Раньше для реалистичного редактирования изображений, например изменения прически или черт лица, требовались профессиональные навыки редактирования фотографий. Но с помощью моделей искусственного интеллекта, таких как диффузионные автоэнкодеры (DiffAE), любой может легко изменять портреты с помощью всего лишь нескольких строк кода.
В этом посте мы узнаем, как использовать DiffAE для редактирования портретов, добавляя или удаляя различные атрибуты, такие как волосы, растительность на лице, макияж и многое другое. Независимо от того, являетесь ли вы фотографом, желающим упростить редактирование, или дизайнером, желающим создавать прототипы идей, эта модель упрощает получение творческих результатов.
Мы рассмотрим реальные примеры использования DiffAE, объясним, как работает модель, и предоставим пример кода, который поможет вам начать работу. Мы также увидим, как можно использовать AIModels.fyi, чтобы найти похожие модели и решить, какая из них нам нравится. Начнем.
Реальные примеры использования
Вот лишь несколько примеров того, как DiffAE можно использовать для редактирования портретов:
* Фотографы могут легко удалить дефекты или заставить объекты выглядеть моложе или старше. * Модельеры могут создавать прототипы одежды и аксессуаров на фотографиях моделей. * Художники по макияжу могут продемонстрировать клиентам такие возможности, как новые прически. * Влиятельные лица в социальных сетях могут быстро создавать варианты своих селфи.
Редактирование на основе искусственного интеллекта открывает новые творческие возможности для самых разных художников и авторов. Приложения, созданные с помощью DiffAE, могут позволить обычным пользователям развлекаться, изменяя селфи и изображения профиля.
Примеры
Вот лишь несколько примеров того, что модель может сделать с реальными изображениями реальных людей! Некоторые из этих изменений — превращение пожилых людей в молодых, заставление грустных людей улыбаться или добавление или снятие аксессуаров, таких как очки, — выглядят очень реалистично!

О модели DiffAE
DiffAE – это модель преобразования изображений в изображения, реализованная и поддерживаемая компанией cjwbw и размещенная на Replica. Он использует технику под названием модели диффузии для управления изображениями. Он размещен на реплике, среднее время выполнения составляет 43 секунды, а стоимость одного запуска — 0,02365 доллара США. В качестве аппаратного обеспечения используется графический процессор Nvidia T4. Более подробную техническую информацию и спецификации API можно найти на странице сведений.
Модель использует входную фотографию и дополнительные параметры, такие как «добавить челку» или «сделать лысину». Он выводит модифицированную версию исходного изображения с запрошенными изменениями. Процесс распространения позволяет получать реалистичные и высококачественные результаты.
Под капотом DiffAE использует архитектуру автоэнкодера. Часть кодера учится представлять ключевые особенности изображения, такие как волосы и формы лица. Затем декодер преобразует эти функции, сохраняя при этом общий реализм. Это позволяет плавно вносить изменения.
Как работает модель DiffAE?
Позвольте мне сначала дать вам техническое объяснение, а затем объяснить, как работает модель, простым языком.
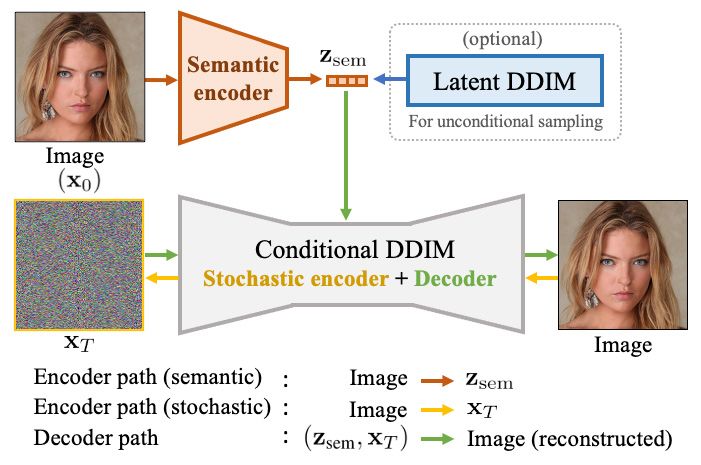
Сначала техническое объяснение! Диффузионный автокодировщик состоит из двух основных частей: семантического кодировщика и условной неявной модели шумоподавления (DDIM).
