
Создание собственного языка программирования с нуля
21 февраля 2022 г.1. Введение
В этом руководстве мы создадим собственный язык программирования и компилятор с использованием Java (вы можете использовать любой другой язык, желательно объектно-ориентированный). Цель статьи — помочь людям, которые ищут способ создать собственный язык программирования и компилятор. Это игрушечный пример, но он попытается помочь вам понять, с чего начать и в каком направлении двигаться. Полный исходный код доступен [над GitHub] (https://github.com/alexandermakeev/toy-language)
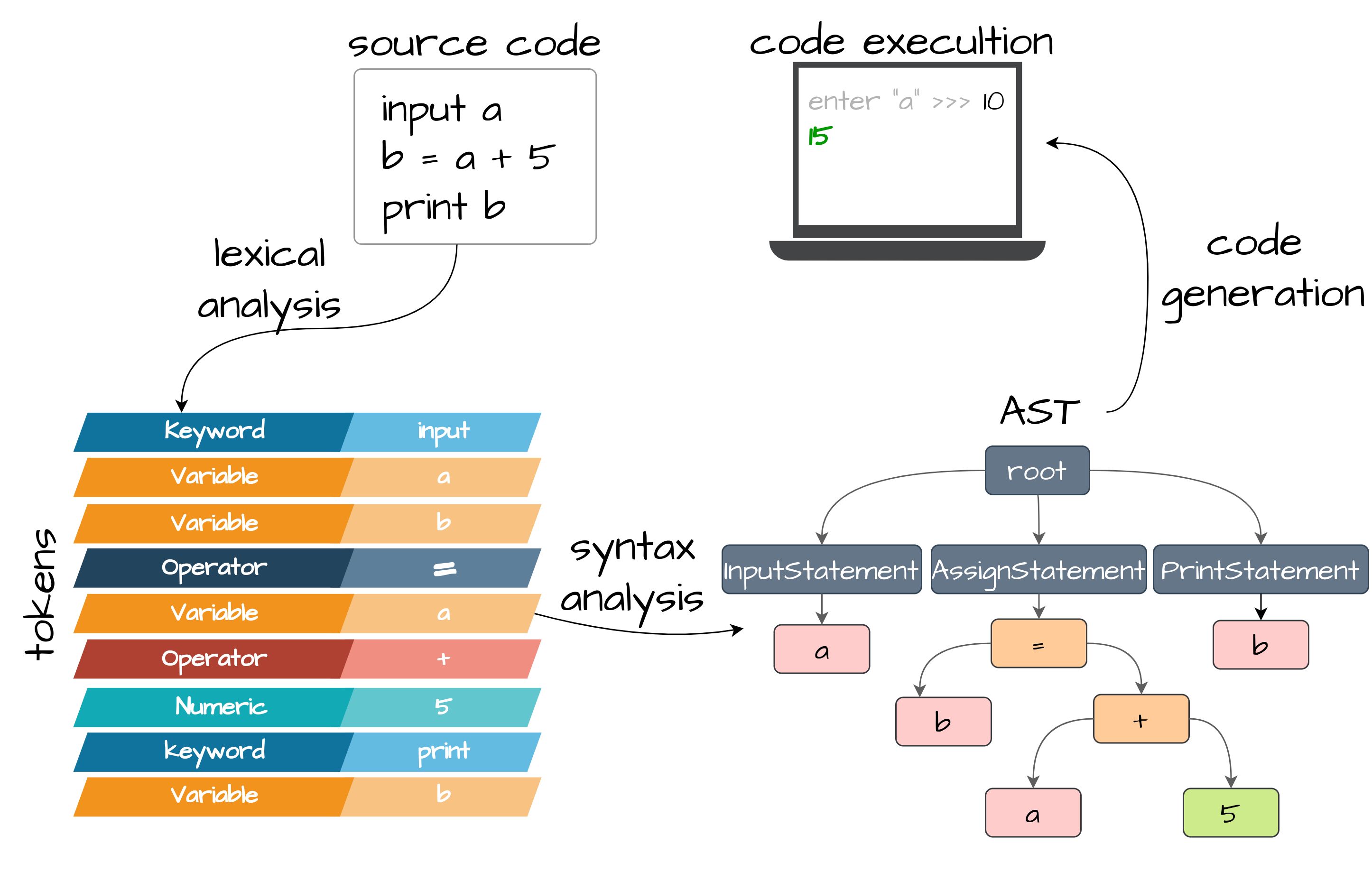
Каждый язык имеет несколько этапов от исходного кода до конечного исполняемого файла. Каждый из этапов определенным образом форматирует поступающие данные:
- Лексический анализ простым языком — это разделение исходного кода на токены. Каждый токен может содержать разную лексему: ключевое слово, идентификатор/переменную, оператор с соответствующим значением и т. д.
- Синтаксический анализ или парсер преобразует список входящих токенов в абстрактное синтаксическое дерево (AST), что позволяет структурно представить правила создаваемого языка. Сам процесс довольно прост, как видно на первый взгляд, но с увеличением языковых конструкций он может значительно усложниться.
- После сборки AST можно сгенерировать код. Код обычно генерируется рекурсивно с использованием абстрактного синтаксического дерева. Наш компилятор для простоты будет создавать операторы во время синтаксического анализа.
Мы создадим простой язык со следующими возможностями:
- назначьте переменные (числовые, логические и текстовые)
- объявлять структуры, создавать экземпляры и получать доступ к полям
- выполнять простые математические операции (сложение, вычитание, приращение, уменьшение, НЕ)
- печатать переменные, значения и более сложные выражения с математическими операторами
- читать числовые, логические и текстовые значения из консоли
- выполнять операторы if-then
Это пример кода нашего языка, это смесь синтаксиса Ruby и Python:
``рубин
структура человека
имя аргумента
аргумент опыт
аргумент is_developer
конец
введите ваше_имя
введите your_experience_in_years
ввод do_you_like_programming
person = new Person [your_name your_experience_in_years do_you_like_programming == "yes"]
печать человек
если человек :: is_developer то
person_name = человек :: имя
напечатайте "привет" + имя_человека + "!"
опыт = человек :: опыт
если опыт > 0 то
start_in = 2022 - опыт
print "вы начали свою карьеру в " +start_in
конец
конец
2 Лексический анализ
Прежде всего, начнем с лексического анализа. Предположим, вы получили сообщение от друга следующего содержания:
``рубин
«Наслаждаюсь чтением книг»
Это выражение немного трудно читать. Это просто набор букв без всякого смысла. Это потому, что наш естественный лексический анализатор не может найти подходящее слово в нашем словаре. Однако, если правильно расставить пробелы, все становится ясно:
``рубин
«Я люблю читать книги»
По такому же принципу работает лексический анализатор языка программирования. Когда мы говорим, мы выделяем отдельные слова по интонации и делаем паузы, чтобы понять друг друга. Точно так же мы должны предоставить код лексическому анализатору, чтобы он нас понял. Если мы напишем его неправильно, лексический анализатор не сможет разделить отдельные лексемы, слова и синтаксические конструкции.
Есть шесть единиц лексемы (лексемы), которые мы будем считать в нашем языке программирования во время лексического анализа:
- Пробел, возврат каретки и другие пробельные символы
Эти лексемные единицы не имеют большого смысла. Вы не можете объявлять какие-либо блоки кода или параметры функций с помощью пробела. Основная цель — лишь помочь разработчику разделить свой код на отдельные лексемы. Поэтому лексический анализатор в первую очередь будет искать пробелы и символы новой строки, чтобы понять, как выделить в коде предоставленные лексемы.
