
Murre — легкий инструмент для мониторинга метрик K8s
20 октября 2022 г.Познакомьтесь с Мурре. Murre — это масштабируемый по требованию источник метрик ресурсов контейнера для Kubernetes. Murre получает CPU & метрики ресурсов памяти непосредственно из kubelet на каждом узле K8s и обогащает ресурсы соответствующими запросами и ограничениями K8s из каждого PodSpec.
Минимализм. Да, громкое слово, я знаю, но потерпите меня здесь. По сути, речь идет о том, чтобы владеть только тем, что добавляет ценности и смысла вашей жизни, и избавляться от всего остального. Речь идет об устранении беспорядка и использовании вашего времени и энергии для того, что осталось, поскольку в нашей жизни есть только определенное количество энергии, времени и пространства.
Лучшие разработчики программного обеспечения в душе минималисты. Минимализм означает не написание меньшего количества кода, а написание кода с элегантной и четкой структурой, который хорошо выполняет одну задачу. Минимализм в этом смысле означает проектирование систем, использующих как можно меньше аппаратных и программных ресурсов — потому что вы можете. Потому что вы считаете, что так все и должно быть.
Как и многие разработчики, мы применяем этот подход ко всему, что проектируем и создаем.
Наш путь к созданию Murre начался, когда мы захотели предоставить нашим клиентам ресурсы узлов K8s и показатели их использования. Как компании, разрабатывающей комплексное решение для мониторинга приложений Kuberenetes, потребность в нем была очевидна. Мы хотели отслеживать и экспортировать ресурсы, которые являются частью уровня инфраструктуры кластера — использование ЦП, памяти и диска на каждом узле, агрегированное каждым контейнером.
Звучит просто, верно? Дело в том, что как платформа мониторинга, встроенная в сердце кластера Kubernetes, мы всегда несем на себе печать минимализма. Мы стремимся быть как можно более легкими везде, где это возможно. Это также означает, что мы предпочитаем не устанавливать какие-либо сторонние инструменты в кластере, если в этом нет абсолютной необходимости.
Итак, мы взяли курс на получение метрик узла K8s, НО без необходимости устанавливать знаменитый Metrics Server.
Традиционный способ мониторинга метрик K8s
Очень часто мы видим, как клиенты борются с мониторингом физического уровня, который был абстрагирован K8s (вы знаете, тот же старый ЦП, память, диск и т. д.). Это становится особенно важным, когда у вас есть эффект шумных соседей, который означает, что ваш модуль может использовать ожидаемое распределение ресурсов, но все же страдать от недостающие ресурсы.
Экосистема Kubernetes включает в себя несколько дополнительных надстроек для сбора и предоставления данных мониторинга из вашего кластера Kubernetes. Metrics Server — одно из таких полезных дополнений.
Kubernetes Metrics Server — это общекластерный агрегатор данных об использовании ресурсов. Он собирает метрики, такие как потребление ЦП или памяти для контейнеров или узлов, из сводного API, предоставляемого Kubelet на каждом узле. Однако это надстройка, что означает, что она не является частью готовых K8s и не развернута по умолчанию на стандартных управляемых платформах Kubernetes.
Сервер метрик должен быть масштабируемым и ресурсоэффективным, требуя около 100 млн ядер ЦП и 200 МБ памяти для типичного кластера из 100 узлов. Это позволяет хранить в памяти только метрики почти в реальном времени, поддерживая специальные проверки использования ЦП или памяти или для периодических запросов службой мониторинга, которая сохраняет данные за более длительные промежутки времени.
Несмотря на то, что он хорошо масштабируется с вашим кластером K8s, он не свободен от проблем. Установка сторонней службы, работающей в вашем кластере, означает, что вы должны время от времени поддерживать ее и устранять неполадки. Он может зависать, потреблять больше ресурсов, чем вы рассчитывали, или не выполнять свою работу. . страница известных проблем сервера метрик — это всего лишь краткий обзор того, что значит принимать ответственность за другую постоянно работающую службу в уже загруженном кластере.
И еще один момент, который нас насторожил. В groundcover мы создали распределенное решение для наблюдения, которое можно масштабировать вместе с кластером и принимать решения на периферии. Например, мы хотим получить образец диапазона HTTP, вызвавшего всплеск загрузки ЦП в соответствующем модуле.
Переход к серверу метрик (помимо необходимости его установки и запуска) также будет означать, что каждому из наших пограничных устройств (работающему на каждом узле) придется регулярно запрашивать центральный сервер метрик для создания такого триггера. Это заставит нашу распределенную архитектуру полагаться на централизованную точку и затруднит масштабирование.
