В эпоху самообслуживания бизнес-аналитики почти каждая компания считает себя поставщиком данных. -first, но не каждая компания относится к своей архитектуре данных с должным уровнем демократизации и масштабируемости.
Например, ваша компания рассматривает данные как движущую силу инноваций. Ваш босс был одним из первых в отрасли, кто увидел потенциал в Snowflake и Looker. Или, может быть, ваш CDO возглавил кросс-функциональную инициативу по обучению команд передовым методам управления данными, а ваш технический директор инвестировал в группу обработки данных.
Однако больше всего вся ваша группа обработки данных желает, чтобы был более простой способ управления растущими потребностями вашей организации, от обработки бесконечного потока специальных запросов до обработки разрозненных источников данных через центральный конвейер ETL.
В основе этого стремления к демократизации и масштабируемости лежит осознание того, что ваша текущая архитектура данных (во многих случаях разрозненное хранилище данных или озеро данных с некоторыми ограниченными возможностями потоковой передачи в реальном времени) может не соответствовать вашим потребностям.
К счастью, командам, ищущим новую аренду данных, не нужно искать ничего, кроме сетки данных, архитектурной парадигмы, которая штурмом берет отрасль.
Что такое сетка данных?
Во многом так же, как команды разработчиков программного обеспечения перешли от монолитных приложений к микросервисной архитектуре, сетка данных во многом является версия платформы данных микросервисов.
Согласно первому определению Жамака Дехгани, консультанта ThoughtWorks и автора этого термина, сетка данных – это Тип архитектуры платформы данных, который охватывает повсеместное распространение данных на предприятии за счет использования доменно-ориентированной архитектуры самообслуживания.
Заимствуя теорию Эрика Эванса о проектировании, ориентированном на предметную область, гибкой, масштабируемой парадигме разработки программного обеспечения, которая соответствует структуре и языку вашего кода соответствующей области бизнеса. .
В отличие от традиционных монолитных инфраструктур данных, которые управляют потреблением, хранением, преобразованием и выводом данных в одном центральном озере данных, сетка данных поддерживает распределенных, специфичных для предметной области потребителей данных и представлений «[данные как продукт] (https: //hackernoon.com/building-data-products-without-the-mesh)», при этом каждый домен обрабатывает свои собственные конвейеры данных. Ткань, соединяющая эти домены и связанные с ними активы данных, представляет собой универсальный уровень взаимодействия, который использует тот же синтаксис и стандарты данных.
Вместо того, чтобы заново изобретать очень продуманно построенное Zhamak колесо, мы сведем определение сетки данных к нескольким ключевым понятиям и подчеркнем, чем она отличается от традиционных архитектур данных.
(Однако, если вы еще этого не сделали, я настоятельно рекомендую прочитать ее новаторскую статью Как перейти от монолитного озера данных к распределенной сетке данных или посмотрите технический доклад Макса Шульте о почему Zalando перешел на сетку данных.Вы не пожалеете).
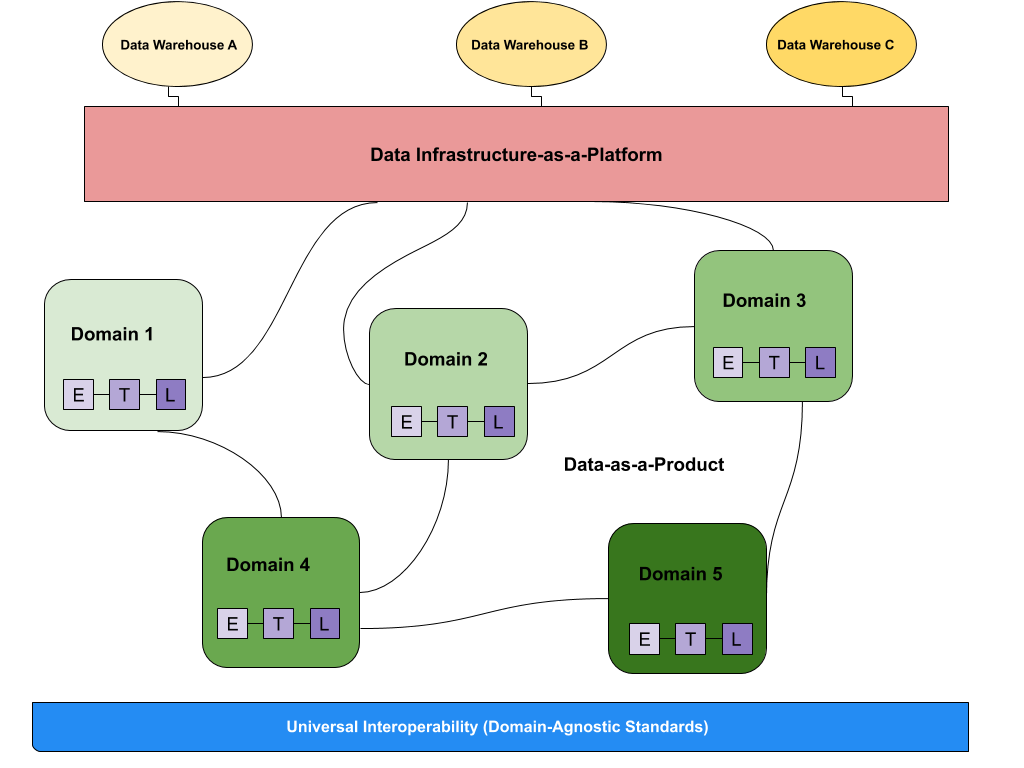
Владельцы и конвейеры данных, ориентированные на предметную область
Ячеистые сети данных объединяют владение данными между владельцами доменных данных, которые несут ответственность за предоставление своих данных в виде продуктов, а также облегчают обмен данными между распределенными данными в разных местах.
