

Как использовать систему отслеживания измененных данных для обнаружения мошенничества
4 мая 2022 г.В разгар повального увлечения бизнес-аналитикой (BI) в начале моей карьеры я работал с внутренней командой по отчетности, чтобы предоставить данные для [извлечение, преобразование и загрузка] (https://en.wikipedia.org/wiki/Extract Процессы ,_transform,_load) (ETL), использующие структуры данных, вдохновленные Ральфом Кимбаллом. Это было новое и захватывающее время в моей жизни, чтобы понять, как оптимизировать данные для отчетности и анализа. Честно говоря, эта схема показалась мне перевернутой, исходя из моего опыта работы с дизайнами, управляемыми транзакциями.
В конце концов, было много движущихся частей и даже некоторые зависимости от наличия плоского файла, чтобы убедиться, что все работает правильно. Отчеты выполнялись быстро, но меня всегда беспокоил один ключевой фактор: я всегда смотрел на вчерашние данные.
Из-за увеличения размера, скорости и типов данных, создаваемых в современных технологических стеках, данные в реальном времени стали святым Граалем для обеспечения актуального и упреждающего анализа и принятия бизнес-решений на основе данных. Когда мы используем обычный пакетный подход к приему данных, данные всегда устаревают и не могут ответить на насущные вопросы.
Чтобы включить эти варианты использования в реальном времени, данные должны быть доступны на уровне хранения и уровнях обработки, реализованных в настоящее время в организации.
В течение многих лет — и это остается верным и сегодня — транзакционные (OLTP) системы, такие как Oracle, Postgres и SQLServer, лежат в основе большинства предприятий и занимают центральное место в последующей аналитике и обработке. Эта работа обычно выполняется группой инженеров по данным, которые тратят месяцы на создание конвейеров, которые извлекают и преобразуют данные из этих систем OLTP в аналитические озера и хранилища данных (OLAP).
За последнее десятилетие организации всех размеров потратили миллиарды долларов на улучшение своих возможностей по обработке данных и извлечению из них ценности для бизнеса. Однако только 26,5% организаций считают, что достигли цели стать компанией, управляемой данными. Одним из самых больших препятствий на пути к достижению состояния «Утопия данных» является получение возможности создавать надежные конвейеры данных, которые извлекают данные из систем OLTP, обеспечивая при этом согласованность данных и простоту масштабирования по мере роста данных.
Это заставило меня задаться вопросом, есть ли лучший способ добиться тех же результатов без изрядного ночного процесса. Моей первой мыслью было изучить шаблон отслеживания измененных данных (CDC) для удовлетворения этих потребностей.
Почему так важен сбор данных об изменениях (CDC)
Извлечение данных из систем OLTP может быть обременительным по следующим причинам:
- В отличие от инструментов SaaS корпоративные базы данных не имеют гибких API, которые можно использовать для реагирования на изменения данных.
- Создание и обслуживание конвейеров для извлечения данных из систем OLTP, особенно в масштабах бизнеса, является сложным и дорогостоящим процессом для обеспечения согласованности данных.
С другой стороны, CDC — это шаблон разработки программного обеспечения, который определяет и отслеживает обновления базы данных по мере их появления. Это позволяет сторонним потребителям реагировать на изменения базы данных, значительно упрощая процесс получения изменений данных в системе OLTP. События CDC могут быть получены с помощью нескольких различных подходов:
- На основе времени: использует требуемый столбец меток времени в качестве источника данных.
- Контрольная сумма: использует контрольную сумму для таблиц в источнике/цели, используя различия в качестве источника данных.
- На основе журнала: читает журналы базы данных в качестве источника данных.
В этой публикации мы сосредоточимся на логарифмическом подходе. CDC на основе журналов обычно считается лучшим вариантом для сценариев использования в реальном времени из-за его легкого подхода к внесению изменений в данные. Подходы, основанные на времени и контрольной сумме, требуют больше ресурсов ЦП и часто используют запросы к базе данных для поиска новейших изменений в наборе данных. CDC, использующий чтение на основе журналов, может сократить эти дорогостоящие и трудоемкие запросы, фиксируя изменения, обращаясь прямо к источнику: журналам.
Используя журнальный подход, записи в базу данных обрабатываются через журналы транзакций, часто называемые журналами изменений. Решения CDC прослушивают те же журналы и генерируют события, когда применяются установленные условия. Используя журналы, служба CDC получает доступ к тем же данным, не дожидаясь фиксации транзакции, а затем запрашивая эти данные в базе данных.