- Операторы:
+,-,=,<,>,::
Они могут быть частью более сложных составных операторов. Знак «плюс» может означать не только сложение, но и объединять в себе более сложный оператор приращения, состоящий из двух «+» подряд. В этом случае лексический анализатор будет пытаться читать выражения слева направо стараясь поймать самый длинный оператор, в частности, если поставить 3 знака плюса подряд, то первые 2 плюса лексический анализатор воспримет как оператор приращения а следующий плюс как разделитель двух токенов и одновременно как оператор сложения.
- Разделители групп:
[,]
Разделители групп могут отделять две групповые лексемы друг от друга. Например, открытая квадратная скобка может использоваться для обозначения начала определенной группы, а закрывающая квадратная скобка будет обозначать конец начатой группы. В нашем языке квадратные скобки будут использоваться только для объявления аргументов экземпляра структуры.
- Ключевые слова: «печать», «ввод», «структура», «аргумент», «конец», «новый», «если», «тогда».
Ключевое слово — это набор буквенных символов с определенным значением, назначенным компилятором. Например, комбинация из 5 букв `print` составляет одно слово и воспринимается компилятором языка как определение оператора вывода консоли. Это значение не может быть изменено программистом. Это основная идея ключевых слов, это языковые аксиомы, которые мы комбинируем для создания наших собственных утверждений — программ.
- Переменные или идентификаторы
Помимо ключевых слов, нам также необходимо учитывать переменные. Переменная — это последовательность символов с некоторым значением, заданным программистом, а не компилятором. В то же время нам нужно наложить определенные ограничения на имена переменных. Наши переменные будут содержать только буквы, цифры и символы подчеркивания. Другие символы внутри идентификатора не могут встречаться, потому что большинство описанных нами операторов являются разделителями и, следовательно, не могут быть частью другой лексемы. В этом случае переменная не может начинаться с цифры из-за того, что лексический анализатор распознает цифру и сразу пытается сопоставить ее с числом. Также важно отметить, что переменная не может быть выражена ключевым словом. Это означает, что если наш язык определяет ключевое слово `print`, то программист не может ввести переменную с тем же набором символов, определенных в том же порядке.
- Литералы
Если заданная последовательность символов не является ключевым словом и не является переменной, остается последний вариант — она может быть литеральной константой. Наш язык сможет определять числовые, логические и текстовые литералы. Числовые литералы — это специальные переменные, содержащие цифры. Для простоты мы не будем использовать числа с плавающей запятой (дроби), вы можете реализовать это самостоятельно позже. Логические литералы могут содержать логические значения: false или true. Текстовый литерал — это произвольный набор символов алфавита, заключенный в двойные кавычки.
Теперь, когда у нас есть основная информация обо всех возможных лексемах в нашем языке программирования, давайте погрузимся в код и начнем объявлять типы наших токенов. Мы будем использовать константы перечисления с соответствующим выражением Pattern для каждого типа лексемы. Я буду использовать аннотации Lombok, чтобы минимизировать шаблонный код:
```java
@RequiredArgsConstructor
@Геттер
общественное перечисление TokenType {
Пробел("[\s\t\
\r]"),
Keyword("(if|then|end|print|input|struct|arg|new)"),
Разделитель("(\[|\])"),
Логический("правда|ложь"),
числовое("[0-9]+"),
Текст("\"([^\"]*)\""),
Переменная("[a-zA-Z_]+[a-zA-Z0-9_]*"),
Оператор("(\+{1,2}|\-{1,2}|\>|\<|\={1,2}|\!|\:{2}) ");
частное конечное регулярное выражение строки;
Для упрощения разбора литералов я разделил каждый из типов литералов на отдельные лексемы: Числовые, Логические и Текстовые. Для литерала Text мы устанавливаем отдельную группу ([^"]*) для захвата литерального значения без двойных кавычек. Для операторов сложения и вычитания мы объявляем диапазон {1,2}. С двумя повторяющимися символами в строки, мы ожидаем поймать оператор инкремента или декремента. Тот же диапазон помечен для оператора равенства. С двумя знаками равенства == мы ожидаем получить оператор сравнения вместо присваивания. Чтобы получить доступ к полю структуры, которое мы объявили оператор двойного двоеточия ::.
Теперь, чтобы найти токен в нашем коде, мы просто перебираем и фильтруем все значения TokenType, применяя регулярное выражение к нашему исходному коду. Чтобы соответствовать началу строки, мы помещаем метасимвол ^ в начало каждого выражения регулярного выражения, создавая экземпляр Pattern. Токен Text вынесет значение без кавычек в отдельную группу. Поэтому, чтобы получить доступ к значению без кавычек, мы берем значение из группы с индексом 1, если у нас есть хотя бы одна явная группа:
```java
for (TokenType tokenType : TokenType.values()) {
Pattern pattern = Pattern.compile("^" + tokenType.getRegex());
Matcher matcher = pattern.matcher(sourceCode);
если (matcher.find()) {
// group(1) используется для получения текстового литерала без двойных кавычек
Строковый токен = matcher.groupCount() > 0? matcher.group(1): matcher.group();
Для хранения найденных лексем нам нужно объявить следующий класс Token с полями типа и значения:
```java
@Строитель
@Геттер
Токен открытого класса {
приватный окончательный тип TokenType;
закрытое конечное строковое значение;
Теперь у нас есть все для создания нашего лексического парсера. Мы получим исходный код в виде String в конструкторе и инициализируем список токенов:
```java
открытый класс LexicalParser {
частные окончательные токены List
частный окончательный источник строки;
public LexicalParser (источник строки) {
этот.источник = источник;
this.tokens = новый ArrayList<>();
Чтобы получить все токены из исходного кода, нам нужно вырезать исходник после каждой найденной лексемы. Мы объявим nextToken() метод, который будет принимать текущий индекс исходного кода в качестве аргумента и получать следующий токен, начиная с текущей позиции:
```java
открытый класс LexicalParser {
частный интервал nextToken (целая позиция) {
Строка nextToken = source.substring(position);
for (TokenType tokenType : TokenType.values()) {
Pattern pattern = Pattern.compile("^" + tokenType.getRegex());
Matcher matcher = pattern.matcher(nextToken);
если (matcher.find()) {
если (tokenType != TokenType.Whitespace) {
// group(1) используется для получения текстового литерала без двойных кавычек
Строковое значение = matcher.groupCount() > 0? matcher.group(1): matcher.group();
Token token = Token.builder().type(tokenType).value(value).build();
tokens.add(токен);
возврат matcher.group().length();
выбросить новое исключение TokenException(String.format("недопустимое выражение: %s", nextToken));
После успешного захвата мы создаем экземпляр Token и накапливаем его в списке токенов. Мы не будем добавлять лексемы «Пробелы», так как они используются только для разделения двух лексем друг от друга. В конце мы возвращаем длину найденной лексемы.
Чтобы захватить все токены в источнике, мы создаем метод parse() с циклом while, увеличивающим исходную позицию каждый раз, когда мы получаем токен:
```java
открытый класс LexicalParser {
открытый список
внутренняя позиция = 0;
в то время как (позиция < source.length()) {
позиция += nextToken(позиция);
возврат токенов;
3 Синтаксический анализ
В нашей модели компилятора синтаксический анализатор получит список токенов от лексического анализатора и проверит, может ли эта последовательность быть сгенерирована грамматикой языка. В конце концов, этот синтаксический анализатор должен вернуть абстрактное синтаксическое дерево.
Мы запустим анализатор синтаксиса, объявив интерфейс Expression:
```java
выражение публичного интерфейса {
Этот интерфейс будет использоваться для объявления литералов, переменных и составных выражений с операторами.