- Семантический кодировщик: он принимает входное изображение и преобразует его в так называемый семантический субкод. Этот субкод инкапсулирует высокоуровневые абстрактные функции изображения.
- Условный DDIM. Эта часть выполняет две роли. Будучи стохастическим кодировщиком, он берет исходное изображение и преобразует его в другую форму, которая фиксирует мелкие случайные изменения. В качестве декодера он использует как семантический субкод, так и эту детальную форму для восстановления исходного изображения.
- Семантический кодировщик. Сначала этот ученик смотрит на картину и понимает ее глубокий смысл — настроение, темы, эмоции. Это похоже на часть «семантического кодировщика», которая понимает высокоуровневые абстрактные особенности изображения.
- Условный DDIM. Затем учащийся обращает внимание на мазки кисти, изменения цвета и мелкие детали. Это похоже на «стохастический кодировщик», который фиксирует мелкие случайные детали изображения. Наконец, ученик может затем воссоздать картину, объединив то, что он понял о ее более глубоком значении, и мелких деталях, действуя как «декодер».
- Ограничено портретами. Модель специализируется на портретных изображениях и может не работать с другими типами.
- Затраты на вычисления. Для запуска модели требуется в среднем 43 секунды, что может быть не идеальным для приложений реального времени.
- Артефакты при высокой амплитуде. Если амплитуда манипуляции установлена слишком высокой, это может привести к появлению артефактов.
- Цена за запуск: 0,02365 доллара США за запуск. Для массовых операций это может быть дорого.
- Описание: это ваше сырье. Предоставьте файл изображения лица, которым вы хотите манипулировать. Модель заботится о выравнивании и обрезке.
- Использование: просто загрузите изображение, которое хотите изменить.
- Описание. Здесь вы можете выбрать вектор манипуляции. Хотите тени 5_o_Clock_Shadow или густые брови? Вам решать.
- Использование. Укажите одно из разрешенных значений, например «Большой_нос», «Улыбающийся» и т. д.
- По умолчанию: «Чёлка».
- Описание. Рассматривайте это как контроль интенсивности. Слишком высокий уровень может привести к артефактам или неестественным результатам.
- Применение. Введите числовое значение. Более высокие значения соответствуют более сильным манипуляциям.
- По умолчанию: 0,3
- Описание. По сути, это количество кадров в секунду для генеративной модели. Больше шагов может означать более плавный переход.
- Использование. Выберите одно из допустимых целочисленных значений, например 50, 100 и т. д.
- По умолчанию: 100
- Описание: параметр перечисления, точная функциональность которого здесь не указана.
- Применение: как и в случае с
T_step, выберите целое число из допустимых значений. - По умолчанию: 200
- Это предполагает, что вы можете получить несколько выходных элементов, каждый как объект.
- Каждый объект в массиве представляет собой один выходной результат модели.
- Просто идентификатор вашего вывода.
- ["изображение"]
- Указывает, что поле «изображение» всегда будет присутствовать.
- изображение:
- тип: "строка"
- Выходное изображение будет представлять собой не необработанные байты, а строку URI.
- Заголовок всей выходной схемы.
- Node.js установлен
- Репликация токена API
- Изображение для манипуляций (в нашем примере
young_face.jpg) версия: конкретная версия модели, которую вы используете.вход: фактические данные, которые вы отправляете на обработку. Вот строка изображения в формате Base64.webhook: URL-адрес для вызова после завершения прогнозирования.webhook_events_filter: список событий, которые запускают вебхук. Здесь мы используемcompleted, чтобы указать, что вебхук должен срабатывать, когда прогноз выполнен.- Убедитесь, что ваш токен API действителен.
