Несмотря на нынешнюю шумиху, языковые модели не новы. Они были у нас в телефонах годами, выполняя автозаполнение. И хотя они могут сэкономить нам пару секунд на правописание, никто никогда не назовет их «умными» или «чувствующая."
Технически все языковые модели — это просто вероятностные распределения токенов. Они обучены определять следующее вероятное слово или символ, в зависимости от того, что было размечено, с учетом предыдущих. Но их также можно настроить для других задач, таких как языковой перевод и ответы на вопросы.
Что такое генерация языка?
Генерация языка — это процесс предоставления алгоритму случайного слова, чтобы он мог сгенерировать следующее на основе вероятностей, полученных из обучающих данных, а затем непрерывно снабжать его собственными выводами. Например, если модель видит "я", мы ожидаем, что она выдаст "есть", затем "хорошо" и т. д.
Его способность создавать осмысленные предложения зависит от размера его контрольного окна. Старые базовые модели, такие как те, что используются в наших телефонах, могут оглядываться назад только на одно или два слова, поэтому они близоруки и забывают начало предложения, когда доходят до середины.
От RNN к трансформерам
До трансформаторов исследователи использовали рекуррентные нейронные сети (RNN) для решения проблемы нехватки памяти. Не вдаваясь в подробности, можно сказать, что их уловка заключалась в создании скрытого вектора состояния, содержащего информацию обо всех узлах входного предложения, и обновлении его с каждым новым введенным токеном.
Хотя идея была определенно умной, скрытое состояние всегда оказывалось сильно смещенным в сторону самых последних входных данных. Поэтому, как и базовые алгоритмы, RNN по-прежнему склонны забывать начало предложения, хотя и не так быстро.
Позже были введены сети с долговременной кратковременной памятью (LSTM) и Gated Recurrent Unit (GRU). В отличие от ванильных RNN, они имели встроенные механизмы (гейты), которые помогали сохранять в памяти соответствующие входные данные, даже если они были далеки от производимого вывода. Но эти сети по-прежнему носили последовательный характер и имели слишком сложную архитектуру. Они были неэффективны и запрещали параллельные вычисления, поэтому не было возможности запускать их на нескольких компьютерах одновременно, чтобы получить молниеносную производительность.
В 2017 году трансформаторы впервые были описаны в этой статье автора Гугл. В отличие от LSTM и GRU, у них была возможность активно выбирать сегменты, которые были актуальны для обработки на данном этапе, и ссылаться на них при оценке. Они были быстрее, эффективнее и имели более простую архитектуру, основанную на принципе внимания.
Забавно, что если читать работу сейчас, то она звучит как заурядная статья по машинному переводу, которых в то время было предостаточно. Авторы, вероятно, не осознавали, что могли изобрести одну из самых важных архитектур в истории ИИ.
Внимание
В контексте машинного обучения внимание относится к векторам, назначенным каждому токену, которые содержат информацию о его положении в последовательности и его важности по отношению к другим входным элементам. Модель может использовать их при прогнозировании без необходимости последовательной обработки. Давайте немного разберем его, чтобы стало понятнее.
До появления преобразователей традиционный подход к обработке последовательностей, такой как перевод нейронного языка, заключался в том, чтобы кодировать все входные данные в одно скрытое состояние с помощью RNN, а затем декодировать целевую последовательность с помощью другой RNN. Все, что имело значение в конце кодирования, — это конечное состояние.
В 2014 г. Богданау и соавт. предложил блестящую идею сделать все скрытые состояния доступными для сети декодера и позволить ей определить, какие из них являются наиболее важными. для создания текущего выхода. Сеть обращала внимание на соответствующие части и игнорировала остальные.
Четыре года спустя статья Google была опубликована. На этот раз авторы предложили полностью отказаться от RNN и просто использовать внимание как на этапах кодирования, так и на этапах декодирования. Для этого им пришлось внести определенные изменения в первоначальный механизм внимания, что привело к развитию самовнимания.
Внимание к себе
Наверное, проще всего представить самовнимание как механизм связи между узлами в одной последовательности. Это работает следующим образом: всем входным токенам назначаются три вектора — Запрос (Q), Ключ (K) и Значение (V), которые представляют различные аспекты их первоначального внедрения.