3.1 Литералы
Прежде всего, мы создаем реализации «Expression» для литеральных типов нашего языка: «Numeric», «Text» и «Logical» с соответствующими типами Java: «Integer», «String» и «Boolean». Мы создадим базовый класс Value с расширением универсального типа Comparable (он будет использоваться позже с операторами сравнения):
```java
@RequiredArgsConstructor
@Геттер
открытый класс Value
частное конечное значение Т;
@Override
общедоступная строка toString () {
возвращаемое значение.toString();
открытый класс NumericValue расширяет Value
public NumericValue (целочисленное значение) {
супер(значение);
открытый класс TextValue расширяет Value
общедоступное TextValue (строковое значение) {
супер(значение);
открытый класс LogicalValue расширяет Value
общественное логическое значение (логическое значение) {
супер(значение);
Мы также объявим StructureValue для экземпляров нашей структуры:
```java
открытый класс StructureValue расширяет Value
общественное значение StructureValue (значение выражения структуры) {
супер(значение);
Выражение структуры будет рассмотрено чуть позже.
3.2 Переменные
Выражение переменной будет иметь одно поле, представляющее его имя:
```java
@AllArgsConstructor
@Геттер
открытый класс VariableExpression реализует Expression {
закрытое конечное имя строки;
3.3 Структуры
Чтобы сохранить экземпляр структуры, нам нужно знать определение структуры и значения аргументов, которые мы передаем для создания объекта. Значения аргументов могут обозначать любые выражения, включая литералы, переменные и более сложные выражения, реализующие интерфейс Expression. Поэтому мы будем использовать Expression в качестве типа значений:
```java
@RequiredArgsConstructor
@Геттер
открытый класс StructureExpression реализует выражение {
частное окончательное определение StructureDefinition;
закрытые окончательные значения List
@RequiredArgsConstructor
@Геттер
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
открытый класс StructureDefinition {
@EqualsAndHashCode.Include
закрытое конечное имя строки;
частные окончательные аргументы List
Значения могут быть типом VariableExpression. Нам нужен способ доступа к значению переменной по ее имени. Я делегирую эту ответственность интерфейсу Function, который примет имя переменной и вернет объект Value:
```java
открытый класс StructureExpression реализует выражение {
закрытый финал Function<String, Value<?>> variableValue;
Теперь мы можем реализовать интерфейс для получения значения аргумента по имени, он будет использоваться для доступа к значениям экземпляра структуры. Чуть позже будет реализован метод getValue():
```java
открытый класс StructureExpression реализует выражение {
общественное значение <?> getArgumentValue (строковое поле) {
вернуть IntStream
.диапазон(0, значения.размер())
.filter(i -> определение.getArguments().get(i).equals(поле))
.mapToObj(this::getValue) //будет реализовано позже
.findFirst()
.илиЕще(нуль);
Не забывайте, что наше StructureExpression используется в качестве параметра универсального типа StructureValue, который расширяет Comparable. Поэтому мы должны реализовать интерфейс Comparable для нашего StructureExpression:
```java
открытый класс StructureExpression реализует Expression, Comparable
@Override
public int compareTo(StructureExpression o) {
для (строковое поле: определение.getArguments()) {
Значение <?> значение = getArgumentValue (поле);
Значение <?> oValue = o.getArgumentValue (поле);
если (значение == null && oValue == null) продолжить;
если (значение == ноль) вернуть -1;
если (oValue == null) вернуть 1;
//проверка не проверена,rawtypes
int result = ((Comparable) value.getValue()).compareTo(oValue.getValue());
если (результат != 0) вернуть результат;
вернуть 0;
Мы также можем переопределить стандартный метод toString(). Это будет полезно, если мы хотим вывести в консоль экземпляр всей структуры:
```java
открытый класс ObjectExpression реализует Expression, Comparable
@Override
общедоступная строка toString () {
вернуть IntStream
.диапазон(0, значения.размер())
.mapToObj (я -> {
Значение<?> значение = getValue(i); //будет реализовано позже
Строка fieldName = определение.getArguments().get(i);
вернуть fieldName + " = " + значение;
.collect(Collectors.joining(", ", определение.getName() + "[ ", " ]"));
3.4 Операторы
В нашем языке у нас будут унарные операторы с 1 операндом и бинарные операторы с 2 операндами.
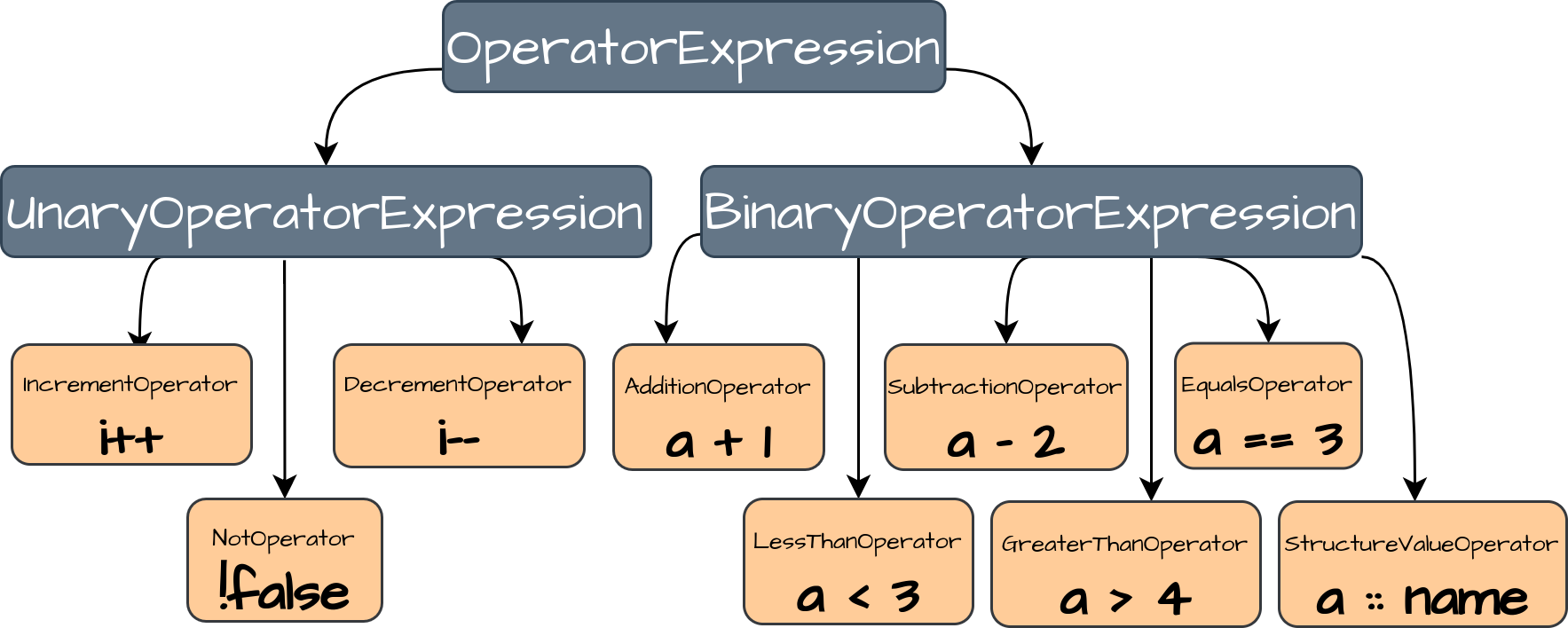
Давайте реализуем интерфейс Expression для каждого из наших операторов. Мы объявляем интерфейс OperatorExpression и создаем базовые реализации для унарных и бинарных операторов:
```java
открытый интерфейс OperatorExpression расширяет выражение {
@RequiredArgsConstructor
@Геттер
открытый класс UnaryOperatorExpression реализует OperatorExpression {
частное конечное значение Expression;
@RequiredArgsConstructor
@Геттер
открытый класс BinaryOperatorExpression реализует OperatorExpression {
частное финальное выражение осталось;
право на частное окончательное выражение;
Нам также необходимо объявить абстрактный метод calc() для каждой из наших реализаций операторов с соответствующими значениями операндов. Этот метод будет вычислять «Значение» из операндов в зависимости от сущности каждого оператора. Переход операнда от «Выражения» к «Значению» будет рассмотрен чуть позже.