Внедрив решение CDC, сторонние потребители данных получают более быстрый доступ к изменениям в базе данных. Кроме того, потребителям данных не требуется доступ к фактической базе данных, поскольку их интересуют только обновления в этих журналах изменений. CDC не только обеспечивает почти мгновенную репликацию данных, но и оказывает минимальное влияние на производительность рабочих баз данных. Поскольку CDC получает доступ только к журналам и не представляет никакой угрозы безопасности, ИТ-командам это тоже нравится. Уникальные характеристики CDC сделали его широко принятым многими технологическими лидерами, поскольку варианты использования в реальном времени являются ключевыми для их бизнес-моделей (например, Shopify. -monolith), Uber, CapitalOne).
Чтобы лучше понять CDC, давайте рассмотрим вариант использования, связанный с финансовой отраслью.
Обнаружение мошенничества с помощью CDC
Мошеннические операции являются серьезной проблемой для финансовой отрасли. На самом деле, [этот отчет] (https://www.fool.com/the-ascent/research/identity-theft-credit-card-fraud-statistics/) отмечает, что мошенничество с кредитными картами увеличилось на 44,7% в 2020 году по сравнению с предыдущим -годовые значения.
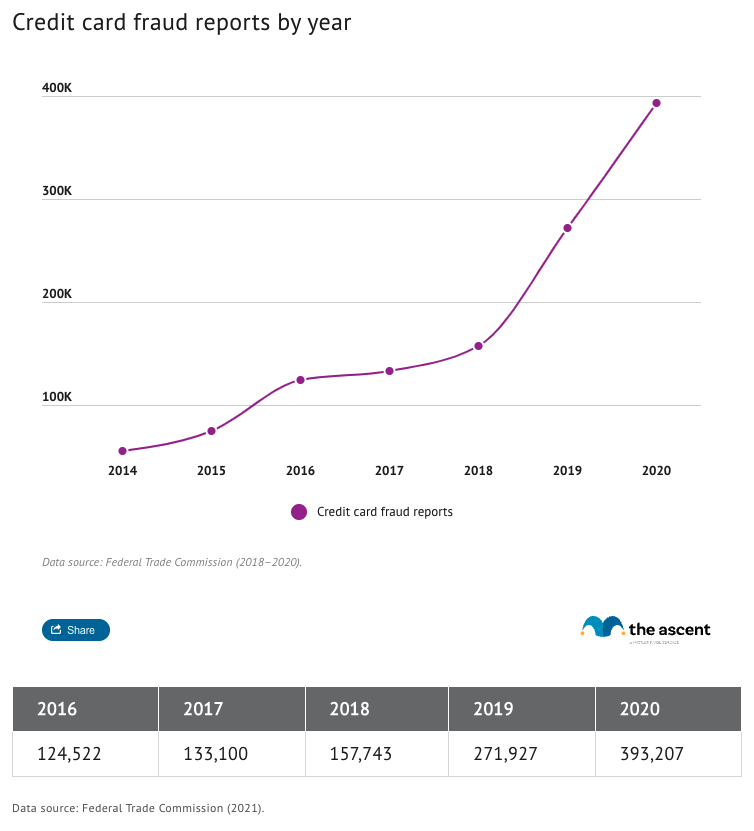
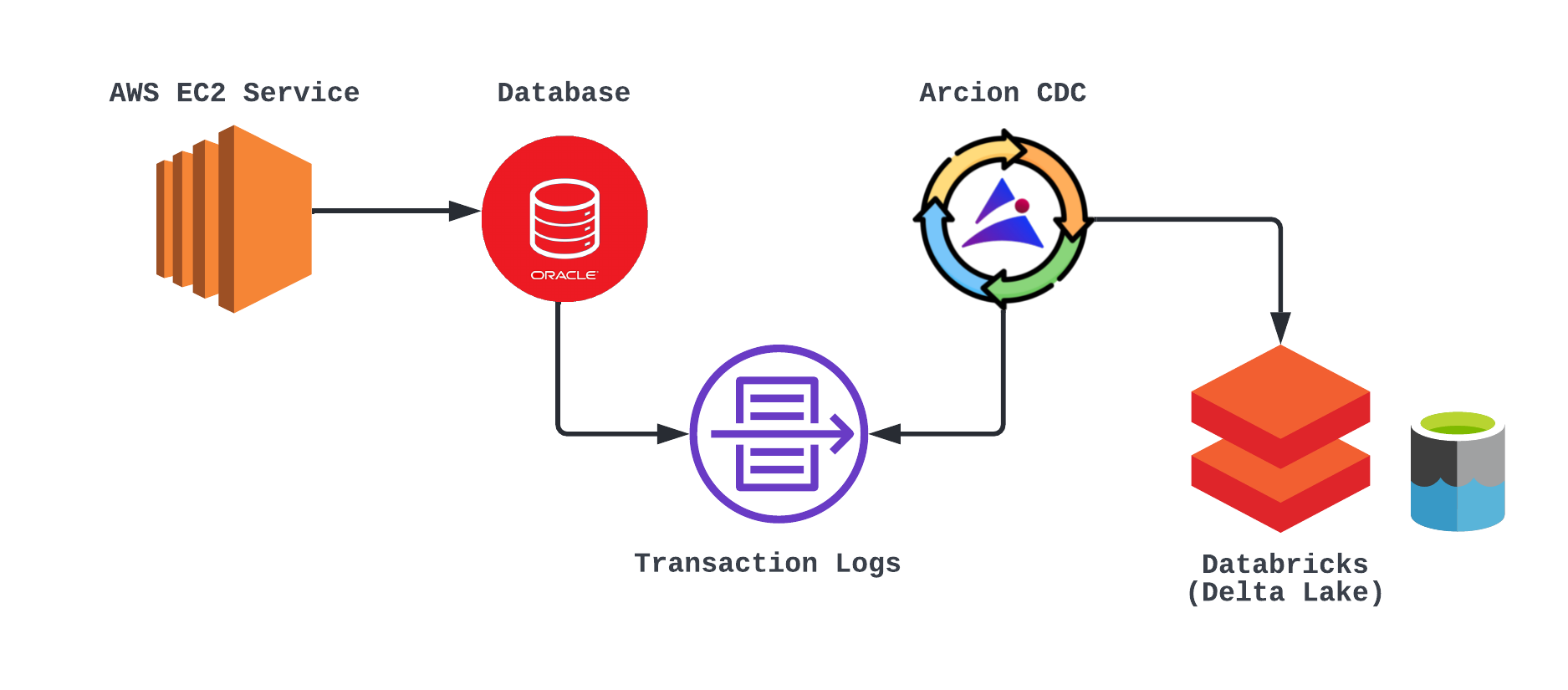
Предположим, вымышленное финансовое учреждение WorldWide Bank хочет повысить скорость распознавания мошенничества. Их текущий подход основан на процессе ETL для запросов к их базе данных Oracle и создания отчетов. Они хотели бы изучить использование Arcion CDC