Особая благодарность Карлу Флёршу и Данкраду Файсту за обзор
Полностью гомоморфное шифрование долгое время считалось одним из святых Граалей криптографии. Обещание полностью гомоморфного шифрования (FHE) является мощным: это тип шифрования, который позволяет третьей стороне выполнять вычисления с зашифрованными данными и получать зашифрованный результат, который они могут передать тому, у кого есть ключ дешифрования для исходных данных. , без расшифровки данных или результата третьей стороной.
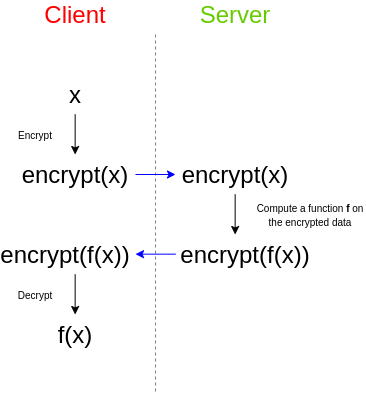
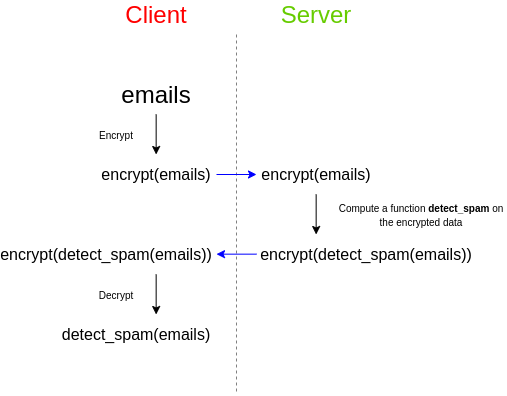
В качестве простого примера представьте, что у вас есть набор электронных писем, и вы хотите использовать сторонний спам-фильтр, чтобы проверить, являются ли они спамом. Спам-фильтр стремится к конфиденциальности своего алгоритма: либо поставщик спам-фильтра хочет держать свой исходный код закрытым, либо спам-фильтр зависит от очень большой базы данных, которую они не хотят раскрывать публично, поскольку это затруднит атаку легче, или и то, и другое. Однако вы заботитесь о конфиденциальности своих данных и не хотите загружать незашифрованные электронные письма третьим лицам. Итак, вот как вы это делаете:
Полностью гомоморфное шифрование имеет множество применений, в том числе в пространстве блокчейна. Одним из ключевых примеров является то, что его можно использовать для реализации легких клиентов с сохранением конфиденциальности (легкий клиент передает серверу зашифрованный индекс i, сервер вычисляет и возвращает data[0] * (i = 0) + data[1] * (i = 1) + ... + data[n] * (i = n), где data[i] – это i-й фрагмент данных в блоке или состоянии вместе с его ветвью Меркла и (i = k) – это выражение, которое возвращает 1, если i = k и 0 в противном случае; легкий клиент получает необходимые ему данные, а сервер ничего не узнает о том, что запросил легкий клиент).
Его также можно использовать для:
- Более эффективные протоколы скрытых адресов и более масштабируемые решения для протоколов сохранения конфиденциальности, которые сегодня требуют от каждого пользователя личного сканирования. весь блокчейн для входящих транзакций
- Торговые площадки для обмена данными, сохраняющие конфиденциальность, которые позволяют пользователям выполнять определенные вычисления над своими данными, сохраняя при этом полный контроль над своими данными для себя.
- Ингредиент более мощных криптографических примитивов, таких как более эффективные протоколы многосторонних вычислений и, возможно, в конечном итоге обфускация.
И оказывается, что полностью гомоморфное шифрование концептуально не так уж сложно понять!
Частично, частично, полностью гомоморфное шифрование
Во-первых, примечание об определениях. Существуют различные виды гомоморфного шифрования, некоторые из которых более мощные, чем другие, и они различаются по функциям, которые можно вычислить для зашифрованных данных.
- Частично гомоморфное шифрование позволяет оценить только очень ограниченный набор операций над зашифрованными данными: либо только сложения (таким образом, учитывая
зашифровать(а)изашифровать(b), вы можете вычислитьзашифровать(а+ b)) или просто умножения (данныезашифровать(a)изашифровать(b)можно вычислитьзашифровать(a*b)).
