:::Информация
В этой статье мы рассмотрим, как создавать, создавать и развертывать каждый компонент этого веб-сайта с рекомендациями по велосипедам: :link: demo
🎯 Гол
Высокий уровень
Идея этого проекта состоит в том, чтобы проверить возможность создания системы рекомендаций с использованием общедоступных данных, моделей неконтролируемого машинного обучения (ML) и только бесплатных ресурсов.
Для этого мы:
- Используйте [Reddit] (https://www.reddit.com/) для сбора данных
- [Трансформеры Spacy] (https://spacy.io/universe/project/spacy-transformers) в качестве платформы ML
- Google Colab для запуска модели машинного обучения, Heroku для размещения серверной части, Страницы GitHub для размещения внешнего интерфейса
Реализация
Garrascobike — это система рекомендаций по горным велосипедам (MTB). Другими словами, вы можете выбрать марку или модель велосипеда, которая вам нравится, а затем система предложит 3 велосипеда, которые будут интересны и связаны с выбранным вами велосипедом.
Идея системы рекомендаций заключается в следующем: когда люди говорят о некоторых велосипедах в одной и той же ветке субреддита, эти велосипеды должны быть каким-то образом связаны. Таким образом, мы могли бы извлечь названия и/или бренды велосипедов из комментариев одного потока и пересечь эту информацию с другими потоками Reddit с похожими велосипедами.
:громкоговоритель: Предисловие
Цель этого руководства — рассмотреть все аспекты, связанные с созданием веб-приложения, которое обслуживает простую систему рекомендаций, пытаясь максимально снизить уровень сложности.