- Убедитесь, что путь к файлу изображения и кодировка base64 верны.
- Если вебхук не срабатывает, проверьте URL-адрес и журналы вашего сервера.
- Оптимизация. Теперь, когда вы знаете основы, следующим шагом будет оптимизация рабочего процесса. Можно ли ускорить время выполнения? Можете ли вы выполнить пакетную обработку нескольких изображений, чтобы получить максимальную отдачу от инвестиций?
- Объединение моделей: используйте AIModels.fyi, чтобы изучить другие модели, которые можно интегрировать с DiffAE для получения еще более мощного изображения. манипуляции. Может быть, объединить его с моделью, улучшающей качество изображения или удаляющей фон?
- Создать приложение. Рассмотрите возможность создания приложения или его интеграции в существующее. Благодаря настройке API вполне возможно создать приложение, в которое пользователи смогут загружать фотографии и настраивать их на основе заранее заданных категорий, таких как «улыбается», «уставший» и т. д.
- Будьте в курсе. Если вы еще этого не сделали, рассмотрите возможность подписки на AIModels.fyi список рассылки. Мы предлагаем краткие дайджесты, экспертные рекомендации и сообщество энтузиастов искусственного интеллекта, которые помогут вам оставаться в авангарде.
- Понимание DiffAE: технический документ: этот документ Arxiv обеспечивает глубокое погружение в технические особенности и математические аспекты модели DiffAE.< /ли>
- Репликация реализации DiffAE: ознакомьтесь с этой практической реализацией DiffAE в Replication, дополненной примерами, которые помогут вам понять ее приложения.
- DiffAE на AIModels.fyi: это страница с подробными сведениями о DiffAE. , где вы найдете подробную информацию, такую как возможности, время работы и стоимость.
- Репозиторий DiffAE на GitHub: официальный репозиторий GitHub для DiffAE. Отлично, если вы хотите расширить проект или внести свой вклад.
- Исследуя мир AI Art: Путеводитель по StyleGAN и DALL-E: Notes исследует увлекательный мир искусства, созданного искусственным интеллектом, охватывая такие популярные модели, как StyleGAN и DALL-E.
- Руководство по StyleCLIP для начинающих: еще один фрагмент от AIModels.fyi Примечания, на этот раз основное внимание уделяется тому, как начать работу со StyleCLIP, моделью, которая использует как текст, так и изображения.
Семантический подкод отражает общие темы, а детальная форма — мельчайшие детали. Вместе они могут практически точно воссоздать исходное изображение.
Для создания новых выборок автоэнкодер использует скрытый DDIM, обученный распределению семантических субкодов. Во время выборки новые субкоды и более детальные формы генерируются из стандартного распределения Гаусса, а затем декодируются для создания нового изображения.
Имеет смысл? Если нет, давайте еще раз посмотрим на это простым языком:
Представьте себе диффузного автокодировщика как студента-художника, который отлично уловил суть и мельчайшие детали картины.
По сути, одна часть понимает, о чем изображение («большая картина»), а другая часть понимает, как оно создано («мельчайшие детали»). Объединив оба варианта, вы сможете воссоздать исходное изображение или очень близко совпадающие варианты.
Чтобы создать новое искусство, наш ученик должен был использовать свое понимание множества разных картин, чтобы создать новый шедевр, объединив новую идею общей картины с новыми мелкими деталями.

Ограничения DiffAE
Хотя DiffAE универсален и эффективен, у него есть ряд ограничений:
Входные и выходные данные модели
Вот описание входных свойств и выходной схемы модели ИИ, специализирующейся на манипулировании лицами. Это важная информация для всех, особенно для основателей и разработчиков, таких как вы, создающие продукты искусственного интеллекта, которым необходимо знать, с чем именно они работают.