- До некоторой степени гомоморфное шифрование позволяет вычислять сложения, а также ограниченное число умножений (или полиномы до ограниченной степени). То есть, если вы получаете
encrypt(x1) ... encrypt(xn)(при условии, что это "исходные" шифры, а не результат гомоморфных вычислений), вы можете вычислитьencrypt(p(x1 ... xn) )), до тех пор, покаp(x1 ... xn)является многочленом степени< Dдля некоторой конкретной границы степениD(Dобычно очень мало, думаю, 5-15) .
- Полностью гомоморфное шифрование допускает неограниченное количество сложений и умножений. Сложения и умножения позволяют воспроизводить любые бинарные схемы (
И(x, y) = x*y,ИЛИ(x, y) = x+yx*y,XOR(x, y) = x+y -2*x*yили простоx+y, если вас интересует только четное и нечетное,NOT(x) = 1-x...), так что этого достаточно для выполнения произвольных вычислений с зашифрованными данными.
Частично гомоморфное шифрование довольно просто; например. RSA имеет мультипликативный гомоморфизм: enc(x)=x^e, enc(y)=y^e, поэтому enc(x)∗enc(y)=(xy)e=enc(xy) . Эллиптические кривые могут предложить аналогичные свойства с добавлением. Как оказалось, разрешить и сложение, и умножение значительно сложнее.
Простой несколько-HE-алгоритм
Здесь мы рассмотрим несколько гомоморфный алгоритм шифрования (то есть тот, который поддерживает ограниченное число умножений), который на удивление прост. Крейг Джентри использовал более сложную версию этой категории техники для создания первой в истории полностью гомоморфная схема в 2009 году. Более поздние попытки переключились на использование других схем. на основе векторов и матриц, но мы все же сначала пройдемся по этой технике.
Мы будем описывать все эти схемы шифрования как схемы с секретным ключом; то есть для шифрования и дешифрования используется один и тот же ключ. Любую схему HE с секретным ключом можно легко превратить в схему с открытым ключом: «открытый ключ» обычно представляет собой просто набор множества нулевых шифрований, а также шифрование одного (и, возможно, более степеней двойки). Чтобы зашифровать значение, сгенерируйте его, сложив соответствующее подмножество ненулевых шифровок, а затем добавив случайное подмножество нулевых шифровок, чтобы «рандомизировать» зашифрованный текст и сделать невозможным определение того, что он представляет.
Секретным ключом здесь является большое простое число p (представьте, что p содержит сотни или даже тысячи цифр). Схема может шифровать только 0 или 1, а "сложение" становится XOR, т.е. 1 + 1 = 0. Чтобы зашифровать значение m (которое равно 0 или 1), сгенерируйте большое случайное значение R (обычно оно даже больше, чем p) и меньшее случайное значение r (обычно намного меньше, чем p), и вывод:
enc(m) = R*p + r * 2 + m
Чтобы расшифровать зашифрованный текст ct, вычислите:
dec(ct) = (ct mod p) mod2
Чтобы добавить два зашифрованных текста ct1 и ct2, вы просто добавляете их: ct1+ct2. И чтобы умножить два зашифрованных текста, вы еще раз... перемножаете их: ct1∗ct2. Мы можем доказать гомоморфное свойство (что сумма зашифровок является зашифровкой суммы, и то же самое для произведений) следующим образом.