Так что технический уровень этого эксперимента не будет слишком глубоким, и мы не следуем лучшим практикам промышленного уровня, тем не менее, это руководство, которое я хотел бы иметь год назад, прежде чем начинать простой проект: * создать веб-приложение с помощью модель машинного обучения в основе.*
🗺️ Дорожная карта
То, что мы будем делать, можно обобщить в виде следующих шагов:
- Загрузить текстовые комментарии с Reddit 🐍
- Извлечь интересные сущности из комментариев 🐍🤖
- Создайте простую модель системы рекомендаций 🐍🤖
- Разверните модель на серверной части 🐍
- Создайте внешний интерфейс, отображающий предсказания модели 🌐
:::Информация
🐍 = блоки, использующие Python
🤖 = блоки с затронутыми темами машинного обучения
🌐 = блоки, использующие HTML, CSS и Javascript
🚵♀️ Гарраскобайк
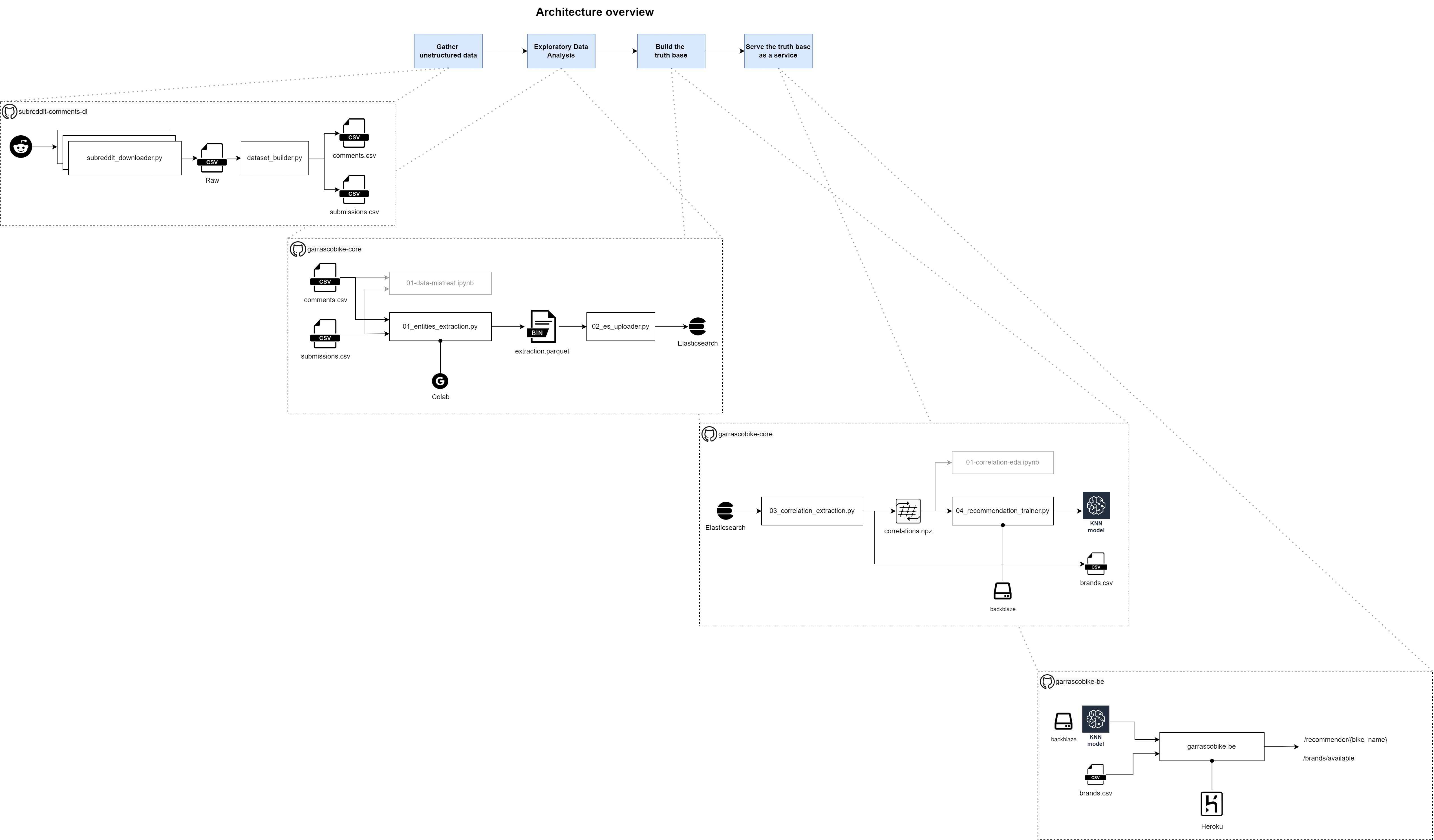
Проект состоит из пяти основных разделов: парсинг, извлечение сущностей, обучение машинному обучению, серверная часть, внешний интерфейс (и они совпадают с пятью главами этого поста).
На приведенном выше изображении первые четыре раздела (исключая внешний интерфейс) сообщаются с их зависимостями и, при необходимости, с платформой, на которой должен выполняться код.
Давайте углубимся в каждый компонент.
1. Скачать текстовые комментарии с Reddit 🐍
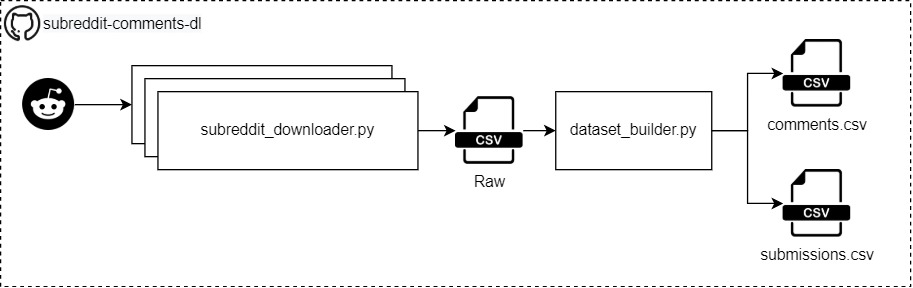
Вступление
Прежде всего: нам нужны данные, а Reddit — замечательная социальная сеть, где люди обсуждают любые темы. Кроме того, Reddit предоставляет некоторый API, который пакеты Python, такие как praw, могут использовать для очистки данных.
