
Как создать приложение для потоковой передачи событий в .NET
14 февраля 2023 г.Когда вы останавливаетесь и думаете о повседневной жизни, вы можете легко рассматривать все как событие. Рассмотрим следующую последовательность:
- В вашем автомобиле загорается индикатор низкого уровня топлива
- В результате вы останавливаетесь на следующей заправочной станции, чтобы заправиться.
- Когда вы заправляете машину бензином, вам предлагается присоединиться к клубу вознаграждений компании, чтобы получить скидку.
- Вы заходите внутрь, регистрируетесь и получаете кредит на следующую покупку
Мы могли бы продолжать и продолжать здесь, но я высказал свое мнение: жизнь — это последовательность событий. Учитывая этот факт, как бы вы спроектировали новую программную систему сегодня? Будете ли вы собирать разные результаты и обрабатывать их с произвольным интервалом или ждать до конца дня, чтобы обработать их? Нет, ты бы не стал; вы хотели бы действовать по каждому событию, как только оно происходит. Конечно, могут быть случаи, когда вы не можете немедленно отреагировать на отдельные обстоятельства… подумайте о том, чтобы получить дамп дневных транзакций за один раз. Но тем не менее, вы будете действовать, как только получите данные, крупную сумму, если хотите.
Итак, как реализовать программную систему для работы с событиями? Ответ — потоковая обработка.
Что такое потоковая обработка?
Став де-факто технологией обработки данных о событиях, потоковая обработка представляет собой подход к разработке программного обеспечения, при котором события рассматриваются как основной ввод или вывод приложения. Например, нет смысла ждать, чтобы действовать в соответствии с информацией или реагировать на потенциальную мошенническую покупку кредитной карты. В других случаях это может включать обработку входящего потока записей в микрослужбе, и наиболее эффективная их обработка лучше всего подходит для вашего приложения.
Каким бы ни был вариант использования, можно с уверенностью сказать, что подход с потоковой передачей событий является лучшим подходом для обработки событий.
В этой записи блога мы создадим приложение для потоковой передачи событий с использованием Apache Kafka®, клиентов производителя и потребителя .NET, а также Библиотека параллельных задач (TPL) от Microsoft. На первый взгляд, вы не можете автоматически поставить все три из них вместе в качестве вероятных кандидатов для совместной работы. Конечно, Kafka и клиенты .NET — отличная пара, но какое место в этой картине занимает TPL?
Чаще всего пропускная способность является ключевым требованием, и чтобы избежать узких мест из-за несоответствия импеданса между потреблением из Kafka и последующей обработкой, мы обычно предлагаем внутрипроцессное распараллеливание при любой возможности.
Читайте дальше, чтобы узнать, как все три компонента работают вместе для создания надежного и эффективного приложения для потоковой передачи событий. Самое приятное то, что клиент Kafka и TPL берут на себя большую часть тяжелой работы; вам нужно сосредоточиться только на своей бизнес-логике.
Прежде чем мы углубимся в приложение, давайте дадим краткое описание каждого компонента.
Апач Кафка
Если обработка потоков является стандартом де-факто для обработки потоков событий, тогда Apache Kafka является стандартом де-факто для создания приложений потоковой передачи событий. Apache Kafka — это распределенный журнал, предоставляемый высокомасштабируемым, эластичным, отказоустойчивым и безопасным способом. В двух словах, Kafka использует брокеров (серверы) и клиентов. Брокеры образуют уровень распределенного хранилища кластера Kafka, который может охватывать центры обработки данных или облачные регионы. Клиенты предоставляют возможность считывать и записывать данные о событиях из кластера брокера. Кластеры Kafka отказоустойчивы: если какой-либо брокер выйдет из строя, другие брокеры возьмут на себя работу, чтобы обеспечить непрерывную работу.
