
Запуск Presto на метамасштабе: извлеченные уроки
25 апреля 2023 г.Presto – это бесплатный механизм запросов SQL с открытым исходным кодом. Мы использовали его в Meta последние десять лет и многому научились при этом. Запуск чего-либо в больших масштабах — инструментов, процессов, служб — требует решения проблем для преодоления неожиданных проблем.
Вот четыре вещи, которые мы узнали при масштабировании Presto до метамасштаба, и несколько советов, если вы заинтересованы в выполнении собственных запросов в масштабе!
Быстрое масштабирование Presto для удовлетворения растущих потребностей: с какими проблемами мы столкнулись?
Развертывание новых выпусков Presto
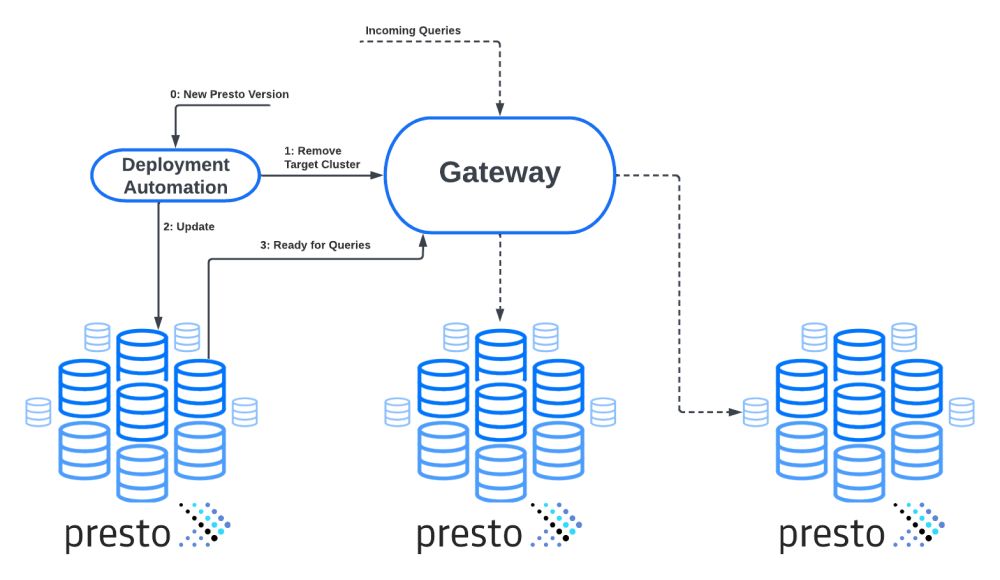
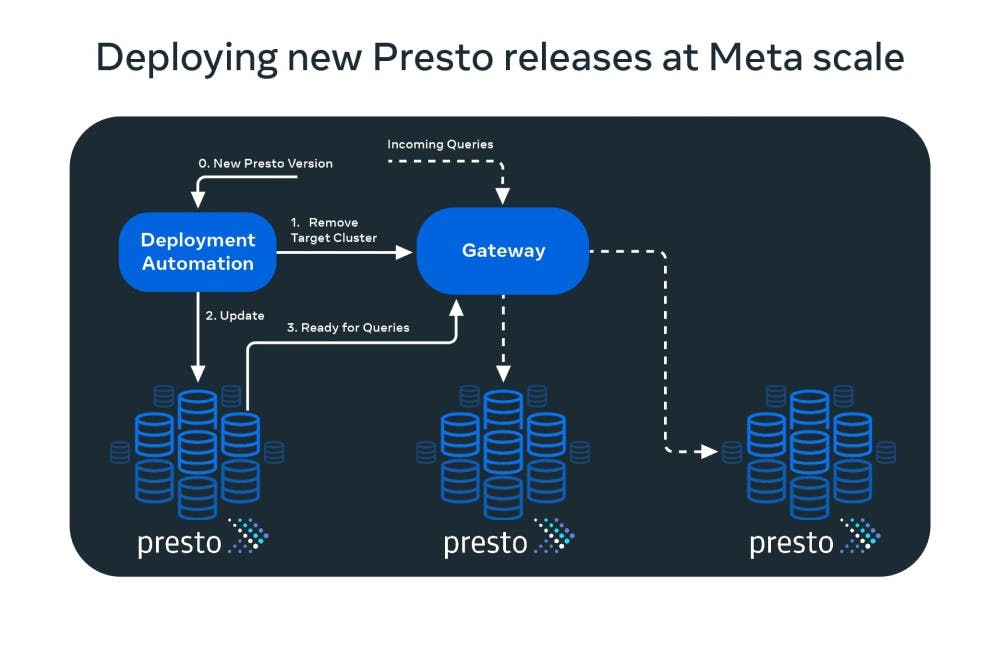
Meta управляет большим количеством кластеров Presto, охватывающих центры обработки данных по всему миру. Новая версия Presto создается и готова к развертыванию примерно один, а иногда и два раза в месяц.
