

Построение модели склонности для лучшего нацеливания на пользователей в маркетинговых кампаниях
5 июня 2022 г.Склонность к надежде и радости - настоящее богатство; тот, кто боится и скорбит о настоящей бедности. — Дэвид Хьюм
Абстрактный
Маркетологи тратят много времени на разговоры о важности доставки правильных сообщений идеальным людям в идеальное время. Уведомление или отправка по электронной почте, когда пользователь не заинтересован, может привести к тому, что многие пользователи отключат уведомления приложений или сообщат о спаме в электронных письмах, что блокирует все будущие сообщения.
Маркетинг требует затрат как финансовых средств, так и пользовательского опыта. Если на платформе 100 тысяч пользователей, разумно приложить усилия только для подгруппы пользователей, которые могут быть заинтересованы в покупке/конверсии.

Лучший способ определить, кто из вашей аудитории с наибольшей вероятностью совершит покупку, примет предложение или подпишется на услугу, — это модель склонности. Давайте лучше разберемся в модели склонности, поработав над постановкой задачи: Создайте модель склонности, чтобы определить, совершит ли пользователь покупку при повторном посещении.
Цель
Задача
- Модель склонности для определения вероятности того, что человек купит продукт при повторном посещении.
- Нам нужно определить вероятность конвертации для каждого пользователя.
Бизнес-результат
- Оценка склонности поможет сегментировать пользователей и проводить различные маркетинговые кампании, чтобы повысить коэффициент конверсии.
- Мы можем делиться мобильными уведомлениями или электронными письмами с эксклюзивными предложениями для пользователей с высокой склонностью, помогая предприятиям с разговорами.
Подход
Что такое показатель склонности?
- Склонность – это естественная склонность вести себя определенным образом. У всех нас есть склонности — вещи, которые мы склонны делать.
- Моделирование склонности пытается предсказать вероятность того, что посетители, лиды и клиенты будут выполнять определенные действия.
- Показатель склонности можно определить как P(Target = 1 | Z), где Z — характерные особенности поведения пользователя на сайте.
Требуется функция
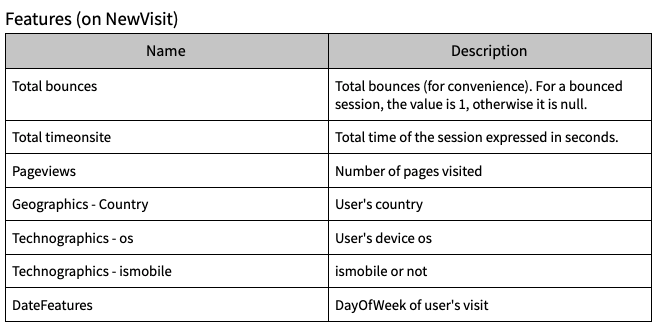
Анализ данных
Проанализируйте свои данные, чтобы понять, сколько % положительного класса (пользователь покупает при повторном посещении) и отрицательного класса (пользователь не покупает при повторном посещении).