для обработки журналов изменений базы данных Oracle для создания событий, которые будут передавать их Databricks Delta Lake. опытный образец. Как и многие другие организации, WorldWide Bank имеет множество транзакционных систем, в том числе большое количество данных в базе данных Oracle. У них растет потребность в предоставлении дополнительных возможностей машинного обучения (ML), а также в объединении различных наборов данных в простой в использовании среде для анализа, что привело к принятию Databricks для озера данных.
Реляционная модель данных Oracle, а также трудности переноса других вспомогательных источников данных в Oracle и отсутствие поддержки запуска машинного обучения непосредственно в Oracle делают Databricks удобным выбором. Но этот подход приводит к другой проблеме: как своевременно передавать транзакции Oracle в Databricks. Чтобы повысить скорость обнаружения мошенничества, для их работы критически важно иметь возможность быстро получать события CDC от Oracle, помещая их в свое озеро данных Databricks для дальнейшей обработки и обнаружения.
Что касается их решения использовать Arcion CDC, почему WorldWideBank может выбрать Arcion, а не другой вариант, даже с открытым исходным кодом? Ответы просты. Например, Debezium — это вариант с открытым исходным кодом, но он требует установки и запуска Zookeeper, Kakfa и MySQL — и все это еще до того, как вы сможете начать использовать или установить этот инструмент. Одно только это потребовало бы большой команды инженеров, чтобы просто установить и поддерживать технологический стек.
