

Подключение событийных данных к прогнозирующему ИИ в режиме реального времени
13 июня 2023 г.За последнее десятилетие рост и успех машинного обучения были феноменальными, в первую очередь благодаря доступности огромных объемов данных и передовых вычислительных мощностей. Этот всплеск был вызван оцифровкой различных секторов, что привело к взрывному росту цифровых данных — всего, от сообщений в социальных сетях до онлайн-транзакций и данных датчиков.
Достижения в области методов машинного обучения, особенно в области глубокого обучения, способствовали разработке более сложных и универсальных моделей. В результате приложения машинного обучения получили повсеместное распространение, способствуя повышению эффективности и расширению возможностей во многих секторах, включая здравоохранение, финансы и транспорт.
Работать с этими огромными объемами основанных на событиях данных и извлекать ценность из самих событий и их контекста во времени — других событий, происходящих поблизости — по-прежнему сложно. Сделать это в режиме реального времени или в потоковом режиме еще сложнее. Часто приходится использовать сложные низкоуровневые API или обходить ограничения языка запросов более высокого уровня, предназначенного для решения самых разных задач, например SQL.
Чтобы решить эти проблемы, мы вводим новую абстракцию для временных данных, называемую временными шкалами. Временные шкалы организуют данные по времени и объектам, предлагая идеальную структуру для событийных данных с интуитивно понятной графической ментальной моделью. Временные шкалы упрощают рассуждения о времени, согласовывая вашу ментальную модель с проблемной областью, позволяя вам сосредоточиться на том, что нужно вычислить, а не на том, как это выразить.
В этом посте мы представляем временные шкалы как естественный способ организации данных на основе событий и извлечения ценности — напрямую, а также в качестве входных данных для машинного обучения и оперативного проектирования. Мы углубимся в концепцию временной шкалы, ее взаимодействие с внешними хранилищами данных (входные и выходные данные) и жизненный цикл запросов с использованием временной шкалы.