Необходимые условия
- Нам нужно выбрать несколько субреддитов, в которых говорится о теме, по которой мы будем создавать рекомендательную систему
- В Garrascobike мы хотим создать систему рекомендаций по горным велосипедам, поэтому нам нужны сабреддиты, рассказывающие об этих велосипедах.
- Субреддиты, выбранные для этого проекта PoC:
Как
- 👨💻Код для использования, размещенный на Github: subreddit-comments-dl
- Следуйте этому руководству, чтобы загрузить комментарии Reddit:
- Более подробная информация также есть в моем блоге:
Исход
- Два файла CSV со всей информацией о комментариях сабреддита.
- Мы создадим два файла CSV, если вы не знакомы с Reddit, может быть полезно прочитать этот небольшой [глоссарий] (https://github.com/pistocop/subreddit-comments-dl#book-glossary)
- комментарии.csv
- Содержит все комментарии с соответствующей информацией, например. текст комментария, дата создания, субреддит и ветка, в которой был написан комментарий
- представления.csv
- Содержит всю информацию о представлениях: представление — это сообщение, которое появляется в каждом сабреддите.
2. Извлекайте интересные сущности из комментариев 🐍🤖
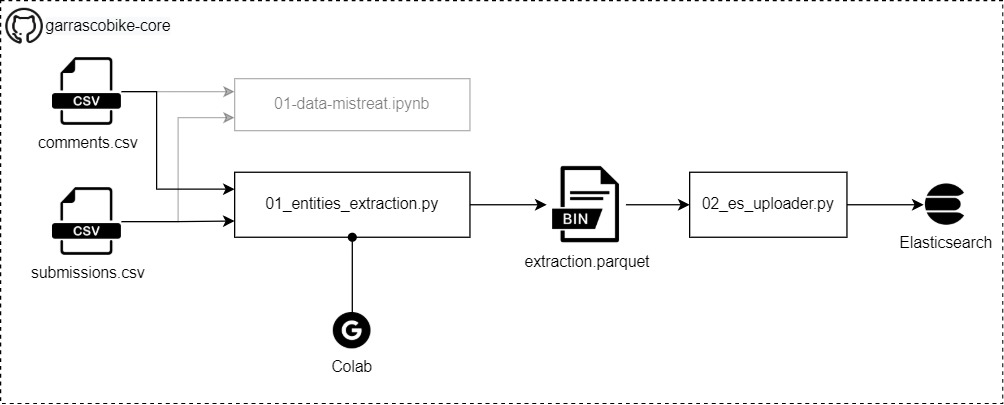
Вступление
- Сущности — это слова или разделы текста, принадлежащие к какому-то заранее определенному «семейству».
- напр. из текста типа «У меня есть Enduro 2019» мы хотели бы извлечь что-то вроде «2019» — это ДАТА, а «Enduro» — это ПРОДУКТ.
- Извлечение сущностей связано с задачей ML под названием «Распознавание именованных сущностей» (NER), дополнительные примеры см. на официальной веб-странице Spacy
- Таким образом, этот блок получает комментарии Reddit и извлекает содержащиеся в них названия велосипедов (extraction.parquet)
- Эта информация будет загружена в экземпляр Elasticsearch.
Необходимые условия
- Комментарии извлечены из нужного сабреддита
- Сколько комментариев?
- Чем больше комментариев, тем выше производительность.
- Для этого проекта мы загрузили 800 000 комментариев из 103 159 заявок
Как
- 👨💻Код для использования, размещенный на Github: garrascobike-core
- Извлечь сущности
- Шаги
- Клонировать репозиторий https://github.com/pistocop/garrascobike-core
- Скопируйте очищенные данные в
/data/01_subreddit_extractions/
- Запустите извлечение с помощью скрипта
/garrascobike/01_entities_extraction.py
- Под капотом скрипт будет использовать систему Spacy NER с spacy-transformers Модель ML
- 💡Совет: используйте этот блокнот Colab для выполнения вышеуказанных задач.
- Поскольку в процессе будет использоваться модель машинного обучения, рекомендуется выполнять код на машине с графическим процессором.