В то время как другие инструменты, такие как HVR Fivetran для CDC, также могут предлагать бесплатные пробные версии, у Arcion есть два бесплатных варианта на выбор: 30-дневная пробная версия с загрузкой или 14-дневная пробная версия в облаке. Это удобно для тестирования, поэтому Arcion легко выбрать при выборе решения CDC.
На высоком уровне архитектуру Arcion CDC можно проиллюстрировать следующим образом:
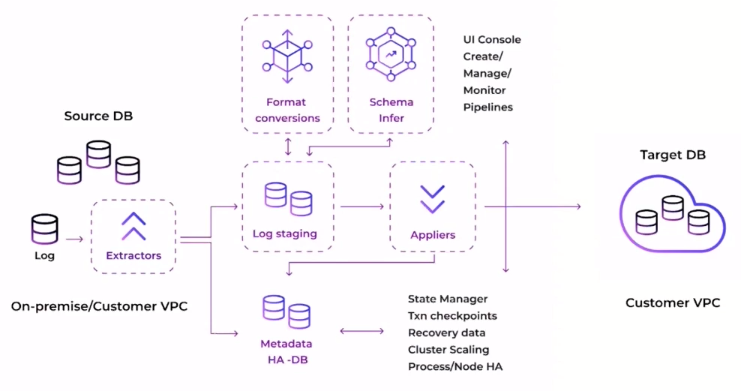
Если этот подход сработает, WorldWide Bank расширит дизайн, чтобы заменить другие исходные базы данных в Oracle, Microsoft SQL Server и MySQL.
Прототип Arcion CDC
Чтобы смоделировать сценарий WorldWide Bank, предположим, что входящие транзакции записываются в таблицу базы данных Oracle с именем TRANSACTIONS, которая имеет следующий дизайн:

Пример записи в таблице TRANSACTIONS будет выглядеть, как показано ниже, в формате JSON:
```javascript
"id": "0d0d6c35-80d0-4303-b9d6-50f0af04beb3",
"post_date": 1501828517,
"транс_дата": 1501828517,
"тип": 1017,
"номер_карты": "4532394417264260",
"номер_счета": "001-234-56789",
"количество": 27,67,
"номер_вендора": 20150307,
"vendor_location_latitude": 42.3465698,
"vendor_location_longitude": -71.0895284,
"vendor_name" : "Книжный магазин музыкального колледжа Беркли"