Конфлюентные клиенты .NET
В предыдущем абзаце я упомянул, что клиенты либо пишут, либо читают из кластера брокера Kafka. Apache Kafka поставляется вместе с Java-клиентами, но доступно несколько других клиентов, а именно производитель и потребитель .NET Kafka, которые лежат в основе приложения, описанного в этом блоге. Производитель и потребитель .NET предоставляют возможности потоковой передачи событий с помощью Kafka разработчику .NET. Дополнительные сведения о клиентах .NET см. в документации.< /p>
Библиотека параллельных задач
Библиотека параллельных задач (TPL) представляет собой «набор общедоступных типов и API-интерфейсов в пространствах имен System.Threading и System.Threading.Tasks», упрощающих работу по написанию параллельных приложений. TPL делает добавление параллелизма более управляемой задачей, обрабатывая следующие детали:
1. Обработка разделения работы 2. Планирование потоков в ThreadPool 3. Детали низкого уровня, такие как отмена, управление состоянием и т. д.
Суть в том, что использование TPL может максимизировать производительность обработки вашего приложения, позволяя вам сосредоточиться на бизнес-логике. В частности, вы будете использовать подмножество Dataflow Library. TPL.
Библиотека потоков данных — это модель программирования на основе акторов, которая позволяет передавать внутрипроцессные сообщения и конвейеризировать задачи. Компоненты потока данных основаны на типах и инфраструктуре планирования TPL и легко интегрируются с языком C#. Чтение из Kafka обычно происходит довольно быстро, но обработка (вызов БД или вызов RPC) обычно является узким местом. Любые возможности распараллеливания, которые мы можем использовать для достижения более высокой пропускной способности, не жертвуя при этом гарантиями порядка, заслуживают рассмотрения.
В этой записи блога мы будем использовать эти компоненты потока данных вместе с клиентами .NET Kafka для создания приложения потоковой обработки, которое будет обрабатывать данные по мере их поступления.
Блоки потока данных
Прежде чем мы перейдем к приложению, которое вы собираетесь создать; мы должны дать некоторую справочную информацию о том, что составляет библиотеку потоков данных TPL. Описанный здесь подход наиболее применим, когда у вас есть задачи с интенсивным использованием ЦП и операций ввода-вывода, требующие высокой пропускной способности. Библиотека потоков данных TPL состоит из блоков, которые могут буферизовать и обрабатывать входящие данные или записи. Блоки относятся к одной из трех категорий:
- Исходные блоки. Действуют как источник данных, и другие блоки могут считывать их.
- Целевые блоки — получатель данных или приемник, в который могут записываться другие блоки.
- Блоки-распространители — ведут себя как исходный и целевой блоки.
Вы берете разные блоки и соединяете их, чтобы сформировать либо линейный конвейер обработки, либо более сложный граф обработки. Рассмотрим следующие иллюстрации:

Библиотека потоков данных предоставляет несколько предопределенных типов блоков, которые делятся на три категории: буферизация, выполнение и группировка. Мы используем типы буферизации и выполнения для проекта, разработанного для этой записи в блоге. BufferBlock
BufferBlock (и классы, которые его расширяют) — это единственный тип блока в библиотеке потоков данных, который обеспечивает непосредственную запись и чтение сообщений; другие типы ожидают получать сообщения от блоков или отправлять сообщения в них. По этой причине мы использовали BufferBlock в качестве делегата при создании исходного блока и реализации интерфейса ISourceBlock и приемного блока, реализующего интерфейс ITargetBlock. .
Другой тип блока потока данных, используемый в нашем приложении, — это TransformBlock Func<TInput, TOutput>, который действует как делегат, который блок преобразования выполняет для каждой входной записи, которую он получает. .
Две важные особенности блоков потока данных заключаются в том, что вы можете контролировать количество записей, которые он будет буферизовать, и уровень параллелизма.