Одной из первых проблем, с которыми мы столкнулись по мере быстрого роста присутствия Presto в Meta, было развертывание механизма запросов на большом количестве кластеров с обеспечением постоянной доступности и надежности.
Это по-прежнему актуально для интерактивных вариантов использования Presto, т. е. когда пользователь запускает запрос и активно ожидает результата. Сбой запроса меньше беспокоит автоматизированных «пакетных» вариантов использования, когда автоматические повторные попытки гарантируют, что запрос в конечном итоге будет успешным.
Решение для этого было простым. Все кластеры Presto находятся за балансировщиком нагрузки, называемым шлюзом, который отвечает (вместе с другими системами в Meta) за маршрутизацию запросов Presto в соответствующий кластер.
Когда кластер Presto необходимо обновить, он сначала помечается как удаленный от шлюза, т. е. шлюз прекращает маршрутизацию любых новых запросов к нему. Затем автоматизация ожидает в течение заранее определенного времени, чтобы завершить запросы, выполняющиеся в данный момент в кластере.
Затем кластер обновляется, и когда он находится в сети, он становится видимым для шлюза, который может начать направлять к нему новые запросы.
Другим аспектом развертывания новых выпусков Presto является доступность. Нам нужно убедиться, что пользователи по-прежнему могут использовать Presto во время обновления кластеров. Опять же, автоматизация гарантирует, что каждый центр обработки данных в каждом физическом регионе всегда будет иметь необходимое количество доступных кластеров Presto.
Конечно, необходимо соблюдать баланс между одновременным отключением слишком большого количества кластеров (проблема доступности) и одновременным удалением слишком малого количества кластеров (развертывание занимает слишком много времени).
Автоматизация запуска и вывода кластеров Presto из эксплуатации
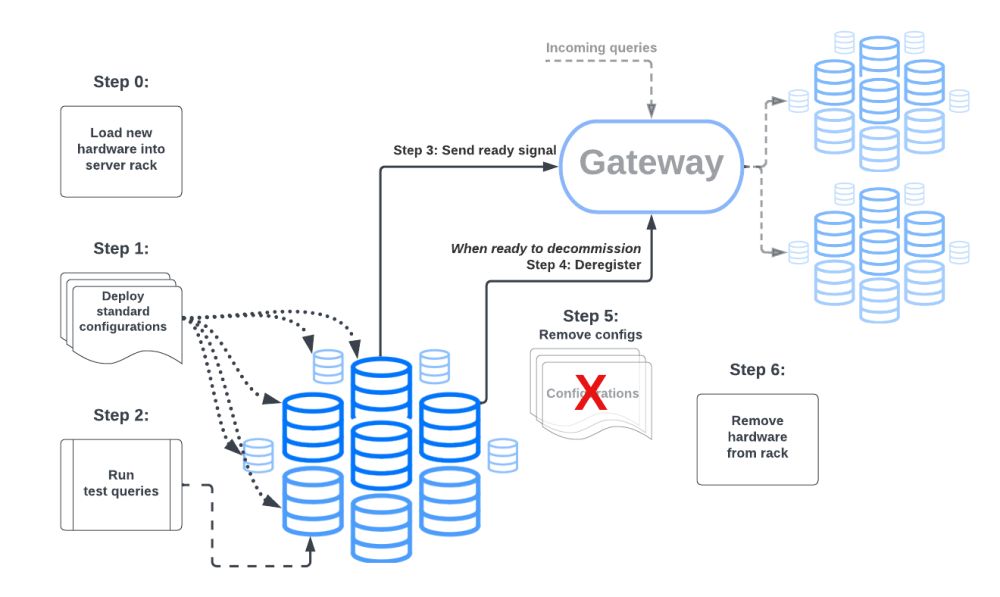
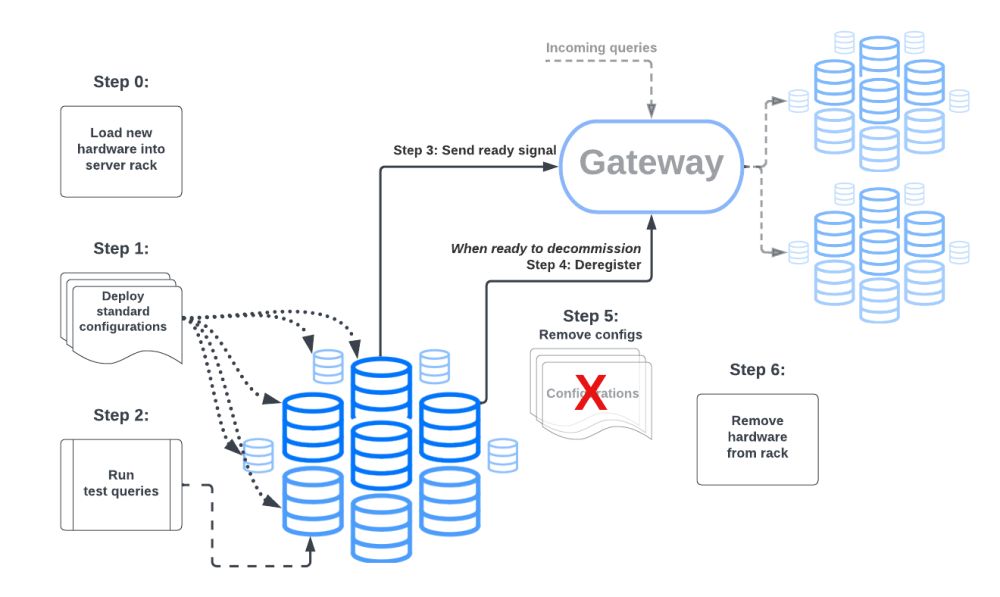