Чтобы использовать возможности Databricks и Delta Lake для предотвращения мошенничества, нам необходимо настроить службу CDC, которая будет выступать в качестве промежуточного программного обеспечения между двумя системами. Структура таблицы TRANSACTIONS и данные в Oracle должны существовать как уровень Bronze (Ingestion) в Delta Lake. Как только существующие данные будут загружены, все будущие транзакции будут использовать поток CDC, включенный в решение Arcion.
**
**Начало работы с CDC начинается с создания бесплатной учетной записи Arcion Cloud и получения информации о подключении/логине для база данных Oracle и система Databricks.
Собрав эту информацию, я запустил новую репликацию в приложении Arcion Cloud и определил режимы репликации и записи между исходной и целевой базами данных:
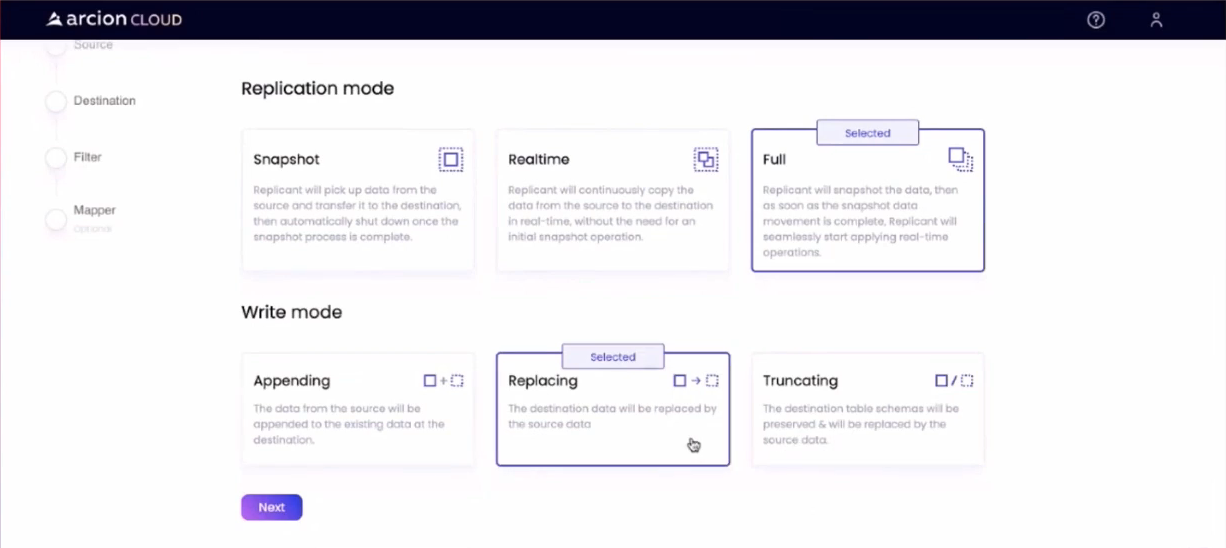
В данном случае я выбрал режим репликации Полный. Это позволяет мне реплицировать полный моментальный снимок базы данных и обеспечивает операции в реальном времени для всех будущих обновлений. Я выбрал вариант Замена режима записи, чтобы полностью заменить любой существующий дизайн базы данных и данные на целевом хосте.**
Затем я установил соединение с базой данных Oracle, подобное тому, что показано ниже:
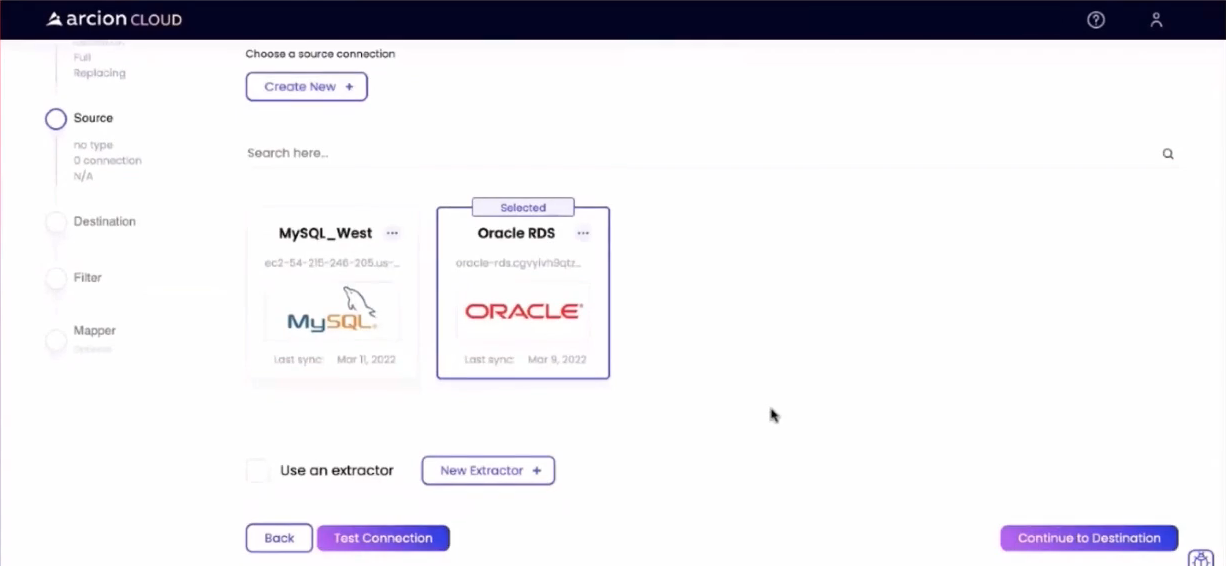
Мы можем проверить соединение с помощью кнопки Test Connection. Когда все будет готово, кнопка Перейти к месту назначения переместит процесс к следующему шагу.