- Если вы не так богаты, как я, есть большая вероятность, что у вас нет мощного графического процессора для задач машинного обучения, поэтому используйте вышеуказанный блокнот и используйте Графические процессоры Google бесплатно 💘
- Нагрузка на Elasticsearch
- Что и почему
- [Elasticsearch] (https://www.elastic.co/elasticsearch/) — это документальная база данных NoSQL, которая может хранить данные, даже если мы не знаем структуру данных.
- Почему мы должны использовать Elasticsearch (ES)?
- Использование этой технологии не было обязательным, если мы остаемся в зоне POC, и для этого может быть достаточно скрипта Python та же работа, необходимая для этого проекта.
- Тем не менее, использование ES обещает нам возможность быть готовыми, если мы выйдем за пределы POC и/или захотим повторно использовать данные различными способами для других проектов.
- ES использовался на первом этапе поиска данных, когда не было ясно, какие данные были извлечены моделью ML и возможно ли привести эту информацию в соответствие с нашими требованиями.
- Использование ES на этом этапе поиска было очень полезным для обнаружения данных и экспресс-запросов, таких как «сколько потоков существует по крайней мере с 1 сущностью продукта», «получить тип всех сущностей» или «перечислить все сущности ПРОДУКТА ”
- Запустите службу Elasticsearch локально
- Установить Докер
- Следуя этому руководству, чтобы запустить мини-кластер локально, кластер
01_single-nodeпредлагается
- Загрузите данные
- Запустите сценарий
/garrascobike/02_es_uploader.py, предоставляющий файл паркета и конечные точки ES.
``` ударить
папка garrascobike-core
$ python garrascobike/02_es_uploader.py --es_index my_index \
--es_host http://локальный_хост \
--es_порт 9200 \
--input_file ./data/02_entities_extractions/extraction.parquet
3. Создайте простую модель системы рекомендаций 🐍🤖
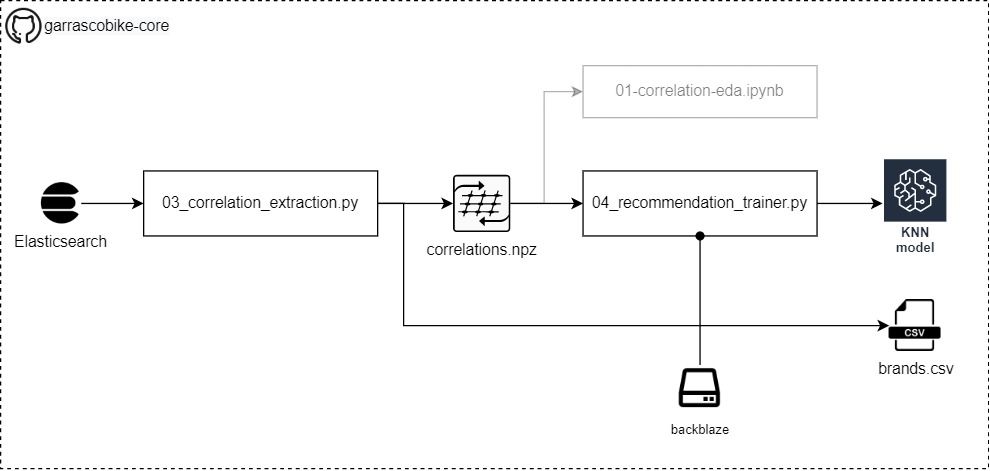
Вступление
- Проанализированные комментарии теперь связаны с фрагментами текста с именем product из процесса извлечения сущностей.
- Взглянув на эти фрагменты, мы увидели, что объекты product здесь — это названия и бренды велосипедов, о которых говорят пользователи в сабреддитах.
- 🦂 Конечно, есть и шум, помеченный как продукт, например. «каньон/гигант» — это фрагмент, который содержит два бренда и не должен включаться и/или разделяться на две сущности «каньон» и «гигант». Более того, «12 скоростей» — это не бренд, а количество передач велосипеда.
