершенное, чем представление профилировщика, которое мы обычно используем.
Но есть еще кое-что. Мы можем дважды щелкнуть каждый объект в списке и увидеть это:
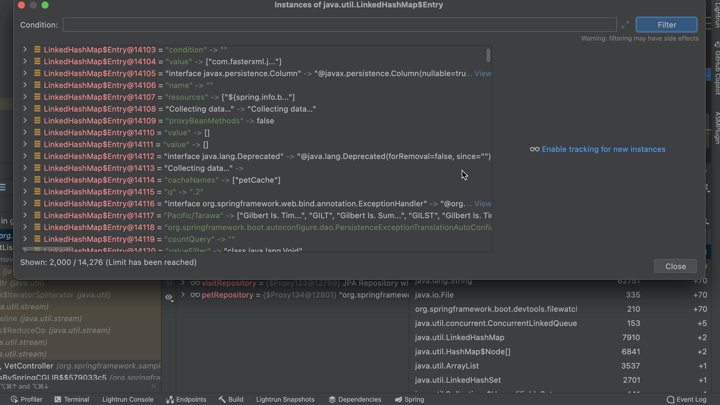
Здесь мы можем видеть все объекты этого типа, которые были размещены во всей куче. Мы можем получить представление о том, что действительно хранится в ячейке памяти, и снова получить более глубокое представление о потенциальных утечках памяти.
Проверка памяти
«Отслеживание новых экземпляров» позволяет еще больше отслеживать распределение кучи. Мы можем включить это для каждого типа объекта. Обратите внимание, что это относится только к «правильному объекту», а не к массивам. Вы можете включить его, щелкнув правой кнопкой мыши:
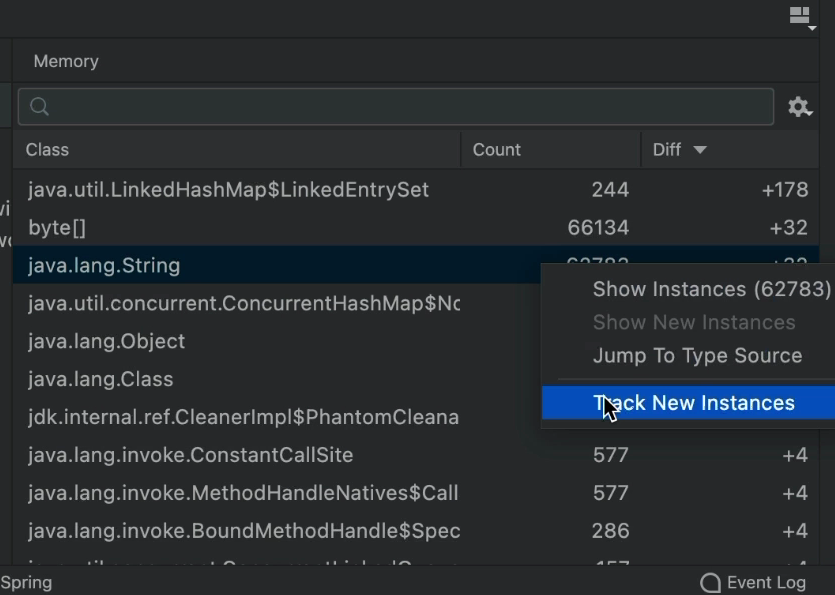
Как только мы включим это, распределение кучи будет отслеживаться везде. Мы получаем следы выделения памяти, которые можем использовать, чтобы сузить строку кода, выделяющую каждый объект в куче!
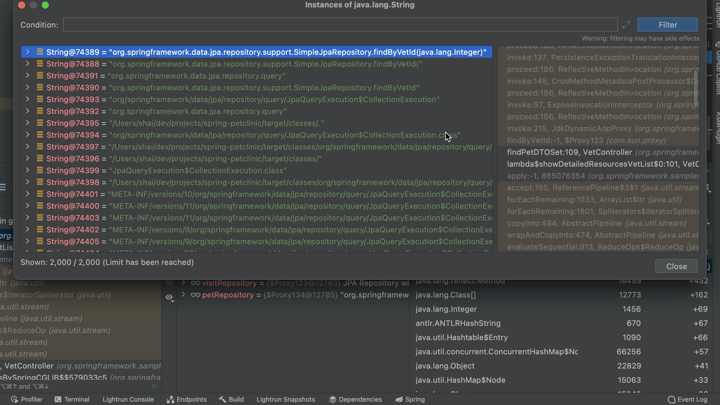
Однако реальная выгода заключается в расширенных возможностях diff. Когда это включено, мы можем различать конкретные объекты, выделенные в этот момент. Скажем, у вас есть блок кода, в котором происходит утечка объекта типа MyObject. Если вы включите отслеживание MyObject и запустите между двумя точками останова, вы увидите каждое выделение MyObject, выполненное только в этом блоке кода...
Следы выделения памяти — это недостающая часть, которая покажет вам, где был выделен каждый из этих экземпляров объекта. Буквальные трассировки стека из распределителя памяти!
Иногда это трудно увидеть в приложениях, интенсивно использующих память. Когда несколько потоков размещают несколько объектов в памяти, шум трудно отфильтровать. Но из всех инструментов, которые я использовал, этот, безусловно, самый простой.
Окончательно
Одна из моих любимых вещей в Java — отсутствие реальных ошибок памяти. Нет недопустимых адресов памяти. Никакая неинициализированная память не приводит к недопустимым обращениям к памяти. Никаких неверных указателей, адресов памяти (которым мы подвергаемся) или ручная настройка. Вещи «просто работают».
Но все еще есть болевые точки, которые выходят за рамки настройки сборки мусора. Размер кучи — одна из самых больших проблем в Java. Это не обязательно должна быть утечка. Иногда это просто расточительство, которого мы не понимаем. Куда девается дополнительная память?
Отладчик позволяет провести прямую линию с трассировкой стека непосредственно к строке исходного кода. Мы можем проверить содержимое памяти и получить применимую статистику памяти, которая выходит далеко за рамки области профилировщика. Просто для ясности: профилировщики отлично подходят для просмотра памяти в целом. Отладчик может дополнить эту картину полным списком для определенного блока кода.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)