Свойства ввода
файл изображения
target_class (строка)
manipulation_amplitude (число)
T_step (целое число)
T_inv (целое число)
Схема вывода
Результат предоставляется в формате JSON со следующей структурой:
{
"type": "array",
"items": {
"type": "object",
"title": "ModelOutput",
"required": [
"image"
],
"properties": {
"image": {
"type": "string",
"title": "Image",
"format": "uri"
}
}
},
"title": "Output"
}
Вот что означает каждый элемент:
тип: "массив"
предметы:
тип: «объект»
title: "ModelOutput"
обязательно:
свойства:
title: «Вывод»
Дополнительную информацию можно прочитать в спецификации API репликации Diffae здесь.
Пошаговое руководство: состаривание лица с помощью DiffAE
Хорошо, готовы запустить DiffAE и создать собственное приложение для изменения лица? Вы попали в нужную часть руководства!
В этом примере мы создадим базовый сценарий, который можно будет использовать в продукте, который будет искусственно старить людей, чтобы показать им, как они будут выглядеть, когда станут старше. Это популярная функция в приложениях, таких как Snapchat.
Фильтры устаревания популярны в таких приложениях, как Snapchat. Мы создадим такой, который превратит входное изображение в изображение гораздо пожилого человека.
Вот пошаговое руководство с фрагментами кода, которое поможет вам это осуществить. В этом примере для управления всей операцией используется Node.js и API репликации.
Предварительные требования:
Шаг 1. Установите копию пакета
Прежде всего, вам необходимо установить пакет Replication для Node.js.
npm install replicate
Шаг 2. Аутентификация с помощью репликации
Получите свой токен API репликации и установите его как переменную среды:
export REPLICATE_API_TOKEN=<paste-your-token-here>
Шаг 3. Напишите сценарий Node.js
Создайте новый файл Node.js (make_old_with_webhook.js) и приступим к написанию кода. Мы будем использовать веб-перехватчики, поэтому включите также axios для HTTP-вызова веб-перехватчика.
npm install axios
import Replicate from 'replicate';
import axios from 'axios';
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const imageFilePath = './young_face.jpg';
const imageBase64 = fs.readFileSync(imageFilePath, { encoding: 'base64' });
// Using the `run` method to age the image
const output = await replicate.run(
'cjwbw/diffae:5d917b91659e117aa8b0c5d6213077e9132083e4a8a272f344cc52c3ba2f6e98',
{
input: {
image: imageBase64,
//add your other parameters here. Ex: target_class of Gray_Hair
},
}
);
// Using the `predictions.create` method with a webhook
const prediction = await replicate.predictions.create({
version: '5d917b91659e117aa8b0c5d6213077e9132083e4a8a272f344cc52c3ba2f6e98',
input: {
image: imageBase64,
},
webhook: 'https://example.com/your-webhook',
webhook_events_filter: ['completed'],
});
// Implement your webhook to receive the processed image asynchronously
// Assuming an Express.js setup:
app.post('/your-webhook', (req, res) => {
const processedData = req.body.data;
// Handle the processed data
res.status(200).send('Received');
});
Несколько переменных, на которые следует обратить внимание:
Шаг 4. Запустите скрипт
Выполните скрипт:
node make_old_with_webhook.js
Как только прогноз будет завершен, ваш URL-адрес веб-перехватчика будет активирован, и вы получите туда обработанное изображение.

Устранение неполадок
Возникли проблемы со сценарием? Проверьте следующее:
Заключение
Итак, мы глубоко углубились в DiffAE, поняв его возможности, технические характеристики и даже то, как запачкать руки кодом. Что дальше? В вашем распоряжении этот мощный инструмент и безграничные возможности.
Дальнейшие шаги
Благодаря этому вы хорошо подготовлены к тому, чтобы продвигаться вперед в творческую вселенную, которую открывает DiffAE. Так что идите и рубите!
Дополнительная литература
Приведенные ниже ресурсы могут помочь вам, если вы застряли или просто хотите узнать больше о DiffAE.
Также опубликовано здесь.