- В этом игрушечном проекте нас не волнует шум, поэтому прогнозы могут привести к предложению велосипедов, которых не существует. В реальном сценарии мы должны внести некоторые изменения в эти продукты, например. найдите каждый бренд в поисковой системе изображений и посмотрите, возвращается ли изображение велосипеда.
- Тем не менее, у некоторых брендов очистка и фильтрация действительно выполняются - ссылка на код
- Система рекомендаций будет построена на пересечении марок велосипедов и веток комментариев, к которым относятся комментарии
- Мы создадим полуфабрикат: correlations.npz (в новой версии кода хранится файл с именем presences.csv), этот файл содержит сущности продукта, найденные для каждого сабреддита поток
- На последнем этапе 04_recommendation_trainer.py обучит рекламный магазин модели искусственного интеллекта на основе алгоритма KNN, способной выполнять процесс рекомендаций по велосипедам.
- Подробнее об этом процессе можно узнать в этих хороших статьях:
- Наконец, мы загрузим вручную (без автоматического сценария) файлы, созданные 04_recommendation_trainer.py
- Использование backblaze.com предлагается и поддерживается в следующем разделе главы, он предоставляет 10 ГБ хранилища бесплатно
Необходимые условия
- Экземпляр ES, работающий с извлеченными сущностями products
- Аккаунт на backblaze.com
Как
- 👨💻Код для использования, размещенный на Github: https://github.com/pistocop/garrascobike-core
Запустите скрипт 03_correlation_extraction.py, параметры:
- es_host: адрес экземпляра Elasticsearch
- es_port: порт экземпляра Elasticsearch
- es_index_list: имена индексов Elasticsearch. Их может быть больше одного, потому что можно объединить извлечение большего количества сущностей. Однако для этого руководства мы могли бы использовать только один параметр: my_index.
``` ударить
$ python garrascobike/03_correlation_extraction.py --es_host localhost \
--es_порт 9200 \
--es_index_list мой_индекс
- Запустить скрипт 04_recommendation_trainer.py, параметры:
- presence_data_path: путь к файлу, созданному 03_correlation_extraction.py
- ml_model: модель для построения системы рекомендаций, в настоящее время доступна только knn
- output_path: где сохранить файлы модели рекомендательной системы, эти файлы затем должны быть загружены на backblaze
``` ударить
$ python garrascobike/04_recommendation_trainer.py --presence_data_path ./data/03_correlation_data/presence_dataset/20210331124802/presences.csv \
--output_path ./data/04_recommendation_models/knn/
Исход
- Модель системы рекомендаций, обученная прогнозировать предложение велосипедов по одному указанному названию велосипеда.
- Все файлы рекомендательных моделей должны быть загружены на Backblaze
4. Разверните модель на серверной части 🐍
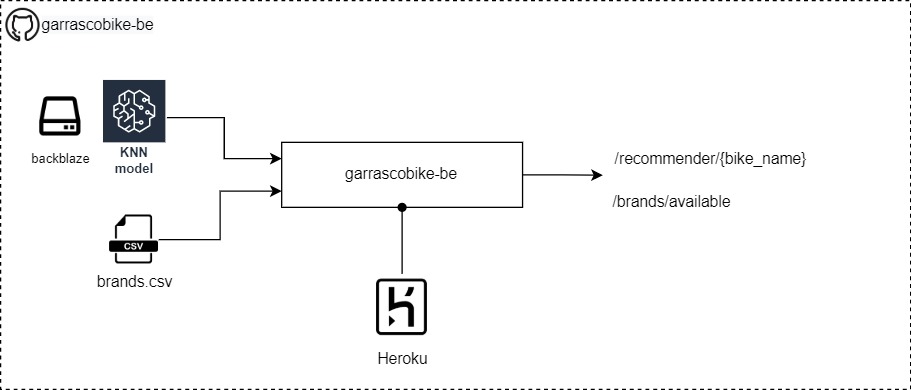
Вступление
- Чтобы дать рекомендацию, нам нужна машина, которая запускает модель прогнозирования.
