
PolyThrottle: энергоэффективный анализ нейронных сетей на периферийных устройствах: эксперименты
3 апреля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC BY-NC-ND 4.0 DEED.
Авторы:
(1) Минхао Ян, Университет Висконсин-Мэдисон;
(2) Хонги Ван, Университет Карнеги-Меллон;
(3) Шиварам Венкатараман, myan@cs.wisc.edu.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Мотивация
- Возможности
- Обзор архитектуры
- Формулировка задачи: двухфазная настройка
- Моделирование помех в рабочей нагрузке
- Эксперименты
- Выводы и amp; Ссылки
- А. Подробности об оборудовании
- Б. Результаты экспериментов
- C. Арифметическая интенсивность
- Д. Анализ предикторов
7 ЭКСПЕРИМЕНТОВ
7.1 Настройка
Аппаратная платформа. Наши эксперименты проводятся с использованием комплектов разработчика Jetson TX2 и Jetson Orin Developer Kit. Для оценки энергопотребления нашей программы мы используем встроенные мониторы энергопотребления в комплектах разработчика Jetson TX2 и Jetson Orin. Мы также проверяем наши измерения с помощью внешнего цифрового мультиметра (более подробную информацию об аппаратном обеспечении и измерении энергии см. в Приложении А).
Выбор рабочей нагрузки. Мы основываем наши эксперименты на семействе EfficientNet и моделях Берта (Tan & Le, 2019; Devlin et al., 2018). EfficientNet выбран не только из-за своего статуса современной сверточной сети для устройств и мобильных устройств, но также из-за ее принципиального подхода к масштабированию ширины, глубины и разрешения слоев свертки. В Таблице 4 представлена схема масштабирования EfficientNet от наименьшего B0 до самого большого B7. Мы выбрали Берта для исследования закономерностей использования энергии в модели на основе Transformer (Wolf et al., 2020), где рабочая нагрузка в большей степени ограничена памятью по сравнению с нейронными сетями на основе свертки. Берт и его варианты (Ким и др., 2021; Девлин и др., 2018; Сан и др., 2019; Тамбе и др., 2021) широко используются для задач вопросов и ответов (Раджпуркар и др., 2016), что делает его применимым для множества периферийных устройств, таких как умные домашние помощники и умные колонки.
Набор данных. Мы оцениваем PolyThrottle на основе данных о реальных потоках трафика (Shen et al., 2019) и единообразно выбираем кадры для передачи в EfficientNet. Что касается Берта, мы оцениваем SQuAD (Rajpurkar et al., 2016) для ответов на вопросы. Обратите внимание, что наборы данных не влияют на производительность PolyThrottle, поскольку задержка вывода не будет существенно меняться в разных наборах данных после выбора модели.
Реализация. PolyThrottle построен на базе сервера вывода Nvidia Triton. Чтобы максимизировать производительность, мы генерируем ядра TensorRT, которые профилируют различные макеты данных и стратегии мозаики, чтобы определить самый быстрый граф выполнения для данной аппаратной платформы. Наши модули включают байесовский оптимизатор для определения наилучшей конфигурации, клиент вывода, отвечающий за предварительную обработку и отправку запросов на сервер вывода, а также модуль прогнозирования производительности, интегрированный в клиент вывода для планирования запросов точной настройки. Мы поддерживаем отдельные очереди для запросов на вывод и тонкую настройку.
7.2. Эффективный поиск оптимальной конфигурации
В этом эксперименте мы проводим обширный эмпирический анализ настройки различных моделей в разных конфигурациях оборудования, а также регулируем уровень квантования. Мы выполняем поиск по сетке EfficientNet B0, B4, B7 и Bert Base, чтобы изучить потенциальную экономию энергии и определить оптимальные частоты графического процессора и памяти для каждой модели. Мы также настраиваем уровень квантования для каждой тестируемой модели. Мы оцениваем точность 16-битных и 32-битных чисел с плавающей запятой (FP16/FP32). Оптимальное энергопотребление и конфигурация, упомянутые далее в этом разделе, используют полученные здесь результаты в качестве базового и оптимального решения. Получив оптимальную частоту с помощью поиска по сетке, мы затем оцениваем среднее количество попыток, необходимых PolyThrottle, чтобы найти решение в пределах 5% от оптимального решения. Мы сравниваем нашу формулировку ограниченной байесовской оптимизации (CBO) со случайным поиском (RS).