```java
открытый абстрактный класс UnaryOperatorExpression extends OperatorExpression {
общественное абстрактное значение <?> calc (значение значения <?>);
общедоступный абстрактный класс BinaryOperatorExpression extends OperatorExpression {
public abstract Value<?> calc(Value<?> слева, Value<?> справа);
После объявления базовых классов операторов мы можем создать более подробные реализации:
3.4.1 Увеличение ++
Первый унарный оператор — IncrementOperator. Мы реализуем метод calc(), проверяя, является ли наше значение объектом NumericValue. В положительном случае мы создаем новый экземпляр NumericValue, передавая в конструктор предыдущее значение, увеличенное на единицу. В негативном сценарии мы можем выдать какую-нибудь ошибку, уведомляющую программиста об ошибке в его коде:
```java
открытый класс IncrementOperator расширяет UnaryOperatorExpression {
public IncrementOperator (выражение выражения) {
супер(выражение);
@Override
public Value<?> calc(Value<?> value) {
если (значение instanceof NumericValue) {
вернуть новое значение NumericValue(((NumericValue) value).getValue() + 1);
} еще {
throw new ExecutionException(String.format("Невозможно увеличить нечисловое значение %s", значение));
3.4.2 Декремент --
Реализация calc() будет выглядеть почти так же, как мы делали для IncrementOperator на предыдущем шаге, за исключением вычитания вместо сложения:
```java
открытый класс DecrementOperator расширяет UnaryOperatorExpression {
@Override
public Value<?> calc(Value<?> value) {
если (значение instanceof NumericValue) {
вернуть новое значение NumericValue(((NumericValue) value).getValue() - 1);
} еще {
throw new ExecutionException(String.format("Невозможно уменьшить нечисловое значение %s", значение));
3.4.3 НЕ !
Этот оператор будет работать только с LogicalValue, возвращающим новый экземпляр LogicalValue с инвертированным значением:
```java
открытый класс NotOperator расширяет UnaryOperatorExpression {
@Override
public Value<?> calc(Value<?> value) {
если (значение instanceof LogicalValue) {
вернуть новое LogicalValue(!((LogicalValue) value.getValue()).getValue());
} еще {
throw new ExecutionException(String.format("Невозможно выполнить оператор НЕ для нелогического значения %s", значение));
Теперь переключимся на реализации BinaryOperatorExpression с двумя операндами:
3.4.4 Добавление +
Первый – дополнение. Метод calc() сделает добавление объектов NumericValue. Для других типов значений мы объединим значения toString(), возвращая экземпляр TextValue:
```java
открытый класс AdditionOperator расширяет BinaryOperatorExpression {
public AdditionOperator (выражение слева, выражение справа) {
супер(слева, справа);
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
если (левый экземпляр числового значения и правый экземпляр числового значения) {
вернуть новое NumericValue(((NumericValue) left).getValue() + ((NumericValue) right).getValue());
} еще {
вернуть новое TextValue (left.toString() + right.toString());
3.4.5 Вычитание -
calc() выполнит сравнение getValue(), только если оба значения имеют тип NumericValue. В другом случае оба значения будут сопоставлены со строкой, удалив совпадения 2-го значения с 1-го значения:
```java
открытый класс SubtractionOperator расширяет BinaryOperatorExpression {
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
если (левый экземпляр числового значения и правый экземпляр числового значения) {
вернуть новое NumericValue(((NumericValue) left).getValue() - ((NumericValue) right).getValue());
} еще {
вернуть новое TextValue(left.toString().replaceAll(right.toString(), ""));
3.4.6 Равно ==
calc() выполнит сравнение getValue(), только если оба значения имеют одинаковый тип. В другом случае оба значения будут сопоставлены со строкой:
```java
открытый класс EqualsOperator расширяет BinaryOperatorExpression {
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
логический результат;
если (Objects.equals(left.getClass(), right.getClass())) {
результат = ((Comparable) left.getValue()).compareTo(right.getValue()) == 0;
} еще {
результат = ((Comparable) left.toString()).compareTo(right.toString()) == 0;
вернуть новое логическое значение (результат);
3.4.7 Меньше < и больше >
```java
открытый класс LessThanOperator расширяет BinaryOperatorExpression {
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
логический результат;
если (Objects.equals(left.getClass(), right.getClass())) {
результат = ((Comparable) left.getValue()).compareTo(right.getValue()) < 0;
} еще {
результат = left.toString().compareTo(right.toString()) < 0;
вернуть новое логическое значение (результат);
открытый класс GreaterThanOperator расширяет BinaryOperatorExpression {
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
логический результат;
если (Objects.equals(left.getClass(), right.getClass())) {
результат = ((Comparable) left.getValue()).compareTo(right.getValue()) > 0;
} еще {
результат = left.toString().compareTo(right.toString()) > 0;
вернуть новое логическое значение (результат);
3.4.8 Оператор значения структуры ::
Чтобы прочитать значение аргумента структуры, мы ожидаем получить левое значение как тип StructureValue:
```java
открытый класс StructureValueOperator расширяет BinaryOperatorExpression {
@Override
public Value<?> calc(Value<?> слева, Value<?> справа) {
если (левый экземпляр StructureValue)
return ((StructureValue) left).getValue().getArgumentValue(right.toString());
вернуться влево;
3.5 Оценка стоимости
Если мы хотим передать переменные или более сложные реализации «Выражения» операторам, включая сами операторы, нам нужен способ преобразования объекта «Выражение» в «Значение». Для этого мы объявляем метод evaluate() в нашем интерфейсе Expression:
```java
выражение публичного интерфейса {
Значение<?> оценить();
Класс Value просто вернет этот экземпляр:
```java
открытый класс Value
@Override
общественное значение<?> оценить() {
вернуть это;
Чтобы реализовать evaluate() для VariableExpression, сначала мы должны предоставить возможность получить Value по имени переменной. Мы делегируем эту работу полю «Функция», которое будет принимать имя переменной и возвращать соответствующий объект «Значение»:
```java
открытый класс VariableExpression реализует Expression {
закрытый финал Function<String, Value<?>> variableValue;
@Override
общественное значение<?> оценить() {
Значение<?> значение = variableValue.apply(имя);
если (значение == ноль) {
вернуть новое TextValue (имя);
возвращаемое значение;
Чтобы оценить StructureExpression, мы создадим экземпляр StructureValue. Нам также нужно реализовать отсутствующий метод getValue(), который будет принимать индекс аргумента и возвращаемое значение в зависимости от типа Expression:
```java
открытый класс StructureExpression реализует Expression, Comparable
@Override
общественное значение<?> оценить() {
вернуть новое значение структуры (это);
частное значение<?> getValue(int index) {