Распределение хранилища данных в Meta по разным регионам постоянно развивается. Это означает, что новые кластеры Presto должны быть установлены, в то время как существующие регулярно выводятся из эксплуатации.
Ранее, когда было небольшое количество кластеров Presto, этот процесс выполнялся вручную.
Когда Meta начала масштабироваться, быстро стало сложно отслеживать все изменения вручную. Чтобы решить эту проблему, мы внедрили автоматизацию для обработки запуска и вывода кластеров из эксплуатации.
Во-первых, нам пришлось стандартизировать конфигурации наших кластеров, т. е. нам нужно было создать базовые конфигурации для различных вариантов использования Presto в Meta. Тогда каждый кластер будет иметь минимальное количество дополнительных или переопределенных спецификаций по сравнению с базовой конфигурацией.
Как только это будет завершено, любой новый кластер можно будет включить, автоматически сгенерировав конфигурации из базового шаблона.
Развертывание кластера также требовало интеграции с крючками автоматизации для интеграции с различными общекорпоративными инфраструктурными сервисами, такими как Tupperware и сервисами, специфичными для хранилища данных.
Как только кластер подключается к сети, в него отправляется несколько тестовых запросов, и автоматизация проверяет, успешно ли они были выполнены кластером. Затем кластер регистрируется на шлюзе и начинает обслуживать запросы.
Вывод кластера из эксплуатации происходит практически в обратном порядке. Регистрация кластера на шлюзе отменяется, и все запущенные запросы могут быть завершены. Процессы Presto останавливаются, а конфигурации кластера удаляются.
Эта автоматизация интегрирована в рабочий процесс установки и вывода из эксплуатации оборудования для хранилища данных.
Конечным результатом является то, что весь процесс, от появления нового оборудования в центре обработки данных до кластеров Presto, которые находятся в сети и обслуживают запросы, а затем отключаются при выводе оборудования из эксплуатации, полностью автоматизирован.