- Мы обернем модель внутри серверной части, которая:
- Работает на Python и использует фреймворк FastAPI
- Запустите на heroku бесплатную Dyno в качестве поставщика оборудования
- Пробегите 30 м, а затем перейдите в [спящий режим] (https://devcenter.heroku.com/articles/free-dyno-hours#dyno-sleeping)
- Если он находится в спящем узле, требуется \~1 м, чтобы проснуться и быть готовым к использованию.
- Серверная часть предоставит эти API:
/recommender/{bike_name}, который берет название велосипеда и возвращает 3 предложенных велосипеда
/brands/available, которые возвращают список поддерживаемых названий велосипедов.
/health, который возвращает метку времени и будет использоваться для проверки работоспособности серверной части.
Необходимые условия
- Нам нужен список велосипедов, которыми может управлять модель системы рекомендаций:
brands.csv
- Модель рекомендаций, которую серверная часть будет использовать для прогнозирования.
Как
- 👨💻Код для использования, размещенный на Github: https://github.com/pistocop/garrascobike-be
- Установите правильные учетные данные и путь в соответствии с вашей учетной записью backblaze:
- Чтобы установить имя корзины Backblaze и путь, измените файл по адресу:
/garrascobike_be/ml_model/hosted-model-info.json
- Чтобы установить учетные данные для подключения Backblaze, измените и переименуйте файл в
.env:/garrascobike_be/.env_example
- Создайте учетную запись на heroku и опубликуйте серверную часть: следуйте этому руководству для получения более подробной информации:
Исход
- Серверная часть работает на Heroku, вы можете получить URL-адрес API с помощью кнопки «открыть приложение» на веб-странице Heroku.
- Внутреннюю спецификацию openAPI можно найти в
https://<heroku-app-url>/docs, и она будет выглядеть следующим образом:
- Примечание: вам может потребоваться подождать \~1 минуту, прежде чем вы увидите эту спецификацию OpenAPI.
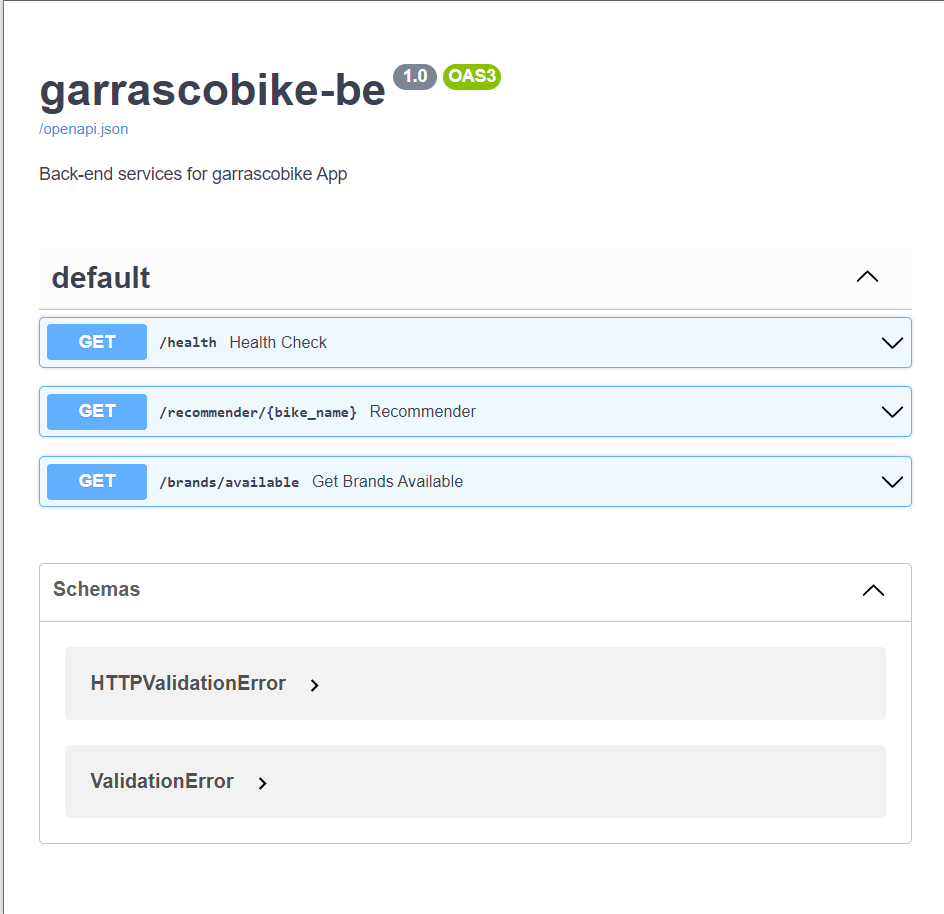
5. Создайте интерфейс, который предоставляет прогнозы модели 🌐
Вступление
- Нам нужен веб-сайт, на котором пользователь мог бы выбрать желаемый велосипед и получить предложения
- Веб-сайт должен использовать API, предоставляемый серверной частью
- Тем не менее, по этой причине FE должен отображать своего рода «отказ от ответственности», пока Heroku разбудит приложение.
