
Экономное масштабирование для стартапов: как мы удерживали наши расходы на уровне менее 5 тысяч долларов в месяц
12 марта 2022 г.Если вам нужно спроектировать систему, которая может обслуживать более 1 миллиарда рекламных запросов в день или ~200 ГБ в час, то, скорее всего, вы выберете какую-нибудь причудливую технологию больших данных. И, конечно, это тоже имеет смысл. Эти цифры покажутся ничтожным человеком по сравнению с такими инструментами, как Kafka, Spark, Flink, Hadoop и другими. Так легко проектировать.
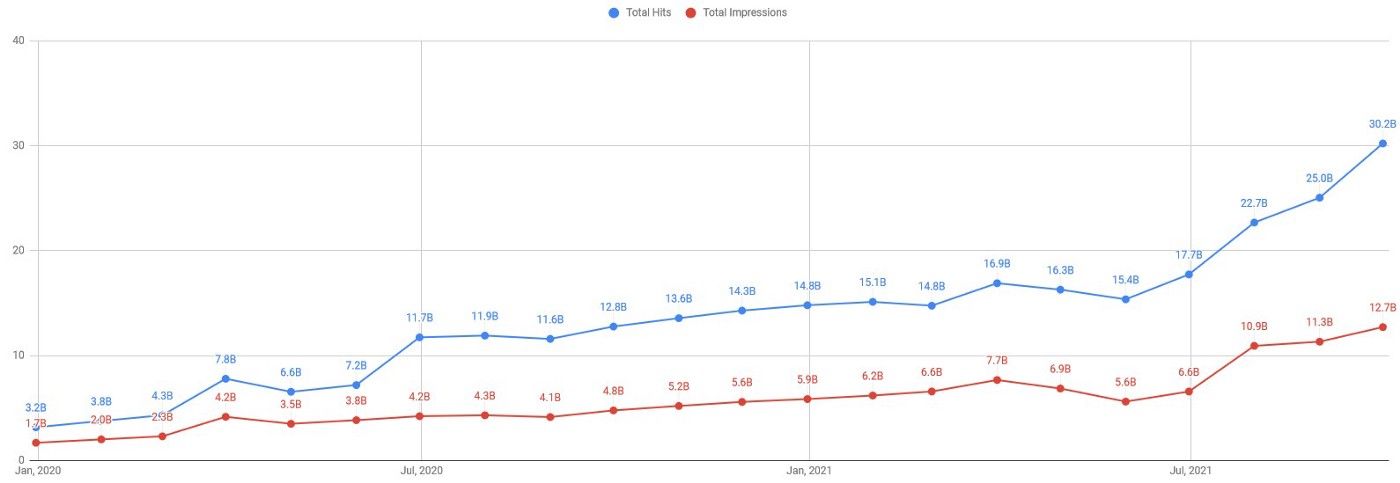
Недавно AdPushup обслужил более 1,2 млрд запросов отзывов и 425 млн уникальных показов в день. Это был момент гордости для инженеров, поскольку собственная система, разработанная 2 года назад, теперь автоматически масштабируется почти в 10 раз. Но путь к разработке такой системы был длинной чередой экспериментов.
Еще в 2016 году, когда я присоединился к AdPushup, у нас не было конкретного конвейера данных. Приоритетом было создание и стабилизация набора инструментов для A/B-тестирования. Для отчетности мы полагались на Google (GAM, Adsense) и других партнеров. Однако частые запросы на отчетность и потребность в принятии обоснованных решений подтолкнули к необходимости внутренней настройки отчетности.
Будучи новичком в отчетности AdTech, команда имела смутное представление о важных данных, которые могут быть полезны издателям. Таким образом, был разработан гибкий подход, и все доступные точки данных были записаны. Сценарий на стороне клиента начал отправлять данные в формате JSON о ряде событий, таких как просмотр рекламы, клик и т. д. Каждое обращение/запрос содержало около 20–30 точек данных.
Требовалась независимая от схемы система/инструмент, и благодаря Microsoft плану венчурного акселератора достаточное количество кредитов были в распоряжении команды для экспериментов.
Да начнутся ЭКСПЕРИМЕНТЫ!
Стек ELK был первым выбором, так как в то время он был очень популярен и обеспечивал необходимую свободу от схемы. Так был настроен небольшой кластер Elastic Search и в него заливались логи. Сначала он работал отлично, но масштабировался не так, как ожидалось.
- Одномерное агрегирование работало очень гладко. Однако производительность ухудшилась, когда была опробована агрегация по нескольким измерениям.
- По мере увеличения размера данных и количества входящих запросов общая производительность кластера снижалась. Добавление дополнительных узлов в кластер сначала помогло, но через какое-то время производительность перестала улучшаться.