Внедрение этого позволило сэкономить драгоценные человеко-часы, сократить время простоя оборудования и свести к минимуму человеческий фактор.
Автоматическая отладка и исправления
Учитывая широкое развертывание Presto в Meta, крайне важно, чтобы у нас были инструменты и средства автоматизации, которые упрощают жизнь дежурного (точки контакта для Presto).
За прошедшие годы мы создали несколько «анализаторов», которые помогают дежурной службе эффективно отлаживать и оценивать основную причину возникающих проблем. Системы мониторинга выдают оповещения при нарушении SLA для клиентов. Затем срабатывают анализаторы.
Они получают информацию из широкого спектра систем мониторинга (Operational Data Store или ODS), событий, опубликованных в Scuba, и даже журналов на уровне хоста. Пользовательская логика в анализаторе затем связывает всю эту информацию вместе, чтобы сделать вывод о возможных основных причинах.
Это чрезвычайно полезно для дежурных, предоставляя им анализ первопричин и позволяя им сразу переходить к возможным вариантам смягчения последствий.
В некоторых случаях мы полностью автоматизировали как отладку, так и исправление, так что дежурному даже не нужно вмешиваться. Несколько примеров описаны ниже:
Обнаружение плохого хоста
При масштабном запуске Presto на большом количестве компьютеров мы заметили, что некоторые «плохие» хосты могут вызывать частые сбои запросов. После наших расследований мы выявили несколько основных причин, из-за которых хосты стали «плохими», в том числе:
* Проблемы на уровне оборудования, которые еще не были обнаружены системами мониторинга всего парка техники из-за отсутствия охвата.
* Непонятные ошибки JVM, которые иногда приводили к постоянным ошибкам запросов.
Чтобы решить эту проблему, мы теперь отслеживаем сбои запросов в кластерах Presto. В частности, мы приписываем каждый сбой запроса хосту, вызвавшему его, где это возможно. Мы также настроили оповещения, которые срабатывают, когда аномально большое количество сбоев запросов связано с определенными хостами.
Затем срабатывает автоматизация, чтобы вывести хост из парка Presto и, таким образом, предотвратить сбои.
Отладка проблем с очередями
Каждый кластер Presto поддерживает постановку запросов в очередь, когда он достигает максимального параллелизма для выполнения запросов в зависимости от варианта использования, конфигурации оборудования и размера запроса.
В Meta существует сложный механизм маршрутизации, так что запрос Presto отправляется в «правильный» кластер, который может выполнить запрос, максимально используя ресурсы.
Несколько систем помимо Presto участвуют в принятии решения о маршрутизации и учитывают множество факторов:
* Текущее состояние очереди в кластерах Presto.
* Распределение оборудования по разным центрам обработки данных.
* Местоположение данных таблиц, которые использует запрос
Учитывая эту сложность, дежурному по вызову может быть очень сложно выяснить основную причину любых проблем с очередями, возникающих в производственной среде. Это еще один случай, когда анализаторы выходят на первый план, извлекая информацию из нескольких источников и представляя выводы.
Надежность балансировщика нагрузки
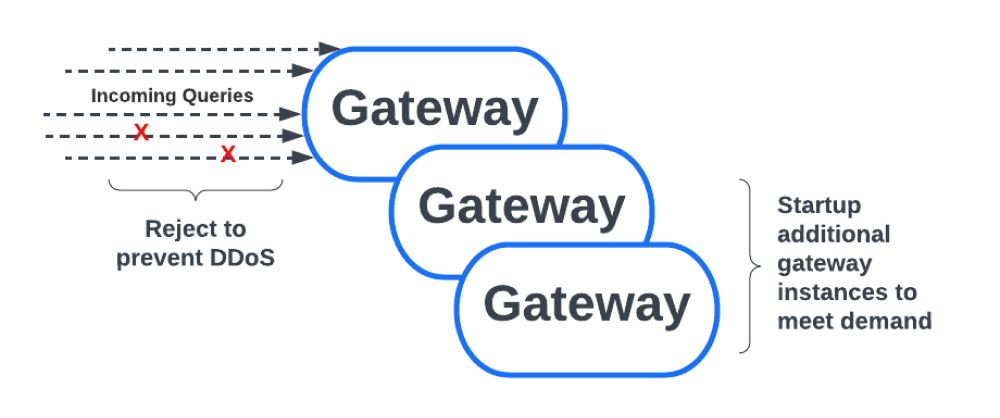
Как упоминалось выше, наши кластеры Presto находятся за балансировщиками нагрузки, которые направляют каждый запрос Presto в Meta. В начале, когда Presto еще не достигла уровня внутреннего использования, который она имеет сегодня, Gateway был очень простым.