* Векторы запроса (Q) указывают, что ищет ввод. Думайте о них как о фразах, которые вы вводите в строку поиска YouTube. * Ключевые векторы (K) служат идентификаторами для ввода, помогая ему находить совпадения для своего запроса. Это похоже на результаты поиска Youtube с соответствующими заголовками. * Векторы значений (V) представляют фактическое содержимое каждого токена и позволяют модели определять важность соответствующего узла по отношению к запросу и генерировать выходные данные. Их можно рассматривать как миниатюры и описания видео, которые помогут вам решить, на какое видео из результатов поиска нажать.
Примечание. В случае внутреннего внимания все Q, K и V происходят из одной и той же последовательности, тогда как в перекрестное внимание это не так.
Формула самовнимания выглядит следующим образом: Внимание(Q,K,V) = softmax((QK^T) / sqrt(d_k)V. И вот вкратце о процедуре:
- К запросам, ключам и значениям применяются три линейных преобразования для создания соответствующих матриц — Q, K, V.
- Вычисляются скалярные произведения Q и K; они сообщают нам, насколько хорошо все запросы соответствуют всем ключам.
- Полученная матрица делится на квадратный корень из размерности ключей d_k. Это процедура уменьшения масштаба, необходимая для достижения более стабильной градиентности (в противном случае умножение значений могло бы иметь эффект взрыва).
- К масштабируемой оценке применяется функция softmax, и таким образом получаются весовые коэффициенты внимания. Это вычисление дает нам значения от 0 до 1.
- Веса внимания для каждого входа умножаются на их векторы значений, и таким образом вычисляются выходные данные.
- Выходные данные проходят через еще одно линейное преобразование, которое помогает включить данные о самоконтроле в остальную часть модели.
Семейство GPT
Изначально преобразователи были изобретены как простая альтернатива RNN для кодирования последовательностей, но за последние пять лет они стали применяться в различных областях исследований ИИ, включая компьютерное зрение, и часто превосходили современные технологии. художественные модели.
Однако в 2018 году мы не знали, насколько мощными они могут быть, если сделать их большими (с миллионами параметров), учитывая достаточную вычислительную мощность и обучая обширным, разнообразным и немаркированным текстовым корпусам из Интернета.