Неудача с ELK (вроде как) заставила нас рассмотреть другие решения. Поэтому вместо внутреннего решения мы начали искать какое-то управляемое или белое решение. Умение команды гуглить привело нас к keen.io (к счастью!) И это оказалось блестящим инструментом. У него были все преимущества стека ELK, а также многое другое:
- Полностью управляемый инструмент. Инфракрасное обслуживание не требуется.
- Автоматическое обнаружение схемы.
- Отлично работает для всех типов запросов агрегации.
- Простота установки и использования.
НО, преимущества не оправдывали счет. Предполагаемая плата составляла где-то около 13 тысяч долларов в месяц. Долгосрочные затраты были слишком высоки для стартапа на ранней стадии.
Напоминая о бесплатных кредитах от Azure, команда планировала использовать полноценный стек больших данных — Kafka+Spark+Hive, вся эта хрень. К счастью, в Azure было найдено управляемое решение — Azure HDInsight. Был проведен короткий POC, и выступление показалось убедительным. Каждый компонент установки можно было масштабировать как по вертикали, так и по горизонтали, плюс практически не требовалось никакого управления. Узких мест не предвиделось. Но опять же стоимость этого кластера не имела смысла, учитывая небольшой размер данных.
Ориентировочная стоимость составляла около 7,5 000 долларов США в месяц, что более чем вдвое превышало стоимость всей инфраструктуры в Azure.
Объезд — Где произошло волшебство
Пока все это происходило, возникла потребность в настройке высокодоступного хранилища данных типа «ключ-значение». Идея заключалась в том, чтобы обслуживать некоторую конфигурацию по всему миру с минимально возможной задержкой. CDN был невозможен, так как команда ожидала сложных вычислений на периферии. Поэтому была разработана установка с веб-серверами и локальными хранилищами данных в нескольких географических точках.
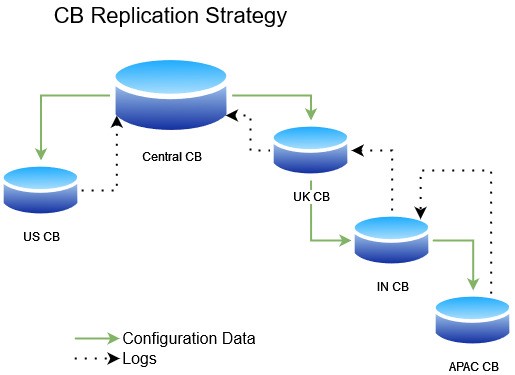
Для хранилища данных были протестированы Redis, MongoDB, ElasticSearch и Couchbase. После нескольких тестов Couchbase (CB) показался наиболее подходящим вариантом. Установка была довольно простой, управление кластером было в основном самоуправляемым, и у него был вполне зрелый и стабильный готовый механизм репликации данных — XDCR.
После нескольких итераций окончательный проект имел автоматически масштабируемый кластер веб-сервера (Azure VMSS) и двухузловой кластер Couchbase (CB) в 4 известных местах: США, Великобритании, Азиатско-Тихоокеанского региона и Индии. Для распределения трафика мы использовали географическую маршрутизацию AWS Route53. Это помогло распределить трафик в зависимости от географического положения входящего DNS-запроса. Были созданы две отдельные корзины CB для хранения конфигураций в центральном кластере CB. Эти корзины CB были дополнительно реплицированы во все четыре периферийных местоположения. Стратегия репликации основывалась на географическом расстоянии между регионами.
Получение документов с определенным ключом прошло быстро, как и ожидалось. Общее время отклика приложения было менее 40 мс, что было приемлемым. Общие понесенные затраты составили около 2,1 тыс. долл. США в месяц.
Также была потребность в системе мониторинга, чтобы следить за журналами приложений. Поэтому мы повторно использовали ту же настройку и создали третью корзину CB для хранения журналов. Для единого представления панели управления все журналы должны были находиться в одном центре обработки данных. Поэтому журналы были XDCR от всех регионов до центрального кластера CB (черные пунктирные линии на предыдущем изображении).
Внутренняя система регистрации
Мы создали панель инструментов для просмотра последних журналов, их сведений и количества. Для этой агрегации использовались Couchbase Views. Система логгеров оказалась весьма полезной. И… к счастью, наша собственная настраиваемая система ведения журналов была запущена и работала с небольшими дополнительными затратами (перемещение журналов между регионами).
Именно тогда нас осенило попытаться повторно использовать это и для нашего конвейера отчетности!!