Сверхлегкие
groundcover предлагает легкий и простой подход к мониторингу приложений Kubernetes, поэтому мы начали искать другие способы выполнить эту работу.
Во-первых, мы начали с самостоятельного измерения ресурсов с помощью инструментов ОС Linux, таких как top, ps и т. д., непосредственно на каждом узле в кластере. Это решило одну часть головоломки по включению мониторинга ресурсов, который не требовал предварительной установки или обслуживания. Тем не менее, это привело к проблеме эффективности. Выходные данные таких инструментов, как top и ps, требуют синтаксического анализа. Кроме того, это были инструменты Linux, а не K8s, поэтому требовался второй уровень, который осмыслял ресурсы процессов и превращал их в ресурсы контейнеров, которые наши клиенты знают и понимают.
Но, как и любой хороший ответ на проблему, наш все время смотрел на нас.
Сервер метрик построен централизованно, по одному на каждый кластер. Так как же он получает все необходимые метрики со всех разных узлов? Беглый взгляд на код показывает четкий ответ — просто запросив Kubelet, работающий на каждом узле. Внезапно все это обрело смысл, поскольку сам K8s также должен измерять ресурсы узлов, чтобы рабочий процесс Kubelet работал!
Кубелет кто?
Kubelet — это процесс, который запускается на каждом узле кластера Kubernetes и создает, уничтожает или обновляет модули и их контейнеры для данного узла по указанию сделать это. По сути, Kubelet — это основной «агент узла», который работает на каждом узле и работает с использованием PodSpecs (объект YAML или JSON, описывающий модуль). Он отвечает за прием PodSpec, которые предоставляются с помощью различных механизмов (в основном через apiserver), и обеспечивает работоспособность контейнеров, описанных в этих PodSpec.
В Kubernetes планирование, вытеснение и вытеснение являются важной частью жизни кластера. Под планированием понимается проверка соответствия модулей узлам, чтобы Kubelet мог их запускать. Вытеснение — это процесс прекращения работы модулей с более низким приоритетом, чтобы модули с более высоким приоритетом могли планировать работу на узлах, а вытеснение — это процесс прекращения работы одного или нескольких модулей на узлах.
Kubelet играет решающую роль в этих основных сценариях. Например, сценарий, называемый выселением из-за давления узла. Kubernetes постоянно проверяет ресурсы узла, такие как загрузка диска, ЦП или нехватка памяти (OOM). Если потребление ресурсов (например, ЦП или памяти) в узле достигает определенного порога, Kubelet начнет вытеснять поды, чтобы освободить ресурс.
Именно поэтому Kubelet должен постоянно использовать метрики ресурсов Kubernetes для выполнения своей работы и предоставлять эти метрики другим службам, которым они также могут понадобиться.
Большой. Поэтому, если Kubelet уже предоставляет этот API серверу метрик, это означает, что мы можем использовать этот API самостоятельно.
Это два зайца одним выстрелом! Мы можем использовать этот API и запрашивать его напрямую, не развертывая сервер метрик в кластере, но мы также можем запрашивать его внутри каждого узла, не покидая узел. О, но это нигде не задокументировано… Так что нам пришлось копнуть глубже.
Глубокое погружение в исходный код Kubelet
Мы начали изучать источники Kubelet, чтобы выяснить, как он достигает метрик ресурсов K8s и как он предоставляет эти данные в виде API в потоке. Мы обнаружили, что Kubelet не только измеряет использование ресурсов на каждом узле кластера, но также предоставляет данные с использованием метрик в формате Prometheus, что нам очень нравится!
Kubelet API не задокументирован, но из его источников мы нашли конечные точки. Есть и другие конечные точки, которые не используются для метрик/статистики, но они выходят за рамки данного исследования. Определенно, впереди еще много золота, но пока мы сосредоточимся на показателях K8s.