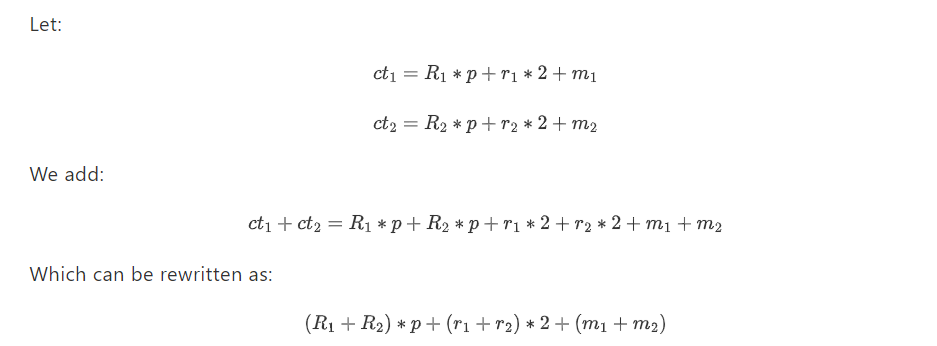
Который имеет ту же «форму», что и зашифрованный текст m1 + m2. Если вы расшифруете его, первая модификация p удалит первый член, вторая модификация 2 удалит второй член, и останется m1+m2 (помните, что если m1=1 и m2=1 тогда 2 поглощается вторым термином). срок, и вы останетесь с нулем). Итак, вуаля, у нас есть аддитивный гомоморфизм!
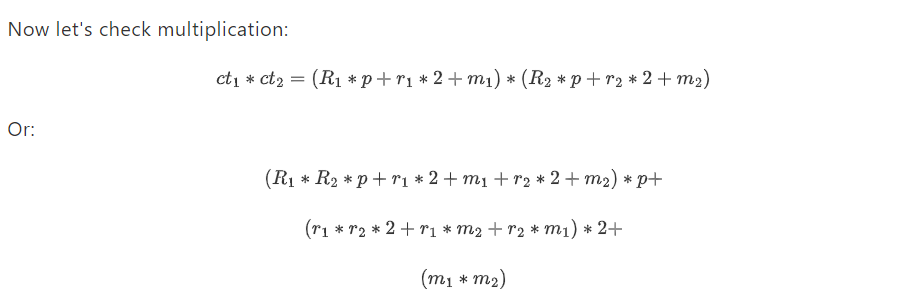
Это был просто вопрос расширения продукта, описанного выше, и группировки вместе всех терминов, содержащих p, затем всех оставшихся терминов, содержащих 2, и, наконец, оставшегося термина, который является произведением сообщений. Если расшифровать, то снова мод p удаляет первую группу, мод 2 удаляет вторую группу, и остается только m1∗m2.
Но здесь есть две проблемы: во-первых, увеличивается размер самого шифротекста (длина увеличивается примерно вдвое при умножении), а во-вторых, "шум" (также часто называемый "ошибкой") в меньшем \*2 члене также увеличивается в квадрате. Добавление этой ошибки в зашифрованные тексты было необходимо, поскольку безопасность этой схемы основана на приблизительной проблеме НОД:
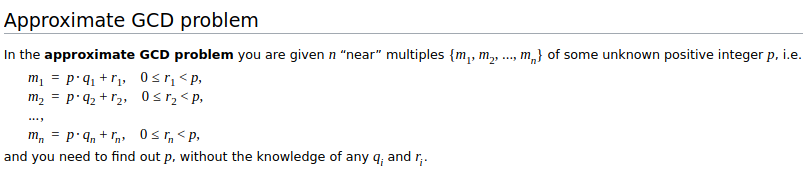
Если бы вместо этого мы использовали «точную задачу НОД», сломать систему было бы легко: если бы у вас был набор выражений вида p∗R1+m1, p∗R2+m2..., то вы могли бы использовать Алгоритм Евклида для эффективного вычисления наибольшего общего делителя p. Но если зашифрованные тексты представляют собой только приблизительные кратные p с некоторой "ошибкой", то быстрое извлечение p становится непрактичным, и поэтому схема может быть безопасной.
К сожалению, ошибка вводит неотъемлемое ограничение: если вы умножаете шифротексты друг на друга достаточное количество раз, ошибка в конечном итоге становится настолько большой, что превышает p, и в этот момент шаги по модулю p и по модулю 2 «мешают» друг другу, делая данные неизвлекаемые. Это будет неотъемлемым компромиссом всех этих гомоморфных схем шифрования: извлечение информации из приблизительных уравнений «с ошибками» намного сложнее, чем извлечение информации из точных уравнений, но любая ошибка, которую вы добавляете, быстро увеличивается по мере того, как вы выполняете вычисления с зашифрованными данными. ограничение объема вычислений, которые вы можете сделать, прежде чем ошибка станет подавляющей. И именно поэтому эти схемы лишь "несколько" гомоморфны.
