

Как настроить чат-бот OpenAI с помощью встраивания
4 марта 2023 г.За последние две недели мы создали чат-бота с помощью React, Node.js и OpenAI. Задавая общий вопрос, например Какая типичная погода в Дубае?, чат-бот дает очень релевантный ответ.
Если мы спросим нашего чат-бота о чем-то очень конкретном (т. е. о чем-то, что требует некоторого начального контекста или знаний), например Кто такой Хассан Джирде?, наш чат-бот либо ответит, что не знает, либо ответит полным неверный ответ.
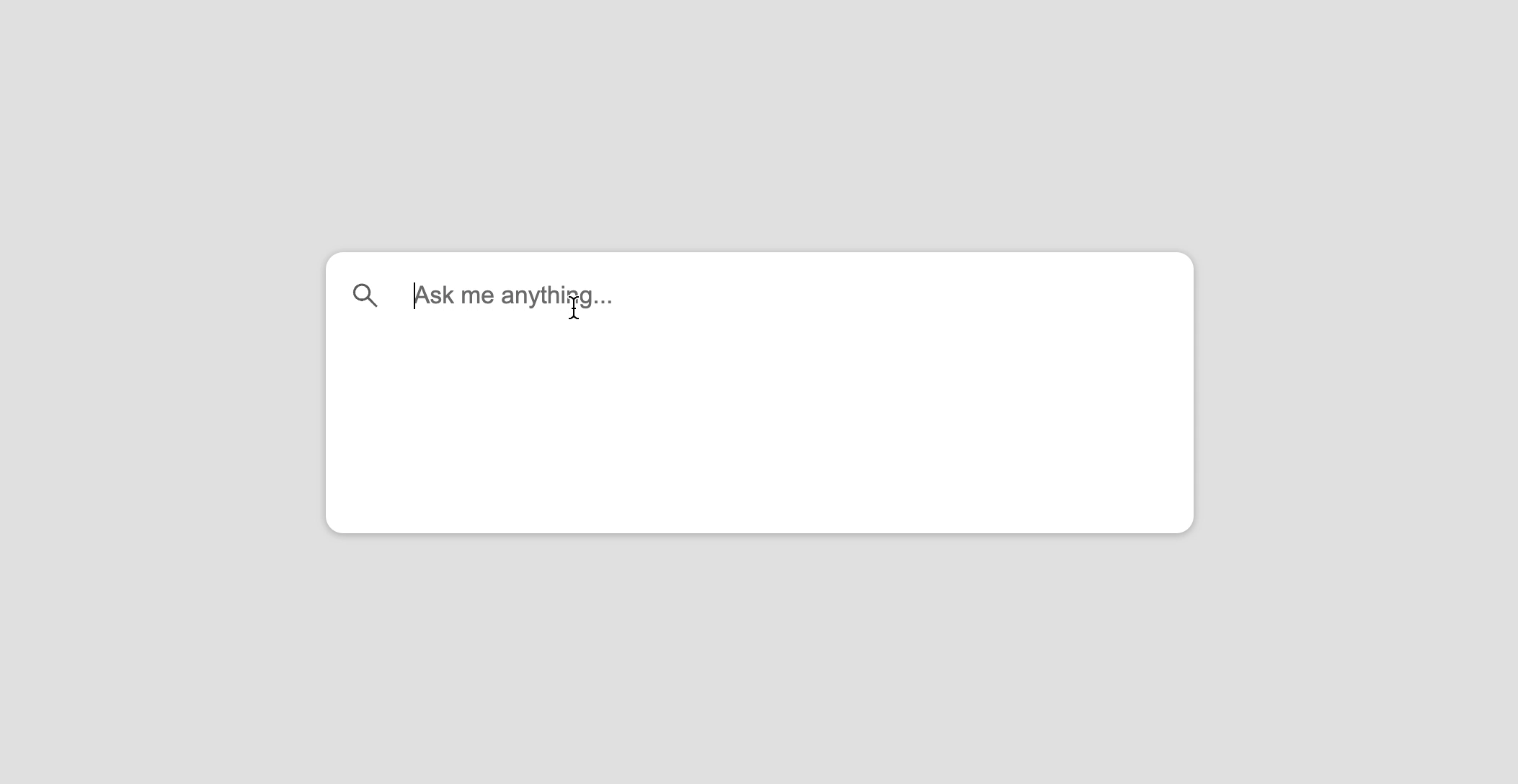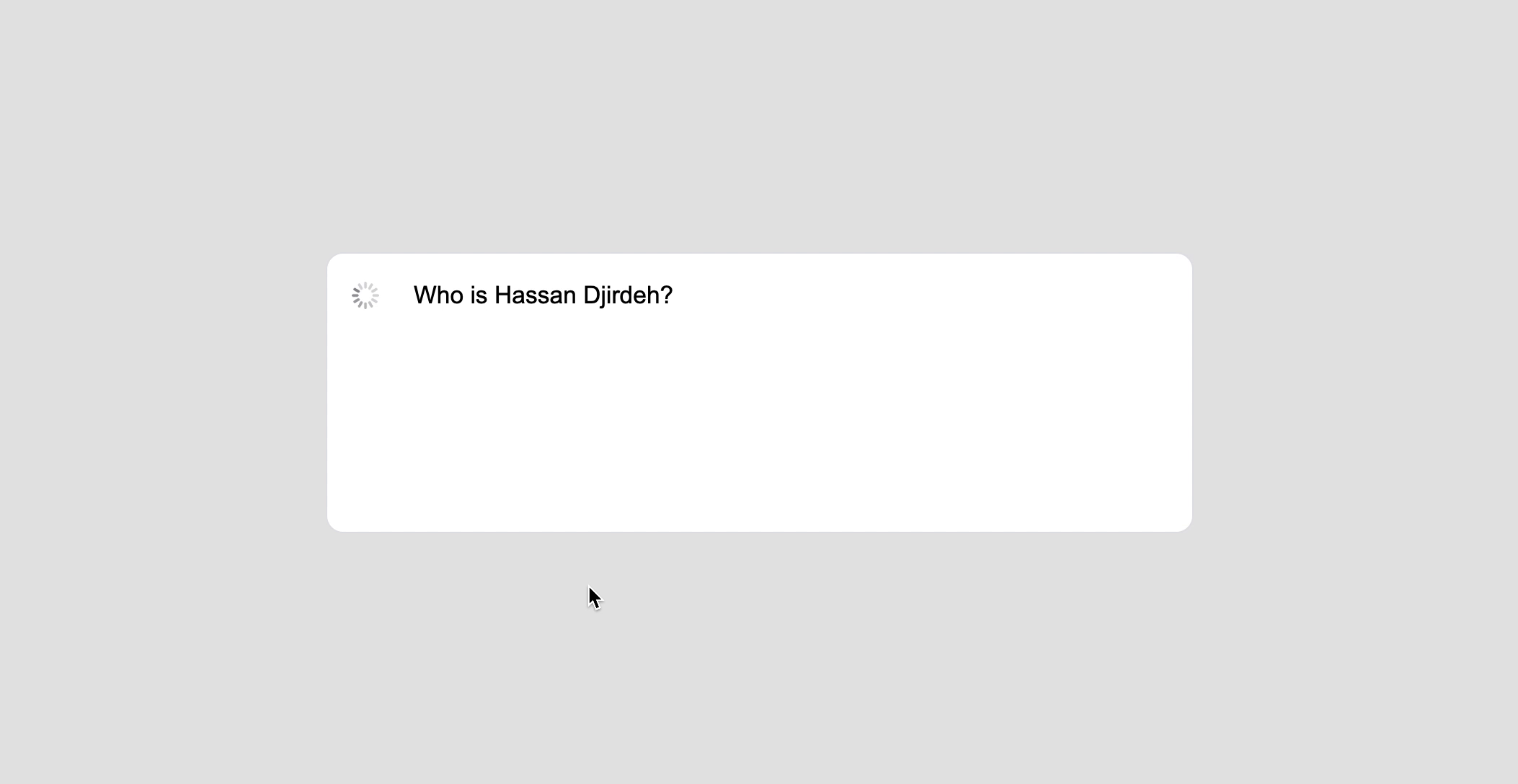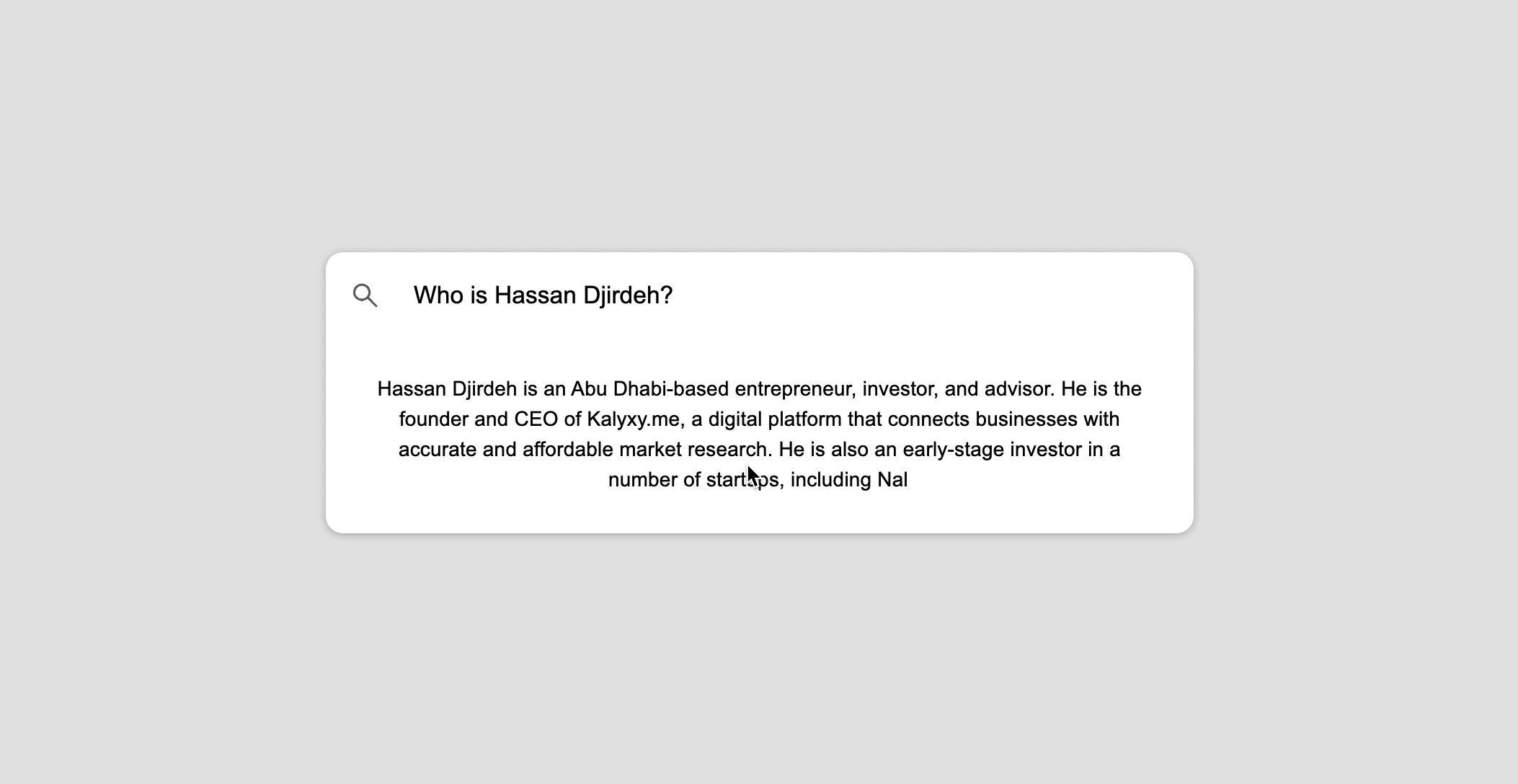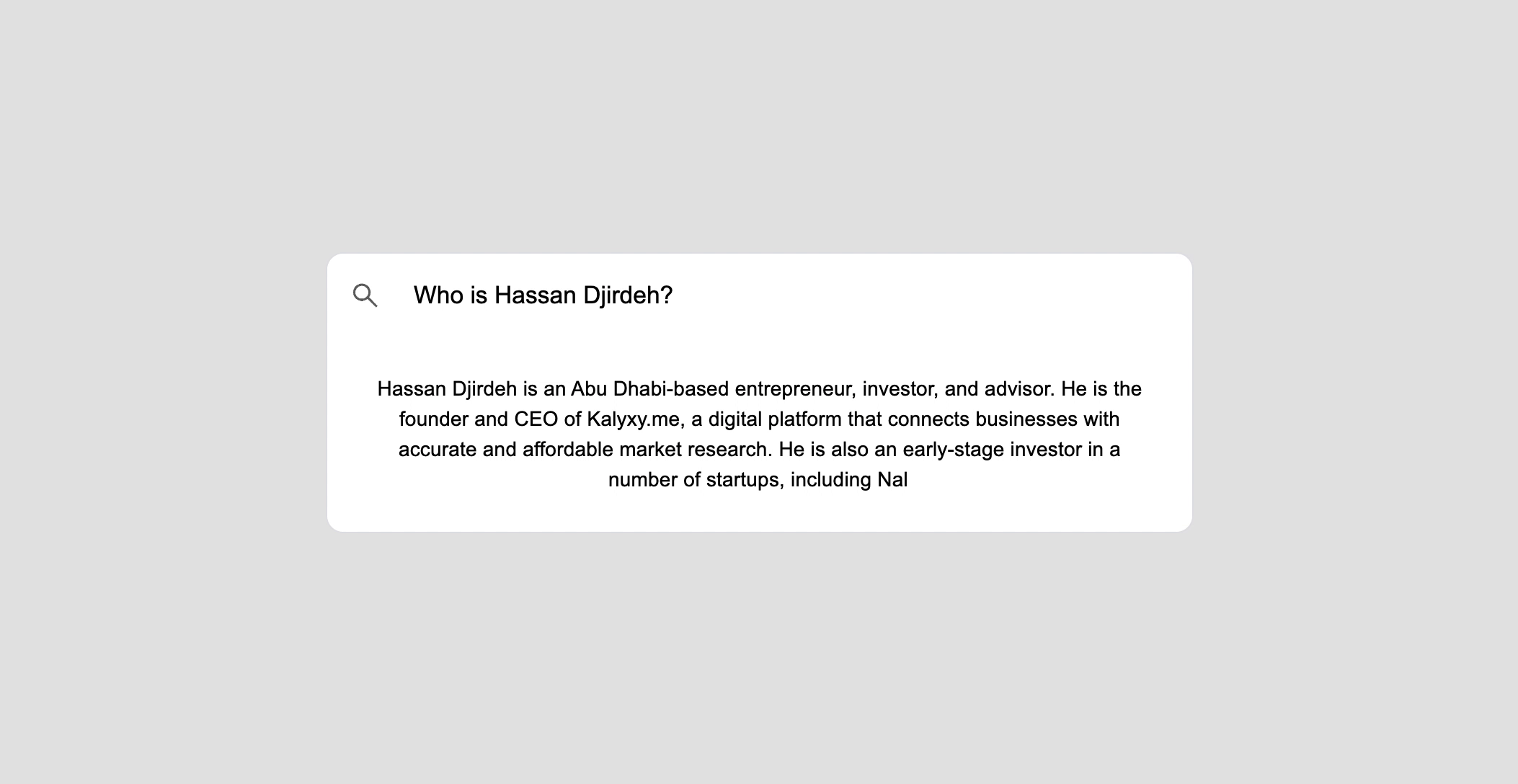
Хотя это было бы действительно здорово — я не предприниматель, инвестор или консультант из Абу-Даби. Мы видим указанную выше проблему, поскольку используемые нами языковые модели OpenAI не имеют доступа к Интернету и не выполняют веб-поиск в режиме реального времени. Вместо этого модели получают информацию из большого набора текстовых данных, на которых они обучаются.