Выражение выражение = values.get(index);
if (expression instanceof VariableExpression) {
return variableValue.apply(((VariableExpression) выражение).getName());
} еще {
вернуть выражение.оценить();
Для операторных выражений мы оцениваем значения операндов и передаем их методу calc():
```java
открытый абстрактный класс UnaryOperatorExpression extends OperatorExpression {
@Override
общественное значение<?> оценить() {
вернуть расчет (получить значение (). оценить ());
общедоступный абстрактный класс BinaryOperatorExpression extends OperatorExpression {
@Override
общественное значение<?> оценить() {
return calc(getLeft().evaluate(), getRight().evaluate());
3.6 Операторы
Прежде чем мы начнем создавать наш синтаксический анализатор, нам нужно представить модель для операторов нашего языка. Начнем с интерфейса Statement с обрабатывающего метода execute(), который будет вызываться во время выполнения кода:
```java
Заявление о публичном интерфейсе {
недействительно выполнить();
3.6.1 Оператор печати
Первым оператором, который мы реализуем, является PrintStatement. Этот оператор должен знать выражение для печати. Наш язык будет поддерживать печать литералов, переменных и других выражений, реализующих Expression, которые будут оцениваться во время выполнения для вычисления объекта Value:
```java
@AllArgsConstructor
@Геттер
открытый класс PrintStatement реализует оператор {
частное выражение final Expression;
@Override
публичное недействительное выполнение () {
Значение<?> значение = выражение.оценить();
System.out.println(значение);
3.6.2 Оператор присваивания
Чтобы объявить присваивание, нам нужно знать имя переменной и выражение, которое мы хотим присвоить. Наш язык сможет назначать литералы, переменные и более сложные выражения, реализуя интерфейс Expression:
```java
@AllArgsConstructor
@Геттер
открытый класс AssignStatement реализует оператор {
закрытое конечное имя строки;
частное выражение final Expression;
@Override
публичное недействительное выполнение () {
Во время выполнения нам нужно где-то хранить значения переменных. Давайте делегируем эту логику в поле BiConsumer, которое будет передавать имя переменной и присваиваемое значение. Обратите внимание, что значение Expression необходимо оценивать при выполнении присваивания:
```java
открытый класс AssignStatement реализует оператор {
закрытый окончательный BiConsumer<String, Value<?>> variableSetter;
@Override
публичное недействительное выполнение () {
variableSetter.accept(имя, выражение.evaluate());
3.6.3 Оператор ввода
Чтобы прочитать выражение из консоли, нам нужно знать имя переменной, которой нужно присвоить значение. Во время execute() мы должны прочитать строку из консоли. Эту работу можно делегировать «Поставщику», поэтому мы не будем создавать несколько входных потоков. После прочтения строки мы разбираем ее на соответствующий объект Value и делегируем присвоение экземпляру BiConsumer, как мы делали это для AssignStatement:
```java
@AllArgsConstructor
@Геттер
открытый класс InputStatement реализует оператор {
закрытое конечное имя строки;
закрытый окончательный Supplier
закрытый окончательный BiConsumer<String, Value<?>> variableSetter;
@Override
публичное недействительное выполнение () {
//просто способ сообщить пользователю, в какой переменной будет присвоено введенное значение
System.out.printf("введите \"%s\" >>> ", name.replace("_", " "));
Строка line = consoleSupplier.get();
Значение<?> значение;
если (line.matches("[0-9]+")) {
значение = новое числовое значение (Integer.parseInt (строка));
} иначе если (line.matches("true|false")) {
значение = новое логическое значение (логическое значение. значение из (строка));
} еще {
значение = новое TextValue (строка);
VariableSetter.accept(имя, значение);
3.6.4 Оператор условия
Во-первых, мы представим класс CompositeStatement, который будет содержать внутренний список операторов для выполнения:
```java
@Геттер
открытый класс CompositeStatement реализует оператор {
частные окончательные операторы List
public void addStatement (оператор заявления) {
если (утверждение != ноль)
операторы2Execute.add (инструкция);
@Override
публичное недействительное выполнение () {
операторы2Execute.forEach(оператор::выполнить);
Этот класс можно повторно использовать позже, если мы создадим конструкцию составных операторов. Первой из конструкций будет оператор «Условие». Для описания условия мы можем использовать литералы, переменные и более сложные конструкции, реализующие интерфейс Expression. В конце во время выполнения мы вычисляем значение «Выражения» и убеждаемся, что значение является логическим, а результат внутри правдивым. Только в этом случае мы можем выполнять внутренние операторы:
```java
@RequiredArgsConstructor
@Геттер
открытый класс ConditionStatement расширяет CompositeStatement {
частное конечное условие Expression;
@Override
публичное недействительное выполнение () {
Значение<?> значение = условие.оценить();
если (значение instanceof LogicalValue) {
если (((LogicalValue) значение).getValue()) {
супер.выполнить();
} еще {
throw new ExecutionException(String.format("Невозможно сравнить не логическое значение %s", значение));
3.7 Анализатор операторов
Теперь у нас есть операторы для работы с нашими лексемами, теперь мы можем построить StatementParser. Внутри класса мы объявляем список токенов и изменяемую переменную позиции токенов:
```java
открытый класс StatementParser {
частные окончательные токены List
частная позиция;
public StatementParser (список токенов
this.tokens = токены;
Затем мы создаем метод parseExpression(), который будет обрабатывать предоставленные токены и возвращать полноценный оператор:
```java
публичное выражение parseExpression() {
Наши языковые выражения могут начинаться только с объявления переменной или ключевого слова. Поэтому сначала нам нужно прочитать токен и проверить, что он имеет тип токена «Переменная» или «Ключевое слово». Чтобы справиться с этим, мы объявляем отдельный метод next() с типами токенов varargs в качестве аргумента, который будет проверять, что следующий токен имеет тот же тип. В истинном случае мы увеличиваем поле позиции StatementParser и возвращаем найденный токен:
```java
частное выражение parseExpression() {
Token token = следующий (TokenType.Keyword, TokenType.Variable);
частный токен следующий (тип TokenType, типы TokenType...) {
TokenType[] tokenTypes = org.apache.commons.lang3.ArrayUtils.add(типы, тип);
если (позиция < tokens.size()) {
Токен токен = tokens.get(position);
if (Stream.of(tokenTypes).anyMatch(t -> t == token.getType())) {
позиция++;
токен возврата;
Предыдущий токен = tokens.get(position - 1);
throw new SyntaxException(String.format("После объявления %s ожидается любая из следующих лексем %s", previousToken, Arrays.toString(tokenTypes)));
После того, как мы нашли подходящий токен, мы можем построить наш оператор в зависимости от типа токена.