Начальная загрузка
Есть два класса решения этой проблемы. Во-первых, во многих гомоморфных схемах шифрования есть хитрые приемы, позволяющие умножать ошибку только на постоянный коэффициент (например, в 1000 раз), а не возводить ее в квадрат. Увеличение ошибки в 1000 раз все еще звучит много, но имейте в виду, что если p (или его эквивалент в других схемах) является 300-значным числом, это означает, что вы можете умножать числа друг на друга 100 раз, что достаточно для вычислить очень широкий класс вычислений. Во-вторых, есть метод «самозагрузки» Крейга Джентри.
Предположим, что у вас есть зашифрованный текст ct, представляющий собой шифрование некоторого m с ключом p, в котором много ошибок. Идея состоит в том, что мы «обновляем» зашифрованный текст, превращая его в новый зашифрованный текст m с другим ключом p2, где этот процесс «удаляет» старую ошибку (хотя он вносит фиксированное количество новых ошибок). Трюк довольно хитрый. Владелец p и p2 предоставляет "начальный ключ", который состоит из шифрования битов p под ключом p2, а также открытого ключа для p2. Тот, кто выполняет вычисления с данными, зашифрованными с помощью p, затем возьмет биты зашифрованного текста ct и зашифрует эти биты по отдельности с помощью p2. Затем они будут гомоморфно вычислять расшифровку при p, используя эти зашифрованные тексты, и получать один бит, который будет m зашифрован при p2.
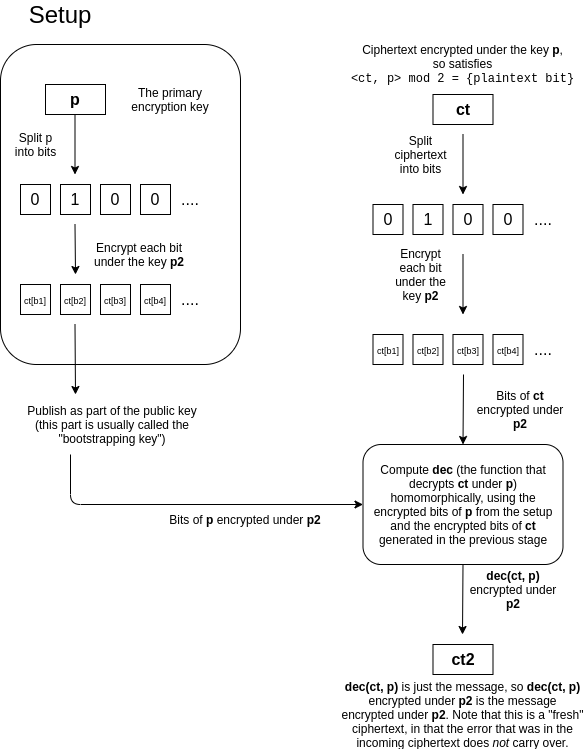
Это трудно понять, поэтому мы можем переформулировать это следующим образом. Процедура дешифрования dec(ct,p) сама по себе является вычислением, поэтому ее может быть реализовано в виде схемы , которая принимает на вход биты ct и биты p и выводит расшифрованный бит m∈0 ,1. Если у кого-то есть зашифрованный текст ct, зашифрованный с помощью p, открытый ключ для p2, и биты p, зашифрованные с помощью p2, то они могут вычислить dec(ct,p)=m "гомоморфно" и получить m зашифрованным с помощью p2. . Обратите внимание, что сама процедура расшифровки смывает старую ошибку; он просто выводит 0 или 1. Процедура расшифровки сама по себе представляет собой схему, которая содержит сложения или умножения, поэтому она приведет к новой ошибке, но эта новая ошибка не зависит от количества ошибок в исходном шифровании.
(Обратите внимание, что мы можем избежать отдельного нового ключа p2 (и, если вы хотите выполнить загрузку несколько раз, также p3, p4...), просто установив p2=p. Однако это вводит новое предположение, обычно называемое "циклическим безопасность"; становится сложнее формально доказать безопасность, если вы это сделаете, хотя многие криптографы думаю, что это нормально, и циклическая безопасность не представляет значительного риска на практике).