Настройки эксперимента: мы измеряем среднее количество попыток, необходимых для поиска почти оптимальной конфигурации. Для случайного поиска мы рассчитываем ожидаемое количество попыток, необходимых для поиска почти оптимальной конфигурации, на основе размера сетки, вычисляя долю почти оптимальных конфигураций и принимая обратное значение. Для CBO мы установили параметр ξ, связанный с функцией ожидаемого улучшения, равным 0,1, а исходные случайные выборки равным 5, что, по нашему мнению, хорошо работает на разных моделях и аппаратных платформах. Мы проводим два эксперимента, в которых устанавливаем разные ограничения на задержку вывода. Результаты можно найти на рисунке 5:
1. Мы ограничиваем задержку вывода до оптимальной (20%). В этом случае жесткие ограничения на задержку делают невозможным пакетную обработку запроса на вывод, что существенно сокращает пространство поиска для оптимальной конфигурации.
2. Во втором тесте мы ослабляем ограничение на задержку вывода, включив в него конфигурации, которые обеспечивают наименьшее энергопотребление на запрос, как показано на рисунке 2. В этом случае нам нужно изучить размер пакета, чтобы найти конфигурацию, которая минимизирует энергопотребление. Мы тестируем EfficientNet B0, B4 и B7, а также Bert Base на Jetson TX2 и Jetson Orin.
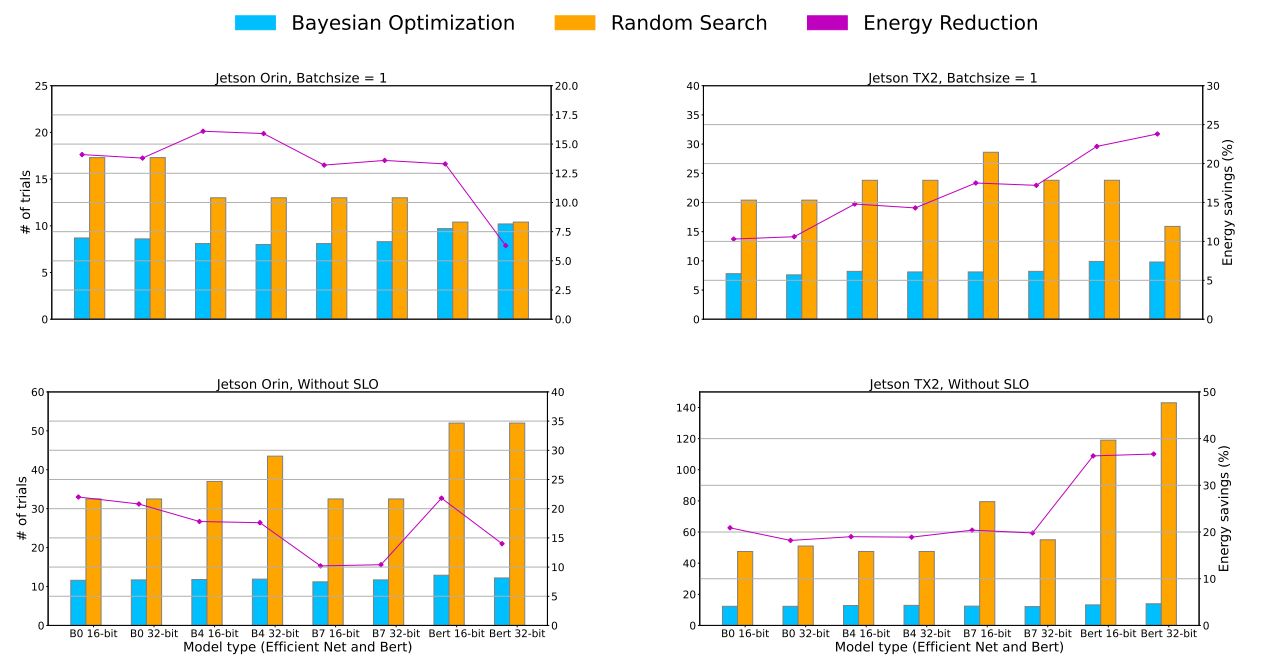
Результаты. На рис. 5 показано, что CBO превосходит RS в обоих сценариях. Поскольку CBO моделирует взаимосвязь между конфигурацией оборудования и задержкой, он может найти почти оптимальное решение, используя всего 5–15 выборок. Во втором сценарии производительность RS ухудшается, поскольку он не может использовать взаимосвязь между задержкой и размером пакета при работе с мультипликативно увеличивающимся пространством поиска. В целом CBO берет в 3–10 раз меньше образцов во втором варианте. Накладные расходы на выполнение CBO также минимальны. Как показано на рисунке 5, CBO требуется всего около 15 образцов, чтобы найти почти оптимальное решение, а процедура оптимизации может быть завершена за несколько минут. В случаях, когда развертывается новая модель, требуется всего несколько минут для поиска оптимальных конфигураций для новой модели.