3.7.1 Переменная
Каждое назначение переменной начинается с токена Variable, который мы уже читали. Следующим токеном, который мы ожидаем, является оператор равенства =. Вы можете переопределить метод next(), который будет принимать TokenType со строковым представлением оператора (например, =) и возвращать следующий найденный токен, только если он имеет тот же тип и значение, что и запрошенный:
```java
публичное выражение parseExpression() {
Token token = следующий (TokenType.Keyword, TokenType.Variable);
переключатель (токен.getType()) {
case Переменная:
следующий(TokenType.Operator, "="); //пропустить равно
значение выражения;
если (заглянуть (TokenType.Keyword, "новый")) {
значение = readInstance();
} еще {
значение = чтениеВыражение();
вернуть новый AssignStatement (token.getValue (), значение, переменные :: положить);
После оператора равенства мы читаем выражение. Выражение может начинаться с ключевого слова new, когда мы создаем экземпляр структуры. Мы рассмотрим этот случай чуть позже. Чтобы использовать токен с намерением проверить его значение без увеличения позиции и выдачи ошибки, мы создадим дополнительный метод peek(), который будет возвращать истинное значение, если следующий токен будет таким же, как мы ожидаем:
```java
частный логический просмотр (тип TokenType, строковое значение) {
если (позиция < tokens.size()) {
Токен токен = tokens.get(position);
возвращаемый тип == token.getType() && token.getValue().equals(value);
вернуть ложь;
Чтобы создать экземпляр AssignStatement, нам нужно передать объект BiConsumer в конструктор. Перейдем к объявлению полей StatementParser и добавим новое поле переменных карты, в котором будет храниться имя переменной в качестве ключа и значение переменной в качестве значения:
```java
открытый класс StatementParser {
закрытые конечные переменные Map<String, Value<?>>;
public StatementParser (список токенов
this.variables = новый HashMap<>();
Переменное выражение
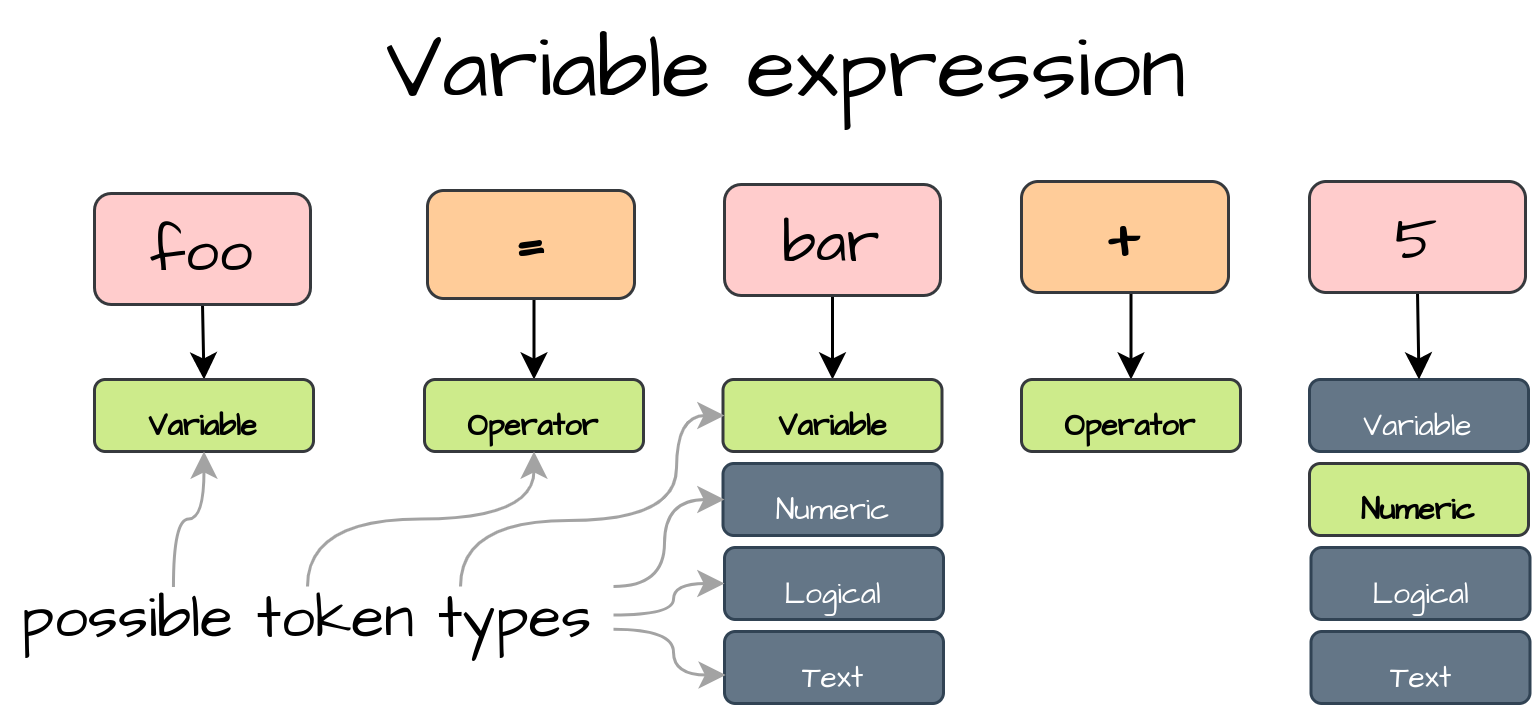
Во-первых, мы рассмотрим простое чтение выражения переменной, которое может быть литералом, другой переменной или более сложным выражением с операторами. Следовательно, метод readExpression() вернет выражение Expression с соответствующими реализациями. Внутри этого метода мы объявляем левый экземпляр Expression. Выражение может начинаться только с литерала или с другой переменной. Таким образом, мы ожидаем получить тип токена «Переменная», «Числовой», «Логический» или «Текст» из нашего метода «next()». После чтения правильного токена мы преобразуем его в соответствующий объект Expression внутри следующего блока переключателей и назначаем его левой переменной Expression:
```java
частное выражение readExpression() {
Выражение слева;
Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text);
Строковое значение = token.getValue();
переключатель (токен.getType()) {
случай Числовой:
слева = новое числовое значение (Integer.parseInt (значение));
случай Логический:
слева = новое логическое значение (логическое значение. значение из (значение));
кейс Текст:
слева = новое TextValue (значение);
case Переменная:
По умолчанию:
слева = новое ВыражениеПеременной(значение, переменные::получить);
После чтения левой переменной или литерала мы ожидаем поймать лексему Operator:
```java
частное выражение readExpression() {
Выражение слева;
Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text);
Строковое значение = token.getValue();
переключатель (токен.getType()) {
Операция токена = следующая (TokenType.Operator);
Класс<? расширяет OperatorExpression> operatorType = Operator.getType(operation.getValue());
Затем мы сопоставляем нашу лексему Operator с объектом OperatorExpression. Для этого вы можете использовать блок переключателей, возвращающий правильный класс OperatorExpression в зависимости от значения токена. Я буду использовать константы перечисления с соответствующим типом OperatorExpression:
```java
@RequiredArgsConstructor
@Геттер
оператор публичного перечисления {
Инкремент ("++", IncrementOperator.class),
Декремент("--", ДекрементОператор.класс),
Не("!", NotOperator.класс),
Дополнение("+", AdditionOperator.class),
Вычитание("-", SubtractionOperator.class),
Равенство ("==", EqualsOperator.class),
GreaterThan(">", GreaterThanOperator.class),
МеньшеЧем("<", МеньшеЧемОператор.класс),
StructureValue("::", StructureValueOperator.class);
закрытый конечный символ строки;
частный окончательный класс<? расширяет OperatorExpression> тип_оператора;
общедоступный статический класс<? расширяет OperatorExpression> getType (строковый символ) {
вернуть Arrays.stream (значения ())
.filter(t -> Objects.equals(t.getCharacter(), символ))
.map(Оператор::getOperatorType)
.findAny().orElse(null);
В конце мы читаем правый литерал или переменную так же, как и для левого Expression. Чтобы не дублировать код, мы выделяем чтение Expression в отдельный метод nextExpression():
```java
частное выражение nextExpression() {
Token token = next(TokenType.Variable, TokenType.Numeric, TokenType.Logical, TokenType.Text);
Строковое значение = token.getValue();
переключатель (токен.getType()) {
случай Числовой:
вернуть новое числовое значение (Integer.parseInt (значение));
случай Логический:
вернуть новое логическое значение (Boolean.valueOf (значение));
кейс Текст:
вернуть новое TextValue (значение);
case Переменная:
По умолчанию:
вернуть новое ВыражениеПеременной(значение, переменные::получить);