Но.... есть загвоздка. В описанной выше схеме (используя циклическую защиту или нет) ошибка вылетает так быстро, что даже схема расшифровки самой схемы оказывается для нее непосильной. То есть новый m, зашифрованный с помощью p2, уже имеет столько ошибок, что его невозможно прочитать. Это связано с тем, что каждый логический элемент И удваивает длину ошибки в битах, поэтому схема, использующая d-битный модуль p, может обрабатывать только меньшее, чем log(d) умножение (последовательно), но дешифрование требует вычисления mod p в схеме, выполненной из этих бинарных логических вентилей, что требует... больше, чем log(d) умножений.
Крейг Джентри придумал хитрые методы, чтобы обойти эту проблему, но они, возможно, слишком сложны, чтобы их можно было объяснить; вместо этого мы сразу перейдем к более новым работам 2011 и 2013 годов, которые решают эту проблему по-другому.
Обучение с ошибками
Чтобы двигаться дальше, мы представим другой тип несколько гомоморфного шифрования, представленный Бракерски и Вайкунтанатаном в 2011 году, и покажем, как его запустить. Здесь мы отойдем от того, чтобы ключи и зашифрованные тексты были целыми, и вместо этого сделали ключи и зашифрованные тексты векторами. Учитывая ключ k=k1,k2....kn, для шифрования сообщения m постройте вектор c=c1,c2...cn такой, что скалярный продукт (или "точечный продукт")

В этом примере мы установили модуль p=103. Скалярное произведение равно 3 * 2 + 14 * 71 + 15 * 82 + 92 * 81 + 65 * 8 = 10 202, а 10 202 = 99 * 103+5. 5 само по себе, конечно, 2∗2+1, поэтому сообщение равно 1. Обратите внимание, что на практике первый элемент ключа часто устанавливается равным 1; это упрощает создание зашифрованных текстов для определенного значения (посмотрите, сможете ли вы понять, почему).
Безопасность схемы основана на допущении, известном как «обучение с ошибками» (LWE) — или, выражаясь более жаргонно, но и более понятно, сложность решения систем уравнений с ошибками.

Сам шифротекст можно рассматривать как уравнение: k1c1+....+kncn≈0, где ключ k1...kn – это неизвестные, шифротекст c1...cn – это коэффициенты, а равенство является приблизительным, поскольку как сообщения (0 или 1), так и ошибки (2e для некоторого относительно небольшого e). Предположение LWE гарантирует, что даже если у вас есть доступ ко многим из этих зашифрованных текстов, вы не сможете восстановить k.
Обратите внимание, что в некоторых описаниях LWE
Умножение зашифрованных текстов
Легко проверить, что шифрование является аддитивным: если
млрд. Мы можем «умножать зашифрованные тексты», используя удобное математическое тождество
Имея два зашифрованных текста c1 и c2, мы вычисляем внешнее произведение c1⊗c2. Если и c1, и c2 были зашифрованы ключом k, то
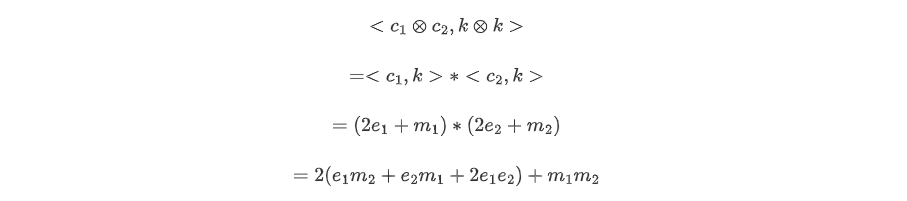
Так что этот подход внешнего продукта работает. Но есть, как вы, наверное, уже заметили, одна загвоздка: размер зашифрованного текста и ключа растет квадратично.