Определения некоторых метрик можно найти здесь pkg/kubelet/server/server.go:
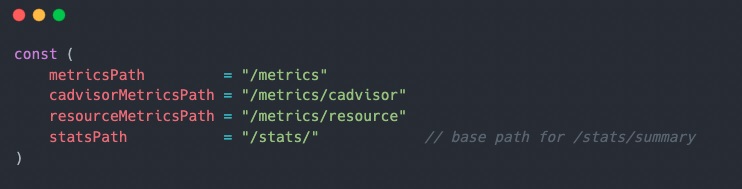
Чтобы получить доступ к Kubelet API, чтобы мы могли видеть данные:

Некоторые конечные точки Kubelet возвращают Json-файлы, а некоторые экспортируют фактические показатели. Вот некоторые из них, на которые стоит обратить внимание:
* /metrics/cadvisor — конечная точка представляет собой метрики, исходящие из cadvisor, и предоставляет все метрики потребления ресурсов контейнера, например: * ПРОЦЕССОР * Память * Файловая система * Сеть * /metrics/resource – эта конечная точка также содержит список ресурсов контейнера (ЦП, память), как и конечная точка cadvisor, но также дает нам ресурсы уровня модуля и уровня узла. * /stats/summary — эта конечная точка предоставляет сводные данные о потреблении ресурсов в формате JSON. По умолчанию он будет описывать все ресурсы (ЦП, память, файловая система и сеть, такие как конечная точка cadvisor), но вы можете передать флаг only_cpu_and_memory=true в качестве параметра запроса и получить только ЦП и память данные, если это то, что вам нужно.
Вот как выглядит структура ответа конечной точки:
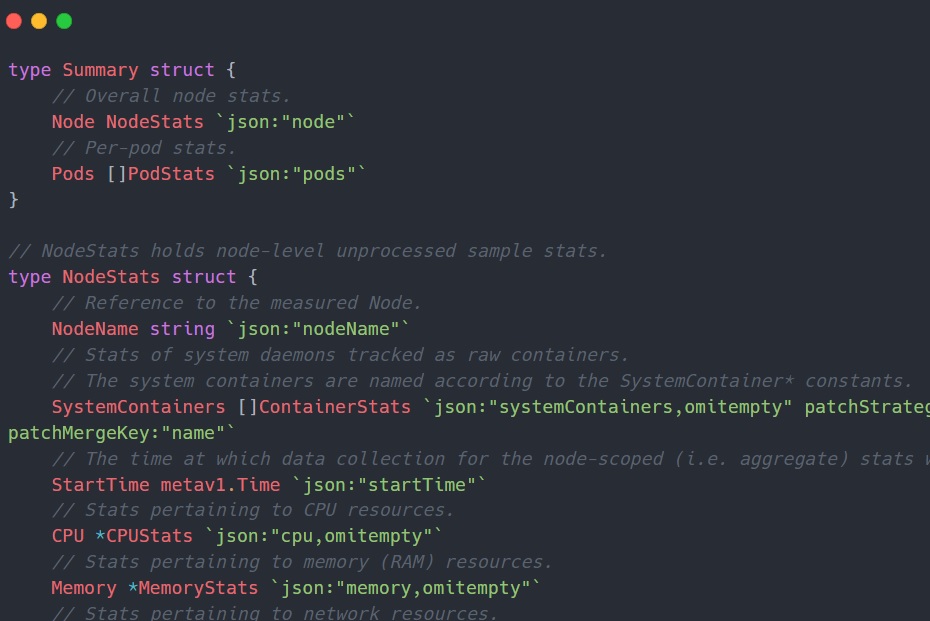
- /pods — эта конечная точка предоставляет информацию о модулях, работающих на узле, с полными характеристиками и статусом модуля. Эти данные также можно получить с помощью интерфейса podLister клиента K8s. Хотя эти конкретные данные полезны, они не имеют отношения к нашей цели мониторинга показателей ресурсов.
- /metrics — эта конечная точка предоставляет метрики, связанные с собственной внутренней статистикой Kubelet. Приятно знать, что он есть, но, как и прежде, он не будет использоваться для наших нужд.
А потом была Мурре
<цитата>Обыкновенная кайра — интересная птица. Он размножается колониями с высокой плотностью и не делает гнезд; Их единственное яйцо инкубируется на голом выступе скалы на скале. Минималистский? Они доводят свои навыки гнездования до крайности. Неудивительно, что нам понравилось это имя :)
После того, как мы выяснили, как получить эти метрики без их сохранения, мы подумали, что можем помочь решить это, этого и многих других с тем же шаблоном; представляем мурре.
Murre — это инструмент OSS, который в основном помогает вам получить ресурсы ЦП и процессора вашего контейнера. метрики памяти без необходимости устанавливать что-либо на кластер. Он работает так же, как metrics-server, только без сохранения метрик. С помощью Murre вы можете отфильтровать определенное пространство имен, модуль или даже имя контейнера, чтобы сосредоточиться на точных показателях, которые вам нужны.
Murre использует 3 различных API для получения данных, необходимых для создания этих показателей:
- NodeList — для обнаружения и поддержки списка всех доступных узлов.