Этот пост является первым в серии о Kaskada, механизме обработки событий с открытым исходным кодом, разработанном на основе абстракции временной шкалы. Далее мы объясним, как Kaskada строит выразительный язык временных запросов на абстракции временной шкалы, как модель данных временной шкалы позволяет Kaskada эффективно выполнять временные запросы и, наконец, как временные шкалы позволяют Kaskada выполнять инкрементально над потоками событий.
Ощущение времени
Очень сложно работать с большим разнообразием событий, когда каждый вид событий рассматривается как отдельная неупорядоченная таблица данных — так SQL рассматривает мир. Трудно понять, что побудило Карлу совершать покупки или что заставило Аарона общаться с другими пользователями с помощью сообщений.
Организовав данные — по времени и пользователям — становится намного проще выявлять закономерности. Аарон отправляет сообщения после победы. Карла совершает покупки, когда расстроена серией потерь. Мы также видим, что Брэд, возможно, перестал играть.
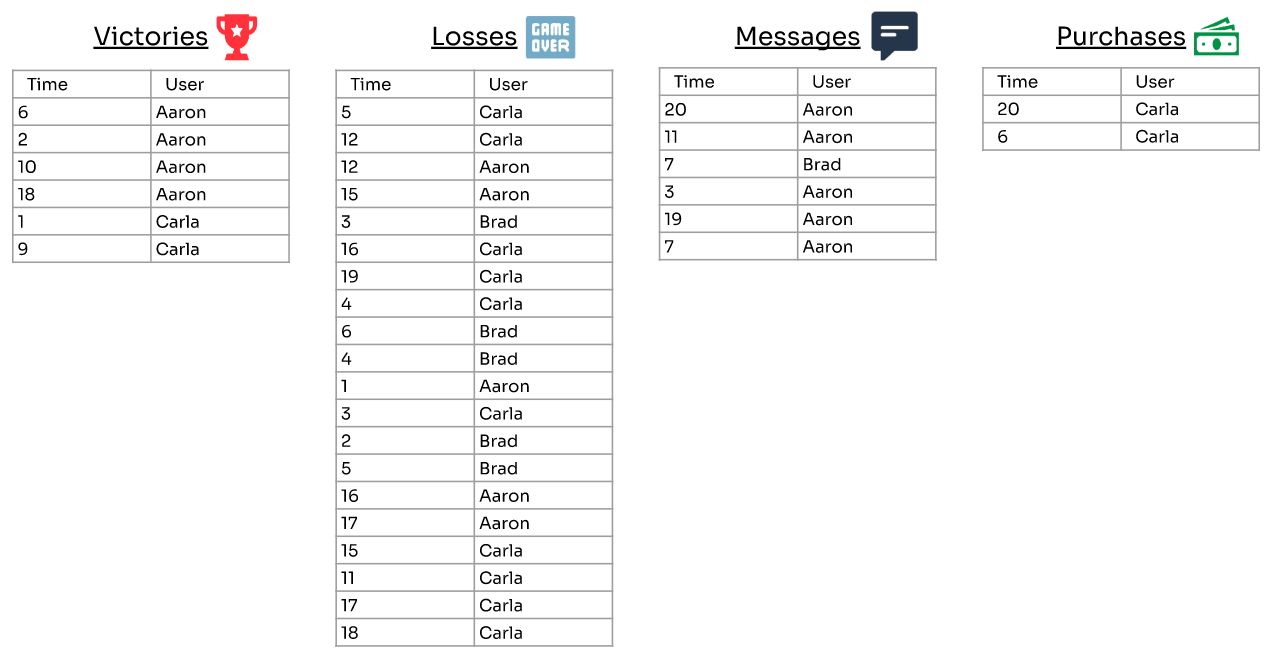
Упорядочивая данные по времени и пользователям, становится намного проще выявлять закономерности. Аарон отправляет сообщения после победы. Карла совершает покупки, когда расстроена серией потерь. Мы также видим, что Брэд, возможно, перестал играть.
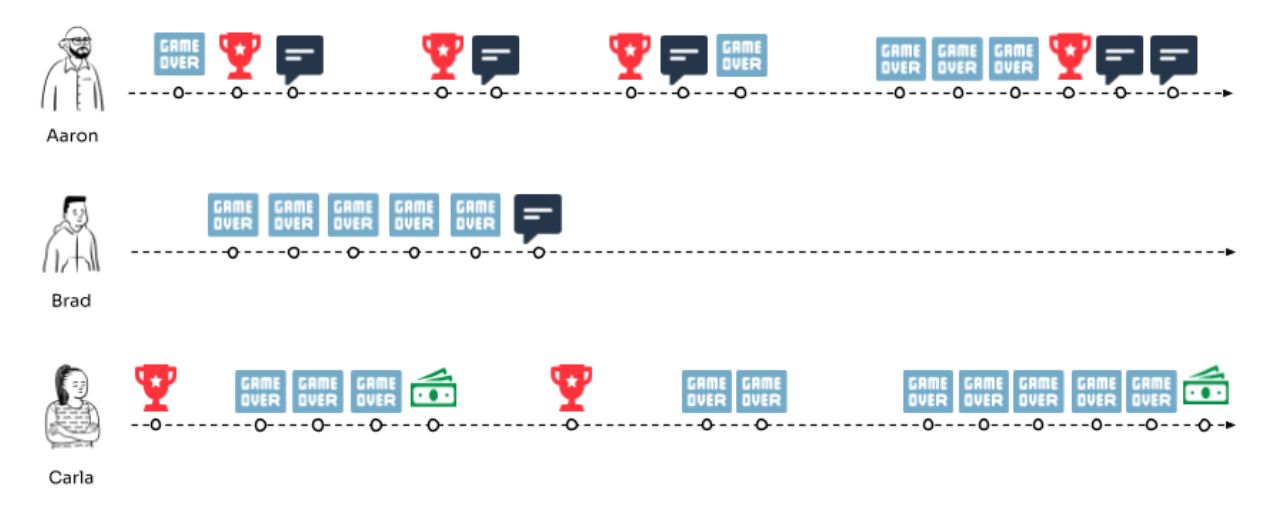
n Организовав события естественным образом — по времени и пользователям — мы смогли выявить закономерности. Эта же организация позволяет нам выражать значения функций, вычисленные на основе событий, и использовать их для обучения и применения моделей машинного обучения или вычисления значений для использования в подсказке.
Абстракция временной шкалы
Рассуждения о времени, например о причинно-следственных связях между событиями, требуют большего, чем просто неупорядоченный набор данных о событиях. Для временных запросов нам нужно включить время как первоклассную часть абстракции. Это позволяет рассуждать о том, когда произошло событие, а также о порядке и времени между событиями.