Релинеаризация
Мы решаем это с помощью релинеаризации процедуры. Владелец закрытого ключа k предоставляет в составе открытого ключа «ключ повторной линеаризации», который можно рассматривать как «зашумленное» шифрование k⊗k при k. Идея состоит в том, что мы предоставляем эти зашифрованные части k⊗k всем, кто выполняет вычисления, позволяя им вычислить уравнение
Важно понимать, что мы подразумеваем под «зашумленным шифрованием». Обычно эта схема шифрования позволяет зашифровать только m∈{0,1}, а «шифрование m» — это вектор c, такой что
Ключ релинеаризации состоит из набора векторов, которые при скалярном произведении (по модулю p) с ключом k дают значения вида ki∗kj∗2d+2e (mod p), один такой вектор для каждой возможной тройки (i ,j,d), где i и j — индексы в ключе, а d — показатель степени, где 2d<p (примечание: если ключ имеет длину n, в ключе релинеаризации будет n2∗log(p) значений; убедитесь, что вы понимаете, почему, прежде чем продолжить).

Теперь давайте сделаем шаг назад и снова посмотрим на нашу цель. У нас есть зашифрованный текст, который при расшифровке с помощью k⊗k дает m1∗m2. Нам нужен зашифрованный текст, который при расшифровке с помощью k дает m1*m2. Мы можем сделать это с помощью ключа релинеаризации. Обратите внимание, что уравнение расшифровки
А что у нас есть в нашем ключе релинеаризации? Набор элементов вида 2d∗kp∗kq, зашифрованных с помощью k, для каждой возможной комбинации p и q! Наличие всех степеней двойки в нашем ключе релинеаризации позволяет нам сгенерировать любое (ct1i∗ct2j)∗kp∗kq, просто сложив ≤log(p) степени двойки (например, 13 = 8 + 4 + 1) вместе для каждого (p,q) пара.
Например, если ct1=[1,2] и ct2=[3,4], то ct1⊗ct2=[3,4,6,8] и enc(
enc(k1∗k1)+enc(k1∗k1∗2)+enc(k1∗k2∗4)+
enc(k2∗k1∗2)+enc(k2∗k1∗4)+enc(k2∗k2∗8)
Обратите внимание, что каждое зашумленное шифрование в ключе релинеаризации имеет некоторую четную ошибку 2e, а само уравнение
Более широкий метод, который мы использовали здесь, является обычным трюком в гомоморфном шифровании: предоставить части ключа, зашифрованные с помощью самого ключа (или другого ключа, если вы педантично избегаете круговых допущений безопасности), чтобы кто-то, вычисляющий данные, мог вычислить уравнение расшифровки, но только таким образом, чтобы сам вывод все еще был зашифрован. Он использовался при начальной загрузке выше и используется здесь; лучше убедиться, что вы мысленно понимаете, что происходит в обоих случаях.
Этот новый зашифрованный текст содержит значительно больше ошибок: n2∗log(p) различных ошибок из частей ключа релинеаризации, которые мы использовали, плюс 2(2e1e2+e1m2+e2m1) из исходного зашифрованного текста внешнего произведения. Следовательно, новый зашифрованный текст по-прежнему имеет квадратично большую ошибку, чем исходные зашифрованные тексты, и, таким образом, мы все еще не решили проблему, заключающуюся в том, что ошибка проявляется слишком быстро. Чтобы решить эту проблему, мы переходим к другому трюку...
Переключение модуля
Здесь нам нужно понять важный алгебраический факт. Зашифрованный текст – это вектор ct, такой что
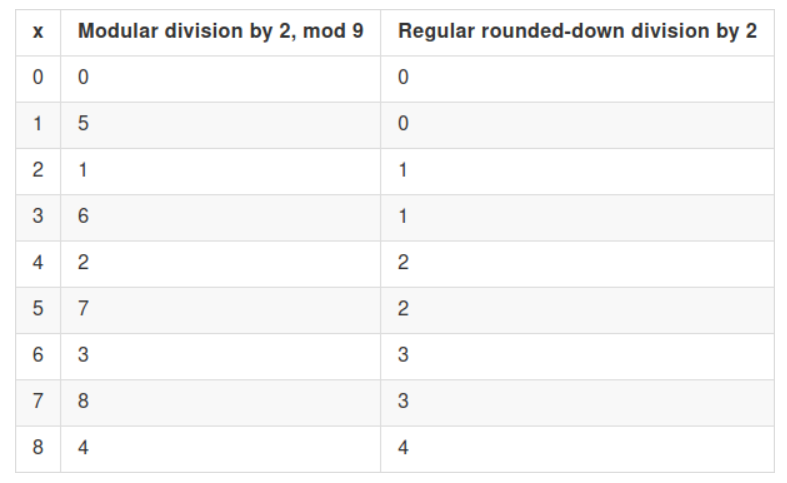
Схема в этом разделе использует как модульное деление (т. е. умножение на модульное мультипликативное обратное) и обычное целочисленное деление с округлением в меньшую сторону; убедитесь, что вы понимаете, как оба работают и чем они отличаются друг от друга.