В то время как инфраструктура данных отвечает за предоставление каждому домену решений для их обработки, задача доменов заключается в управлении приемом, очисткой и агрегированием данных для создания активов, которые могут использоваться приложениями бизнес-аналитики.
Каждый домен отвечает за владение своими конвейерами ETL, но ко всем доменам применяется набор возможностей, которые хранят, каталогизируют и поддерживают контроль доступа к необработанным данным. После того как данные переданы и преобразованы данным доменом, владельцы домена могут использовать эти данные для своих аналитических или операционных нужд.
Функция самообслуживания
Сети данных используют принципы доменно-ориентированного проектирования для предоставления самообслуживаемой платформы данных, которая позволяет пользователям абстрагироваться от технической сложности и сосредоточиться на своих индивидуальных случаях использования данных.
Как отметил Жамак, одной из основных проблем доменно-ориентированного проектирования является дублирование усилий и навыков, необходимых для обслуживания конвейеров данных и инфраструктуры в каждом домене. Чтобы решить эту проблему, сетка данных собирает и извлекает возможности инфраструктуры данных, не зависящие от предметной области, в центральную платформу, которая обрабатывает механизмы конвейера данных, хранилище и инфраструктуру потоковой передачи.
Между тем, каждый домен отвечает за использование этих компонентов для запуска настраиваемых конвейеров ETL, предоставляя им поддержку, необходимую для простого обслуживания своих данных, а также автономию, необходимую для реального владения процессом.
Совместимость и стандартизация связи
В основе каждого домена лежит универсальный набор стандартов данных, который помогает облегчить сотрудничество между доменами, когда это необходимо — и это часто бывает. Неизбежно, что некоторые данные (как необработанные источники, так и очищенные, преобразованные и обслуживаемые наборы данных) будут ценны более чем для одной области.
Чтобы обеспечить междоменное сотрудничество, сетка данных должна стандартизировать форматирование, управление, возможности обнаружения и поля метаданных, а также другие функции данных. Более того, как и в случае отдельного микросервиса, каждый домен данных должен определять и согласовывать SLA и меры качества, которые они «гарантируют» своим потребителям.
Зачем использовать сетку данных?
До недавнего времени многие компании использовали единое хранилище данных, подключенное к множеству платформ бизнес-аналитики. Такие решения поддерживались небольшой группой специалистов и часто были обременены значительным техническим долгом.
В 2020 году архитектура du jour представляет собой озеро данных с доступностью данных в режиме реального времени и потоковой обработкой с целью приема, обогащения, преобразования и обслуживания данных с централизованной платформы данных. Многим организациям этот тип архитектуры не подходит по нескольким причинам:
- Центральный конвейер ETL дает командам меньший контроль над растущими объемами данных.
- Поскольку каждая компания становится компанией данных, разные варианты использования данных требуют разных типов преобразований, что создает большую нагрузку на центральную платформу.
Такие озера данных приводят к отключенным производителям данных, нетерпеливым потребителям данных и, что еще хуже, к отставанию группы данных, изо всех сил пытающейся идти в ногу с требованиями бизнеса. Вместо этого доменно-ориентированные архитектуры данных, такие как сетки данных, дают командам лучшее из обоих миров: централизованную базу данных (или распределенное озеро данных) с доменами (или бизнес-областями), ответственными за обработку своих собственных конвейеров.
[Как утверждает Жамак] (https://martinfowler.com/articles/data-monolith-to-mesh.html#DomainDataAsAProduct), архитектуры данных проще всего масштабировать, разбив их на более мелкие, ориентированные на предметную область компоненты.
Сетки данных обеспечивают решение недостатков озер данных, предоставляя владельцам данных большую автономию и гибкость, способствуя большему экспериментированию с данными и инновациям, а также уменьшая нагрузку на группы данных, связанные с удовлетворением потребностей каждого потребителя данных через единый конвейер.