В сегодняшней статье мы рассмотрим некоторые способы того, как наш чат-бот правильно отвечает на заданные контекстуальные вопросы.
Примечание: эта статья является всего лишь псевдоучебником. Мы не будем пошагово раскрывать эту возможность, как в предыдущих двух статьях, а вместо этого объясним общий подход. В конце мы поделимся ссылкой на пример работающего кода, чтобы вы могли опробовать полную реализацию, если вам это интересно.
Точная настройка
Есть две возможности, которые OpenAI позволяет нам использовать для создания пользовательского интерфейса чат-бота.
* Точная настройка * Быстрый инжиниринг и усилитель; Встраивания
Точная настройка может помочь получить более качественные результаты OpenAI за счет предварительной подготовки с большим объемом информации. Шаги для этого включают:
* Подготовка и загрузка исходных данных обучения. * Обучение новой модели. * Использование новой обученной модели в наших запросах API.
OpenAI рекомендует иметь в тщательно обученном наборе данных не менее пары сотен примеров. Мы не будем использовать этот подход, а вместо этого выберем более рекомендуемый подход для нашего варианта использования — использование встраивания.
Оперативное проектирование & Вложения
Прежде чем обсуждать, что такое встраивание, полезно сначала понять концепцию Prompt Engineering при взаимодействии с OpenAI. Этот очень полезный документ в кулинарной книге OpenAI содержит более подробные сведения, но мы подведем итоги. ниже.
Как мы видели, при задании OpenAI вопроса, требующего определенного контекста:
Who is Hassan Djirdeh?
Он может либо галлюцинировать ответ, либо сказать нам «я не знаю».

Чтобы помочь OpenAI ответить на вопрос, мы можем предоставить дополнительную контекстную информацию в самой подсказке.
Hassan Djirdeh is a front-end engineer based in Toronto, Canada. He is currently working on producing a newsletter called Frontend Fresh where he shares tips, tutorials, and articles on a weekly basis.
Who is Hassan Djirdeh?

На этот раз мы получаем полезный ответ от OpenAI, потому что наше приглашение содержит соответствующую информацию для заданного вопроса.
Как мы можем использовать эту возможность, чтобы помочь нам создать более индивидуальный чат-бот? Мы можем сделать это с помощью концепции, известной как встраивание.
Встраивания
OpenAI предоставляет возможность, известную как текстовые встраивания, для измерения связанности текста. строки.
Для каждого блока текста, главы или темы мы можем отправить эту информацию в службу встраивания OpenAI, чтобы получить обратно данные встраивания (то есть векторный список чисел с плавающей запятой).
Запрос
curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{"input": "Hassan Djirdeh is a software engineer...",
"model":"text-embedding-ada-002"}'
Ответ
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
// ...
}
Когда у нас есть данные для встраивания различных рекламных роликов контекстной информации, которые мы хотим, чтобы наш чат-бот знал, нам нужно их где-то сохранить. Обратите внимание, что это одноразовая процедура: мы получаем данные о встраивании текстовых аннотаций один раз и обновляем их только в случае изменения контекстной информации.