Kaskada построена на абстракции временной шкалы: мультимножество, упорядоченное по времени и сгруппированное по сущности. Временные шкалы имеют естественную визуализацию, показанную ниже. Время показано на оси x и соответствующие значения на оси y. Рассмотрим события покупки от двух человек: Бена и Давора. Они отображаются в виде дискретных точек, отражающих время и сумму покупки. Мы называем эти временные шкалы дискретными, потому что они представляют собой дискретные точки.
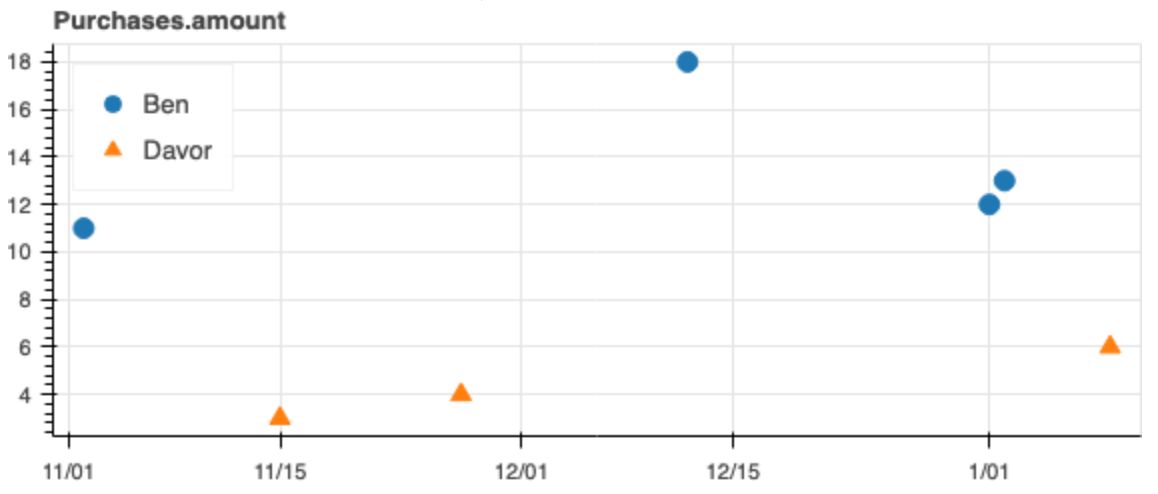
Ось времени временной шкалы отражает время результата вычисления. Например, в любой момент времени мы можем спросить: «Какова сумма всех покупок?» Агрегации по временным шкалам являются кумулятивными — по мере наблюдения событий ответ на вопрос меняется. Мы называем эти временные шкалы непрерывными, поскольку каждое значение продолжается до следующего изменения.
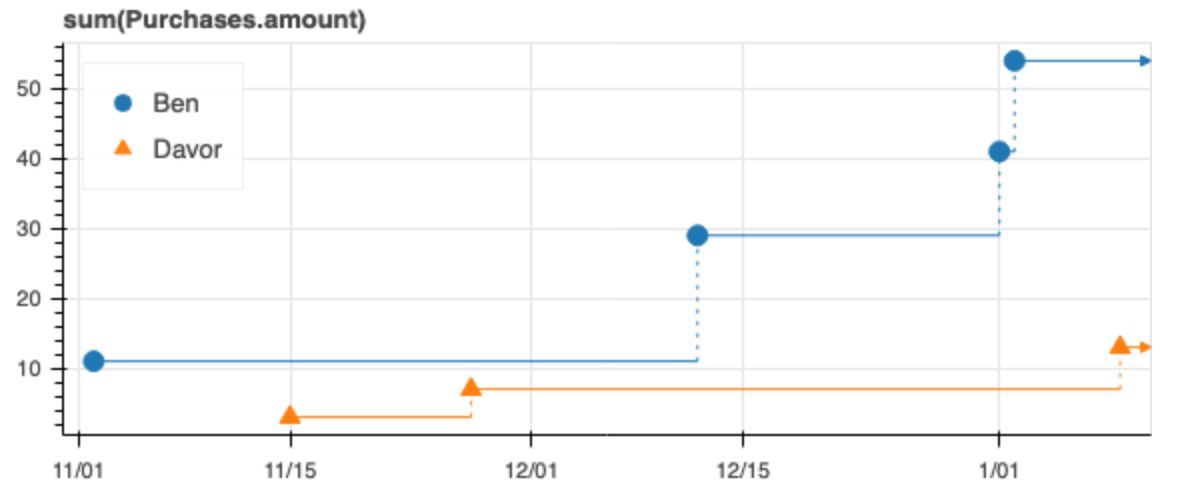
По сравнению с SQL временные шкалы предъявляют два требования: упорядочение по времени и группировка по объектам. Хотя отношение SQL — неупорядоченный мультимножество или сумка — полезно для неупорядоченных данных, дополнительные требования временных шкал делают их идеальными для рассуждений о причинно-следственных связях. Временные шкалы относятся к временным данным так же, как отношения к статическим данным.