Первое представление об их возможностях было замечено в Generative Pre Обученный преобразователь (GPT), разработанный OpenAI, который имел 117 миллионов параметров и был предварительно обучен на неразмеченных данных. В 9 из 12 задач НЛП он превзошел модели, обученные на основе выборочного обучения, несмотря на то, что эти алгоритмы были специально обучены для этих задач, а GPT — нет.
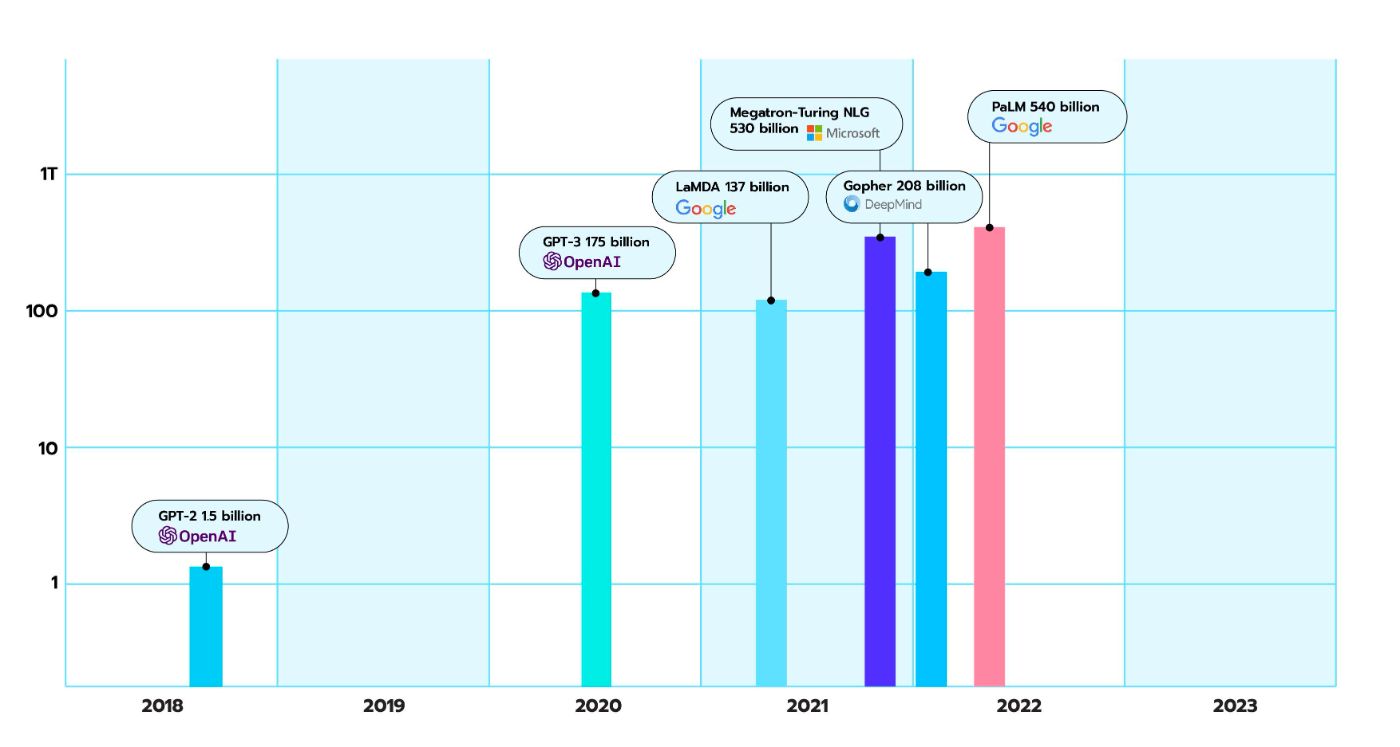
Затем появились модели GPT-2 (самая большая с 1,5 миллиардами параметров), за которыми последовало множество других трансформеров. . А в 2020 году OpenAI наконец-то выпустила GPT-3; его самая большая версия имела 175 миллиардов параметров, а ее архитектура была в основном такой же, как в GPT-2.
Похоже, что цель OpenAI состояла в том, чтобы определить, насколько высокий уровень производительности они могут выжать из своей модели, просто увеличив ее и снабдив ее большим количеством текста и мощности. Результаты были ошеломляющими.
Примечание. 175 млрд параметров – это довольно мало по сегодняшним меркам.
GPT-3 способен генерировать тексты в различных стилях и форматах, таких как романы, стихи, руководства, сценарии, новостные статьи, пресс-релизы, подписи к изображениям, тексты песен, электронные письма, ответы на диалоги и т. д. Он может писать код, резюмировать, перефразировать, упростить, классифицировать любую информацию и многое другое. Чтобы перечислить все его возможности, буквально потребовалась бы целая статья. И все же по своей сути этот зверь по-прежнему представляет собой простую систему автозаполнения.
ChatGPT
Хорошо, у нас есть невероятно мощная языковая модель. Можем ли мы просто использовать его как чат-бот? №
GPT-3 и его аналоги по-прежнему являются инструментами для завершения последовательности и не более того. Без надлежащего направления они будут болтать о теме, которую они уловили из вашего вопроса, и придумают фальшивые статьи, новости, романы и т. д., которые могут показаться беглыми, связными и грамматически безупречными, но от них редко будет польза.
Чтобы создать действительно полезного чат-бота, OpenAI провела обширную тонкую настройку GPT-3 или GPT 3.5, обновленной версии модели — мы пока точно не знаем. Хотя большая часть деталей этого процесса еще не раскрыта, мы знаем, что бот обучался почти таким же образом. как InstructGPT, родственная ему модель. И мы также заметили, что последний во многом похож на Sparrow, еще не запущенную версию «интеллектуального диалогового агента» DeepMind, описанную в эта статья, вышедшая чуть позже.