Между тем, инфраструктура самообслуживания сеток данных как платформа предоставляет группам данных универсальный, не зависящий от предметной области и часто автоматизированный подход к стандартизации данных, происхождению продуктов данных, мониторингу продуктов данных, предупреждению, регистрации и продуктам данных. метрики качества (другими словами, сбор данных и обмен ими).
В совокупности эти преимущества обеспечивают конкурентное преимущество по сравнению с традиционными архитектурами данных, которым часто мешает отсутствие стандартизации данных как между принимающими, так и потребителями.
Сетить или не сешать: вот в чем вопрос
Команды, работающие с большим объемом источников данных и нуждающиеся в экспериментировании с данными (другими словами, быстром преобразовании данных), могут рассмотреть возможность использования сетки данных.
Мы провели простой расчет, чтобы определить, имеет ли смысл для вашей организации инвестировать в сетку данных. оценка сетки данных.
- Количество источников данных. Сколько источников данных у вашей компании?
- Размер вашей группы данных. Сколько аналитиков данных, инженеров данных и менеджеров по продуктам (если есть) есть в вашей команде данных?
- Количество доменов данных. Сколько функциональных групп (маркетинг, продажи, операции и т. д.) полагаются на ваши источники данных для принятия решений, сколько продуктов у вашей компании и сколько функций, управляемых данными, разрабатывается? Добавьте общее количество.
- Узкие места при обработке данных. Как часто команда по обработке данных становится узким местом при внедрении новых продуктов обработки данных по шкале от 1 до 10, где 1 означает «никогда», а 10 — «всегда»?
- Управление данными. Насколько приоритетным является управление данными для вашей организации по шкале от 1 до 10, где 1 – "мне все равно", а 10 – "это не дает мне спать всю ночь"?
Оценка сетки данных
В целом, чем выше ваш балл, тем сложнее и требовательнее требования вашей компании к инфраструктуре данных и, в свою очередь, тем больше вероятность того, что ваша организация выиграет от сетки данных.
Если вы набрали более 10 баллов, то внедрение некоторых передовых методов работы с сеткой данных, вероятно, имеет смысл для вашей компании. Если вы набрали более 30 баллов, значит, ваша организация находится в выигрышном положении в области сетки данных, и вам следует присоединиться к революции данных.
Вот как разбить ваш счет:
- 1–15: Учитывая размер и одномерность вашей экосистемы данных, вам может не понадобиться сетка данных.
- 15–30: Ваша организация быстро взрослеет и, возможно, даже находится на перепутье с точки зрения возможности опираться на данные. Мы настоятельно рекомендуем использовать некоторые передовые методы и концепции сетки данных, чтобы облегчить последующую миграцию.
- 30 или больше: организация данных — это двигатель инноваций для вашей компании, а сетка данных будет поддерживать любые текущие или будущие инициативы по демократизации данных и предоставлению аналитики самообслуживания в масштабах предприятия.
По мере того, как данные становятся все более распространенными, а требования потребителей данных продолжают диверсифицироваться, мы ожидаем, что сетки данных станут все более распространенными для облачных компаний с более чем 300 сотрудниками.

Сетка данных может снизить риски
Огромный потенциал использования архитектуры сетки данных одновременно захватывающий и пугающий для многих в индустрии данных. На самом деле, некоторые опасаются, что непредвиденная автономия и демократизация сетки данных создают новые риски, связанные с обнаружением и работоспособностью данных, а также с управлением данными.
Учитывая относительную новизну сеток данных, это справедливое беспокойство, но я бы посоветовал пытливым умам читать мелкий шрифт. Вместо того, чтобы создавать эти риски, сетка данных фактически требует масштабируемой, самостоятельной наблюдения в ваших данных.
По словам Жамака, такие возможности самообслуживания, присущие любой хорошей сетке данных, включают:
- Шифрование данных в состоянии покоя и в движении
- Версии продукта данных
- Схема продукта данных
- Обнаружение продукта данных, регистрация каталога и публикация
- Управление данными и стандартизация
- Линия производства данных
- Мониторинг продуктов данных, оповещение и регистрация
- Показатели качества продукта данных
В совокупности эти функции и стандартизация обеспечивают надежный уровень [наблюдаемости данных] (https://www.montecarlodata.com/blog-what-is-data-observability/).
Хотите узнать больше о сетке данных? В дополнение к ресурсам Жамака и Макса ознакомьтесь с некоторыми из наших любимых статей об этой восходящей звезде инженерии данных:
- [Применение сетки данных — Свен Балноян] (https://towardsdatascience.com/data-mesh-applied-21bed87876f2)
- [Должно ли ваше приложение учитывать возможность подключения к сетке данных? — Джо Глейнсер] (https://www.eckerson.com/articles/the-data-mesh-re-thinking-data-integration)
Также опубликовано [Здесь] (https://www.montecarlodata.com/blog-what-is-a-data-mesh-and-how-not-to-mesh-it-up/)