Однако по мере увеличения использования Presto в Meta мы несколько раз сталкивались с проблемами масштабируемости. Одним из них был сбой шлюза при большой нагрузке, что могло привести к недоступности Presto для всех пользователей.
Основной причиной некоторых проблем со стабильностью была одна служба, которая непреднамеренно бомбардировала шлюз миллионами запросов за короткий промежуток времени, что приводило к сбою процессов шлюза и невозможности маршрутизировать какие-либо запросы.
Чтобы предотвратить такой сценарий, мы решили сделать шлюз более надежным и устойчивым к такому непреднамеренному трафику в стиле DDoS. Мы реализовали функцию регулирования, которая отклоняет запросы при большой нагрузке.
Регулирование может быть активировано на основе количества запросов в секунду по различным измерениям, например, для каждого пользователя, для каждого источника, для каждого IP-адреса, а также на глобальном уровне для всех запросов. Еще одним усовершенствованием, которое мы внедрили, было автоматическое масштабирование.
Опираясь на службу Meta-wide, которая поддерживает увеличение и уменьшение количества заданий, количество экземпляров Gateway теперь является динамическим.
Это означает, что при высокой нагрузке шлюз теперь может масштабироваться для обработки дополнительного трафика и не перегружать ЦП/память, что предотвращает описанный выше сценарий сбоя.
Это, в сочетании с функцией регулирования, обеспечивает надежность шлюза и возможность противостоять неблагоприятным непредсказуемым схемам трафика.
Что бы мы посоветовали команде, расширяющей собственный Data Lakehouse с помощью Presto?
Вот некоторые из важных аспектов, которые следует учитывать при расширении Presto:
- Создание простых для понимания и четких соглашений об уровне обслуживания для клиентов. Определение SLA для важных показателей, таких как время ожидания в очереди и частота отказов запросов, таким образом, чтобы отслеживать болевые точки клиентов, становится критически важным по мере масштабирования Presto. При большом количестве пользователей отсутствие надлежащих соглашений об уровне обслуживания может сильно затруднить усилия по устранению производственных проблем из-за путаницы при определении влияния инцидента.
2. Мониторинг и автоматическая отладка. По мере масштабирования Presto и увеличения количества кластеров мониторинг и автоматическая отладка становятся критически важными.
-
Тщательный мониторинг может помочь выявить производственные проблемы до того, как радиус их поражения станет слишком большим. Своевременное обнаружение проблем гарантирует, что мы по возможности сведем к минимуму влияние на пользователей.
2. Ручные расследования производственных проблем, влияющих на клиента, не масштабируются. Крайне важно иметь автоматическую отладку, чтобы можно было быстро определить основную причину.
3. Хорошая балансировка нагрузки. По мере роста парка Presto важно иметь хорошее решение для балансировки нагрузки перед кластерами Presto. В больших масштабах небольшая неэффективность балансировки нагрузки может иметь серьезные негативные последствия из-за огромного объема рабочей нагрузки.
4. Управление конфигурацией. Управление конфигурацией большого парка кластеров Presto может стать проблемой, если оно не будет хорошо спланировано. По возможности конфигурации должны быть доступны для горячей перезагрузки, чтобы экземпляры Presto не приходилось перезапускать или обновлять с нарушением работы, что может привести к сбоям запросов и неудовлетворенности клиентов.
Эта статья была написана в сотрудничестве с Нирадом Соманчи, инженером по производству в Meta, и Филипом Беллом, защитником разработчиков в Meta.
Чтобы узнать больше о Presto, посетите prestodb.io, посмотрите краткое объяснение Presto на YouTube или следите за Presto на Twitter, Facebook, и LinkedIn.
Первоначально опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27664)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)