Итак, зная, что все алгоритмы на основе преобразователя фактически имеют одинаковую архитектуру, мы можем прочитать сообщение в блоге OpenAI, сравнить его с документом Sparrow, а затем сделать некоторые обоснованные предположения о том, что происходит под капотом ChatGPT.
Процесс тонкой настройки из статьи состоял из трех этапов:
- Накопление данных, которые показывают ИИ, как должен действовать помощник. Этот набор данных состоит из текстов, в которых за вопросами следуют точные и полезные ответы. К счастью, большие предварительно обученные языковые модели очень эффективны с точки зрения выборки, а это означает, что процесс, вероятно, не займет так много времени.
2. Опробовать модель, заставив ее отвечать на запросы и генерируя несколько ответов на один и тот же вопрос, а затем заставляя людей оценивать каждый ответ. И в то же время обучая модель вознаграждения распознавать желаемые ответы.
3. Использование оптимизации проксимальной политики OpenAI для точной настройки классификатора и обеспечения того, чтобы ответы ChatGPT получали высокий балл в соответствии с политикой.
В статье Sparrow описан аналогичный метод, но с несколькими дополнительными шагами. Как и все диалоговые агенты DeepMind, Sparrow зависит от конкретных подсказок, созданных вручную, которые действуют как входные данные, которые всегда вводятся в модель программистами и не видны пользователям. ChatGPT, вероятно, также руководствуется такими «невидимыми» подсказками.

Чтобы сделать его эффективным помощником, Sparrow задавали вопросы, и он генерировал ответы, которые затем оценивались людьми на основе общих принципов полезности и этических правил, выдвинутых DeepMind (таких как вежливость и точность). Был также состязательный тип обучения, когда люди активно пытались заставить Воробья потерпеть неудачу. Затем для ее оценки были обучены два нейросетевых классификатора; тот, который оценивает ответы с точки зрения полезности, и тот, который определяет, насколько ответы отклоняются от правил DeepMind.
ChatGPT теперь знает, что нельзя генерировать оскорбительный контент, но иногда после выпуска он выдавал нечувствительные ответы; мы думаем, что OpenAI, возможно, добавил еще одну модель, специально разработанную, чтобы не пропускать вредоносный текст. Но, конечно, мы пока не можем знать наверняка, и сам ChatGPT скрывает это.

В отличие от ChatGPT, Sparrow также сможет предоставить доказательства в поддержку того, что он говорит, поскольку он будет цитировать источники и получать доступ к поиску Google. Чтобы сделать модель способной делать это, исследователи обновили ее первоначальную подсказку и добавили в нее еще два персонажа: поисковый запрос и результат поиска.

Примечание. Тот же принцип, вероятно, был применен в Bard, конкуренте ChatGPT, о котором недавно объявил Google.
После обучения с двумя классификаторами с использованием набора данных ELI5 и ответов предыдущего итераций модель способна генерировать несколько точных и хорошо изученных ответов на каждый вопрос. Пользователю всегда показывается тот ответ, который имеет наивысший балл по классификатору полезности и самый низкий по классификатору отклонения от правил.
Итак, что дальше?
Bard, чат-бот Google, основанный на языковой модели LaMDA, был анонсирован 6 февраля. Он уже вызывает ажиотаж, но никаких конкретных подробностей о его обучении пока не появлялось. Ожидается, что бета-версия Sparrow будет выпущена где-то в 2023 году. Пока неизвестно, станет ли какой-либо из этих ботов почти таким же популярным, как ChatGPT. У обоих есть уникальные функции, которые дают им возможность стать новым чат-ботом номер один, но мы также не думаем, что OpenAI перестанет обновлять и улучшать своего суперзвездного чат-помощника.
Возможно, скоро мы увидим ChatGPT с новыми и даже лучшими функциями. Невозможно предсказать, какая компания окажется на вершине с точки зрения доминирования на рынке. Но тот, кто выиграет соревнование, еще больше раздвинет границы того, что считается достижимым с помощью технологии ИИ, и это, безусловно, будет захватывающе.