- FE также должен предоставить краткий список велосипедов, из которых пользователь может выбирать.
- Мы создадим текстовое поле автозаполнения, используя удивительный фреймворк autoComplete.js.
- Мы создадим статический сайт с HTML, CSS и JS
- Затем веб-сайт бесплатно размещается на [GitHub Pages] (https://pages.github.com/)
Необходимые условия
- Серверная часть Garrascobike запущена и работает онлайн
- URL-адрес серверной части
- программа
live-serverдля локального запуска веб-сайта - npm
Как
- 👨💻Код для использования, размещенный на Github: https://github.com/pistocop/garrascobike-fe
- Шаги по настройке нового интерфейса
- Форкнуть [проект] (https://github.com/pistocop/garrascobike-fe)
- Замените эту строку вашим внутренним URL-адресом.
- Зафиксировать изменения
- Следуйте этому руководству, чтобы включить Служба страниц GitHub в вашем репозитории (примечание: репо должно быть общедоступным!)
- Перейдите по ссылке, сгенерированной интерфейсом GitHub.
- Наслаждайтесь своим новым интерфейсом!
Исход
- Демонстрация веб-сайта: https://pistocop.github.io/garrascobike-fe/
- Веб-сайт, который вы увидите, должен выглядеть следующим образом:


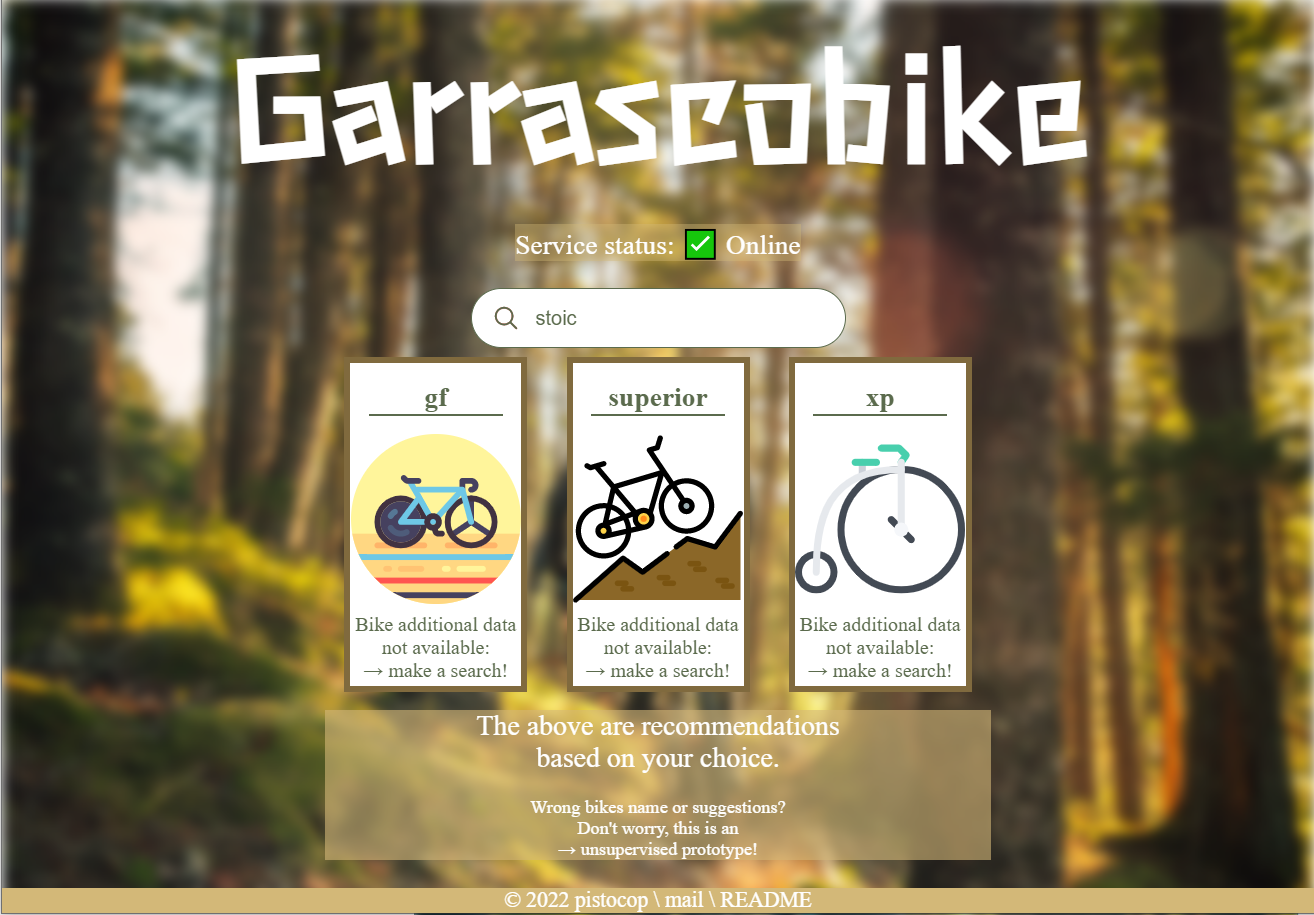
🎌 Другие языки
- Весь проект построен и работает для английских субреддитов
- Другие языки могут поддерживаться, единственный раздел, который требует изменения, — это пространственная модель в задаче извлечения сущностей https://github.com/pistocop/garrascobike-core
- Модели трансформеров Spacy на разных языках можно найти здесь: поддержка языков