Вот пример хранения этой информации в базе Airtable (которую вы можете увидеть здесь).

Затем, когда пользователь вводит подсказку, мы получаем данные о внедрении этой конкретной подсказки. Затем мы можем использовать простую проверку косинусного сходства между внедренными данными подсказки, которая была запрошена, с внедренными данными информации хранятся в нашей базе данных.
Давайте разберем это на простом для понимания примере. Предположим, что в нашей таблице сохраненных данных у нас есть встроенные данные для 4 различных наборов информации.
| Текстовая реклама | Данные о вложениях | |----|----| | Создан информационный бюллетень Frontend Fresh... | [0.000742552,-0.0049907574, ...] | | Будучи частью информационного бюллетеня, читатели... | [-0.027452856,-0.0023051118, ...] | | В первых четырех-пяти письмах... | [-0.007873567,-0.014787777, ...] | | Хассан Джирдех — инженер-конструктор... | [-0.008849341,0.011449747, ...] |
3 блока текста выше содержат информацию о бюллетене, а 1 блок текста содержит информацию об авторе бюллетеня.
Когда пользователь делает запрос "Кто такой Хассан Джирде", мы получаем данные о внедрении для этого конкретного запроса.
| Подскажите | Данные о вложениях | |----|----| | Кто такой Хасан Джирде? | [-0.009949322,0.044449654, ...] |
Затем мы вычисляем косинусное сходство для данных встраивания в нашей базе данных с данными встраивания подсказки. Это дает нам число от 0 до 1 для каждого сравнения.
| Текстовая реклама | Косинусное сходство с подсказкой | |----|----| | Создан информационный бюллетень Frontend Fresh... | 0,5 | | Будучи частью информационного бюллетеня, читатели... | 0,4 | | В первых четырех-пяти письмах... | 0,6 | | Хассан Джирдех — инженер-конструктор... | 0,9 |
Данные о внедрении с наивысшей оценкой косинуса — это текст, который наиболее похож на то, что задает пользователь. Затем мы берем эту текстовую аннотацию и встраиваем ее в «супер» подсказку, которую отправляем в OpenAI.
const initial Prompt = "Who is Hassan Djirdeh?"
/* after some work, we determine the following contextual information to be closest in similarity to the prompt question above. */
const textWithHighestScore = "Hassan Djirdeh is a front-end engineer..."
// build final prompt
const finalPrompt = `
Info: ${textWithHighestScore}
Question: ${prompt}
Answer:
`;
// ask Open AI to answer the prompt
const response = await openai.createCompletion({
model: "text-davinci-003",
prompt: finalPrompt,
max_tokens: 64,
});
Теперь, когда мы задаем нашему чат-боту вопрос, требующий некоторого контекста, окончательное приглашение создается за кулисами перед отправкой в OpenAI. В итоге мы получаем более релевантный ответ!

Вот и все! Это простое введение в то, как мы можем использовать быструю разработку и встраивание, чтобы сделать чат-бот более уникальным с помощью OpenAI.
Для получения дополнительной информации о тонкой настройке и встраивании обязательно ознакомьтесь с подробной документацией по OpenAI.
Заключительные мысли
- Вы можете найти исходный код для обновления сервера Node/Express нашего чат-бота с оперативной разработкой и внедрением здесь.
- Одним большим преимуществом хранения данных о встраиваниях в отдельной базе данных электронных таблиц по сравнению с нашим приложением является то, что мы можем вносить изменения в базу данных электронных таблиц в режиме реального времени без простоя приложения.
- Подпишитесь на https://www.frontendfresh.com/, чтобы получать больше подобных руководств, которые помогут вам почту еженедельно!
✨ Эта статья является третьей статьей, отправленной на frontendfresh.com информационный бюллетень. Подпишитесь на информационный бюллетень Front-end Fresh, чтобы каждую неделю получать советы, учебные пособия и проекты по фронтенд-инженерии на ваш почтовый ящик!
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27409)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)