Установив максимальную емкость буфера, ваше приложение будет автоматически применять обратное давление, когда приложение сталкивается с длительным ожиданием в какой-то точке конвейера обработки. Это обратное давление необходимо для предотвращения чрезмерного накопления данных. Затем, когда проблема исчезнет и размер буфера уменьшится, он снова начнет потреблять данные.
Возможность установки параллелизма для блока имеет решающее значение для производительности. Если один блок выполняет задачу, интенсивно использующую ЦП или ввод-вывод, возникает естественная тенденция к распараллеливанию работы для увеличения пропускной способности. Но добавление параллелизма может вызвать проблему — порядок обработки. Если вы добавите многопоточность в задачу блока, вы не сможете гарантировать порядок вывода данных. В некоторых случаях порядок не имеет значения, но когда он имеет значение, необходимо учитывать серьезный компромисс: более высокая пропускная способность с параллелизмом по сравнению с обработкой выходных данных по порядку. К счастью, вам не нужно идти на этот компромисс с библиотекой потока данных.
Когда вы устанавливаете параллелизм блока более чем на один, платформа гарантирует, что он будет поддерживать исходный порядок входных записей (обратите внимание, что поддержание порядка с параллелизмом настраивается, при этом значение по умолчанию равно true). Если исходный порядок данных — A, B, C, то порядок вывода будет A, B, C. Скептически? Я знаю, что был, поэтому я проверил его и обнаружил, что