То есть операция деления на 2 (по модулю p) преобразует небольшие четные числа в небольшие числа, а 1 – в p2 (с округлением вверх). Поэтому, если мы посмотрим на ct2 (по модулю p) вместо ct, расшифровка включает в себя вычисление
Вот что мы можем сделать с зашифрованным текстом.
- Начало:
- Разделите ct на 2 (по модулю p):
- Умножьте ct′ на qp используя "обычное целочисленное деление с округлением вниз":
- Умножьте ct″ на 2 (по модулю q):
Шаг 3 является решающим: он преобразует зашифрованный текст по модулю p в зашифрованный текст по модулю q. Процесс просто включает «уменьшение» каждого элемента ct’ путем умножения на qp и округления в меньшую сторону, например. этаж(56∗15103)=этаж(8.15533..)=8.
Идея такова: если
Чего мы достигли? Мы превратили зашифрованный текст с модулем p и ошибкой 2e в зашифрованный текст с модулем q и ошибкой 2(floor(e(p/q))+e2), где новая ошибка меньше* исходной ошибки.
Давайте рассмотрим вышесказанное на примере. Предполагать:
- ct – это всего лишь одно значение, [5612]
- к=[9]
- p = 9999 и q = 113
Шаг 2: ct'=ct2=2806 (помните, что это модульное деление; если бы ct было вместо 5613, мы бы получили ct2=7806). Проверка:
Шаг 3: ct″=этаж(2806∗1139999)=этаж(31,7109...)=31. Проверка:
Шаг 4: ct‴=31∗2=62. Проверка:
Таким образом, бит 1 сохраняется при преобразовании. Самое безумное в этой процедуре то, что ни для чего не требуется знать k. Теперь проницательный читатель может заметить: вы уменьшили абсолютный размер ошибки (с 256 до 2), но относительный размер ошибки остался неизменным и даже немного увеличился: 256/9999≈2,5%, но 4113 ≈3,5%. Учитывая, что именно относительная ошибка приводит к взлому зашифрованных текстов, что мы здесь получили?
Ответ исходит из того, что происходит с ошибкой, когда вы умножаете зашифрованные тексты. Предположим, что мы начинаем с зашифрованного текста x с ошибкой 100 и модулем p = 1016−1. Мы хотим многократно возводить x в квадрат, чтобы вычислить (((x^2)^2)^2)^2=x16. Во-первых, "обычный способ":
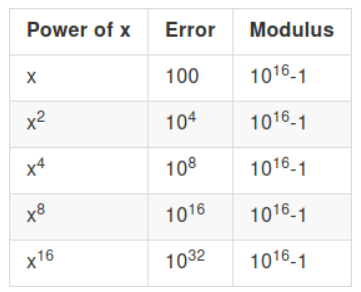
Ошибка возникает слишком быстро, чтобы вычисление стало возможным. Теперь давайте уменьшать модуль после каждого умножения. Мы предполагаем, что уменьшение модуля несовершенно и увеличивает ошибку в 10 раз, поэтому уменьшение по модулю в 1000 раз уменьшает ошибку только с 10000 до 100 (а не до 10):
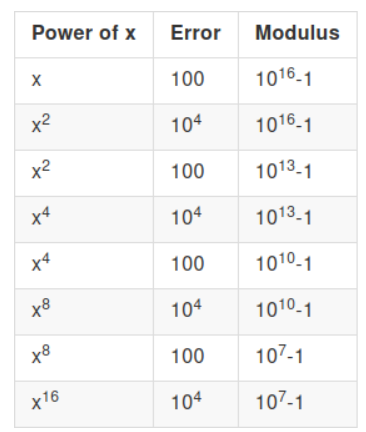 Ключевая математическая идея здесь заключается в том, что коэффициент , на который увеличивается ошибка при умножении, зависит от абсолютного размера ошибки, а не его относительный размер, и поэтому, если мы продолжаем уменьшать модуль, чтобы ошибка оставалась маленькой, каждое умножение увеличивает ошибку только на постоянный коэффициент. Итак, с d-битным модулем (и, следовательно, ≈2d-местом для «ошибки»), мы можем делать O(d) умножений! Этого достаточно для начальной загрузки.