На экране Destination я могу добавить подключение к службе Databricks и выбрать ее в качестве цели для создаваемой репликации:
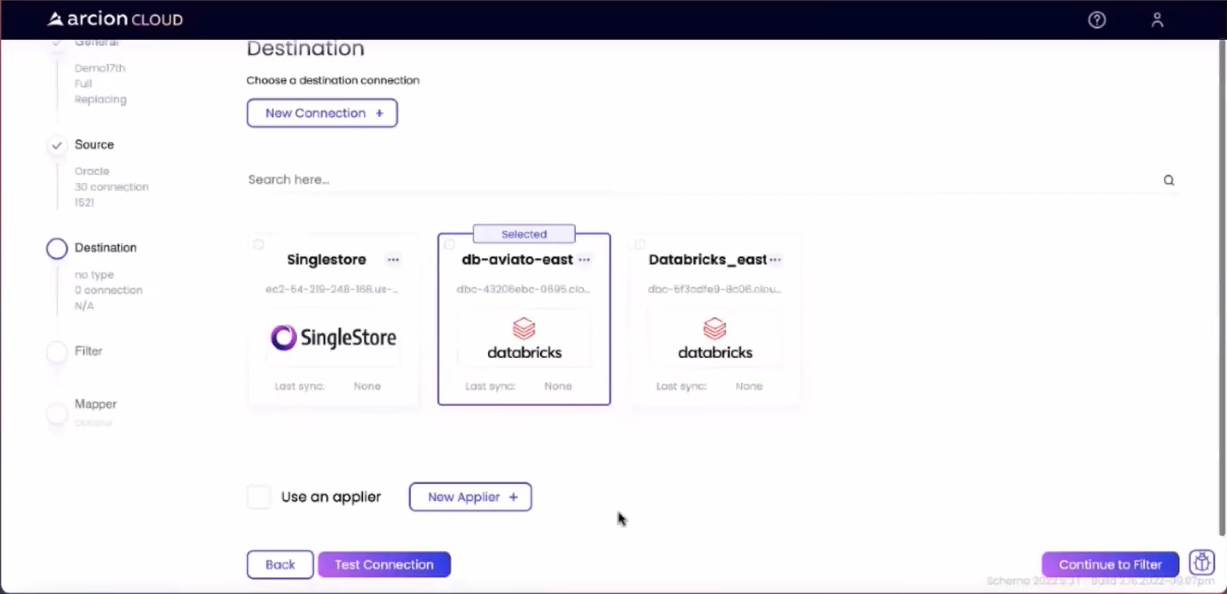
Используя кнопку Продолжить фильтрацию, я смог перейти к экрану фильтра, показанному ниже:
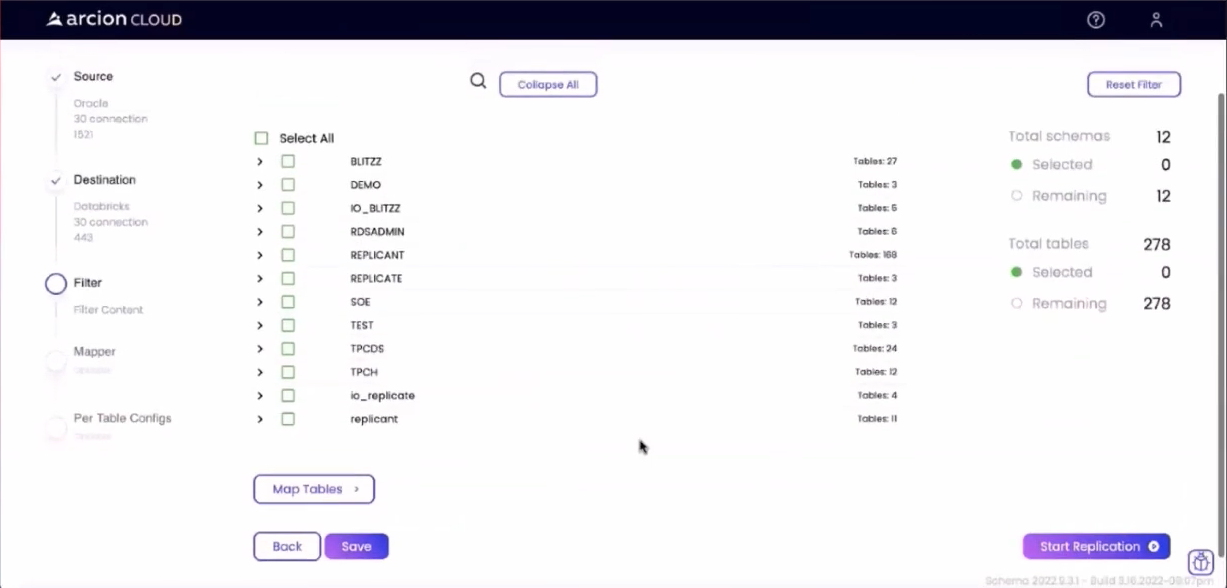
Я выбрал исходную базу данных и таблицы на экране «Фильтр». Когда все было готово, все, что мне нужно было сделать, это нажать кнопку Начать репликацию, чтобы выполнить следующие задачи:
- Удалите все существующие базы данных в Databricks, соответствующие текущему запросу на репликацию.