- /metrics/cadvisor — чтобы получить фактические показатели использования. Этот API используется для каждого узла, как мы описали ранее.
- PodList — для обогащения данных запросами ресурсов K8s. и ограничения для каждого контейнера.
Вот как выглядит процесс обработки Murre:
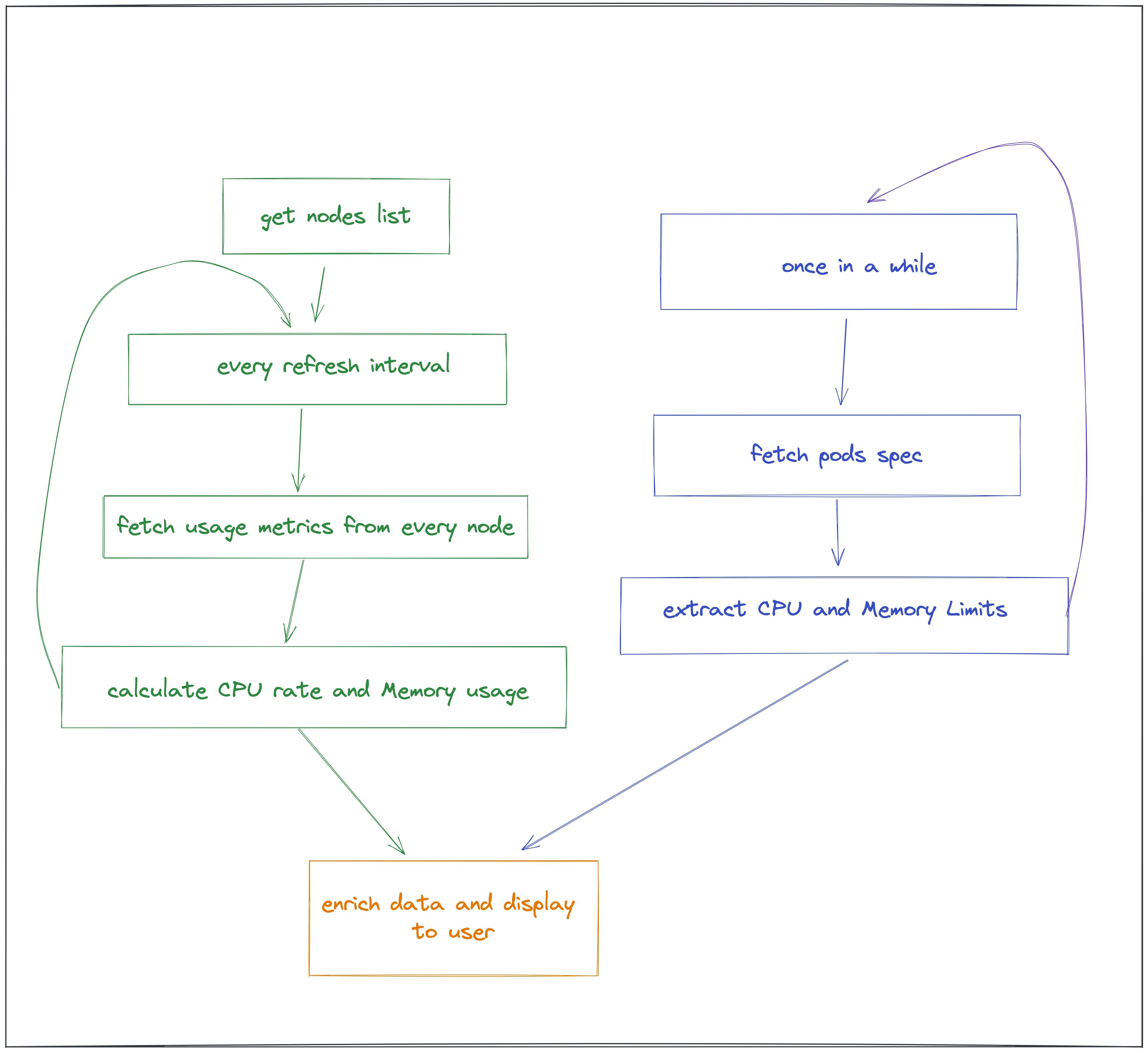
И вуаля!
демонстрация мурре – посмотреть видео

Не стесняйтесь мыслить масштабно, открывать проблемы или добавлять возможности самостоятельно. Небо — это (буквально) предел для этой особенной птицы.
Вопросы о Мурре? Присоединяйтесь к нашему сообществу Slack и свяжитесь с создателями!
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27631)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)