- Положительный класс (1), т. е. покупка пользователем при повторном посещении: 1,53% [Покупатель с высокой склонностью]
- Отрицательный класс (0), т. е. пользователь не покупает при повторном посещении: 98,47% [Клиент с низкой склонностью]
Выбор показателя
Для нашего маркетингового варианта использования для повышения коэффициента конверсии:
Стоимость ложноотрицательного результата (маркировка высокой склонности как низкой) > Стоимость ложноположительного результата (маркировка клиента с низкой склонностью как высокой)
Следовательно, наша метрика должна быть такой, что: отзыв важнее точности
Значение бета, равное 2, будет привлекать больше внимания к отзыву, чем к точности, и называется мерой F2.
```javascript
F2-мера = ((1 + 2²) * точность * полнота) / (2² * точность + полнота)
Обучение модели
Модель склонности представляет собой проблему бинарной классификации, мы будем использовать логистическую регрессию для нашей модели.
Схема обучения модели
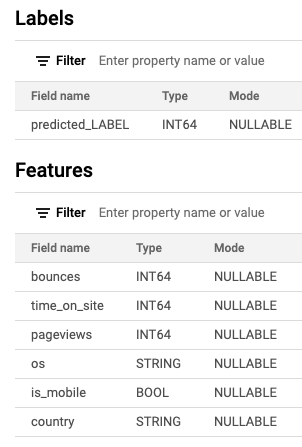
Выход модели
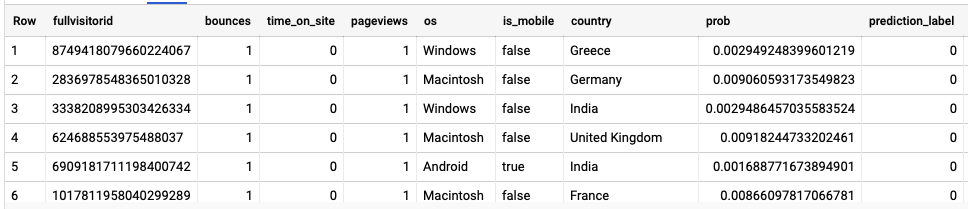
вероятность: — это логистическая регрессия вероятность возникновения события, в нашем случае событием является покупка пользователем при повторном посещении или нет.
Эксперимент
Мы провели 3 эксперимента с различными наборами функций с логистической регрессией и обнаружили, что 2-й из них показал лучшие результаты по нашим показателям.
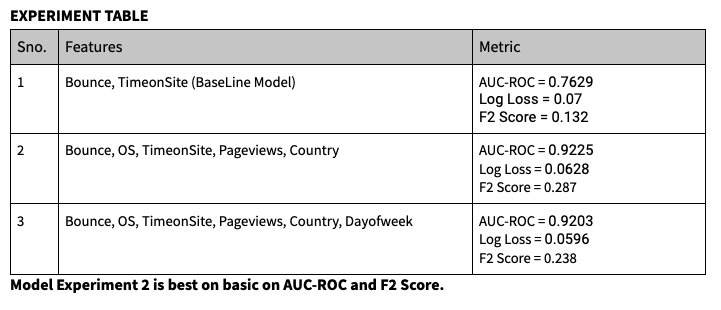
ВИЗУАЛИЗАЦИЯ оценки модели (Лучшая модель: 2-е место в приведенной выше таблице экспериментов | Порог положительного класса: 0,0217)
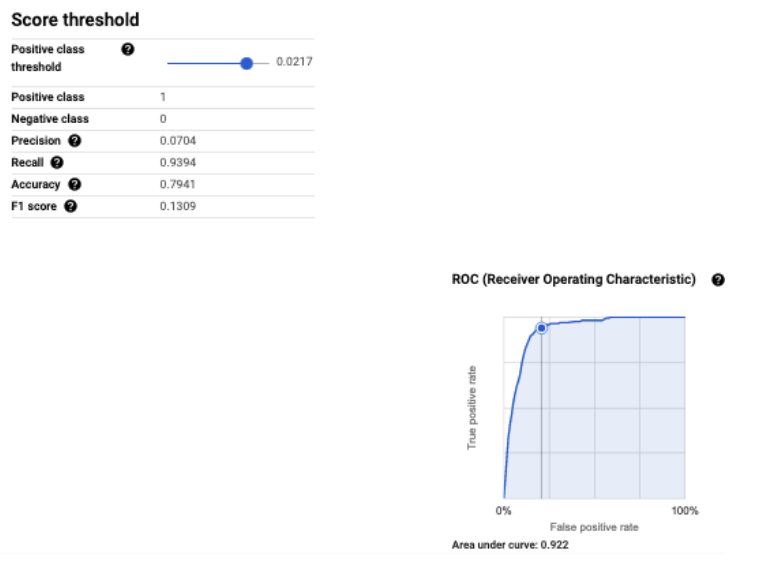
Лучшее пороговое значение для положительного класса = 0,0217 означает вероятность логистической регрессии ≥ пороговое значение относится к положительному классу (пользователь купит при повторном посещении), иначе — к отрицательному классу.
Результаты тестового набора данных для модели предрасположенности
При тестировании экспериментальной модели 2 с функциями Bounce, OS, TimeOnSite, просмотрами страниц и страной. Мы получили отзыв 91,7% и точность 3,9%. Высокий отзыв связан с низким уровнем ложноотрицательных результатов, а низкий уровень точности связан с высоким уровнем ложноположительных результатов.
Матрица путаницы в тестовом наборе данных
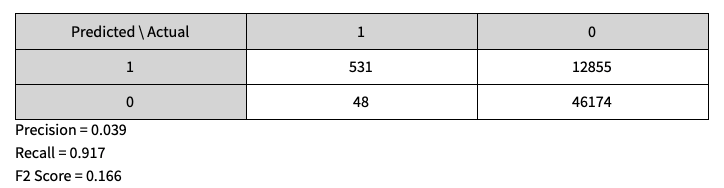
ПРИМЕЧАНИЕ. При построении этой модели нашей целью было максимизировать коэффициент конверсии. Мы уделили больше внимания отзыву, т. Е. Стоимость (ложноотрицательный результат)> стоимость (ложноположительный результат)
Если затраты на маркетинговую коммуникацию высоки, а требования бизнеса (равные Точность и Отзыв) нам потребуется изменить порог положительного класса и метрику таким образом, чтобы Отзыв = Точность (в качестве метрики взять F1 Score).
Объем улучшения модели
- Если пользователь вошел в систему на веб-сайте или нет.
- Добавить источник трафика; органика или реклама привела их на сайт
- Используйте временные функции: некоторые пользователи любят делать покупки ночью (ссылка на пример)
- Используйте технические характеристики: бренд и модель устройства, чтобы лучше ориентироваться на пользователей. Было проведено несколько тематических исследований, подтверждающих, что пользователи, имеющие дорогие/высококачественные устройства, конвертируют больше. (ссылка на пример)
- Попробуйте поэкспериментировать с моделью, добавив дополнительные географические данные пользователя, например город/штат. Пользователи, посещающие веб-сайт из городов уровня 1 или штатов с более высоким показателем на душу населения, имеют более высокую склонность к конверсии.
Вывод
Теперь, используя эту модель предрасположенности, маркетинг и таргетинг на аудиторию можно делать более разумно, где шансы на конверсию пользователя (покупку) с платформы выше. Кроме того, это помогает команде маркетинга с точки зрения затрат, поскольку им больше не нужно запускать кампании/уведомления/рассылки по электронной почте для всех посетителей, а вместо этого сосредоточиться только на подмножестве пользователей с высоким показателем предрасположенности.
Надеюсь, вы узнали что-то новое из этого блога. Если вам понравилось, нажмите 👏 и поделитесь этой статьей. Следите за новостями!
АВТОР: https://www.linkedin.com/in/shaurya-uppal/
Информационный бюллетень: https://www.linkedin.com/newsletters/problem-solving-data-science-6874965456701198336/
*Также опубликовано здесь. *
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27702)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)