он работает так, как рекламируется. Мы поговорим об этом тесте чуть позже в этом посте. Обратите внимание, что усиление параллелизма следует выполнять только с операциями без сохранения состояния или с сохранением состояния, которые являются ассоциативными и коммутативными, то есть изменение порядка или группировки операций операции не повлияют на результат.
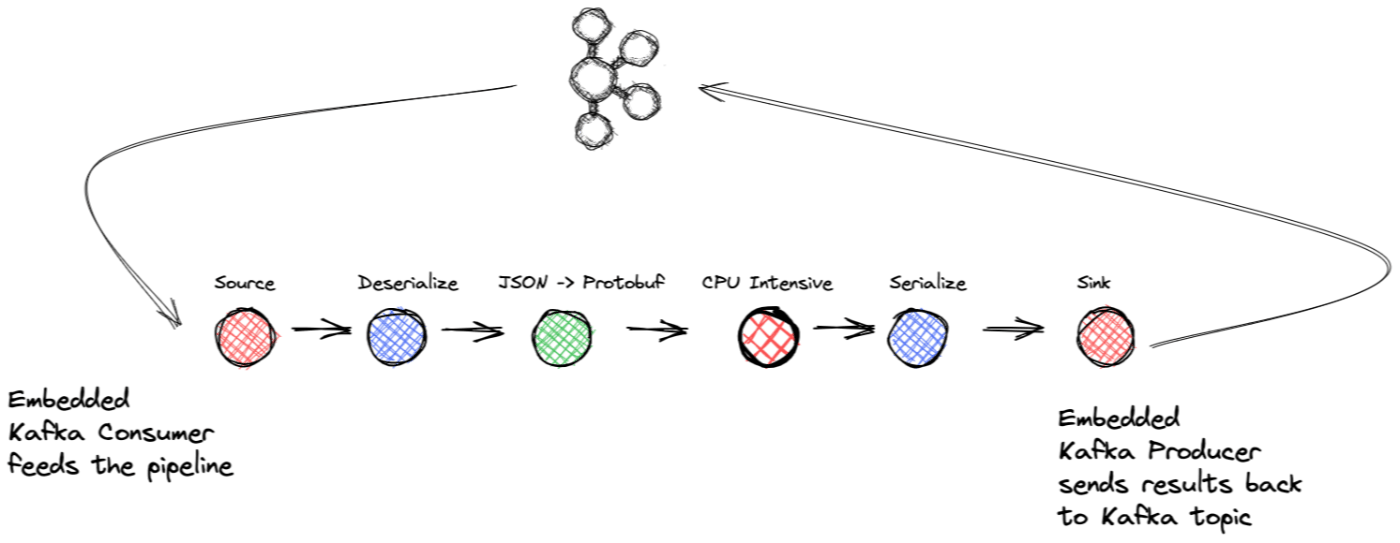
На данный момент, вы можете видеть, куда это идет. У вас есть тема Kafka, представляющая события, которые вам нужно обработать как можно быстрее. Итак, вы собираетесь создать потоковое приложение, состоящее из исходного блока с .NET KafkaConsumer, блоков обработки для выполнения бизнес-логики и приемного блока, содержащего .NET KafkaProducer, для записи окончательных результатов обратно в тему Kafka. Вот иллюстрация высокоуровневого представления приложения:
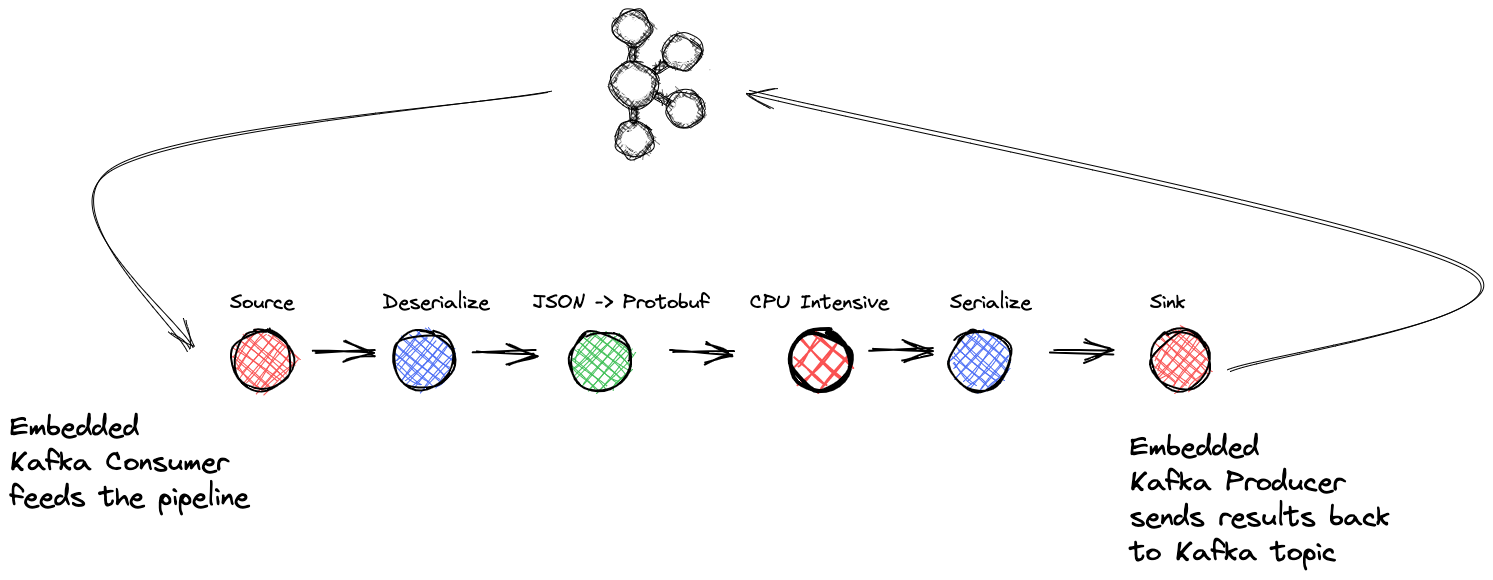
Приложение будет иметь следующую структуру:
- Исходный блок: упаковка .NET KafkaConsumer и делегата
BufferBlock - Блок преобразования: десериализация
- Блок преобразования: сопоставление входящих данных JSON с объектом покупки
- Блок преобразования: задача с интенсивным использованием ЦП (симуляция)
- Блок преобразования: сериализация
- Целевой блок: упаковка .NET KafkaProducer и делегата
BufferBlock
Далее следует описание общего потока приложения и некоторые важные моменты, касающиеся использования Kafka и библиотеки потоков данных для создания мощного приложения для потоковой передачи событий.