- Создание новых баз данных в среде Databricks
- Выполнение моментальной репликации всех существующих данных, соответствующих фильтрам, указанным в запросе на репликацию.
- Установите поток CDC между журналами изменений Oracle и Databricks для всех будущих транзакций.
Я завершил все это с нулевым кодом.
Как только репликация началась, я мог наблюдать за процессом в пользовательском интерфейсе Arcion Cloud:
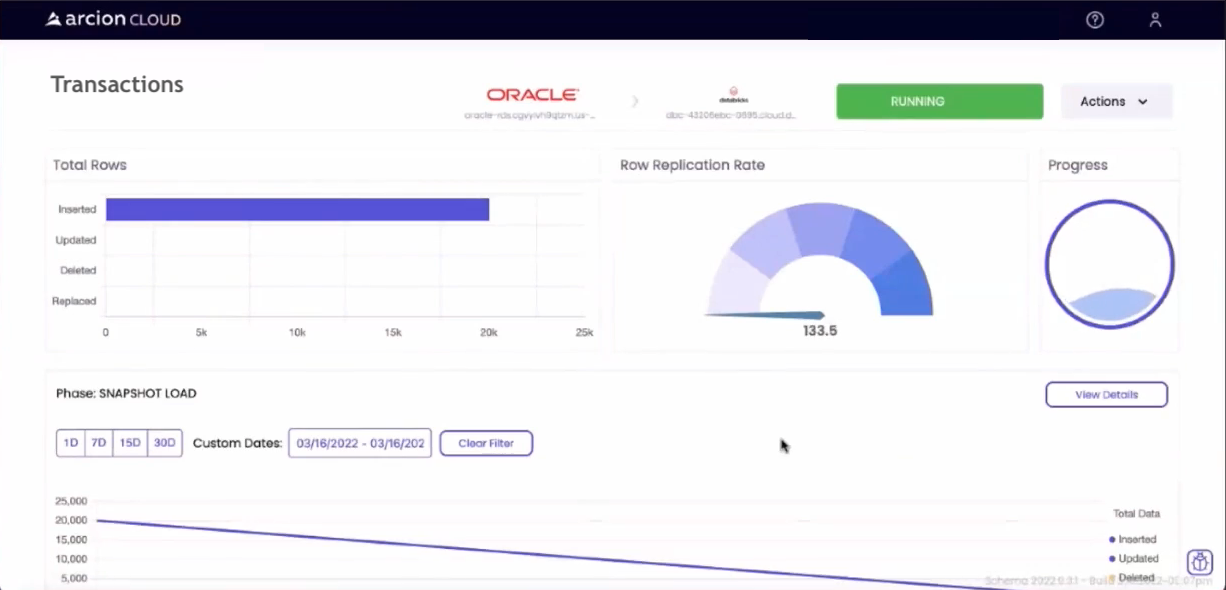
Как отмечалось выше, сначала будет выполнен моментальный снимок, а затем любые будущие обновления будут поступать через поток CDC. После завершения пользовательский интерфейс обновляется, как показано ниже:
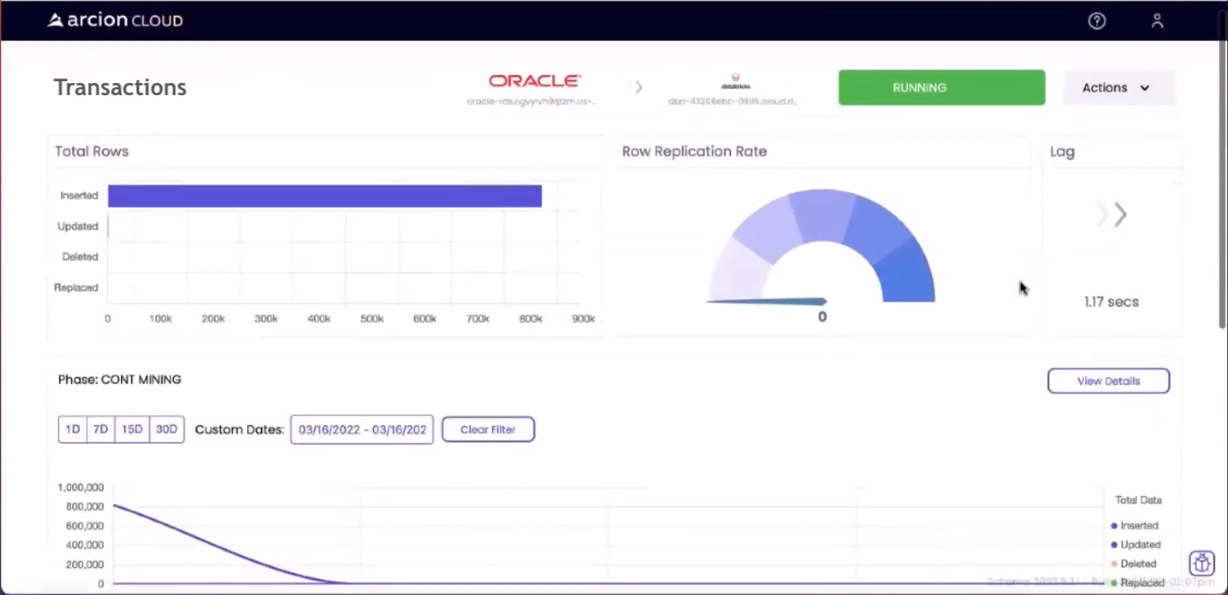
На данный момент слой Bronze (Ingestion) Delta Lake готов к использованию.
Полученные данные могут быть преобразованы в уровни Silver (переопределенные таблицы) и Gold (хранилище данных Feature/Agg), что позволяет нам использовать преимущества функциональности Delta Lake для обнаружения и предотвращения мошенничества. В будущем ожидается, что все данные из таблицы Oracle TRANSACTIONS будут автоматически находить путь в блоки данных.
У нас есть последний шаг по включению CDC в озеро данных. Прежде чем запускать модель мошенничества ML для вывода прогнозов, мы запускаем предварительно созданные тесты dbt или контрольные точки больших ожиданий, чтобы убедиться, что мы получили новые записи с момента нашего последнего запуска обнаружения мошенничества. Это придало бы WorldWide Bank уверенность в том, что полный сквозной CDC от Oracle перетекает в Databricks, как и ожидалось.
Меня очень впечатляет то, что я могу установить этот уровень дизайна, просто выполнив ряд шагов в пользовательском интерфейсе Arcion Cloud, не написав ни одной строки программного кода. В сценарии использования WorldWide Bank создание аналогичных реплик для других их баз данных должно быть таким же простым, что позволяет обрабатывать все обнаружение мошенничества в одной единой системе.