Добавление этих требований означает, что временные шкалы подходят не для каждой задачи обработки данных. Вместо этого они позволяют временным шкалам лучше подходить для задач обработки данных, которые работают с событиями и временем. На самом деле, большинство потоков событий (например, Apache Kafka, Apache Pulsar, AWS Kinesis и т. д.) обеспечивают упорядочение и разделение по ключу.
Думая о событиях и времени, вы, вероятно, уже представляете что-то вроде временной шкалы. Соответствуя тому, как вы уже думаете о времени, временные шкалы упрощают рассуждения о событиях и времени. Встраивая требования к времени и порядку, абстракция временной шкалы позволяет временным запросам интуитивно выражать причину и следствие.
Использование временных шкал для временных запросов
Временные шкалы — это абстракция, используемая в Kaskada для построения временных запросов, но данные начинаются и заканчиваются за пределами Kaskada. Важно понимать поток данных от входа к временным шкалам и, наконец, к выходу.
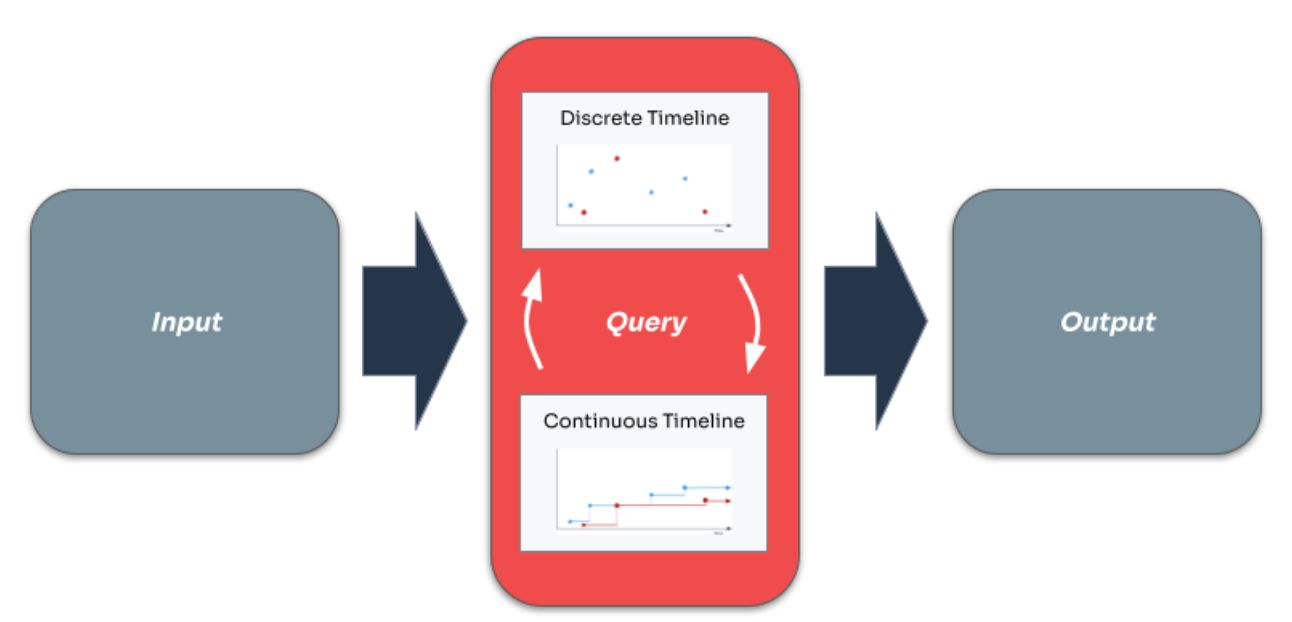
Каждый запрос начинается с одного или нескольких источников входных данных. Каждый ввод — будь то события, поступающие в поток или хранящиеся в таблице, или факты, хранящиеся в таблице, — можно преобразовать во временную шкалу без потери важного контекста, такого как время каждого события.