Приложение для потоковой передачи событий
Вот наш сценарий. У вас есть тема Kafka, которая получает записи о покупках из вашего интернет-магазина, а формат входящих данных — JSON. Вы хотите обработать эти события покупки, применяя вывод машинного обучения к сведениям о покупке. Кроме того, вы хотели бы преобразовать записи JSON в формат Protobuf, так как это общекорпоративный формат данных. Конечно, пропускная способность для приложения имеет важное значение. Операции машинного обучения интенсивно используют ЦП, поэтому вам нужен способ максимизировать пропускную способность приложения, чтобы вы могли воспользоваться преимуществами распараллеливания этой части приложения.
Использование данных в конвейере
Давайте рассмотрим критические точки потокового приложения, начиная с исходного блока. Я уже упоминал о реализации интерфейса ISourceBlock, и поскольку BufferBlock также реализует ISourceBlock, мы будем использовать его как делегат для удовлетворения всех требований интерфейса. методы. Таким образом, реализация исходного блока будет обертывать KafkaConsumer и BufferBlock. Внутри нашего исходного блока у нас будет отдельный поток, единственная ответственность которого заключается в том, чтобы потребитель передал записи, которые он потреблял, в буфер. Оттуда буфер будет пересылать записи в следующий блок конвейера.
Перед отправкой записи в буфер ConsumeRecord (возвращенный вызовом Consumer.consume) обертывается абстракцией Record, которая, кроме того, к ключу и значению, фиксирует исходный раздел и смещение, что очень важно для приложения, и я вскоре объясню, почему. Также стоит отметить, что весь конвейер работает с абстракцией Record, поэтому любые преобразования приводят к созданию нового объекта Record, обертывающего ключ, значение и другие важные поля, такие как исходное смещение. сохраняя их на протяжении всего конвейера.
Обработка блоков
Приложение разбивает обработку на несколько разных блоков. Каждый блок связан со следующим шагом в цепочке обработки, поэтому исходный блок связан с первым блоком, который обрабатывает десериализацию. Хотя .NET KafkaConsumer может обрабатывать десериализацию записей, у нас есть потребитель, который передает сериализованную полезную нагрузку и десериализует ее в блоке Transform. Десериализация может потребовать больших ресурсов ЦП, поэтому размещение ее в блоке обработки позволяет нам при необходимости распараллелить операцию.
После десериализации записи передаются в другой блок Transform, который преобразует полезные данные JSON в объект модели данных Purchase в формате Protobuf. Более интересная часть начинается, когда данные переходят в следующий блок, представляя задачу с интенсивным использованием ЦП, необходимую для полного завершения транзакции покупки. Приложение имитирует эту часть, а предоставляемая функция приостанавливается со случайным временем от одной до трех секунд.
В этом моделируемом блоке обработки мы используем всю мощь структуры блока потока данных. Когда вы создаете экземпляр блока потока данных, вы предоставляете экземпляр делегата Func, который применяется к каждой записи, с которой он сталкивается, и экземпляр ExecutionDataflowBlockOptions. Я упоминал о настройке блоков потока данных ранее, но мы быстро рассмотрим их здесь снова. ExecutionDataflowBlockOptions содержит два важных свойства: максимальный размер буфера для этого блока и максимальную степень распараллеливания.
Хотя мы устанавливаем конфигурацию размера буфера для всех блоков в конвейере на 10 000 записей, мы придерживаемся уровня параллелизации по умолчанию, равного 1, за исключением моделируемой интенсивной загрузки ЦП, где мы устанавливаем его на 4. Обратите внимание, что размер буфера потока данных по умолчанию равен неограниченно. Влияние на производительность мы обсудим в следующем разделе, а пока завершим обзор приложения.