Давайте реорганизуем метод readExpression() и прочитаем нужную лексему, используя nextExpression(). Но прежде чем мы прочитаем правильную лексему, нам нужно убедиться, что наш оператор поддерживает два операнда. Мы можем проверить, расширяет ли наш оператор BinaryOperatorExpression. В другом случае, если оператор унарный, мы создаем OperatorExpression, используя только левое выражение. Чтобы создать объект OperatorExpression, мы извлекаем подходящий конструктор для реализации унарного или бинарного оператора, а затем создаем экземпляр с полученными ранее выражениями:
```java
@SneakyThrows
частное выражение readExpression() {
Выражение слева = следующееВыражение();
Операция токена = следующая (TokenType.Operator);
Класс<? расширяет OperatorExpression> operatorType = Operator.getType(operation.getValue());
if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) {
Выражение справа = следующееВыражение();
тип оператора возврата
.getConstructor(Выражение.класс, Выражение.класс)
.newInstance (слева, справа);
} else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) {
тип оператора возврата
.getConstructor(выражение.класс)
.новый экземпляр (слева);
вернуться влево;
Кроме того, мы можем предоставить возможность создать длинное выражение с несколькими операторами или вообще без операторов с одним литералом или переменной. Заключим операцию чтения в цикл while с условием, что у нас есть Оператор в качестве следующей лексемы. Каждый раз, когда мы создаем OperatorExpression, мы присваиваем его левому выражению, таким образом создавая дерево последующих операторов внутри одного Expression, пока мы не прочитаем все выражение. В конце возвращаем левое выражение:
```java
@SneakyThrows
частное выражение readExpression() {
Выражение слева = следующееВыражение();
// рекурсивно читаем выражение
в то время как (заглянуть (TokenType.Operator)) {
Операция токена = следующая (TokenType.Operator);
Класс<? расширяет OperatorExpression> operatorType = Operator.getType(operation.getValue());
if (BinaryOperatorExpression.class.isAssignableFrom(operatorType)) {
Выражение справа = следующееВыражение();
слева = тип оператора
.getConstructor(Выражение.класс, Выражение.класс)
.newInstance (слева, справа);
} else if (UnaryOperatorExpression.class.isAssignableFrom(operatorType)) {
слева = тип оператора
.getConstructor(выражение.класс)
.новый экземпляр (слева);
вернуться влево;
частный логический просмотр (тип TokenType) {
если (позиция < tokens.size()) {
Токен токен = tokens.get(position);
вернуть token.getType() == тип;
вернуть ложь;
Экземпляр структуры
После того, как мы завершили реализацию readExpression(), мы можем вернуться к parseExpression() и завершить реализацию readInstance() для создания экземпляра структуры:

Согласно семантике нашего языка мы знаем, что создание экземпляра нашей структуры начинается с ключевого слова new, мы можем пропустить следующий токен, вызвав метод next(). Следующая лексема будет обозначать имя структуры, мы читаем ее как тип токена Variable. После имени структуры мы ожидаем получить аргументы в квадратных скобках в качестве разделителей групп. В некоторых случаях наша структура может быть создана вообще без аргументов. Поэтому сначала мы используем peek(). Каждый аргумент, передаваемый в структуру, может означать выражение, поэтому мы вызываем readExpression() и передаем результат в список аргументов. После построения аргументов структуры мы можем построить наше StructureExpression, предварительно получив соответствующее StructureDefinition:
```java
частное выражение readInstance() {
следующий(TokenType.Keyword, "новый"); //пропустить новый
Тип токена = следующий (TokenType.Variable);
Аргументы List
если (заглянуть (TokenType.GroupDivider, "[")) {
следующий (TokenType.GroupDivider, "["); //пропустить открытую квадратную скобку
в то время как (! peek (TokenType.GroupDivider, "]")) {
Значение выражения = readExpression();
аргументы.добавить (значение);
следующий(TokenType.GroupDivider, "]"); //пропустить закрывающую квадратную скобку
Определение StructureDefinition = Structures.get(type.getValue());
если (определение == ноль) {
throw new SyntaxException(String.format("Структура не определена: %s", type.getValue()));
вернуть новое СтруктурноеВыражение(определение, аргументы, переменные::получить);
Чтобы получить StructureDefinition по имени, мы должны объявить карту структур как поле StatementParser, мы заполним его позже во время анализа ключевого слова struct:
```java
открытый класс StatementParser {
закрытые конечные структуры Map
public StatementParser (список токенов
this.structures = новый HashMap<>();
3.7.2 Ключевое слово
Теперь мы можем продолжить работу над методом parseExpression(), когда получим лексему Keyword:
```java
публичное выражение parseExpression() {
переключатель (токен.getType()) {
case Переменная:
чехол Ключевое слово:
переключатель (токен.getValue()) {
случай "печать":
случай "ввод":
случай "если":
случай "структура":
Наше языковое выражение может начинаться с ключевых слов «print», «input», «if» и «struct».
Распечатать
Чтобы прочитать значение печати, мы вызываем уже созданный метод readExpression(). Он будет читать литерал, переменную или более сложную реализацию «Выражения», как мы это делали для назначения переменной. Затем мы создаем и возвращаем экземпляр PrintStatement:
```java
случай "печать":
Выражение выражение = чтениеВыражение();
вернуть новый PrintStatement (выражение);
Вход
Для оператора ввода нам нужно знать имя переменной, которой мы присваиваем значение. Поэтому мы просим метод next() поймать для нас следующий токен Variable:
```java
случай "ввод":
Переменная токена = следующая (TokenType.Variable);
вернуть новый InputStatement(variable.getValue(), Scanner::nextLine, Variables::put);
Чтобы создать экземпляр InputStatement, мы вводим объект Scanner в объявлении полей StatementParser, который поможет нам прочитать строку из консоли:
```java
открытый класс StatementParser {
частный финальный сканер Scanner;
public StatementParser (список токенов
this.scanner = новый сканер (System.in);
Если
Следующее утверждение, которое мы коснемся, это условие if/then:
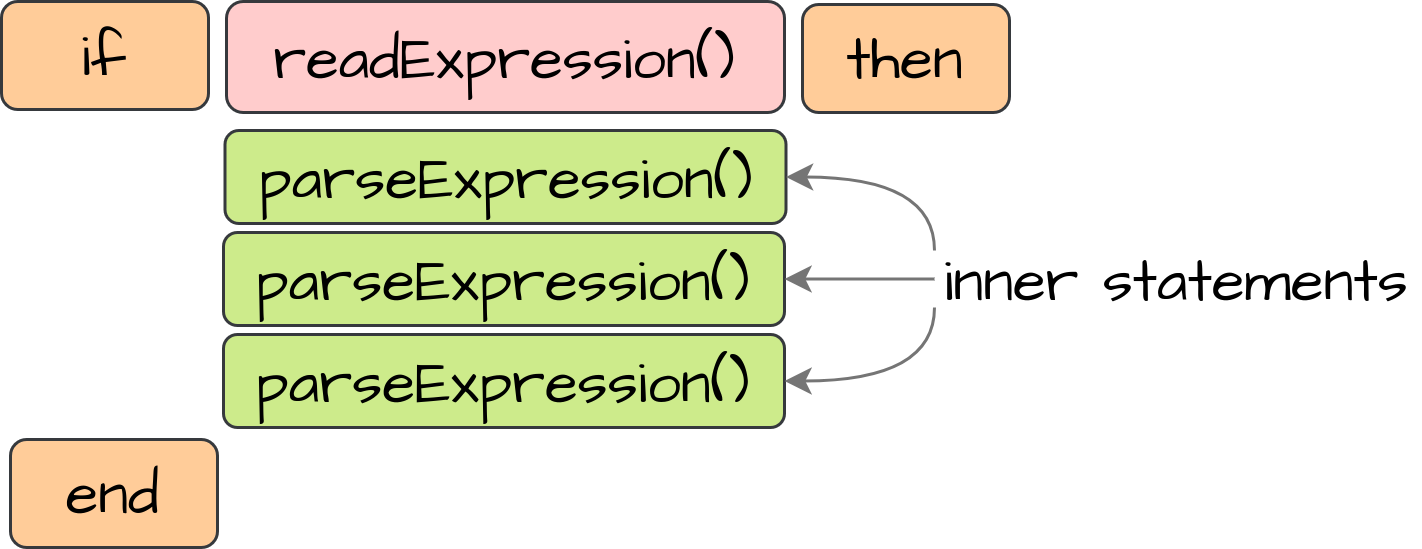
Во-первых, когда мы получаем ключевое слово if, мы читаем выражение условия, вызывая readExpression(). Затем, в соответствии с семантикой нашего языка, нам нужно поймать ключевое слово then. Внутри нашего условия мы можем объявить другие операторы, включая другие операторы условий. Поэтому мы рекурсивно добавляем parseExpression() во внутренние операторы условия, пока не прочитаем завершающее ключевое слово end:
```java
случай "если":
Условие выражения = readExpression();
следующий(ТипТокена.Ключевое слово, "затем"); // тогда пропустить
ConditionStatement conditionStatement = новый ConditionStatement(условие);
в то время как (!Peek(TokenType.Keyword, "конец")) {
Оператор оператора = parseExpression();
conditionStatement.addStatement (оператор);
следующий(ТипТокена.Ключевое слово, "конец"); // пропустить конец
вернуть условиеУтверждение;
Структура
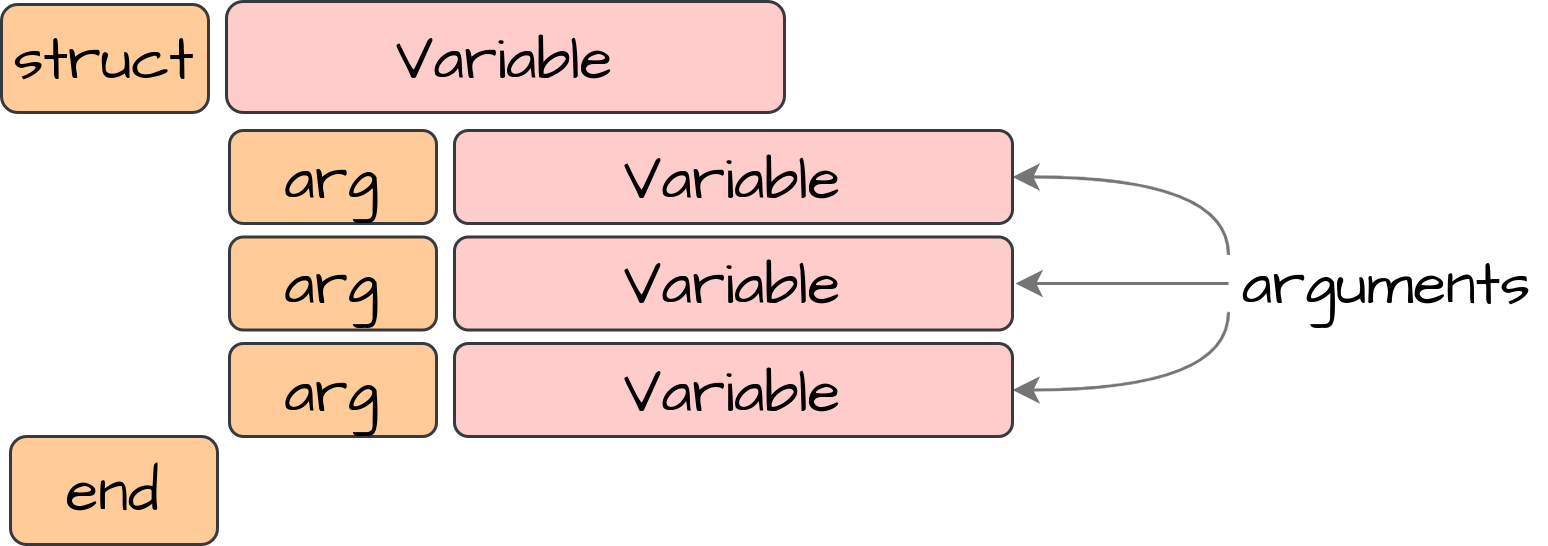
Объявление структуры довольно простое, потому что оно состоит только из типов токенов «Переменная» и «Ключевое слово». После прочтения ключевого слова struct мы ожидаем прочитать имя структуры как тип токена Variable. Затем мы читаем аргументы, пока не найдем ключевое слово end. В конце мы создаем наше StructureDefinition и помещаем его в карту структур, чтобы к нему можно было получить доступ в будущем, когда мы создадим экземпляр структуры:
```java
случай "структура":
Тип токена = следующий (TokenType.Variable);
Set
в то время как (!Peek(TokenType.Keyword, "конец")) {
следующий(ТипТокена.Ключевое слово, "аргумент");
Аргумент токена = следующий (TokenType.Variable);
args.add(arg.getValue());
следующий(ТипТокена.Ключевое слово, "конец"); // пропустить конец
Structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args)));
вернуть ноль;
Полный метод parseExpression():
```java
публичное выражение parseExpression() {
Token token = следующий (TokenType.Keyword, TokenType.Variable);
переключатель (токен.getType()) {
case Переменная:
следующий(TokenType.Operator, "="); //пропустить равно
значение выражения;
если (заглянуть (TokenType.Keyword, "новый")) {
значение = readInstance();
} еще {
значение = чтениеВыражение();
вернуть новый AssignStatement (token.getValue (), значение, переменные :: положить);
чехол Ключевое слово:
переключатель (токен.getValue()) {
случай "печать":
Выражение выражение = чтениеВыражение();
вернуть новый PrintStatement (выражение);
случай "ввод":
Переменная токена = следующая (TokenType.Variable);
вернуть новый InputStatement(variable.getValue(), Scanner::nextLine, Variables::put);
случай "если":
Условие выражения = readExpression();
следующий(ТипТокена.Ключевое слово, "затем"); // тогда пропустить
ConditionStatement conditionStatement = новый ConditionStatement(условие);
в то время как (!Peek(TokenType.Keyword, "конец")) {
Оператор оператора = parseExpression();
conditionStatement.addStatement (оператор);
следующий(ТипТокена.Ключевое слово, "конец"); // пропустить конец
вернуть условиеУтверждение;
случай "структура":
Тип токена = следующий (TokenType.Variable);
Set
в то время как (!Peek(TokenType.Keyword, "конец")) {
следующий(ТипТокена.Ключевое слово, "аргумент");
Аргумент токена = следующий (TokenType.Variable);
args.add(arg.getValue());
следующий(ТипТокена.Ключевое слово, "конец"); // пропустить конец
Structures.put(type.getValue(), new StructureDefinition(type.getValue(), new ArrayList<>(args)));
вернуть ноль;
По умолчанию:
throw new SyntaxException(String.format("Утверждение не может начинаться со следующей лексемы %s", токен));
Чтобы найти и собрать все операторы, мы создаем метод parse(), который будет анализировать все выражения из заданных токенов и возвращать экземпляр CompositeStatement:
```java
анализ публичного заявления () {
CompositeStatement root = new CompositeStatement();
в то время как (позиция < tokens.size()) {
Оператор оператора = parseExpression();
root.addStatement (оператор);
вернуть корень;
4 Язык игрушек
Мы закончили с лексическим и синтаксическим анализатором. Теперь мы можем собрать обе реализации в класс ToyLanguage и, наконец, запустить наш язык:
```java
открытый класс ToyLanguage {
@SneakyThrows
public void execute (путь пути) {
Источник строки = Files.readString(путь);
LexicalParser lexicalParser = новый LexicalParser(источник);
List
StatementParser statementParser = новый StatementParser (токены);
Заявление заявление = заявлениеParser.parse();
заявление.выполнить();

5 Подведение итогов
В этом руководстве мы создали собственный язык с помощью лексического и синтаксического анализа. Надеюсь, эта статья будет кому-то полезна. Я настоятельно рекомендую вам попробовать написать свой собственный язык, несмотря на то, что вы должны понимать множество деталей реализации. Это обучающий, самосовершенствующийся и интересный эксперимент!
Оригинал
🔥 Популярное на этой неделе
-
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27758)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)