Вывод
С 2021 года я стараюсь жить в соответствии со следующей миссией, которую, как мне кажется, можно применить к любому ИТ-специалисту:
- «Сосредоточьте свое время на предоставлении возможностей/функциональности, которые повышают ценность вашей интеллектуальной собственности. Используйте фреймворки, продукты и услуги для всего остального».*
- Дж. Вестер
Arcion обеспечивает функциональность CDC, не изобретая велосипед. Их платформа позволяет группам специалистов использовать подход без кода для установления исходных и целевых источников данных, а также все необходимое для маршрутизации входящих транзакций базы данных во вторичный источник до того, как они будут записаны в базу данных.
Кроме того, Arcion можно развернуть несколькими способами. Финансовые или медицинские предприятия, например, могут иметь требования безопасности или соответствия. Они могут развернуть Arcion с собственным хостингом локально или в виртуальном частном облаке. Для компаний, у которых нет ресурсов DevOps для управления собственными развертываниями, хорошим вариантом будет полностью управляемое облако Arcion.
Кроме того, простота установки моментальных снимков и потоковой репликации CDC позволяет дополнительным источникам данных использовать ту же логику обработки, что и реализация Databricks Delta Lake. В конечном итоге это обеспечивает подход «не повторяйся» (DRY), позволяя одному источнику логики сосредоточиться на обнаружении мошенничества.
Команда Arcion, безусловно, придерживается моей личной миссии и позволяет своим клиентам сосредоточиться на достижении корпоративных приоритетов.
Если бы я работал с той же командой BI, о которой упоминал во введении, я бы, безусловно, рекомендовал изучить Arcion Cloud для удовлетворения их потребностей. Это даст возможность получать данные в режиме реального времени, а не полагаться на данные за день для принятия решений.
Хорошего дня!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)