Блок интенсивной обработки перенаправляется в блок сериализующего преобразования, который передает блок приемника, который затем обертывает .NET KafkaProducer и выдает окончательные результаты в тему Kafka. Блок приемника также использует делегат BufferBlock и отдельный поток для создания. Поток извлекает следующую доступную запись из буфера. Затем он вызывает метод KafkaProducer.Produce, передавая делегат Action, обертывающий DeliveryReport — поток ввода-вывода производителя выполнит Действие делегировать после завершения запроса на создание.
На этом общее пошаговое руководство по приложению завершено. Теперь давайте обсудим важнейшую часть нашей настройки — как обрабатывать фиксацию смещений — что очень важно, учитывая, что мы передаем записи от потребителя по конвейеру.
Выполнение смещений
При обработке данных с помощью Kafka вы будете периодически фиксировать смещения (смещение — это логическая позиция записи в теме Kafka) записей, которые ваше приложение успешно обработало до определенного момента. Итак, почему кто-то совершает смещения? На этот вопрос легко ответить: когда ваш потребитель выключается контролируемым образом или из-за ошибки, он возобновляет обработку с последнего известного зафиксированного смещения. Периодически фиксируя смещения, ваш потребитель не будет повторно обрабатывать записи или, по крайней мере, минимальное количество, если ваше приложение завершит работу после обработки нескольких записей, но до фиксации. Этот подход известен как обработка по крайней мере один раз, которая гарантирует, что записи будут обработаны по крайней мере один раз, а в случае ошибок, возможно, некоторые из них будут обработаны повторно, но это отличный вариант, когда альтернативой является риск потери данных. Kafka также предоставляет гарантии однократной обработки, и хотя мы не будем касаться транзакций в этом сообщении блога, вы можете больше узнать о транзакциях в Kafka в эта запись в блоге.
Хотя существует несколько различных способов фиксации смещений, самым простым и основным является подход с автоматической фиксацией. Потребитель читает записи, а приложение их обрабатывает. По прошествии настраиваемого количества времени (на основе временных меток записей) потребитель зафиксирует смещения уже использованных записей. Обычно автоматическая фиксация является разумным подходом; в типичном цикле потребления-процесса вы не вернетесь к потребителю, пока не обработаете все ранее использованные записи. Если бы произошла непредвиденная ошибка или завершение работы, код никогда не возвращается потребителю, поэтому фиксация не происходит. Но в нашем приложении мы используем конвейерную обработку — мы берем использованные записи, помещаем их в буфер и возвращаемся, чтобы потреблять больше — нет необходимости ждать успешной обработки.
n Как при конвейерном подходе мы можем гарантировать хотя бы однократную обработку? Мы будем использовать метод IConsumer.StoreOffset, который задает единственный параметр — TopicPartitionOffset — и сохраняет его (вместе с другими смещениями) для следующего коммита. . Обратите внимание, что такой подход к управлению смещением отличается от того, как автофиксация работает с Java API.
Таким образом, процедура фиксации работает следующим образом: когда блок приемника извлекает запись для создания в Kafka, он также предоставляет ее делегату Action. Когда производитель выполняет обратный вызов, он передает исходное смещение потребителю (тот же экземпляр в исходном блоке), и потребитель использует метод StoreOffset. У вас по-прежнему включена автоматическая фиксация для потребителя, но вы предоставляете смещения для фиксации вместо того, чтобы потребитель слепо фиксировал последние смещения, которые он использовал до этого момента.