Ключевая математическая идея здесь заключается в том, что коэффициент , на который увеличивается ошибка при умножении, зависит от абсолютного размера ошибки, а не его относительный размер, и поэтому, если мы продолжаем уменьшать модуль, чтобы ошибка оставалась маленькой, каждое умножение увеличивает ошибку только на постоянный коэффициент. Итак, с d-битным модулем (и, следовательно, ≈2d-местом для «ошибки»), мы можем делать O(d) умножений! Этого достаточно для начальной загрузки.
Другой метод: матрицы
Другой метод (см. Gentry, Sahai, Waters (2013)) для полностью гомоморфного шифрования включает матрицы: вместо представления зашифрованного текста в виде ct, где
Тот факт, что сложение работает, прост: если k∗CT1=m1∗k+e1 и k∗CT2=m2∗k+e2, то k∗(CT1+CT2)=(m1+m2)∗k+(e1+e2) . Тот факт, что умножение работает, также прост:
kCT1CT2 =(m1k+e1)CT2 =m1kCT2+e1CT2 =m1m2k+m1e2+e1*CT2
Первый срок является «предполагаемым сроком»; последние два термина являются «ошибкой». Тем не менее, обратите внимание, что здесь ошибка действительно увеличивается квадратично (см. член e1∗CT2 ; размер ошибки увеличивается на размер каждого элемента зашифрованного текста, а элементы зашифрованного текста также имеют квадратный размер), и вам нужны некоторые хитрые приемы. чтобы избежать этого. По сути, это включает в себя преобразование зашифрованных текстов в матрицы, содержащие составляющие их биты, перед умножением, чтобы избежать умножения на что-либо большее, чем 1; если вы хотите подробно посмотреть, как это работает, я рекомендую посмотреть мой код: https://github.com/vbuterin/research/blob/master/matrix_fhe/matrix_fhe.py#L121
Кроме того, приведенный там код, а также https://github.com/vbuterin/research/blob/master/tensor_fhe/homomorphic_encryption.py#L186 содержит простые примеры полезных схем, которые можно построить из этих бинарных логических операции; основной пример — сложение чисел, представленных в виде нескольких битов, но можно также создавать схемы для сравнения (<, >, =), умножения, деления и многих других операций.
С 2012-13 года, когда были созданы эти алгоритмы, было сделано много оптимизаций, но все они работают поверх этих базовых фреймворков. Часто вместо целых чисел используются многочлены; это называется кольцо LWE. Главной проблемой по-прежнему является эффективность: операция, включающая один бит, включает в себя умножение целых матриц или выполнение всего вычисления релинеаризации, что требует очень больших накладных расходов. Существуют приемы, которые позволяют выполнять множество битовых операций в одной операции зашифрованного текста, и над этим активно работают и улучшают.
Мы быстро приближаемся к моменту, когда многие приложения гомоморфного шифрования в вычислениях, сохраняющих конфиденциальность, начинают становиться практичными. Кроме того, быстро развиваются исследования более продвинутых приложений криптографии на основе решетки, используемой в гомоморфном шифровании. Так что это пространство, где некоторые вещи можно сделать уже сегодня, но мы надеемся, что в следующем десятилетии станет возможным гораздо больше.
- Первоначально опубликовано как «[Изучение полностью гомоморфного шифрования] (https://vitalik.ca/general/2020/07/20/homomorphic.html)»*