Сам запрос выражается в виде последовательности операций. Каждая операция создает временную шкалу из временных шкал. Результат последней операции используется как результат запроса. Таким образом, запрос создает временную шкалу, которая может быть либо дискретной, либо непрерывной.
Результатом запроса является временная шкала, которая может быть выведена в приемник. Строки, записанные в приемник, могут представлять собой историю, отражающую изменения на временной шкале, или снимок, отражающий значения в определенный момент времени.
Ввод временных шкал
Перед выполнением запроса каждый ввод сопоставляется с временной шкалой. Каждый ввод — будь то события из потока или таблицы или факты в таблице — можно сопоставить с временной шкалой без потери важной временной информации, например, когда произошли события. События становятся дискретными временными шкалами со значениями каждого события, происходящими во время события. Факты становятся непрерывными временными шкалами, отражающими время, в течение которого применялся каждый факт. Представляя без потерь все виды временных входных данных, временные шкалы позволяют запросам сосредоточиться на вычислениях, а не на типе входных данных.
Вывод графика
После выполнения запроса результирующая временная шкала должна быть выведена во внешнюю систему для использования. Приемник для каждого места назначения позволяет настроить запись данных с особенностями, зависящими от приемника и места назначения (см. эту документацию по коннектору для получения дополнительной информации).
Существует несколько вариантов преобразования временной шкалы в строки данных, влияющих на количество создаваемых строк:
- Включить всю историю изменений в диапазоне или просто моментальный снимок значения в определенный момент времени.
- Включить в выходные данные только события (изменения), произошедшие через определенное время.
- Включить в выходные данные только события (изменения) до определенного времени.
Полная история изменений помогает визуализировать или идентифицировать закономерности в пользовательских значениях с течением времени. Напротив, моментальный снимок в определенное время полезен для онлайн-панелей или классификации похожих пользователей.
Включение событий после определенного времени уменьшает размер выходных данных, если в пункте назначения уже есть данные до этого времени или когда более ранние точки не имеют значения. Это особенно полезно при повторном выполнении запроса для материализации в хранилище данных.
Включение событий до определенного времени также ограничивает размер вывода и позволяет выбрать моментальный снимок. При добавочном выполнении выбор времени немного раньше текущего времени сокращает задержку обработки данных.
Параметры «изменено с» и «до» особенно полезны при добавочном выполнении, о котором мы поговорим в следующей статье.
История
История — набор всех точек на временной шкале — полезна, когда вам важны прошлые точки. Например, это может быть необходимо для визуализации или выявления закономерностей изменения значений для каждого пользователя с течением времени. История особенно полезна для вывода обучающих примеров, которые можно использовать для создания модели.
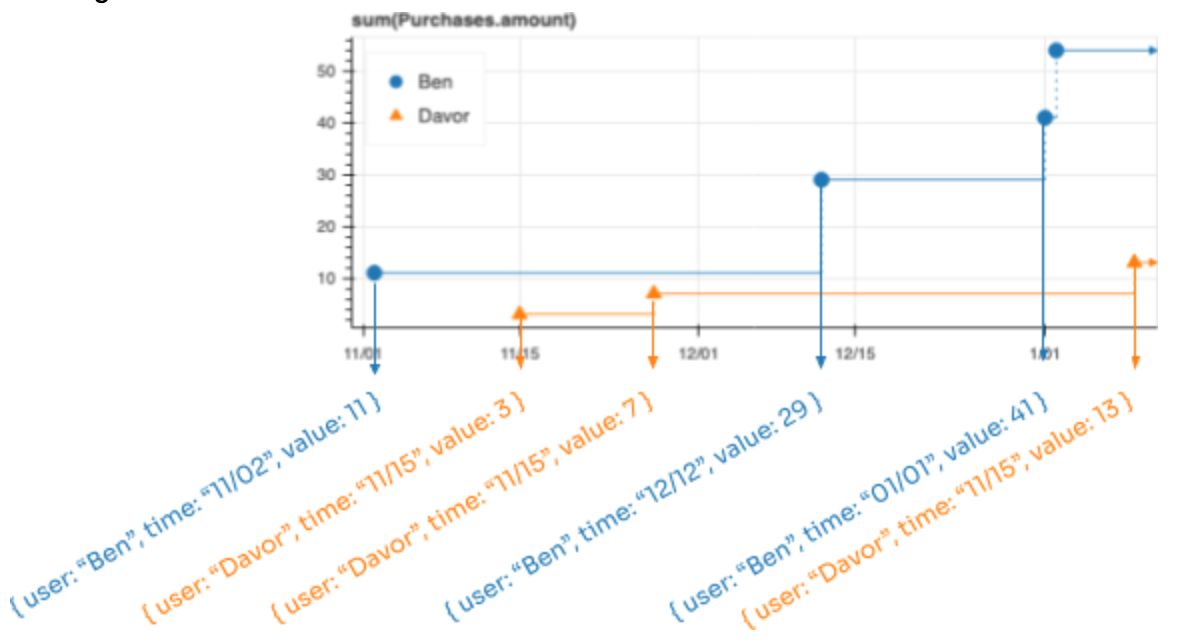
Любая временная шкала может быть выведена в виде истории. Для дискретной временной шкалы история представляет собой набор событий на временной шкале. Для непрерывной временной шкалы история содержит точки, в которых значение изменяется — это фактически журнал изменений.