Таким образом, несмотря на то, что приложение использует конвейерную обработку, оно фиксируется только после получения подтверждения от брокера, что означает, что брокер и минимальный набор брокеров реплики сохранили запись. Работа таким образом позволяет приложению работать быстрее, поскольку потребитель может постоянно извлекать данные из конвейера и загружать их, пока блоки выполняют свою работу. Такой подход возможен, потому что клиент-потребитель .NET является потокобезопасным (некоторые методы не являются таковыми и задокументированы как таковые), поэтому мы можем обеспечить, чтобы наш единственный потребитель безопасно работал как в потоках исходного, так и в потоке приемного блока.
При любой ошибке на этапе создания приложение регистрирует ошибку и помещает запись обратно во вложенный блок BufferBlock, поэтому производитель повторно пытается отправить запись брокеру. Но эта логика повторных попыток выполняется вслепую, и на практике вам, вероятно, понадобится более надежное решение.
Влияние на производительность
Теперь, когда мы рассмотрели, как работает приложение, давайте посмотрим на показатели производительности. Все тесты выполнялись локально на ноутбуке с macOS Big Sur (11.6), поэтому в этом сценарии ваши результаты могут отличаться. Настройка теста производительности проста:
- Создайте 1 миллион записей в теме Kafka в формате JSON. Этот шаг был выполнен заранее и не учитывался в тестовых измерениях.
- Запустите приложение с поддержкой Kafka Dataflow и установите для параллелизации всех блоков значение 1 (по умолчанию)
- Приложение работает до тех пор, пока оно не обработает 1 миллион записей, а затем закрывается.
- Запишите время, которое потребовалось для обработки всех записей.
Единственное отличие во втором раунде заключалось в том, что для параметра MaxDegreeOfParallelism для моделируемого блока с интенсивным использованием ЦП было установлено значение четыре.
Вот результаты:
| Количество записей | Фактор параллелизма | Время (минуты) | |----|----|----| | 1М | 1 | 38 | | 1М | 4 | 9 |
Таким образом, просто настроив конфигурацию, мы значительно повысили пропускную способность при сохранении порядка событий. Таким образом, включив максимальную степень параллелизма до четырех, мы получаем ожидаемое ускорение более чем в четыре раза. Но важнейшая часть этого повышения производительности заключается в том, что вы не написали никакого параллельного кода, который было бы трудно сделать правильно.
Ранее в сообщении блога я упомянул тест для проверки того, что параллелизм с блоками потока данных сохраняет порядок событий, поэтому давайте поговорим об этом сейчас. Испытание включало следующие этапы:
- Вывести 1 млн целых чисел (0–999 999) в тему Kafka
- Измените эталонное приложение для работы с целочисленными типами
- Запустите приложение с уровнем параллелизма, равным единице, для смоделированного блока удаленного процесса — создайте тему Kafka
- Повторно запустите приложение с уровнем параллелизма 4 и передайте числа в другую тему Kafka
- Запустите программу, чтобы получить целые числа из обеих разделов результатов и сохранить их в массиве в памяти.
- Сравните оба массива и убедитесь, что они расположены в одинаковом порядке.
Результатом этого теста было то, что оба массива содержали целые числа в порядке от 0 до 999 999, доказывая, что использование блока потока данных с уровнем параллелизма более единицы сохраняет порядок обработки входящих данных. Более подробную информацию о параллелизме потоков данных можно найти в документация.
Обзор
В этом посте мы рассказали, как использовать клиенты .NET Kafka и библиотеку параллельных задач для создания надежного приложения для потоковой передачи событий с высокой пропускной способностью. Kafka обеспечивает высокопроизводительную потоковую передачу событий, а библиотека параллельных задач предоставляет строительные блоки для создания параллельных приложений с буферизацией для обработки всех деталей, что позволяет разработчикам сосредоточиться на бизнес-логике. Хотя сценарий для приложения немного надуманный, надеюсь, вы сможете увидеть полезность объединения двух технологий. Попробуйте — вот репозиторий GitHub.
Также опубликовано здесь. n
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27385)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)