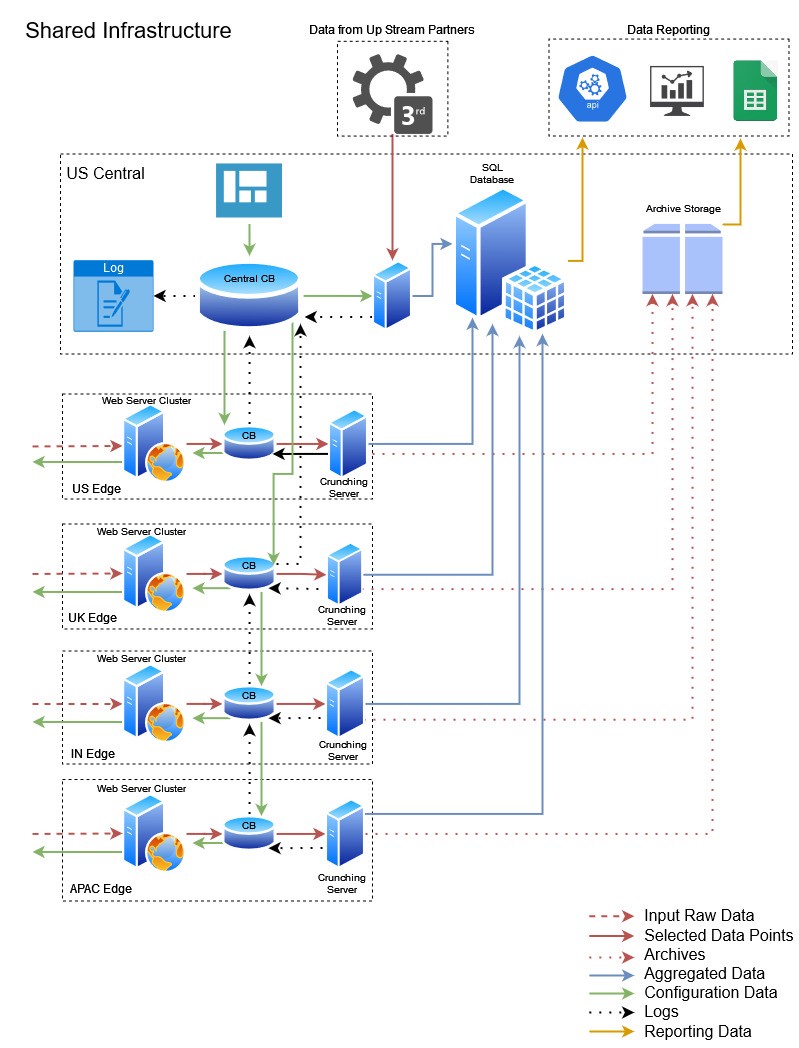
Мы начали с добавления новой конечной точки Java Servlet на существующие веб-серверы для сбора необработанных данных от клиентов. Данные запроса хранились во вновь созданной корзине CB в каждом регионе. Java-приложение для потоковой передачи данных с использованием CB View было создано и развернуто в каждом регионе. Был сформирован список фиксированных точек данных, и приложение агрегировало их в памяти. Он продолжал читать из представления CB, агрегировать до конца часа и помещать агрегации в центральную базу данных SQL.
Он также одновременно сжимал необработанные данные в формат .tar.gz и сохранял их в холодном хранилище для последующей обработки по запросу. Сообщение об успешном цикле, контрольные точки были обновлены, журналы предыдущего часа были очищены, и была начата обработка данных следующего часа.

Эврика момент!
ЭТО РАБОТАЛО!! К нашему удивлению, это оказалось успешным с точки зрения экономической эффективности и целей отчетности.
Дополнительные ежемесячные расходы включали в себя перегрузочные серверы (фиксированная 1,3 тыс. долларов) + дополнительная пропускная способность входящих данных (\~300 долларов) + SQL Server (фиксированная 1,1 тыс. долларов). Таким образом, реальный и простой в обслуживании конвейер данных был возможен менее чем за 5 000 долларов США в месяц.
Мы смогли получить полную отчетность менее чем за 1 месяц. Мы поддерживали 21 параметр и 42 показателя с возможностью добавления дополнительных точек данных в любое время в будущем. Одним из самых больших преимуществ этой общей инфраструктуры была низкая стоимость и низкие эксплуатационные расходы. Благодаря простоте этой конструкции мы смогли построить и обслуживать трубопровод только командой из 2 инженеров!
После тестирования установки в течение почти двух кварталов, тщательного сопоставления чисел и устранения расхождений в данных, мы запустили вживую в августе 2019 года.
Краткое описание настройки приведено ниже. Каждый цвет линии имеет значение, так что читайте между строк!
Сноски
- Недавно я прочитал статью [Кайлаша Надха] (https://nadh.in/) о [Масштабирование с учетом здравого смысла] (https://zerodha.tech/blog/scaling-with-common-sense/) и понял что мы уже практикуем все это в AdPushup. Я вдохновился и тоже решил поделиться нашим путешествием.
- За разработку системы и внедрение первой стабильной версии полностью отвечает [Шреяс Заре] (https://twitter.com/shreyasonline). Он предвидел повторное использование инфраструктуры. Его опыт проектирования простых, но мощных архитектур лег в основу всех работающих конвейеров данных и других серверных систем в AdPushup. Ознакомьтесь с другими его работами [здесь] (https://github.com/TechnitiumSoftware).
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27648)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)