Снимки
Снимок — значение для каждого объекта в определенный момент времени — полезен, когда вам нужны только самые последние значения. Например, при обновлении информационной панели или заполнении хранилища функций для подключения к обслуживанию моделей.
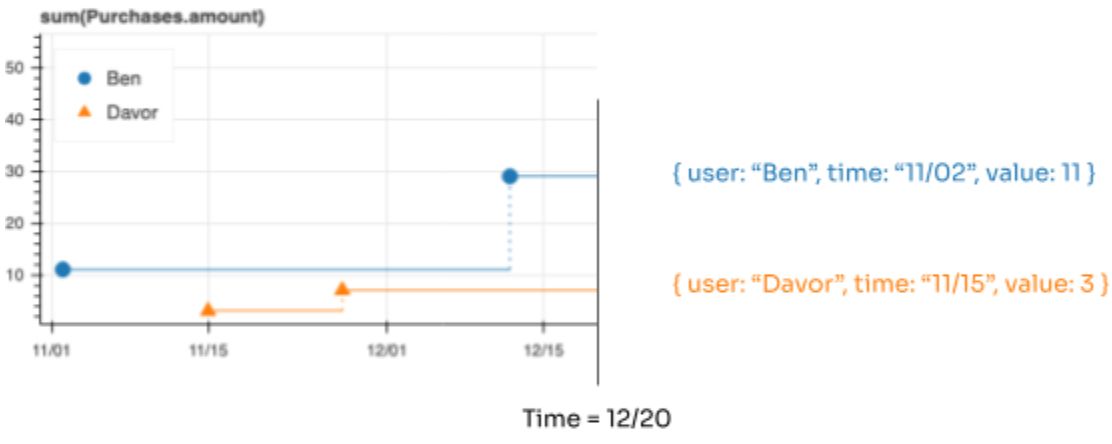
Любая временная шкала может быть выведена в виде снимка. Для дискретной временной шкалы моментальный снимок включает строки для каждого события, происходящего в это время. Для непрерывной временной шкалы моментальный снимок включает строку для каждого объекта со значением этого объекта в данный момент времени.
Заключение
В этой записи блога подчеркивается важность временных характеристик при создании моделей машинного обучения на основе данных на основе событий. Время и временной контекст событий имеют решающее значение для выявления закономерностей в деятельности. В этом посте представлена абстракция временной шкалы, которая позволяет работать с событиями и временным контекстом. Временные шкалы организуют данные по времени и объектам, обеспечивая более подходящую структуру для данных на основе событий по сравнению с мультинаборами. п
Абстракция временной шкалы — это естественное развитие потоковой обработки, позволяющее более эффективно рассуждать о времени и причинно-следственных связях. Мы также изучили поток данных во временном запросе, от ввода к выводу, и обсудили различные варианты вывода временных шкал во внешние системы.
Вместо того, чтобы применять табличный (статический) запрос к последовательности снимков, Kaskada работает с историей (потоком изменений). Это делает естественным работу со временем между моментальными снимками, а не только с данными, содержащимися в моментальном снимке. Использование временных шкал в качестве основной абстракции упрощает работу с данными на основе событий и обеспечивает плавный переход между потоками и таблицами.
Вы можете начать экспериментировать со своим временным запросы сегодня. присоединяйтесь к сообществу Slack и позвольте нам знать, что вы думаете об абстракции временной шкалы. В следующем посте мы углубимся в язык запросов Kaskada и его возможности в экспрессивных темпоральных запросах.
Бен Чемберс и Терапон Скотейниотис, DataStax
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27399)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)