Важно отметить, что, хотя RS может достичь производительности, сравнимой с CBO при определенных условиях, этот результат является всего лишь ожидаемым значением, а дисперсия RS велика. Например, если 10 из 200 конфигураций близки к оптимальным, ожидаемое количество испытаний, необходимых для достижения почти оптимальной конфигурации, равно 20 со стандартным отклонением 19,49. Следовательно, вполне вероятно, что даже после 40 испытаний RS все равно не сможет определить конфигурацию, близкую к оптимальной. С другой стороны, стандартное отклонение CBO меньше; во всех экспериментах стандартные отклонения CBO составляют менее 3.
7.3 Точная настройка планирования с учетом рабочей нагрузки
Далее мы оцениваем, насколько хорошо PolyThrottle обрабатывает запросы тонкой настройки наряду с логическим выводом. Главный вопрос, который мы стремимся решить, заключается в том, может ли наш предсказатель производительности эффективно идентифицировать и соответствующим образом корректировать ситуацию, когда существует риск нарушения требования SLO, и может ли уменьшение размера пакета вывода и торговой пропускной способности удовлетворить SLO с задержкой. Чтобы смоделировать этот сценарий, мы генерируем два различных шаблона вывода (Uniform и Poisson), используем общедоступную трассировку Twitter (twi, 2018) и сравниваем наш подход к адаптивному планированию с жадным планированием, при котором запрос на тонкую настройку планируется, как только оно приходит. Три шаблона поступления представляют собой сценарии, которые являются строго контролируемыми и импульсными соответственно. В этом контексте мы сравниваем механизм адаптивного планирования PolyThrottle с жадным подходом к планированию, чтобы оценить эффективность PolyThrottle в удовлетворении желаемого требования SLO.
Настройки эксперимента. Мы оцениваем как синтетические, так и реальные рабочие нагрузки. Для синтетических рабочих нагрузок мы генерируем поток запросов вывода, используя как равномерное распределение, так и распределение Пуассона. Для реальной рабочей нагрузки мы сначала равномерно выбираем следы потоковой передачи Twitter за день, а затем вычисляем дисперсию запросов в течение каждой минуты. Затем мы выбрали сегмент с наибольшей дисперсией, чтобы проверить способность PolyThrottle обрабатывать пакеты запросов (twi, 2018; Romero et al., 2021). На Jetson Orin мы воспроизводим поток в течение 30 секунд и измеряем частоту нарушений SLO во время воспроизведения с помощью EfficientNet B7. Поскольку каждый пакет длится всего несколько секунд, этого достаточно для захвата большого количества пакетов рабочей нагрузки. Мы обнаружили, что проведение эксперимента в течение более длительного времени дает аналогичные результаты. Мы установили размер пакета точной настройки равным 64, количество итераций точной настройки — 10, SLO — 0,7 с, размерность вывода — 1000 и в среднем 8 запросов на вывод в секунду. На Jetson TX2 мы проделываем тот же эксперимент на EfficientNet B4. Из-за ограничений памяти мы выполняем точную настройку размера пакета до 8, SLO до 1 с, размерность вывода до 100 и в среднем 4 запроса на вывод в секунду. Мы выбираем менее производительную модель на TX2, чтобы достичь разумного целевого показателя SLO (менее 1 с). Количество итераций тонкой настройки выбирается исходя из длительности повтора. Затем мы измеряем затраты энергии при развертывании PolyThrottle на стандартной и оптимальной аппаратной частоте соответственно, чтобы измерить, сколько энергии мы экономим за этот период. Оптимальная аппаратная частота получается из результатов раздела 7.2.
Для жадного планирования мы используем стандартную политику отбрасывания (Crankshaw et al., 2017; Shen et al., 2019), согласно которой запрос отбрасывается, если срок его выполнения уже истек. В адаптивной настройке мы используем предиктор, чтобы определить, следует ли отбрасывать запрос на вывод. Мы также воспроизводим поток запросов на вывод без тонкой настройки запросов, чтобы они служили базовыми показателями.