💭 Заключительные мысли
Мы только что увидели, как построить рекомендательную систему от процесса парсинга до веб-приложения. Все данные берутся из Reddit и обрабатываются с помощью неконтролируемых моделей машинного обучения (Spacy) с использованием платформы Google Colab. Это сэкономило нам много работы и предоставило простой путь, который также можно было бы автоматизировать.
Наконец, бесплатная серверная часть, размещенная на Heruko, и бесплатная внешняя часть, размещенная на страницах GitHub, дополняют проект благодаря странице веб-приложения.
Отсюда можно проделать большую работу по доработке каждого из компонентов, например. если мы хотим перейти от проекта POC, подобного этому, к производственной и более серьезной системе, мы должны:
- Отфильтруйте и удалите все извлеченные объекты, которые не являются велосипедами.
- Очистите и обработайте больше данных
- Создавайте и тестируйте различные параметры или семейства для системы рекомендаций
В заключение я хочу сказать, что было приятно создавать этот проект, у меня нет опыта работы с интерфейсом, а простой веб-сайт сделан после перехода на [theodinproject.com] (https://www.theodinproject.com). /) бесплатный курс.
:beer: И теперь, после завершения всех компонентов и запуска веб-сайта, я должен признать, что я доволен, надеюсь, вам понравилось путешествие!
:::Информация
📧 Нашли ошибку или есть вопрос? давайте подключимся
Эта статья была впервые опубликована здесь: https://www.pistocop.dev/posts/garrascobike/