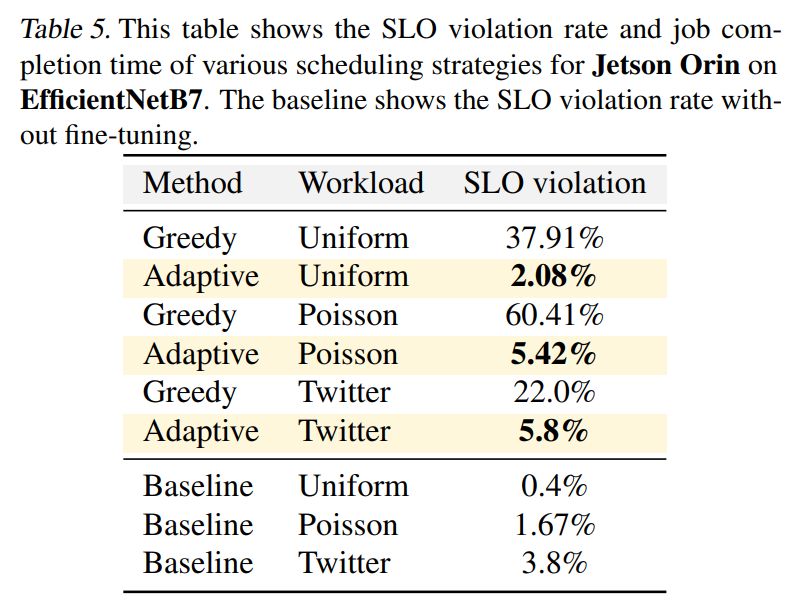
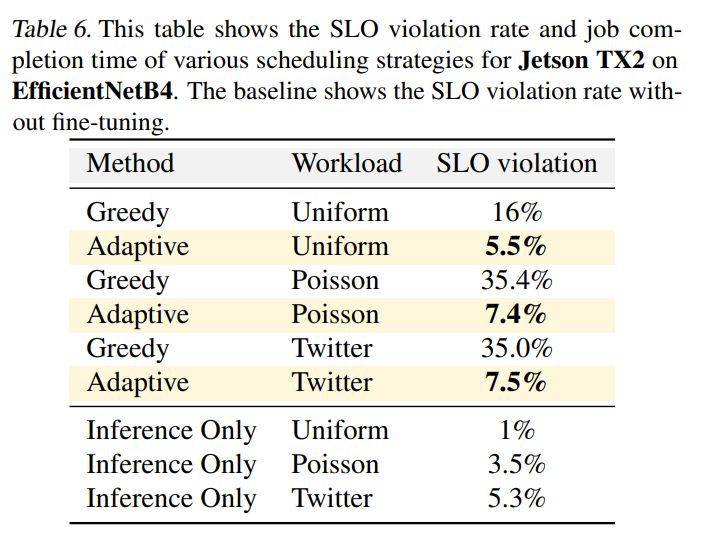
Результаты. В таблицах 5 и 6 показаны показатели нарушений SLO при различных рабочих нагрузках и целевых значениях задержки. Результаты показывают, что жадное планирование может привести к серьезным нарушениям SLO из-за помех, вызванных рабочей нагрузкой по точной настройке. Напротив, механизм адаптивного планирования PolyThrottle демонстрирует способность достигать низкого уровня нарушений SLO за счет динамической настройки конфигураций. Базовые цифры в таблице представляют уровень нарушений SLO при отсутствии вмешательства со стороны запросов на тонкую настройку.
Присущая дисперсия вывода нейронной сети привела к 1% нарушений SLO в случае равномерного распределения. Однако всплески распределения Пуассона и рабочая нагрузка Twitter привели к увеличению количества нарушений SLO. Механизм адаптивного планирования PolyThrottle значительно снижает частоту нарушений SLO, удовлетворяя требованиям SLO и одновременно обрабатывая запросы на тонкую настройку. Тем не менее, в нескольких случаях нам не удалось добиться почти нулевого уровня нарушений SLO. Это ограничение можно объяснить детализацией планирования, поскольку мы обрабатываем текущий пакет запросов в течение длительного периода времени из-за помех со стороны рабочей нагрузки тонкой настройки.
Мы также снижаем энергопотребление на 14 % при использовании EfficientNet B7 на Jetson Orin и на 23 % при использовании EfficientNet B4 на Jetson TX2 во всех рабочих нагрузках. В Приложении D мы покажем, как PolyThrottle реагирует на изменение SLO при наличии невыполненных запросов на тонкую настройку.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27664)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)